
Build a Serverless Application To Automate Invoice Processing on AWS
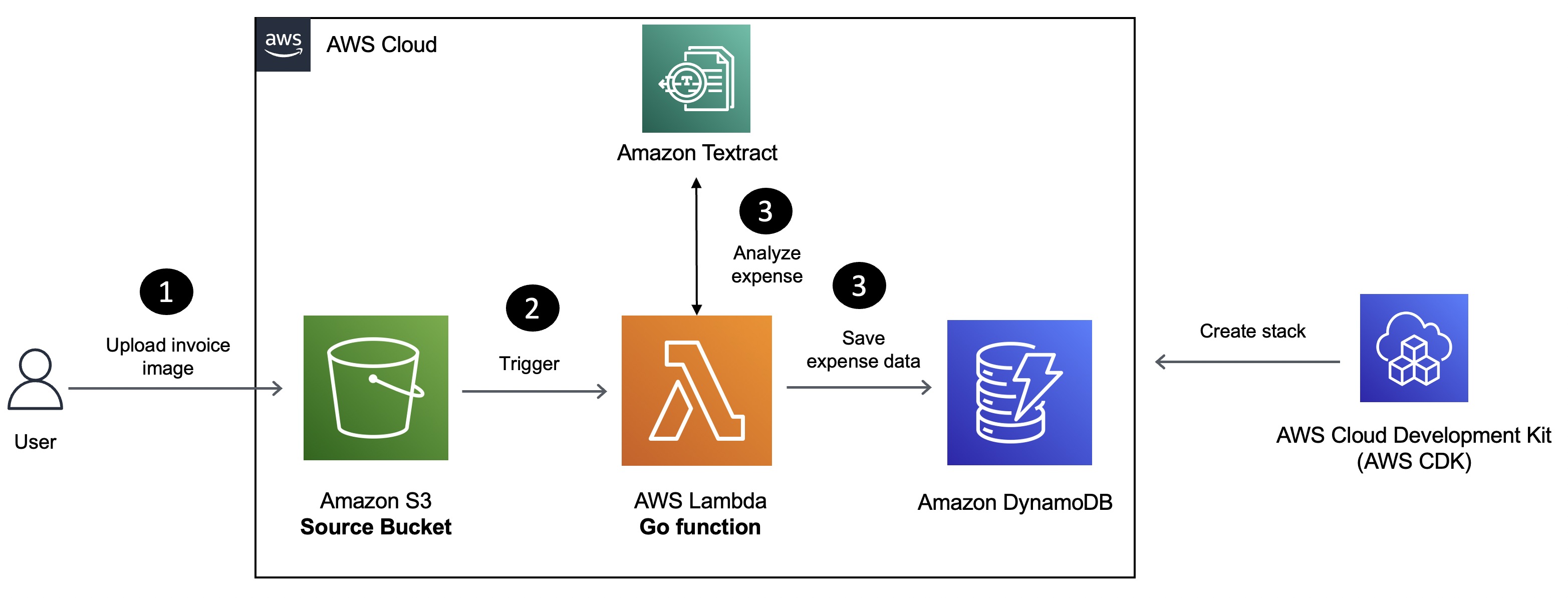
In this blog post, you will learn how to build a serverless solution for invoice processing using Amazon Textract, AWS Lambda, and the Go programming language. Invoices and expense receipt images uploaded to Amazon S3 will trigger a Lambda function which will extract invoice metadata (ID, date, amount, etc.) using the AWS Go SDK and persist it to an Amazon DynamoDB table. You will also use Go bindings for AWS CDK to implement “Infrastructure-as-code” for the entire solution and deploy it with the AWS Cloud Development Kit (CDK) CLI.
The code is available on GitHub.
Introduction To Amazon Textract
Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. It helps add document text detection and analysis to applications which help businesses automate their document processing workflows and reduce manual data entry, which can save time, reduce errors, and increase productivity.
Common use cases for Amazon Textract include:
- Build intelligent search index – Create libraries of text that are detected in image and PDF files.
- Using intelligent text extraction for natural language processing (NLP) – You have control over how text is grouped as input for NLP applications. It can extract text as words and lines and also group text by table cells if document table analysis is enabled.
- Automating data capture from forms – Enable structured data to be extracted from forms and integrate into existing business workflows so that user data submitted through forms can be extracted into a usable format.
- Automating document classification and extraction – With Amazon Textract’s Analyze Lending document processing API, you can automate the classification of lending documents into various document classes, and then automatically route the classified pages to the correct analysis operation for further processing.
