
Adapting a Sentiment Analysis Model to a Custom Domain | by Magdalena Konkiewicz | Sep, 2022
What our experiments found and your chance to try the model out
Introduction
Can you take a general ML model for sentiment analysis, adapt it to a specific domain, and come up with acceptable results? How much of a challenge is that?
As it turns out, it’s doable with reasonable effort. The ML team at Toloka recently tweaked a general sentiment model to the financial domain, and I’m excited to share the results of our experiments.
You can try the fine-tuned sentiment analysis model here or keep reading for more details.
Baseline model
The baseline model we used is a RoBERTa-based classifier described in this paper.
It is a general natural language processing model that performs a simple sentiment analysis task. It sorts English texts into three classes:
- Positive sentiment 😀
- Neutral sentiment 😐
- Negative sentiment 🙁
This deep learning model was relatively good at recognizing the sentiment of short, tweet-like texts similar to what it was trained on, but that aptitude dropped off a cliff when we checked its performance in the financial domain. It was the perfect opportunity for the ML team to adapt the model to a specific area.
Fine-tuned model
We used the FinancialPhraseBank dataset. It consists of 4840 English sentences from financial news categorized by sentiment. Once again, we had three classes:
- Positive sentiment 😀
- Neutral sentiment 😐
- Negative sentiment 🙁
In our experiment we only tuned the classification head using a learning rate of 1e-2, running it for five epochs, and using only half of the data. Tuning only the head (freezing the rest of the weights) is an unusual way to train deep learning models. This approach is usually applied in CV and significantly reduces training complexity. It can be done on smaller GPUs, but the procedure does not work all the time — for some of the tasks it may be insufficient. Luckily in our case, the model trained that way gave us impressive results on the test set and we decided to evaluate it using a different set of financial data.
Evaluation Data set
The dataset we used to evaluate both sentiment analysis models is from Kaggle and can be downloaded here. It is a long list of financial headlines annotated with a sentiment relative to the financial entities in them. You can see the first few lines of this below.

Because our sentiment analysis model is not aspect-based, we had to preprocess the dataset before we could evaluate it. We decided to sentiment-label each title like this:
- If all entities mentioned in the headline have the same sentiment, we can assume that is the sentiment for the whole headline
- If entities have mixed sentiments, we remove them from the dataset
That resulted in a unique overall sentiment for each headline as seen below.

We only used 1000 entries, assuming that was enough for reliable evaluation. You can check this colab notebook to find the code we used in the experiment and more details on how we did perform sentiment analysis for each model.
Sentiment analysis results
After we have gathered sentiment analysis predictions for both our machine learning models we could have built a fair comparison between them by looking at accuracy, precision, recall, and f-score. We printed classification reports for both models using the scikit-learn library.
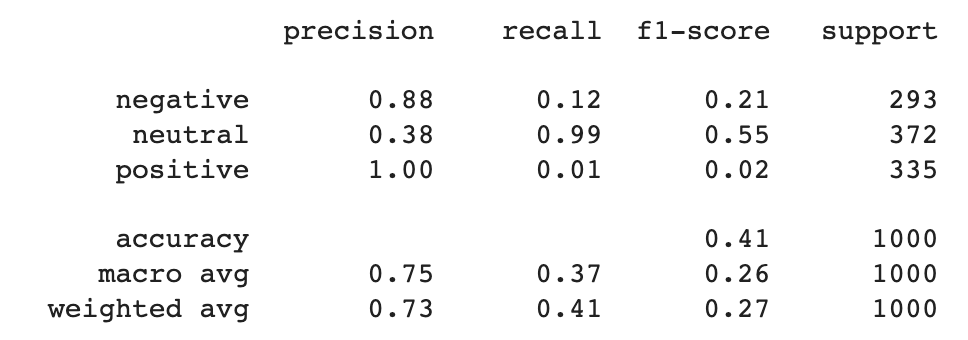

From the pictures above, you can see that the fine-tuned version outperformed the baseline in all average metrics:
- Precision went from 0.73 to 0.77
- Recall went from 0.41 to 0.76
- F-score went from 0.27 to 0.77
The individual results show that the recall of positive and negative classes for the baseline model was very low: 0.01 and 0.12, respectively. Fine-tuning the new model drove a recall of 0.71 for the positive class and 0.78 for the negative class.
This high improvement in recall, in this case, is an effect of domain tuning. The baseline model did not encounter in its training the financial terms present in the evaluation data set and this is why it struggled with finding positive and negative words in this context. It definitively changed after the model was adapted and exposed to in-domain training data and resulted in a boost of a recall for positive and negative classes.
Recall for the neutral class, however, dropped from 0.99 to 0.8. Precision for negative and positive fell slightly as well. Those are metrics we need to bear in mind, though the high baseline scores were caused by the model overpredicting the neutral class.
Confusion matrices illustrate the situation.

