
Building a Khmer Spelling Checker | by Socret Lee | May, 2022
Learning about the BK-tree and the Edit Distance (a.k.a Levenshtein Distance)
Recently, I had the opportunity to work on a Khmer keyboard app. Like any other keyboard app, spelling checking and spelling suggestions are core features of the user experience. While trying to implement these features, I came across a popular method that relies on two concepts to do spell checking: Edit Distance (a.k.a Levenshtein Distance) and the BK-tree. Hence, this post will discuss these concepts and their shortcomings and share a Python implementation of a Khmer Spell Checker that relies on them.
The Edit Distance is the minimum number of steps/operations needed to transform one string into another. There are multiple techniques to calculate the Edit distance. However, the most popular one is the Levenshtein Distance, proposed by a Soviet mathematician, Vladimir Levenshtein. His approach allows for three types of string operations to be factored into the edit distance: Insertion, Deletion, and Substitution/Replacement. In the context of spell checking, the Edit Distance allows us to measure “how different” two words are from one another.
Algorithm
We can efficiently calculate the Edit Distance through dynamic programming. It uses a matrix represented by a 2D array to store the temporary distance between substrings to save computation costs. Let’s look at how we can calculate the Edit Distance between “កាល” and “ក្បាល”.
Step 1: Initialize an empty 2D array of size (len(word1) + 1, len(word2) +1)

Step 2: Fill in the cells in the first rows with their column index.

Step 3: Fill in the cells in the first cols with their row index.

Step 4: At position (1, 1), we look at the characters of both words at that position: word1 (ក) and word2 (ក). Since they are the same, we set the current cell value as the value of its top-left neighbor. Therefore, the value of cell (1, 1) becomes 0. Then, we move to the next column in row 1.

Step 5: At the position (1, 2), we again compare the characters of both words at the position: word1 (ក) and word2 (្). This time the two characters are different. So, the current cell’s value is the min([left, top, top-left]) + 1. Then, we repeat steps 4 and 5 for the remaining cells.

Step 6: After we fill all the cells, the minimum Edit distance is the bottom-right cells of the 2D matrix. Hence, the minimum Edit distance between the word “កាល” and “ក្បាល” is 2.

In addition, to know which combination of edit operations leads to the minimum Edit Distance, we need to perform the shortest path search from the top-left to the lower-right cell. Of course, there can be multiple combinations since there can be multiple shortest paths that can lead to the lower-right cell.
A naive approach to building a spell checker is to find the Edit distance between the word provided by the user to all other words in the dictionary and return those with the smallest Edit distance to that word. However, that approach will take time and calculations if the dictionary is extensive. The BK-tree allows us to perform the search faster by limiting the number of comparisons needed using a tree data structure that utilizes Edit distance. Each node in the tree is a word. Each edge connecting different nodes is the Edit Distance between that node to its parent. To better understand the BK-tree, we can look at an example of how we can build the tree for a dictionary of 4 words: {“ស្គម”, “ស្អាត”, “កាល”, “ក្បាល”}. Then, we will go further by looking at how we can search the tree for matching nodes.
BK-tree Construction Algorithm
Step 1: Add the first word “ស្គម” as the tree’s root node. Then move on to the next word, “ស្អាត”.

