
Visual Question Answering with DeepProbLog Using Neuro-Symbolic AI | by Jorrit Willaert | Oct, 2022
Comparing neuro-symbolic AI against a purely neural network-based approach on visual question-answering
This article focuses on Visual Question Answering, where a neuro-symbolic AI approach with a knowledge base is compared with a purely neural network-based approach. From the experiments, it follows that DeepProbLog, the framework used for the neuro-symbolic AI approach, is able to achieve the same accuracy as the pure neural network-based approach with almost 200 times less iterations. Clearly, the training is much more targeted, but comes at a cost. The algebraic operators internal to DeepProbLog are extremely costly and hence the actual training time is considerably slower. Another drawback of DeepProbLog is that no easy speedups can be achieved, since the algebraic operators only work on CPUs (at least for now), and hence cannot benefit from accelerators such as GPUs.
The Neuro-Symbolic AI field is interested in building a bridge between the robustness of probabilistic knowledge and the well-known popularity and proven strengths of deep neural networks. DeepProbLog [1] offers this ability, by using both the strengths of neural networks (i.e., system 1, typical subconscious tasks such as visual recognition, the processing of languages, …), along with the strengths of rule-based probabilistic systems (i.e., system 2, slow, sequential thinking such as the derivation of a proof) [2].
This article elaborates on an application that requires both systems to be used, namely Visual Question Answering. System 1 will be required in order to gain an understanding of the image under investigation, with in particular their shapes and colors. System 2, on the other hand, will use this extracted information for deriving certain properties of objects (e.g., finding the shape of a green object), or even for capturing the relations between the objects (e.g., counting the number of circles in the image).
The application focuses on Visual Question Answering (VQA), for which huge datasets are present, along with very sophisticated methods. The best known dataset for VQA is CLEVR [3], which contains 100k images accompanied by one million questions. An example image is given beneath, while example questions are:
- Are there an equal number of large things and metal
spheres? - What size is the cylinder that is left of the brown metal
thing that is left of the big sphere? - How many objects are either small cylinders or metal
things?

Clearly, both system 1 and system 2 are actively used when answering these questions. One could wonder if neural networks alone could answer these questions without having an explicit system 2 encoding (i.e. the rule based knowledge base). Intuitively, it makes sense that if certain facts of the world are known, learning can proceed much more quickly. Seen from an optimization viewpoint, errors made during prediction in this setup can be targeted exactly, which makes the optimization process more targeted as well, and hence more efficient. Finally, this article also provides evidence for these statements, since in subsection 4.1, the comparison between a VQA implementation with DeepProbLog is made with a purely neural network based approach.
This article is inspired by the CLEVR dataset, but uses a much more simplified version. In essence, it is almost like the Sort-of-CLEVR dataset [4]. The Sort-of-CLEVR dataset contains images as in Figure 2, while asking questions such as:sed for commercial use…
- Non-relational questions: the shape, horizontal or vertical location of an object.
- Relational questions: shape of the closest/furthest object to the object under investigation, or the number of objects with the same shape.
![A sample image from the Sort-of-CLEVR dataset [4]](https://miro.medium.com/max/512/1*vAh8tZ8uydRj1NNEc3Ttaw.png)
As illustrated earlier, both system 1 and system 2 are required for these types of VQA’s.
A. Santoro et al. conducted similar experiments with the Sort-of-CLEVR dataset as in this article, where they were able to achieve an accuracy of 63% on relational questions with CNN’s. In contrast, an accuracy of 94% for both relational and non-relational questions was achieved with CNN’s, complemented with an RN. For them, augmenting the model with a relational module, such as an RN, turned out to be sufficient to overcome the hurdle of solving relational questions [4]. They were the only researchers who undertook experiments on a dataset resembling the one from this article, and hence are the only reference point.
Finally, since this application uses DeepProbLog, quite some time was spent in digesting the DeepProbLog paper [1], along with understanding the examples provided in the code repository [5].
