
Question-Answering Systems: Overview of Main Architectures
Discover design approaches for building a scalable information retrieval system
Introduction
Question-answering applications have intensely emerged in recent years. They can be found everywhere: in modern search engines, chatbots or applications that simply retrieve relevant information from large volumes of thematic data.
As the name indicates, the objective of QA applications is to retrieve the most suitable answer to a given question in a text passage. Some of the first methods consisted of naive search by keywords or regular expressions. Obviously, such approaches are not optimal: a question or text can contain typos. Moreover, regular expressions cannot detect synonyms which can be highly relevant to a given word in a query. As a result, these approaches were replaced by the new robust ones, especially in the era of Transformers and vector databases.
This article covers three main design approaches for building modern and scalable QA applications.
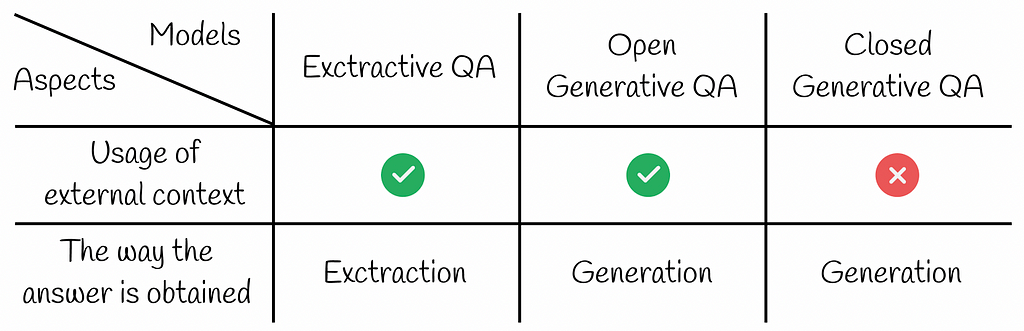
Exctractive QA
Extractive QA systems consist of three components:
- Retriever
- Database
- Reader

Firstly, the question is fed into the retriever. The goal of the retriever is to return an embedding corresponding to the question. There can be multiple implementations of retriever starting from simple vectorization methods like TF-IDF, BM-25 and ending up with more complex models. Most of the time, Transformer-like models (BERT) are integrated into the retriever. Unlike naive approaches that rely only on word frequency, language models can build dense embeddings that are capable of capturing the semantic meaning of text.
After obtaining a query vector from a question, it is then used to find the most similar vectors among an external collection of documents. Each of the documents has a certain chance of containing the answer to the question. As a rule, the collection of documents is processed during the training phase by being passed to the retriever which outputs corresponding embeddings to the documents. These embeddings are then usually stored in a database which can provide an effective search.
In QA systems, vector databases usually play the role of a component for efficient storage and search among embeddings based on their similarity. The most popular vector databases are Faiss, Pinecone and Chroma.
If you would like to better understand how vector databases work under the hood, then I recommend you check my article series on similarity search where I deeply cover the most popular algorithms:
By retrieving the k most similar database vectors to the query vector, their original text representations are used to find the answer by another component called the reader. The reader takes an initial question and for each of the k retrieved documents it extracts the answer in the text passage and returns a probability of this answer being correct. The answer with the highest probability is then finally returned from the exclusive QA system.
Fine-tuned large language models specialising in QA downstream tasks are usually used in the role of the reader.
Open Generative QA
Open Generative QA follows exactly the same framework as Extractive QA except for the fact that they use the generator instead of the reader. Unlike the reader, the generator does not extract the answer from a text passage. Instead, the answer is generated from the information provided in the question and text passages. As in the case of Extractive QA, the answer with the highest probability is chosen as the final answer.
As the name indicates, Open Generative QA systems normally use generative models like GPT for answer generation.

By having a very similar structure, there might come a question of when it is better to use an Extractive or Open Generative architecture. It turns out that when a reader model has direct access to a text passage containing relative information, it is usually smart enough to retrieve a precise and concise answer. On the other hand, most of the time, generative models tend to produce longer and more generic information for a given context. That might be beneficial in cases when a question is asked in an open form but not for situations when a short or exact answer is expected.