Let’s learn Amazon Textract with a hands-on tutorial!
Prerequisites
Before you proceed, make sure you have the following installed:
Clone the project and change it to the right directory:
git clone https://github.com/abhirockzz/ai-ml-golang-textract-text-extraction
cd ai-ml-golang-textract-text-extraction
Use AWS CDK To Deploy the Solution
AWS CDK is a framework that lets you define your cloud infrastructure as code in one of its supported programming and provision it through AWS CloudFormation.
To start the deployment, invoke the cdk deploy command. You will see a list of resources that will be created and will need to provide your confirmation to proceed.
cd cdk
cdk deploy
# output
Bundling asset TextractInvoiceProcessingGolangStack/textract-function/Code/Stage...
✨ Synthesis time: 5.26
//.... omitted
Do you wish to deploy these changes (y/n)? y
Enter y to start creating the AWS resources required for the application.
If you want to see the AWS CloudFormation template which will be used behind the scenes, run cdk synth and check the cdk.out folder.
You can keep track of the stack creation progress in the terminal or navigate to the AWS console: CloudFormation > Stacks > TextractInvoiceProcessingGolangStack.
Once the stack creation is complete, you should have:
- An
S3bucket (Source bucket to upload images) - A Lambda function to process invoice images using Amazon Textract
- A
DyanmoDBtable to store the invoice data for each image - A few other components (like
IAMroles, etc.)
You will also see the following output in the terminal (resource names will differ in your case) – these are the names of the S3 buckets created by CDK:
✅ TextractInvoiceProcessingGolangStack
✨ Deployment time: 113.51s
Outputs:
TextractInvoiceProcessingGolangStack.invoiceinputbucketname = textractinvoiceprocessin-invoiceimagesinputbucket-bro1y13pib0r
TextractInvoiceProcessingGolangStack.invoiceoutputtablename = textractinvoiceprocessin-invoiceimagesinputbucket-bro1y13pib0r_invoice_output
.....
You are ready to try out the end-to-end solution!
Extract Expense Metadata From Invoices
To try the solution, you can either use an image of your own or use the sample files provided in the GitHub repository which has a few sample invoices.
I will be using the S3 CLI to upload the files, but you can use the AWS console as well.
export SOURCE_BUCKET=<enter source S3 bucket name from the CDK output>
aws s3 cp ./invoice1.jpeg s3://$SOURCE_BUCKET
# verify that the file was uploaded
aws s3 ls s3://$SOURCE_BUCKET
This Lambda function will extract invoice data (ID, total amount, etc.) from the image and store them in a DynamoDB table.
Upload other files:
export SOURCE_BUCKET=<enter source S3 bucket name - check the CDK output>
aws s3 cp ./invoice2.jpeg s3://$SOURCE_BUCKET
aws s3 cp ./invoice3.jpeg s3://$SOURCE_BUCKET
Check the DynamoDB table in the AWS console. You should see the extracted invoice information.

DynamoDB table is designed with the source file name as the partition key. This allows you to retrieve all invoice data for a given image.
You can also use the AWS CLI to scan the table:
aws dynamodb scan --table-name <enter table name - check the CDK output>
Clean Up
Once you’re done, to delete all the services, simply use:
cdk destroy
#output prompt (choose 'y' to continue)
Are you sure you want to delete: RekognitionLabelDetectionGolangStack (y/n)?
You were able to set up and try the complete solution. Before we wrap up, let’s quickly walk through some of the important parts of the code to get a better understanding of what’s going on behind the scenes.
Code Walkthrough
Some of the code (error handling, logging, etc.) has been omitted for brevity since we only want to focus on the important parts.
AWS CDK
You can refer to the complete CDK code here.
bucket := awss3.NewBucket(stack, jsii.String("invoice-images-input-bucket"), &awss3.BucketProps{
BlockPublicAccess: awss3.BlockPublicAccess_BLOCK_ALL(),
RemovalPolicy: awscdk.RemovalPolicy_DESTROY,
AutoDeleteObjects: jsii.Bool(true),
})
We start by creating the source S3 bucket.
table := awsdynamodb.NewTable(stack, jsii.String("invoice-output-table"),
&awsdynamodb.TableProps{
PartitionKey: &awsdynamodb.Attribute{
Name: jsii.String("source_file"),
Type: awsdynamodb.AttributeType_STRING},
TableName: jsii.String(*bucket.BucketName() + "_invoice_output"),
})
Then, we create a DynamoDB table to store the invoice data for each image.
