
Building LLMs-Powered Apps with OPL Stack | by Wen Yang | Apr, 2023
OPL: OpenAI, Pinecone, and Lanchain for knowledge-based AI assistant

I remember a month ago, Eugene Yan posted a poll on Linkedin:
Are you feeling the FOMO from not working on LLMs/Generative AI?
Most answered “Yes”. It’s easy to understand why, given the sweeping attention generated by chatGPT and now the release of gpt-4. People describe the rise of Large Language Models (LLMs) feels like the iPhone moment. Yet I think there’s really no need to feel the FOMO. Consider this: missing out on the opportunity to develop iPhones doesn’t preclude the ample potential for creating innovative iPhone apps. So too with LLMs. We have just entered the dawn of a new era and now it’s the perfect time to harness the magic of integrating LLMs to build powerful applications.
In this post, I’ll cover below topics:
- What is the OPL stack?
- How to use the OPL to build chatGPT with domain knowledge? (Essential components with code walkthrough)
- Production considerations
- Common misconceptions
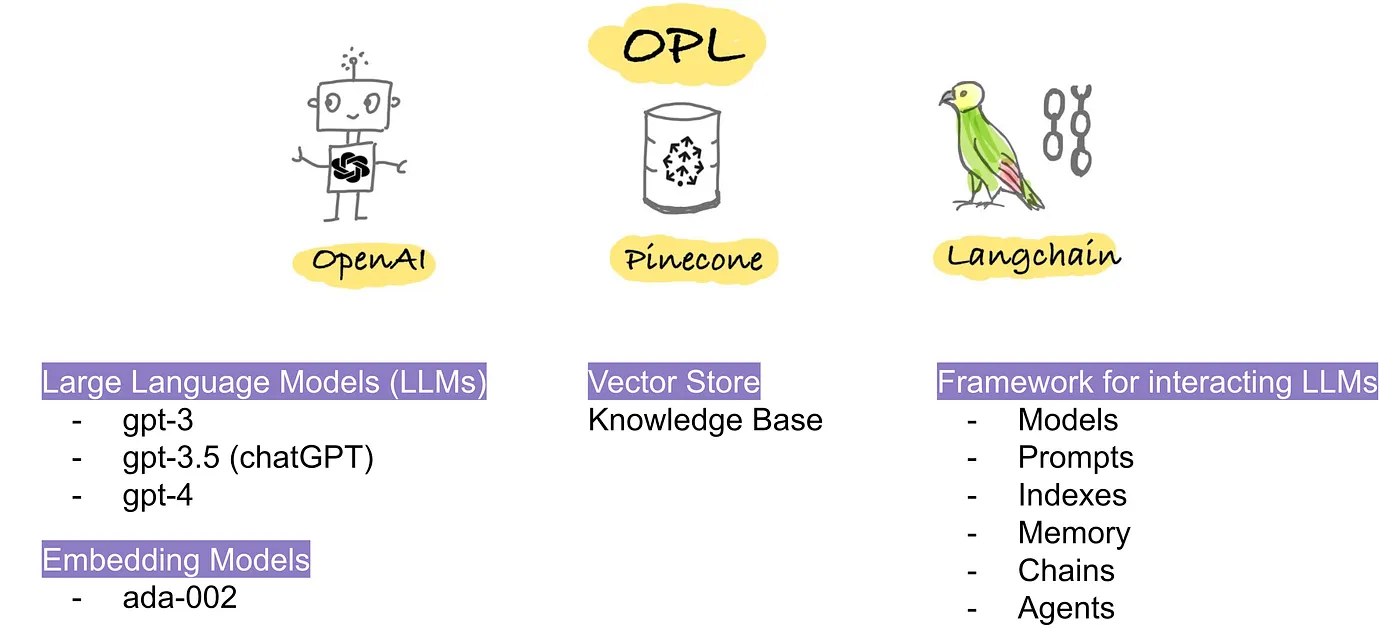
OPL stands for OpenAI, Pinecone, and Langchain, which has increasingly become the industry solution to overcome the two limitations of LLMs:
- LLMs hallucination: chatGPT will sometimes provide wrong answers with overconfidence. One of the underlying causes is that those language models are trained to predict the next word very effectively, or the next token to be precise. Given an input text, chatGPT will return words with high probability, which doesn’t mean that chatGPT has reasoning ability.
