
De-Coded: Understanding Context Windows for Transformer Models
Everything you need to know about how context windows affect Transformer training and usage
The context window is the maximum sequence length that a transformer can process at a time. With the rise of proprietary LLMs that limit the number of tokens and therefore the prompt size — as well as the growing interest in techniques such as Retrieval Augmented Generation (RAG)— understanding the key ideas around context windows and their implications is becoming increasingly important, as this is often cited when discussing different models.
The transformer architecture is a powerful tool for natural language processing, but it has some limitations when it comes to handling long sequences of text. In this article, we will explore how different factors affect the maximum context length that a transformer model can process, and whether bigger is always better when choosing a model for your task.
How many words can I fit into a Transformer?
At the time of writing, models such as the Llama-2 variants have a context length of 4k tokens, GPT-4 turbo has 128k, and Claude 2.1 has 200k! From the number of tokens alone, it can be difficult to envisage how this translates into words; whilst it depends on the tokenizer used, a good rule of thumb is that 100k tokens is approximately 75,000 words. To put that in perspective, we can compare this to some popular literature:
- The Lord of the Rings (J. R. R. Tolkien): 564,187 words, 752k tokens
- Dracula (Bram Stoker): 165,453 words, 220k tokens
- Grimms’ Fairy Tales (Jacob Grimm and Wilhelm Grimm): 104,228 words, 139k tokens
- Frankenstein (Mary Shelley): 78,100 words, 104k tokens
- Harry Potter and the Philosopher’s Stone (J. K. Rowling): 77,423 words, 103k tokens
- Treasure Island (Robert Louis Stevenson): 72,036 words, 96k tokens
- The War of the Worlds (H. G. Wells): 63,194 words, 84k tokens
- The Hound of the Baskervilles (Arthur Conan Doyle): 62,297 words, 83k tokens
- The Jungle Book (Rudyard Kipling): 54,178 words, 72k tokens
To summarise, 100k tokens is roughly equivalent to a short novel, whereas at 200k we can almost fit the entirety of Dracula, a medium sized volume! To ingest a large volume, such as The Lord of the Rings, we would need 6 requests to GPT-4 and only 4 calls to Claude 2!

What determines the size of the context window?
At this point, you may be wondering why some models have larger context windows than others.
To understand this, let’s first review how the attention mechanism works in the figure below; if you aren’t familiar with the details of attention, this is covered in detail in my previous article. Recently, there have been several attention improvements and variants which aim to make this mechanism more efficient, but the key challenges remain the same. Here, will focus on the original scaled dot-product attention.
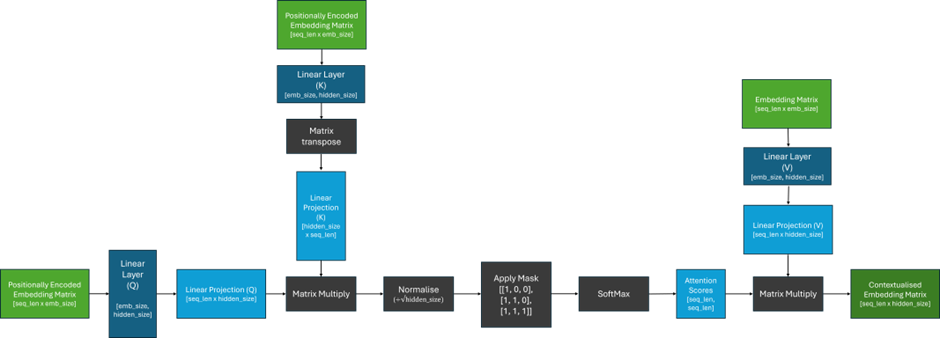
From the figure above, we can notice that the size of the matrix containing our attention scores is determined by the lengths of the sequences passed into the model and can grow arbitrarily large! Therefore, we can see that the context window is not determined by the architecture, but rather the length of the sequences that are given to the model during training.
This calculation can be incredibly expensive to compute as, without any optimisations, matrix multiplications are generally quadratic in space complexity (O(n^2)). Put simply, this means that if the length of an input sequence doubles, the amount of memory required quadruples! Therefore, training a model on sequence lengths of 128k will require approximately 1024 times the memory compared to training on sequence lengths of 4k!
It is also important to keep in mind that this operation is repeated for every layer and every head of the transformer, which results in a significant amount of computation. As the amount of GPU memory available is also shared with the parameters of the model, any computed gradients, and a reasonable sized batch of input data, hardware can quickly become a bottleneck on the size of the context window when training large models.
Can we extend the context window of a pre-trained model?