Step 2: Set the root node as the current node. Then calculate the edit distance between “ស្អាត” to the current node. So dist(ស្អាត, ស្គម) = 3. After that, we look at the children of the current node. Since the current node has no children whose distance is equal to dist(ស្អាត, ស្គម), we insert “ស្អាត” as a child of the current node. Then we move to the next word, “កាល”.
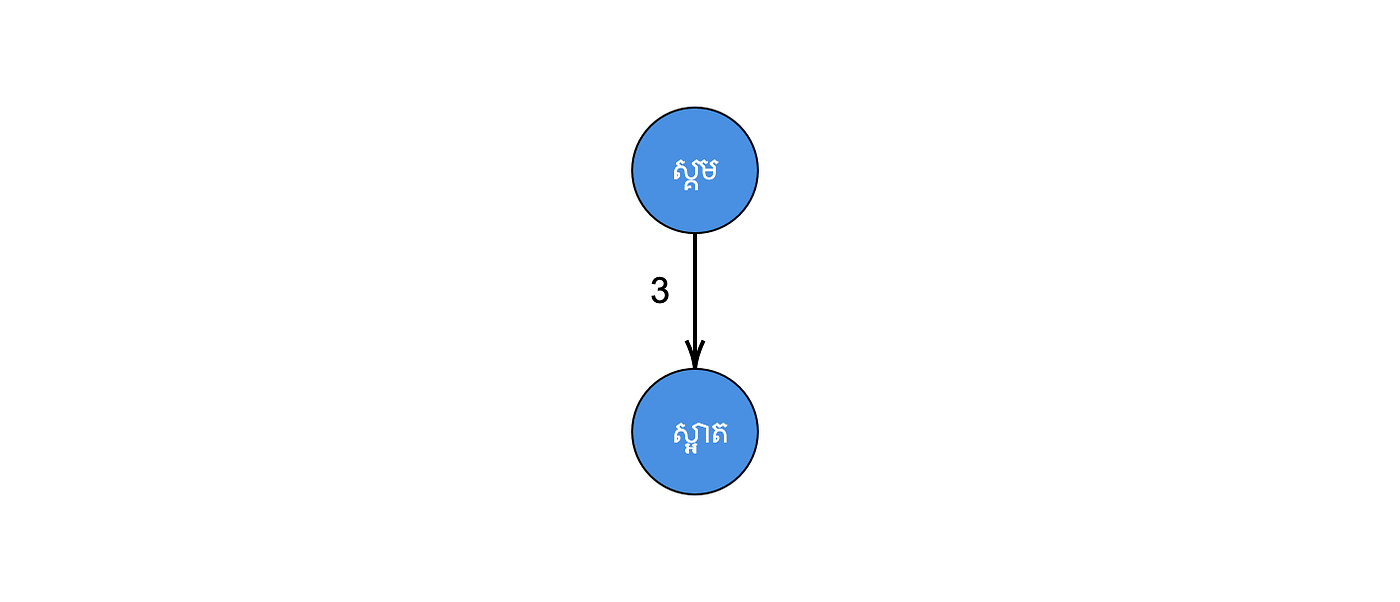
Step 3: Set the root node as the current node. Then calculate the edit distance between “កាល” to the current node. So we get dist(កាល, ស្គម) = 4. Similar to step 2, the current node has no children whose distance is equal to dist(កាល, ស្គម). Hence, we insert “កាល” as a child of the current node. Then we move to the next word, “ក្បាល”.

