
Audio Diffusion: Generative Music’s Secret Sauce
Exploring the principles behind diffusion technology and how it is being used to create groundbreaking AI tools for artists and producers.
Much has been made of the hype of recent generative music AI algorithms. Some see it as the future of creativity and others see it as the death of music. While I tend to lean towards the former camp, as an engineer and researcher, I generally attempt to view these advancements through a more objective lens. With this in mind, I wanted to offer an introduction to one of the core technologies fueling the world of generative audio and music: Diffusion.
My goal is not to sell or diminish the hype, but rather shed some light on what is happening under the hood so that musicians, producers, hobbyists, and creators, can better understand these new seemingly magic music-making black boxes. I will answer what it means by the claim that these AI algorithms are “creating something completely new” and how that differs from human originality. I hope that a clearer picture will lower the collective temperature and provide insight into how these powerful technologies can be leveraged to the benefit of the creator.
This piece will touch on technical topics, but you do not need an engineering background to follow along. Let’s begin with some context and definitions.
Background
The term “AI-generated” has become pervasive across the music industry, but what qualifies as “AI-generated” is actually quite clouded. Eager to jump on the hype of the buzzword, this claim is casually tossed around whether AI is used to emulate an effect, automatically mix or master, separate stems, or augment timbre. As long as the final audio has been touched in some way by AI, the term gets slapped on the entire piece. However, the vast majority of music presently released continues to be primarily generated through human production (yes, even ghostwriter’s “Heart On My Sleeve” 👻).
Even though this “AI-generated” term is becoming hackneyed for clicks, an appropriate use is when new sounds truly are being created by a computer, i.e. Generative Audio.
Audio generation can encompass the creation of sound effects samples, melodies, vocals, and even full songs. The two main ways that this is achieved are via MIDI Generation and Audio Waveform Generation. MIDI (Musical Instrument Digital Interface) generation has a much lower computational cost and can provide high-quality outputs, as the generated MIDI data is then run through an existing virtual instrument to produce sounds. This is the same concept as a producer programming MIDI on a piano roll and playing it through a VST plugin such as Serum.
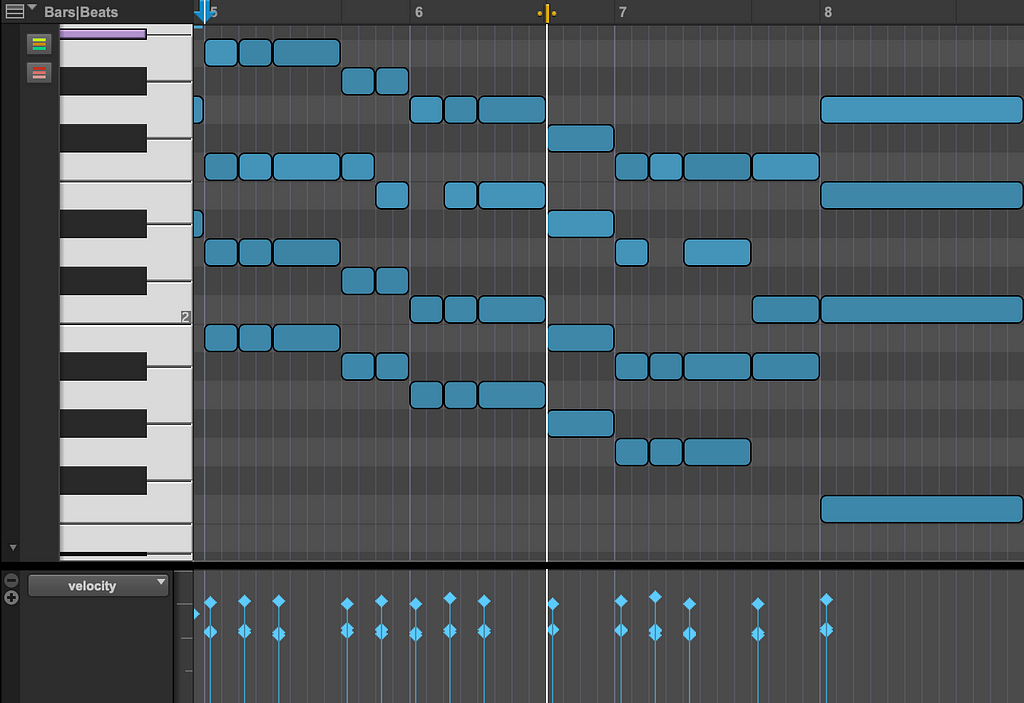
While this is compelling, it is only partially generative, as no audio is actually produced by AI, just as humans cannot synthesize instrument sounds from thin air. The creative capabilities are further limited by whatever virtual instruments the algorithm has access to. Even with these limitations, products implementing this technique, such as AIVA and Seeds by Lemonaide, can generate quite compelling outputs.
Audio waveform generation is a much more complicated task, as it is an end-to-end system that does not rely on any external technology. In other words, it produces sounds from scratch. This process most precisely aligns with the true definition of “AI-generated” audio.