After understanding the computational challenges of training models on longer sequence lengths, it may be tempting to train a model on short sequences, with the hope that this will generalise to longer contexts.

One obstacle to this is the positional encoding mechanism, used to enable transformers to capture the position of tokens in a sequence. In the original paper, two strategies for positional encoding were proposed. The first was to use learnable embeddings specific to each position in the sequence, which are clearly unable to generalise past the maximum sequence length that the model was trained on. However, the authors hypothesised that their preferred sinusoidal approach may extrapolate to longer sequences; subsequent research has demonstrated that this is not the case.
In many recent transformer models such as PaLM and Llama-2, absolute positional encodings have been replaced by relative positional encodings, such as RoPE, which aim to preserve the relative distance between tokens after encodings. Whilst these are slightly better at generalising to longer sequences than previous approaches, performance quickly breaks down for sequence lengths significantly longer than the model has seen before.
Whilst there are several approaches that aim to change or remove positional encodings completely, these require fundamental changes to the transformer architecture, and would require models to be retrained, which is highly expensive and time consuming. As many of the top performing open-source models at the time of writing, are derived from pretrained versions of Llama-2, there is a lot of active research taking place into how to extend the context length of existing model which use RoPE embeddings, with varying success.
Many of these approaches employ some variation of interpolating the input sequence; scaling the positional embeddings so that they fit within the original context window of the model. The intuition behind this is that it should be easier for the model fill in the gaps between words, rather than trying to predict what comes after the words.
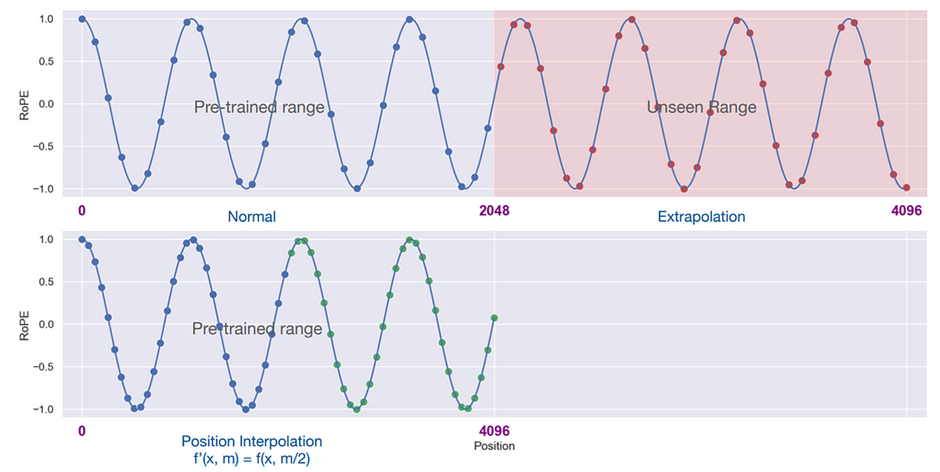
One such approach, known as YaRN, was able to extend the context window of the Llama-2 7B and 13B models to 128k without a significant degradation in performance!
Whilst a definitive approach that works well in all contexts has yet to emerge, this remains an exciting area of research, with big potential implications!
Are longer context windows always better?
Now that we understand some of the practical challenges around training models on longer sequence lengths, and some potential mitigations to overcome this, we can ask another question — is this extra effort worth it? At first glance, the answer may seem obvious; providing more information to a model should make it easier to inject new knowledge and reduce hallucinations, making it more useful in almost every conceivable application. However, things are not so simple.

In the 2023 paper Lost in the Middle, researchers at Stanford and Berkley investigated how models use and access information provided in their context window, and concluded the following:
“We find that changing the position of relevant information in the input context can substantially affect model performance, indicating that current language models do not robustly access and use information in long input contexts”.
For their experiments, the authors created a dataset where, for each query, they had a document that contains the answer and k — 1 distractor documents which did not contain the answer; adjusting the input context length by changing the number of retrieved documents that do not contain the answer. They then modulated the position of relevant information within the input context by changing the order of the documents to place the relevant document at the beginning, middle or end of the context, and evaluated whether any of the correct answers appear in the predicted output.
Specifically, they observed that the models studied performed the best when the relevant information was found at the start or the end of the context window; when the information required was in the middle of the context, performance significantly decreased.
In theory, the self-attention mechanism in a Transformer enables the model to consider all parts of the input when generating the next word, regardless of their position in the sequence. As such, I believe that any biases that the model has learned about where to find important information is more likely to come from the training data than the architecture. We can explore this idea further by examining the results that the authors observed when evaluating the Llama-2 family of models on the accuracy or retrieving documents based on their position, which are presented in the figure below.
