
Build a (recipe) recommender chatbot using RAG and hybrid search (Part I)
This tutorial will teach you how to create sparse and dense embeddings and build a recommender system using hybrid search
This tutorial provides a step-by-step guide with code on how to create a chatbot-style recommender system. By the end, you will have built a recommender that uses the user’s open-text input to find matching items through a hybrid search on sparse and dense vectors. The dataset used in this tutorial contains recipes. However, you can easily replace the dataset with one that suits your needs with minimal adjustments. The first part of this task will focus on building the recommender system, which involves data cleaning, creating sparse and dense embeddings, uploading them to a vector database, and performing dense vector search and hybrid search. In the second part, you will create a chatbot that generates responses based on user input and recommendations, and a UI using a Plotly dashboard.
To follow this tutorial, you will need to set up accounts for paid services such as Vertex AI, OpenAI API, and Pinecone. Fortunately, most services offer free credits, and the costs associated with this tutorial should not exceed $5. Additionally, you can reduce costs further by using the files and datasets provided on my GitHub repository.
Data preparation
For this project, we will use recipes from Public Domain Recipes. All recipes are stored as markdown files in this GitHub repository. For this tutorial, I already did some data cleaning and created features from the raw text input. If you are keen on doing the data cleaning part yourself, the code is available on my GitHub repository.
The dataset consists of the following columns:
- title: the title of the recipe
- date: the date the recipe was added
- tags: a list of tags that describe the meal
- introduction: an introduction to the recipe, the content varies strongly between records
- ingredients: all needed ingredients. Note that I removed the quantity as it is not needed for creating embeddings and contrary may lead to undesirable recommendations.
- direction: all required steps you need to perform to cook the meal
- recipe_type: indicator if the recipe is vegan, vegetarian, or regular
- output: contains the title, ingredients, and direction of the recipe and will be later provided to the chat model as input.
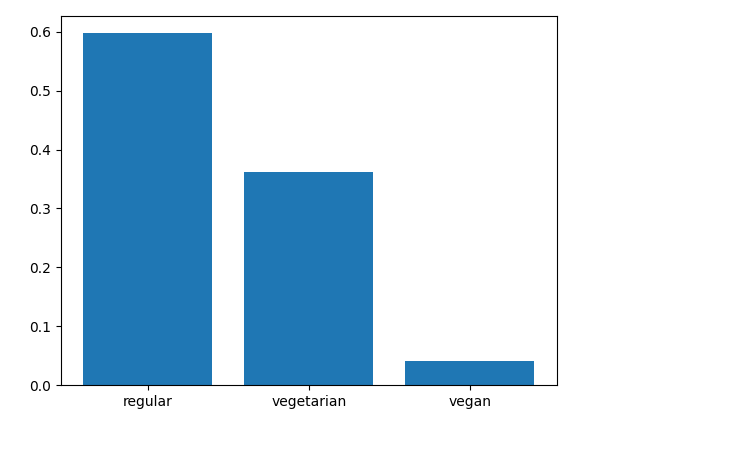
Let’s have a look at the distribution of the recipe_type feature. We see that the majority (60%) of the recipes include fish or meat and aren’t vegetarian-friendly. Approximately 35% are vegetarian-friendly and only 5% are vegan-friendly. This feature will be used as a hard filter for retrieving matching recipes from the vector database.
import re
import json
import spacy
import torch
import openai
import vertexai
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from transformers import AutoModelForMaskedLM, AutoTokenizer
from pinecone import Pinecone, ServerlessSpec
from vertexai.language_models import TextEmbeddingModel
from utils_google import authenticate
credentials, PROJECT_ID, service_account, pinecone_API_KEY = authenticate()
from utils_openai import authenticate
OPENAI_API_KEY = authenticate()
openai_client = openai.OpenAI(api_key=OPENAI_API_KEY)
REGION = "us-central1"
vertexai.init(project = PROJECT_ID,
location = REGION,
credentials = credentials)
pc = Pinecone(api_key=pinecone_API_KEY)
# download spacy model
#!python -m spacy download en_core_web_sm
recipes = pd.read_json("recipes_v2.json")
recipes.head()

plt.bar(recipes.recipe_type.unique(), recipes.recipe_type.value_counts(normalize=True).values)
plt.show()
Hybrid search uses a combination of sparse and dense vectors and a weighting factor alpha, which allows adjusting the importance of the dense vector in the retrieval process. In the following, we will create dense vectors based on the title, tags, and introduction and sparse vectors on the ingredients. By adjusting alpha we can therefore later on determine how much “attention” should be paid to ingredients the user mentioned in its query.
Before creating the embeddings a new feature needs to be created that contains the combined information of the title, the tags, and the introduction.