The implementation process involved three main parts:
- Generation of the data
- Linking the data and controlling the training process in pure Python code.
- Creation of the logical part with DeepProbLog statements.
3.1 Generation of the data
As mentioned in Section 2, the data used in this application is based on the Sort-of-CLEVR dataset, with one extra simplification. Given that the logical part will have to decide whether an object is for example located on the left side of an image, the neural network will have to convey positional information to the logical part. Hence, each discrete position will have to be encoded by a possible outcome of the neural network. Therefore, objects may only be located at certain positions in a grid. In this article, results on a grid of 2×2 and 6×6 are discussed.
The data generator that was used for the creation of the Sort-of-CLEVR dataset has been modified in order to position objects in the mentioned grid positions [4]. An example of a generated image is given in Figure 3, where the difference with Figure 2 is the grid-layout.

Each specified color will have an object located somewhere in the grid, of which the shape can be a square or a circle. These images are accompanied with a question about a random object, which can be one of the following:
- Non-relational — What is the shape of this object (square or circle)?
- Non-relational — Is this object located on the left hand
side of the image? - Non-relational — Is this object located on the bottom
side of the image? - Relational — How many objects have the same shape as
this object?
These questions are encoded in a vector encoding, after which they are stored in a CSV file, along with the expected answers. A training and test dataset has been generated beforehand, in order to make the training process more efficient.
3.2 Controlling the training process
The overall training process is controlled via the Python API of DeepProbLog, along with general PyTorch implementations of the CNN’s. First of all, CNN’s are defined with PyTorch. A relatively simple network is used, where the input is given as a square RGB image of 100 pixels wide, which is transformed by the CNN into 72 output features for the 6×6 grid (for the 2×2 grid example, 8 output features are required). Each color that is present in the image has its accompanied CNN network, hence the 72 output features encode the possible positions of the object with that color, along with their shape, which can be either square or circular (6 · 6 · 2 = 72).
The final thing (besides the logical rule encodings) required before commencing the training process, are the data loaders. The most challenging part here is the transformation from the generated data to specific query mappings and their outcome.
3.3 Logical rule encodings
Once the CNN belonging to a specific color has determined the position and the shape of that object, logical rules can deduce whether this object is located on the left hand side of the image, on the bottom side, and how many objects have the same shape. The logical rule program can be found in the associated Github, linked at the bottom of this article. An example snippet is shown:
The main focus of this article is to outline the advantages of using a Neuro Symbolic AI approach (offered by the DeepProbLog framework), instead of a purely neural network based approach. Therefore, a neural network-based approach had to be implemented. Not all details will be listed here, but the main idea is that the image has to be fused with the question, after which a prediction can be made. The general structure of this network is given in Figure 4.
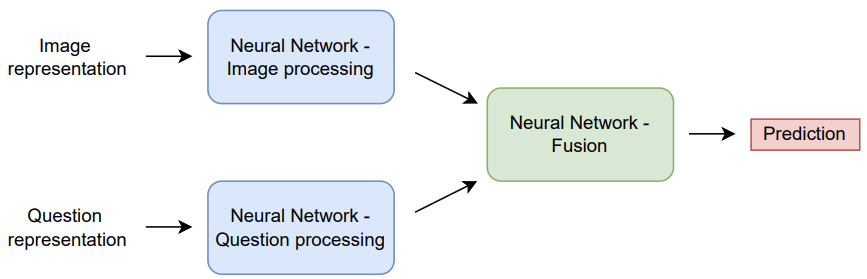
4.1 Comparisons with pure system 1 approaches
The loss curves of both the DeepProbLog approach, as well as the purely neural network based approach, are visualized respectively in Figure 5 and Figure 6.