Audio waveform generation can be accomplished using various approaches and yield different outcomes. It can produce single samples, such as Audialab’s ED 2 and Humanize or my previous work with Tiny Audio Diffusion, all the way up to full songs, with models such as AudioLM, Moûsai, Riffusion, MusicGen, and Stable Audio. Among these state-of-the-art models, many leverage some form of Diffusion to generate sounds. You have likely at least tangentially heard of diffusion from Stable Diffusion or any of the other top-performing image generation models that took the world by storm. This generative method can be applied to audio as well. But what does any of it actually mean?
What is Diffusion?
The Basics
In the context of AI, diffusion simply refers to the process of adding or removing noise from a signal (like static from an old TV). Forward Diffusion adds noise to a signal (Noising) and Reverse Diffusion removes noise (Denoising). At a conceptual level, diffusion models take white noise and step through the denoising processes until the audio resembles something recognizable, such as a sample or a song. This process of denoising a signal is the secret sauce in the creativity of many generative audio models.
This process was originally developed for images. Looking at how the noise resolves into an image (for instance, a puppy sitting next to a tennis ball) provides an even clearer example of how these models work.

With a conceptual understanding, let’s take a look under the hood at the key components of the architecture of an audio diffusion model. While this will veer into the technical side of things, stick with me, as a deeper understanding of how these algorithms work will better illustrate why and how they produce the results that they do (if not, you can always just ask ChatGPT for the Cliff Notes).
The U-Net Model Architecture, Compression, and Reconstruction
At the core of an audio diffusion model is the U-Net. Originally developed for medical image segmentation and aptly named for its resemblance to a U, the U-Net has been adapted to generative audio due to its powerful ability to capture both local and global features in data. The original U-Net was a 2-dimensional convolutional neural network (CNN) used for images, but can be adapted to 1-dimensional convolution to work with audio waveform data. See a visual representation of the original U-Net architecture (for images) below.
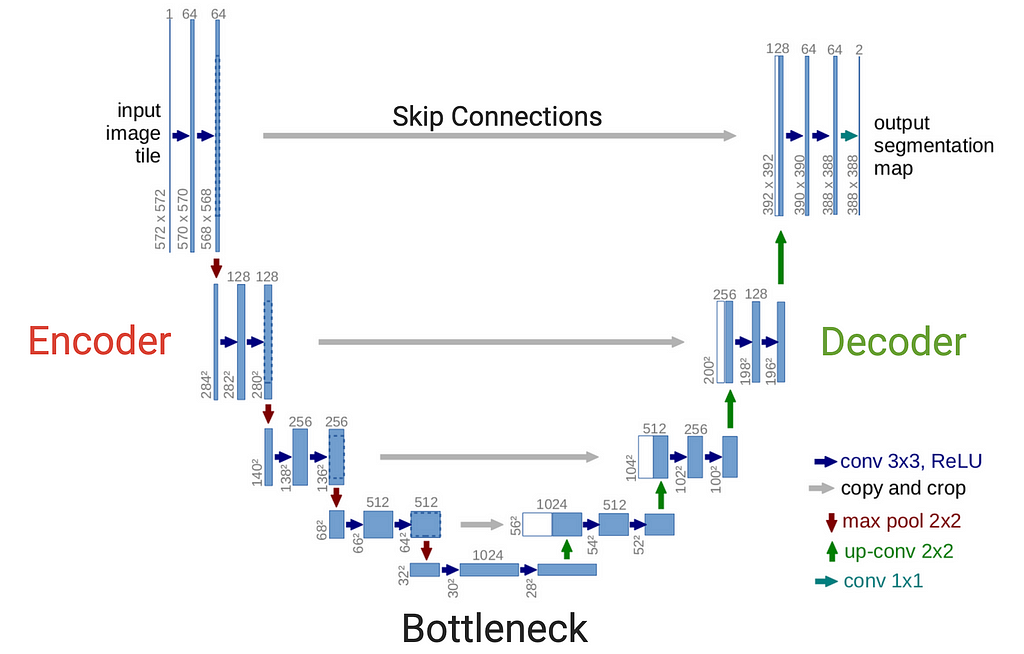
Similar to a Variational Autoencoder (VAE), A U-Net consists of an encoder (the left side of the U) and a decoder (the right side of the U), connected by a bottleneck (the bottom layer of the U). Unlike a VAE, however, a U-Net hosts skip connections (shown by the horizontal gray arrows) that link the encoder to the decoder which is the key piece to producing high-resolution outputs. The encoder is responsible for capturing the features, or characteristics, of the input audio signal while the decoder is responsible for the reconstruction of the signal.
