
Can LLMs Replace Data Analysts? Learning to Collaborate
Part 3: Teaching the LLM agent to pose and address clarifying questions
Collaboration is a core aspect of analysts’ day-to-day jobs. Frequently, we encounter high-level requests such as, “What will be the impact of the new feature?” or “What is going on with retention?". Before jumping to writing queries and pulling data, we usually need to define tasks more clearly: talk to stakeholders, understand their needs thoroughly, and determine how we can provide the best assistance.
So, for an LLM-powered analyst, mastering the art of posing and addressing follow-up questions is essential since I can’t imagine an analyst working in isolation.
In this article, we will teach our LLM analyst to ask clarifying questions and follow long conversations. We will talk in detail about different memory implementations in LangChain.
We’ve already discussed many aspects of LLM agents in the previous articles. So, let me quickly summarise them. Also, since our last implementation, LangChain has been updated, and it’s time to catch up.
LLM agents recap
Let’s quickly recap what we’ve already learned about LLM agents.
- We’ve discussed how to empower LLMs with external tools. It helps them overcome limitations (i.e., poor performance on maths tasks) and get access to the world (i.e., your database or internet).
- The core idea of the LLM agents is to use LLM as a reasoning engine to define the set of actions to take and leverage tools. So, in this approach, you don’t need to hardcode the logic and just let LLM make decisions on the following steps to achieve the final goal.
- We’ve implemented an LLM-powered agent that can work with SQL databases and answer user requests.
Since our last iteration, LangChain has been updated from 0.0.350 to 0.1.0 version. The documentation and best practices for LLM agents have changed. This domain is developing quickly, so it’s no surprise the tools are evolving, too. Let’s quickly recap.
First, LangChain has significantly improved the documentation, and now you can find a clear, structured view of the supported agent types and the differences between them.
It’s easier for models to work with tools with just one input parameter, so some agents have such limitations. However, in most real-life cases, tools have several arguments. So, let’s focus on the agents capable of working with multiple inputs. It leaves us just three possible options.
- It’s the most cutting-edge type of agent since it supports chat history, tools with multiple inputs and even parallel function calling.
- You can use it with the recent OpenAI models (after 1106) since they were fine-tuned for tool calling.
- OpenAI functions agents are close to OpenAI tools but are slightly different under the hood.
- Such agents don’t support parallel function calling.
- You can use recent OpenAI models that were fine-tuned to work with functions (the complete list is here) or compatible open-source LLMs.
- This approach is similar to ReAct. It instructs an agent to follow the Thought -> Action -> Observation framework.
- It doesn’t support parallel function calling, just as OpenAI functions approach.
- You can use it with any model.
Also, you can notice that the experimental agent types we tried in the previous article, such as BabyAGI, Plan-and-execute and AutoGPT, are still not part of the suggested options. They might be included later (I hope), but for now I wouldn’t recommend using them in production.
After reading the new documentation, I’ve finally realised the difference between OpenAI tools and OpenAI functions agents. With the OpenAI tools approach, an agent can call multiple tools at the same iterations, while other agent types don’t support such functionality. Let’s see how it works and why it matters.
Let’s create two agents — OpenAI tools and OpenAI functions. We will empower them with two tools:
- get_monthly_active_users returns the number of active customers for city and month. To simplify debugging, we will be using a dummy function for it. In practice, we would go to our database to retrieve this data.
- percentage_difference calculates the difference between two metrics.
Let’s create tools from Python functions and specify schemas using Pydantic. If you want to recap this topic, you can find a detailed explanation in the first article of this series.
from pydantic import BaseModel, Field
from typing import Optional
from langchain.agents import tool
# define tools
class Filters(BaseModel):
month: str = Field(description="Month of the customer's activity in the format %Y-%m-%d")
city: Optional[str] = Field(description="The city of residence for customers (by default no filter)",
enum = ["London", "Berlin", "Amsterdam", "Paris"])
@tool(args_schema=Filters)
def get_monthly_active_users(month: str, city: str = None) -> int:
"""Returns the number of active customers for the specified month.
Pass month in format %Y-%m-01.
"""
coefs = {
'London': 2,
'Berlin': 1,
'Amsterdam': 0.5,
'Paris': 0.25
}
dt = datetime.datetime.strptime(month, '%Y-%m-%d')
total = dt.year + 10*dt.month
if city is None:
return total
else:
return int(round(coefs[city]*total))
class Metrics(BaseModel):
metric1: float = Field(description="Base metric value to calculate the difference")
metric2: float = Field(description="New metric value that we compare with the baseline")
@tool(args_schema=Metrics)
def percentage_difference(metric1: float, metric2: float) -> float:
"""Calculates the percentage difference between metrics"""
return (metric2 - metric1)/metric1*100
# save them into a list for future use
tools = [get_monthly_active_users, percentage_difference]
To test a tool, you can execute it using the following commands.
get_monthly_active_users.run({"month": "2023-12-01", "city": "London"})
# 4286
get_monthly_active_users.run({"month": "2023-12-01", "city": "Berlin"})
# 2183
Let’s create a prompt template that we will be using for the agents. It will consist of a system message, a user request and a placeholder for tools’ observations. Our prompt has two variables — input and agent_scratchpad.