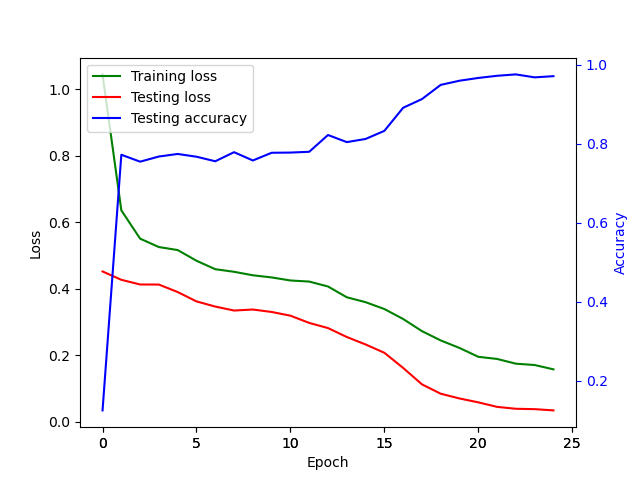
An extremely important remark to be made is the difference between ‘number of iterations’ and ‘number of epochs’. By the number of iterations, the number of forward and backward passes of a batch (with size 32) is meant, whereas the number of epochs denotes the number of times all the images of the training set are forward and backwardly passed. In this application, a training size of 10 000 was used, hence one epoch consists of 312.5 iterations.
From the loss curves, it is clear that both approaches seem to converge to an accuracy of 100%. However, DeepProbLog only requires around 40 iterations, whereas the purely neural network based approach requires at least 7 800 iterations. This again demonstrates the value of Neuro Symbolic AI.
On the other hand, one has to consider the actual running times for those iterations. DeepProbLog takes around 10 minutes to finish its 160 iterations, while the purely neural network based approach only requires around 5 minutes to finish 7 800 iterations. Taking into consideration that the purely neural network based approach can be accelerated massively (by using GPU’s), while DeepProbLog can’t, it is clear that DeepProbLog trains much more targeted, but is computationally extremely heavy (at least for now).
Note that DeepProbLog offers the ability to send the CNN to a GPU for faster inference, however, the arithmetic operators (i.e. semirings) of DeepProbLog work on the CPU. These arithmetic operators possess by far the highest computational cost.
The loss curves for the 6×6 experiment of DeepProbLog and the neural network based approach are depicted in respectively Figure 7 and Figure 8.
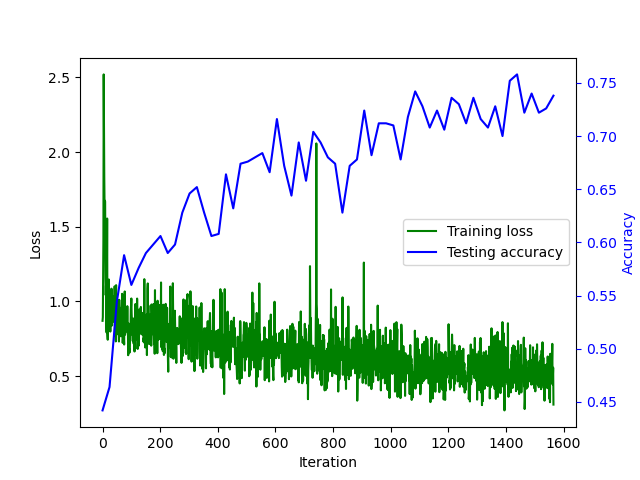
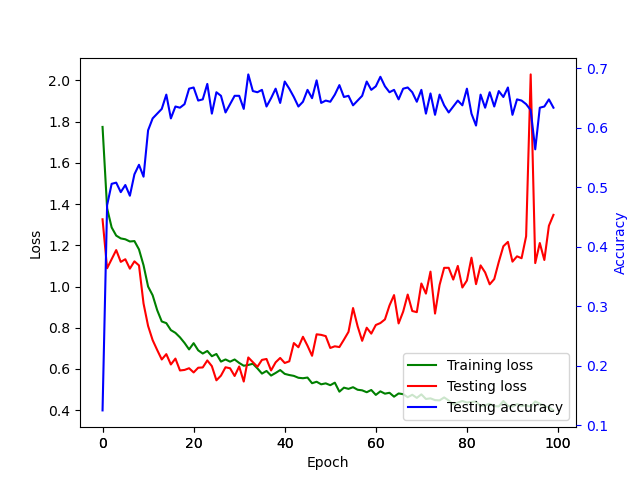
In these experiments, the training time of the purely neural network based approach was 20 minutes (for fair speed estimation, training has been conducted on the CPU), while the training time of the DeepProbLog approach was a little under eight hours.