Step 4: Set the root node as the current node. Then calculate the edit distance between “ក្បាល” to the current node, which gives us dist(ក្បាល, ស្គម) = 4. This time, the current node has a child whose distance is 4, which is the dist(កាល, ស្គម). In this scenario, we push the insertion process down to that child node by setting it as the current node. After that, we repeat the insertion process with the current node as “កាល”, giving us dist(ក្បាល, កាល) = 2. At this stage, there is no child of “កាល” whose distance is equal to dist(ក្បាល, កាល). Hence, we insert “ក្បាល” as a child of “កាល”.
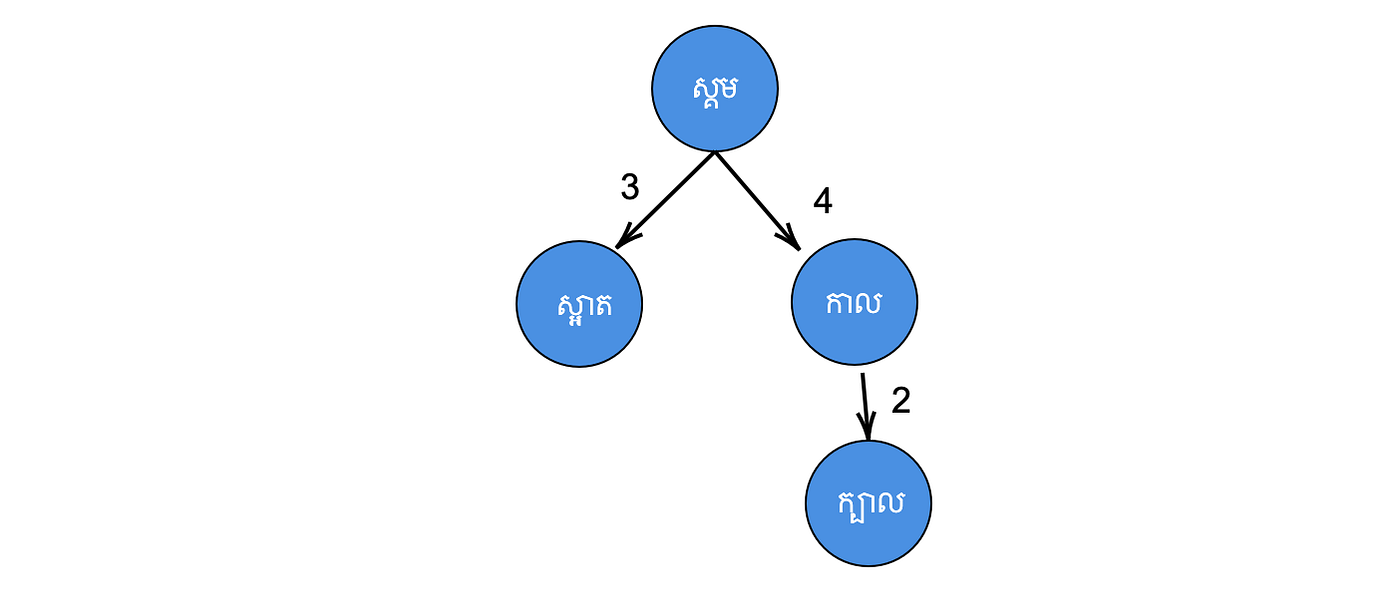
After building the tree, we can search it to find matching nodes as word corrections.
BK-tree Search
We can apply any tree searching algorithm to search the BK-tree. In our case, I opted for the depth-first search. However, one special feature that the BK-tree gives us is the ability to prune/skip a large portion of the nodes in the tree. It achieves this by allowing us to only look at nodes whose Edit distance is within a certain tolerance threshold. More specially, we only look at children of the current node whose edit distance is between [dist(word, current_node)-N, dist(word, current_node) + N], where N is the tolerance level.
Let’s look at what will get returned if a user types in the word “កាក” and our tolerance level N = 2.
Step 1: Initialize an empty stack and an empty matches list.

Step 2: Add the root node (ស្គម) to the stack.
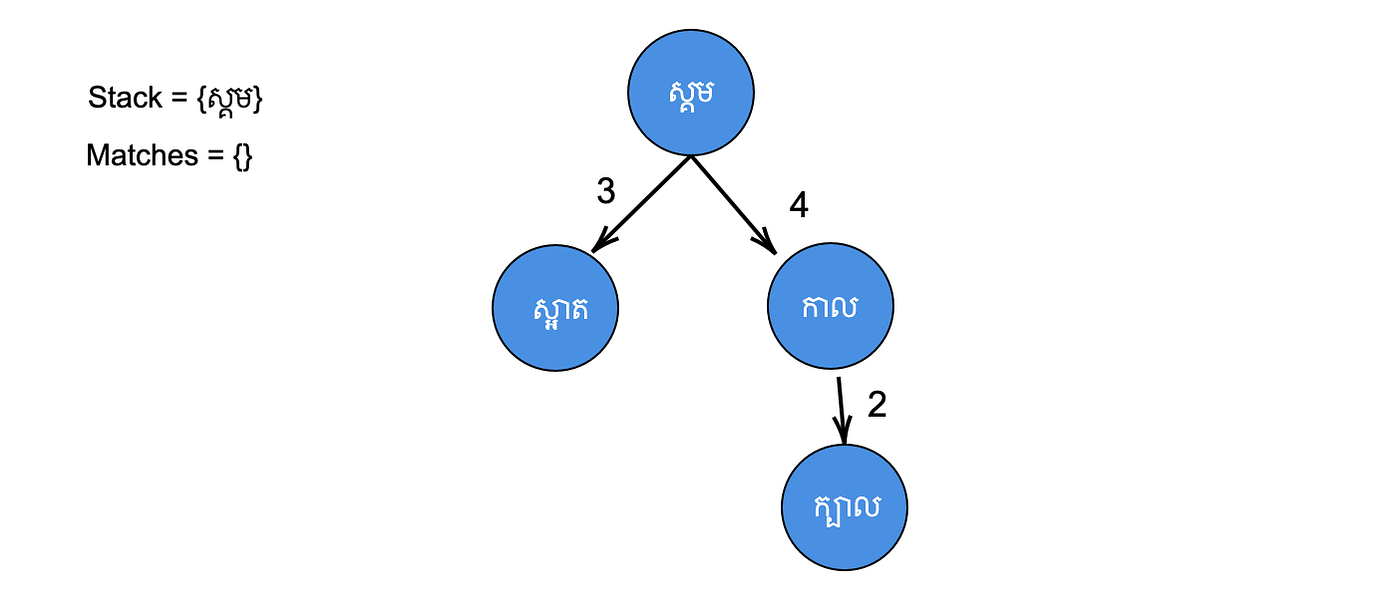
Step 3: Get the node at the top of the stack (ស្គម). After that, we find that dist(ស្គម, កាក) = 4 > N. Hence, we do not add it to the matches list. Then look at its children “ស្អាត” and “កាល”. For each child, if dist(ស្គម, កាក) – 2 ≤ dist(child, ស្គម) ≤ dist(ស្គម, កាក) + 2, then we add it to the stack. In this case, both “ស្អាត” and “កាល” are added to the stack since 2 ≤ dist(ស្អាត, ស្គម) = 3 ≤ 6 and 2 ≤ dist(កាល, ស្គម) = 4 ≤ 6.