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# defining prompt
system_message = '''
You are working as a product analyst for a e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
'''
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
Let’s use new LangChain functions to create agents — create_openai_functions_agent and create_openai_tools_agent. To create an agent, we need to specify parameters — an LLM model, a list of tools and a prompt template. On top of the agents, we also need to create agent executors.
from langchain.agents import create_openai_tools_agent, create_openai_functions_agent, AgentExecutor
from langchain_community.chat_models import ChatOpenAI
# OpenAI tools agent
agent_tools = create_openai_tools_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
agent_tools_executor = AgentExecutor(
agent = agent_tools, tools = tools,
verbose = True, max_iterations = 10,
early_stopping_method = 'generate')
# OpenAI functions agent
agent_funcs = create_openai_functions_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
agent_funcs_executor = AgentExecutor(
agent = agent_funcs, tools = tools,
verbose = True, max_iterations = 10,
early_stopping_method = 'generate')
I used the ChatGPT 4 Turbo model since it’s capable of working with OpenAI tools. We will need some complex reasoning, thus ChatGPT 3.5 will likely be insufficient in our use case.
We’ve created two agent executors, and it’s time to try them in practice and compare results.
user_question = 'What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?'
agent_funcs_executor.invoke(
{'input': user_question,
'agent_scratchpad': []})
agent_tools_executor.invoke(
{'input': user_question,
'agent_scratchpad': []})
# In December 2023, the number of customers in London was 4,286, and in Berlin,
# it was 2,143. The percentage difference between the number of customers
# in London and Berlin is -50.0%, indicating that London had twice
# as many customers as Berlin.
Interestingly, the agents returned the same correct result. It’s not so surprising since we used low temperatures.
Both agents performed well, but let’s compare how they work under the hood. We can switch on debug mode (execute langchain.debug = True for it) and see the number of LLM calls and tokens used.
You can see the scheme depicting the calls for two agents below.
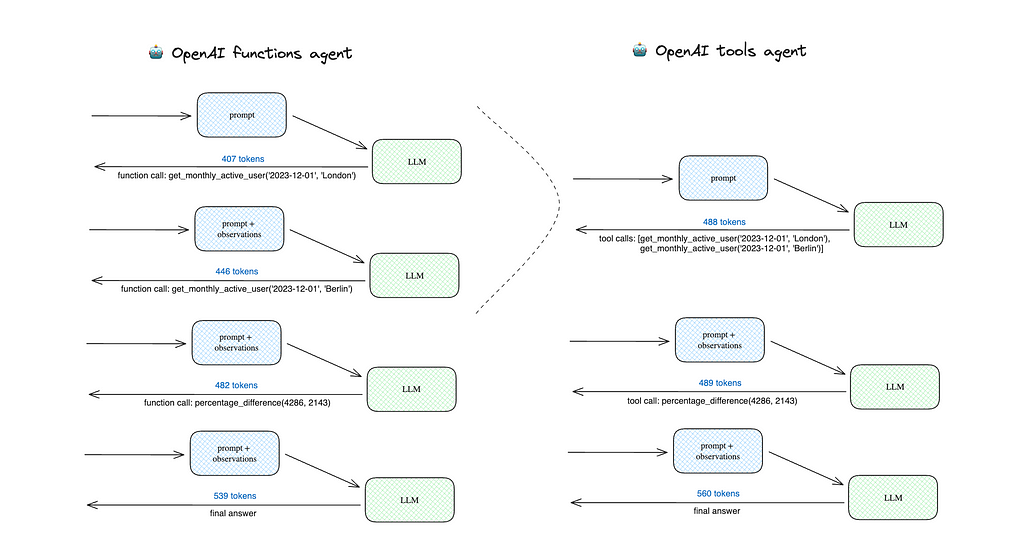
The OpenAI functions agent did 4 LLM calls, while the OpenAI tools agent made just 3 ones because it could get MAUs for London and Berlin in one iteration. Overall, it leads to a lower number of used tokens and, hence, lower price:
- OpenAI tools agent — 1 537 tokens
- OpenAI functions agent — 1 874 tokens (+21.9%).
So, I would recommend you consider using OpenAI tools agents. You can use it with both ChatGPT 4 Turbo and ChatGPT 3.5 Turbo.
We’ve revised our previous implementation of an LLM-powered analyst. So, it’s time to move on and teach our agent to pose follow-up questions.
Asking clarifying questions
We would like to teach our agent to ask the user clarifying questions. The most reasonable way to teach LLM agents something new is to give them a tool. So, LangChain has a handy tool — Human.
There’s no rocket science in it. You can see the implementation here. We can easily implement it ourselves, but it’s a good practice to use tools provided by the framework.
Let’s initiate such a tool. We don’t need to specify any arguments unless we want to customise something, for example, a tool’s description or input function. See more details in the documentation.
from langchain.tools import HumanInputRun
human_tool = HumanInputRun()
We can look at the default tool’s description and arguments.
print(human_tool.description)
# You can ask a human for guidance when you think you got stuck or
# you are not sure what to do next. The input should be a question
# for the human.
print(human_tool.args)
# {'query': {'title': 'Query', 'type': 'string'}}
Let’s add this new tool to our agent’s toolkit and reinitialise the agent. I’ve also tweaked the system message to encourage the model to ask follow-up questions when it doesn’t have enough details.
# tweaking the system message
system_message = '''
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
If you don't have enough context to answer question, you should ask user the follow-up question to get needed info.
You don't make any assumptions about data requests. For example, if dates are not specified, you ask follow up questions.