However, it should be mentioned that approximately half of the time was spent on calculating the accuracy each time, since the whole testing set had to be forwarded through the network, while for the training iterations this is only one batch.
The most important observation here is that the purely neural network approach overfits quickly and also achieves a considerably lower accuracy (68% instead of 75% for DeepProbLog). Another important remark is the fact that both approaches are clearly not longer able to attain an accuracy of 100%. However, if the DeepProbLog network could train longer, it would be able to converge somewhat further.
In Figure 9 and Figure 10, the confusion matrices are depicted in order to show where typical mistakes are made.
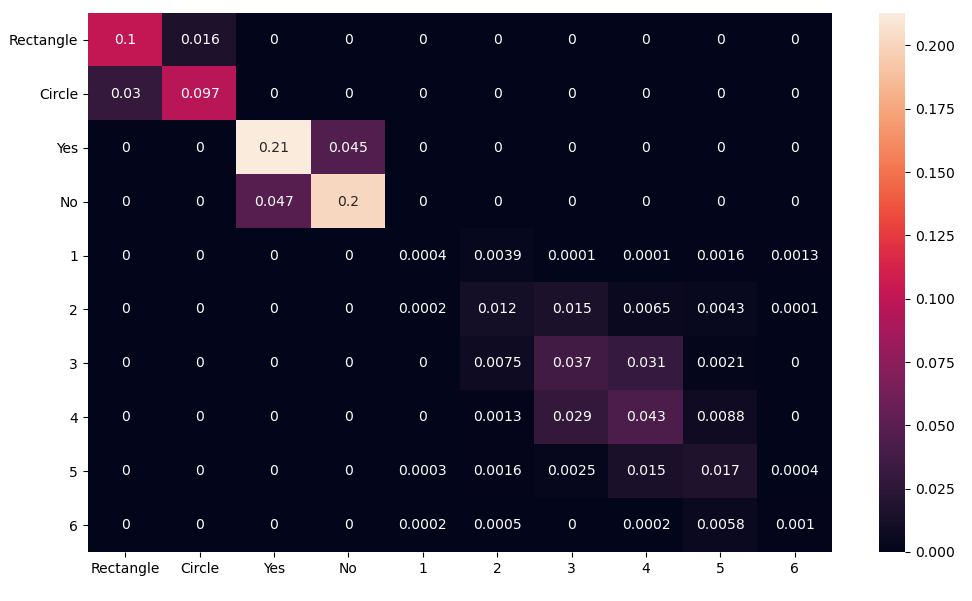

DeepProbLog naturally will not make any ‘nonsense’ mistakes such as answering ‘yes’ to the question ‘What shape has the object under investigation?’, since the possible correct answers are encoded in the program. However, the purely neural network based approach has learned perfectly to link the possible answers to the questions.
Another observation is that DeepProbLog is much better in answering the questions ‘What shape has the object under investigation?’ and ‘Is the object located on the left hand side (or on the bottom side) of the image?’ than a purely neural network approach is. This makes sense, since DeepProbLog can use its knowledge base to derive these properties, once the position (and shape) of the given object is determined. The observation that a pure neural network based approach has a much harder time to distinguish these cases, was also observed by A. Santoro et al. [4], where they achieved an accuracy of 63% on these questions with a pure neural network based approach. DeepProbLog was not able to achieve the accuracy of 94% that these researchers achieved on all questions with an added RN module, which may be due to the inherent training cost of the algebraic operators, as well as due to less resources, less hyperparameter tuning, and an absence of RN modules, among many other unknown variables.