recipes["dense_feature"] = recipes.title + "; " + recipes.tags.apply(lambda x: str(x).strip("[]").replace("'", "")) + "; " + recipes.introduction
recipes["dense_feature"].head()

Finally, before diving deeper into the generation of the embeddings we’ll have a look at the output column. The second part of the tutorial will be all about creating a chatbot using OpenAI that is able to answer user questions using knowledge from our recipe database. Therefore, after finding the recipes that match best the user query the chat model needs some information it builds its answer on. That’s where the output is used, as it contains all the needed information for an adequate answer
# example output
{'title': 'Creamy Mashed Potatoes',
'ingredients': 'The quantities here are for about four adult portions. If you are planning on eating this as a side dish, it might be more like 6-8 portions. * 1kg potatoes * 200ml milk* * 200ml mayonnaise* * ~100g cheese * Garlic powder * 12-16 strips of bacon * Butter * 3-4 green onions * Black pepper * Salt *You can play with the proportions depending on how creamy or dry you want the mashed potatoes to be.',
'direction': '1. Peel and cut the potatoes into medium sized pieces. 2. Put the potatoes in a pot with some water so that it covers the potatoes and boil them for about 20-30 minutes, or until the potatoes are soft. 3. About ten minutes before removing the potatoes from the boiling water, cut the bacon into little pieces and fry it. 4. Warm up the milk and mayonnaise. 5. Shred the cheese. 6. When the potatoes are done, remove all water from the pot, add the warm milk and mayonnaise mix, add some butter, and mash with a potato masher or a blender. 7. Add some salt, black pepper and garlic powder to taste and continue mashing the mix. 8. Once the mix is somewhat homogeneous and the potatoes are properly mashed, add the shredded cheese and fried bacon and mix a little. 9. Serve and top with chopped green onions.'}
Further, a unique identifier needs to be added to each recipe, which allows retrieving the records of the recommended candidate recipes and their output.
recipes["ID"] = range(len(recipes))
Generate sparse embeddings
The next step involves creating sparse embeddings for all 360 observations. To calculate these embeddings, a more sophisticated method than the frequently used TF-IDF or BM25 approach is used. Instead, the SPLADE Sparse Lexical and Expansion model is applied. A detailed explanation of SPLADE can be found here. Dense embeddings have the same shape for each text input, regardless of the number of tokens in the input. In contrast, sparse embeddings contain a weight for each unique token in the input. The dictionary below represents a sparse vector, where the token ID is the key and the assigned weight is the value.
model_id = "naver/splade-cocondenser-ensembledistil"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
def to_sparse_vector(text, tokenizer, model):
tokens = tokenizer(text, return_tensors='pt')
output = model(**tokens)
vec = torch.max(
torch.log(1 + torch.relu(output.logits)) * tokens.attention_mask.unsqueeze(-1), dim=1
)[0].squeeze()
cols = vec.nonzero().squeeze().cpu().tolist()
weights = vec[cols].cpu().tolist()
sparse_dict = dict(zip(cols, weights))
return sparse_dict
sparse_vectors = []
for i in tqdm(range(len(recipes))):
sparse_vectors.append(to_sparse_vector(recipes.iloc[i]["ingredients"], tokenizer, model))
recipes["sparse_vectors"] = sparse_vectors

Generating dense embeddings
At this point of the tutorial, some costs will arise if you use a text embedding model from VertexAI (Google) or OpenAI. However, if you use the same dataset, the costs will be at most $5. The cost may vary if you use a dataset with more records or longer texts, as you are charged by tokens. If you do not wish to incur any costs but still want to follow the tutorial, particularly the second part, you can download the pandas DataFrame recipes_with_vectors.pkl with pre-generated embedding data from my GitHub repository.
You can choose to use either VertexAI or OpenAI to create the embeddings. OpenAI has the advantage of being easy to set up with an API key, while VertexAI requires logging into Google Console, creating a project, and adding the VertexAI API to your project. Additionally, the OpenAI model allows you to specify the number of dimensions for the dense vector. Nevertheless, both of them create state-of-the-art dense embeddings.
Using VertexAI API
# running this code will create costs !!!
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@003")
def to_dense_vector(text, model):
dense_vectors = model.get_embeddings([text])
return [dense_vector.values for dense_vector in dense_vectors][0]
dense_vectors = []
for i in tqdm(range(len(recipes))):
dense_vectors.append(to_dense_vector(recipes.iloc[i]["dense_feature"], model))
recipes["dense_vectors"] = dense_vectors
Using OpenAI API
# running this code will create costs !!!
# Create dense embeddings using OpenAIs text embedding model with 768 dimensions
model = "text-embedding-3-small"
def to_dense_vector_openAI(text, client, model, dimensions):
dense_vectors = client.embeddings.create(model=model, dimensions=dimensions, input=[text])
return [dense_vector.values for dense_vector in dense_vectors][0]
dense_vectors = []
for i in tqdm(range(len(recipes))):
dense_vectors.append(to_dense_vector_openAI(recipes.iloc[i]["dense_feature"], openai_client, model, 768))
recipes["dense_vectors"] = dense_vectors
Upload data to vector database
After generating the sparse and dense embeddings, we have all the necessary data to upload them to a vector database. In this tutorial, Pinecone will be used as they allow performing a hybrid search using sparse and dense vectors and offer a serverless pricing schema with $100 free credits. To perform a hybrid search later on, the similarity metric needs to be set to dot product. If we would only perform a dense instead of a hybrid search we would be able to select one of these similarity metrics: dot product, cosine, and Euclidean distance. More information about similarity metrics and how they calculate the similarity between two vectors can be found here.
# load pandas DataFrame with pre-generated embeddings if you
# didn't generate them in the last step
recipes = pd.read_pickle("recipes_with_vectors.pkl")
# if you need to delte an existing index
pc.delete_index("index-name")
# create a new index
pc.create_index(
name="recipe-project",
dimension=768, # adjust if needed
metric="dotproduct",
spec=ServerlessSpec(
cloud="aws",
region="us-west-2"
)
)
pc.describe_index("recipe-project")

Congratulations on creating your first Pinecone index! Now, it’s time to upload the embedded data to the vector database. If the embedding model you used creates vectors with a different number of dimensions, make sure to adjust the dimension argument.
Now it’s time to upload the data to the newly created Pinecone index.