- Less up-to-date knowledge: chatGPT’s training data is limited to internet data prior to Sep 2021. Therefore, it will produce less desirable answers if your questions are about recent trends or topics.
The common solution is to add a knowledge base on top of LLMs and use Langchain as a framework to build the pipeline. The essential components of each technology can be summarized below:
- OpenAI:
– provides API access to powerful LLMs such as chatGPT and gpt-4
– provides embedding models to convert text to embeddings. - Pinecone: it provides embedding vector storage, semantic similarity comparison, and fast retrieval.
- Langchain: it comprises 6 modules (
Models,Prompts,Indexes,Memory,ChainsandAgents).
–Modelsoffers flexibility in embedding models, chat models, and LLMs, including but not limited to OpenAI’s offerings. You can also use other models from Hugging Face like BLOOM and FLAN-T5.
–Memory: there are a variety of ways to allow chatbots to remember past conversation memory. From my experience, entity memory works well and is efficient.
–Chains: If you’re new to Langchain, Chains is a great starting point. It follows a pipeline-like structure to process user input, select the LLM model, apply a Prompt template, and search the relevant context from the knowledge base.
Next, I’ll walk through the app I built using the OPL stack.
The app I built is called chatOutside , which has two primary sections:
- chatGPT: lets you chat with chatGPT directly, and the format is similar to a Q&A app, where you receive a single input and output at a time.
- chatOutside: allows you to chat with a version of chatGPT with expert knowledge of Outdoor activities and trends. The format is more like a chatbot style, where all messages are recorded as the conversation progresses. I’ve also included a section that provides source links, which can boost user confidence and is always useful to have.
As you can see, if you ask the same question: “What’re the best running shoes in 2023? My budget is around $200”. chatGPT will say “as an AI language model, I don’t have access to information from the future.” While chatOutside will provide you with more up-to-date answers, along with source links.

There are three major steps involved in the development process:
- Step 1: Build an Outside Knowledge Base in Pinecone
- Step 2: Use Langchain for Question & Answering Service
- Step 3: Build our app in Streamlit
Implementation details for each step are discussed below.
Step 1: Build an Outside Knowledge Base in Pinecone
- Step 1.1: I connected to our Outside catalog database and selected articles published between January 1st, 2022, and March 29th, 2023. This provided us with approximately 20,000 records.

Next, we need to perform two data transformations.
- Step 1.2: convert the above dataframe to a list of dictionaries to ensure data can be upserted correctly into Pinecone.
# Convert dataframe to a list of dict for Pinecone data upsert
data = df_item.to_dict('records')
- Step 1.3: Split the
contentinto smaller chunks using Langchain’sRecursiveCharacterTextSplitter. The benefit of breaking down documents into smaller chunks is twofold:
– A typical article might be more than 1000 characters, which is very long. Imagine we want to retrieve top-3 articles as context to prompt the chatGPT, we could easily hit the 4000 token limit.
– Smaller chunks provide more relevant information, resulting in better context to prompt chatGPT.
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=20,
length_function=tiktoken_len,
separators=["\n\n", "\n", " ", ""]
)
After splitting, each record’s content was broken down into multiple chunks, each having less than 400 tokens.

One thing worth noting is that the text splitter used is called RecursiveCharacterTextSplitter , which is recommended use by Harrison Chase, the creator of Langchain. The basic idea is to first split by the paragraph, then split by sentence, with overlapping (20 tokens). This helps preserve meaningful information and context from the surrounding sentences.