To aid the visualization, picture the audio data entering the top left side of the U, following the red and blue arrows down the encoder to the bottleneck at the bottom, and then back up the decoder following the blue and green arrows to the top right of the U. Each blue rectangle represents a model layer. At each level of the encoder, the input audio signal is compressed further and further until it reaches a highly condensed representation of the sound at the base of the U (the bottleneck). The decoder then takes this compressed signal and effectively reverses the process to reconstruct the signal. Each layer (blue rectangle) the data passes through has a series of adjustable weights associated with it that can be thought of as millions of tiny knobs that can be turned to tweak this compression/reconstruction process. Having layers at different levels of compression allows the model to learn a range of features from the data, from large-scale features (e.g. melody and rhythm) to fine-grained details (e.g. high-frequency timbral characteristics).
Using an analogy, you can think of this full system as the process required to create an MP3 audio file and then listen to that MP3 on a playback device. At its core, an MP3 is a compressed version of an audio signal. Imagine that the encoder’s job is to create a new type of compressed audio format, just like an MP3, in order to consistently condense an audio signal as much as possible without losing fidelity. Then the decoder’s job is to act like your iPhone (or any playback device) and reconstruct the MP3 into a high-fidelity audio representation that can be played through your headphones. The bottleneck can be thought of as this newly created MP3-type format, itself. The U-Net represents the process of compression and reconstruction, not the audio data. The model can then be trained with the goal of being able to accurately compress and reconstruct a wide range of audio signals.
This is all well and good, but we haven’t generated anything yet. We’ve only constructed a way to compress and reconstruct an audio signal. However, this is the base process required to begin generating new audio, and it only requires a slight adjustment to do so.
Noising and Denoising
Let's revisit the idea of noising and denoising that we touched on earlier. Theoretically, we had some magic model that could be taught to take some white noise and “denoise” it into recognizable audio, perhaps a beautiful concerto. A critical requirement of this magic model is that it must be able to reconstruct the input audio signal at high fidelity. Luckily, the U-Net architecture is designed to do exactly that. So the next piece of the puzzle is to modify the U-Net to perform this denoising process.
Counter-intuitively, to teach a model to denoise an audio signal, it is first taught how to add noise to a signal. Once it has learned this process, it inherently knows how to perform the inverse in order to denoise a signal.
Recall in the previous section that we detailed how the U-Net can learn to compress and reconstruct an audio signal. The noising process follows nearly the same formula, but instead of reconstructing the exact input audio signal, the U-Net is directed to reconstruct the input audio signal with a small amount of noise added to it. This can be visualized as reversing the steps taken in the earlier series of images of the puppy.

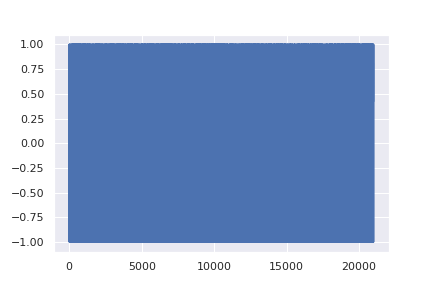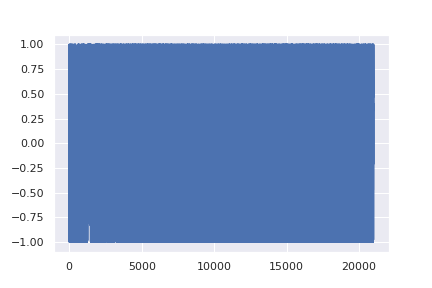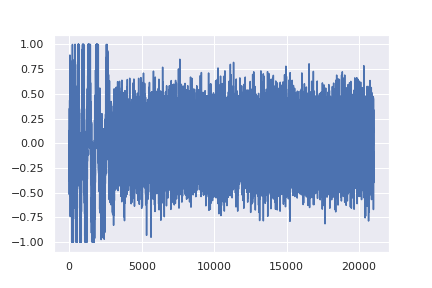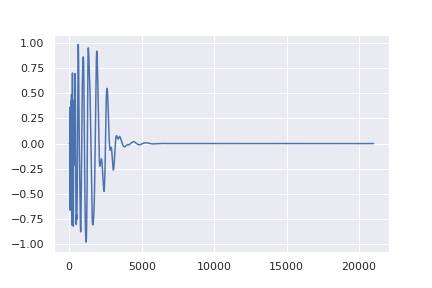
The process of adding noise to a signal must be probabilistic (i.e. predictable). The model is shown an audio signal and then instructed to predict the same signal with a small amount of Gaussian noise added to it. Because of its properties, Gaussian noise is most commonly used but it is not required. The noise must be defined by probabilistic distribution, meaning that it follows a specific pattern that is consistently predictable. This process of instructing the model to add small amounts of predictable noise to the audio signal is repeated for a number of steps until the signal has effectively become just noise.
