
Deploy Long-Running ETL Pipelines to ECS with Fargate
To keep things simple and costs to a minimum
ETL stands for Extract, Transform, and Load. An ETL pipeline is essentially just a data transformation process — extracting data from one place, doing something with it, and then loading it back to the same or a different place.
If you are working with natural language processing via APIs, which I’m guessing most will start doing, you can easily hit the timeout threshold of AWS Lambda when processing your data, especially if at least one function exceeds 15 minutes. So, while Lambda is great because it’s quick and really cheap, the timeout can be a bother.
The choice here is to deploy your code as a container that has the option of running as long as it needs to and run it on a schedule. So, instead of spinning up a function as you do with Lambda, we can spin up a container to run in an ECS cluster using Fargate.

For clarification, Lambda, ECS and EventBridge are all AWS Services.
Just as with Lambda, the cost of running a container for an hour or two is minimal. However, it’s a bit more complicated than running a serverless function. But if you’re reading this, then you’ve probably run into the same issues and are wondering what the easiest way to transition is.
I have created a very simple ETL template that uses Google BigQuery to extract and load data. This template will get you up and running within a few minutes if you follow along.
Using BigQuery is entirely optional but I usually store my long term data there.
Introduction
Instead of building something complex here, I will show you how to build something minimal and keep it really lean.
If you don’t need to process data in parallel, you shouldn’t need to include something like Airflow. I’ve seen a few articles out there that unnecessarily set up complex workflows, which aren’t strictly necessary for straightforward data transformation.
Besides, if you feel like you want to add on to this later, that option is yours.
Workflow
We’ll build our script in Python as we’re doing data transformation, then bundle it up with Docker and push it to an ECR repository.
From here, we can create a task definition using AWS Fargate and run it on a schedule in an ECS cluster.
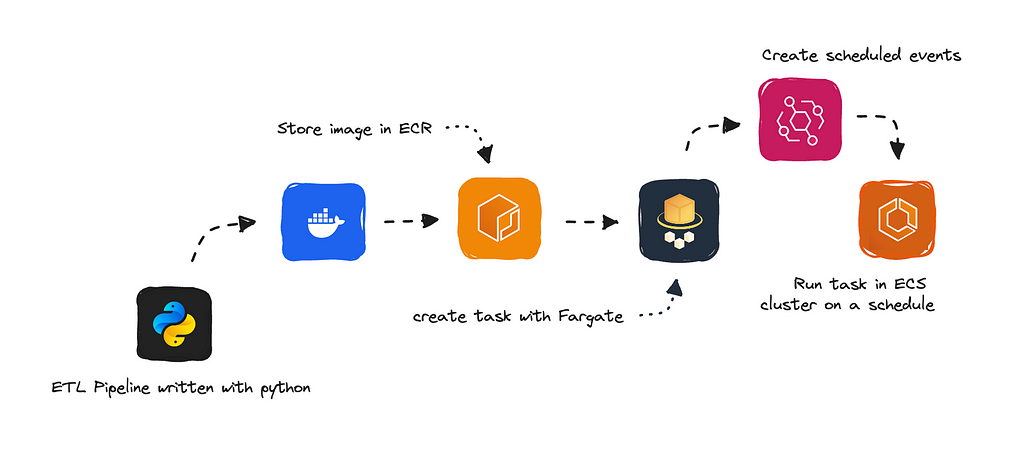
Don’t worry if this feels foreign; you’ll understand all these services and what they do as we go along.
Technology
If you are new to working with containers, then think of ECS (Elastic Container Service) as something that helps us set up an environment where we can run one or more containers simultaneously.
Fargate, on the other hand, helps us simplify the management and setup of the containers themselves using Docker images — which are referred to as tasks in AWS.
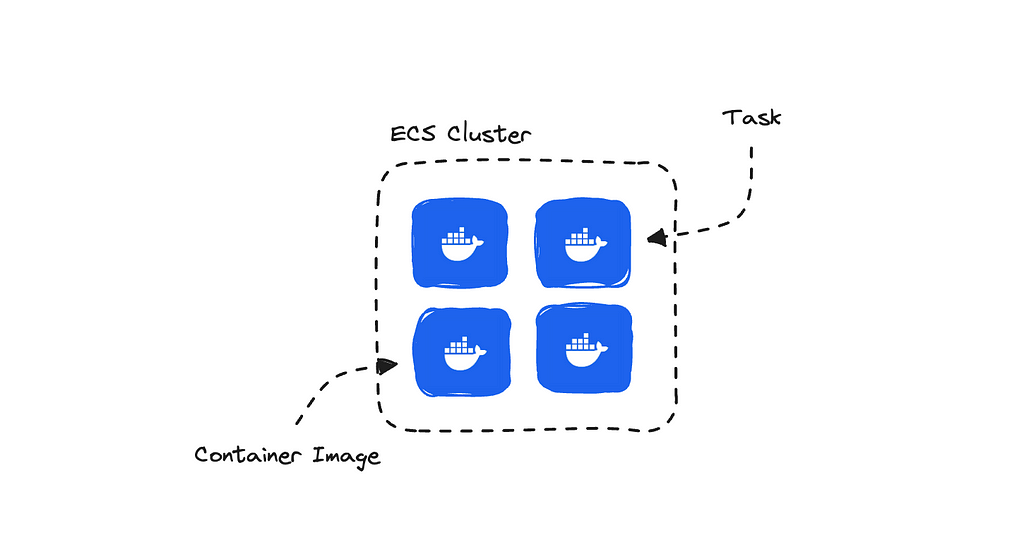
There is the option of using EC2 to set up your containers, but you would have to do a lot more manual work. Fargate manages the underlying instances for us, whereas with EC2, you are required to manage and deploy your own compute instances. Hence, Fargate is often referred to as the ‘serverless’ option.
I found a thread on Reddit discussing this, if you’re keen to read a bit about how users find using EC2 versus Fargate. It can give you an idea of how people compare EC2 and Fargate.