- Step 1.4: Upsert data to Pinecone. The below code is adapted from James Briggs’s wonderful tutorial.
import pinecone
from langchain.embeddings.openai import OpenAIEmbeddings# 0. Initialize Pinecone Client
with open('./credentials.yml', 'r') as file:
cre = yaml.safe_load(file)
# pinecone API
pinecone_api_key = cre['pinecone']['apikey']
pinecone.init(api_key=pinecone_api_key, environment="us-west1-gcp")
# 1. Create a new index
index_name = 'outside-chatgpt'
# 2. Use OpenAI's ada-002 as embedding model
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(
document_model_name=model_name,
query_model_name=model_name,
openai_api_key=OPENAI_API_KEY
)
embed_dimension = 1536
# 3. check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():
# if does not exist, create index
pinecone.create_index(
name=index_name,
metric='cosine',
dimension=embed_dimension
)
# 3. Connect to index
index = pinecone.Index(index_name)
We batch upload and embed all articles. which took about 20 minutes to upsert 20k records. Be sure to adjust the tqdmimport accordingly based on your env (you don’t need to import both!)
# If using terminal
from tqdm.auto import tqdm# If using in Jupyter notebook
from tqdm.autonotebook import tqdm
from uuid import uuid4
batch_limit = 100
texts = []
metadatas = []
for i, record in enumerate(tqdm(data)):
# 1. Get metadata fields for this record
metadata = {
'item_uuid': str(record['id']),
'source': record['url'],
'title': record['title']
}
# 2. Create chunks from the record text
record_texts = text_splitter.split_text(record['content'])
# 3. Create individual metadata dicts for each chunk
record_metadatas = [{
"chunk": j, "text": text, **metadata
} for j, text in enumerate(record_texts)]
# 4. Append these to current batches
texts.extend(record_texts)
metadatas.extend(record_metadatas)
# 5. Special case: if we have reached the batch_limit we can add texts
if len(texts) >= batch_limit:
ids = [str(uuid4()) for _ in range(len(texts))]
embeds = embed.embed_documents(texts)
index.upsert(vectors=zip(ids, embeds, metadatas))
texts = []
metadatas = []
After upserting the Outside articles data, we can inspect our pinecone index by using index.describe_index_stats() . One of the stats to pay attention to is index_fullness, which was 0.2 in our case. This means the Pinecone pod was 20% full, suggesting that a single p1 pod can store approximately 100k articles.

Step 2: Use Langchain for Question & Answering Service
Note: Langchain updates so fast these days, the version used below code is 0.0.118 .

The above sketchnote illustrates how data flows during the inference stage:
- The user asks a question: “What are the best running shoes in 2023?”.
- The question is converted into embedding using the
ada-002model. - The user question embedding is compared with all vectors stored in Pinecone using
similarity_searchfunction, which retrieves the top 3 text chunks that are most likely to answer the question. - Langchain then passes the top 3 text chunks as
context, along with the user question to gpt-3.5 (ChatCompletion) to generate the answers.
All can be achieved with less than 30 lines of code:
from langchain.vectorstores import Pinecone
from langchain.chains import VectorDBQAWithSourcesChain
from langchain.embeddings.openai import OpenAIEmbeddings# 1. Specify Pinecone as Vectorstore
# =======================================
# 1.1 get pinecone index name
index = pinecone.Index(index_name) #'outside-chatgpt'
# 1.2 specify embedding model
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(
document_model_name=model_name,
query_model_name=model_name,
openai_api_key=OPENAI_API_KEY
)
# 1.3 provides text_field
text_field = "text"
vectorstore = Pinecone(
index, embed.embed_query, text_field
)
# 2. Wrap the chain as a function
qa_with_sources = VectorDBQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
vectorstore=vectorstore
)
Now we can test by asking a hiking-related question: “Can you recommend some advanced hiking trails with views of water in California bay area?”