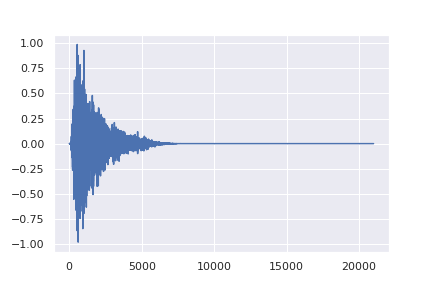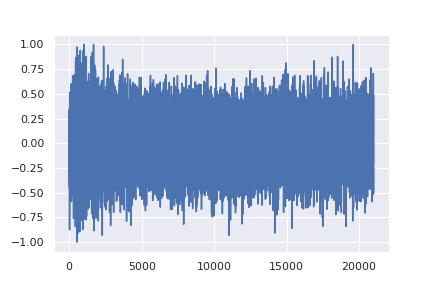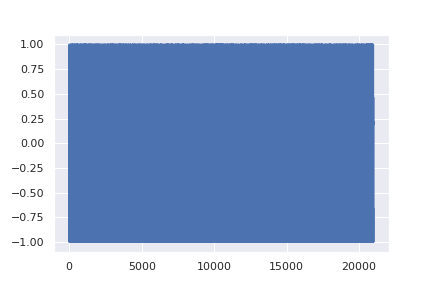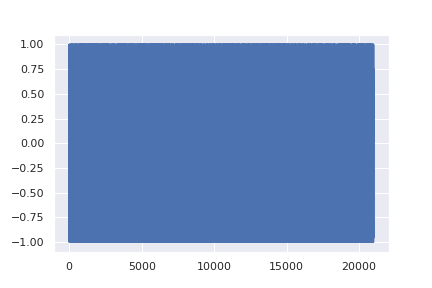
For example, let’s take a one-shot sample of a snare drum. The U-Net is provided this snare sample and it is asked to reconstruct that snare sound, but with a little noise added making it sound a little less clean. Then this slightly noisy snare sample is provided to the model, and it is again instructed to reconstruct this snare sample with even more noise. This cycle is repeated until it sounds as if the snare sample no longer exists, rather only white noise remains. The model is then taught how to do this for a wide range of sounds. Once it becomes an expert at predicting how to add noise to an input audio signal, because the process is probabilistic, it can simply be reversed so that at each step a little noise is removed. This is how the model can generate a snare sample when provided with white noise.
Because of the probabilistic nature of this process, some incredible capabilities arise, specifically the ability to simulate creativity.
Let’s continue with our snare example. Imagine the model was trained on thousands of one-shot snare samples. You would imagine that it could take some white noise and then turn it into any one of these snare samples. However, that is not exactly how the model learns. Because it is shown such a wide range of sounds, it instead learns to create sounds that are generally similar to any of the snares that it has been trained on, but not exactly. This is how brand new sounds are created and these models appear to exhibit a spark of creativity.
To illustrate this, let’s use the following sketch.
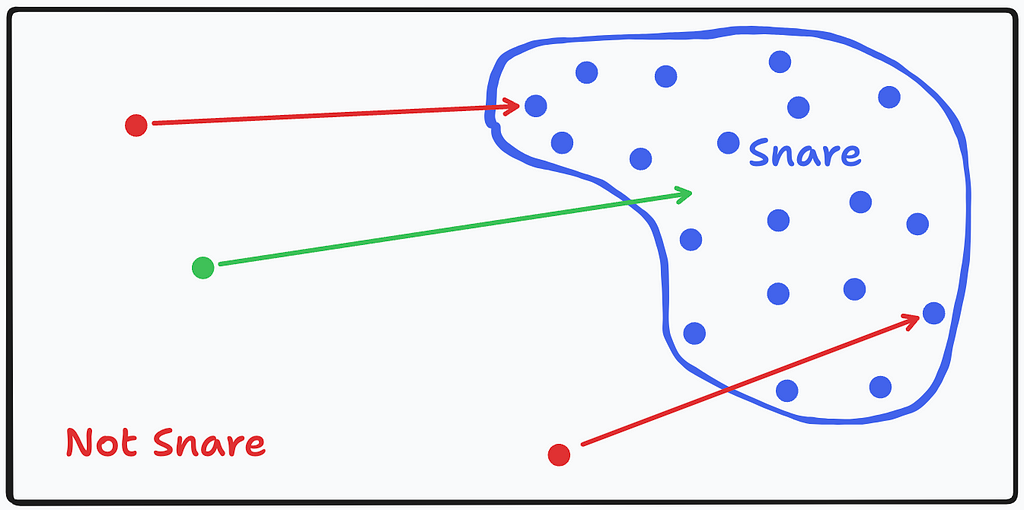
Pretend that all possible sounds, from guitar strums to dog barks to white noise, can be plotted on a 2-dimensional plane represented by the black rectangle in the image above. Within this space, there is a region where snare hits exist. They are somewhat grouped together because of their similar timbral and transient characteristics. This is shown by the blue blob and each blue dot is representative of a single snare sample that we trained our model on. The red dots represent the fully noised versions of the snares the model was trained on and correspond to their un-noised blue dot counterparts.