Regarding the relational question: ‘How many objects have the same shape as the object under investigation?’, a lot more confusion in both approaches is going on. DeepProbLog will typically be able to come close to the correct answer, but may make some ‘off-by-one’ mistakes (i.e., one CNN that is wrongly predicting the shape of its object). The purely neural network based approach does also in this perspective a little worse. It is also plausible that in this approach, the neural network may have observed that due to probabilistic reasons, there are likely three or four equal objects (inclusive the one under investigation), and hence prefers such an answer.
The strengths of the Neuro Symbolic AI field has been demonstrated in the context of Visual Question Answering. By using DeepProbLog, the chosen framework for the Neuro Symbolic AI task, it became clear that almost 200 times less iterations are required to achieve the same accuracy as a purely neural network based approach. However, due to the costly algebraic operators, the total training time of the DeepProbLog approach was considerably slower, compared to the purely neural network based approach.
Notably, DeepProbLog performs a lot better on the non-relational questions. This because the knowledge base can derive these properties much more accurately, while a purely neural network based approach has more difficulties with such derivations.
Hence, a lot of value can be seen in Neuro Symbolic AI approaches, despite the costly algebraic operators. Especially for tasks where the knowledge base is much larger, these approaches can make the difference between being able to learn a certain task or not. Over time, speedups for these algebraic operators could probably be developed, which opens the road to even more applications.
- [1] R. Manhaeve, A. Kimmig, S. Dumančić, T. Demeester, L. De Raedt, “Deepproblog: Neural probabilistic logic programming”, in Advances in Neural Information Processing Systems, vol. 2018-Decem, pp. 3749–3759, jul 2018, doi:10.48550/arxiv.1907.08194, URL: https://arxiv.org/abs/1907.08194v2
- [2] D. Kahneman, Thinking, fast and slow, Penguin Books, London, 2012.
- [3] J. Johnson, L. Fei-Fei, B. Hariharan, C. L. Zitnick, L. Van Der Maaten, R. Girshick, “CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning”, Proceedings — 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, vol. 2017-Janua, pp. 1988–1997, 2017, doi: 10.1109/CVPR.2017.215, 1612.06890.
- [4] K. Heecheol, “kimhc6028/relational-networks: Pytorch implementation of “A simple neural network module for relational reasoning” (Relational Networks)”, URL: https://github.com/kimhc6028/relational-networks
- [5] R. Manhaeve, “ML-KULeuven/deepproblog: DeepProbLog is an extension of ProbLog that integrates Probabilistic Logic Programming with deep learning by introducing the neural predicate.”, URL: https://github.com/ML-KULeuven/deepproblog
[6] C. Theodoropoulos, “Information Retrieval and Search Engines [H02C8b] Project Visual Question Answering”, Toledo, pp. 1–5, 2022.
All images unless otherwise noted are by the author.
The code belonging to this article can be found here.
Comparing neuro-symbolic AI against a purely neural network-based approach on visual question-answering
This article focuses on Visual Question Answering, where a neuro-symbolic AI approach with a knowledge base is compared with a purely neural network-based approach. From the experiments, it follows that DeepProbLog, the framework used for the neuro-symbolic AI approach, is able to achieve the same accuracy as the pure neural network-based approach with almost 200 times less iterations. Clearly, the training is much more targeted, but comes at a cost. The algebraic operators internal to DeepProbLog are extremely costly and hence the actual training time is considerably slower. Another drawback of DeepProbLog is that no easy speedups can be achieved, since the algebraic operators only work on CPUs (at least for now), and hence cannot benefit from accelerators such as GPUs.