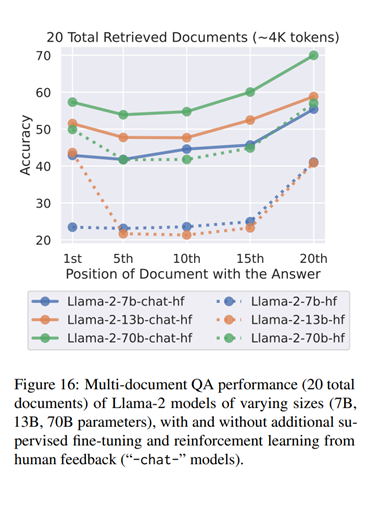
Looking at the base models, we can clearly observe the authors’ conclusions for the Llama-2 13B and 70B models. Interestingly, for the 7B model, we can see that it relies almost exclusively on the end of the context; as a lot of unsupervised finetuning is on streams of data scraped from various sources, when the model has relatively few parameters to dedicate to predicting the next word in an ever-changing context, it makes sense to focus on the most recent tokens!
The bigger models also perform well when the relevant information is at the beginning of the text; suggesting that they learn to focus more on the start of the text as they get more parameters. The authors hypothesise that this is because, during pre-training, the models see a lot of data from sources like StackOverflow which start with important information. I doubt the 13B model’s slight advantage with front-loaded information is significant, as the accuracy is similar in both cases and the 70B model does not show this pattern.
The ‘chat’ models are trained further with instruction tuning and RLHF, and they perform better overall, and also seem to become less sensitive to the position of the relevant information in the text. This is more clear for the 13B model, and less for the 70B model. The 7B model does not change much, perhaps because it has fewer parameters. This could mean that these models learn to use information from other parts of the text better after more training, but they still prefer the most recent information. Given that the subsequent training stages are significantly shorter, they have not completely overcome have the biases from the first unsupervised training; I suspect that the 70B model may require a larger, more diverse subsequent training to exhibit a similar magnitude of change as in the performance of the 13B model observed here.
Additionally, I would be interested in an investigation which explores the position of the relevant information in the text in the datasets used for SFT. As humans exhibit similar behaviour of being better at recalling information at the start and end of sequences, it would not be surprising if this behaviour is mirrored in a lot of the examples given.
Conclusion
To summarise, the context window is not fixed and can grow as large as you want it to, provided there is enough memory available! However, longer sequences mean more computation — which also result in the model being slower — and unless the model has been trained on sequences of a similar length, the output may not make much sense! However, even for models with large context windows, there is no guarantee that they will effectively use all of the information provided to them — there really is no free lunch!
Chris Hughes is on LinkedIn
Unless otherwise stated, all images were created by the author.
References
- RAG and generative AI — Azure AI Search | Microsoft Learn
- Llama 2 — Meta AI
- Models — OpenAI API
- Introducing Claude 2.1 \ Anthropic
- What are tokens and how to count them? | OpenAI Help Center
- De-coded: Transformers explained in plain English | by Chris Hughes | Towards Data Science
- [1706.03762] Attention Is All You Need (arxiv.org)
- Train Short, Test Long: Attention with Linear Biases enables input length extrapolation (openreview.net)
- [2203.16634] Transformer Language Models without Positional Encodings Still Learn Positional Information (arxiv.org)
- [2310.06825] Mistral 7B (arxiv.org)
- [2401.07872] The What, Why, and How of Context Length Extension Techniques in Large Language Models — A Detailed Survey (arxiv.org)
- [2306.15595] Extending Context Window of Large Language Models via Positional Interpolation (arxiv.org)
- [2309.00071] YaRN: Efficient Context Window Extension of Large Language Models (arxiv.org)
- [2307.03172] Lost in the Middle: How Language Models Use Long Contexts (arxiv.org)
- Primary Effect: Meaning, How It Works (verywellmind.com)
- No free lunch theorem — Wikipedia
De-Coded: Understanding Context Windows for Transformer Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Everything you need to know about how context windows affect Transformer training and usage
The context window is the maximum sequence length that a transformer can process at a time. With the rise of proprietary LLMs that limit the number of tokens and therefore the prompt size — as well as the growing interest in techniques such as Retrieval Augmented Generation (RAG)— understanding the key ideas around context windows and their implications is becoming increasingly important, as this is often cited when discussing different models.
The transformer architecture is a powerful tool for natural language processing, but it has some limitations when it comes to handling long sequences of text. In this article, we will explore how different factors affect the maximum context length that a transformer model can process, and whether bigger is always better when choosing a model for your task.

How many words can I fit into a Transformer?