In essence, our model learned to take dots from the “not snare” region and bring them into the “snare” region. So if we take a new green dot in the “not snare” region (e.g. random noise) that does not correspond to any blue dot, and ask our model to bring it into the “snare” region, it will bring it to a new location within that “snare” region. This is the model generating a “new” snare sample that contains some similarities to all other snares it was trained on in the snare region, but also some new unknown characteristics.
This concept can be applied to any type of sound, including full songs. This is an incredible innovation that can lead to numerous new ways to create. It is important to understand that these models will not create something outside of the bounds of how they are trained, however. As shown in the previous illustration, while our conceptual model can take in any type of sound, it can only produce snare samples similar to those it was trained on. This holds true for any of these audio diffusion models. Because of this, it is critical to train models on extensive datasets so the known regions (like the snare region) are sufficiently diverse and large enough to not simply copy the training data.
All of this means that no model can replicate human creativity, just simulate variations of it.
Applications of Diffusion Models
These models will not magically generate new genres or explore unknown sonic landscapes as humans do. With this understanding, these generative models should not be viewed as a replacement for human creativity, but rather as tools that can enhance creativity. Below are just a few ways that this technology can be leveraged for creative means:
- Creativity Through Curation: Searching through sample packs to find a desired sound is a common practice in production. These models can effectively be used as a version of an “unlimited sample pack”, enhancing an artist’s creativity through the curation of sounds.
- Voice Transfer: Just like how diffusion models can take random noise and change it into recognizable audio, they can also be fed other sounds and “transfer” them to another type of sound. If we take our previous snare model, for example, and feed it a kick drum sample instead of white noise, it will take the kick sample and begin to morph it into a snare sound. This allows for very unique creations, being able to combine the characteristics of multiple different sounds.
- Sound Variability (Humanization): When humans play a live instrument, such as a hi-hat on a drum set, there is always inherent variability in each hit. Various virtual instruments have attempted to simulate this via a number of different methods, but can still sound artificial and lack character. Audio diffusion allows for the unlimited variation of a single sound, which can add a human element to an audio sample. For example, if you program a drum kit, audio diffusion can be leveraged so that each hit is slightly different in timbre, velocity, attack, etc. to humanize what might sound like a stale performance.
- Sound Design Adjustments: Similar to the human variability potential, this concept can also be applied to sound design to create slight changes to a sound. Perhaps you mostly like the sound of a door slam sample, but you wish that it had more body or crunch. A diffusion model can take this sample and slightly change it to maintain most of its characteristics while taking on a few new ones. This can add, remove, or change the spectral content of a sound at a more fundamental level than applying an EQ or filter.
- Melody Generation: Similar to surfing through sample packs, audio diffusion models can generate melodies that can spark ideas to build on.
- Stereo Effect: There are several different mixing tricks to add stereo width to a single-channel (mono) sound. However, they can often add undesired coloration, delay, or phase shifts. Audio diffusion can be leveraged to generate a sound nearly identical to the mono sound, but different enough in its content to expand the stereo width while avoiding many of the unwanted phenomena.
- Super Resolution: Audio diffusion models can enhance the resolution and quality of audio recordings, making them clearer and more detailed. This can be particularly useful in audio restoration or when working with low-quality recordings.
- Inpainting: Diffusion models can be leveraged to fill in missing or corrupted parts of audio signals, restoring them to their original or improved state. This is valuable for repairing damaged audio recordings, completing sections of audio that may be missing, or adding transitions between audio clips.
Conclusion
There is no doubt that these new generative AI models are incredible technological advancements, independent of whether they are viewed in a positive or negative light. There are many more aspects to diffusion models that can optimize their performance regarding speed, diversity, and quality, but we have discussed the base principles that govern the functionality of these models. This knowledge provides a deeper context into what it really means when these models are generating “new sounds”.
On a broader level, it is not only the music, itself, that people care about — it is the human element in the creation of that music. Ask yourself, if you were to hear a recording of a virtuosic lightning-fast guitar solo, would you be impressed? It all depends. If it was artificially generated by a virtual MIDI instrument programmed by a producer, you will likely be unphased and may not even like how it sounds. However, if you know an actual guitarist played the solo on a real guitar, or even saw him or her do it, you will be completely enamored by their expertise and precision. We are drawn to the deftness in a performance, the thoughts and emotions behind lyrics, and the considerations that go into each decision when crafting a song.
While these incredible advancements have led to some existential dread for artists and producers, AI can never take that human element away from the sounds and music that we create. So we should approach these new advancements with the intent that they are tools for enhancing artists’ creativity rather than replacing it.
All images, unless otherwise noted, are by the author.
I am an audio machine learning engineer and researcher as well as a lifelong musician. If you are interested in more audio AI applications, see my previously published articles on Tiny Audio Diffusion and Music Demixing.
Find me on LinkedIn & GitHub and keep up to date with my current work and research here: www.chrislandschoot.com
Find my music on Spotify, Apple Music, YouTube, SoundCloud, and other streaming platforms as After August.