Step 3: Build our app in Streamlit
After verifying the logic is working in Jupyter notebook, we can assemble everything together and build a frontend using streamlit. In our streamlit app, there are two python files:
– app.py : the main python file for frontend and power the app
– utils.py : the supporting function which will be called by app.py
Here’s what my utils.py looks like:
import pinecone
import streamlit as st
from langchain.chains import VectorDBQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings# ------OpenAI: LLM---------------
OPENAI_API_KEY = st.secrets["OPENAI_KEY"]
llm = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-3.5-turbo',
temperature=0.0
)
# ------OpenAI: Embed model-------------
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(
document_model_name=model_name,
query_model_name=model_name,
openai_api_key=OPENAI_API_KEY
)
# --- Pinecone ------
pinecone_api_key = st.secrets["PINECONE_API_KEY"]
pinecone.init(api_key=pinecone_api_key, environment="us-west1-gcp")
index_name = "outside-chatgpt"
index = pinecone.Index(index_name)
text_field = "text"
vectorstore = Pinecone(index, embed.embed_query, text_field)
# ======= Langchain ChatDBQA with source chain =======
def qa_with_sources(query):
qa = VectorDBQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
vectorstore=vectorstore
)
response = qa(query)
return response
And finally, here’s what my app.pylooks like:
import os
import openai
from PIL import Image
from streamlit_chat import message
from utils import *openai.api_key = st.secrets["OPENAI_KEY"]
# For Langchain
os.environ["OPENAI_API_KEY"] = openai.api_key
# ==== Section 1: Streamlit Settings ======
with st.sidebar:
st.markdown("# Welcome to chatOutside 🙌")
st.markdown(
"**chatOutside** allows you to talk to version of **chatGPT** \n"
"that has access to latest Outside content! \n"
)
st.markdown(
"Unlike chatGPT, chatOutside can't make stuff up\n"
"and will answer from Outside knowledge base. \n"
)
st.markdown("👩🏫 Developer: Wen Yang")
st.markdown("---")
st.markdown("# Under The Hood 🎩 🐇")
st.markdown("How to Prevent Large Language Model (LLM) hallucination?")
st.markdown("- **Pinecone**: vector database for Outside knowledge")
st.markdown("- **Langchain**: to remember the context of the conversation")
# Homepage title
st.title("chatOutside: Outside + ChatGPT")
# Hero Image
image = Image.open('VideoBkg_08.jpg')
st.image(image, caption='Get Outside!')
st.header("chatGPT 🤖")
# ====== Section 2: ChatGPT only ======
def chatgpt(prompt):
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{"role": "system",
"content": "You are a friendly and helpful assistant. "
"Answer the question as truthfully as possible. "
"If unsure, say you don't know."},
{"role": "user", "content": prompt},
],
temperature=0,
)["choices"][0]["message"]["content"]
return res
input_gpt = st.text_input(label='Chat here! 💬')
output_gpt = st.text_area(label="Answered by chatGPT:",
value=chatgpt(input_gpt), height=200)
# ========= End of Section 2 ===========
# ========== Section 3: chatOutside ============================
st.header("chatOutside 🏕️")
def chatoutside(query):
# start chat with chatOutside
try:
response = qa_with_sources(query)
answer = response['answer']
source = response['sources']
except Exception as e:
print("I'm afraid your question failed! This is the error: ")
print(e)
return None
if len(answer) > 0:
return answer, source
else:
return None
# ============================================================
# ========== Section 4. Display ChatOutside in chatbot style ===========
if 'generated' not in st.session_state:
st.session_state['generated'] = []
if 'past' not in st.session_state:
st.session_state['past'] = []
if 'source' not in st.session_state:
st.session_state['source'] = []
def clear_text():
st.session_state["input"] = ""
# We will get the user's input by calling the get_text function
def get_text():
input_text = st.text_input('Chat here! 💬', key="input")
return input_text
user_input = get_text()
if user_input:
# source contain urls from Outside
output, source = chatoutside(user_input)
# store the output
st.session_state.past.append(user_input)
st.session_state.generated.append(output)
st.session_state.source.append(source)
# Display source urls
st.write(source)
if st.session_state['generated']:
for i in range(len(st.session_state['generated'])-1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state['past'][i], is_user=True,
avatar_style="big-ears", key=str(i) + '_user')
OPL: OpenAI, Pinecone, and Lanchain for knowledge-based AI assistant
I remember a month ago, Eugene Yan posted a poll on Linkedin:
Are you feeling the FOMO from not working on LLMs/Generative AI?
Most answered “Yes”. It’s easy to understand why, given the sweeping attention generated by chatGPT and now the release of gpt-4. People describe the rise of Large Language Models (LLMs) feels like the iPhone moment. Yet I think there’s really no need to feel the FOMO. Consider this: missing out on the opportunity to develop iPhones doesn’t preclude the ample potential for creating innovative iPhone apps. So too with LLMs. We have just entered the dawn of a new era and now it’s the perfect time to harness the magic of integrating LLMs to build powerful applications.