The Neuro-Symbolic AI field is interested in building a bridge between the robustness of probabilistic knowledge and the well-known popularity and proven strengths of deep neural networks. DeepProbLog [1] offers this ability, by using both the strengths of neural networks (i.e., system 1, typical subconscious tasks such as visual recognition, the processing of languages, …), along with the strengths of rule-based probabilistic systems (i.e., system 2, slow, sequential thinking such as the derivation of a proof) [2].
This article elaborates on an application that requires both systems to be used, namely Visual Question Answering. System 1 will be required in order to gain an understanding of the image under investigation, with in particular their shapes and colors. System 2, on the other hand, will use this extracted information for deriving certain properties of objects (e.g., finding the shape of a green object), or even for capturing the relations between the objects (e.g., counting the number of circles in the image).
The application focuses on Visual Question Answering (VQA), for which huge datasets are present, along with very sophisticated methods. The best known dataset for VQA is CLEVR [3], which contains 100k images accompanied by one million questions. An example image is given beneath, while example questions are:
- Are there an equal number of large things and metal
spheres? - What size is the cylinder that is left of the brown metal
thing that is left of the big sphere? - How many objects are either small cylinders or metal
things?
Clearly, both system 1 and system 2 are actively used when answering these questions. One could wonder if neural networks alone could answer these questions without having an explicit system 2 encoding (i.e. the rule based knowledge base). Intuitively, it makes sense that if certain facts of the world are known, learning can proceed much more quickly. Seen from an optimization viewpoint, errors made during prediction in this setup can be targeted exactly, which makes the optimization process more targeted as well, and hence more efficient. Finally, this article also provides evidence for these statements, since in subsection 4.1, the comparison between a VQA implementation with DeepProbLog is made with a purely neural network based approach.
This article is inspired by the CLEVR dataset, but uses a much more simplified version. In essence, it is almost like the Sort-of-CLEVR dataset [4]. The Sort-of-CLEVR dataset contains images as in Figure 2, while asking questions such as:sed for commercial use…
- Non-relational questions: the shape, horizontal or vertical location of an object.
- Relational questions: shape of the closest/furthest object to the object under investigation, or the number of objects with the same shape.
As illustrated earlier, both system 1 and system 2 are required for these types of VQA’s.
A. Santoro et al. conducted similar experiments with the Sort-of-CLEVR dataset as in this article, where they were able to achieve an accuracy of 63% on relational questions with CNN’s. In contrast, an accuracy of 94% for both relational and non-relational questions was achieved with CNN’s, complemented with an RN. For them, augmenting the model with a relational module, such as an RN, turned out to be sufficient to overcome the hurdle of solving relational questions [4]. They were the only researchers who undertook experiments on a dataset resembling the one from this article, and hence are the only reference point.
Finally, since this application uses DeepProbLog, quite some time was spent in digesting the DeepProbLog paper [1], along with understanding the examples provided in the code repository [5].
The implementation process involved three main parts:
- Generation of the data
- Linking the data and controlling the training process in pure Python code.
- Creation of the logical part with DeepProbLog statements.
3.1 Generation of the data
As mentioned in Section 2, the data used in this application is based on the Sort-of-CLEVR dataset, with one extra simplification. Given that the logical part will have to decide whether an object is for example located on the left side of an image, the neural network will have to convey positional information to the logical part. Hence, each discrete position will have to be encoded by a possible outcome of the neural network. Therefore, objects may only be located at certain positions in a grid. In this article, results on a grid of 2×2 and 6×6 are discussed.
The data generator that was used for the creation of the Sort-of-CLEVR dataset has been modified in order to position objects in the mentioned grid positions [4]. An example of a generated image is given in Figure 3, where the difference with Figure 2 is the grid-layout.
Each specified color will have an object located somewhere in the grid, of which the shape can be a square or a circle. These images are accompanied with a question about a random object, which can be one of the following:
- Non-relational — What is the shape of this object (square or circle)?