Always use tool if you have follow-up questions to the request.
'''
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# updated list of tools
tools = [get_monthly_active_users, percentage_difference, human_tool]
# reinitialising the agent
human_input_agent = create_openai_tools_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
human_input_agent_executor = AgentExecutor(
agent = human_input_agent, tools = tools,
verbose = True, max_iterations = 10, # early stopping criteria
early_stopping_method = 'generate')
Now, it’s time to try it out. The agent just returned the output, asking for a specific time period. It doesn’t work as we expected.
human_input_agent_executor.invoke(
{'input': 'What are the number of customers in London?',
'agent_scratchpad': []})
# {'input': 'What are the number of customers in London?',
# 'agent_scratchpad': [],
# 'output': 'To provide you with the number of customers in London,
# I need to know the specific time period you are interested in.
# Are you looking for the number of monthly active users in London
# for a particular month, or do you need a different metric?
# Please provide the time frame or specify the metric you need.'}
The agent didn’t understand that it needed to use this tool. Let’s try to fix it and change the Human tool’s description so that it is more evident for the agent when it should use this tool.
human_tool_desc = '''
You can use this tool to ask the user for the details related to the request.
Always use this tool if you have follow-up questions.
The input should be a question for the user.
Be concise, polite and professional when asking the questions.
'''
human_tool = HumanInputRun(
description = human_tool_desc
)
After the change, the agent used the Human tool and asked for a specific time period. I provided an answer, and we got the correct result — 4 286 active customers in December 2023 for London.
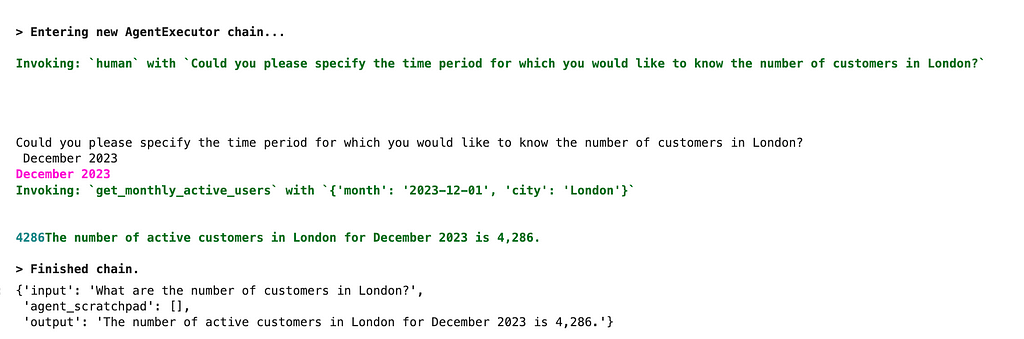
So, as usual, tweaking the prompt helps. Now, it works pretty well. Remember that creating a good prompt is an iterative process, and it’s worth trying several options and evaluating results.
We’ve taught our LLM agent to ask for details and take them into account while working on data requests.
However, it’s only part of the collaboration. In real life, analysts often get follow-up questions after providing any research. Now, our agent can’t keep up the conversation and address the new questions from the user since it doesn’t have any memory. It’s time to learn more about the tools we have to implement memory in LangChain.
Actually, we already have a concept of memory in the current agent implementation. Our agent stores the story of its interactions with tools in the agent_scratchpad variable. We need to remember not only interactions with tools but also the conversation with the user.
Memory in LangChain
By default, LLMs are stateless and don’t remember previous conversations. If we want our agent to be able to have long discussions, we need to store the chat history somehow. LangChain provides a bunch of different memory implementations. Let’s learn more about it.
ConversationBufferMemory is the most straightforward approach. It just saves all the context you pushed to it. Let’s try it out: initialise a memory object and add a couple of conversation exchanges.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
# Human: Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
This approach works well. However, in many cases, it’s not feasible to pass the whole previous conversation to LLM on each iteration because:
- we might hit the context length limit,
- LLMs are not so good at dealing with long texts,
- we are paying for tokens, and such an approach might become quite expensive.
So there’s another implementation, ConversationBufferWindowMemory, that can store a limited number of conversation exchanges. So, it will store only the last k iterations.
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k = 1)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# Human: Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
We’ve used k = 1 just to show how it works. In real-life use cases, you will likely use much higher thresholds.
This approach can help you to keep chat history size manageable. However, it has a drawback: you can still hit the context size limit since you don’t control the chat history size in tokens.
To address this challenge, we can use ConversationTokenBufferMemory. It won’t split statements, so don’t worry about incomplete sentences in the context.
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
max_token_limit=100)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
# <Comment from the author>: the whole info since it fits the memory size
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
# <Comment from the author>: only the last response from the LLM fit the memory size
In this case, we need to pass an LLM model to initialise a memory object because LangChain needs to know the model to calculate the number of tokens.
In all approaches we’ve discussed above, we stored the exact conversation or at least parts of it. However, we don’t need to do it. For example, people usually don’t remember their conversations exactly. I can’t reproduce yesterday’s meeting’s content word by word, but I remember the main ideas and action items — a summary. Since humans are GI (General Intelligence), it sounds reasonable to leverage this strategy for LLMs as well. LangChain implemented it in ConversationSummaryBufferMemory.
Let’s try it in practice: initiate the memory and save the first conversation exchange. We got the whole conversation since our current context hasn’t hit the threshold.