Audio Diffusion: Generative Music’s Secret Sauce was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.

Exploring the principles behind diffusion technology and how it is being used to create groundbreaking AI tools for artists and producers.
Much has been made of the hype of recent generative music AI algorithms. Some see it as the future of creativity and others see it as the death of music. While I tend to lean towards the former camp, as an engineer and researcher, I generally attempt to view these advancements through a more objective lens. With this in mind, I wanted to offer an introduction to one of the core technologies fueling the world of generative audio and music: Diffusion.
My goal is not to sell or diminish the hype, but rather shed some light on what is happening under the hood so that musicians, producers, hobbyists, and creators, can better understand these new seemingly magic music-making black boxes. I will answer what it means by the claim that these AI algorithms are “creating something completely new” and how that differs from human originality. I hope that a clearer picture will lower the collective temperature and provide insight into how these powerful technologies can be leveraged to the benefit of the creator.
This piece will touch on technical topics, but you do not need an engineering background to follow along. Let’s begin with some context and definitions.
Background
The term “AI-generated” has become pervasive across the music industry, but what qualifies as “AI-generated” is actually quite clouded. Eager to jump on the hype of the buzzword, this claim is casually tossed around whether AI is used to emulate an effect, automatically mix or master, separate stems, or augment timbre. As long as the final audio has been touched in some way by AI, the term gets slapped on the entire piece. However, the vast majority of music presently released continues to be primarily generated through human production (yes, even ghostwriter’s “Heart On My Sleeve” 👻).
Even though this “AI-generated” term is becoming hackneyed for clicks, an appropriate use is when new sounds truly are being created by a computer, i.e. Generative Audio.
Audio generation can encompass the creation of sound effects samples, melodies, vocals, and even full songs. The two main ways that this is achieved are via MIDI Generation and Audio Waveform Generation. MIDI (Musical Instrument Digital Interface) generation has a much lower computational cost and can provide high-quality outputs, as the generated MIDI data is then run through an existing virtual instrument to produce sounds. This is the same concept as a producer programming MIDI on a piano roll and playing it through a VST plugin such as Serum.
While this is compelling, it is only partially generative, as no audio is actually produced by AI, just as humans cannot synthesize instrument sounds from thin air. The creative capabilities are further limited by whatever virtual instruments the algorithm has access to. Even with these limitations, products implementing this technique, such as AIVA and Seeds by Lemonaide, can generate quite compelling outputs.
Audio waveform generation is a much more complicated task, as it is an end-to-end system that does not rely on any external technology. In other words, it produces sounds from scratch. This process most precisely aligns with the true definition of “AI-generated” audio.
Audio waveform generation can be accomplished using various approaches and yield different outcomes. It can produce single samples, such as Audialab’s ED 2 and Humanize or my previous work with Tiny Audio Diffusion, all the way up to full songs, with models such as AudioLM, Moûsai, Riffusion, MusicGen, and Stable Audio. Among these state-of-the-art models, many leverage some form of Diffusion to generate sounds. You have likely at least tangentially heard of diffusion from Stable Diffusion or any of the other top-performing image generation models that took the world by storm. This generative method can be applied to audio as well. But what does any of it actually mean?
What is Diffusion?
The Basics
In the context of AI, diffusion simply refers to the process of adding or removing noise from a signal (like static from an old TV). Forward Diffusion adds noise to a signal (Noising) and Reverse Diffusion removes noise (Denoising). At a conceptual level, diffusion models take white noise and step through the denoising processes until the audio resembles something recognizable, such as a sample or a song. This process of denoising a signal is the secret sauce in the creativity of many generative audio models.
This process was originally developed for images. Looking at how the noise resolves into an image (for instance, a puppy sitting next to a tennis ball) provides an even clearer example of how these models work.
With a conceptual understanding, let’s take a look under the hood at the key components of the architecture of an audio diffusion model. While this will veer into the technical side of things, stick with me, as a deeper understanding of how these algorithms work will better illustrate why and how they produce the results that they do (if not, you can always just ask ChatGPT for the Cliff Notes).
The U-Net Model Architecture, Compression, and Reconstruction
At the core of an audio diffusion model is the U-Net. Originally developed for medical image segmentation and aptly named for its resemblance to a U, the U-Net has been adapted to generative audio due to its powerful ability to capture both local and global features in data. The original U-Net was a 2-dimensional convolutional neural network (CNN) used for images, but can be adapted to 1-dimensional convolution to work with audio waveform data. See a visual representation of the original U-Net architecture (for images) below.
Similar to a Variational Autoencoder (VAE), A U-Net consists of an encoder (the left side of the U) and a decoder (the right side of the U), connected by a bottleneck (the bottom layer of the U). Unlike a VAE, however, a U-Net hosts skip connections (shown by the horizontal gray arrows) that link the encoder to the decoder which is the key piece to producing high-resolution outputs. The encoder is responsible for capturing the features, or characteristics, of the input audio signal while the decoder is responsible for the reconstruction of the signal.
