
Code Search Using Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is becoming a popular paradigm for bridging the knowledge gap between pre-trained Large Language models and other data sources. For developer productivity, several code copilots help with code completion. Code Search is an age-old problem that can be rethought in the age of RAG. Imagine you are trying to contribute to a new code base (a GitHub repository) for a beginner task. Knowing which file to change and where to make the change can be time-consuming. We’ve all been there. You’re enthusiastic about contributing to a new GitHub repository but overwhelmed. Which file do you modify? Where do you start? For newcomers, the maze of a new codebase can be truly daunting.
Retrieval Augmented Generation for Code Search
The technical solution consists of 2 parts.
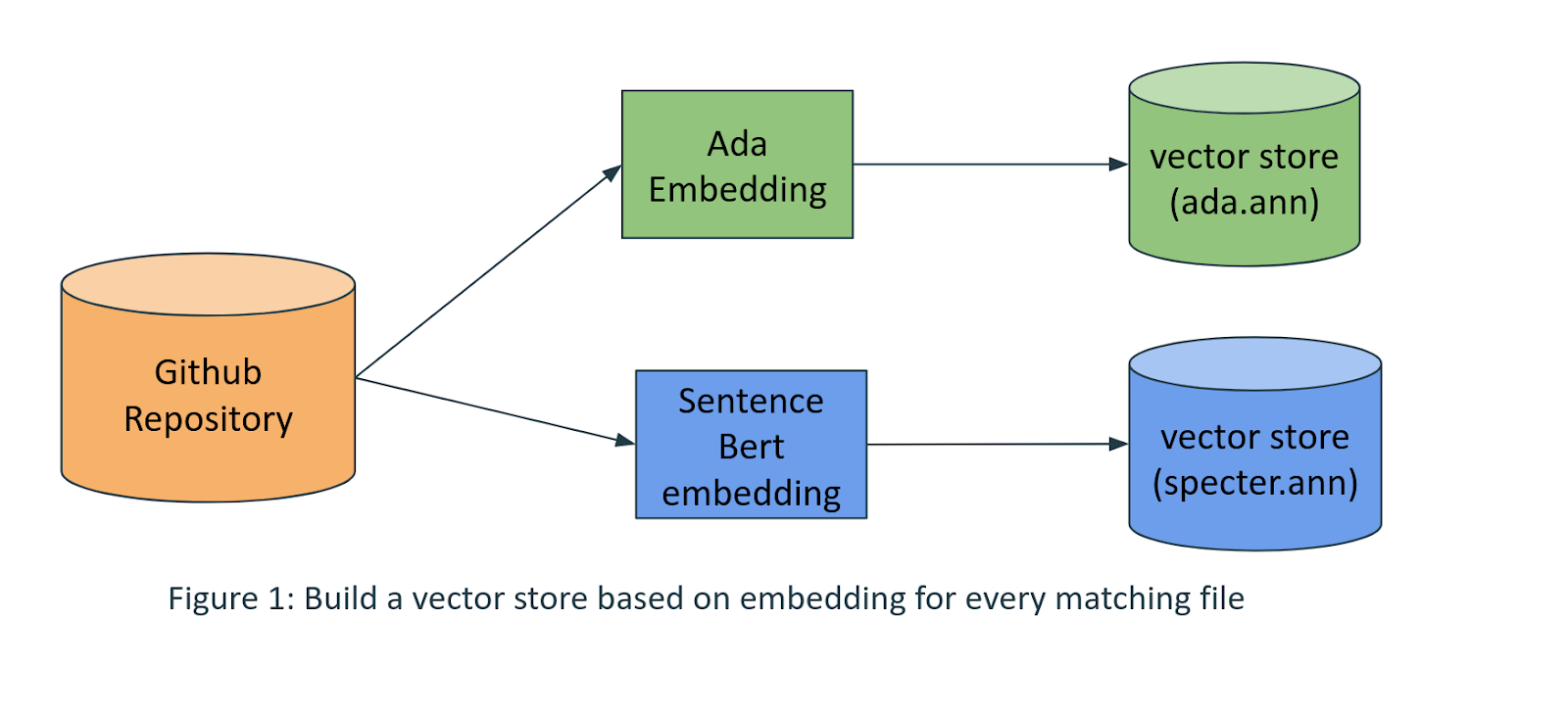
1. Build a vector index generating embedding for every file (eg. .py .java.)
2. Query the vector index and leverage the code interpreter to provide instructions by calling GPT-x.
Building the Vector Index
Once you have a local copy of the GitHub repo, akin to a crawler of web search index,
- Traverse every file matching a regex (*.py, *.sh, *.java)
- Read the content and generate an embedding.
- Using OpenAI’s Ada embedding or Sentence BERT embedding (or both.)
- Build a vector store using annoy.
Instead of choosing a single embedding, if we build multiple vector stores based on different embeddings, it improves the quality of retrieval. (anecdotally) However, there is a cost of maintaining multiple indices.
1. Prepare Your Requirements.txt To Install Necessary Python Packages
pip install -r requirements.txt