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
max_token_limit=100)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.load_memory_variables({})['history'])
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
Let’s add one more conversation exchange. Now, we’ve hit the limit: the whole chat history exceeds 100 tokens, the specified threshold. So, only the last AI response is stored (it’s within the 100 tokens limit). For earlier messages, the summary has been generated.
The summary is stored with the prefix System: .
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.load_memory_variables({})['history'])
# System: The AI had a good weekend learning about LLM agents and describes it as magical. The human requests assistance with an urgent task from the CEO, asking for the absolute numbers and percentage difference of customers in London and Berlin in December 2023.
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
As usual, it’s interesting to see how it works under the hood, and we can understand it in a debug mode. When the conversation exceeded the limit on the memory size, the LLM call was made with the following prompt:
Human: Progressively summarize the lines of conversation provided,
adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI
thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full
potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks
artificial intelligence is a force for good because it will help humans reach
their full potential.
END OF EXAMPLE
Current summary:
New lines of conversation:
Human: Hey, how are you? How was your weekend?
AI: Good morning, I had a wonder time off and spent the whole day learning
about LLM agents. It works like magic.
Human: Could you please help me with the urgent request from our CEO.
What are the absolute numbers and the percentage difference between
the number of customers in London and Berlin in December 2023?
New summary:
It implements the progressive update of the summary. So, it uses fewer tokens, not passing the whole chat history every time to get an updated summary. That’s reasonable.
Also, LangChain has more advanced memory types:
- Vector data memory — storing texts’ embeddings in vector stores (similar to what we did in RAG — Retrieval Augmented Generation), then we could retrieve the most relevant bits of information and include them into the conversation. This memory type would be the most useful for long-term conversations.
- Entity memories to remember details about specific entities (i.e. people).
You can even combine different memory types. For example, you can use conversation memory + entity memory to keep details about the tables in the database. To learn more about combined memory, consult the documentation.
We won’t discuss these more advanced approaches in this article.
We’ve got an understanding of how we can implement memory in LangChain. Now, it’s time to use this knowledge for our agent.
Adding memory to the agent
Let’s try to see how the current agent implementation works with the follow-up questions from the user.
human_input_agent_executor.invoke(
{'input': 'What are the number of customers in London in December 2023?',
'agent_scratchpad': []})
For this call, the agent executed a tool and returned the correct answer: The number of active customers in London in December 2023 was 4,286.
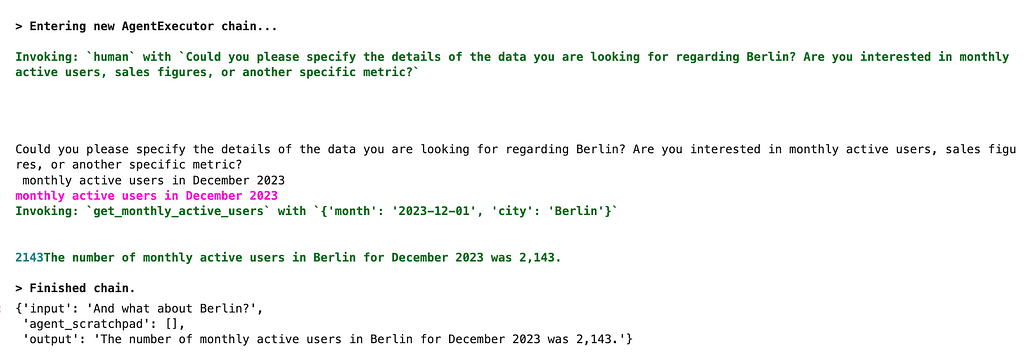
We know the number of users for London. It would be interesting to learn about Berlin as well. Let’s ask our agent.
human_input_agent_executor.invoke(
{'input': 'And what about Berlin?',
'agent_scratchpad': []})
Surprisingly, the agent was able to handle this question correctly. However, it had to clarify the questions using the Human tool, and the user had to provide the same information (not the best customer experience).
Now, let’s start holding the chart history for the agent. I will use a simple buffer that stores the complete previous conversation, but you could use a more complex strategy.
First, we need to add a placeholder for the chat history to the prompt template. I’ve marked it as optional.
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history", optional=True),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
Next, let’s initialise a memory and save a small talk (it’s impossible to have a chat without a small talk, you know). Note that we’ve specified the same memory_key = 'chat_history’ as in the prompt template.
memory = ConversationBufferMemory(
return_messages=True, memory_key="chat_history")
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
Let’s try the previous use case once again and ask the LLM analyst about the number of users in London.
human_input_agent_executor.invoke(
{'input': 'What is the number of customers in London?'})
# {'input': 'What is the number of customers in London?',
# 'chat_history': [
# HumanMessage(content='Hey, how are you? How was your weekend?'),
# AIMessage(content='Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.'),
# HumanMessage(content='What is the number of customers in London?'),
# AIMessage(content='The number of active customers in London for December 2023 is 4,286.')],
# 'output': 'The number of active customers in London for December 2023 is 4,286.'}
After answering the question, "Could you please specify the time period for which you would like to know the number of customers in London?", we got the correct answer and the conversation history between the agent and the user with all the previous statements, including the small talk.