# upsert to pinecone in batches
def sparse_to_dict(data):
dict_ = {"indices": list(data.keys()),
"values": list(data.values())}
return dict_
batch_size = 100
index = pc.Index("recipe-project")
for i in tqdm(range(0, len(recipes), batch_size)):
i_end = min(i + batch_size, len(recipes))
meta_batch = recipes.iloc[i: i_end][["ID", "recipe_type"]]
meta_dict = meta_batch.to_dict(orient="records")
sparse_batch = recipes.iloc[i: i_end]["sparse_vectors"].apply(lambda x: sparse_to_dict(x))
dense_batch = recipes.iloc[i: i_end]["dense_vectors"]
upserts = []
ids = [str(x) for x in range(i, i_end)]
for id_, meta, sparse_, dense_ in zip(ids, meta_dict, sparse_batch, dense_batch):
upserts.append({
"id": id_,
"sparse_values": sparse_,
"values": dense_,
"metadata": meta
})
index.upsert(upserts)
index.describe_index_stats()
If you are curious about what the uploaded data looks like, log in to Pinecone, select the newly created index, and have a look at its items. For now, we don’t need to pay attention to the score, as it is generated by default and indicates the match with a vector randomly generated by Pinecone. However, later we will calculate the similarity of the embedded user query with all items in the vector database and retrieve the k most similar items. Further, each item contains an item ID generated by Pinecone, and the metadata, which consists of the recipe ID and its recipe_type. The dense embeddings are stored in Values and the sparse embeddings in Sparse Values.
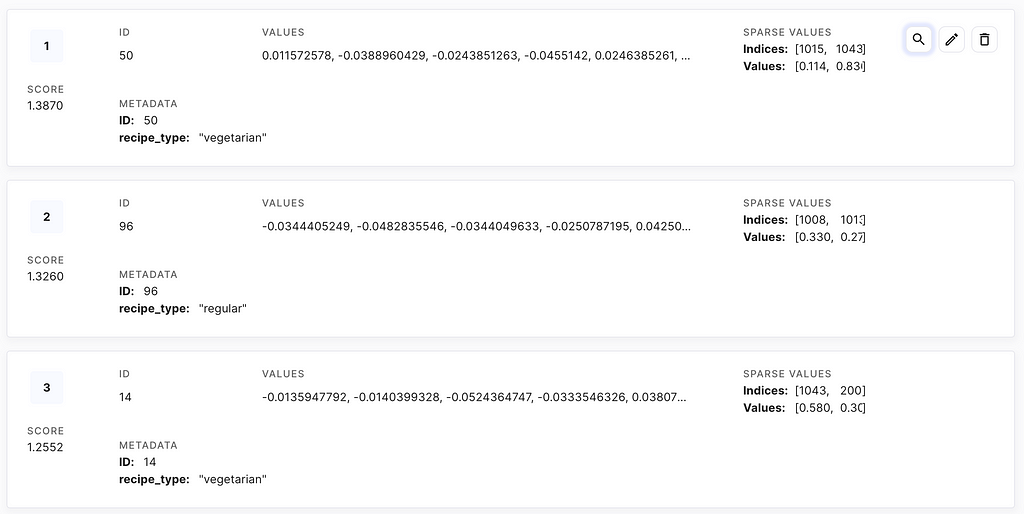
We can fetch the information from above using the Pinecone Python SDK. Let’s have a look at the stored information of the first item with the index item ID 50.
index.fetch(ids=["50"])

As in the Pinecone dashboard, we get the item ID of the element, its metadata, the sparse values, and the dense values, which are stored in the list at the bottom of the truncated output.
Search
In this section, we will solely use dense vectors to find the best-matching entries in our database (dense search). In the second step, we will utilize the information stored in both the sparse and dense vectors to perform a hybrid search.
Regular search using dense vectors
To test the functionality of our recommender system, we will attempt to obtain recommendations for a vegetarian Italian dish. It is important to note that the same model must be used to generate the dense embeddings as the one used to embed the recipes.
user_query = "I want to cook some Italian dish with rice"
recipe_type = "vegetarian"
# running this code will create costs !!!
# If you used VertexAI and gecko003 to create dense embeddings
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@003")
def to_dense_vector(text, model):
dense_vectors = model.get_embeddings([text])
return [dense_vector.values for dense_vector in dense_vectors][0]
text_dense_vector = to_dense_vector(user_query, model)
Using OpenAI API
# running this code will create costs !!!
# If you used OpenAI to create dense embeddings
model = "text-embedding-3-small"
def to_dense_vector_openAI(text, client, model, dimensions):
dense_vectors = client.embeddings.create(model=model, dimensions=dimensions, input=[text])
return [dense_vector.values for dense_vector in dense_vectors][0]
text_dense_vector = to_dense_vector_openAI(user_query, openai_client, model, 768)
After embedding the user text, we can query the vector database for the recipes that resemble the user query the most. As previously defined Pinecone uses the dot product to calculate the similarity score. Further, we specify that Piencone should return the metadata of the recommended items, as we need the ID of the recipe to filter the recipes database and get the output of the corresponding items. The parameter top_k allows us to specify the number of matches that should be returned and lastly, we specify with a hard filter to only recommend coffee blends that cost equal to or less than the indicated price (10.0). More information on how the filtering of metadata works in Pinecone can be found here.
index = pc.Index("recipe-project")
retrieved_items = index.query(vector=text_dense_vector,
include_values=False,
include_metadata=True,
top_k=3,
filter={"recipe_type": {"$eq": recipe_type}})
retrieved_ids = [item.get("metadata").get("ID") for item in retrieved_items.get("matches")]
retrieved_items

After obtaining the IDs of the recommended recipes we can easily query the recipes dataset for them and have a look at their output. The output contains all the needed information as the title, the ingredients, and the directions. A look at the first recommendations reveals that they are all vegetarian, this is not surprising as we applied a “hard” filter, but they are all Italian dishes as requested by the user.
