
A Simple Guide to Inplace Operations in Pandas | by Avi Chawla | Aug, 2022
Introduction to inplace operations in Pandas, exploring commonly supported methods and a common misconceptions
Inplace assignment operations are widely popular in transforming Pandas DataFrames. As the name suggests, the core idea behind inplace assignment is to avoid creating a new DataFrame object with each successive modification but instead making changes to the original DataFrame itself.
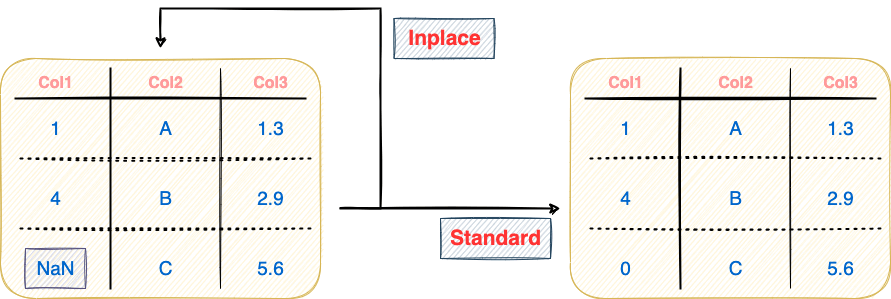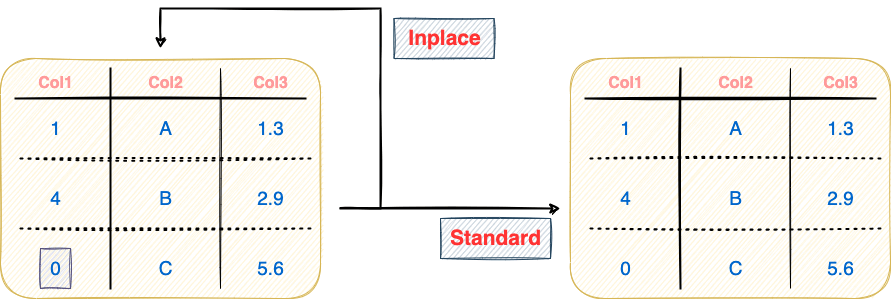
Inplace assignment operations are especially useful in applications with extreme memory constraints. This is because modifications are made to an existing DataFrame (or the source DataFrame) without creating any intermediate DataFrames.
This post is an introduction to inplace operations, specifically on Pandas DataFrames. We will discuss how inplace operations differ from the standard assignment operations. Towards the end, I will present some of the most common methods that support inplace assignments in Pandas.
The highlight of the article is as follows:
Introduction to Inplace Assignment
Common Misconception about Inplace Assignment
Popular Functions that Support Inplace Assignment
Run-time Comparison
Conclusion
Let’s begin 🚀!
Once we load a DataFrame into the Python environment, we typically perform a wide range of transformations on the DataFrame, don’t we? These include adding new columns, renaming headers, deleting columns, altering cell values, replacing NaN values, and many more.
These can be typically performed in two ways, as depicted in the image below:
Standard Assignment
If the applied transformation returns a new copy of the DataFrame, it is called a “non-in-place” or “Standard Assignment” operation in Pandas.
By default, Pandas always resorts to standard assignment and returns the modified copy of the DataFrame, leaving the original DataFrame untouched.