If we ask the follow-up question about Berlin now, the agent will just return the number for December 2023 without asking for details because it already has it in the context.
human_input_agent_executor.invoke(
{'input': 'What is the number for Berlin?'})
# {'input': 'What is the number for Berlin?',
# 'chat_history': [HumanMessage(content='Hey, how are you? How was your weekend?'),
# AIMessage(content='Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.'),
# HumanMessage(content='What is the number of customers in London?'),
# AIMessage(content='The number of active customers in London for December 2023 is 4,286.'),
# HumanMessage(content='What is the number for Berlin?'),
# AIMessage(content='The number of active customers in Berlin for December 2023 is 2,143.')],
# 'output': 'The number of active customers in Berlin for December 2023 is 2,143.'}
Let’s look at the prompt for the first LLM call. We can see that all chat history was actually passed to the model.
System:
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions
based on the data you provide. So, you are extremely accurate
with the numbers you provided.
If you're not sure about the details of the request, you don't provide
the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
If you don't have enough context to answer question, you should ask user
the follow-up question to get needed info.
You don't make any assumptions about data requests. For example,
if dates are not specified, you ask follow up questions.
Always use tool if you have follow-up questions to the request.
Human: Hey, how are you? How was your weekend?
AI: Good morning, I had a wonderful time off and spent the whole day
learning about LLM agents. It works like magic.
Human: What is the number of customers in London?
AI: The number of active customers in London for December 2023 is 4,286.
Human: What is the number for Berlin?
So, we’ve added the chat history to our LLM-powered analyst, and now it can handle somewhat long conversations and answer follow-up questions. That’s a significant achievement.
You can find the complete code on GitHub.
Summary
In this article, we’ve taught our LLM-powered analyst how to collaborate with users. Now, it can ask clarifying questions if there’s not enough information in the initial request and even answer the follow-up question from the user.
We’ve achieved such a significant improvement:
- by adding a tool — Human input that allows to ask the user,
- by adding a memory to the agent that can store the chat history.
Our agent has mastered collaboration now. In one of the following articles, we will try to take the next step and combine LLM agents with RAG (Retrieval Augmented Generation). We’ve understood how to query databases and communicate with the users. The next step is to start using knowledge bases. Stay tuned!
Thank you a lot for reading this article. I hope it was insightful to you. If you have any follow-up questions or comments, please leave them in the comments section.
Can LLMs Replace Data Analysts? Learning to Collaborate was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Part 3: Teaching the LLM agent to pose and address clarifying questions

Collaboration is a core aspect of analysts’ day-to-day jobs. Frequently, we encounter high-level requests such as, “What will be the impact of the new feature?” or “What is going on with retention?". Before jumping to writing queries and pulling data, we usually need to define tasks more clearly: talk to stakeholders, understand their needs thoroughly, and determine how we can provide the best assistance.
So, for an LLM-powered analyst, mastering the art of posing and addressing follow-up questions is essential since I can’t imagine an analyst working in isolation.
In this article, we will teach our LLM analyst to ask clarifying questions and follow long conversations. We will talk in detail about different memory implementations in LangChain.
We’ve already discussed many aspects of LLM agents in the previous articles. So, let me quickly summarise them. Also, since our last implementation, LangChain has been updated, and it’s time to catch up.
LLM agents recap
Let’s quickly recap what we’ve already learned about LLM agents.
- We’ve discussed how to empower LLMs with external tools. It helps them overcome limitations (i.e., poor performance on maths tasks) and get access to the world (i.e., your database or internet).
- The core idea of the LLM agents is to use LLM as a reasoning engine to define the set of actions to take and leverage tools. So, in this approach, you don’t need to hardcode the logic and just let LLM make decisions on the following steps to achieve the final goal.
- We’ve implemented an LLM-powered agent that can work with SQL databases and answer user requests.
Since our last iteration, LangChain has been updated from 0.0.350 to 0.1.0 version. The documentation and best practices for LLM agents have changed. This domain is developing quickly, so it’s no surprise the tools are evolving, too. Let’s quickly recap.
First, LangChain has significantly improved the documentation, and now you can find a clear, structured view of the supported agent types and the differences between them.
It’s easier for models to work with tools with just one input parameter, so some agents have such limitations. However, in most real-life cases, tools have several arguments. So, let’s focus on the agents capable of working with multiple inputs. It leaves us just three possible options.
- It’s the most cutting-edge type of agent since it supports chat history, tools with multiple inputs and even parallel function calling.
- You can use it with the recent OpenAI models (after 1106) since they were fine-tuned for tool calling.
- OpenAI functions agents are close to OpenAI tools but are slightly different under the hood.
- Such agents don’t support parallel function calling.
- You can use recent OpenAI models that were fine-tuned to work with functions (the complete list is here) or compatible open-source LLMs.
- This approach is similar to ReAct. It instructs an agent to follow the Thought -> Action -> Observation framework.
- It doesn’t support parallel function calling, just as OpenAI functions approach.
- You can use it with any model.
Also, you can notice that the experimental agent types we tried in the previous article, such as BabyAGI, Plan-and-execute and AutoGPT, are still not part of the suggested options. They might be included later (I hope), but for now I wouldn’t recommend using them in production.
After reading the new documentation, I’ve finally realised the difference between OpenAI tools and OpenAI functions agents. With the OpenAI tools approach, an agent can call multiple tools at the same iterations, while other agent types don’t support such functionality. Let’s see how it works and why it matters.
Let’s create two agents — OpenAI tools and OpenAI functions. We will empower them with two tools:
- get_monthly_active_users returns the number of active customers for city and month. To simplify debugging, we will be using a dummy function for it. In practice, we would go to our database to retrieve this data.
