
Architecting High-Performance Supercomputers for Tomorrow’s Challenges
Since the 1940s, neural networks have evolved significantly, from the early concepts of McCulloch and Pitts to Frank Rosenblatt’s perceptron in the 1950s. Major advancements in the late 20th century, like the development of the Backpropagation method, set the stage for modern deep learning. The introduction of the transformer architecture in 2017’s “Attention is All You Need” by Google researchers marked a turning point in Natural Language Processing (NLP), leading to the development of powerful models like BERT and GPT.
In 2020, OpenAI’s introduction of GPT-3, a model with 175 billion parameters, exemplified the need for high-performance computing. Training such massive models required advanced GPU or TPU clusters and immense computational resources, highlighting the evolving challenges in supercomputing architecture for AI development.
This article encompasses a range of topics, from Yandex’s use of advanced neural networks in search technologies and the training of Large Language Models to the challenges faced by engineers in utilizing High-Performance Computing and strategies for future HPC cluster design.
Transformers in Search: Yandex’s Utilization of Advanced Neural Networks
In “Transformers in Search: Yandex’s Implementation of Advanced Neural Networks for Meaning-Based Search” published by Sasha Gotmanov, Head of the Neural Network Technologies Group at Yandex.Search, on Habr, delves into the integration of transformer neural networks into Yandex’s search engine, aiming to optimize web page ranking by assessing semantic relevance.
Neural networks in search are essential for effectively ranking search results by understanding the semantic relationship between a user’s query and web documents. Initially, search ranking relied on analytical and heuristic methods, but their effectiveness plateaued over time. The advent of neural networks, especially transformers, marked a significant improvement in quality indicators. These transformers are versatile, extending beyond language tasks to include voice generation and user behavior prediction. However, training these models demands substantial computational power. While training on a regular CPU server could take decades, using GPU accelerators significantly reduces this time. The process is further optimized by parallelizing the task across multiple GPUs with good connectivity between them, enabling efficient training within a reasonable timeframe. This advancement marks a significant stride in Yandex’s search technology over the last decade.
What Training Large Models Looks Like: Yandex Case Study
As was already stated, training large models at Yandex involves deploying powerful GPU clusters, addressing significant challenges in computational resources and network efficiency. But what does its training process look like? In the “Yandex Supercomputers: An Inside Look”, authors endeavored to construct an initial cluster using the materials they had at their disposal. They employed several servers, each embedded with eight NVIDIA V100 GPUs connected via RoCE network. Their initial trials, however, did not yield successful results.
The efficiency of scaling was disappointingly low according to the measurements taken. To diagnose the issue, they formulated an evaluation method that, in addition to understanding how the learning algorithm works, provided a metric that shows what the problem is. They simply created a chart that compared energy usage and data exchange on the same scale.
The graph of energy consumption and traffic exchange on the same scale – the one obtained on an initial cluster. Source: HABR
The training process was repetitive: Each GPU is assigned a batch which it processes, as represented by a blue segment in the chart. Following this, the GPU transmits the processed data to adjacent GPUs via the network, depicted as a green segment on the chart. This cycle then recommences from the first step.
The graph provided above pinpointed the main issue. Half of the time was consumed by network exchanges, during which the GPUs remained idle, leading to inefficient hardware utilization.
The server’s limitations, restricted by PCIe Gen3 x8 and capped at a network throughput of 62 Gbps, rendered serious computation impractical on the existing cluster. This made the development of a new solution needed to address the interconnect bottlenecks.
Thus, this necessitated the deployment of a comprehensive HPC solution. As a result, the “Chervonenkis” cluster, equipped with 1,592 GPUs, was initiated in 2021. Its reported performance capabilities were 21,530 petaflops for operational tasks and 29,415 petaflops at peak, establishing it as the most powerful supercomputer in Russia and Eastern Europe. But to achieve this peak performance, we had to fix many software problems that were found with LINPACK benchmarks, which is used to build the TOP500 list.