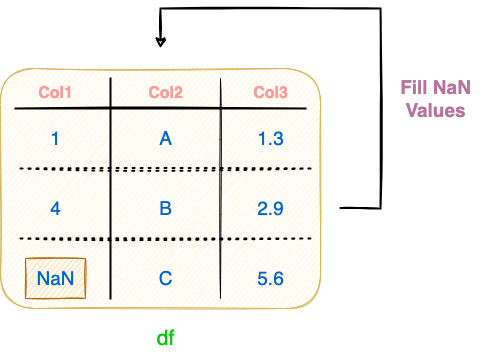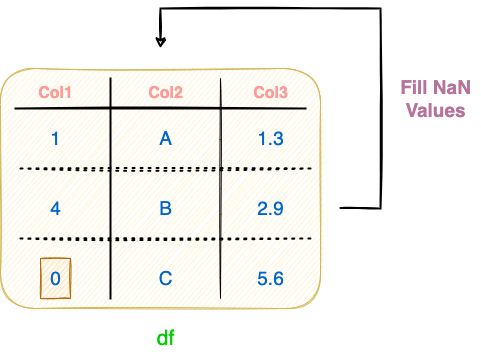
As you may have guessed, this will practically take up additional space in the memory, which can eventually lead to memory constraints. The standard assignment operation is demonstrated in the image below and implemented in the code block following the image:
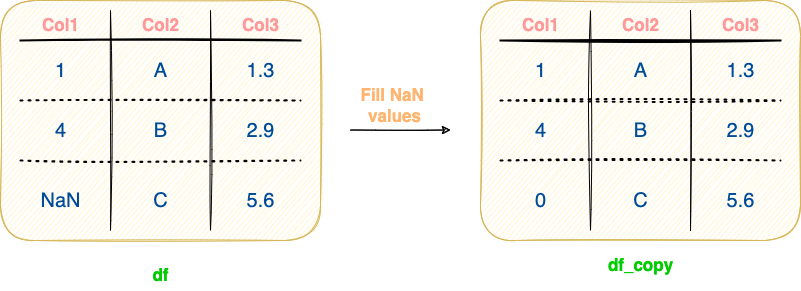
As a result of the standard assignment operation of filling NaN values shown above, two distinct Pandas objects will exist in the scope of the program — df and df_copy.
Inplace Assignment
In contrast to the standard/traditional assignment, if the intermediate DataFrame generated (such as df_copy above) is of no use to you, performing an inplace assignment is the ideal way to proceed. This is demonstrated below:
On a side note, you should know that inplace assignment exists in numerous functions outside Pandas as well. For instance, when you append an element to a Python list using the
append()method, it is an inplace operation because the element is appended to the source list. Similarly, thesort()method on a Python list also performs inplace sorting.
Inplace operations in Pandas require the inplace argument to be passed as True to the method being invoked. For instance, we can replace the NaN values with 0 in the above DataFrame inplace as follows:
Here, one may argue that we can optimize the memory by assigning the new DataFrame back to the name of the original DataFrame as follows:
Although there’s nothing wrong with the above assignment operation syntactically, you should understand that taking this route inevitably creates a new DataFrame during the assignment operation, leading to an increase in memory utilization temporarily.
We can verify the creation of a new DataFrame object using the id() method in Python as follows:
The ID (or address) of the source DataFrame and that of the new DataFrame are different, implying the creation of a new instance of a Pandas DataFrame.
On the flip side, if you perform an inplace operation with the inplace=True argument, it does not create a new DataFrame. The modifications are made to the original DataFrame itself. This can be verified as follows:
There are a handful of methods in Pandas that are inherently compatible with inplace operations. A few of the most commonly used functions are demonstrated below:
#1 Renaming DataFrame headers
Every column has a specific column header that defines the column’s name. You can change the name of the some/all columns as shown below:
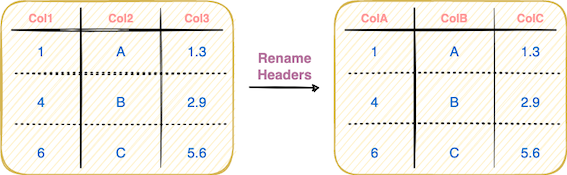
To rename column(s) of a DataFrame, you can use the rename() method in Pandas as shown below:
The standard assignment returns a new DataFrame. Therefore, you must assign it to a variable. However, as the inplace assignment modifies the source DataFrame itself, it does not return anything.
#2 Deleting column(s)
Say you want to remove unwanted column(s) from an existing DataFrame, as illustrated in the figure below:
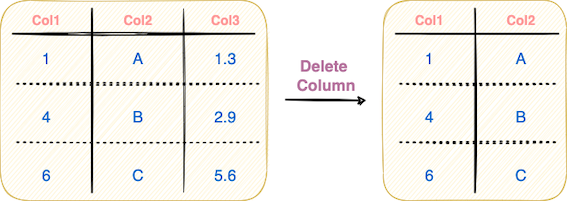
To delete column(s) of a DataFrame, you can use the drop() method in Pandas as shown below:
You should pass the columns you want to drop as a list of column names to the columns argument of the drop() method.