annoy==1.17.3
langchain==0.0.279
sentence-transformers==2.2.2
openai==0.28.0
open-interpreter==0.1.62. Walk Through Every File
### Traverse through every file in the directory
def get_files(path):
files = []
for r, d, f in os.walk(path):
for file in f:
if ".py" in file or ".sh" in file or ".java" in file:
files.append(os.path.join(r, file))
return files3. Get OpenAI Ada Embeddings
embeddings = OpenAIEmbeddings(openai_api_key=" <Insert your key>")
# we are getting embeddings for the contents of the file
def get_file_embeddings(path):
try:
text = get_file_contents(path)
ret = embeddings.embed_query(text)
return ret
except:
return None
def get_file_contents(path):
with open(path, 'r') as f:
return f.read()
files = get_files(LOCAL_REPO_GITHUB_PATH)
embeddings_dict = {}
s = set()
for file in files:
e = get_file_embeddings(file)
if (e is None):
print ("Error in generating an embedding for the contents of file: ")
print (file)
s.add(file)
else:
embeddings_dict[file] = e4. Generate the Annoy Index
In Annoy, the metric can be “angular,” “euclidean,” “manhattan,” “hamming,” or “dot.”
annoy_index_t = AnnoyIndex(1536, 'angular')
index_map = {}
i = 0
for file in embeddings_dict:
annoy_index_t.add_item(i, embeddings_dict[file])
index_map[i] = file
i+=1
annoy_index_t.build(len(files))
name = "CodeBase" + "_ada.ann"
annoy_index_t.save(name)
### Maintains a forward map of id -> file name
with open('index_map' + "CodeBase" + '.txt', 'w') as f:
for idx, path in index_map.items():
f.write(f'{idx}\t{path}\n')
We can see the size of indices is proportional to the number of files in the local repository. Size of annoy index generated for popular GitHub repositories.