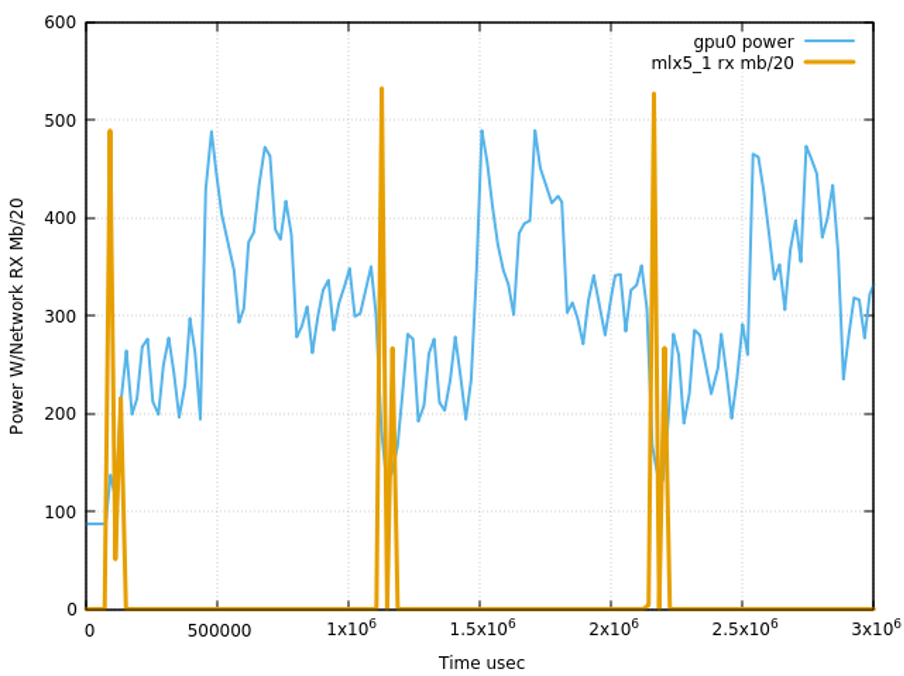
In this setup, the phase for network exchange required significantly less time compared to the initial arrangement. This efficiency enabled the training of contemporary models in a reasonable timeframe while achieving high cluster utilization. Achieving this required not only state-of-the-art equipment but also substantial updates to the entire software stack, including the training code. Nevertheless, the models continue to grow in complexity and size.
How To Train Your LLM
To date, we have observed this process within Yandex. However, to better grasp that modern language models require even greater computational power, let’s consider an additional example. Imagine that you want to train your own modern LLM. What exactly would you need?
As stated in the summary of Andrej Karpathy’s (Ex-Senior Director of AI at Tesla, Current OpenAI Technical Member) video on the basics of Large Language Models, to train a large language model like LLama 2–70b developed by Meta AI, substantial resources are required. Initially, a significant portion of the internet, about 10 terabytes (or 10,000 gigabytes) of data, is collected through web crawling and scraping. This data is then processed using a powerful setup of around 6,000 GPUs, running continuously for approximately 12 days. The cost of this extensive training process is estimated to be around $2 million. The end result is a condensed parameters file, approximately 140GB in size. This demonstrates a compression ratio of nearly 100 times, illustrating the process as akin to “compressing” the internet.
