
6 Ways to Encode Features for Machine Learning Algorithms | by Anthony Cavin | Jun, 2022
Encoding categorical variables into numeric
A machine learning algorithm needs to be able to understand the data it receives. For example, categories such as “small”, “medium”, and “large” need to be converted into numbers. To solve that, we can for example convert them into numeric labels with “1” for small, “2” for medium, and “3” for large.
But is it really the best way?
There are plenty of methods to encode categorical variables into numeric and each method comes with its own advantages and disadvantages.
To discover them, we will see the following ways to encode categorical variables:
- One-hot/dummy encoding
- Label / Ordinal encoding
- Target encoding
- Frequency / count encoding
- Binary encoding
- Feature Hashing
We will illustrate the concepts with a very simple dataframe: a toy dataset of top NBA players and the number of points that they scored with free throws during past games.
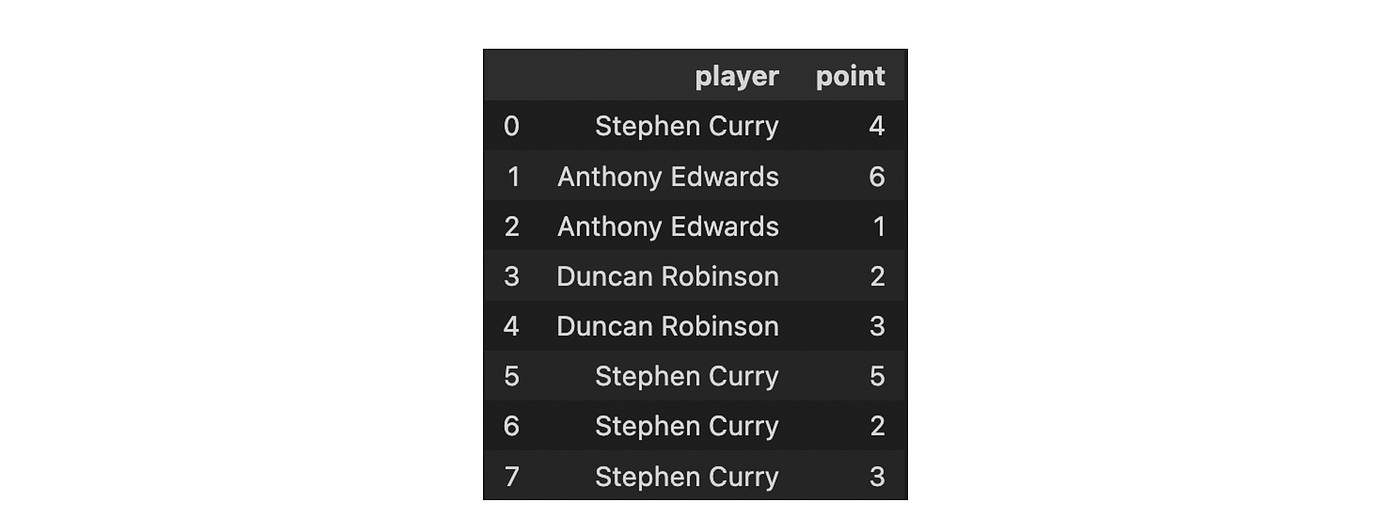
I also recommend using this python library for encoding categorical variables into numeric:
pip install category_encoders
Before digging further, we need to clarify some concepts:
- Nominal variables are variables that have no inherent order. They are simply categories that can be distinguished from each other.
- Ordinal variables have an inherent order. They can be ranked from highest to lowest or vice versa.
- Unsupervised encoding methods don’t make use of the target variable to encode categorical variables (e.g. encode player names with a formula that takes the number of points that they made).
- Supervised encoding methods employ the target variable to encode categorical variables.
- The “cardinality” of a categorical variable stands for the number of categories represented by this variable.
- Target leakage occurs when a variable is used for training but would not be available at inference time.