Not that I’m saying Reddit is the source of truth, but it’s useful for getting a sense of user perspectives.
Costs
The primary concern I usually have is to keep the code running efficiently while also managing the total cost.
As we’re only running the container when we need to, we only pay for the amount of resources we use. The price we pay is determined by several factors, such as the number of tasks running, the execution duration of each task, the number of virtual CPUs (vCPUs) used for the task, and memory usage.
But to give you a rough idea, on a high level, the total cost for running one task is around $0.01384 per hour for the EU region, depending on the resources you’ve provisioned.
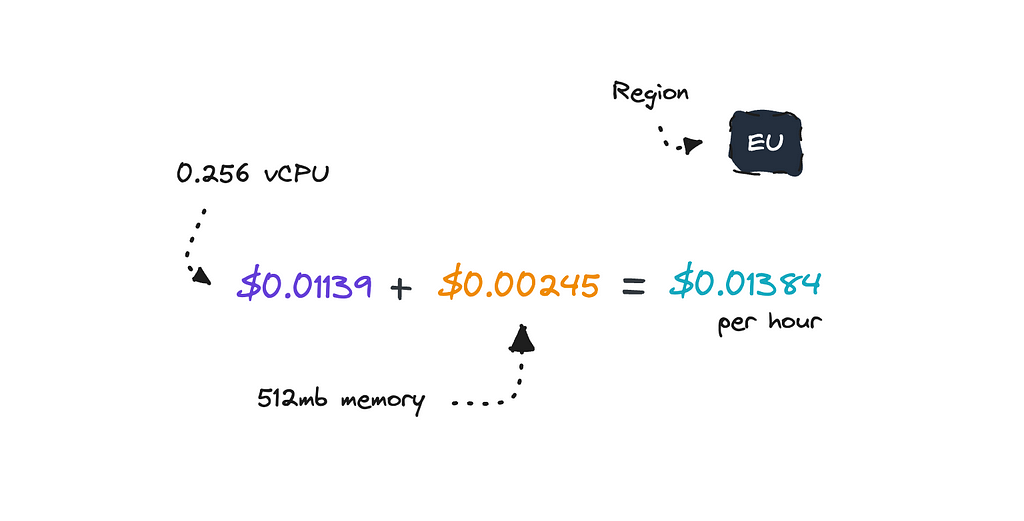
If we were to compare this price with AWS Glue we can get a bit of perspective if it is good or not.
If an ETL job requires 4 DPUs (the default number for an AWS Glue job) and runs for an hour, it would cost 4 DPUs * $0.44 = $1.76. This cost is for only one hour and is significantly higher than running a simple container.
This is, of course, a simplified calculation, and the actual number of DPUs can vary depending on the job. You can check out AWS Glue pricing in more detail on their pricing page.
To run long-running scripts, setting up your own container and deploying it on ECS with Fargate makes sense, both in terms of efficiency and cost.
Getting Started
To follow this article, I’ve created a simple ETL template to help you get up and running quickly.
This template uses BigQuery to extract and load data. It will extract a few rows, do something simple and then load it back to BigQuery.
When I run my pipelines I have other things that transform data — I use APIs for natural language processing that runs for a few hours in the morning — but that is up to you to add on later. This is just to give you a template that will be easy to work with.
To follow along this tutorial, the main steps will be as follows:
- Setting up your local code.
- Setting up an IAM user & the AWS CLI.
- Build & push Docker image to AWS.
- Create an ECS task definition.
- Create an ECS cluster.
- Schedule to your tasks.
In total it shouldn’t take you longer than 20 minutes to get through this, using the code I’ll provide you with. This assumes you have an AWS account ready, and if not, add on 5 to 10 minutes.
The Code
First create a new folder locally and locate into it.
mkdir etl-pipelines
cd etl-pipelines
Make sure you have python installed.
python --version
If not, install it locally.
Once you’re ready, you can go ahead and clone the template I have already set up.
git clone https://github.com/ilsilfverskiold/etl-pipeline-fargate.git
When it has finished fetching the code, open it up in your code editor.
First check the main.py file to look how I’ve structured the code to understand what it does.
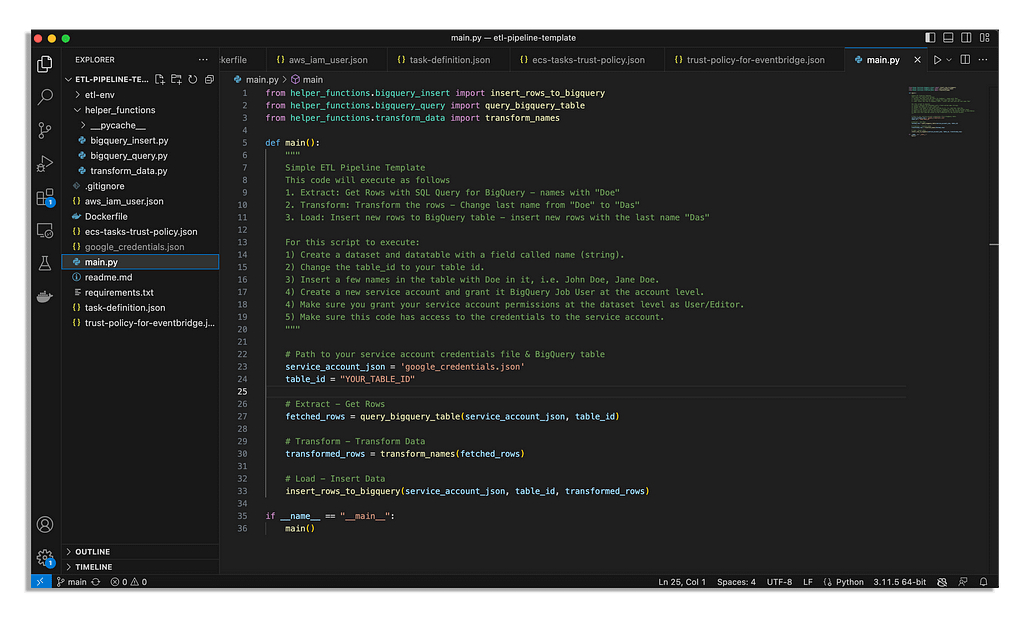
Essentially, it will fetch all names with “Doe” in it from a table in BigQuery that you specify, transform these names and then insert them back into the same data table as new rows.