recipes[recipes.ID.isin(retrieved_ids)].output.values

recipes[recipes.ID.isin(retrieved_ids)].output.values[0]
{'title': 'Pasta Arrabbiata',
'ingredients': '- Pasta - Olive oil - Chilli flakes or diced chilli peppers - Crushed garlic cloves - Crushed tomatoes (about 800 gramms for 500 gramms of pasta) - Chopped parsley - Grated Pecorino Romano or Parmigiano Reggiano (optional, but highly recommended)',
'direction': '1. Start heating up water for the pasta. 2. Heat up a few tablespoons of olive oil over low heat. 3. Crush several cloves of garlic into the olive oil, add the chilli flakes or chilli peppers and fry them for a short time, while being careful not to burn the garlic. 4. Add your crushed tomatoes, together with some salt and pepper, increase the heat to medium and let simmer for 10-15 minutes or until it looks nicely thickened. 5. When the water starts boiling, put a handful of salt into it and then your pasta of choice. Ideally leave the pasta slightly undercooked, because it will go in the hot sauce and finish cooking there. 6. When the sauce is almost ready, add most of your chopped parsley and stir it around. Save some to top the dish later. 8. When the pasta is ready (ideally at the same time as the sauce or slightly later), strain it and add it to the sauce, which should be off the heat. If the sauce looks a bit too thick, add some of the pasta water. Mix well. 9. Add some of the grated cheese of your choice and stir it in. 10. Serve with some more grated cheese and chopped parsley on top.'}
Hybrid Search
Now it’s time to implement hybrid search. The concept sounds fancier than it is and you will realize it when we implement it in just two lines of code. Hybrid search weights the values of the dense vector by a factor alpha and the values of the sparse vector by 1-alpha. In other words, alpha determines how much “attention” should be paid to the dense respectively the sparse embeddings of the input text. If alpha=1 we perform a pure dense vector search, alpha=0.5 is a pure hybrid search, and alpha=0 is a pure sparse vector search.
As you remember the sparse and dense vectors were created using different information. Whereas the sparse vector contains information about the ingredients, the dense vector incorporates the title, tags, and introduction. Therefore, by changing alpha we can tell the query engine to prioritize some features of the recipes more than others. Let’s use an alpha of 1 first and run a pure dense search on the user query:
What can I cook with potatos, mushrooms, and beef?
Unfortunately, besides beef, the recommended recipe doesn’t contain any of the other mentioned ingredients.
Generate sparse embeddings
model_id = "naver/splade-cocondenser-ensembledistil"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
def to_sparse_vector(text, tokenizer, model):
tokens = tokenizer(text, return_tensors='pt')
output = model(**tokens)
vec = torch.max(
torch.log(1 + torch.relu(output.logits)) * tokens.attention_mask.unsqueeze(-1), dim=1
)[0].squeeze()
cols = vec.nonzero().squeeze().cpu().tolist()
weights = vec[cols].cpu().tolist()
sparse_dict = dict(zip(cols, weights))
return sparse_dict
text_sparse_vector = to_sparse_vector(user_query, tokenizer, model)
Generate dense embeddings
# running this code will create costs !!!
# If you used VertexAI and gecko003 to create dense embeddings
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@003")
text_dense_vector = to_dense_vector(user_query, model)
def hybride_search(sparse_dict, dense_vectors, alpha):
# check alpha value is in range
if alpha < 0 or alpha > 1:
raise ValueError("Alpha must be between 0 and 1")
# scale sparse and dense vectors to create hybrid search vecs
hsparse = {
"indices": list(sparse_dict.keys()),
"values": [v * (1 - alpha) for v in list(sparse_dict.values())]
}
hdense = [v * alpha for v in dense_vectors]
return hdense, hsparse
user_query = "What can I cook with potatos, mushrooms, and beef?"
recipe_type = ["regular", "vegetarian", "vegan"] # allows for all recipe types
dense_vector, sparse_dict = hybride_search(text_sparse_vector, text_dense_vector, 1.0)
retrieved_items = index.query(vector=dense_vector,
sparse_vector=sparse_dict,
include_values=False,
include_metadata=True,
top_k=1,
filter={"recipe_type": {"$in": recipe_type}})
retrieved_ids = [item.get("metadata").get("ID") for item in retrieved_items.get("matches")]
[x.get("ingredients") for x in recipes[recipes.ID.isin(retrieved_ids)].output.values]
# retrived output with alpha=1.0
['- 1 beef kidney - 60g butter - 2 onions - 2 shallots - 1 sprig of fresh parsley - 3 bay leaves - 400g croutons or toasted bread in pieces']
Let’s set alpha to 0.5 and have a look at the ingredients of the recommended recipe. This alpha score leads to a much better result and the recommended recipe contains all three asked ingredients:
- 500g beef
- 300–400g potatoes
- 2–3 champignon mushrooms
dense_vector, sparse_dict = hybride_search(text_sparse_vector, text_dense_vector, 0.5)
retrieved_items = index.query(vector=dense_vector,
sparse_vector=sparse_dict,
include_values=False,
include_metadata=True,
top_k=1,
filter={"recipe_type": {"$in": recipe_type}})
retrieved_ids = [item.get("metadata").get("ID") for item in retrieved_items.get("matches")]
[x.get("ingredients") for x in recipes[recipes.ID.isin(retrieved_ids)].output.values]
# retrived output with alpha=0.5
['* 500g beef * 300-400g potatoes * 1 carrot * 1 medium onion * 12 tablespoons tomato paste * 500ml water * 3-4 garlic cloves * 3-4 bay leaves * Curcuma * Paprika * Oregano * Parsley * Caraway * Basil (optional) * Cilantro (optional) * 2-3 champignon mushrooms (optional)']Using a serverless index has the advantage that you do not need to pay for a server instance that runs 24/7. Instead, you are billed by queries or read and write units, as they are called by Pinecone. Sparse and dense vector searches work well with a serverless index. However, please keep in mind the following limitation.