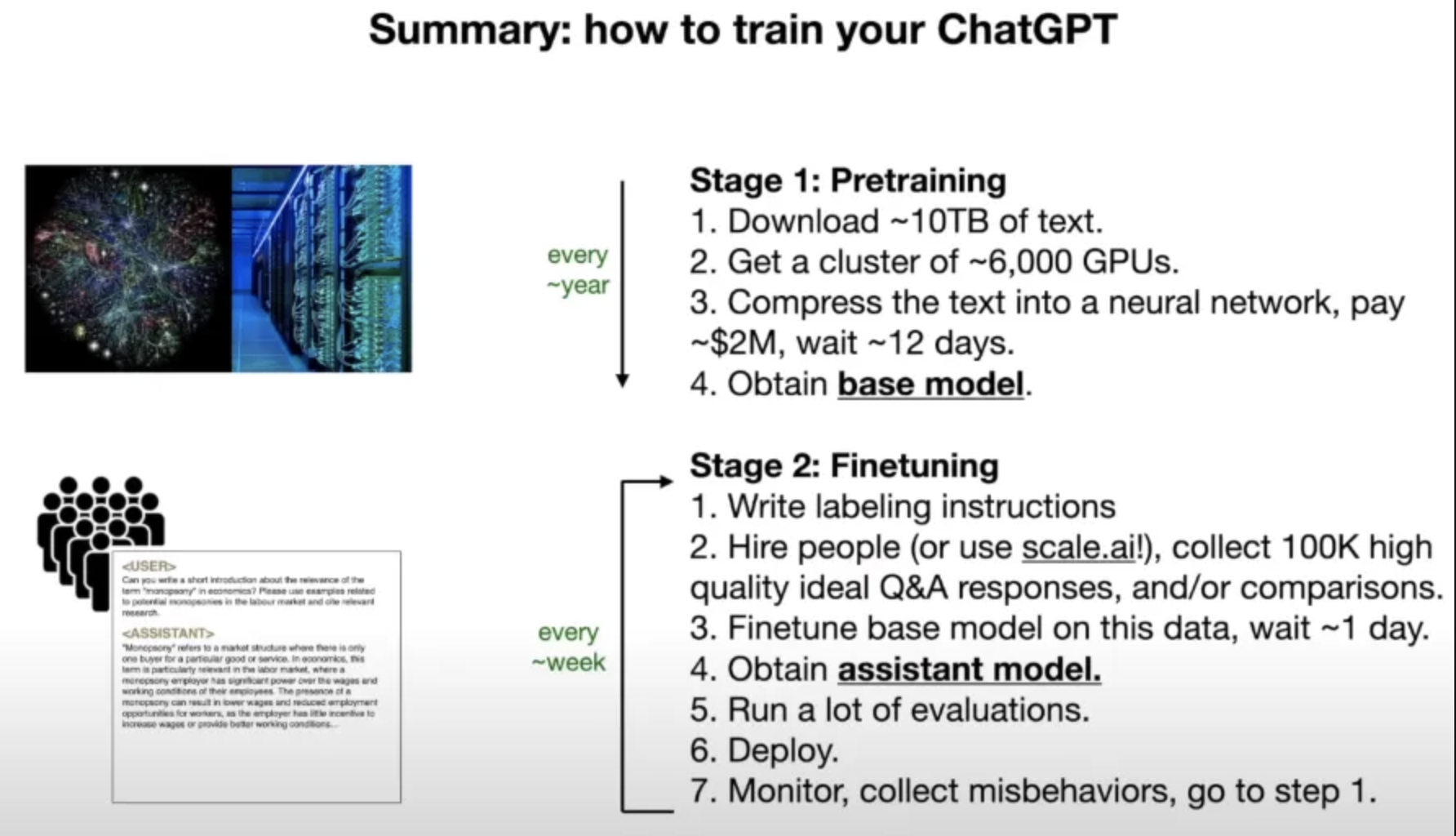
In other terms, the development of a large language model (LLM) involves two key steps:
Pretraining: Initially, the internet is scraped to gather extensive textual data. This data is used to train a neural network, focusing on improving its next-word prediction capabilities. The result is a basic “document generator software” that produces text. However, the aim is to create a useful assistant capable of performing various tasks, not just generating text.
Finetuning: In this phase, individuals are hired to precisely label data, ensuring the responses are accurate and safe. This stage also includes human-machine collaboration to optimize responses. Finetuning is less costly than pretraining and, through repeated iterations, leads to the development of a practical LLM assistant model.
However, when it comes to training, understanding the LLM Scaling Law is crucial, as it outlines how system behavior changes with increases in size or other key parameters. Generally, this law indicates that larger models with more parameters and data tend to perform better, seemingly enhancing intelligence without significant algorithmic advancements. This is significant because improvements in LLMs directly enhance performance across various NLP tasks, as evidenced during evaluations, leading to more capable and effective language models.