You can go into each helper function to see how we set up the SQL Query job, transform the data and then insert it back to the BigQuery table.
The idea is of course that you set up something more complex but this is a simple test run to make it easy to tweak the code.
Setting Up BigQuery
If you want to continue with the code I’ve prepared you will need to set up a few things in BigQuery. Otherwise you can skip this part.
Here are the things you will need:
- A BigQuery table with a field of ‘name’ as a string.
- A few rows in the data table with the name “Doe” in it.
- A service account that will have access to this dataset.
To get a service account you will need to navigate to IAM in the Google Cloud Console and then to Service Accounts.
Once there, create a new service account.
Once it has been created, you will need to give your service account BigQuery User access globally via IAM.
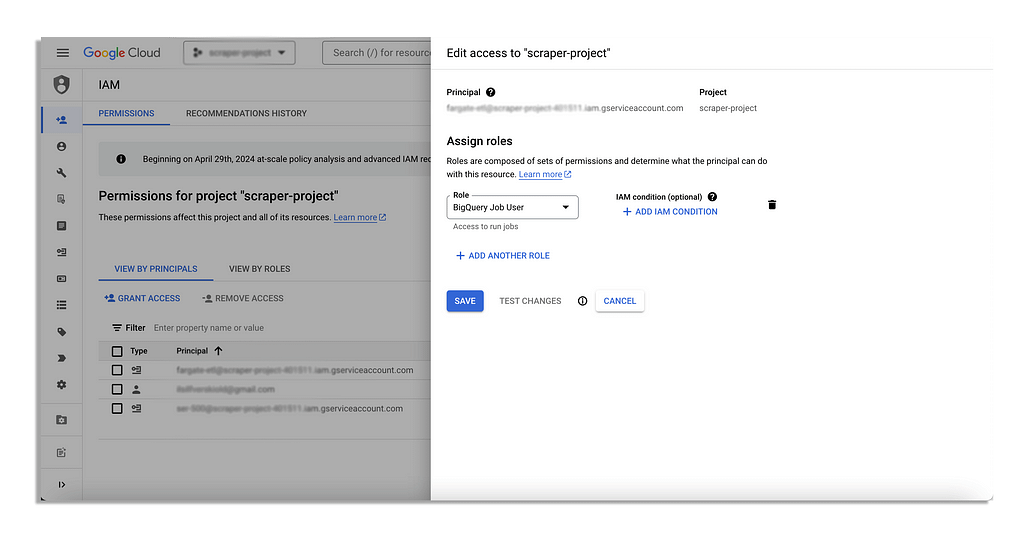
You will also have to give this service account access to the dataset itself which you do in BigQuery directly via the dataset’s Share button and then by pressing Add Principal.

After you’ve given the user the appropriate permissions, make sure you go back to the Service Accounts and then download a key. This will give you a json file that you need to put in your root folder.

Now, the most important part is making sure the code has access to the google credentials and is using the correct data table.
You’ll want the json file you’ve downloaded with the Google credentials in your root folder as google_credentials.json and then you want to specify the correct table ID.
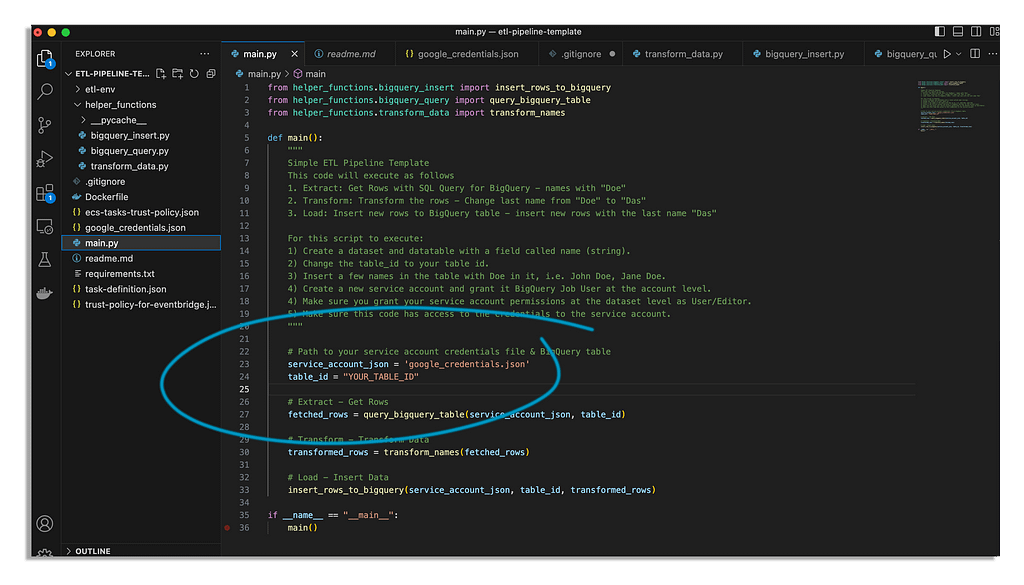
Now you might argue that you do not want to store your credentials locally which is only right.
You can add in the option of storing your json file in AWS Secrets Manager later. However, to start, this will be easier.
Run ETL Pipeline Locally
We’ll run this code locally first, just so we can see that it works.
