
Async for Data Scientists — Don’t Block the Event Loop | by Diego Barba | Jul, 2022
CPU-hungry tasks or non-async I/O libraries may block the event loop of your program. Learn how to avoid this in Python.
Asynchronous programming has become the standard paradigm for API design and most services. The scope for a data scientist’s skill set has also evolved. Today is not enough to create good models or visualizations; in most cases, deploying them through an API or another service is also necessary. If you haven’t been dealing with async programming in your deployments, the odds are you will soon.
Just to be clear, this story is not another async tutorial. But instead, some insight into the common obstacles a data scientist may face when interfacing its tools with async frameworks. Namely, blocking the event loop with CPU-hungry tasks or non-async I/O libraries.
This story will explore how the event loop may get blocked and the resources we have to prevent it.
There are many good libraries in Python which handle async programming, but Asyncio got to be the library included as standard in Python; check out Trio, for example. Hence, in this story, we will focus on Asyncio.
Story Structure
- The event loop
- Test Setup
- Calling blocking functions naively
- Asyncio default executor
- Concurrent.futures ThreadPool
- Concurrent.futures ProcessPool
- I/O-bound benchmarks
- CPU-bound benchmarks
- Moral of the story
The event loop
Whether you use the Asyncio module or any other async library, they all use an event loop underneath. The event loop is a scheduler responsible for executing all coroutines (async functions) during the program’s lifespan.
This concurrency model is essentially a single while (loop) that takes the coroutines and cleverly runs them. Once a coroutine is executing, the await (yield) keyword yields back control to the event loop to run other coroutines. Hence, while the event loop waits for an I/O response, a future completion, or simply an async sleep, it can run other coroutines. The event loop keeps track of what should be returned to each coroutine and will return it to the corresponding coroutine in future iterations of the loop.
Now that we know how the event loop works, let’s think of what happens when we run CPU-intensive tasks in the event loop. Here is precisely where the discussion becomes relevant for data scientists. If we run a CPU-bound job in the event loop, the loop will run the task until it is completed, like any sequential and plain while loop you have ever used. That is a massive problem in async programming since all other tasks will have to wait until our CPU-hungry job is done.
There are three rules when it comes to event loops:
- you do not block the event loop
- you do not block the event loop
- you do not block the event loop
At first glance, blocking the event loop may not sound so bad. But think of this scenario. You are responsible for coding a module that will provide data analytics within a larger app (service) that exposes an API. The API is written in an async framework. If you wrap your CPU-bound functions in coroutines, you may end up crippling the whole app. All other tasks, like client handling, will be stopped until the CPU-hungry task is done.
The following sections will review ways to run event loop blocking tasks and study their performance.
Test Setup
We begin our event loop blocking test with two functions:
- a function that performs a CPU-bound task: a matrix multiplication using NumPy
- a function that sleeps the thread, i.e., some non-async I/O (for example, a non-async database library); yes,
time.sleepwill block the event loop
Let’s time (outside the event loop) our CPU-bound function with a square matrix of 7,000 elements per side so we know what to expect:
9.97 s ± 2.07 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
Then we create a function that simulates a periodic I/O task. This function runs a loop for durarion_secs and appends the current timestamp to a list (time_log) before the task begins (asyncio.sleep for sleep_secs) and after it is completed:
This function’s time log will be our data to assess whether other processes are blocking the event loop. Furthermore, we format the time logs so that we only keep the time differences before the task was executed and right after.
Using a sleep of 1 millisecond, this is how the time_log looks without any other function running in the event loop:
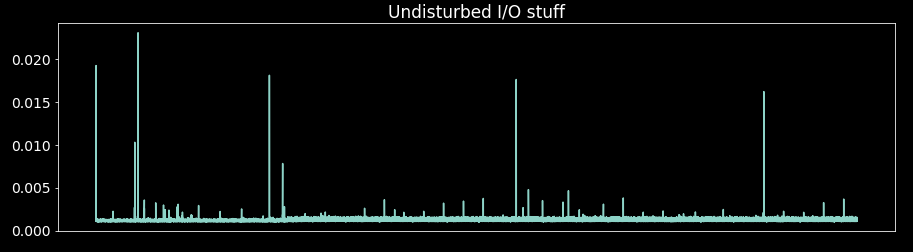
Calling blocking functions naively
The first approach we could take, naively, to create an async library is to wrap our blocking functions in a coroutine:
To test this approach, we wrap our functions, the CPU-bound and the thread blocking (time.sleep), inside a loop that executes the function periodically and appends to a time_log:
Now we run all tasks concurrently, the dummy_io_stuff , the CPU-intensive and thread sleep functions:
Note: In this code, I ran await coroutine outside a coroutine because I am using a Jupyter notebook, but the rule is that await should only be used inside coroutines (async def).