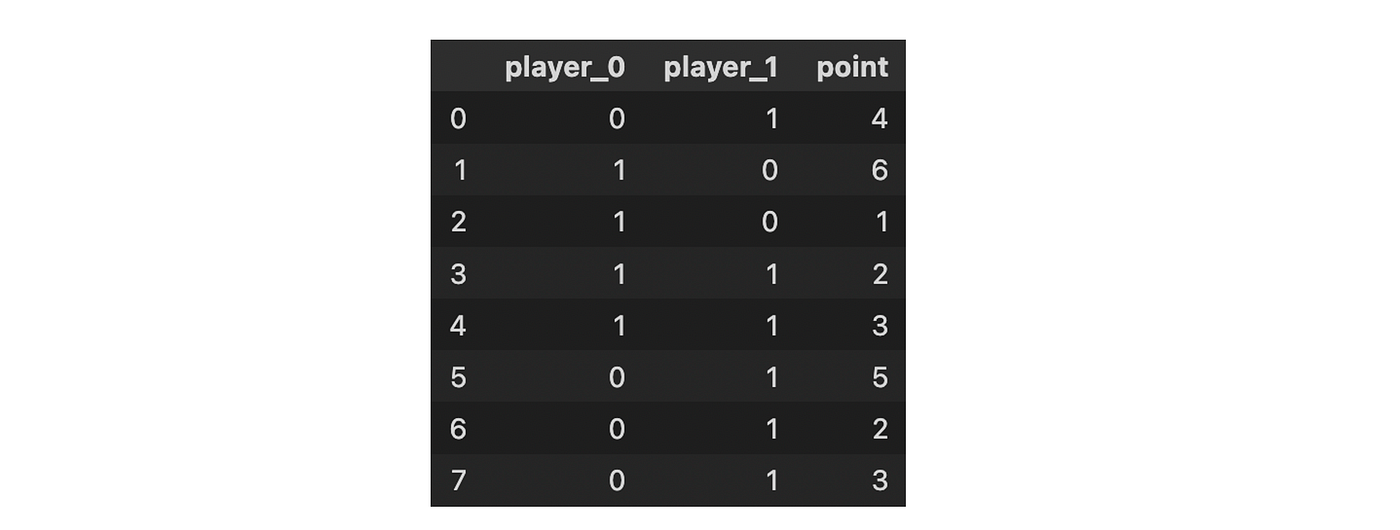
In one-hot encoding, categorical data are represented as vectors of zeros and ones. This is done by using a separate dummy variable for each category, and setting the value of the dummy variable to 1 if the observation belongs to that category and 0 otherwise.
For instance, if there are three categories, each category can be represented as a vector of zeros with a single one in the position corresponding to the category.
from category_encoder import OneHotEncoder
OneHotEncoder(cols=['player']).fit(df).transform(df)
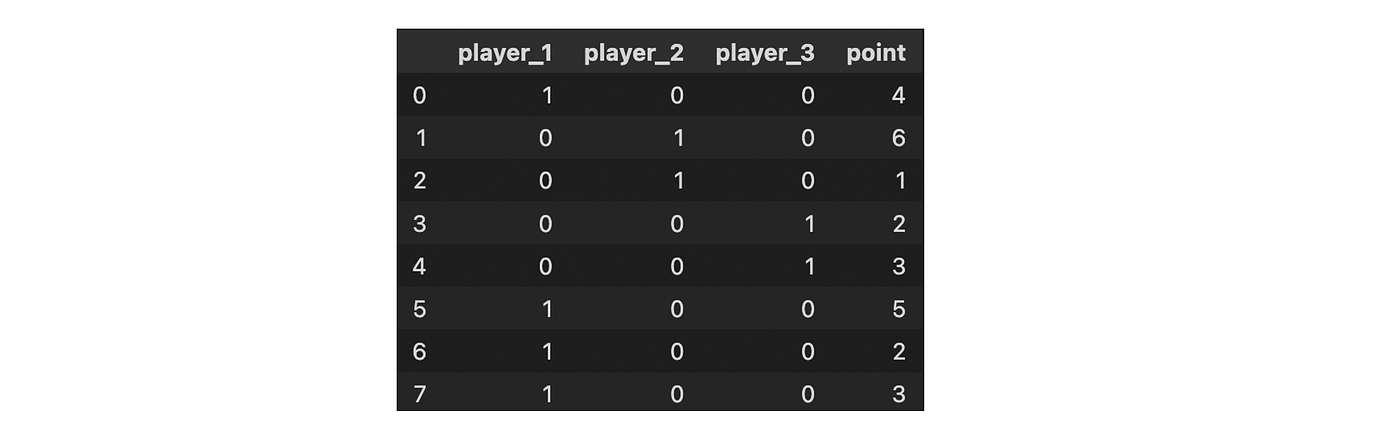
This is probably the simplest way to encode features for a machine learning algorithm. In this method, the categorical data is converted into numerical data. Each category is assigned a numerical value.