So, set up a Python virtual environment and activate it.
python -m venv etl-env
source etl-env/bin/activate # On Windows use `venv\Scripts\activate`
Then install dependencies. We only have google-cloud-bigquery in there but ideally you will have more dependencies.
pip install -r requirements.txt
Run the main script.
python main.py
This should log ‘New rows have been added’ in your terminal. This will then confirm that the code works as we’ve intended.
The Docker Image
Now to push this code to ECS we will have to bundle it up into a Docker image which means that you will need Docker installed locally.
If you do not have Docker installed, you can download it here.
Docker helps us package an application and its dependencies into an image, which can be easily recognized and run on any system. Using ECS, it’s required of us to bundle our code into Docker images, which are then referenced by a task definition to run as containers.
I have already set up a Dockerfile in your folder. You should be able to look into it there.
FROM --platform=linux/amd64 python:3.11-slim
WORKDIR /app
COPY . /app
RUN pip install --no-cache-dir -r requirements.txt
CMD ["python", "main.py"]
As you see, I’ve kept this really lean as we’re not connecting web traffic to any ports here.
We’re specifying AMD64 which you may not need if you are not on a Mac with an M1 chip but it shouldn’t hurt. This will specify to AWS the architecture of the docker image so we don’t run into compatibility issues.
Create an IAM User
When working with AWS, access will need to be specified. Most of the issues you’ll run into are permission issues. We’ll be working with the CLI locally, and for this to work we’ll have to create an IAM user that will need quite broad permissions.
Go to the AWS console and then navigate to IAM. Create a new user, add permissions and then create a new policy to attach to it.
I have specified the permissions needed in your code in the aws_iam_user.json file. You’ll see a short snippet below of what this json file looks like.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"iam:CreateRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy",
"ecs:DescribeTaskDefinition",
...more
],
"Resource": "*"
}
]
}
You’ll need to go into this file to get all the permissions you will need to set, this is just a short snippet. I’ve set it to quite a few, which you may want to tweak to your own preferences later.
Once you’ve created the IAM user and you’ve added the correct permissions to it, you will need to generate an access key. Choose ‘Command Line Interface (CLI)’ when asked about your use case.
Download the credentials. We’ll use these to authenticate in a bit.
Set up the AWS CLI
Next, we’ll connect our terminal to our AWS account.
If you don’t have the CLI set up yet you can follow the instructions here. It is really easy to set this up.
Once you’ve installed the AWS CLI you’ll need to authenticate with the IAM user we just created.
aws configure
Use the credentials we downloaded from the IAM user in the previous step.
Create an ECR Repository
Now, we can get started with the DevOps of it all.
We’ll first need to create a repository in Elastic Container Registry. ECR is where we can store and manage our docker images. We’ll be able to reference these images from ECR when we set up our task definitions.
To create a new ECR repository run this command in your terminal. This will create a repository called bigquery-etl-pipeline.
aws ecr create-repository — repository-name bigquery-etl-pipeline
Note the repository URI you get back.
From here we have to build the docker image and then push this image to this repository.
To do this you can technically go into the AWS console and find the ECR repository we just created. Here AWS will let us see the entire push commands we need to run to authenticate, build and push our docker image to this ECR repository.
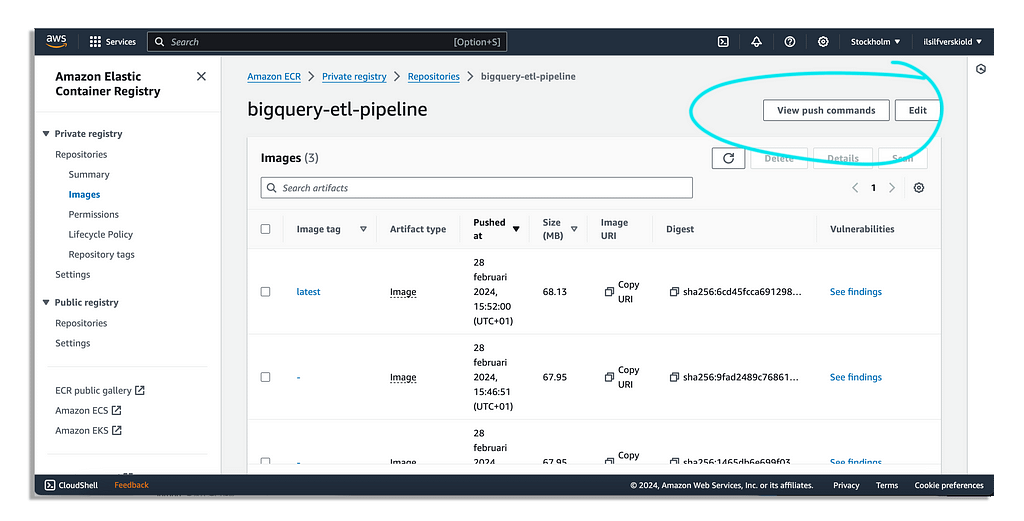
However, if you are on a Mac I would advice you to specify the architecture when building the docker image or you may run into issues.
If you are following along with me, then start with authenticating your docker client like so.
aws ecr get-login-password --region YOUR_REGION | docker login --username AWS --password-stdin YOUR_ACCOUNT_ID.dkr.ecr.YOUR_REGION.amazonaws.com
Be sure to change the values, region and account ID where applicable.
Build the docker image.
docker buildx build --platform=linux/amd64 -t bigquery-etl-pipeline .
This is where I have tweaked the command to specify the linux/amd64 architecture.
Tag the docker image.
docker tag bigquery-etl-pipeline:latest YOUR_ACCOUNT_ID.dkr.ecr.YOUR_REGION.amazonaws.com/bigquery-etl-pipeline:latest
Push the docker image.
docker push YOUR_ACCOUNT_ID.dkr.ecr.YOUR_REGION.amazonaws.com/bigquery-etl-pipeline:latest
If everything worked as planned you’ll see something like this in your terminal.