To aid the visualization, picture the audio data entering the top left side of the U, following the red and blue arrows down the encoder to the bottleneck at the bottom, and then back up the decoder following the blue and green arrows to the top right of the U. Each blue rectangle represents a model layer. At each level of the encoder, the input audio signal is compressed further and further until it reaches a highly condensed representation of the sound at the base of the U (the bottleneck). The decoder then takes this compressed signal and effectively reverses the process to reconstruct the signal. Each layer (blue rectangle) the data passes through has a series of adjustable weights associated with it that can be thought of as millions of tiny knobs that can be turned to tweak this compression/reconstruction process. Having layers at different levels of compression allows the model to learn a range of features from the data, from large-scale features (e.g. melody and rhythm) to fine-grained details (e.g. high-frequency timbral characteristics).
Using an analogy, you can think of this full system as the process required to create an MP3 audio file and then listen to that MP3 on a playback device. At its core, an MP3 is a compressed version of an audio signal. Imagine that the encoder’s job is to create a new type of compressed audio format, just like an MP3, in order to consistently condense an audio signal as much as possible without losing fidelity. Then the decoder’s job is to act like your iPhone (or any playback device) and reconstruct the MP3 into a high-fidelity audio representation that can be played through your headphones. The bottleneck can be thought of as this newly created MP3-type format, itself. The U-Net represents the process of compression and reconstruction, not the audio data. The model can then be trained with the goal of being able to accurately compress and reconstruct a wide range of audio signals.
This is all well and good, but we haven’t generated anything yet. We’ve only constructed a way to compress and reconstruct an audio signal. However, this is the base process required to begin generating new audio, and it only requires a slight adjustment to do so.
Noising and Denoising
Let's revisit the idea of noising and denoising that we touched on earlier. Theoretically, we had some magic model that could be taught to take some white noise and “denoise” it into recognizable audio, perhaps a beautiful concerto. A critical requirement of this magic model is that it must be able to reconstruct the input audio signal at high fidelity. Luckily, the U-Net architecture is designed to do exactly that. So the next piece of the puzzle is to modify the U-Net to perform this denoising process.
Counter-intuitively, to teach a model to denoise an audio signal, it is first taught how to add noise to a signal. Once it has learned this process, it inherently knows how to perform the inverse in order to denoise a signal.
Recall in the previous section that we detailed how the U-Net can learn to compress and reconstruct an audio signal. The noising process follows nearly the same formula, but instead of reconstructing the exact input audio signal, the U-Net is directed to reconstruct the input audio signal with a small amount of noise added to it. This can be visualized as reversing the steps taken in the earlier series of images of the puppy.
The process of adding noise to a signal must be probabilistic (i.e. predictable). The model is shown an audio signal and then instructed to predict the same signal with a small amount of Gaussian noise added to it. Because of its properties, Gaussian noise is most commonly used but it is not required. The noise must be defined by probabilistic distribution, meaning that it follows a specific pattern that is consistently predictable. This process of instructing the model to add small amounts of predictable noise to the audio signal is repeated for a number of steps until the signal has effectively become just noise.
For example, let’s take a one-shot sample of a snare drum. The U-Net is provided this snare sample and it is asked to reconstruct that snare sound, but with a little noise added making it sound a little less clean. Then this slightly noisy snare sample is provided to the model, and it is again instructed to reconstruct this snare sample with even more noise. This cycle is repeated until it sounds as if the snare sample no longer exists, rather only white noise remains. The model is then taught how to do this for a wide range of sounds. Once it becomes an expert at predicting how to add noise to an input audio signal, because the process is probabilistic, it can simply be reversed so that at each step a little noise is removed. This is how the model can generate a snare sample when provided with white noise.
Because of the probabilistic nature of this process, some incredible capabilities arise, specifically the ability to simulate creativity.
Let’s continue with our snare example. Imagine the model was trained on thousands of one-shot snare samples. You would imagine that it could take some white noise and then turn it into any one of these snare samples. However, that is not exactly how the model learns. Because it is shown such a wide range of sounds, it instead learns to create sounds that are generally similar to any of the snares that it has been trained on, but not exactly. This is how brand new sounds are created and these models appear to exhibit a spark of creativity.
To illustrate this, let’s use the following sketch.
Pretend that all possible sounds, from guitar strums to dog barks to white noise, can be plotted on a 2-dimensional plane represented by the black rectangle in the image above. Within this space, there is a region where snare hits exist. They are somewhat grouped together because of their similar timbral and transient characteristics. This is shown by the blue blob and each blue dot is representative of a single snare sample that we trained our model on. The red dots represent the fully noised versions of the snares the model was trained on and correspond to their un-noised blue dot counterparts.