In this post, I’ll cover below topics:
- What is the OPL stack?
- How to use the OPL to build chatGPT with domain knowledge? (Essential components with code walkthrough)
- Production considerations
- Common misconceptions
OPL stands for OpenAI, Pinecone, and Langchain, which has increasingly become the industry solution to overcome the two limitations of LLMs:
- LLMs hallucination: chatGPT will sometimes provide wrong answers with overconfidence. One of the underlying causes is that those language models are trained to predict the next word very effectively, or the next token to be precise. Given an input text, chatGPT will return words with high probability, which doesn’t mean that chatGPT has reasoning ability.
- Less up-to-date knowledge: chatGPT’s training data is limited to internet data prior to Sep 2021. Therefore, it will produce less desirable answers if your questions are about recent trends or topics.
The common solution is to add a knowledge base on top of LLMs and use Langchain as a framework to build the pipeline. The essential components of each technology can be summarized below:
- OpenAI:
– provides API access to powerful LLMs such as chatGPT and gpt-4
– provides embedding models to convert text to embeddings. - Pinecone: it provides embedding vector storage, semantic similarity comparison, and fast retrieval.
- Langchain: it comprises 6 modules (
Models,Prompts,Indexes,Memory,ChainsandAgents).
–Modelsoffers flexibility in embedding models, chat models, and LLMs, including but not limited to OpenAI’s offerings. You can also use other models from Hugging Face like BLOOM and FLAN-T5.
–Memory: there are a variety of ways to allow chatbots to remember past conversation memory. From my experience, entity memory works well and is efficient.
–Chains: If you’re new to Langchain, Chains is a great starting point. It follows a pipeline-like structure to process user input, select the LLM model, apply a Prompt template, and search the relevant context from the knowledge base.
Next, I’ll walk through the app I built using the OPL stack.
The app I built is called chatOutside , which has two primary sections:
- chatGPT: lets you chat with chatGPT directly, and the format is similar to a Q&A app, where you receive a single input and output at a time.
- chatOutside: allows you to chat with a version of chatGPT with expert knowledge of Outdoor activities and trends. The format is more like a chatbot style, where all messages are recorded as the conversation progresses. I’ve also included a section that provides source links, which can boost user confidence and is always useful to have.
As you can see, if you ask the same question: “What’re the best running shoes in 2023? My budget is around $200”. chatGPT will say “as an AI language model, I don’t have access to information from the future.” While chatOutside will provide you with more up-to-date answers, along with source links.
There are three major steps involved in the development process:
- Step 1: Build an Outside Knowledge Base in Pinecone
- Step 2: Use Langchain for Question & Answering Service
- Step 3: Build our app in Streamlit
Implementation details for each step are discussed below.
Step 1: Build an Outside Knowledge Base in Pinecone
- Step 1.1: I connected to our Outside catalog database and selected articles published between January 1st, 2022, and March 29th, 2023. This provided us with approximately 20,000 records.
Next, we need to perform two data transformations.
- Step 1.2: convert the above dataframe to a list of dictionaries to ensure data can be upserted correctly into Pinecone.
# Convert dataframe to a list of dict for Pinecone data upsert
data = df_item.to_dict('records')
- Step 1.3: Split the
contentinto smaller chunks using Langchain’sRecursiveCharacterTextSplitter. The benefit of breaking down documents into smaller chunks is twofold:
– A typical article might be more than 1000 characters, which is very long. Imagine we want to retrieve top-3 articles as context to prompt the chatGPT, we could easily hit the 4000 token limit.
– Smaller chunks provide more relevant information, resulting in better context to prompt chatGPT.
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=20,
length_function=tiktoken_len,
separators=["\n\n", "\n", " ", ""]
)
After splitting, each record’s content was broken down into multiple chunks, each having less than 400 tokens.
One thing worth noting is that the text splitter used is called RecursiveCharacterTextSplitter , which is recommended use by Harrison Chase, the creator of Langchain. The basic idea is to first split by the paragraph, then split by sentence, with overlapping (20 tokens). This helps preserve meaningful information and context from the surrounding sentences.