- percentage_difference calculates the difference between two metrics.
Let’s create tools from Python functions and specify schemas using Pydantic. If you want to recap this topic, you can find a detailed explanation in the first article of this series.
from pydantic import BaseModel, Field
from typing import Optional
from langchain.agents import tool
# define tools
class Filters(BaseModel):
month: str = Field(description="Month of the customer's activity in the format %Y-%m-%d")
city: Optional[str] = Field(description="The city of residence for customers (by default no filter)",
enum = ["London", "Berlin", "Amsterdam", "Paris"])
@tool(args_schema=Filters)
def get_monthly_active_users(month: str, city: str = None) -> int:
"""Returns the number of active customers for the specified month.
Pass month in format %Y-%m-01.
"""
coefs = {
'London': 2,
'Berlin': 1,
'Amsterdam': 0.5,
'Paris': 0.25
}
dt = datetime.datetime.strptime(month, '%Y-%m-%d')
total = dt.year + 10*dt.month
if city is None:
return total
else:
return int(round(coefs[city]*total))
class Metrics(BaseModel):
metric1: float = Field(description="Base metric value to calculate the difference")
metric2: float = Field(description="New metric value that we compare with the baseline")
@tool(args_schema=Metrics)
def percentage_difference(metric1: float, metric2: float) -> float:
"""Calculates the percentage difference between metrics"""
return (metric2 - metric1)/metric1*100
# save them into a list for future use
tools = [get_monthly_active_users, percentage_difference]
To test a tool, you can execute it using the following commands.
get_monthly_active_users.run({"month": "2023-12-01", "city": "London"})
# 4286
get_monthly_active_users.run({"month": "2023-12-01", "city": "Berlin"})
# 2183
Let’s create a prompt template that we will be using for the agents. It will consist of a system message, a user request and a placeholder for tools’ observations. Our prompt has two variables — input and agent_scratchpad.
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# defining prompt
system_message = '''
You are working as a product analyst for a e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
'''
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
Let’s use new LangChain functions to create agents — create_openai_functions_agent and create_openai_tools_agent. To create an agent, we need to specify parameters — an LLM model, a list of tools and a prompt template. On top of the agents, we also need to create agent executors.
from langchain.agents import create_openai_tools_agent, create_openai_functions_agent, AgentExecutor
from langchain_community.chat_models import ChatOpenAI
# OpenAI tools agent
agent_tools = create_openai_tools_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
agent_tools_executor = AgentExecutor(
agent = agent_tools, tools = tools,
verbose = True, max_iterations = 10,
early_stopping_method = 'generate')
# OpenAI functions agent
agent_funcs = create_openai_functions_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
agent_funcs_executor = AgentExecutor(
agent = agent_funcs, tools = tools,
verbose = True, max_iterations = 10,
early_stopping_method = 'generate')
I used the ChatGPT 4 Turbo model since it’s capable of working with OpenAI tools. We will need some complex reasoning, thus ChatGPT 3.5 will likely be insufficient in our use case.
We’ve created two agent executors, and it’s time to try them in practice and compare results.
user_question = 'What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?'
agent_funcs_executor.invoke(
{'input': user_question,
'agent_scratchpad': []})
agent_tools_executor.invoke(
{'input': user_question,
'agent_scratchpad': []})
# In December 2023, the number of customers in London was 4,286, and in Berlin,
# it was 2,143. The percentage difference between the number of customers
# in London and Berlin is -50.0%, indicating that London had twice
# as many customers as Berlin.
Interestingly, the agents returned the same correct result. It’s not so surprising since we used low temperatures.
Both agents performed well, but let’s compare how they work under the hood. We can switch on debug mode (execute langchain.debug = True for it) and see the number of LLM calls and tokens used.
You can see the scheme depicting the calls for two agents below.
The OpenAI functions agent did 4 LLM calls, while the OpenAI tools agent made just 3 ones because it could get MAUs for London and Berlin in one iteration. Overall, it leads to a lower number of used tokens and, hence, lower price:
- OpenAI tools agent — 1 537 tokens
- OpenAI functions agent — 1 874 tokens (+21.9%).
So, I would recommend you consider using OpenAI tools agents. You can use it with both ChatGPT 4 Turbo and ChatGPT 3.5 Turbo.
We’ve revised our previous implementation of an LLM-powered analyst. So, it’s time to move on and teach our agent to pose follow-up questions.
Asking clarifying questions
We would like to teach our agent to ask the user clarifying questions. The most reasonable way to teach LLM agents something new is to give them a tool. So, LangChain has a handy tool — Human.
There’s no rocket science in it. You can see the implementation here. We can easily implement it ourselves, but it’s a good practice to use tools provided by the framework.
Let’s initiate such a tool. We don’t need to specify any arguments unless we want to customise something, for example, a tool’s description or input function. See more details in the documentation.
from langchain.tools import HumanInputRun
human_tool = HumanInputRun()
We can look at the default tool’s description and arguments.
print(human_tool.description)
# You can ask a human for guidance when you think you got stuck or
# you are not sure what to do next. The input should be a question
# for the human.
print(human_tool.args)
# {'query': {'title': 'Query', 'type': 'string'}}
Let’s add this new tool to our agent’s toolkit and reinitialise the agent. I’ve also tweaked the system message to encourage the model to ask follow-up questions when it doesn’t have enough details.