function := awscdklambdagoalpha.NewGoFunction(stack, jsii.String("textract-function"),
&awscdklambdagoalpha.GoFunctionProps{
Runtime: awslambda.Runtime_GO_1_X(),
Environment: &map[string]*string{"TABLE_NAME": table.TableName()},
Entry: jsii.String(functionDir),
})
table.GrantWriteData(function)
bucket.GrantRead(function, "*")
function.Role().AddManagedPolicy(awsiam.ManagedPolicy_FromAwsManagedPolicyName(jsii.String("AmazonTextractFullAccess")))
Next, we create the Lambda function, passing the DynamoDB table name as an environment variable to the function. We also grant the function access to the DynamoDB table and the S3 bucket. We also grant the function access to the AmazonTextractFullAccess managed policy.
function.AddEventSource(awslambdaeventsources.NewS3EventSource(sourceBucket, &awslambdaeventsources.S3EventSourceProps{
Events: &[]awss3.EventType{awss3.EventType_OBJECT_CREATED},
}))
We add an event source to the Lambda function that will trigger it when an invoice image is uploaded to the source S3 bucket.
awscdk.NewCfnOutput(stack, jsii.String("invoice-input-bucket-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("invoice-input-bucket-name"),
Value: bucket.BucketName()})
awscdk.NewCfnOutput(stack, jsii.String("invoice-output-table-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("invoice-output-table-name"),
Value: table.TableName()})
Finally, we export the bucket and DynamoDB table names as AWS CloudFormation output.
Lambda Function
You can refer to the complete Lambda Function code here.
func handler(ctx context.Context, s3Event events.S3Event) {
for _, record := range s3Event.Records {
sourceBucketName := record.S3.Bucket.Name
fileName := record.S3.Object.Key
err := invoiceProcessing(sourceBucketName, fileName)
}
}
The Lambda function is triggered when an invoice is uploaded to the source bucket. The function iterates through the list of invoices and calls the invoiceProcessing function for each.
Let’s go through it.
func invoiceProcessing(sourceBucketName, fileName string) error {
resp, err := textractClient.AnalyzeExpense(context.Background(), &textract.AnalyzeExpenseInput{
Document: &types.Document{
S3Object: &types.S3Object{
Bucket: &sourceBucketName,
Name: &fileName,
},
},
})
for _, doc := range resp.ExpenseDocuments {
item := make(map[string]ddbTypes.AttributeValue)
item["source_file"] = &ddbTypes.AttributeValueMemberS{Value: fileName}
for _, summaryField := range doc.SummaryFields {
if *summaryField.Type.Text == "INVOICE_RECEIPT_ID" {
item["receipt_id"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
} else if *summaryField.Type.Text == "TOTAL" {
item["total"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
} else if *summaryField.Type.Text == "INVOICE_RECEIPT_DATE" {
item["receipt_date"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
} else if *summaryField.Type.Text == "DUE_DATE" {
item["due_date"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
}
}
_, err := dynamodbClient.PutItem(context.Background(), &dynamodb.PutItemInput{
TableName: aws.String(table),
Item: item,
})
}
return nil
}
- The
invoiceProcessingfunction calls Amazon Textract AnalyzeExpense API to extract the invoice data. - The function then iterates through the list of ExpenseDocuments and extracts information from specific fields –
INVOICE_RECEIPT_ID,TOTAL,INVOICE_RECEIPT_DATE,DUE_DATE. - It then stores the extracted data in the
DynamoDBtable.
Conclusion and Next Steps
In this post, you saw how to create a serverless solution to process invoices using Amazon Textract. The entire infrastructure life-cycle was automated using AWS CDK. All this was done using the Go programming language, which is well-supported in AWS Lambda and AWS CDK.
To improve/extend this solution, try experimenting with other fields in the ExpenseDocuments response and see if you can extract more information.
Happy building!
In this blog post, you will learn how to build a serverless solution for invoice processing using Amazon Textract, AWS Lambda, and the Go programming language. Invoices and expense receipt images uploaded to Amazon S3 will trigger a Lambda function which will extract invoice metadata (ID, date, amount, etc.) using the AWS Go SDK and persist it to an Amazon DynamoDB table. You will also use Go bindings for AWS CDK to implement “Infrastructure-as-code” for the entire solution and deploy it with the AWS Cloud Development Kit (CDK) CLI.
The code is available on GitHub.
Introduction To Amazon Textract
Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. It helps add document text detection and analysis to applications which help businesses automate their document processing workflows and reduce manual data entry, which can save time, reduce errors, and increase productivity.