|
Repository |
File Count (approx as its growing) |
Size |
|
Langchain |
1983+ |
60 MB |
|
Llama Index |
779 |
14 MB |
|
Apache Solr |
5000+ |
328 MB |
|
Local GPT |
8 |
165 KB |
Generate Response With Open Interpreter (Calls GPT-4)
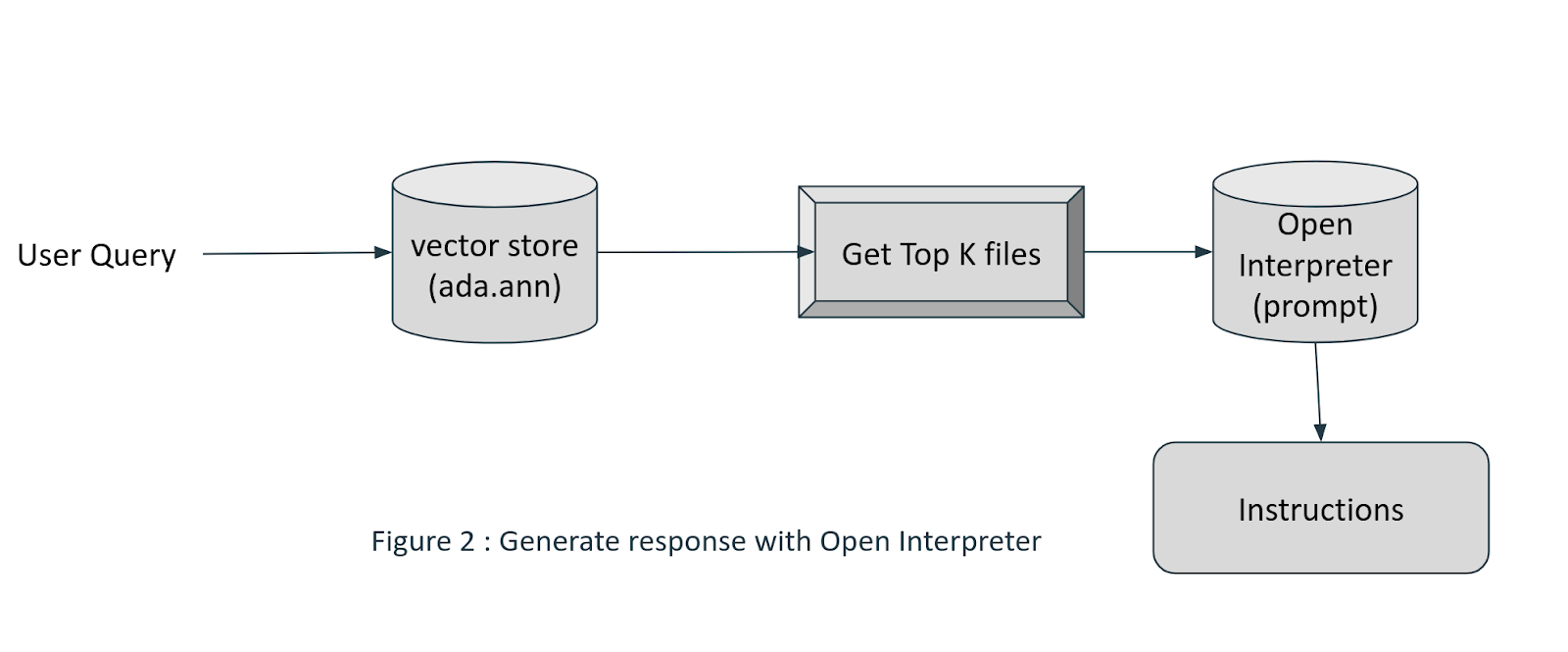
Once the index is built, a simple command line python script can be implemented to ask questions right from the terminal about your codebase. We can leverage Open Interpreter.
One of the reasons to use Open Interpreter instead of us calling GPT-4 or other LLMs directly is because Open-Interpreter allows us to make changes to your file and run commands. It handles interaction with GPT-4.
embeddings = OpenAIEmbeddings(openai_api_key="Your OPEN AI KEY")
query = sys.argv[1] ### Your question
depth = int(sys.argv[2]) ## Number of documents to retrieve from Vector SEarch
name = sys.argv[3] ## Name of your index
### Get Top K files based on nearest neighbor search
def query_top_files(query, top_n=4):
# Load annoy index and index map
t = AnnoyIndex(EMBEDDING_DIM, 'angular')
t.load(name+'_ada.ann')
index_map = load_index_map()
# Get embeddings for the query
query_embedding = get_embeddings_for_text(query)
# Search in the Annoy index
indices, distances = t.get_nns_by_vector(query_embedding, top_n, include_distances=True)
# Fetch file paths for these indices (forward index helps)
files = [(index_map[idx], dist) for idx, dist in zip(indices, distances)]
return files
### Use Open Interpreter to make the call to GPT-4
import interpreter
results = query_top_files(query, depth)
file_content = ""
s = set()
print ("Files you might want to read:")
for path, dist in results:
content = get_file_contents(path)
file_content += "Path : "
file_content += path
if (path not in s):
print (path)
s.add(path)
file_content += "\n"
file_content += content
print( "open interpreter's recommendation")
message = "Take a deep breath. I have a task to complete. Please help with the task below and answer my question. Task : READ THE FILE content below and their paths and answer " + query + "\n" + file_content
interpreter.chat(message)
print ("interpreter's recommendation done. (Risk: LLMs are known to hallucinate)")Anecdotal Results
Langchain
Question: Where should I make changes to add a new summarization prompt?