- Non-relational — Is this object located on the left hand
side of the image? - Non-relational — Is this object located on the bottom
side of the image? - Relational — How many objects have the same shape as
this object?
These questions are encoded in a vector encoding, after which they are stored in a CSV file, along with the expected answers. A training and test dataset has been generated beforehand, in order to make the training process more efficient.
3.2 Controlling the training process
The overall training process is controlled via the Python API of DeepProbLog, along with general PyTorch implementations of the CNN’s. First of all, CNN’s are defined with PyTorch. A relatively simple network is used, where the input is given as a square RGB image of 100 pixels wide, which is transformed by the CNN into 72 output features for the 6×6 grid (for the 2×2 grid example, 8 output features are required). Each color that is present in the image has its accompanied CNN network, hence the 72 output features encode the possible positions of the object with that color, along with their shape, which can be either square or circular (6 · 6 · 2 = 72).
The final thing (besides the logical rule encodings) required before commencing the training process, are the data loaders. The most challenging part here is the transformation from the generated data to specific query mappings and their outcome.
3.3 Logical rule encodings
Once the CNN belonging to a specific color has determined the position and the shape of that object, logical rules can deduce whether this object is located on the left hand side of the image, on the bottom side, and how many objects have the same shape. The logical rule program can be found in the associated Github, linked at the bottom of this article. An example snippet is shown:
The main focus of this article is to outline the advantages of using a Neuro Symbolic AI approach (offered by the DeepProbLog framework), instead of a purely neural network based approach. Therefore, a neural network-based approach had to be implemented. Not all details will be listed here, but the main idea is that the image has to be fused with the question, after which a prediction can be made. The general structure of this network is given in Figure 4.
4.1 Comparisons with pure system 1 approaches
The loss curves of both the DeepProbLog approach, as well as the purely neural network based approach, are visualized respectively in Figure 5 and Figure 6.
An extremely important remark to be made is the difference between ‘number of iterations’ and ‘number of epochs’. By the number of iterations, the number of forward and backward passes of a batch (with size 32) is meant, whereas the number of epochs denotes the number of times all the images of the training set are forward and backwardly passed. In this application, a training size of 10 000 was used, hence one epoch consists of 312.5 iterations.
From the loss curves, it is clear that both approaches seem to converge to an accuracy of 100%. However, DeepProbLog only requires around 40 iterations, whereas the purely neural network based approach requires at least 7 800 iterations. This again demonstrates the value of Neuro Symbolic AI.
On the other hand, one has to consider the actual running times for those iterations. DeepProbLog takes around 10 minutes to finish its 160 iterations, while the purely neural network based approach only requires around 5 minutes to finish 7 800 iterations. Taking into consideration that the purely neural network based approach can be accelerated massively (by using GPU’s), while DeepProbLog can’t, it is clear that DeepProbLog trains much more targeted, but is computationally extremely heavy (at least for now).
Note that DeepProbLog offers the ability to send the CNN to a GPU for faster inference, however, the arithmetic operators (i.e. semirings) of DeepProbLog work on the CPU. These arithmetic operators possess by far the highest computational cost.
The loss curves for the 6×6 experiment of DeepProbLog and the neural network based approach are depicted in respectively Figure 7 and Figure 8.
In these experiments, the training time of the purely neural network based approach was 20 minutes (for fair speed estimation, training has been conducted on the CPU), while the training time of the DeepProbLog approach was a little under eight hours.
However, it should be mentioned that approximately half of the time was spent on calculating the accuracy each time, since the whole testing set had to be forwarded through the network, while for the training iterations this is only one batch.
The most important observation here is that the purely neural network approach overfits quickly and also achieves a considerably lower accuracy (68% instead of 75% for DeepProbLog). Another important remark is the fact that both approaches are clearly not longer able to attain an accuracy of 100%. However, if the DeepProbLog network could train longer, it would be able to converge somewhat further.
In Figure 9 and Figure 10, the confusion matrices are depicted in order to show where typical mistakes are made.