With our toy dataset, we can randomly assign numbers to players such as “1” for Stephan Curry, “2” for Anthony Edwards, and “3” for Ducan Robinson.
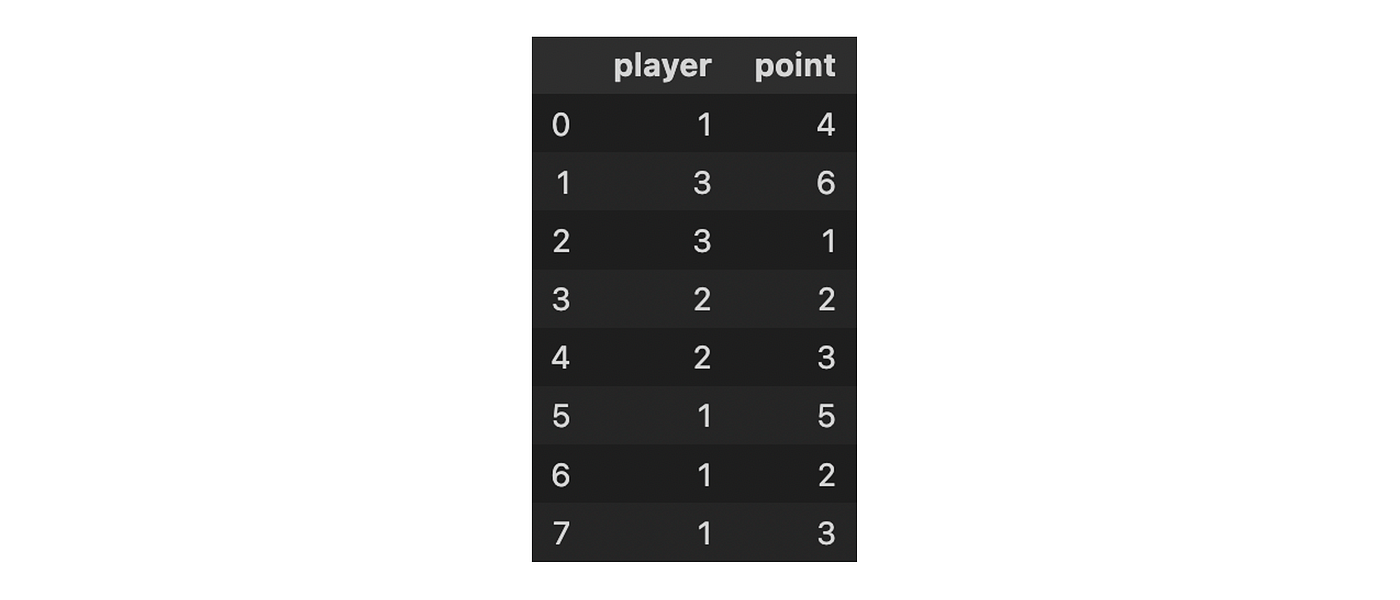
But what if we need to encode ordinal variables?