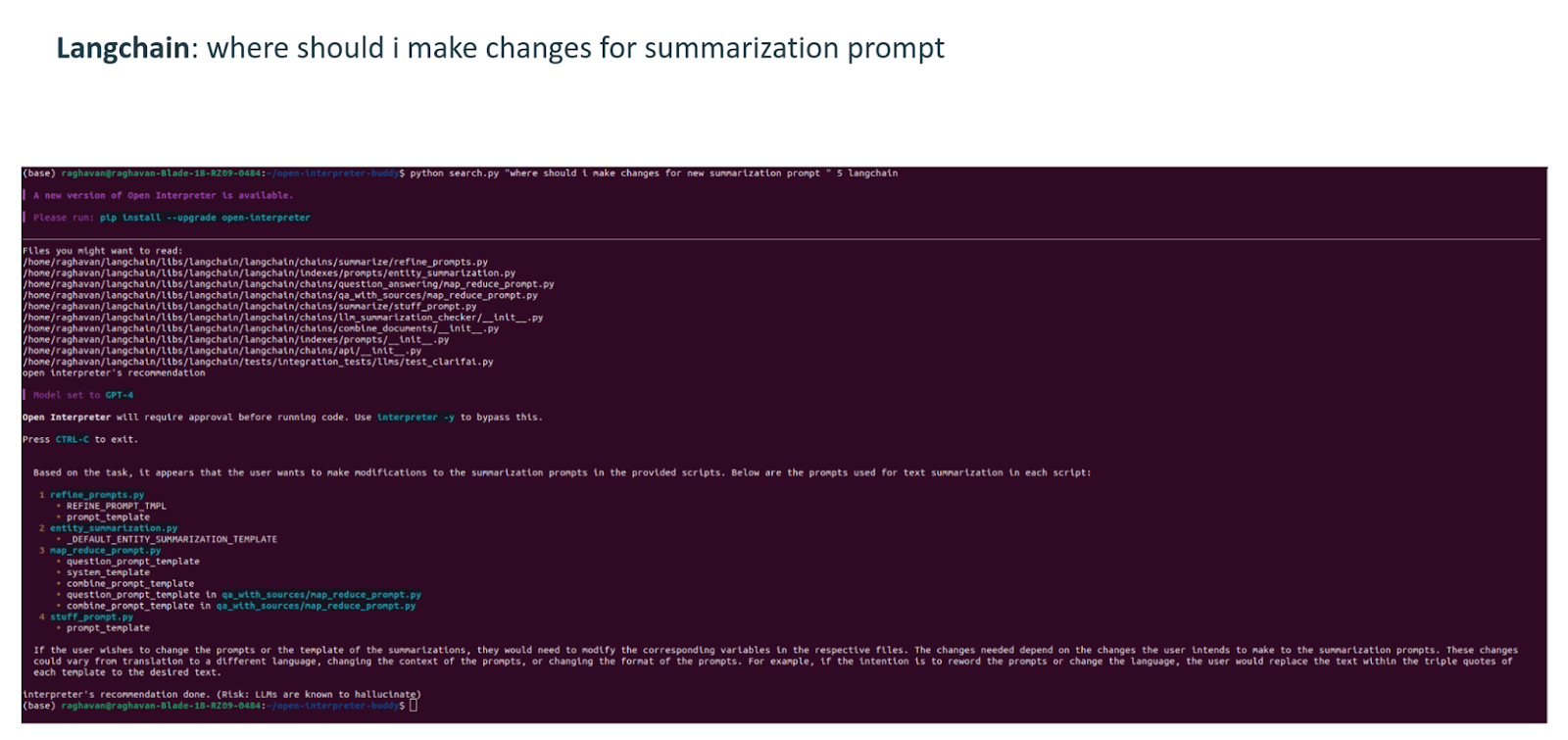
The recommended files to change are;
- refine_prompts.py
- stuff_prompt.py
- map_reduce_prompt.py
- entity_summarization.py
All of these files are indeed related to the summarization prompt in langchain.