#3 Sorting a DataFrame
The sorting operation is another widely used method in Pandas. As the name suggests, the idea here is to sort a DataFrame based on the values in one or more columns, as shown below:
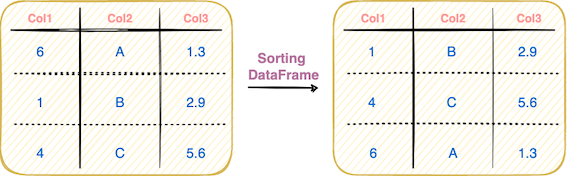
You can use the sort_values() method to sort a DataFrame as shown below:
#4 Replacing NaN values
The presence of missing values is inevitable in real-world datasets. With Pandas, you have a range of methods to handle missing data and replace them with definite values, as shown below:
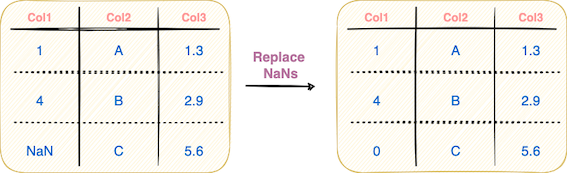
To replace NaN values, use the fillna() method as demonstrated below:
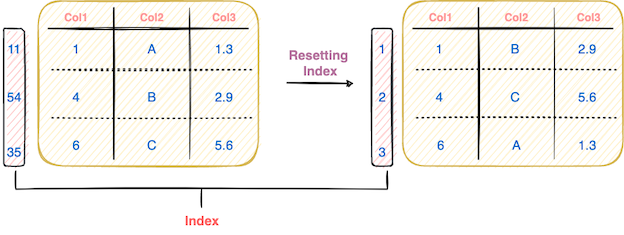
#5 Reset Index, and many more.
If you want to reset the index values of the DataFrame, you can use the reset_index() method in Pandas. The image below demonstrates this operation:
Next, we shall experimentally compare the run-time performance of the standard and the inplace assignment operations on the five Pandas functions discussed above — drop(), rename(), fillna(), reset_index() and sort_values().
The following code-block demonstrates my implementation to measure the run-time:
To give you a gist, the above implementation finds the average run-time of the standard assignment and the inplace assignment by iteratively performing these operations on a dummy DataFrame df.
To find the run-time performance of other methods, we can replace the reset_index() method with the method of interest (drop(), rename(), fillna() and sort_values()).
The bar-plot below depicts the results obtained.
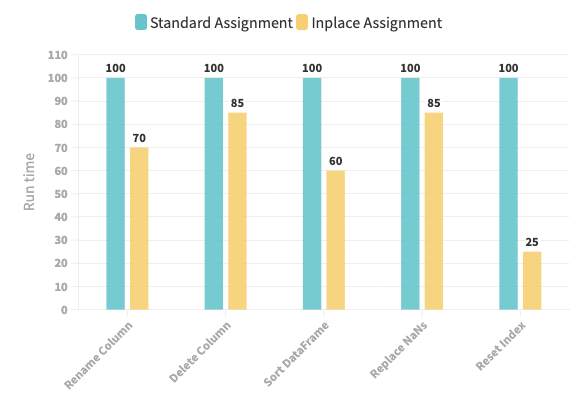
In the above bar plot, I have considered the standard assignment as a reference point and scaled the performance of the inplace assignment accordingly. In other words, if the standard assignment took 100 seconds to execute, each yellow bar above represents the scaled run-time corresponding to the inplace assignment method.
Overall, the Inplace assignment operation always performed better than the standard operation.
Introduction to inplace operations in Pandas, exploring commonly supported methods and a common misconceptions
Inplace assignment operations are widely popular in transforming Pandas DataFrames. As the name suggests, the core idea behind inplace assignment is to avoid creating a new DataFrame object with each successive modification but instead making changes to the original DataFrame itself.
Inplace assignment operations are especially useful in applications with extreme memory constraints. This is because modifications are made to an existing DataFrame (or the source DataFrame) without creating any intermediate DataFrames.
This post is an introduction to inplace operations, specifically on Pandas DataFrames. We will discuss how inplace operations differ from the standard assignment operations. Towards the end, I will present some of the most common methods that support inplace assignments in Pandas.
The highlight of the article is as follows:
Introduction to Inplace Assignment
Common Misconception about Inplace Assignment
Popular Functions that Support Inplace Assignment
Run-time Comparison
Conclusion
Let’s begin 🚀!