A closer look reveals the problems the baseline model had labeling positive and negative sentiments. It mislabeled positive headlines as neutral 331 times. Similarly, the negative class was mislabeled as neutral 258 times. That is very poor performance on classes that should be reliably detected in such sentiment classification tasks.
The fine-tuned model fixed that problem and gave us more correct predictions. The positive class was only mislabeled as neutral 85 times, while the negative class was mislabeled as neutral 56 times. This is again thanks to adapting the model and the fact that during find tuning it learned what are positive and negative indicators in financial texts.
Summary
Toloka ML team has proved that a sentiment model trained on a different domain can be fine-tuned to a new domain creating a custom sentiment analysis model with relative ease and not much data.
Our baseline model was trained to detect sentiment for social media posts, making it prone to errors in the financial domain. But fine-tuning the model in the financial domain, even with a completely different financial dataset, improved the results significantly.
You can read through the code for the experiment in this colab notebook.
You’re also welcome to play around with the fine-tuned model and let us know what you think about it in the comments below.
PS: I am writing articles that explain basic Data Science concepts in a simple and comprehensible manner on Medium and aboutdatablog.com. You can subscribe to my email list to get notified every time I write a new article. And if you are not a Medium member yet you can join here.
Below there are some other posts you may enjoy:
What our experiments found and your chance to try the model out

Introduction
Can you take a general ML model for sentiment analysis, adapt it to a specific domain, and come up with acceptable results? How much of a challenge is that?
As it turns out, it’s doable with reasonable effort. The ML team at Toloka recently tweaked a general sentiment model to the financial domain, and I’m excited to share the results of our experiments.
You can try the fine-tuned sentiment analysis model here or keep reading for more details.
Baseline model
The baseline model we used is a RoBERTa-based classifier described in this paper.
It is a general natural language processing model that performs a simple sentiment analysis task. It sorts English texts into three classes:
- Positive sentiment 😀
- Neutral sentiment 😐
- Negative sentiment 🙁
This deep learning model was relatively good at recognizing the sentiment of short, tweet-like texts similar to what it was trained on, but that aptitude dropped off a cliff when we checked its performance in the financial domain. It was the perfect opportunity for the ML team to adapt the model to a specific area.
Fine-tuned model
We used the FinancialPhraseBank dataset. It consists of 4840 English sentences from financial news categorized by sentiment. Once again, we had three classes:
- Positive sentiment 😀
- Neutral sentiment 😐
- Negative sentiment 🙁
In our experiment we only tuned the classification head using a learning rate of 1e-2, running it for five epochs, and using only half of the data. Tuning only the head (freezing the rest of the weights) is an unusual way to train deep learning models. This approach is usually applied in CV and significantly reduces training complexity. It can be done on smaller GPUs, but the procedure does not work all the time — for some of the tasks it may be insufficient. Luckily in our case, the model trained that way gave us impressive results on the test set and we decided to evaluate it using a different set of financial data.
Evaluation Data set
The dataset we used to evaluate both sentiment analysis models is from Kaggle and can be downloaded here. It is a long list of financial headlines annotated with a sentiment relative to the financial entities in them. You can see the first few lines of this below.
Because our sentiment analysis model is not aspect-based, we had to preprocess the dataset before we could evaluate it. We decided to sentiment-label each title like this:
- If all entities mentioned in the headline have the same sentiment, we can assume that is the sentiment for the whole headline
- If entities have mixed sentiments, we remove them from the dataset
That resulted in a unique overall sentiment for each headline as seen below.
We only used 1000 entries, assuming that was enough for reliable evaluation. You can check this colab notebook to find the code we used in the experiment and more details on how we did perform sentiment analysis for each model.
Sentiment analysis results
After we have gathered sentiment analysis predictions for both our machine learning models we could have built a fair comparison between them by looking at accuracy, precision, recall, and f-score. We printed classification reports for both models using the scikit-learn library.
From the pictures above, you can see that the fine-tuned version outperformed the baseline in all average metrics:
- Precision went from 0.73 to 0.77
- Recall went from 0.41 to 0.76
- F-score went from 0.27 to 0.77
The individual results show that the recall of positive and negative classes for the baseline model was very low: 0.01 and 0.12, respectively. Fine-tuning the new model drove a recall of 0.71 for the positive class and 0.78 for the negative class.
This high improvement in recall, in this case, is an effect of domain tuning. The baseline model did not encounter in its training the financial terms present in the evaluation data set and this is why it struggled with finding positive and negative words in this context. It definitively changed after the model was adapted and exposed to in-domain training data and resulted in a boost of a recall for positive and negative classes.
Recall for the neutral class, however, dropped from 0.99 to 0.8. Precision for negative and positive fell slightly as well. Those are metrics we need to bear in mind, though the high baseline scores were caused by the model overpredicting the neutral class.
Confusion matrices illustrate the situation.
A closer look reveals the problems the baseline model had labeling positive and negative sentiments. It mislabeled positive headlines as neutral 331 times. Similarly, the negative class was mislabeled as neutral 258 times. That is very poor performance on classes that should be reliably detected in such sentiment classification tasks.
The fine-tuned model fixed that problem and gave us more correct predictions. The positive class was only mislabeled as neutral 85 times, while the negative class was mislabeled as neutral 56 times. This is again thanks to adapting the model and the fact that during find tuning it learned what are positive and negative indicators in financial texts.
Summary
Toloka ML team has proved that a sentiment model trained on a different domain can be fine-tuned to a new domain creating a custom sentiment analysis model with relative ease and not much data.
Our baseline model was trained to detect sentiment for social media posts, making it prone to errors in the financial domain. But fine-tuning the model in the financial domain, even with a completely different financial dataset, improved the results significantly.
You can read through the code for the experiment in this colab notebook.
You’re also welcome to play around with the fine-tuned model and let us know what you think about it in the comments below.
PS: I am writing articles that explain basic Data Science concepts in a simple and comprehensible manner on Medium and aboutdatablog.com. You can subscribe to my email list to get notified every time I write a new article. And if you are not a Medium member yet you can join here.
Below there are some other posts you may enjoy:
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.