Retrieval-Augmented Generation
Recently, the popularity of the term “Retrieval-Augmented Generation” or “RAG” has skyrocketed in machine learning. In simple words, it is a framework for creating LLM applications whose architecture is based on Open Generative QA systems.
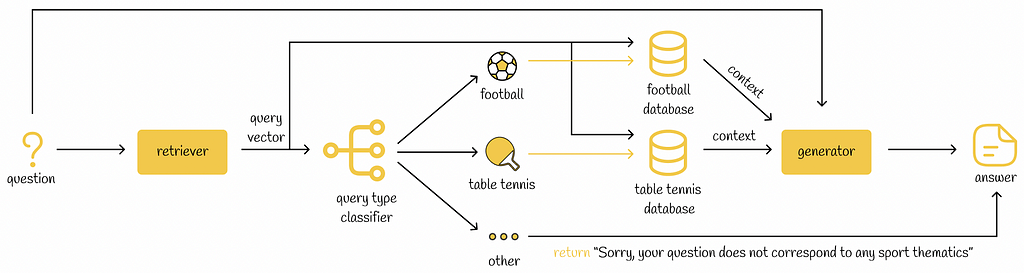
In some cases, if an LLM application works with several knowledge domains, the RAG retriever can add a supplementary step in which it will try to identify the most relevant knowledge domain to a given query. Depending on an identified domain, the retriever can then perform different actions. For example, it is possible to use several vector databases each corresponding to a particular domain. When a query belongs to a certain domain, the vector database of that domain is then used to retrieve the most relevant information for the query.
This technique makes the search process faster since we search through only a particular subset of documents (instead of all documents). Moreover, it can make the search more reliable as the ultimate retrieved context is constructed from more relevant documents.
Closed Generative QA
Closed Generative QA systems do not have access to any external information and generate answers by only using the information from the question.

The obvious advantage of closed QA systems is reduced pipeline time as we do not have to search through a large collection of external documents. But it comes with the cost of training and accuracy: the generator should be robust enough and have a large training knowledge to be capable of generating appropriate answers.
Closed Generative QA pipeline has another disadvantage: generators do not know any information that appeared later in the data it had been trained on. To eliminate this issue, a generator can be trained again on a more recent dataset. However, generators usually have millions or billions of parameters, thus training them is an extremely resource-heavy task. In comparison, dealing with the same problem with Extractive QA and Open Generative QA systems is much simpler: it is just enough to add new context data to the vector database.
Most of the time closed generative approach is used in applications with generic questions. For very specific domains, the performance of closed generative models tends to degrade.
Conclusion
In this article, we have discovered three main approaches for building QA systems. There is no absolute winner among them: all of them have their own pros and cons. For that reason, it is firstly necessary to analyse the input problem and then choose the correct QA architecture type, so it can produce a better performance.
It is worth noting that Open Generative QA architecture is currently on the trending hype in machine learning, especially with innovative RAG techniques that have appeared recently. If you are an NLP engineer, then you should definitely keep your eye on RAG systems as they are evolving at a very high rate nowadays.
Resources
All images unless otherwise noted are by the author
Question-Answering Systems: Overview of Main Architectures was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Discover design approaches for building a scalable information retrieval system
Introduction
Question-answering applications have intensely emerged in recent years. They can be found everywhere: in modern search engines, chatbots or applications that simply retrieve relevant information from large volumes of thematic data.
As the name indicates, the objective of QA applications is to retrieve the most suitable answer to a given question in a text passage. Some of the first methods consisted of naive search by keywords or regular expressions. Obviously, such approaches are not optimal: a question or text can contain typos. Moreover, regular expressions cannot detect synonyms which can be highly relevant to a given word in a query. As a result, these approaches were replaced by the new robust ones, especially in the era of Transformers and vector databases.
This article covers three main design approaches for building modern and scalable QA applications.
Exctractive QA
Extractive QA systems consist of three components:
- Retriever
- Database
- Reader
Firstly, the question is fed into the retriever. The goal of the retriever is to return an embedding corresponding to the question. There can be multiple implementations of retriever starting from simple vectorization methods like TF-IDF, BM-25 and ending up with more complex models. Most of the time, Transformer-like models (BERT) are integrated into the retriever. Unlike naive approaches that rely only on word frequency, language models can build dense embeddings that are capable of capturing the semantic meaning of text.