At the time of writing, models such as the Llama-2 variants have a context length of 4k tokens, GPT-4 turbo has 128k, and Claude 2.1 has 200k! From the number of tokens alone, it can be difficult to envisage how this translates into words; whilst it depends on the tokenizer used, a good rule of thumb is that 100k tokens is approximately 75,000 words. To put that in perspective, we can compare this to some popular literature:
- The Lord of the Rings (J. R. R. Tolkien): 564,187 words, 752k tokens
- Dracula (Bram Stoker): 165,453 words, 220k tokens
- Grimms’ Fairy Tales (Jacob Grimm and Wilhelm Grimm): 104,228 words, 139k tokens
- Frankenstein (Mary Shelley): 78,100 words, 104k tokens
- Harry Potter and the Philosopher’s Stone (J. K. Rowling): 77,423 words, 103k tokens
- Treasure Island (Robert Louis Stevenson): 72,036 words, 96k tokens
- The War of the Worlds (H. G. Wells): 63,194 words, 84k tokens
- The Hound of the Baskervilles (Arthur Conan Doyle): 62,297 words, 83k tokens
- The Jungle Book (Rudyard Kipling): 54,178 words, 72k tokens
To summarise, 100k tokens is roughly equivalent to a short novel, whereas at 200k we can almost fit the entirety of Dracula, a medium sized volume! To ingest a large volume, such as The Lord of the Rings, we would need 6 requests to GPT-4 and only 4 calls to Claude 2!
What determines the size of the context window?
At this point, you may be wondering why some models have larger context windows than others.
To understand this, let’s first review how the attention mechanism works in the figure below; if you aren’t familiar with the details of attention, this is covered in detail in my previous article. Recently, there have been several attention improvements and variants which aim to make this mechanism more efficient, but the key challenges remain the same. Here, will focus on the original scaled dot-product attention.
From the figure above, we can notice that the size of the matrix containing our attention scores is determined by the lengths of the sequences passed into the model and can grow arbitrarily large! Therefore, we can see that the context window is not determined by the architecture, but rather the length of the sequences that are given to the model during training.
This calculation can be incredibly expensive to compute as, without any optimisations, matrix multiplications are generally quadratic in space complexity (O(n^2)). Put simply, this means that if the length of an input sequence doubles, the amount of memory required quadruples! Therefore, training a model on sequence lengths of 128k will require approximately 1024 times the memory compared to training on sequence lengths of 4k!
It is also important to keep in mind that this operation is repeated for every layer and every head of the transformer, which results in a significant amount of computation. As the amount of GPU memory available is also shared with the parameters of the model, any computed gradients, and a reasonable sized batch of input data, hardware can quickly become a bottleneck on the size of the context window when training large models.
Can we extend the context window of a pre-trained model?
After understanding the computational challenges of training models on longer sequence lengths, it may be tempting to train a model on short sequences, with the hope that this will generalise to longer contexts.
One obstacle to this is the positional encoding mechanism, used to enable transformers to capture the position of tokens in a sequence. In the original paper, two strategies for positional encoding were proposed. The first was to use learnable embeddings specific to each position in the sequence, which are clearly unable to generalise past the maximum sequence length that the model was trained on. However, the authors hypothesised that their preferred sinusoidal approach may extrapolate to longer sequences; subsequent research has demonstrated that this is not the case.
In many recent transformer models such as PaLM and Llama-2, absolute positional encodings have been replaced by relative positional encodings, such as RoPE, which aim to preserve the relative distance between tokens after encodings. Whilst these are slightly better at generalising to longer sequences than previous approaches, performance quickly breaks down for sequence lengths significantly longer than the model has seen before.
Whilst there are several approaches that aim to change or remove positional encodings completely, these require fundamental changes to the transformer architecture, and would require models to be retrained, which is highly expensive and time consuming. As many of the top performing open-source models at the time of writing, are derived from pretrained versions of Llama-2, there is a lot of active research taking place into how to extend the context length of existing model which use RoPE embeddings, with varying success.
Many of these approaches employ some variation of interpolating the input sequence; scaling the positional embeddings so that they fit within the original context window of the model. The intuition behind this is that it should be easier for the model fill in the gaps between words, rather than trying to predict what comes after the words.
One such approach, known as YaRN, was able to extend the context window of the Llama-2 7B and 13B models to 128k without a significant degradation in performance!
Whilst a definitive approach that works well in all contexts has yet to emerge, this remains an exciting area of research, with big potential implications!
Are longer context windows always better?