9f691c4f0216: Pushed
ca0189907a60: Pushed
687f796c98d5: Pushed
6beef49679a3: Pushed
b0dce122021b: Pushed
4de04bd13c4a: Pushed
cf9b23ff5651: Pushed
644fed2a3898: Pushed
Now that we have pushed the docker image to an ECR repository, we can use it to set up our task definition using Fargate.
If you run into EOF issues here it is most likely related to IAM permissions. Be sure to give it everything it needs, in this case full access to ECR to tag and push the image.
Roles & Log Groups
Remember what I told you before, the biggest issues you’ll run into in AWS pertains to roles between different services.
For this to flow neatly we’ll have to make sure we set up a few things before we start setting up a task definition and an ECS cluster.
To do this, we first have to create a task role — this role is the role that will need access to services in the AWS ecosystem from our container — and then the execution role — so the container will be able to pull the docker image from ECR.
aws iam create-role --role-name etl-pipeline-task-role --assume-role-policy-document file://ecs-tasks-trust-policy.json
aws iam create-role - role-name etl-pipeline-execution-role - assume-role-policy-document file://ecs-tasks-trust-policy.json
I have specified a json file called ecs-tasks-trust-policy.json in your folder locally that it will use to create these roles.
For the script that we are pushing, it won’t need to have permission to access other AWS services so for now there is no need to attach policies to the task role. Nevertheless, you may want to do this later.
However, for the execution role though we will need to give it ECR access to pull the docker image.
To attach the policy AmazonECSTaskExecutionRolePolicy to the execution role run this command.
aws iam attach-role-policy --role-name etl-pipeline-execution-role --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
We also create one last role while we’re at it, a service role.
aws iam create-service-linked-role - aws-service-name ecs.amazonaws.com
If you don’t create the service role you may end up with an errors such as ‘Unable to assume the service linked role. Please verify that the ECS service linked role exists’ when you try to run a task.
The last thing we create a log group. Creating a log group is essential for capturing and accessing logs generated by your container.
To create a log group you can run this command.
aws logs create-log-group - log-group-name /ecs/etl-pipeline-logs
Once you’ve created the execution role, the task role, the service role and then the log group we can continue to set up the ECS task definition.
Create an ECS Task Definition
A task definition is a blueprint for your tasks, specifying what container image to use, how much CPU and memory is needed, and other configurations. We use this blueprint to run tasks in our ECS cluster.
I have already set up the task definition in your code at task-definition.json. However, you need to set your account id as well as region in there to make sure it runs as it should.
{
"family": "my-etl-task",
"taskRoleArn": "arn:aws:iam::ACCOUNT_ID:role/etl-pipeline-task-role",
"executionRoleArn": "arn:aws:iam::ACCOUNT_ID:role/etl-pipeline-execution-role",
"networkMode": "awsvpc",
"containerDefinitions": [
{
"name": "my-etl-container",
"image": "ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/bigquery-etl-pipeline:latest",
"cpu": 256,
"memory": 512,
"essential": true,
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/etl-pipeline-logs",
"awslogs-region": "REGION",
"awslogs-stream-prefix": "ecs"
}
}
}
],
"requiresCompatibilities": ["FARGATE"],
"cpu": "256",
"memory": "512"
}
Remember the URI we got back when we created the ECR repository? This is where we’ll use it. Remember the execution role, the task role and the log group? We’ll use it there as well.
If you’ve named the ECR repository along with the roles and log group exactly what I named mine then you can simply change the account ID and Region in this json otherwise make sure the URI is the correct one.
You can also set CPU and memory here for what you’ll need to run your task — i.e. your code. I’ve set .25 vCPU and 512 mb as memory.
Once you’re satisfied you can register the task definition in your terminal.
aws ecs register-task-definition --cli-input-json file://task-definition.json
Now you should be able to go into Amazon Elastic Container Service and then find the task we’ve created under Task Definitions.
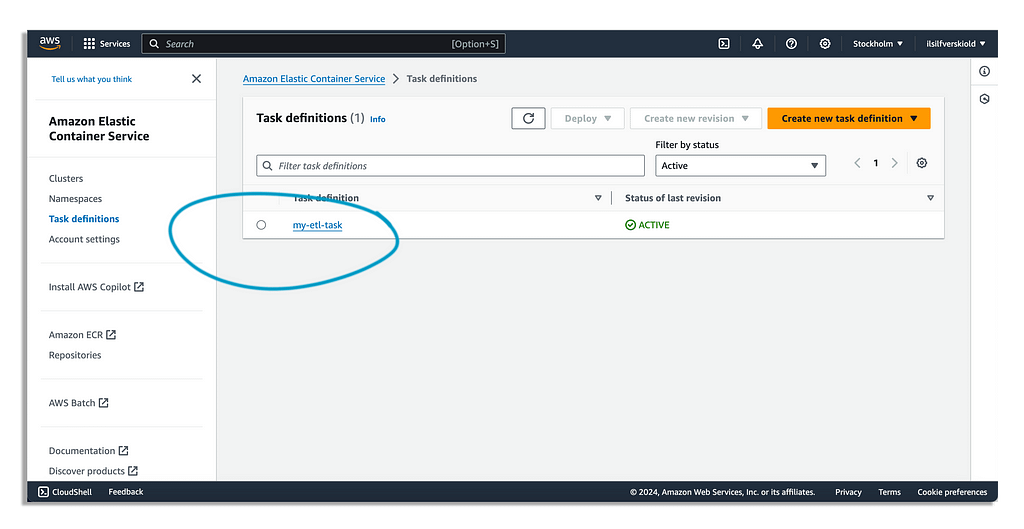
This task — i.e. blueprint — won’t run on it’s own, we need to invoke it later.
Create an ECS Cluster
An ECS Cluster serves as a logical grouping of tasks or services. You specify this cluster when running tasks or creating services.
To create a cluster via the CLI run this command.
aws ecs create-cluster --cluster-name etl-pipeline-cluster
Once you run this command, you’ll be able to see this cluster in ECS in your AWS console if you look there.