In that case, we can manually define the mapping for each player. Let’s say that we consider an order such as Stephen Curry < Duncan Robinson < Anthony Edwards, the ordinal encoding will look as follows.
from category_encoder import OrdinalEncodermapping = [{'col': 'player', 'mapping': {"Stephen Curry": 1, "Duncan Robinson": 2, "Anthony Edwards": 3}}]OrdinalEncoder(cols=['player'], mapping=mapping).fit(df).transform(df)
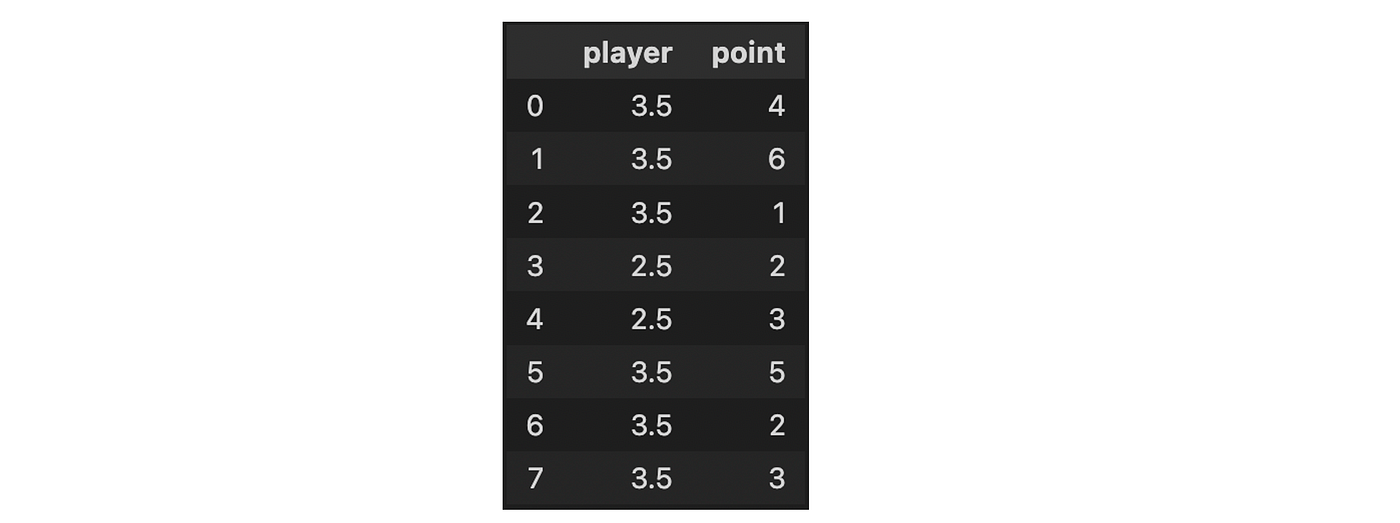
Target encoding is a technique for encoding the categorical values of the features by using the target value. The idea behind this technique is that if the feature is a good predictor of the target, then its values should be closer to the target.
- Target-mean encoding: we replace the category with the mean of the target values. This method will usually be used with smoothing to avoid target leakage.
- Leave-one-out encoding: this method is very similar to target mean encoding, but the difference is that in leave-one-out encoding, we take the mean of the target values of all the samples except the one we want to predict.
For example, Leave-one-out encoding would look as follows:
from category_encoder import TargetEncoder
TargetEncoder(cols=['player'], smoothing=1.0).fit(df, df['point']).transform(df)from category_encoder import LeaveOneOutEncoder
LeaveOneOutEncoder(cols=['player']).fit(df, df['point']).transform(df)
Count encoding is a way of representing categorical data using the count of the categories. Frequency encoding is simply a normalized version of count encoding.