Congratulations, you made it to the end of this tutorial!
Final remarks
The implementation of hybrid search is meaningfully different between pod-based and serverless indexes. If you switch from one to the other, you may experience a regression in accuracy or performance.
When you query a serverless index, the dense value of the query is used to retrieve the initial candidate records, and then the sparse value is considered when returning the final results.
Conclusion
In this tutorial, you have learned how to embed a dataset using sparse and dense embeddings and use dense and hybrid search to find the closest matching entries in a vector database.
In the second part, you will build a chatbot using a GPT 3.5-turbo model with function calling and generate a UI using Plotly Dash. Have a look at it if you’re curious and enjoyed the first part.
Please support my work!
If you liked this blog post, please leave a clap or comment. To stay tuned follow me on Medium and LinkedIn.
Build a (recipe) recommender chatbot using RAG and hybrid search (Part I) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
This tutorial will teach you how to create sparse and dense embeddings and build a recommender system using hybrid search

This tutorial provides a step-by-step guide with code on how to create a chatbot-style recommender system. By the end, you will have built a recommender that uses the user’s open-text input to find matching items through a hybrid search on sparse and dense vectors. The dataset used in this tutorial contains recipes. However, you can easily replace the dataset with one that suits your needs with minimal adjustments. The first part of this task will focus on building the recommender system, which involves data cleaning, creating sparse and dense embeddings, uploading them to a vector database, and performing dense vector search and hybrid search. In the second part, you will create a chatbot that generates responses based on user input and recommendations, and a UI using a Plotly dashboard.
To follow this tutorial, you will need to set up accounts for paid services such as Vertex AI, OpenAI API, and Pinecone. Fortunately, most services offer free credits, and the costs associated with this tutorial should not exceed $5. Additionally, you can reduce costs further by using the files and datasets provided on my GitHub repository.
Data preparation
For this project, we will use recipes from Public Domain Recipes. All recipes are stored as markdown files in this GitHub repository. For this tutorial, I already did some data cleaning and created features from the raw text input. If you are keen on doing the data cleaning part yourself, the code is available on my GitHub repository.
The dataset consists of the following columns:
- title: the title of the recipe
- date: the date the recipe was added
- tags: a list of tags that describe the meal
- introduction: an introduction to the recipe, the content varies strongly between records
- ingredients: all needed ingredients. Note that I removed the quantity as it is not needed for creating embeddings and contrary may lead to undesirable recommendations.
- direction: all required steps you need to perform to cook the meal
- recipe_type: indicator if the recipe is vegan, vegetarian, or regular
- output: contains the title, ingredients, and direction of the recipe and will be later provided to the chat model as input.
Let’s have a look at the distribution of the recipe_type feature. We see that the majority (60%) of the recipes include fish or meat and aren’t vegetarian-friendly. Approximately 35% are vegetarian-friendly and only 5% are vegan-friendly. This feature will be used as a hard filter for retrieving matching recipes from the vector database.
import re
import json
import spacy
import torch
import openai
import vertexai
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from transformers import AutoModelForMaskedLM, AutoTokenizer
from pinecone import Pinecone, ServerlessSpec
from vertexai.language_models import TextEmbeddingModel
from utils_google import authenticate
credentials, PROJECT_ID, service_account, pinecone_API_KEY = authenticate()
from utils_openai import authenticate
OPENAI_API_KEY = authenticate()
openai_client = openai.OpenAI(api_key=OPENAI_API_KEY)
REGION = "us-central1"
vertexai.init(project = PROJECT_ID,
location = REGION,
credentials = credentials)
pc = Pinecone(api_key=pinecone_API_KEY)
# download spacy model
#!python -m spacy download en_core_web_sm
recipes = pd.read_json("recipes_v2.json")
recipes.head()
plt.bar(recipes.recipe_type.unique(), recipes.recipe_type.value_counts(normalize=True).values)
plt.show()
Hybrid search uses a combination of sparse and dense vectors and a weighting factor alpha, which allows adjusting the importance of the dense vector in the retrieval process. In the following, we will create dense vectors based on the title, tags, and introduction and sparse vectors on the ingredients. By adjusting alpha we can therefore later on determine how much “attention” should be paid to ingredients the user mentioned in its query.