Once we load a DataFrame into the Python environment, we typically perform a wide range of transformations on the DataFrame, don’t we? These include adding new columns, renaming headers, deleting columns, altering cell values, replacing NaN values, and many more.
These can be typically performed in two ways, as depicted in the image below:
Standard Assignment
If the applied transformation returns a new copy of the DataFrame, it is called a “non-in-place” or “Standard Assignment” operation in Pandas.
By default, Pandas always resorts to standard assignment and returns the modified copy of the DataFrame, leaving the original DataFrame untouched.
As you may have guessed, this will practically take up additional space in the memory, which can eventually lead to memory constraints. The standard assignment operation is demonstrated in the image below and implemented in the code block following the image:
As a result of the standard assignment operation of filling NaN values shown above, two distinct Pandas objects will exist in the scope of the program — df and df_copy.
Inplace Assignment
In contrast to the standard/traditional assignment, if the intermediate DataFrame generated (such as df_copy above) is of no use to you, performing an inplace assignment is the ideal way to proceed. This is demonstrated below:
On a side note, you should know that inplace assignment exists in numerous functions outside Pandas as well. For instance, when you append an element to a Python list using the
append()method, it is an inplace operation because the element is appended to the source list. Similarly, thesort()method on a Python list also performs inplace sorting.
Inplace operations in Pandas require the inplace argument to be passed as True to the method being invoked. For instance, we can replace the NaN values with 0 in the above DataFrame inplace as follows:
Here, one may argue that we can optimize the memory by assigning the new DataFrame back to the name of the original DataFrame as follows:
Although there’s nothing wrong with the above assignment operation syntactically, you should understand that taking this route inevitably creates a new DataFrame during the assignment operation, leading to an increase in memory utilization temporarily.
We can verify the creation of a new DataFrame object using the id() method in Python as follows:
The ID (or address) of the source DataFrame and that of the new DataFrame are different, implying the creation of a new instance of a Pandas DataFrame.
On the flip side, if you perform an inplace operation with the inplace=True argument, it does not create a new DataFrame. The modifications are made to the original DataFrame itself. This can be verified as follows:
There are a handful of methods in Pandas that are inherently compatible with inplace operations. A few of the most commonly used functions are demonstrated below:
#1 Renaming DataFrame headers
Every column has a specific column header that defines the column’s name. You can change the name of the some/all columns as shown below:
To rename column(s) of a DataFrame, you can use the rename() method in Pandas as shown below:
The standard assignment returns a new DataFrame. Therefore, you must assign it to a variable. However, as the inplace assignment modifies the source DataFrame itself, it does not return anything.
#2 Deleting column(s)
Say you want to remove unwanted column(s) from an existing DataFrame, as illustrated in the figure below:
To delete column(s) of a DataFrame, you can use the drop() method in Pandas as shown below:
You should pass the columns you want to drop as a list of column names to the columns argument of the drop() method.
#3 Sorting a DataFrame
The sorting operation is another widely used method in Pandas. As the name suggests, the idea here is to sort a DataFrame based on the values in one or more columns, as shown below:
You can use the sort_values() method to sort a DataFrame as shown below:
#4 Replacing NaN values
The presence of missing values is inevitable in real-world datasets. With Pandas, you have a range of methods to handle missing data and replace them with definite values, as shown below:
To replace NaN values, use the fillna() method as demonstrated below:
#5 Reset Index, and many more.
If you want to reset the index values of the DataFrame, you can use the reset_index() method in Pandas. The image below demonstrates this operation:
Next, we shall experimentally compare the run-time performance of the standard and the inplace assignment operations on the five Pandas functions discussed above — drop(), rename(), fillna(), reset_index() and sort_values().
The following code-block demonstrates my implementation to measure the run-time:
To give you a gist, the above implementation finds the average run-time of the standard assignment and the inplace assignment by iteratively performing these operations on a dummy DataFrame df.
To find the run-time performance of other methods, we can replace the reset_index() method with the method of interest (drop(), rename(), fillna() and sort_values()).
The bar-plot below depicts the results obtained.
In the above bar plot, I have considered the standard assignment as a reference point and scaled the performance of the inplace assignment accordingly. In other words, if the standard assignment took 100 seconds to execute, each yellow bar above represents the scaled run-time corresponding to the inplace assignment method.
Overall, the Inplace assignment operation always performed better than the standard operation.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.