- Step 1.4: Upsert data to Pinecone. The below code is adapted from James Briggs’s wonderful tutorial.
import pinecone
from langchain.embeddings.openai import OpenAIEmbeddings# 0. Initialize Pinecone Client
with open('./credentials.yml', 'r') as file:
cre = yaml.safe_load(file)
# pinecone API
pinecone_api_key = cre['pinecone']['apikey']
pinecone.init(api_key=pinecone_api_key, environment="us-west1-gcp")
# 1. Create a new index
index_name = 'outside-chatgpt'
# 2. Use OpenAI's ada-002 as embedding model
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(
document_model_name=model_name,
query_model_name=model_name,
openai_api_key=OPENAI_API_KEY
)
embed_dimension = 1536
# 3. check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():
# if does not exist, create index
pinecone.create_index(
name=index_name,
metric='cosine',
dimension=embed_dimension
)
# 3. Connect to index
index = pinecone.Index(index_name)
We batch upload and embed all articles. which took about 20 minutes to upsert 20k records. Be sure to adjust the tqdmimport accordingly based on your env (you don’t need to import both!)
# If using terminal
from tqdm.auto import tqdm# If using in Jupyter notebook
from tqdm.autonotebook import tqdm
from uuid import uuid4
batch_limit = 100
texts = []
metadatas = []
for i, record in enumerate(tqdm(data)):
# 1. Get metadata fields for this record
metadata = {
'item_uuid': str(record['id']),
'source': record['url'],
'title': record['title']
}
# 2. Create chunks from the record text
record_texts = text_splitter.split_text(record['content'])
# 3. Create individual metadata dicts for each chunk
record_metadatas = [{
"chunk": j, "text": text, **metadata
} for j, text in enumerate(record_texts)]
# 4. Append these to current batches
texts.extend(record_texts)
metadatas.extend(record_metadatas)
# 5. Special case: if we have reached the batch_limit we can add texts
if len(texts) >= batch_limit:
ids = [str(uuid4()) for _ in range(len(texts))]
embeds = embed.embed_documents(texts)
index.upsert(vectors=zip(ids, embeds, metadatas))
texts = []
metadatas = []
After upserting the Outside articles data, we can inspect our pinecone index by using index.describe_index_stats() . One of the stats to pay attention to is index_fullness, which was 0.2 in our case. This means the Pinecone pod was 20% full, suggesting that a single p1 pod can store approximately 100k articles.
Step 2: Use Langchain for Question & Answering Service
Note: Langchain updates so fast these days, the version used below code is 0.0.118 .
The above sketchnote illustrates how data flows during the inference stage:
- The user asks a question: “What are the best running shoes in 2023?”.
- The question is converted into embedding using the
ada-002model. - The user question embedding is compared with all vectors stored in Pinecone using
similarity_searchfunction, which retrieves the top 3 text chunks that are most likely to answer the question. - Langchain then passes the top 3 text chunks as
context, along with the user question to gpt-3.5 (ChatCompletion) to generate the answers.
All can be achieved with less than 30 lines of code:
from langchain.vectorstores import Pinecone
from langchain.chains import VectorDBQAWithSourcesChain
from langchain.embeddings.openai import OpenAIEmbeddings# 1. Specify Pinecone as Vectorstore
# =======================================
# 1.1 get pinecone index name
index = pinecone.Index(index_name) #'outside-chatgpt'
# 1.2 specify embedding model
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(
document_model_name=model_name,
query_model_name=model_name,
openai_api_key=OPENAI_API_KEY
)
# 1.3 provides text_field
text_field = "text"
vectorstore = Pinecone(
index, embed.embed_query, text_field
)
# 2. Wrap the chain as a function
qa_with_sources = VectorDBQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
vectorstore=vectorstore
)
Now we can test by asking a hiking-related question: “Can you recommend some advanced hiking trails with views of water in California bay area?”