These are the results of the formated time logs:

As we can see from the I/O time log (first subplot), the event loop is blocked. We expect an average of a millisecond, and the time taken is more than 5 seconds in most iterations.
The other two plots show that the other tasks did not execute all the time during the test, instead competed for resources and blocked each other.
Asyncio default executor
The solution to avoid event loop blockage is executing our blocking code elsewhere. We can use threads or other processes to accomplish this. Asyncio has a very convenient loop method, run_in_executor. This method uses the concurrent.futures threading and multiprocessing interface. The default way to run our blocking functions is like so:
The first argument of run_in_executor is set to None (default executor), the second argument is the function we want to run in the executor, and the following arguments are the function’s arguments. This default executor is the ThreadPoolExecutor from concurrent.futures with the defaults.
Wrapping our functions, analogous to the previous section, and running the tasks concurrently:
The results of the formated time logs are:
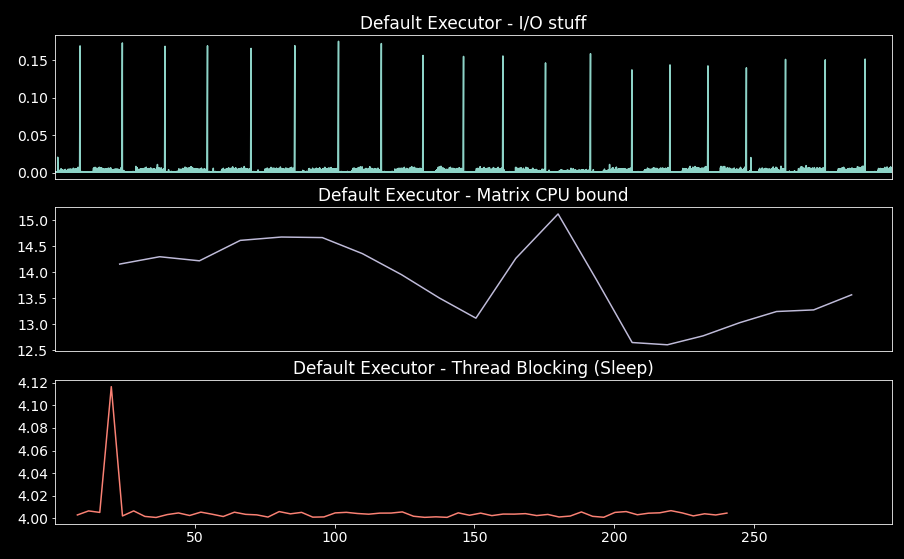
We can see that there are still some minor glitches in the event loop (first plot), but the I/O time log shows a time difference of close to one millisecond. As per the blocking tasks themselves, they did execute concurrently.
Concurrent.futures ThreadPool
We can customize the ThreadPoolExecutor from the previous section by defining it explicitly and passing it to the run_in_executor method:
Using the ThreadPoolExecutorwith only one worker, we wrap our blocking functions to execute them periodically and keep a time log, analogous to the previous sections:
Running our tasks concurrently and plotting the formated time logs:
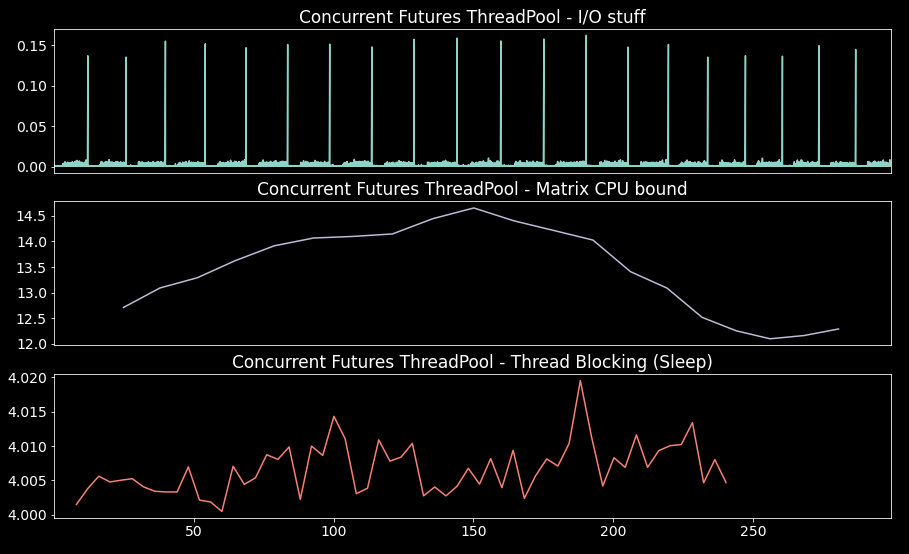
We see results similar to the ones obtained in the previous section; of course, this was to be expected; both use ThreadPoolExecutor.