from category_encoder import CountEncoder
CountEncoder(cols=['player']).fit(df).transform(df)
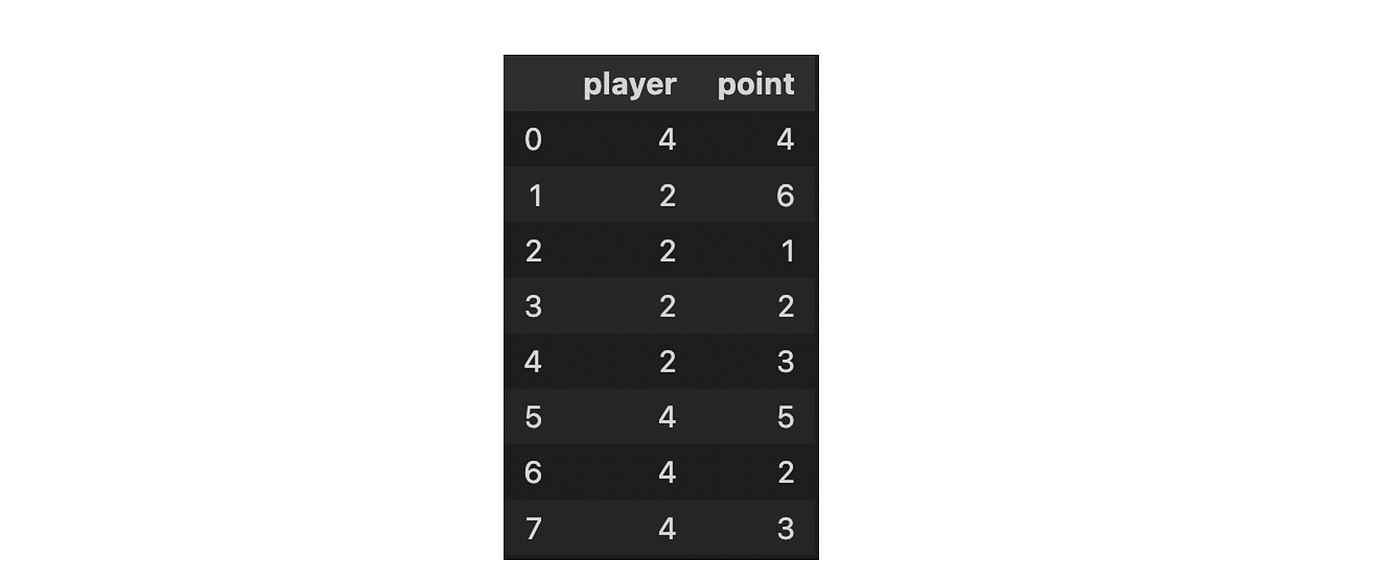
from category_encoder import CountEncoder
CountEncoder(cols=['player'], normalize=True).fit(df).transform(df)
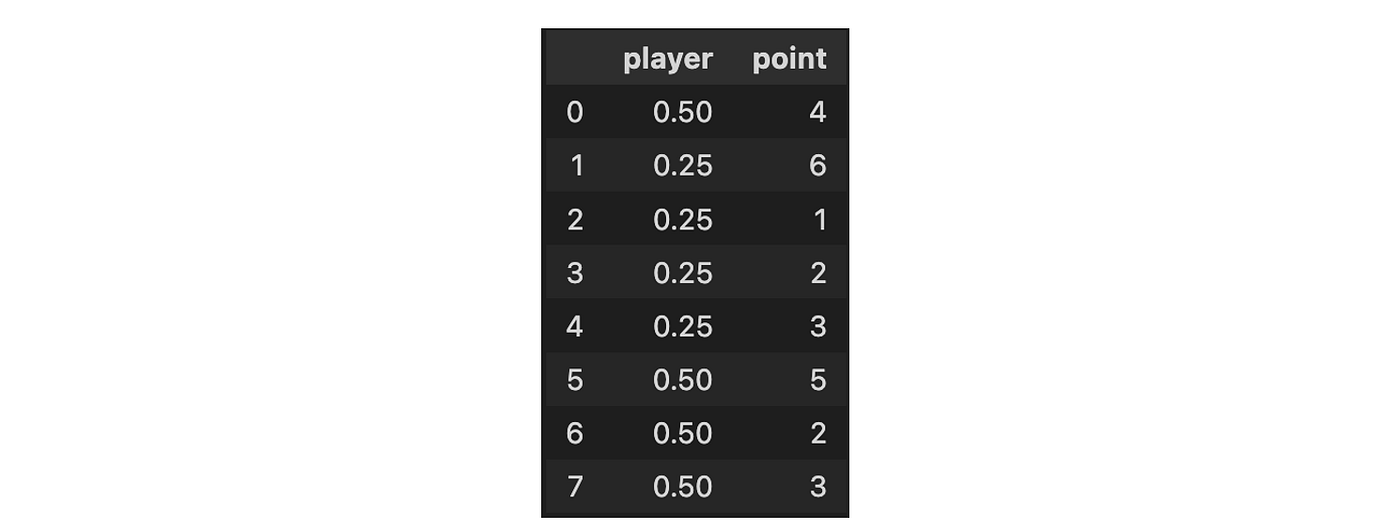
Binary encoding is a technique used to transform categorical data into numerical data by encoding categories as integers and then converting them into binary code.