# tweaking the system message
system_message = '''
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
If you don't have enough context to answer question, you should ask user the follow-up question to get needed info.
You don't make any assumptions about data requests. For example, if dates are not specified, you ask follow up questions.
Always use tool if you have follow-up questions to the request.
'''
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# updated list of tools
tools = [get_monthly_active_users, percentage_difference, human_tool]
# reinitialising the agent
human_input_agent = create_openai_tools_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
human_input_agent_executor = AgentExecutor(
agent = human_input_agent, tools = tools,
verbose = True, max_iterations = 10, # early stopping criteria
early_stopping_method = 'generate')
Now, it’s time to try it out. The agent just returned the output, asking for a specific time period. It doesn’t work as we expected.
human_input_agent_executor.invoke(
{'input': 'What are the number of customers in London?',
'agent_scratchpad': []})
# {'input': 'What are the number of customers in London?',
# 'agent_scratchpad': [],
# 'output': 'To provide you with the number of customers in London,
# I need to know the specific time period you are interested in.
# Are you looking for the number of monthly active users in London
# for a particular month, or do you need a different metric?
# Please provide the time frame or specify the metric you need.'}
The agent didn’t understand that it needed to use this tool. Let’s try to fix it and change the Human tool’s description so that it is more evident for the agent when it should use this tool.
human_tool_desc = '''
You can use this tool to ask the user for the details related to the request.
Always use this tool if you have follow-up questions.
The input should be a question for the user.
Be concise, polite and professional when asking the questions.
'''
human_tool = HumanInputRun(
description = human_tool_desc
)
After the change, the agent used the Human tool and asked for a specific time period. I provided an answer, and we got the correct result — 4 286 active customers in December 2023 for London.
So, as usual, tweaking the prompt helps. Now, it works pretty well. Remember that creating a good prompt is an iterative process, and it’s worth trying several options and evaluating results.
We’ve taught our LLM agent to ask for details and take them into account while working on data requests.
However, it’s only part of the collaboration. In real life, analysts often get follow-up questions after providing any research. Now, our agent can’t keep up the conversation and address the new questions from the user since it doesn’t have any memory. It’s time to learn more about the tools we have to implement memory in LangChain.
Actually, we already have a concept of memory in the current agent implementation. Our agent stores the story of its interactions with tools in the agent_scratchpad variable. We need to remember not only interactions with tools but also the conversation with the user.
Memory in LangChain
By default, LLMs are stateless and don’t remember previous conversations. If we want our agent to be able to have long discussions, we need to store the chat history somehow. LangChain provides a bunch of different memory implementations. Let’s learn more about it.
ConversationBufferMemory is the most straightforward approach. It just saves all the context you pushed to it. Let’s try it out: initialise a memory object and add a couple of conversation exchanges.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
# Human: Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
This approach works well. However, in many cases, it’s not feasible to pass the whole previous conversation to LLM on each iteration because:
- we might hit the context length limit,
- LLMs are not so good at dealing with long texts,
- we are paying for tokens, and such an approach might become quite expensive.
So there’s another implementation, ConversationBufferWindowMemory, that can store a limited number of conversation exchanges. So, it will store only the last k iterations.
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k = 1)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# Human: Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
We’ve used k = 1 just to show how it works. In real-life use cases, you will likely use much higher thresholds.
This approach can help you to keep chat history size manageable. However, it has a drawback: you can still hit the context size limit since you don’t control the chat history size in tokens.
To address this challenge, we can use ConversationTokenBufferMemory. It won’t split statements, so don’t worry about incomplete sentences in the context.
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
max_token_limit=100)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
# <Comment from the author>: the whole info since it fits the memory size
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
# <Comment from the author>: only the last response from the LLM fit the memory size
In this case, we need to pass an LLM model to initialise a memory object because LangChain needs to know the model to calculate the number of tokens.
In all approaches we’ve discussed above, we stored the exact conversation or at least parts of it. However, we don’t need to do it. For example, people usually don’t remember their conversations exactly. I can’t reproduce yesterday’s meeting’s content word by word, but I remember the main ideas and action items — a summary. Since humans are GI (General Intelligence), it sounds reasonable to leverage this strategy for LLMs as well. LangChain implemented it in ConversationSummaryBufferMemory.
Let’s try it in practice: initiate the memory and save the first conversation exchange. We got the whole conversation since our current context hasn’t hit the threshold.
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
max_token_limit=100)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.load_memory_variables({})['history'])
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
Let’s add one more conversation exchange. Now, we’ve hit the limit: the whole chat history exceeds 100 tokens, the specified threshold. So, only the last AI response is stored (it’s within the 100 tokens limit). For earlier messages, the summary has been generated.
The summary is stored with the prefix System: .
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.load_memory_variables({})['history'])
# System: The AI had a good weekend learning about LLM agents and describes it as magical. The human requests assistance with an urgent task from the CEO, asking for the absolute numbers and percentage difference of customers in London and Berlin in December 2023.
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
As usual, it’s interesting to see how it works under the hood, and we can understand it in a debug mode. When the conversation exceeded the limit on the memory size, the LLM call was made with the following prompt:
Human: Progressively summarize the lines of conversation provided,
adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI
thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full
potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks
artificial intelligence is a force for good because it will help humans reach
their full potential.
END OF EXAMPLE
Current summary:
New lines of conversation:
Human: Hey, how are you? How was your weekend?