Tune the number of threads in the thread pool according to your needs. Test what the optimum number is. A higher number of threads is not always better for some use cases as it introduces some overhead.
ThreadPool executors shine when dealing with I/O libraries which are not written in the async paradigm. Many database libraries in Python do not work with async yet. Using them in your async program will block the event loop; instead, use a ThreadPool executor to wrap them.
Concurrent.futures ProcessPool
Finally, we can use a separate process to run our blocking code. We do this by passing an instance of ProcessPoolExecutor from concurrent futures to the run_in_executor method:
We create our periodic wrapper again for the test, now using separate processes:
Run the test and plot the results:

We see that the glitches in the I/O
time logs are not as significant as in the previous cases. The blocking processes were executed concurrently as well.
Multiprocessing can be a good solution for some cases, especially for CPU-bound tasks (not thread sleeping jobs) that take longer. Creating multiple new processes and moving the data around is expensive. I.e., be sure that you are willing to pay the price of multiprocessing.
I/O-bound benchmarks
The following plot shows the time logs’ time differences (less is better) for the I/O dummy coroutine (before and after the task was completed) using the four approaches outlined in the past sections:
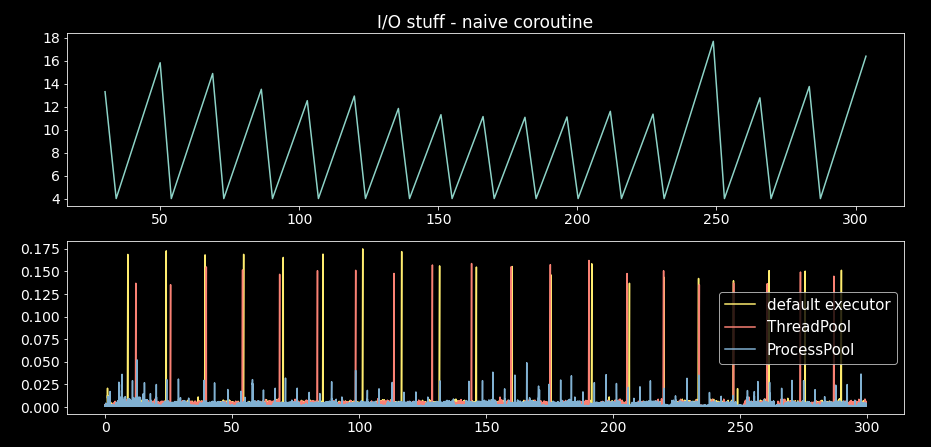
In all cases, we want these differences to be close to 1 millisecond since that is the theoretical value. Some inconsistencies are acceptable but not differences of over 4 seconds, as when we block the event loop. The thread pool results (default executor and ThreadPool with one worker) are not significantly different. However, the results for ProcessPool clearly show that this executor will incur the least disruption of the event loop.
CPU-bound benchmarks
The following plot shows the time taken (less is better) to complete the CPU-bound task for all approaches discussed earlier:

We can see that calling our blocking function naively yields the best results. It makes sense; the CPU-hungry task is executed at the expense of blocking everything else. Regarding the other three executors, their results are comparable; the ProcessPool took a bit longer. Moving data from the primary process to the forked process takes some time.
In any case, we can say that using an executor will not result in a drastic performance hit, and the event loop will be kept free of significant blockages. Conduct your performance tests to choose the right executor (and configuration). However, it is not a bad idea to start with the default executor and use it as a benchmark.