In essence, our model learned to take dots from the “not snare” region and bring them into the “snare” region. So if we take a new green dot in the “not snare” region (e.g. random noise) that does not correspond to any blue dot, and ask our model to bring it into the “snare” region, it will bring it to a new location within that “snare” region. This is the model generating a “new” snare sample that contains some similarities to all other snares it was trained on in the snare region, but also some new unknown characteristics.
This concept can be applied to any type of sound, including full songs. This is an incredible innovation that can lead to numerous new ways to create. It is important to understand that these models will not create something outside of the bounds of how they are trained, however. As shown in the previous illustration, while our conceptual model can take in any type of sound, it can only produce snare samples similar to those it was trained on. This holds true for any of these audio diffusion models. Because of this, it is critical to train models on extensive datasets so the known regions (like the snare region) are sufficiently diverse and large enough to not simply copy the training data.
All of this means that no model can replicate human creativity, just simulate variations of it.
Applications of Diffusion Models
These models will not magically generate new genres or explore unknown sonic landscapes as humans do. With this understanding, these generative models should not be viewed as a replacement for human creativity, but rather as tools that can enhance creativity. Below are just a few ways that this technology can be leveraged for creative means:
- Creativity Through Curation: Searching through sample packs to find a desired sound is a common practice in production. These models can effectively be used as a version of an “unlimited sample pack”, enhancing an artist’s creativity through the curation of sounds.
- Voice Transfer: Just like how diffusion models can take random noise and change it into recognizable audio, they can also be fed other sounds and “transfer” them to another type of sound. If we take our previous snare model, for example, and feed it a kick drum sample instead of white noise, it will take the kick sample and begin to morph it into a snare sound. This allows for very unique creations, being able to combine the characteristics of multiple different sounds.
- Sound Variability (Humanization): When humans play a live instrument, such as a hi-hat on a drum set, there is always inherent variability in each hit. Various virtual instruments have attempted to simulate this via a number of different methods, but can still sound artificial and lack character. Audio diffusion allows for the unlimited variation of a single sound, which can add a human element to an audio sample. For example, if you program a drum kit, audio diffusion can be leveraged so that each hit is slightly different in timbre, velocity, attack, etc. to humanize what might sound like a stale performance.
- Sound Design Adjustments: Similar to the human variability potential, this concept can also be applied to sound design to create slight changes to a sound. Perhaps you mostly like the sound of a door slam sample, but you wish that it had more body or crunch. A diffusion model can take this sample and slightly change it to maintain most of its characteristics while taking on a few new ones. This can add, remove, or change the spectral content of a sound at a more fundamental level than applying an EQ or filter.
- Melody Generation: Similar to surfing through sample packs, audio diffusion models can generate melodies that can spark ideas to build on.
- Stereo Effect: There are several different mixing tricks to add stereo width to a single-channel (mono) sound. However, they can often add undesired coloration, delay, or phase shifts. Audio diffusion can be leveraged to generate a sound nearly identical to the mono sound, but different enough in its content to expand the stereo width while avoiding many of the unwanted phenomena.
- Super Resolution: Audio diffusion models can enhance the resolution and quality of audio recordings, making them clearer and more detailed. This can be particularly useful in audio restoration or when working with low-quality recordings.
- Inpainting: Diffusion models can be leveraged to fill in missing or corrupted parts of audio signals, restoring them to their original or improved state. This is valuable for repairing damaged audio recordings, completing sections of audio that may be missing, or adding transitions between audio clips.
Conclusion
There is no doubt that these new generative AI models are incredible technological advancements, independent of whether they are viewed in a positive or negative light. There are many more aspects to diffusion models that can optimize their performance regarding speed, diversity, and quality, but we have discussed the base principles that govern the functionality of these models. This knowledge provides a deeper context into what it really means when these models are generating “new sounds”.
On a broader level, it is not only the music, itself, that people care about — it is the human element in the creation of that music. Ask yourself, if you were to hear a recording of a virtuosic lightning-fast guitar solo, would you be impressed? It all depends. If it was artificially generated by a virtual MIDI instrument programmed by a producer, you will likely be unphased and may not even like how it sounds. However, if you know an actual guitarist played the solo on a real guitar, or even saw him or her do it, you will be completely enamored by their expertise and precision. We are drawn to the deftness in a performance, the thoughts and emotions behind lyrics, and the considerations that go into each decision when crafting a song.
While these incredible advancements have led to some existential dread for artists and producers, AI can never take that human element away from the sounds and music that we create. So we should approach these new advancements with the intent that they are tools for enhancing artists’ creativity rather than replacing it.
All images, unless otherwise noted, are by the author.
I am an audio machine learning engineer and researcher as well as a lifelong musician. If you are interested in more audio AI applications, see my previously published articles on Tiny Audio Diffusion and Music Demixing.
Find me on LinkedIn & GitHub and keep up to date with my current work and research here: www.chrislandschoot.com
Find my music on Spotify, Apple Music, YouTube, SoundCloud, and other streaming platforms as After August.
Audio Diffusion: Generative Music’s Secret Sauce was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.