Local GPT
Question: Which files should I change, and how do I add support to the new model Falcon 80B?
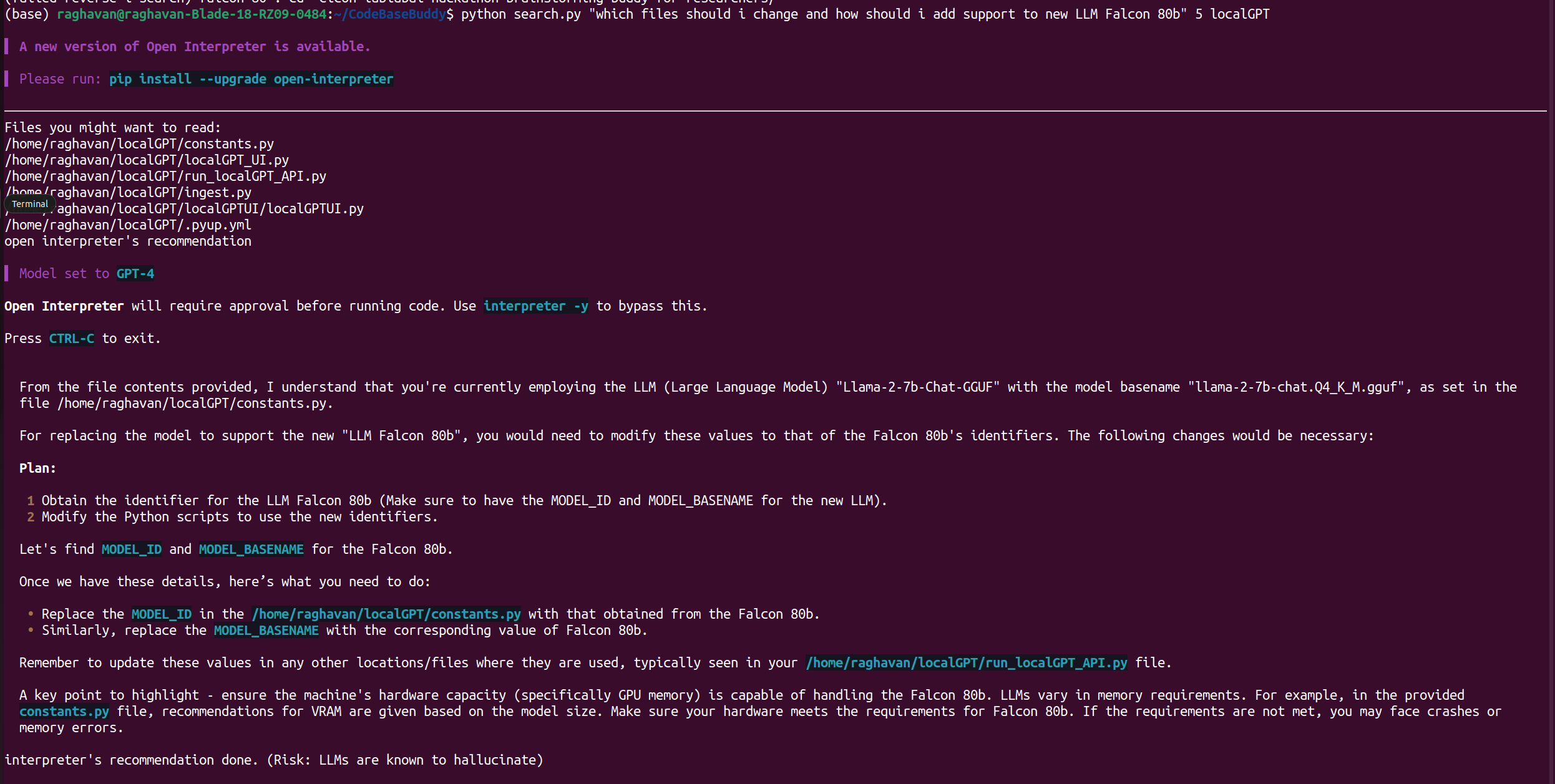
- Open interpreter identifies the files to be changed and gives specific step-by-step instruction for adding Falcon 80 b model to the list of models in constants.py and adding support in the user interface of localGPT_UI.py.