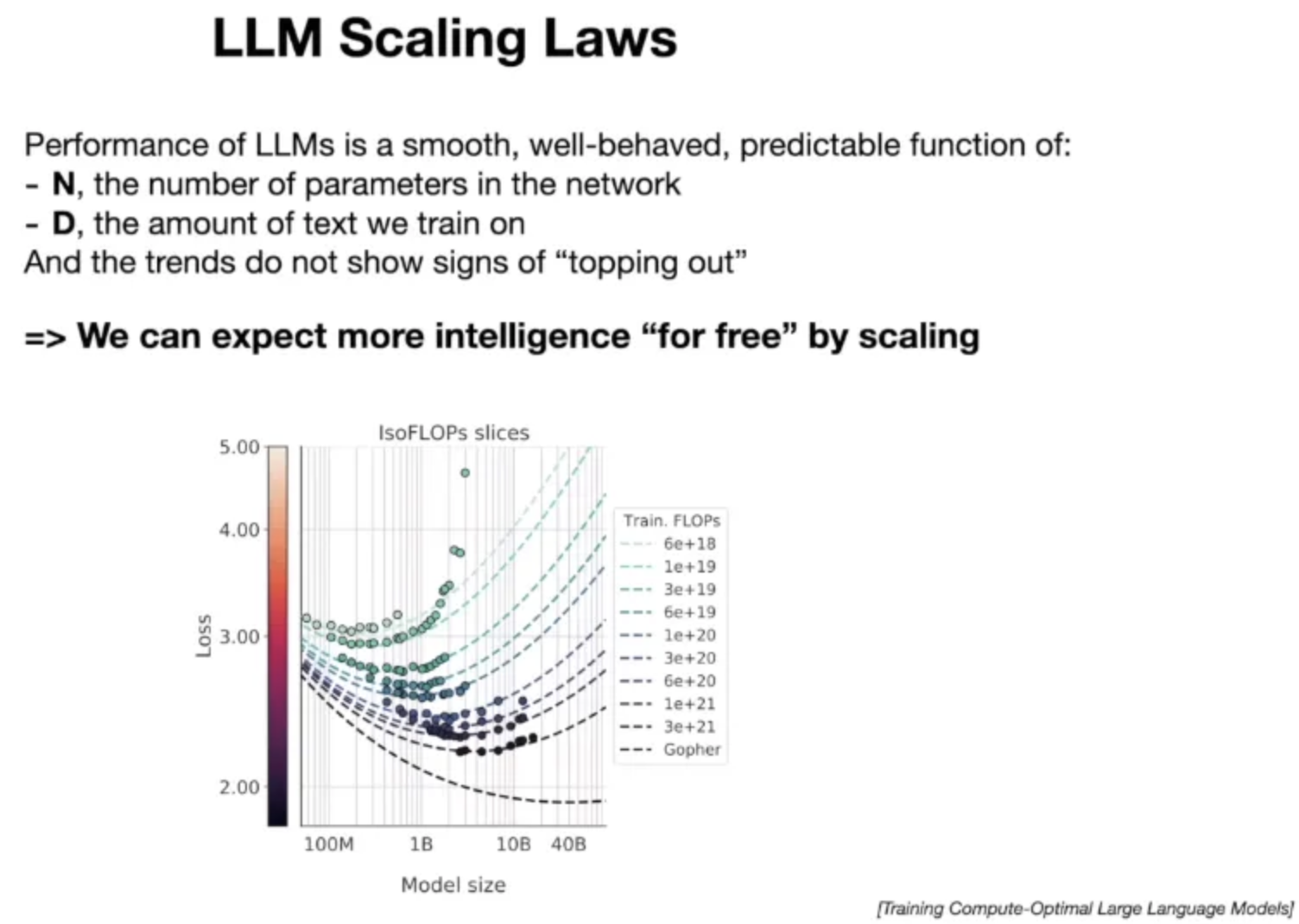
Consequently, this implies a trend towards larger models, making the deployment of even larger High-Performance Computing (HPC) clusters necessary to support these advanced systems. In fact, modern LLMs require a cluster about 3-4 times larger than the Chervonenkis cluster, and this escalation has occurred in just two years.
Challenges for Machine Learning Engineers in Utilizing High-Performance Computing
In the case of modern high-performance computing (HPC), clusters are evolving into comprehensive platforms that encompass not just hardware but also software, methodologies, and more. These platforms aim to provide ML engineers with a convenient service for independently training models while minimizing both human and hardware resources.
Key areas of focus include performance, observability, and debuggability. The platform must offer necessary tools for profiling distributed training and identifying bottlenecks.
Besides that, training sessions that span weeks pose another challenge. Hardware is prone to failure; for instance, in a cluster with thousands of GPUs, daily breakdowns are inevitable. Additionally, distinguishing between user-related issues and platform issues is often complex, necessitating specialized tools. For example, at Yandex, we implemented the execution of specialized tests before and after initiating training on each node. This was done to ensure that the node is functional for training purposes and to differentiate between hardware errors and faults in the training code (though this does not cover all potential failures). This reality highlights the importance of having capabilities to save training states. Transferring this responsibility to the user risks significant losses in machine time and resources. Therefore, contemporary learning platforms are tasked with resolving these issues on behalf of the user.
What Are the Strategies For the Design of HPC Clusters of The Future?