AI: Good morning, I had a wonder time off and spent the whole day learning
about LLM agents. It works like magic.
Human: Could you please help me with the urgent request from our CEO.
What are the absolute numbers and the percentage difference between
the number of customers in London and Berlin in December 2023?
New summary:
It implements the progressive update of the summary. So, it uses fewer tokens, not passing the whole chat history every time to get an updated summary. That’s reasonable.
Also, LangChain has more advanced memory types:
- Vector data memory — storing texts’ embeddings in vector stores (similar to what we did in RAG — Retrieval Augmented Generation), then we could retrieve the most relevant bits of information and include them into the conversation. This memory type would be the most useful for long-term conversations.
- Entity memories to remember details about specific entities (i.e. people).
You can even combine different memory types. For example, you can use conversation memory + entity memory to keep details about the tables in the database. To learn more about combined memory, consult the documentation.
We won’t discuss these more advanced approaches in this article.
We’ve got an understanding of how we can implement memory in LangChain. Now, it’s time to use this knowledge for our agent.
Adding memory to the agent
Let’s try to see how the current agent implementation works with the follow-up questions from the user.
human_input_agent_executor.invoke(
{'input': 'What are the number of customers in London in December 2023?',
'agent_scratchpad': []})
For this call, the agent executed a tool and returned the correct answer: The number of active customers in London in December 2023 was 4,286.
We know the number of users for London. It would be interesting to learn about Berlin as well. Let’s ask our agent.
human_input_agent_executor.invoke(
{'input': 'And what about Berlin?',
'agent_scratchpad': []})
Surprisingly, the agent was able to handle this question correctly. However, it had to clarify the questions using the Human tool, and the user had to provide the same information (not the best customer experience).
Now, let’s start holding the chart history for the agent. I will use a simple buffer that stores the complete previous conversation, but you could use a more complex strategy.
First, we need to add a placeholder for the chat history to the prompt template. I’ve marked it as optional.
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history", optional=True),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
Next, let’s initialise a memory and save a small talk (it’s impossible to have a chat without a small talk, you know). Note that we’ve specified the same memory_key = 'chat_history’ as in the prompt template.
memory = ConversationBufferMemory(
return_messages=True, memory_key="chat_history")
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
Let’s try the previous use case once again and ask the LLM analyst about the number of users in London.
human_input_agent_executor.invoke(
{'input': 'What is the number of customers in London?'})
# {'input': 'What is the number of customers in London?',
# 'chat_history': [
# HumanMessage(content='Hey, how are you? How was your weekend?'),
# AIMessage(content='Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.'),
# HumanMessage(content='What is the number of customers in London?'),
# AIMessage(content='The number of active customers in London for December 2023 is 4,286.')],
# 'output': 'The number of active customers in London for December 2023 is 4,286.'}
After answering the question, "Could you please specify the time period for which you would like to know the number of customers in London?", we got the correct answer and the conversation history between the agent and the user with all the previous statements, including the small talk.
If we ask the follow-up question about Berlin now, the agent will just return the number for December 2023 without asking for details because it already has it in the context.
human_input_agent_executor.invoke(
{'input': 'What is the number for Berlin?'})
# {'input': 'What is the number for Berlin?',
# 'chat_history': [HumanMessage(content='Hey, how are you? How was your weekend?'),
# AIMessage(content='Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.'),
# HumanMessage(content='What is the number of customers in London?'),
# AIMessage(content='The number of active customers in London for December 2023 is 4,286.'),
# HumanMessage(content='What is the number for Berlin?'),
# AIMessage(content='The number of active customers in Berlin for December 2023 is 2,143.')],
# 'output': 'The number of active customers in Berlin for December 2023 is 2,143.'}
Let’s look at the prompt for the first LLM call. We can see that all chat history was actually passed to the model.
System:
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions
based on the data you provide. So, you are extremely accurate
with the numbers you provided.
If you're not sure about the details of the request, you don't provide
the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
If you don't have enough context to answer question, you should ask user
the follow-up question to get needed info.
You don't make any assumptions about data requests. For example,
if dates are not specified, you ask follow up questions.
Always use tool if you have follow-up questions to the request.
Human: Hey, how are you? How was your weekend?
AI: Good morning, I had a wonderful time off and spent the whole day
learning about LLM agents. It works like magic.
Human: What is the number of customers in London?
AI: The number of active customers in London for December 2023 is 4,286.
Human: What is the number for Berlin?
So, we’ve added the chat history to our LLM-powered analyst, and now it can handle somewhat long conversations and answer follow-up questions. That’s a significant achievement.
You can find the complete code on GitHub.
Summary
In this article, we’ve taught our LLM-powered analyst how to collaborate with users. Now, it can ask clarifying questions if there’s not enough information in the initial request and even answer the follow-up question from the user.
We’ve achieved such a significant improvement:
- by adding a tool — Human input that allows to ask the user,
- by adding a memory to the agent that can store the chat history.
Our agent has mastered collaboration now. In one of the following articles, we will try to take the next step and combine LLM agents with RAG (Retrieval Augmented Generation). We’ve understood how to query databases and communicate with the users. The next step is to start using knowledge bases. Stay tuned!
Thank you a lot for reading this article. I hope it was insightful to you. If you have any follow-up questions or comments, please leave them in the comments section.
Can LLMs Replace Data Analysts? Learning to Collaborate was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.