Common use cases for Amazon Textract include:
- Build intelligent search index – Create libraries of text that are detected in image and PDF files.
- Using intelligent text extraction for natural language processing (NLP) – You have control over how text is grouped as input for NLP applications. It can extract text as words and lines and also group text by table cells if document table analysis is enabled.
- Automating data capture from forms – Enable structured data to be extracted from forms and integrate into existing business workflows so that user data submitted through forms can be extracted into a usable format.
- Automating document classification and extraction – With Amazon Textract’s Analyze Lending document processing API, you can automate the classification of lending documents into various document classes, and then automatically route the classified pages to the correct analysis operation for further processing.
Let’s learn Amazon Textract with a hands-on tutorial!
Prerequisites
Before you proceed, make sure you have the following installed:
Clone the project and change it to the right directory:
git clone https://github.com/abhirockzz/ai-ml-golang-textract-text-extraction
cd ai-ml-golang-textract-text-extraction
Use AWS CDK To Deploy the Solution
AWS CDK is a framework that lets you define your cloud infrastructure as code in one of its supported programming and provision it through AWS CloudFormation.
To start the deployment, invoke the cdk deploy command. You will see a list of resources that will be created and will need to provide your confirmation to proceed.
cd cdk
cdk deploy
# output
Bundling asset TextractInvoiceProcessingGolangStack/textract-function/Code/Stage...
✨ Synthesis time: 5.26
//.... omitted
Do you wish to deploy these changes (y/n)? y
Enter y to start creating the AWS resources required for the application.
If you want to see the AWS CloudFormation template which will be used behind the scenes, run cdk synth and check the cdk.out folder.
You can keep track of the stack creation progress in the terminal or navigate to the AWS console: CloudFormation > Stacks > TextractInvoiceProcessingGolangStack.
Once the stack creation is complete, you should have:
- An
S3bucket (Source bucket to upload images) - A Lambda function to process invoice images using Amazon Textract
- A
DyanmoDBtable to store the invoice data for each image - A few other components (like
IAMroles, etc.)
You will also see the following output in the terminal (resource names will differ in your case) – these are the names of the S3 buckets created by CDK:
✅ TextractInvoiceProcessingGolangStack
✨ Deployment time: 113.51s
Outputs:
TextractInvoiceProcessingGolangStack.invoiceinputbucketname = textractinvoiceprocessin-invoiceimagesinputbucket-bro1y13pib0r
TextractInvoiceProcessingGolangStack.invoiceoutputtablename = textractinvoiceprocessin-invoiceimagesinputbucket-bro1y13pib0r_invoice_output
.....
You are ready to try out the end-to-end solution!
Extract Expense Metadata From Invoices
To try the solution, you can either use an image of your own or use the sample files provided in the GitHub repository which has a few sample invoices.
I will be using the S3 CLI to upload the files, but you can use the AWS console as well.
export SOURCE_BUCKET=<enter source S3 bucket name from the CDK output>
aws s3 cp ./invoice1.jpeg s3://$SOURCE_BUCKET
# verify that the file was uploaded
aws s3 ls s3://$SOURCE_BUCKET
This Lambda function will extract invoice data (ID, total amount, etc.) from the image and store them in a DynamoDB table.
Upload other files:
export SOURCE_BUCKET=<enter source S3 bucket name - check the CDK output>
aws s3 cp ./invoice2.jpeg s3://$SOURCE_BUCKET
aws s3 cp ./invoice3.jpeg s3://$SOURCE_BUCKET
Check the DynamoDB table in the AWS console. You should see the extracted invoice information.
DynamoDB table is designed with the source file name as the partition key. This allows you to retrieve all invoice data for a given image.
You can also use the AWS CLI to scan the table:
aws dynamodb scan --table-name <enter table name - check the CDK output>
Clean Up
Once you’re done, to delete all the services, simply use:
cdk destroy
#output prompt (choose 'y' to continue)
Are you sure you want to delete: RekognitionLabelDetectionGolangStack (y/n)?
You were able to set up and try the complete solution. Before we wrap up, let’s quickly walk through some of the important parts of the code to get a better understanding of what’s going on behind the scenes.
Code Walkthrough
Some of the code (error handling, logging, etc.) has been omitted for brevity since we only want to focus on the important parts.