from category_encoder import BinaryEncoder
BinaryEncoder(cols=['player']).fit(df).transform(df)
Feature hashing is a way of representing data in a high-dimensional space using a fixed-size array. This is done by encoding categorical variables with the help of a hash function.
from category_encoder import HashingEncoder
HashingEncoder(cols=['player']).fit(df).transform(df)

So, which one should you use?
It depends on the dataset, the model, and the performance metric you are trying to optimize. In general, one-hot encoding is the most commonly used method for nominal variables. It is simple to understand and implement, and it works well with most machine learning models. To fight the curse of dimensionality, binary encoding might be a good alternative to one-hot encoding because it creates fewer columns when encoding categorical variables.
Ordinal encoding is a good choice if the order of the categorical variables matters. For example, if we were predicting the price of a house, the label “small”, “medium”, and “large” would imply that a small house is cheaper than a medium house, which is cheaper than a large house. The label is easily reversible and doesn’t increase the dimensionality of the data.
On the other hand, the target encoding is a supervised encoder that captures information about the label and potentially predictive features. This encoder does not increase the dimensionality of the feature space, but can lead to overfitting and is prone to target leakage.
The frequency and count encoders are also supervised methods that do not increase the dimensionality of the feature space. However, these methods can only be used if the count refers to the target variable, otherwise, all categories that have similar cardinality will be counted the same.
The feature hashing is a good way to handle categorical variables when the cardinality is very high as it is fast to compute and does not grow in size when adding categories.
To dig further into the subject, I would recommend reading the following interesting articles:
Encoding categorical variables into numeric
A machine learning algorithm needs to be able to understand the data it receives. For example, categories such as “small”, “medium”, and “large” need to be converted into numbers. To solve that, we can for example convert them into numeric labels with “1” for small, “2” for medium, and “3” for large.
But is it really the best way?
There are plenty of methods to encode categorical variables into numeric and each method comes with its own advantages and disadvantages.
To discover them, we will see the following ways to encode categorical variables:
- One-hot/dummy encoding
- Label / Ordinal encoding
- Target encoding
- Frequency / count encoding
- Binary encoding
- Feature Hashing
We will illustrate the concepts with a very simple dataframe: a toy dataset of top NBA players and the number of points that they scored with free throws during past games.
I also recommend using this python library for encoding categorical variables into numeric:
pip install category_encoders
Before digging further, we need to clarify some concepts:
- Nominal variables are variables that have no inherent order. They are simply categories that can be distinguished from each other.
- Ordinal variables have an inherent order. They can be ranked from highest to lowest or vice versa.
- Unsupervised encoding methods don’t make use of the target variable to encode categorical variables (e.g. encode player names with a formula that takes the number of points that they made).
- Supervised encoding methods employ the target variable to encode categorical variables.
- The “cardinality” of a categorical variable stands for the number of categories represented by this variable.
- Target leakage occurs when a variable is used for training but would not be available at inference time.