DeepProbLog naturally will not make any ‘nonsense’ mistakes such as answering ‘yes’ to the question ‘What shape has the object under investigation?’, since the possible correct answers are encoded in the program. However, the purely neural network based approach has learned perfectly to link the possible answers to the questions.
Another observation is that DeepProbLog is much better in answering the questions ‘What shape has the object under investigation?’ and ‘Is the object located on the left hand side (or on the bottom side) of the image?’ than a purely neural network approach is. This makes sense, since DeepProbLog can use its knowledge base to derive these properties, once the position (and shape) of the given object is determined. The observation that a pure neural network based approach has a much harder time to distinguish these cases, was also observed by A. Santoro et al. [4], where they achieved an accuracy of 63% on these questions with a pure neural network based approach. DeepProbLog was not able to achieve the accuracy of 94% that these researchers achieved on all questions with an added RN module, which may be due to the inherent training cost of the algebraic operators, as well as due to less resources, less hyperparameter tuning, and an absence of RN modules, among many other unknown variables.
Regarding the relational question: ‘How many objects have the same shape as the object under investigation?’, a lot more confusion in both approaches is going on. DeepProbLog will typically be able to come close to the correct answer, but may make some ‘off-by-one’ mistakes (i.e., one CNN that is wrongly predicting the shape of its object). The purely neural network based approach does also in this perspective a little worse. It is also plausible that in this approach, the neural network may have observed that due to probabilistic reasons, there are likely three or four equal objects (inclusive the one under investigation), and hence prefers such an answer.
The strengths of the Neuro Symbolic AI field has been demonstrated in the context of Visual Question Answering. By using DeepProbLog, the chosen framework for the Neuro Symbolic AI task, it became clear that almost 200 times less iterations are required to achieve the same accuracy as a purely neural network based approach. However, due to the costly algebraic operators, the total training time of the DeepProbLog approach was considerably slower, compared to the purely neural network based approach.
Notably, DeepProbLog performs a lot better on the non-relational questions. This because the knowledge base can derive these properties much more accurately, while a purely neural network based approach has more difficulties with such derivations.
Hence, a lot of value can be seen in Neuro Symbolic AI approaches, despite the costly algebraic operators. Especially for tasks where the knowledge base is much larger, these approaches can make the difference between being able to learn a certain task or not. Over time, speedups for these algebraic operators could probably be developed, which opens the road to even more applications.
- [1] R. Manhaeve, A. Kimmig, S. Dumančić, T. Demeester, L. De Raedt, “Deepproblog: Neural probabilistic logic programming”, in Advances in Neural Information Processing Systems, vol. 2018-Decem, pp. 3749–3759, jul 2018, doi:10.48550/arxiv.1907.08194, URL: https://arxiv.org/abs/1907.08194v2
- [2] D. Kahneman, Thinking, fast and slow, Penguin Books, London, 2012.
- [3] J. Johnson, L. Fei-Fei, B. Hariharan, C. L. Zitnick, L. Van Der Maaten, R. Girshick, “CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning”, Proceedings — 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, vol. 2017-Janua, pp. 1988–1997, 2017, doi: 10.1109/CVPR.2017.215, 1612.06890.
- [4] K. Heecheol, “kimhc6028/relational-networks: Pytorch implementation of “A simple neural network module for relational reasoning” (Relational Networks)”, URL: https://github.com/kimhc6028/relational-networks
- [5] R. Manhaeve, “ML-KULeuven/deepproblog: DeepProbLog is an extension of ProbLog that integrates Probabilistic Logic Programming with deep learning by introducing the neural predicate.”, URL: https://github.com/ML-KULeuven/deepproblog
[6] C. Theodoropoulos, “Information Retrieval and Search Engines [H02C8b] Project Visual Question Answering”, Toledo, pp. 1–5, 2022.
All images unless otherwise noted are by the author.
The code belonging to this article can be found here.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.