Now that we understand some of the practical challenges around training models on longer sequence lengths, and some potential mitigations to overcome this, we can ask another question — is this extra effort worth it? At first glance, the answer may seem obvious; providing more information to a model should make it easier to inject new knowledge and reduce hallucinations, making it more useful in almost every conceivable application. However, things are not so simple.
In the 2023 paper Lost in the Middle, researchers at Stanford and Berkley investigated how models use and access information provided in their context window, and concluded the following:
“We find that changing the position of relevant information in the input context can substantially affect model performance, indicating that current language models do not robustly access and use information in long input contexts”.
For their experiments, the authors created a dataset where, for each query, they had a document that contains the answer and k — 1 distractor documents which did not contain the answer; adjusting the input context length by changing the number of retrieved documents that do not contain the answer. They then modulated the position of relevant information within the input context by changing the order of the documents to place the relevant document at the beginning, middle or end of the context, and evaluated whether any of the correct answers appear in the predicted output.
Specifically, they observed that the models studied performed the best when the relevant information was found at the start or the end of the context window; when the information required was in the middle of the context, performance significantly decreased.
In theory, the self-attention mechanism in a Transformer enables the model to consider all parts of the input when generating the next word, regardless of their position in the sequence. As such, I believe that any biases that the model has learned about where to find important information is more likely to come from the training data than the architecture. We can explore this idea further by examining the results that the authors observed when evaluating the Llama-2 family of models on the accuracy or retrieving documents based on their position, which are presented in the figure below.
Looking at the base models, we can clearly observe the authors’ conclusions for the Llama-2 13B and 70B models. Interestingly, for the 7B model, we can see that it relies almost exclusively on the end of the context; as a lot of unsupervised finetuning is on streams of data scraped from various sources, when the model has relatively few parameters to dedicate to predicting the next word in an ever-changing context, it makes sense to focus on the most recent tokens!
The bigger models also perform well when the relevant information is at the beginning of the text; suggesting that they learn to focus more on the start of the text as they get more parameters. The authors hypothesise that this is because, during pre-training, the models see a lot of data from sources like StackOverflow which start with important information. I doubt the 13B model’s slight advantage with front-loaded information is significant, as the accuracy is similar in both cases and the 70B model does not show this pattern.
The ‘chat’ models are trained further with instruction tuning and RLHF, and they perform better overall, and also seem to become less sensitive to the position of the relevant information in the text. This is more clear for the 13B model, and less for the 70B model. The 7B model does not change much, perhaps because it has fewer parameters. This could mean that these models learn to use information from other parts of the text better after more training, but they still prefer the most recent information. Given that the subsequent training stages are significantly shorter, they have not completely overcome have the biases from the first unsupervised training; I suspect that the 70B model may require a larger, more diverse subsequent training to exhibit a similar magnitude of change as in the performance of the 13B model observed here.
Additionally, I would be interested in an investigation which explores the position of the relevant information in the text in the datasets used for SFT. As humans exhibit similar behaviour of being better at recalling information at the start and end of sequences, it would not be surprising if this behaviour is mirrored in a lot of the examples given.
Conclusion
To summarise, the context window is not fixed and can grow as large as you want it to, provided there is enough memory available! However, longer sequences mean more computation — which also result in the model being slower — and unless the model has been trained on sequences of a similar length, the output may not make much sense! However, even for models with large context windows, there is no guarantee that they will effectively use all of the information provided to them — there really is no free lunch!
Chris Hughes is on LinkedIn
Unless otherwise stated, all images were created by the author.
References
- RAG and generative AI — Azure AI Search | Microsoft Learn
- Llama 2 — Meta AI
- Models — OpenAI API
- Introducing Claude 2.1 \ Anthropic
- What are tokens and how to count them? | OpenAI Help Center
- De-coded: Transformers explained in plain English | by Chris Hughes | Towards Data Science
- [1706.03762] Attention Is All You Need (arxiv.org)
- Train Short, Test Long: Attention with Linear Biases enables input length extrapolation (openreview.net)
- [2203.16634] Transformer Language Models without Positional Encodings Still Learn Positional Information (arxiv.org)
- [2310.06825] Mistral 7B (arxiv.org)
- [2401.07872] The What, Why, and How of Context Length Extension Techniques in Large Language Models — A Detailed Survey (arxiv.org)
- [2306.15595] Extending Context Window of Large Language Models via Positional Interpolation (arxiv.org)
- [2309.00071] YaRN: Efficient Context Window Extension of Large Language Models (arxiv.org)
- [2307.03172] Lost in the Middle: How Language Models Use Long Contexts (arxiv.org)
- Primary Effect: Meaning, How It Works (verywellmind.com)
- No free lunch theorem — Wikipedia
De-Coded: Understanding Context Windows for Transformer Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.