We’ll attach the Task Definition we just created to this cluster when we run it for the next part.
Run Task
Before we can run the task we need to get ahold of the subnets that are available to us along with a security group id.
We can do this directly in the terminal via the CLI.
Run this command in the terminal to get the available subnets.
aws ec2 describe-subnets
You’ll get back an array of objects here, and you’re looking for the SubnetId for each object.
If you run into issues here, make sure your IAM has the appropriate permissions. See the aws_iam_user.json file in your root folder for the permissions the IAM user connected to the CLI will need. I will stress this, because it’s the main issues that I always run into.
To get the security group ID you can run this command.
aws ec2 describe-security-groups
You are looking for GroupId here in the terminal.
If you got at least one SubnetId and then a GroupId for a security group, we’re ready to run the task to test that the blueprint — i.e. task definition — works.
aws ecs run-task \
--cluster etl-pipeline-cluster \
--launch-type FARGATE \
--task-definition my-etl-task \
--count 1 \
--network-configuration "awsvpcConfiguration={subnets=[SUBNET_ID],securityGroups=[SECURITY_GROUP_ID],assignPublicIp=ENABLED}"
Do remember to change the names if you’ve named your cluster and task definition differently. Remember to also set your subnet ID and security group ID.
Now you can navigate to the AWS console to see the task running.

If you are having issues you can look into the logs.
If successful, you should see a few transformed rows added to BigQuery.
EventBridge Schedule
Now, we’ve managed to set up the task to run in an ECS cluster. But what we’re interested in is to make it run on a schedule. This is where EventBridge comes in.
EventBridge will set up our scheduled events, and we can set this up using the CLI as well. However, before we set up the schedule we first need to create a new role.
This is life when working with AWS, everything needs to have permission to interact with each other.
In this case, EventBridge will need permission to call the ECS cluster on our behalf.
In the repository you have a file called trust-policy-for-eventbridge.json that I have already put there, we’ll use this file to create this EventBridge role.
Paste this into the terminal and run it.
aws iam create-role \
--role-name ecsEventsRole \
--assume-role-policy-document file://trust-policy-for-eventbridge.json
We then have to attach a policy to this role.
aws iam attach-role-policy \
--role-name ecsEventsRole \
--policy-arn arn:aws:iam::aws:policy/AmazonECS_FullAccess
We need it to at least be able to have ecs:RunTask but we’ve given it full access. If you prefer to limit the permissions, you can create a custom policy with just the necessary permissions instead.
Now let’s set up the rule to schedule the task to run with the task definition every day at 5 am UTC. This is usually the time I’d like for it to process data for me so if it fails I can look into it after breakfast.
aws events put-rule \
--name "ETLPipelineDailyRun" \
--schedule-expression "cron(0 5 * * ? *)" \
--state ENABLED
You should receive back an object with a field called RuleArn here. This is just to confirm that it worked.
Next step is now to associate the rule with the ECS task definition.
aws events put-targets --rule "ETLPipelineDailyRun" \
--targets "[{\"Id\":\"1\",\"Arn\":\"arn:aws:ecs:REGION:ACCOUNT_NUMBER:cluster/etl-pipeline-cluster\",\"RoleArn\":\"arn:aws:iam::ACCOUNT_NUMBER:role/ecsEventsRole\",\"EcsParameters\":{\"TaskDefinitionArn\":\"arn:aws:ecs:REGION:ACCOUNT_NUMBER:task-definition/my-etl-task\",\"TaskCount\":1,\"LaunchType\":\"FARGATE\",\"NetworkConfiguration\":{\"awsvpcConfiguration\":{\"Subnets\":[\"SUBNET_ID\"],\"SecurityGroups\":[\"SECURITY_GROUP_ID\"],\"AssignPublicIp\":\"ENABLED\"}}}}]"
Remember to set your own values here for region, account number, subnet and security group.
Use the subnets and security group that we got earlier. You can set multiple subnets.
Once you’ve run the command the task is scheduled for 5 am every day and you’ll find it under Scheduled Tasks in the AWS Console.
AWS Secrets Manager (Optional)
So keeping your Google credentials in the root folder isn’t ideal, even if you’ve limited access to your datasets for the Google service account.
Here we can add on the option of moving these credentials to another AWS service and then accessing it from our container.
For this to work you’ll have to move the credentials file to Secrets Manager, tweak the code so it can fetch it to authenticate and make sure that the task role has permissions to access AWS Secrets Manager on your behalf.
When you’re done you can simply push the updated docker image to your ECR repo you set up before.
The End Result
Now you’ve got a very simple ETL pipeline running in a container on AWS on a schedule. The idea is that you add to it to do your own data transformations.
Hopefully this was a useful piece for anyone that is transitioning to setting up their long-running data transformation scripts on ECS in a simple, cost effective and straightforward way.
Let me know if you run into any issues in case there is something I missed to include.
❤
Deploy Long-Running ETL Pipelines to ECS with Fargate was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
To keep things simple and costs to a minimum
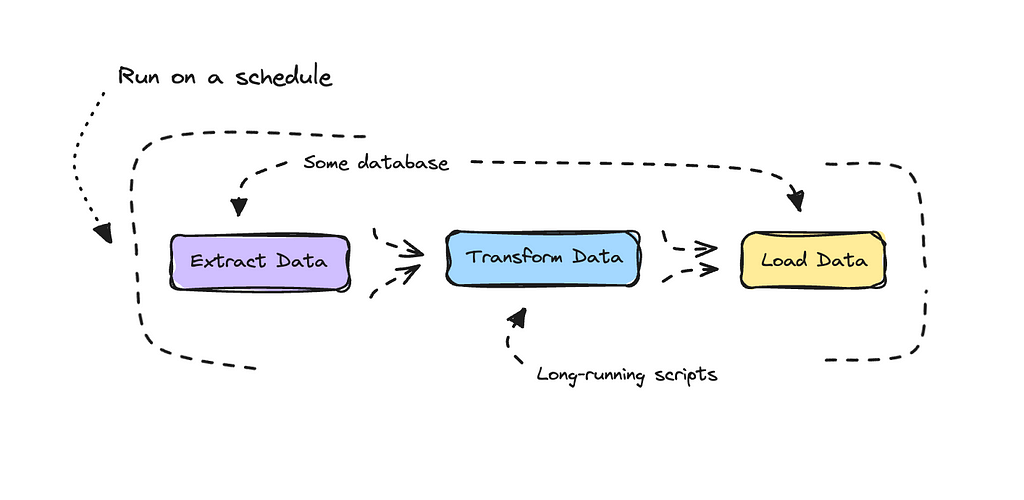
ETL stands for Extract, Transform, and Load. An ETL pipeline is essentially just a data transformation process — extracting data from one place, doing something with it, and then loading it back to the same or a different place.