In envisioning the future of High-Performance Computing (HPC) clusters, it’s essential to focus on maximizing fleet-wide throughput. One promising approach is the design principles adopted by Singularity, Microsoft’s global scheduling service designed for efficient and reliable execution of deep learning tasks, encompassing both training and inference workloads. These principles include:
No Idling of Resources: It treats all accelerators as part of a single, shared resource, preventing underutilization and avoiding the need for fixed capacity reservations. This method enables flexible use of available capacity for various tasks globally.
Job-Level SLAs: While utilizing available resources, Singularity also ensures that specific service agreements for each job are honored. It dynamically adjusts resources, such as reducing training job resources to meet the demands of inference jobs when necessary.
Resilience to Failures: Recognizing the long duration of DNN training, Singularity is designed to recover from disruptions efficiently. Instead of restarting, jobs continue from the last saved point, reducing time and resource waste.
Conversely, future HPC systems must be capable of processing even larger models. This necessitates addressing the challenge of connectivity between nodes. Meta Platforms have their vision: they strive to adapt Ethernet technology for AI applications. Currently, their fabric based on RoCE allows up to 32,000 GPUs to be combined.
Another key trend transforming the HPC field that should be mentioned is the swift uptake of cloud computing, driven by the increasing availability and affordability of services from major providers like AWS, Azure, and Google Cloud. These companies offer advanced HPC services, including high-performance VMs and storage. However, supercomputers, despite their impressive capabilities, face the challenge of a relatively short lifespan. Their use of advanced technology for high-speed processing and computation leads to issues like heat and high power consumption, reducing their longevity and increasing costs over time.
Conclusion: What the Future Holds
High-performance computing is transitioning from an exclusive resource to a widely accessible platform for numerous companies, driven by the growing necessity of LLMs. The expansion of HPC is essential for businesses to keep pace with technological advancements. However, as LLMs expand, HPC clusters must also evolve, presenting various engineering challenges.
Moreover, a significant future development could be the potential replacement of GPUs with Quantum Processing Units (QPUs), offering a transformative leap in processing power and efficiency, thereby reshaping the HPC scene.
Since the 1940s, neural networks have evolved significantly, from the early concepts of McCulloch and Pitts to Frank Rosenblatt’s perceptron in the 1950s. Major advancements in the late 20th century, like the development of the Backpropagation method, set the stage for modern deep learning. The introduction of the transformer architecture in 2017’s “Attention is All You Need” by Google researchers marked a turning point in Natural Language Processing (NLP), leading to the development of powerful models like BERT and GPT.
In 2020, OpenAI’s introduction of GPT-3, a model with 175 billion parameters, exemplified the need for high-performance computing. Training such massive models required advanced GPU or TPU clusters and immense computational resources, highlighting the evolving challenges in supercomputing architecture for AI development.
This article encompasses a range of topics, from Yandex’s use of advanced neural networks in search technologies and the training of Large Language Models to the challenges faced by engineers in utilizing High-Performance Computing and strategies for future HPC cluster design.
Transformers in Search: Yandex’s Utilization of Advanced Neural Networks
In “Transformers in Search: Yandex’s Implementation of Advanced Neural Networks for Meaning-Based Search” published by Sasha Gotmanov, Head of the Neural Network Technologies Group at Yandex.Search, on Habr, delves into the integration of transformer neural networks into Yandex’s search engine, aiming to optimize web page ranking by assessing semantic relevance.
Neural networks in search are essential for effectively ranking search results by understanding the semantic relationship between a user’s query and web documents. Initially, search ranking relied on analytical and heuristic methods, but their effectiveness plateaued over time. The advent of neural networks, especially transformers, marked a significant improvement in quality indicators. These transformers are versatile, extending beyond language tasks to include voice generation and user behavior prediction. However, training these models demands substantial computational power. While training on a regular CPU server could take decades, using GPU accelerators significantly reduces this time. The process is further optimized by parallelizing the task across multiple GPUs with good connectivity between them, enabling efficient training within a reasonable timeframe. This advancement marks a significant stride in Yandex’s search technology over the last decade.
What Training Large Models Looks Like: Yandex Case Study
As was already stated, training large models at Yandex involves deploying powerful GPU clusters, addressing significant challenges in computational resources and network efficiency. But what does its training process look like? In the “Yandex Supercomputers: An Inside Look”, authors endeavored to construct an initial cluster using the materials they had at their disposal. They employed several servers, each embedded with eight NVIDIA V100 GPUs connected via RoCE network. Their initial trials, however, did not yield successful results.