Moral of the story
So far, we have learned that blocking the event loop is the key thing we have to avoid when doing async programming. If you manage to keep the event loop without blockages, everything will be well; your MLOps and DevOps teammates will thank you.
The three key takeaways from the story are:
- do not call regular functions blindly from a coroutine (async def), as they may block the event loop
- use a ThreadPool executor for non-async I/O (non-async database libraries) or light CPU-bound computation
- use a ProcesPool executor for intensive CPU-hungry tasks; remember creating processes and moving data around is expensive, so it has to be worth it
CPU-hungry tasks or non-async I/O libraries may block the event loop of your program. Learn how to avoid this in Python.

Asynchronous programming has become the standard paradigm for API design and most services. The scope for a data scientist’s skill set has also evolved. Today is not enough to create good models or visualizations; in most cases, deploying them through an API or another service is also necessary. If you haven’t been dealing with async programming in your deployments, the odds are you will soon.
Just to be clear, this story is not another async tutorial. But instead, some insight into the common obstacles a data scientist may face when interfacing its tools with async frameworks. Namely, blocking the event loop with CPU-hungry tasks or non-async I/O libraries.
This story will explore how the event loop may get blocked and the resources we have to prevent it.
There are many good libraries in Python which handle async programming, but Asyncio got to be the library included as standard in Python; check out Trio, for example. Hence, in this story, we will focus on Asyncio.
Story Structure
- The event loop
- Test Setup
- Calling blocking functions naively
- Asyncio default executor
- Concurrent.futures ThreadPool
- Concurrent.futures ProcessPool
- I/O-bound benchmarks
- CPU-bound benchmarks
- Moral of the story
The event loop
Whether you use the Asyncio module or any other async library, they all use an event loop underneath. The event loop is a scheduler responsible for executing all coroutines (async functions) during the program’s lifespan.
This concurrency model is essentially a single while (loop) that takes the coroutines and cleverly runs them. Once a coroutine is executing, the await (yield) keyword yields back control to the event loop to run other coroutines. Hence, while the event loop waits for an I/O response, a future completion, or simply an async sleep, it can run other coroutines. The event loop keeps track of what should be returned to each coroutine and will return it to the corresponding coroutine in future iterations of the loop.
Now that we know how the event loop works, let’s think of what happens when we run CPU-intensive tasks in the event loop. Here is precisely where the discussion becomes relevant for data scientists. If we run a CPU-bound job in the event loop, the loop will run the task until it is completed, like any sequential and plain while loop you have ever used. That is a massive problem in async programming since all other tasks will have to wait until our CPU-hungry job is done.
There are three rules when it comes to event loops:
- you do not block the event loop
- you do not block the event loop
- you do not block the event loop
At first glance, blocking the event loop may not sound so bad. But think of this scenario. You are responsible for coding a module that will provide data analytics within a larger app (service) that exposes an API. The API is written in an async framework. If you wrap your CPU-bound functions in coroutines, you may end up crippling the whole app. All other tasks, like client handling, will be stopped until the CPU-hungry task is done.
The following sections will review ways to run event loop blocking tasks and study their performance.
Test Setup
We begin our event loop blocking test with two functions:
- a function that performs a CPU-bound task: a matrix multiplication using NumPy
- a function that sleeps the thread, i.e., some non-async I/O (for example, a non-async database library); yes,
time.sleepwill block the event loop
Let’s time (outside the event loop) our CPU-bound function with a square matrix of 7,000 elements per side so we know what to expect:
9.97 s ± 2.07 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
Then we create a function that simulates a periodic I/O task. This function runs a loop for durarion_secs and appends the current timestamp to a list (time_log) before the task begins (asyncio.sleep for sleep_secs) and after it is completed:
This function’s time log will be our data to assess whether other processes are blocking the event loop. Furthermore, we format the time logs so that we only keep the time differences before the task was executed and right after.
Using a sleep of 1 millisecond, this is how the time_log looks without any other function running in the event loop:
Calling blocking functions naively
The first approach we could take, naively, to create an async library is to wrap our blocking functions in a coroutine:
To test this approach, we wrap our functions, the CPU-bound and the thread blocking (time.sleep), inside a loop that executes the function periodically and appends to a time_log:
Now we run all tasks concurrently, the dummy_io_stuff , the CPU-intensive and thread sleep functions:
Note: In this code, I ran await coroutine outside a coroutine because I am using a Jupyter notebook, but the rule is that await should only be used inside coroutines (async def).