Before creating the embeddings a new feature needs to be created that contains the combined information of the title, the tags, and the introduction.
recipes["dense_feature"] = recipes.title + "; " + recipes.tags.apply(lambda x: str(x).strip("[]").replace("'", "")) + "; " + recipes.introduction
recipes["dense_feature"].head()
Finally, before diving deeper into the generation of the embeddings we’ll have a look at the output column. The second part of the tutorial will be all about creating a chatbot using OpenAI that is able to answer user questions using knowledge from our recipe database. Therefore, after finding the recipes that match best the user query the chat model needs some information it builds its answer on. That’s where the output is used, as it contains all the needed information for an adequate answer
# example output
{'title': 'Creamy Mashed Potatoes',
'ingredients': 'The quantities here are for about four adult portions. If you are planning on eating this as a side dish, it might be more like 6-8 portions. * 1kg potatoes * 200ml milk* * 200ml mayonnaise* * ~100g cheese * Garlic powder * 12-16 strips of bacon * Butter * 3-4 green onions * Black pepper * Salt *You can play with the proportions depending on how creamy or dry you want the mashed potatoes to be.',
'direction': '1. Peel and cut the potatoes into medium sized pieces. 2. Put the potatoes in a pot with some water so that it covers the potatoes and boil them for about 20-30 minutes, or until the potatoes are soft. 3. About ten minutes before removing the potatoes from the boiling water, cut the bacon into little pieces and fry it. 4. Warm up the milk and mayonnaise. 5. Shred the cheese. 6. When the potatoes are done, remove all water from the pot, add the warm milk and mayonnaise mix, add some butter, and mash with a potato masher or a blender. 7. Add some salt, black pepper and garlic powder to taste and continue mashing the mix. 8. Once the mix is somewhat homogeneous and the potatoes are properly mashed, add the shredded cheese and fried bacon and mix a little. 9. Serve and top with chopped green onions.'}
Further, a unique identifier needs to be added to each recipe, which allows retrieving the records of the recommended candidate recipes and their output.
recipes["ID"] = range(len(recipes))
Generate sparse embeddings
The next step involves creating sparse embeddings for all 360 observations. To calculate these embeddings, a more sophisticated method than the frequently used TF-IDF or BM25 approach is used. Instead, the SPLADE Sparse Lexical and Expansion model is applied. A detailed explanation of SPLADE can be found here. Dense embeddings have the same shape for each text input, regardless of the number of tokens in the input. In contrast, sparse embeddings contain a weight for each unique token in the input. The dictionary below represents a sparse vector, where the token ID is the key and the assigned weight is the value.
model_id = "naver/splade-cocondenser-ensembledistil"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
def to_sparse_vector(text, tokenizer, model):
tokens = tokenizer(text, return_tensors='pt')
output = model(**tokens)
vec = torch.max(
torch.log(1 + torch.relu(output.logits)) * tokens.attention_mask.unsqueeze(-1), dim=1
)[0].squeeze()
cols = vec.nonzero().squeeze().cpu().tolist()
weights = vec[cols].cpu().tolist()
sparse_dict = dict(zip(cols, weights))
return sparse_dict
sparse_vectors = []
for i in tqdm(range(len(recipes))):
sparse_vectors.append(to_sparse_vector(recipes.iloc[i]["ingredients"], tokenizer, model))
recipes["sparse_vectors"] = sparse_vectors
Generating dense embeddings
At this point of the tutorial, some costs will arise if you use a text embedding model from VertexAI (Google) or OpenAI. However, if you use the same dataset, the costs will be at most $5. The cost may vary if you use a dataset with more records or longer texts, as you are charged by tokens. If you do not wish to incur any costs but still want to follow the tutorial, particularly the second part, you can download the pandas DataFrame recipes_with_vectors.pkl with pre-generated embedding data from my GitHub repository.
You can choose to use either VertexAI or OpenAI to create the embeddings. OpenAI has the advantage of being easy to set up with an API key, while VertexAI requires logging into Google Console, creating a project, and adding the VertexAI API to your project. Additionally, the OpenAI model allows you to specify the number of dimensions for the dense vector. Nevertheless, both of them create state-of-the-art dense embeddings.
Using VertexAI API
# running this code will create costs !!!
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@003")
def to_dense_vector(text, model):
dense_vectors = model.get_embeddings([text])
return [dense_vector.values for dense_vector in dense_vectors][0]
dense_vectors = []
for i in tqdm(range(len(recipes))):
dense_vectors.append(to_dense_vector(recipes.iloc[i]["dense_feature"], model))
recipes["dense_vectors"] = dense_vectors
Using OpenAI API
# running this code will create costs !!!
# Create dense embeddings using OpenAIs text embedding model with 768 dimensions
model = "text-embedding-3-small"
def to_dense_vector_openAI(text, client, model, dimensions):
dense_vectors = client.embeddings.create(model=model, dimensions=dimensions, input=[text])
return [dense_vector.values for dense_vector in dense_vectors][0]
dense_vectors = []
for i in tqdm(range(len(recipes))):
dense_vectors.append(to_dense_vector_openAI(recipes.iloc[i]["dense_feature"], openai_client, model, 768))
recipes["dense_vectors"] = dense_vectors
Upload data to vector database
After generating the sparse and dense embeddings, we have all the necessary data to upload them to a vector database. In this tutorial, Pinecone will be used as they allow performing a hybrid search using sparse and dense vectors and offer a serverless pricing schema with $100 free credits. To perform a hybrid search later on, the similarity metric needs to be set to dot product. If we would only perform a dense instead of a hybrid search we would be able to select one of these similarity metrics: dot product, cosine, and Euclidean distance. More information about similarity metrics and how they calculate the similarity between two vectors can be found here.
# load pandas DataFrame with pre-generated embeddings if you
# didn't generate them in the last step
recipes = pd.read_pickle("recipes_with_vectors.pkl")
# if you need to delte an existing index
pc.delete_index("index-name")
# create a new index
pc.create_index(
name="recipe-project",
dimension=768, # adjust if needed
metric="dotproduct",
spec=ServerlessSpec(
cloud="aws",
region="us-west-2"
)
)
pc.describe_index("recipe-project")
Congratulations on creating your first Pinecone index! Now, it’s time to upload the embedded data to the vector database. If the embedding model you used creates vectors with a different number of dimensions, make sure to adjust the dimension argument.