Step 4: Get the node at the top of the stack (កាល). Then, dist(កាល, កាក) = 1 ≤ N. So we add it to the matches list. Again we find the children of “កាល” that can be added to the stack. This time only “ក្បាល” can be added since -1 ≤ dist(ក្បាល, កាល) = 2 ≤ 3.

Step 5: Get the node at the top of the stack (ក្បាល). Then, dist(ក្បាល, កាក) = 3 > N. Hence, we do not add it to the matches list. Since “ក្បាល” does not have any children, then we do not add any more nodes to the stack.

Step 5: Get the node at the top of the stack (ស្អាត). Then, dist(ស្អាត, កាក) = 4 > N. Hence, we do not add it to the matches list. Since “ស្អាត” does not have any children, then we do not add any more nodes to the stack.
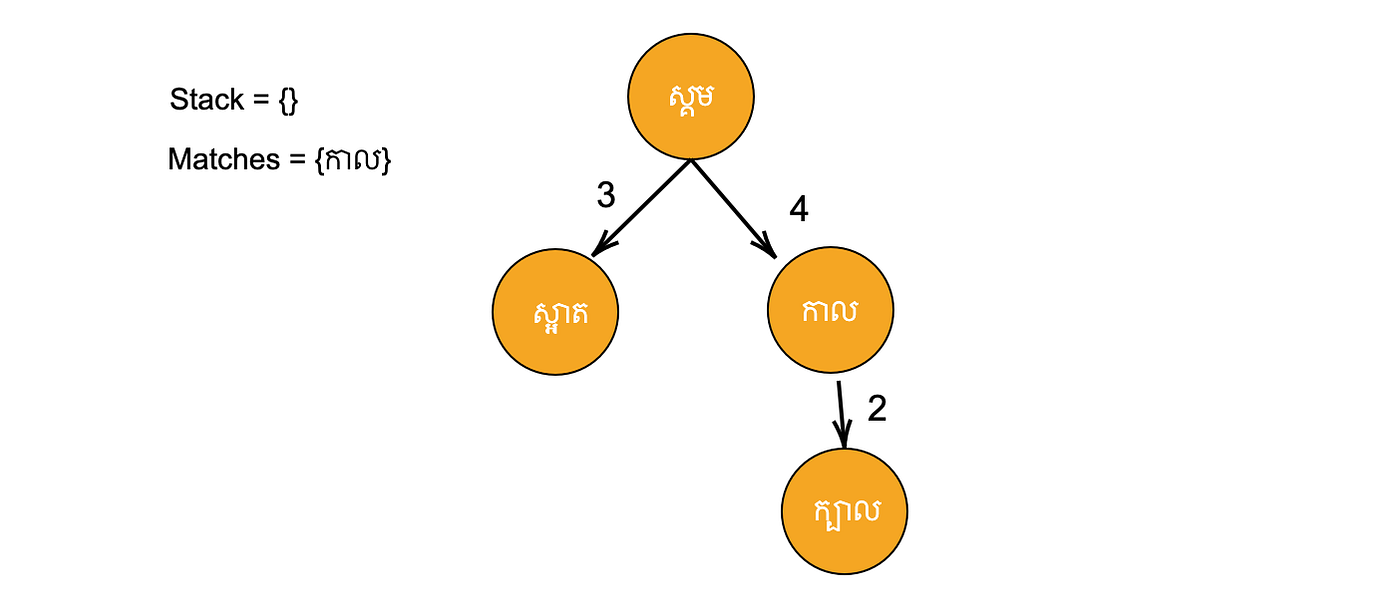
Step 7: Since there are no more nodes in the stack, the algorithm ends.