These are the results of the formated time logs:
As we can see from the I/O time log (first subplot), the event loop is blocked. We expect an average of a millisecond, and the time taken is more than 5 seconds in most iterations.
The other two plots show that the other tasks did not execute all the time during the test, instead competed for resources and blocked each other.
Asyncio default executor
The solution to avoid event loop blockage is executing our blocking code elsewhere. We can use threads or other processes to accomplish this. Asyncio has a very convenient loop method, run_in_executor. This method uses the concurrent.futures threading and multiprocessing interface. The default way to run our blocking functions is like so:
The first argument of run_in_executor is set to None (default executor), the second argument is the function we want to run in the executor, and the following arguments are the function’s arguments. This default executor is the ThreadPoolExecutor from concurrent.futures with the defaults.
Wrapping our functions, analogous to the previous section, and running the tasks concurrently:
The results of the formated time logs are:
We can see that there are still some minor glitches in the event loop (first plot), but the I/O time log shows a time difference of close to one millisecond. As per the blocking tasks themselves, they did execute concurrently.
Concurrent.futures ThreadPool
We can customize the ThreadPoolExecutor from the previous section by defining it explicitly and passing it to the run_in_executor method:
Using the ThreadPoolExecutorwith only one worker, we wrap our blocking functions to execute them periodically and keep a time log, analogous to the previous sections:
Running our tasks concurrently and plotting the formated time logs:
We see results similar to the ones obtained in the previous section; of course, this was to be expected; both use ThreadPoolExecutor.
Tune the number of threads in the thread pool according to your needs. Test what the optimum number is. A higher number of threads is not always better for some use cases as it introduces some overhead.
ThreadPool executors shine when dealing with I/O libraries which are not written in the async paradigm. Many database libraries in Python do not work with async yet. Using them in your async program will block the event loop; instead, use a ThreadPool executor to wrap them.
Concurrent.futures ProcessPool
Finally, we can use a separate process to run our blocking code. We do this by passing an instance of ProcessPoolExecutor from concurrent futures to the run_in_executor method:
We create our periodic wrapper again for the test, now using separate processes:
Run the test and plot the results:
We see that the glitches in the I/O
time logs are not as significant as in the previous cases. The blocking processes were executed concurrently as well.
Multiprocessing can be a good solution for some cases, especially for CPU-bound tasks (not thread sleeping jobs) that take longer. Creating multiple new processes and moving the data around is expensive. I.e., be sure that you are willing to pay the price of multiprocessing.
I/O-bound benchmarks
The following plot shows the time logs’ time differences (less is better) for the I/O dummy coroutine (before and after the task was completed) using the four approaches outlined in the past sections:
In all cases, we want these differences to be close to 1 millisecond since that is the theoretical value. Some inconsistencies are acceptable but not differences of over 4 seconds, as when we block the event loop. The thread pool results (default executor and ThreadPool with one worker) are not significantly different. However, the results for ProcessPool clearly show that this executor will incur the least disruption of the event loop.
CPU-bound benchmarks
The following plot shows the time taken (less is better) to complete the CPU-bound task for all approaches discussed earlier:
We can see that calling our blocking function naively yields the best results. It makes sense; the CPU-hungry task is executed at the expense of blocking everything else. Regarding the other three executors, their results are comparable; the ProcessPool took a bit longer. Moving data from the primary process to the forked process takes some time.
In any case, we can say that using an executor will not result in a drastic performance hit, and the event loop will be kept free of significant blockages. Conduct your performance tests to choose the right executor (and configuration). However, it is not a bad idea to start with the default executor and use it as a benchmark.
Moral of the story
So far, we have learned that blocking the event loop is the key thing we have to avoid when doing async programming. If you manage to keep the event loop without blockages, everything will be well; your MLOps and DevOps teammates will thank you.
The three key takeaways from the story are:
- do not call regular functions blindly from a coroutine (async def), as they may block the event loop
- use a ThreadPool executor for non-async I/O (non-async database libraries) or light CPU-bound computation
- use a ProcesPool executor for intensive CPU-hungry tasks; remember creating processes and moving data around is expensive, so it has to be worth it
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.