- For specific prompt templates, it recommends to modify the method get_prompt_template in prompt_template_utils.py.
The complete code can be found here.
Conclusion
The advantages of a simple RAG solution like this will help with:
- Accelerated Onboarding: New contributors can quickly get up to speed with the codebase, reducing the onboarding time.
- Reduced Errors: With specific guidance, newcomers are less likely to make mistakes or introduce bugs.
- Increased Engagement: A supportive tool can encourage more contributions from the community, especially those hesitant due to unfamiliarity with the codebase.
- Continuous Learning: Even for experienced developers, the tool can be a means to discover and learn about lesser-known parts of the codebase.
Retrieval Augmented Generation (RAG) is becoming a popular paradigm for bridging the knowledge gap between pre-trained Large Language models and other data sources. For developer productivity, several code copilots help with code completion. Code Search is an age-old problem that can be rethought in the age of RAG. Imagine you are trying to contribute to a new code base (a GitHub repository) for a beginner task. Knowing which file to change and where to make the change can be time-consuming. We’ve all been there. You’re enthusiastic about contributing to a new GitHub repository but overwhelmed. Which file do you modify? Where do you start? For newcomers, the maze of a new codebase can be truly daunting.
Retrieval Augmented Generation for Code Search
The technical solution consists of 2 parts.
1. Build a vector index generating embedding for every file (eg. .py .java.)
2. Query the vector index and leverage the code interpreter to provide instructions by calling GPT-x.
Building the Vector Index
Once you have a local copy of the GitHub repo, akin to a crawler of web search index,
- Traverse every file matching a regex (*.py, *.sh, *.java)
- Read the content and generate an embedding.
- Using OpenAI’s Ada embedding or Sentence BERT embedding (or both.)
- Build a vector store using annoy.
Instead of choosing a single embedding, if we build multiple vector stores based on different embeddings, it improves the quality of retrieval. (anecdotally) However, there is a cost of maintaining multiple indices.
1. Prepare Your Requirements.txt To Install Necessary Python Packages
pip install -r requirements.txt
annoy==1.17.3
langchain==0.0.279
sentence-transformers==2.2.2
openai==0.28.0
open-interpreter==0.1.62. Walk Through Every File
### Traverse through every file in the directory
def get_files(path):
files = []
for r, d, f in os.walk(path):
for file in f:
if ".py" in file or ".sh" in file or ".java" in file:
files.append(os.path.join(r, file))
return files3. Get OpenAI Ada Embeddings
embeddings = OpenAIEmbeddings(openai_api_key=" <Insert your key>")
# we are getting embeddings for the contents of the file
def get_file_embeddings(path):
try:
text = get_file_contents(path)
ret = embeddings.embed_query(text)
return ret
except:
return None
def get_file_contents(path):
with open(path, 'r') as f:
return f.read()
files = get_files(LOCAL_REPO_GITHUB_PATH)
embeddings_dict = {}
s = set()
for file in files:
e = get_file_embeddings(file)
if (e is None):
print ("Error in generating an embedding for the contents of file: ")
print (file)
s.add(file)
else:
embeddings_dict[file] = e4. Generate the Annoy Index
In Annoy, the metric can be “angular,” “euclidean,” “manhattan,” “hamming,” or “dot.”