In our example above, the search traversed through all the nodes. However, when the number of words in the dictionary is large, this method will allow us to skip many unnecessary nodes.
This method for spelling checking and suggestion while providing acceptable results has some drawbacks.
- The tree construction process can take quite a long time to complete and therefore need to be pre-calculated and saved into a file.
- The quality of suggestions depends heavily on the words in the dictionary. If the word is not in the dictionary, it could not be suggested.
- It does not have any previous context words, and therefore the suggestions might not fit the overall sentence structure.
After learning about these concepts, I got a chance to write a python package that utilizes them. The first thing that I did was prepare a dictionary of Khmer words. To do that, I downloaded an open-source (MIT License) Khmer words dataset from SBBIC and did some preprocessing to end up with a list of around 40k unique words. Then, I used the below code to construct the BK-tree, save the tree to an XML file, and use it to make spelling suggestions. Furthermore, I also packaged it into a python library that you can install through pip.
Edit Distance
BK-tree Construction
BK-tree Search / Spell Checking and Suggestions
Learning about the Edit distance and the BK-tree allowed me to implement a simple but effective spelling checker and suggestion features. I hope this post provides you with enough understanding to implement these concepts in other programming languages and maybe extend them to more than just a spell checker. Happy learning!
Back To Back SWE. (2019). Edit Distance Between 2 Strings — The Levenshtein Distance (“Edit Distance” on LeetCode) [YouTube channel]. YouTube. Retrieved from https://www.youtube.com/watch?v=MiqoA-yF-0M&t=5s
EpicFactFind. (2019). Spell checking with Levenshtein distance and Bk-Trees [YouTube channel]. YouTube. Retrieved from https://www.youtube.com/watch?v=oIsPB2pqq_8
Jurafsky, D. (n.d.). Minimum Edit Distance [PowerPoint Slides]. Standford University. Retrieved from https://web.stanford.edu/class/cs124/lec/med.pdf
Kumar, N. (2022). BK-Tree | Introduction & Implementation. GeeksforGeeks. Retrieved from https://www.geeksforgeeks.org/bk-tree-introduction-implementation/
Mishra, B, H. (n.d.). Burkhard Keller Tree (BK Tree). OpenGenus. Retrieved from https://iq.opengenus.org/burkhard-keller-tree/
SBBIC. (2017). SBBIC Khmer Word List [Data set]. SBBIC. Retrieved from https://sbbic.org/2010/07/29/sbbic-khmer-word-list/
Singh, A. (2020). BK Trees: Unexplored Data Structure. Towards Data Science. Retrieved from https://medium.com/future-vision/bk-trees-unexplored-data-structure-ec234f39052d
Tushar Roy — Coding Made Simple. (2015). Minimum Edit Distance Dynamic Programming [YouTube channel]. YouTube. Retrieved from https://www.youtube.com/watch?v=We3YDTzNXEk
Learning about the BK-tree and the Edit Distance (a.k.a Levenshtein Distance)