The efficiency of scaling was disappointingly low according to the measurements taken. To diagnose the issue, they formulated an evaluation method that, in addition to understanding how the learning algorithm works, provided a metric that shows what the problem is. They simply created a chart that compared energy usage and data exchange on the same scale.
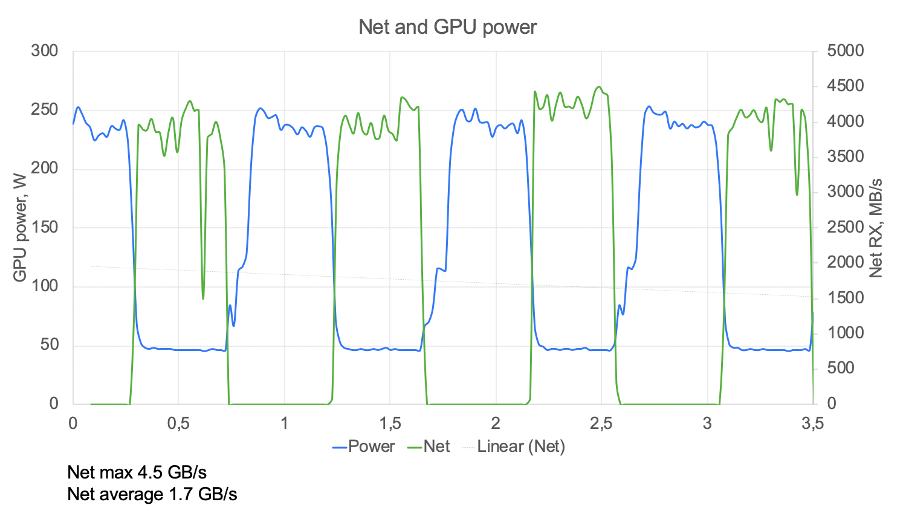
The graph of energy consumption and traffic exchange on the same scale – the one obtained on an initial cluster. Source: HABR
The training process was repetitive: Each GPU is assigned a batch which it processes, as represented by a blue segment in the chart. Following this, the GPU transmits the processed data to adjacent GPUs via the network, depicted as a green segment on the chart. This cycle then recommences from the first step.
The graph provided above pinpointed the main issue. Half of the time was consumed by network exchanges, during which the GPUs remained idle, leading to inefficient hardware utilization.
The server’s limitations, restricted by PCIe Gen3 x8 and capped at a network throughput of 62 Gbps, rendered serious computation impractical on the existing cluster. This made the development of a new solution needed to address the interconnect bottlenecks.
Thus, this necessitated the deployment of a comprehensive HPC solution. As a result, the “Chervonenkis” cluster, equipped with 1,592 GPUs, was initiated in 2021. Its reported performance capabilities were 21,530 petaflops for operational tasks and 29,415 petaflops at peak, establishing it as the most powerful supercomputer in Russia and Eastern Europe. But to achieve this peak performance, we had to fix many software problems that were found with LINPACK benchmarks, which is used to build the TOP500 list.
In this setup, the phase for network exchange required significantly less time compared to the initial arrangement. This efficiency enabled the training of contemporary models in a reasonable timeframe while achieving high cluster utilization. Achieving this required not only state-of-the-art equipment but also substantial updates to the entire software stack, including the training code. Nevertheless, the models continue to grow in complexity and size.
How To Train Your LLM
To date, we have observed this process within Yandex. However, to better grasp that modern language models require even greater computational power, let’s consider an additional example. Imagine that you want to train your own modern LLM. What exactly would you need?
As stated in the summary of Andrej Karpathy’s (Ex-Senior Director of AI at Tesla, Current OpenAI Technical Member) video on the basics of Large Language Models, to train a large language model like LLama 2–70b developed by Meta AI, substantial resources are required. Initially, a significant portion of the internet, about 10 terabytes (or 10,000 gigabytes) of data, is collected through web crawling and scraping. This data is then processed using a powerful setup of around 6,000 GPUs, running continuously for approximately 12 days. The cost of this extensive training process is estimated to be around $2 million. The end result is a condensed parameters file, approximately 140GB in size. This demonstrates a compression ratio of nearly 100 times, illustrating the process as akin to “compressing” the internet.