If you are working with natural language processing via APIs, which I’m guessing most will start doing, you can easily hit the timeout threshold of AWS Lambda when processing your data, especially if at least one function exceeds 15 minutes. So, while Lambda is great because it’s quick and really cheap, the timeout can be a bother.
The choice here is to deploy your code as a container that has the option of running as long as it needs to and run it on a schedule. So, instead of spinning up a function as you do with Lambda, we can spin up a container to run in an ECS cluster using Fargate.
For clarification, Lambda, ECS and EventBridge are all AWS Services.
Just as with Lambda, the cost of running a container for an hour or two is minimal. However, it’s a bit more complicated than running a serverless function. But if you’re reading this, then you’ve probably run into the same issues and are wondering what the easiest way to transition is.
I have created a very simple ETL template that uses Google BigQuery to extract and load data. This template will get you up and running within a few minutes if you follow along.
Using BigQuery is entirely optional but I usually store my long term data there.
Introduction
Instead of building something complex here, I will show you how to build something minimal and keep it really lean.
If you don’t need to process data in parallel, you shouldn’t need to include something like Airflow. I’ve seen a few articles out there that unnecessarily set up complex workflows, which aren’t strictly necessary for straightforward data transformation.
Besides, if you feel like you want to add on to this later, that option is yours.
Workflow
We’ll build our script in Python as we’re doing data transformation, then bundle it up with Docker and push it to an ECR repository.
From here, we can create a task definition using AWS Fargate and run it on a schedule in an ECS cluster.
Don’t worry if this feels foreign; you’ll understand all these services and what they do as we go along.
Technology
If you are new to working with containers, then think of ECS (Elastic Container Service) as something that helps us set up an environment where we can run one or more containers simultaneously.
Fargate, on the other hand, helps us simplify the management and setup of the containers themselves using Docker images — which are referred to as tasks in AWS.
There is the option of using EC2 to set up your containers, but you would have to do a lot more manual work. Fargate manages the underlying instances for us, whereas with EC2, you are required to manage and deploy your own compute instances. Hence, Fargate is often referred to as the ‘serverless’ option.
I found a thread on Reddit discussing this, if you’re keen to read a bit about how users find using EC2 versus Fargate. It can give you an idea of how people compare EC2 and Fargate.
Not that I’m saying Reddit is the source of truth, but it’s useful for getting a sense of user perspectives.
Costs
The primary concern I usually have is to keep the code running efficiently while also managing the total cost.
As we’re only running the container when we need to, we only pay for the amount of resources we use. The price we pay is determined by several factors, such as the number of tasks running, the execution duration of each task, the number of virtual CPUs (vCPUs) used for the task, and memory usage.
But to give you a rough idea, on a high level, the total cost for running one task is around $0.01384 per hour for the EU region, depending on the resources you’ve provisioned.
If we were to compare this price with AWS Glue we can get a bit of perspective if it is good or not.
If an ETL job requires 4 DPUs (the default number for an AWS Glue job) and runs for an hour, it would cost 4 DPUs * $0.44 = $1.76. This cost is for only one hour and is significantly higher than running a simple container.
This is, of course, a simplified calculation, and the actual number of DPUs can vary depending on the job. You can check out AWS Glue pricing in more detail on their pricing page.
To run long-running scripts, setting up your own container and deploying it on ECS with Fargate makes sense, both in terms of efficiency and cost.
Getting Started
To follow this article, I’ve created a simple ETL template to help you get up and running quickly.
This template uses BigQuery to extract and load data. It will extract a few rows, do something simple and then load it back to BigQuery.
When I run my pipelines I have other things that transform data — I use APIs for natural language processing that runs for a few hours in the morning — but that is up to you to add on later. This is just to give you a template that will be easy to work with.
To follow along this tutorial, the main steps will be as follows:
- Setting up your local code.
- Setting up an IAM user & the AWS CLI.
- Build & push Docker image to AWS.
- Create an ECS task definition.
- Create an ECS cluster.
- Schedule to your tasks.
In total it shouldn’t take you longer than 20 minutes to get through this, using the code I’ll provide you with. This assumes you have an AWS account ready, and if not, add on 5 to 10 minutes.
The Code
First create a new folder locally and locate into it.
mkdir etl-pipelines
cd etl-pipelines
Make sure you have python installed.
python --version
If not, install it locally.
Once you’re ready, you can go ahead and clone the template I have already set up.
git clone https://github.com/ilsilfverskiold/etl-pipeline-fargate.git
When it has finished fetching the code, open it up in your code editor.
First check the main.py file to look how I’ve structured the code to understand what it does.
Essentially, it will fetch all names with “Doe” in it from a table in BigQuery that you specify, transform these names and then insert them back into the same data table as new rows.
You can go into each helper function to see how we set up the SQL Query job, transform the data and then insert it back to the BigQuery table.
The idea is of course that you set up something more complex but this is a simple test run to make it easy to tweak the code.
Setting Up BigQuery
If you want to continue with the code I’ve prepared you will need to set up a few things in BigQuery. Otherwise you can skip this part.