Recently, I had the opportunity to work on a Khmer keyboard app. Like any other keyboard app, spelling checking and spelling suggestions are core features of the user experience. While trying to implement these features, I came across a popular method that relies on two concepts to do spell checking: Edit Distance (a.k.a Levenshtein Distance) and the BK-tree. Hence, this post will discuss these concepts and their shortcomings and share a Python implementation of a Khmer Spell Checker that relies on them.
The Edit Distance is the minimum number of steps/operations needed to transform one string into another. There are multiple techniques to calculate the Edit distance. However, the most popular one is the Levenshtein Distance, proposed by a Soviet mathematician, Vladimir Levenshtein. His approach allows for three types of string operations to be factored into the edit distance: Insertion, Deletion, and Substitution/Replacement. In the context of spell checking, the Edit Distance allows us to measure “how different” two words are from one another.
Algorithm
We can efficiently calculate the Edit Distance through dynamic programming. It uses a matrix represented by a 2D array to store the temporary distance between substrings to save computation costs. Let’s look at how we can calculate the Edit Distance between “កាល” and “ក្បាល”.
Step 1: Initialize an empty 2D array of size (len(word1) + 1, len(word2) +1)
Step 2: Fill in the cells in the first rows with their column index.
Step 3: Fill in the cells in the first cols with their row index.
Step 4: At position (1, 1), we look at the characters of both words at that position: word1 (ក) and word2 (ក). Since they are the same, we set the current cell value as the value of its top-left neighbor. Therefore, the value of cell (1, 1) becomes 0. Then, we move to the next column in row 1.
Step 5: At the position (1, 2), we again compare the characters of both words at the position: word1 (ក) and word2 (្). This time the two characters are different. So, the current cell’s value is the min([left, top, top-left]) + 1. Then, we repeat steps 4 and 5 for the remaining cells.
Step 6: After we fill all the cells, the minimum Edit distance is the bottom-right cells of the 2D matrix. Hence, the minimum Edit distance between the word “កាល” and “ក្បាល” is 2.
In addition, to know which combination of edit operations leads to the minimum Edit Distance, we need to perform the shortest path search from the top-left to the lower-right cell. Of course, there can be multiple combinations since there can be multiple shortest paths that can lead to the lower-right cell.
A naive approach to building a spell checker is to find the Edit distance between the word provided by the user to all other words in the dictionary and return those with the smallest Edit distance to that word. However, that approach will take time and calculations if the dictionary is extensive. The BK-tree allows us to perform the search faster by limiting the number of comparisons needed using a tree data structure that utilizes Edit distance. Each node in the tree is a word. Each edge connecting different nodes is the Edit Distance between that node to its parent. To better understand the BK-tree, we can look at an example of how we can build the tree for a dictionary of 4 words: {“ស្គម”, “ស្អាត”, “កាល”, “ក្បាល”}. Then, we will go further by looking at how we can search the tree for matching nodes.
BK-tree Construction Algorithm
Step 1: Add the first word “ស្គម” as the tree’s root node. Then move on to the next word, “ស្អាត”.
Step 2: Set the root node as the current node. Then calculate the edit distance between “ស្អាត” to the current node. So dist(ស្អាត, ស្គម) = 3. After that, we look at the children of the current node. Since the current node has no children whose distance is equal to dist(ស្អាត, ស្គម), we insert “ស្អាត” as a child of the current node. Then we move to the next word, “កាល”.
Step 3: Set the root node as the current node. Then calculate the edit distance between “កាល” to the current node. So we get dist(កាល, ស្គម) = 4. Similar to step 2, the current node has no children whose distance is equal to dist(កាល, ស្គម). Hence, we insert “កាល” as a child of the current node. Then we move to the next word, “ក្បាល”.
Step 4: Set the root node as the current node. Then calculate the edit distance between “ក្បាល” to the current node, which gives us dist(ក្បាល, ស្គម) = 4. This time, the current node has a child whose distance is 4, which is the dist(កាល, ស្គម). In this scenario, we push the insertion process down to that child node by setting it as the current node. After that, we repeat the insertion process with the current node as “កាល”, giving us dist(ក្បាល, កាល) = 2. At this stage, there is no child of “កាល” whose distance is equal to dist(ក្បាល, កាល). Hence, we insert “ក្បាល” as a child of “កាល”.
After building the tree, we can search it to find matching nodes as word corrections.