In other terms, the development of a large language model (LLM) involves two key steps:
Pretraining: Initially, the internet is scraped to gather extensive textual data. This data is used to train a neural network, focusing on improving its next-word prediction capabilities. The result is a basic “document generator software” that produces text. However, the aim is to create a useful assistant capable of performing various tasks, not just generating text.
Finetuning: In this phase, individuals are hired to precisely label data, ensuring the responses are accurate and safe. This stage also includes human-machine collaboration to optimize responses. Finetuning is less costly than pretraining and, through repeated iterations, leads to the development of a practical LLM assistant model.
However, when it comes to training, understanding the LLM Scaling Law is crucial, as it outlines how system behavior changes with increases in size or other key parameters. Generally, this law indicates that larger models with more parameters and data tend to perform better, seemingly enhancing intelligence without significant algorithmic advancements. This is significant because improvements in LLMs directly enhance performance across various NLP tasks, as evidenced during evaluations, leading to more capable and effective language models.
Consequently, this implies a trend towards larger models, making the deployment of even larger High-Performance Computing (HPC) clusters necessary to support these advanced systems. In fact, modern LLMs require a cluster about 3-4 times larger than the Chervonenkis cluster, and this escalation has occurred in just two years.
Challenges for Machine Learning Engineers in Utilizing High-Performance Computing
In the case of modern high-performance computing (HPC), clusters are evolving into comprehensive platforms that encompass not just hardware but also software, methodologies, and more. These platforms aim to provide ML engineers with a convenient service for independently training models while minimizing both human and hardware resources.
Key areas of focus include performance, observability, and debuggability. The platform must offer necessary tools for profiling distributed training and identifying bottlenecks.
Besides that, training sessions that span weeks pose another challenge. Hardware is prone to failure; for instance, in a cluster with thousands of GPUs, daily breakdowns are inevitable. Additionally, distinguishing between user-related issues and platform issues is often complex, necessitating specialized tools. For example, at Yandex, we implemented the execution of specialized tests before and after initiating training on each node. This was done to ensure that the node is functional for training purposes and to differentiate between hardware errors and faults in the training code (though this does not cover all potential failures). This reality highlights the importance of having capabilities to save training states. Transferring this responsibility to the user risks significant losses in machine time and resources. Therefore, contemporary learning platforms are tasked with resolving these issues on behalf of the user.
What Are the Strategies For the Design of HPC Clusters of The Future?
In envisioning the future of High-Performance Computing (HPC) clusters, it’s essential to focus on maximizing fleet-wide throughput. One promising approach is the design principles adopted by Singularity, Microsoft’s global scheduling service designed for efficient and reliable execution of deep learning tasks, encompassing both training and inference workloads. These principles include:
No Idling of Resources: It treats all accelerators as part of a single, shared resource, preventing underutilization and avoiding the need for fixed capacity reservations. This method enables flexible use of available capacity for various tasks globally.
Job-Level SLAs: While utilizing available resources, Singularity also ensures that specific service agreements for each job are honored. It dynamically adjusts resources, such as reducing training job resources to meet the demands of inference jobs when necessary.
Resilience to Failures: Recognizing the long duration of DNN training, Singularity is designed to recover from disruptions efficiently. Instead of restarting, jobs continue from the last saved point, reducing time and resource waste.
Conversely, future HPC systems must be capable of processing even larger models. This necessitates addressing the challenge of connectivity between nodes. Meta Platforms have their vision: they strive to adapt Ethernet technology for AI applications. Currently, their fabric based on RoCE allows up to 32,000 GPUs to be combined.
Another key trend transforming the HPC field that should be mentioned is the swift uptake of cloud computing, driven by the increasing availability and affordability of services from major providers like AWS, Azure, and Google Cloud. These companies offer advanced HPC services, including high-performance VMs and storage. However, supercomputers, despite their impressive capabilities, face the challenge of a relatively short lifespan. Their use of advanced technology for high-speed processing and computation leads to issues like heat and high power consumption, reducing their longevity and increasing costs over time.
Conclusion: What the Future Holds
High-performance computing is transitioning from an exclusive resource to a widely accessible platform for numerous companies, driven by the growing necessity of LLMs. The expansion of HPC is essential for businesses to keep pace with technological advancements. However, as LLMs expand, HPC clusters must also evolve, presenting various engineering challenges.
Moreover, a significant future development could be the potential replacement of GPUs with Quantum Processing Units (QPUs), offering a transformative leap in processing power and efficiency, thereby reshaping the HPC scene.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.