annoy_index_t = AnnoyIndex(1536, 'angular')
index_map = {}
i = 0
for file in embeddings_dict:
annoy_index_t.add_item(i, embeddings_dict[file])
index_map[i] = file
i+=1
annoy_index_t.build(len(files))
name = "CodeBase" + "_ada.ann"
annoy_index_t.save(name)
### Maintains a forward map of id -> file name
with open('index_map' + "CodeBase" + '.txt', 'w') as f:
for idx, path in index_map.items():
f.write(f'{idx}\t{path}\n')
We can see the size of indices is proportional to the number of files in the local repository. Size of annoy index generated for popular GitHub repositories.
|
Repository |
File Count (approx as its growing) |
Size |
|
Langchain |
1983+ |
60 MB |
|
Llama Index |
779 |
14 MB |
|
Apache Solr |
5000+ |
328 MB |
|
Local GPT |
8 |
165 KB |
Generate Response With Open Interpreter (Calls GPT-4)
Once the index is built, a simple command line python script can be implemented to ask questions right from the terminal about your codebase. We can leverage Open Interpreter.
One of the reasons to use Open Interpreter instead of us calling GPT-4 or other LLMs directly is because Open-Interpreter allows us to make changes to your file and run commands. It handles interaction with GPT-4.
embeddings = OpenAIEmbeddings(openai_api_key="Your OPEN AI KEY")
query = sys.argv[1] ### Your question
depth = int(sys.argv[2]) ## Number of documents to retrieve from Vector SEarch
name = sys.argv[3] ## Name of your index
### Get Top K files based on nearest neighbor search
def query_top_files(query, top_n=4):
# Load annoy index and index map
t = AnnoyIndex(EMBEDDING_DIM, 'angular')
t.load(name+'_ada.ann')
index_map = load_index_map()
# Get embeddings for the query
query_embedding = get_embeddings_for_text(query)
# Search in the Annoy index
indices, distances = t.get_nns_by_vector(query_embedding, top_n, include_distances=True)
# Fetch file paths for these indices (forward index helps)
files = [(index_map[idx], dist) for idx, dist in zip(indices, distances)]
return files
### Use Open Interpreter to make the call to GPT-4
import interpreter
results = query_top_files(query, depth)
file_content = ""
s = set()
print ("Files you might want to read:")
for path, dist in results:
content = get_file_contents(path)
file_content += "Path : "
file_content += path
if (path not in s):
print (path)
s.add(path)
file_content += "\n"
file_content += content
print( "open interpreter's recommendation")
message = "Take a deep breath. I have a task to complete. Please help with the task below and answer my question. Task : READ THE FILE content below and their paths and answer " + query + "\n" + file_content
interpreter.chat(message)
print ("interpreter's recommendation done. (Risk: LLMs are known to hallucinate)")Anecdotal Results
Langchain
Question: Where should I make changes to add a new summarization prompt?
The recommended files to change are;
- refine_prompts.py
- stuff_prompt.py
- map_reduce_prompt.py
- entity_summarization.py
All of these files are indeed related to the summarization prompt in langchain.
Local GPT
Question: Which files should I change, and how do I add support to the new model Falcon 80B?
- Open interpreter identifies the files to be changed and gives specific step-by-step instruction for adding Falcon 80 b model to the list of models in constants.py and adding support in the user interface of localGPT_UI.py.
- For specific prompt templates, it recommends to modify the method get_prompt_template in prompt_template_utils.py.
The complete code can be found here.
Conclusion
The advantages of a simple RAG solution like this will help with:
- Accelerated Onboarding: New contributors can quickly get up to speed with the codebase, reducing the onboarding time.
- Reduced Errors: With specific guidance, newcomers are less likely to make mistakes or introduce bugs.
- Increased Engagement: A supportive tool can encourage more contributions from the community, especially those hesitant due to unfamiliarity with the codebase.
- Continuous Learning: Even for experienced developers, the tool can be a means to discover and learn about lesser-known parts of the codebase.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.