Now it’s time to upload the data to the newly created Pinecone index.
# upsert to pinecone in batches
def sparse_to_dict(data):
dict_ = {"indices": list(data.keys()),
"values": list(data.values())}
return dict_
batch_size = 100
index = pc.Index("recipe-project")
for i in tqdm(range(0, len(recipes), batch_size)):
i_end = min(i + batch_size, len(recipes))
meta_batch = recipes.iloc[i: i_end][["ID", "recipe_type"]]
meta_dict = meta_batch.to_dict(orient="records")
sparse_batch = recipes.iloc[i: i_end]["sparse_vectors"].apply(lambda x: sparse_to_dict(x))
dense_batch = recipes.iloc[i: i_end]["dense_vectors"]
upserts = []
ids = [str(x) for x in range(i, i_end)]
for id_, meta, sparse_, dense_ in zip(ids, meta_dict, sparse_batch, dense_batch):
upserts.append({
"id": id_,
"sparse_values": sparse_,
"values": dense_,
"metadata": meta
})
index.upsert(upserts)
index.describe_index_stats()
If you are curious about what the uploaded data looks like, log in to Pinecone, select the newly created index, and have a look at its items. For now, we don’t need to pay attention to the score, as it is generated by default and indicates the match with a vector randomly generated by Pinecone. However, later we will calculate the similarity of the embedded user query with all items in the vector database and retrieve the k most similar items. Further, each item contains an item ID generated by Pinecone, and the metadata, which consists of the recipe ID and its recipe_type. The dense embeddings are stored in Values and the sparse embeddings in Sparse Values.
We can fetch the information from above using the Pinecone Python SDK. Let’s have a look at the stored information of the first item with the index item ID 50.
index.fetch(ids=["50"])
As in the Pinecone dashboard, we get the item ID of the element, its metadata, the sparse values, and the dense values, which are stored in the list at the bottom of the truncated output.
Search
In this section, we will solely use dense vectors to find the best-matching entries in our database (dense search). In the second step, we will utilize the information stored in both the sparse and dense vectors to perform a hybrid search.
Regular search using dense vectors
To test the functionality of our recommender system, we will attempt to obtain recommendations for a vegetarian Italian dish. It is important to note that the same model must be used to generate the dense embeddings as the one used to embed the recipes.
user_query = "I want to cook some Italian dish with rice"
recipe_type = "vegetarian"
# running this code will create costs !!!
# If you used VertexAI and gecko003 to create dense embeddings
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@003")
def to_dense_vector(text, model):
dense_vectors = model.get_embeddings([text])
return [dense_vector.values for dense_vector in dense_vectors][0]
text_dense_vector = to_dense_vector(user_query, model)
Using OpenAI API
# running this code will create costs !!!
# If you used OpenAI to create dense embeddings
model = "text-embedding-3-small"
def to_dense_vector_openAI(text, client, model, dimensions):
dense_vectors = client.embeddings.create(model=model, dimensions=dimensions, input=[text])
return [dense_vector.values for dense_vector in dense_vectors][0]
text_dense_vector = to_dense_vector_openAI(user_query, openai_client, model, 768)
After embedding the user text, we can query the vector database for the recipes that resemble the user query the most. As previously defined Pinecone uses the dot product to calculate the similarity score. Further, we specify that Piencone should return the metadata of the recommended items, as we need the ID of the recipe to filter the recipes database and get the output of the corresponding items. The parameter top_k allows us to specify the number of matches that should be returned and lastly, we specify with a hard filter to only recommend coffee blends that cost equal to or less than the indicated price (10.0). More information on how the filtering of metadata works in Pinecone can be found here.
index = pc.Index("recipe-project")
retrieved_items = index.query(vector=text_dense_vector,
include_values=False,
include_metadata=True,
top_k=3,
filter={"recipe_type": {"$eq": recipe_type}})
retrieved_ids = [item.get("metadata").get("ID") for item in retrieved_items.get("matches")]
retrieved_items
After obtaining the IDs of the recommended recipes we can easily query the recipes dataset for them and have a look at their output. The output contains all the needed information as the title, the ingredients, and the directions. A look at the first recommendations reveals that they are all vegetarian, this is not surprising as we applied a “hard” filter, but they are all Italian dishes as requested by the user.
recipes[recipes.ID.isin(retrieved_ids)].output.values
recipes[recipes.ID.isin(retrieved_ids)].output.values[0]
{'title': 'Pasta Arrabbiata',
'ingredients': '- Pasta - Olive oil - Chilli flakes or diced chilli peppers - Crushed garlic cloves - Crushed tomatoes (about 800 gramms for 500 gramms of pasta) - Chopped parsley - Grated Pecorino Romano or Parmigiano Reggiano (optional, but highly recommended)',
'direction': '1. Start heating up water for the pasta. 2. Heat up a few tablespoons of olive oil over low heat. 3. Crush several cloves of garlic into the olive oil, add the chilli flakes or chilli peppers and fry them for a short time, while being careful not to burn the garlic. 4. Add your crushed tomatoes, together with some salt and pepper, increase the heat to medium and let simmer for 10-15 minutes or until it looks nicely thickened. 5. When the water starts boiling, put a handful of salt into it and then your pasta of choice. Ideally leave the pasta slightly undercooked, because it will go in the hot sauce and finish cooking there. 6. When the sauce is almost ready, add most of your chopped parsley and stir it around. Save some to top the dish later. 8. When the pasta is ready (ideally at the same time as the sauce or slightly later), strain it and add it to the sauce, which should be off the heat. If the sauce looks a bit too thick, add some of the pasta water. Mix well. 9. Add some of the grated cheese of your choice and stir it in. 10. Serve with some more grated cheese and chopped parsley on top.'}
Hybrid Search
Now it’s time to implement hybrid search. The concept sounds fancier than it is and you will realize it when we implement it in just two lines of code. Hybrid search weights the values of the dense vector by a factor alpha and the values of the sparse vector by 1-alpha. In other words, alpha determines how much “attention” should be paid to the dense respectively the sparse embeddings of the input text. If alpha=1 we perform a pure dense vector search, alpha=0.5 is a pure hybrid search, and alpha=0 is a pure sparse vector search.