Step 3: Build our app in Streamlit
After verifying the logic is working in Jupyter notebook, we can assemble everything together and build a frontend using streamlit. In our streamlit app, there are two python files:
– app.py : the main python file for frontend and power the app
– utils.py : the supporting function which will be called by app.py
Here’s what my utils.py looks like:
import pinecone
import streamlit as st
from langchain.chains import VectorDBQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings# ------OpenAI: LLM---------------
OPENAI_API_KEY = st.secrets["OPENAI_KEY"]
llm = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-3.5-turbo',
temperature=0.0
)
# ------OpenAI: Embed model-------------
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(
document_model_name=model_name,
query_model_name=model_name,
openai_api_key=OPENAI_API_KEY
)
# --- Pinecone ------
pinecone_api_key = st.secrets["PINECONE_API_KEY"]
pinecone.init(api_key=pinecone_api_key, environment="us-west1-gcp")
index_name = "outside-chatgpt"
index = pinecone.Index(index_name)
text_field = "text"
vectorstore = Pinecone(index, embed.embed_query, text_field)
# ======= Langchain ChatDBQA with source chain =======
def qa_with_sources(query):
qa = VectorDBQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
vectorstore=vectorstore
)
response = qa(query)
return response
And finally, here’s what my app.pylooks like:
import os
import openai
from PIL import Image
from streamlit_chat import message
from utils import *openai.api_key = st.secrets["OPENAI_KEY"]
# For Langchain
os.environ["OPENAI_API_KEY"] = openai.api_key
# ==== Section 1: Streamlit Settings ======
with st.sidebar:
st.markdown("# Welcome to chatOutside 🙌")
st.markdown(
"**chatOutside** allows you to talk to version of **chatGPT** \n"
"that has access to latest Outside content! \n"
)
st.markdown(
"Unlike chatGPT, chatOutside can't make stuff up\n"
"and will answer from Outside knowledge base. \n"
)
st.markdown("👩🏫 Developer: Wen Yang")
st.markdown("---")
st.markdown("# Under The Hood 🎩 🐇")
st.markdown("How to Prevent Large Language Model (LLM) hallucination?")
st.markdown("- **Pinecone**: vector database for Outside knowledge")
st.markdown("- **Langchain**: to remember the context of the conversation")
# Homepage title
st.title("chatOutside: Outside + ChatGPT")
# Hero Image
image = Image.open('VideoBkg_08.jpg')
st.image(image, caption='Get Outside!')
st.header("chatGPT 🤖")
# ====== Section 2: ChatGPT only ======
def chatgpt(prompt):
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{"role": "system",
"content": "You are a friendly and helpful assistant. "
"Answer the question as truthfully as possible. "
"If unsure, say you don't know."},
{"role": "user", "content": prompt},
],
temperature=0,
)["choices"][0]["message"]["content"]
return res
input_gpt = st.text_input(label='Chat here! 💬')
output_gpt = st.text_area(label="Answered by chatGPT:",
value=chatgpt(input_gpt), height=200)
# ========= End of Section 2 ===========
# ========== Section 3: chatOutside ============================
st.header("chatOutside 🏕️")
def chatoutside(query):
# start chat with chatOutside
try:
response = qa_with_sources(query)
answer = response['answer']
source = response['sources']
except Exception as e:
print("I'm afraid your question failed! This is the error: ")
print(e)
return None
if len(answer) > 0:
return answer, source
else:
return None
# ============================================================
# ========== Section 4. Display ChatOutside in chatbot style ===========
if 'generated' not in st.session_state:
st.session_state['generated'] = []
if 'past' not in st.session_state:
st.session_state['past'] = []
if 'source' not in st.session_state:
st.session_state['source'] = []
def clear_text():
st.session_state["input"] = ""
# We will get the user's input by calling the get_text function
def get_text():
input_text = st.text_input('Chat here! 💬', key="input")
return input_text
user_input = get_text()
if user_input:
# source contain urls from Outside
output, source = chatoutside(user_input)
# store the output
st.session_state.past.append(user_input)
st.session_state.generated.append(output)
st.session_state.source.append(source)
# Display source urls
st.write(source)
if st.session_state['generated']:
for i in range(len(st.session_state['generated'])-1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state['past'][i], is_user=True,
avatar_style="big-ears", key=str(i) + '_user')
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.