AWS CDK
You can refer to the complete CDK code here.
bucket := awss3.NewBucket(stack, jsii.String("invoice-images-input-bucket"), &awss3.BucketProps{
BlockPublicAccess: awss3.BlockPublicAccess_BLOCK_ALL(),
RemovalPolicy: awscdk.RemovalPolicy_DESTROY,
AutoDeleteObjects: jsii.Bool(true),
})
We start by creating the source S3 bucket.
table := awsdynamodb.NewTable(stack, jsii.String("invoice-output-table"),
&awsdynamodb.TableProps{
PartitionKey: &awsdynamodb.Attribute{
Name: jsii.String("source_file"),
Type: awsdynamodb.AttributeType_STRING},
TableName: jsii.String(*bucket.BucketName() + "_invoice_output"),
})
Then, we create a DynamoDB table to store the invoice data for each image.
function := awscdklambdagoalpha.NewGoFunction(stack, jsii.String("textract-function"),
&awscdklambdagoalpha.GoFunctionProps{
Runtime: awslambda.Runtime_GO_1_X(),
Environment: &map[string]*string{"TABLE_NAME": table.TableName()},
Entry: jsii.String(functionDir),
})
table.GrantWriteData(function)
bucket.GrantRead(function, "*")
function.Role().AddManagedPolicy(awsiam.ManagedPolicy_FromAwsManagedPolicyName(jsii.String("AmazonTextractFullAccess")))
Next, we create the Lambda function, passing the DynamoDB table name as an environment variable to the function. We also grant the function access to the DynamoDB table and the S3 bucket. We also grant the function access to the AmazonTextractFullAccess managed policy.
function.AddEventSource(awslambdaeventsources.NewS3EventSource(sourceBucket, &awslambdaeventsources.S3EventSourceProps{
Events: &[]awss3.EventType{awss3.EventType_OBJECT_CREATED},
}))
We add an event source to the Lambda function that will trigger it when an invoice image is uploaded to the source S3 bucket.
awscdk.NewCfnOutput(stack, jsii.String("invoice-input-bucket-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("invoice-input-bucket-name"),
Value: bucket.BucketName()})
awscdk.NewCfnOutput(stack, jsii.String("invoice-output-table-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("invoice-output-table-name"),
Value: table.TableName()})
Finally, we export the bucket and DynamoDB table names as AWS CloudFormation output.
Lambda Function
You can refer to the complete Lambda Function code here.
func handler(ctx context.Context, s3Event events.S3Event) {
for _, record := range s3Event.Records {
sourceBucketName := record.S3.Bucket.Name
fileName := record.S3.Object.Key
err := invoiceProcessing(sourceBucketName, fileName)
}
}
The Lambda function is triggered when an invoice is uploaded to the source bucket. The function iterates through the list of invoices and calls the invoiceProcessing function for each.
Let’s go through it.
func invoiceProcessing(sourceBucketName, fileName string) error {
resp, err := textractClient.AnalyzeExpense(context.Background(), &textract.AnalyzeExpenseInput{
Document: &types.Document{
S3Object: &types.S3Object{
Bucket: &sourceBucketName,
Name: &fileName,
},
},
})
for _, doc := range resp.ExpenseDocuments {
item := make(map[string]ddbTypes.AttributeValue)
item["source_file"] = &ddbTypes.AttributeValueMemberS{Value: fileName}
for _, summaryField := range doc.SummaryFields {
if *summaryField.Type.Text == "INVOICE_RECEIPT_ID" {
item["receipt_id"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
} else if *summaryField.Type.Text == "TOTAL" {
item["total"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
} else if *summaryField.Type.Text == "INVOICE_RECEIPT_DATE" {
item["receipt_date"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
} else if *summaryField.Type.Text == "DUE_DATE" {
item["due_date"] = &ddbTypes.AttributeValueMemberS{Value: *summaryField.ValueDetection.Text}
}
}
_, err := dynamodbClient.PutItem(context.Background(), &dynamodb.PutItemInput{
TableName: aws.String(table),
Item: item,
})
}
return nil
}
- The
invoiceProcessingfunction calls Amazon Textract AnalyzeExpense API to extract the invoice data. - The function then iterates through the list of ExpenseDocuments and extracts information from specific fields –
INVOICE_RECEIPT_ID,TOTAL,INVOICE_RECEIPT_DATE,DUE_DATE. - It then stores the extracted data in the
DynamoDBtable.
Conclusion and Next Steps
In this post, you saw how to create a serverless solution to process invoices using Amazon Textract. The entire infrastructure life-cycle was automated using AWS CDK. All this was done using the Go programming language, which is well-supported in AWS Lambda and AWS CDK.
To improve/extend this solution, try experimenting with other fields in the ExpenseDocuments response and see if you can extract more information.
Happy building!
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.