As you remember the sparse and dense vectors were created using different information. Whereas the sparse vector contains information about the ingredients, the dense vector incorporates the title, tags, and introduction. Therefore, by changing alpha we can tell the query engine to prioritize some features of the recipes more than others. Let’s use an alpha of 1 first and run a pure dense search on the user query:
What can I cook with potatos, mushrooms, and beef?
Unfortunately, besides beef, the recommended recipe doesn’t contain any of the other mentioned ingredients.
Generate sparse embeddings
model_id = "naver/splade-cocondenser-ensembledistil"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
def to_sparse_vector(text, tokenizer, model):
tokens = tokenizer(text, return_tensors='pt')
output = model(**tokens)
vec = torch.max(
torch.log(1 + torch.relu(output.logits)) * tokens.attention_mask.unsqueeze(-1), dim=1
)[0].squeeze()
cols = vec.nonzero().squeeze().cpu().tolist()
weights = vec[cols].cpu().tolist()
sparse_dict = dict(zip(cols, weights))
return sparse_dict
text_sparse_vector = to_sparse_vector(user_query, tokenizer, model)
Generate dense embeddings
# running this code will create costs !!!
# If you used VertexAI and gecko003 to create dense embeddings
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@003")
text_dense_vector = to_dense_vector(user_query, model)
def hybride_search(sparse_dict, dense_vectors, alpha):
# check alpha value is in range
if alpha < 0 or alpha > 1:
raise ValueError("Alpha must be between 0 and 1")
# scale sparse and dense vectors to create hybrid search vecs
hsparse = {
"indices": list(sparse_dict.keys()),
"values": [v * (1 - alpha) for v in list(sparse_dict.values())]
}
hdense = [v * alpha for v in dense_vectors]
return hdense, hsparse
user_query = "What can I cook with potatos, mushrooms, and beef?"
recipe_type = ["regular", "vegetarian", "vegan"] # allows for all recipe types
dense_vector, sparse_dict = hybride_search(text_sparse_vector, text_dense_vector, 1.0)
retrieved_items = index.query(vector=dense_vector,
sparse_vector=sparse_dict,
include_values=False,
include_metadata=True,
top_k=1,
filter={"recipe_type": {"$in": recipe_type}})
retrieved_ids = [item.get("metadata").get("ID") for item in retrieved_items.get("matches")]
[x.get("ingredients") for x in recipes[recipes.ID.isin(retrieved_ids)].output.values]
# retrived output with alpha=1.0
['- 1 beef kidney - 60g butter - 2 onions - 2 shallots - 1 sprig of fresh parsley - 3 bay leaves - 400g croutons or toasted bread in pieces']
Let’s set alpha to 0.5 and have a look at the ingredients of the recommended recipe. This alpha score leads to a much better result and the recommended recipe contains all three asked ingredients:
- 500g beef
- 300–400g potatoes
- 2–3 champignon mushrooms
dense_vector, sparse_dict = hybride_search(text_sparse_vector, text_dense_vector, 0.5)
retrieved_items = index.query(vector=dense_vector,
sparse_vector=sparse_dict,
include_values=False,
include_metadata=True,
top_k=1,
filter={"recipe_type": {"$in": recipe_type}})
retrieved_ids = [item.get("metadata").get("ID") for item in retrieved_items.get("matches")]
[x.get("ingredients") for x in recipes[recipes.ID.isin(retrieved_ids)].output.values]
# retrived output with alpha=0.5
['* 500g beef * 300-400g potatoes * 1 carrot * 1 medium onion * 12 tablespoons tomato paste * 500ml water * 3-4 garlic cloves * 3-4 bay leaves * Curcuma * Paprika * Oregano * Parsley * Caraway * Basil (optional) * Cilantro (optional) * 2-3 champignon mushrooms (optional)']Using a serverless index has the advantage that you do not need to pay for a server instance that runs 24/7. Instead, you are billed by queries or read and write units, as they are called by Pinecone. Sparse and dense vector searches work well with a serverless index. However, please keep in mind the following limitation.
Congratulations, you made it to the end of this tutorial!
Final remarks
The implementation of hybrid search is meaningfully different between pod-based and serverless indexes. If you switch from one to the other, you may experience a regression in accuracy or performance.
When you query a serverless index, the dense value of the query is used to retrieve the initial candidate records, and then the sparse value is considered when returning the final results.
Conclusion
In this tutorial, you have learned how to embed a dataset using sparse and dense embeddings and use dense and hybrid search to find the closest matching entries in a vector database.
In the second part, you will build a chatbot using a GPT 3.5-turbo model with function calling and generate a UI using Plotly Dash. Have a look at it if you’re curious and enjoyed the first part.
Please support my work!
If you liked this blog post, please leave a clap or comment. To stay tuned follow me on Medium and LinkedIn.
Build a (recipe) recommender chatbot using RAG and hybrid search (Part I) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.