In one-hot encoding, categorical data are represented as vectors of zeros and ones. This is done by using a separate dummy variable for each category, and setting the value of the dummy variable to 1 if the observation belongs to that category and 0 otherwise.
For instance, if there are three categories, each category can be represented as a vector of zeros with a single one in the position corresponding to the category.
from category_encoder import OneHotEncoder
OneHotEncoder(cols=['player']).fit(df).transform(df)
This is probably the simplest way to encode features for a machine learning algorithm. In this method, the categorical data is converted into numerical data. Each category is assigned a numerical value.
With our toy dataset, we can randomly assign numbers to players such as “1” for Stephan Curry, “2” for Anthony Edwards, and “3” for Ducan Robinson.
But what if we need to encode ordinal variables?
In that case, we can manually define the mapping for each player. Let’s say that we consider an order such as Stephen Curry < Duncan Robinson < Anthony Edwards, the ordinal encoding will look as follows.
from category_encoder import OrdinalEncodermapping = [{'col': 'player', 'mapping': {"Stephen Curry": 1, "Duncan Robinson": 2, "Anthony Edwards": 3}}]OrdinalEncoder(cols=['player'], mapping=mapping).fit(df).transform(df)
Target encoding is a technique for encoding the categorical values of the features by using the target value. The idea behind this technique is that if the feature is a good predictor of the target, then its values should be closer to the target.
- Target-mean encoding: we replace the category with the mean of the target values. This method will usually be used with smoothing to avoid target leakage.
- Leave-one-out encoding: this method is very similar to target mean encoding, but the difference is that in leave-one-out encoding, we take the mean of the target values of all the samples except the one we want to predict.
For example, Leave-one-out encoding would look as follows:
from category_encoder import TargetEncoder
TargetEncoder(cols=['player'], smoothing=1.0).fit(df, df['point']).transform(df)from category_encoder import LeaveOneOutEncoder
LeaveOneOutEncoder(cols=['player']).fit(df, df['point']).transform(df)
Count encoding is a way of representing categorical data using the count of the categories. Frequency encoding is simply a normalized version of count encoding.
from category_encoder import CountEncoder
CountEncoder(cols=['player']).fit(df).transform(df)
from category_encoder import CountEncoder
CountEncoder(cols=['player'], normalize=True).fit(df).transform(df)
Binary encoding is a technique used to transform categorical data into numerical data by encoding categories as integers and then converting them into binary code.
from category_encoder import BinaryEncoder
BinaryEncoder(cols=['player']).fit(df).transform(df)
Feature hashing is a way of representing data in a high-dimensional space using a fixed-size array. This is done by encoding categorical variables with the help of a hash function.
from category_encoder import HashingEncoder
HashingEncoder(cols=['player']).fit(df).transform(df)
So, which one should you use?
It depends on the dataset, the model, and the performance metric you are trying to optimize. In general, one-hot encoding is the most commonly used method for nominal variables. It is simple to understand and implement, and it works well with most machine learning models. To fight the curse of dimensionality, binary encoding might be a good alternative to one-hot encoding because it creates fewer columns when encoding categorical variables.
Ordinal encoding is a good choice if the order of the categorical variables matters. For example, if we were predicting the price of a house, the label “small”, “medium”, and “large” would imply that a small house is cheaper than a medium house, which is cheaper than a large house. The label is easily reversible and doesn’t increase the dimensionality of the data.
On the other hand, the target encoding is a supervised encoder that captures information about the label and potentially predictive features. This encoder does not increase the dimensionality of the feature space, but can lead to overfitting and is prone to target leakage.
The frequency and count encoders are also supervised methods that do not increase the dimensionality of the feature space. However, these methods can only be used if the count refers to the target variable, otherwise, all categories that have similar cardinality will be counted the same.
The feature hashing is a good way to handle categorical variables when the cardinality is very high as it is fast to compute and does not grow in size when adding categories.
To dig further into the subject, I would recommend reading the following interesting articles:
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.