BK-tree Search
We can apply any tree searching algorithm to search the BK-tree. In our case, I opted for the depth-first search. However, one special feature that the BK-tree gives us is the ability to prune/skip a large portion of the nodes in the tree. It achieves this by allowing us to only look at nodes whose Edit distance is within a certain tolerance threshold. More specially, we only look at children of the current node whose edit distance is between [dist(word, current_node)-N, dist(word, current_node) + N], where N is the tolerance level.
Let’s look at what will get returned if a user types in the word “កាក” and our tolerance level N = 2.
Step 1: Initialize an empty stack and an empty matches list.
Step 2: Add the root node (ស្គម) to the stack.
Step 3: Get the node at the top of the stack (ស្គម). After that, we find that dist(ស្គម, កាក) = 4 > N. Hence, we do not add it to the matches list. Then look at its children “ស្អាត” and “កាល”. For each child, if dist(ស្គម, កាក) – 2 ≤ dist(child, ស្គម) ≤ dist(ស្គម, កាក) + 2, then we add it to the stack. In this case, both “ស្អាត” and “កាល” are added to the stack since 2 ≤ dist(ស្អាត, ស្គម) = 3 ≤ 6 and 2 ≤ dist(កាល, ស្គម) = 4 ≤ 6.
Step 4: Get the node at the top of the stack (កាល). Then, dist(កាល, កាក) = 1 ≤ N. So we add it to the matches list. Again we find the children of “កាល” that can be added to the stack. This time only “ក្បាល” can be added since -1 ≤ dist(ក្បាល, កាល) = 2 ≤ 3.
Step 5: Get the node at the top of the stack (ក្បាល). Then, dist(ក្បាល, កាក) = 3 > N. Hence, we do not add it to the matches list. Since “ក្បាល” does not have any children, then we do not add any more nodes to the stack.
Step 5: Get the node at the top of the stack (ស្អាត). Then, dist(ស្អាត, កាក) = 4 > N. Hence, we do not add it to the matches list. Since “ស្អាត” does not have any children, then we do not add any more nodes to the stack.
Step 7: Since there are no more nodes in the stack, the algorithm ends.
In our example above, the search traversed through all the nodes. However, when the number of words in the dictionary is large, this method will allow us to skip many unnecessary nodes.
This method for spelling checking and suggestion while providing acceptable results has some drawbacks.
- The tree construction process can take quite a long time to complete and therefore need to be pre-calculated and saved into a file.
- The quality of suggestions depends heavily on the words in the dictionary. If the word is not in the dictionary, it could not be suggested.
- It does not have any previous context words, and therefore the suggestions might not fit the overall sentence structure.
After learning about these concepts, I got a chance to write a python package that utilizes them. The first thing that I did was prepare a dictionary of Khmer words. To do that, I downloaded an open-source (MIT License) Khmer words dataset from SBBIC and did some preprocessing to end up with a list of around 40k unique words. Then, I used the below code to construct the BK-tree, save the tree to an XML file, and use it to make spelling suggestions. Furthermore, I also packaged it into a python library that you can install through pip.
Edit Distance
BK-tree Construction
BK-tree Search / Spell Checking and Suggestions
Learning about the Edit distance and the BK-tree allowed me to implement a simple but effective spelling checker and suggestion features. I hope this post provides you with enough understanding to implement these concepts in other programming languages and maybe extend them to more than just a spell checker. Happy learning!
Back To Back SWE. (2019). Edit Distance Between 2 Strings — The Levenshtein Distance (“Edit Distance” on LeetCode) [YouTube channel]. YouTube. Retrieved from https://www.youtube.com/watch?v=MiqoA-yF-0M&t=5s
EpicFactFind. (2019). Spell checking with Levenshtein distance and Bk-Trees [YouTube channel]. YouTube. Retrieved from https://www.youtube.com/watch?v=oIsPB2pqq_8
Jurafsky, D. (n.d.). Minimum Edit Distance [PowerPoint Slides]. Standford University. Retrieved from https://web.stanford.edu/class/cs124/lec/med.pdf
Kumar, N. (2022). BK-Tree | Introduction & Implementation. GeeksforGeeks. Retrieved from https://www.geeksforgeeks.org/bk-tree-introduction-implementation/
Mishra, B, H. (n.d.). Burkhard Keller Tree (BK Tree). OpenGenus. Retrieved from https://iq.opengenus.org/burkhard-keller-tree/
SBBIC. (2017). SBBIC Khmer Word List [Data set]. SBBIC. Retrieved from https://sbbic.org/2010/07/29/sbbic-khmer-word-list/
Singh, A. (2020). BK Trees: Unexplored Data Structure. Towards Data Science. Retrieved from https://medium.com/future-vision/bk-trees-unexplored-data-structure-ec234f39052d
Tushar Roy — Coding Made Simple. (2015). Minimum Edit Distance Dynamic Programming [YouTube channel]. YouTube. Retrieved from https://www.youtube.com/watch?v=We3YDTzNXEk
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.