After obtaining a query vector from a question, it is then used to find the most similar vectors among an external collection of documents. Each of the documents has a certain chance of containing the answer to the question. As a rule, the collection of documents is processed during the training phase by being passed to the retriever which outputs corresponding embeddings to the documents. These embeddings are then usually stored in a database which can provide an effective search.
In QA systems, vector databases usually play the role of a component for efficient storage and search among embeddings based on their similarity. The most popular vector databases are Faiss, Pinecone and Chroma.
If you would like to better understand how vector databases work under the hood, then I recommend you check my article series on similarity search where I deeply cover the most popular algorithms:
By retrieving the k most similar database vectors to the query vector, their original text representations are used to find the answer by another component called the reader. The reader takes an initial question and for each of the k retrieved documents it extracts the answer in the text passage and returns a probability of this answer being correct. The answer with the highest probability is then finally returned from the exclusive QA system.
Fine-tuned large language models specialising in QA downstream tasks are usually used in the role of the reader.
Open Generative QA
Open Generative QA follows exactly the same framework as Extractive QA except for the fact that they use the generator instead of the reader. Unlike the reader, the generator does not extract the answer from a text passage. Instead, the answer is generated from the information provided in the question and text passages. As in the case of Extractive QA, the answer with the highest probability is chosen as the final answer.
As the name indicates, Open Generative QA systems normally use generative models like GPT for answer generation.
By having a very similar structure, there might come a question of when it is better to use an Extractive or Open Generative architecture. It turns out that when a reader model has direct access to a text passage containing relative information, it is usually smart enough to retrieve a precise and concise answer. On the other hand, most of the time, generative models tend to produce longer and more generic information for a given context. That might be beneficial in cases when a question is asked in an open form but not for situations when a short or exact answer is expected.
Retrieval-Augmented Generation
Recently, the popularity of the term “Retrieval-Augmented Generation” or “RAG” has skyrocketed in machine learning. In simple words, it is a framework for creating LLM applications whose architecture is based on Open Generative QA systems.
In some cases, if an LLM application works with several knowledge domains, the RAG retriever can add a supplementary step in which it will try to identify the most relevant knowledge domain to a given query. Depending on an identified domain, the retriever can then perform different actions. For example, it is possible to use several vector databases each corresponding to a particular domain. When a query belongs to a certain domain, the vector database of that domain is then used to retrieve the most relevant information for the query.
This technique makes the search process faster since we search through only a particular subset of documents (instead of all documents). Moreover, it can make the search more reliable as the ultimate retrieved context is constructed from more relevant documents.
Closed Generative QA
Closed Generative QA systems do not have access to any external information and generate answers by only using the information from the question.
The obvious advantage of closed QA systems is reduced pipeline time as we do not have to search through a large collection of external documents. But it comes with the cost of training and accuracy: the generator should be robust enough and have a large training knowledge to be capable of generating appropriate answers.
Closed Generative QA pipeline has another disadvantage: generators do not know any information that appeared later in the data it had been trained on. To eliminate this issue, a generator can be trained again on a more recent dataset. However, generators usually have millions or billions of parameters, thus training them is an extremely resource-heavy task. In comparison, dealing with the same problem with Extractive QA and Open Generative QA systems is much simpler: it is just enough to add new context data to the vector database.
Most of the time closed generative approach is used in applications with generic questions. For very specific domains, the performance of closed generative models tends to degrade.
Conclusion
In this article, we have discovered three main approaches for building QA systems. There is no absolute winner among them: all of them have their own pros and cons. For that reason, it is firstly necessary to analyse the input problem and then choose the correct QA architecture type, so it can produce a better performance.
It is worth noting that Open Generative QA architecture is currently on the trending hype in machine learning, especially with innovative RAG techniques that have appeared recently. If you are an NLP engineer, then you should definitely keep your eye on RAG systems as they are evolving at a very high rate nowadays.
Resources
All images unless otherwise noted are by the author
Question-Answering Systems: Overview of Main Architectures was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.