Here are the things you will need:
- A BigQuery table with a field of ‘name’ as a string.
- A few rows in the data table with the name “Doe” in it.
- A service account that will have access to this dataset.
To get a service account you will need to navigate to IAM in the Google Cloud Console and then to Service Accounts.
Once there, create a new service account.
Once it has been created, you will need to give your service account BigQuery User access globally via IAM.
You will also have to give this service account access to the dataset itself which you do in BigQuery directly via the dataset’s Share button and then by pressing Add Principal.
After you’ve given the user the appropriate permissions, make sure you go back to the Service Accounts and then download a key. This will give you a json file that you need to put in your root folder.
Now, the most important part is making sure the code has access to the google credentials and is using the correct data table.
You’ll want the json file you’ve downloaded with the Google credentials in your root folder as google_credentials.json and then you want to specify the correct table ID.
Now you might argue that you do not want to store your credentials locally which is only right.
You can add in the option of storing your json file in AWS Secrets Manager later. However, to start, this will be easier.
Run ETL Pipeline Locally
We’ll run this code locally first, just so we can see that it works.
So, set up a Python virtual environment and activate it.
python -m venv etl-env
source etl-env/bin/activate # On Windows use `venv\Scripts\activate`
Then install dependencies. We only have google-cloud-bigquery in there but ideally you will have more dependencies.
pip install -r requirements.txt
Run the main script.
python main.py
This should log ‘New rows have been added’ in your terminal. This will then confirm that the code works as we’ve intended.
The Docker Image
Now to push this code to ECS we will have to bundle it up into a Docker image which means that you will need Docker installed locally.
If you do not have Docker installed, you can download it here.
Docker helps us package an application and its dependencies into an image, which can be easily recognized and run on any system. Using ECS, it’s required of us to bundle our code into Docker images, which are then referenced by a task definition to run as containers.
I have already set up a Dockerfile in your folder. You should be able to look into it there.
FROM --platform=linux/amd64 python:3.11-slim
WORKDIR /app
COPY . /app
RUN pip install --no-cache-dir -r requirements.txt
CMD ["python", "main.py"]
As you see, I’ve kept this really lean as we’re not connecting web traffic to any ports here.
We’re specifying AMD64 which you may not need if you are not on a Mac with an M1 chip but it shouldn’t hurt. This will specify to AWS the architecture of the docker image so we don’t run into compatibility issues.
Create an IAM User
When working with AWS, access will need to be specified. Most of the issues you’ll run into are permission issues. We’ll be working with the CLI locally, and for this to work we’ll have to create an IAM user that will need quite broad permissions.
Go to the AWS console and then navigate to IAM. Create a new user, add permissions and then create a new policy to attach to it.
I have specified the permissions needed in your code in the aws_iam_user.json file. You’ll see a short snippet below of what this json file looks like.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"iam:CreateRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy",
"ecs:DescribeTaskDefinition",
...more
],
"Resource": "*"
}
]
}
You’ll need to go into this file to get all the permissions you will need to set, this is just a short snippet. I’ve set it to quite a few, which you may want to tweak to your own preferences later.
Once you’ve created the IAM user and you’ve added the correct permissions to it, you will need to generate an access key. Choose ‘Command Line Interface (CLI)’ when asked about your use case.
Download the credentials. We’ll use these to authenticate in a bit.
Set up the AWS CLI
Next, we’ll connect our terminal to our AWS account.
If you don’t have the CLI set up yet you can follow the instructions here. It is really easy to set this up.
Once you’ve installed the AWS CLI you’ll need to authenticate with the IAM user we just created.
aws configure
Use the credentials we downloaded from the IAM user in the previous step.
Create an ECR Repository
Now, we can get started with the DevOps of it all.
We’ll first need to create a repository in Elastic Container Registry. ECR is where we can store and manage our docker images. We’ll be able to reference these images from ECR when we set up our task definitions.
To create a new ECR repository run this command in your terminal. This will create a repository called bigquery-etl-pipeline.
aws ecr create-repository — repository-name bigquery-etl-pipeline
Note the repository URI you get back.
From here we have to build the docker image and then push this image to this repository.
To do this you can technically go into the AWS console and find the ECR repository we just created. Here AWS will let us see the entire push commands we need to run to authenticate, build and push our docker image to this ECR repository.
However, if you are on a Mac I would advice you to specify the architecture when building the docker image or you may run into issues.
If you are following along with me, then start with authenticating your docker client like so.
aws ecr get-login-password --region YOUR_REGION | docker login --username AWS --password-stdin YOUR_ACCOUNT_ID.dkr.ecr.YOUR_REGION.amazonaws.com
Be sure to change the values, region and account ID where applicable.
Build the docker image.
docker buildx build --platform=linux/amd64 -t bigquery-etl-pipeline .
This is where I have tweaked the command to specify the linux/amd64 architecture.
Tag the docker image.
docker tag bigquery-etl-pipeline:latest YOUR_ACCOUNT_ID.dkr.ecr.YOUR_REGION.amazonaws.com/bigquery-etl-pipeline:latest
Push the docker image.
docker push YOUR_ACCOUNT_ID.dkr.ecr.YOUR_REGION.amazonaws.com/bigquery-etl-pipeline:latest
If everything worked as planned you’ll see something like this in your terminal.
9f691c4f0216: Pushed
ca0189907a60: Pushed
687f796c98d5: Pushed
6beef49679a3: Pushed
b0dce122021b: Pushed
4de04bd13c4a: Pushed
cf9b23ff5651: Pushed
644fed2a3898: Pushed
Now that we have pushed the docker image to an ECR repository, we can use it to set up our task definition using Fargate.
If you run into EOF issues here it is most likely related to IAM permissions. Be sure to give it everything it needs, in this case full access to ECR to tag and push the image.
Roles & Log Groups
Remember what I told you before, the biggest issues you’ll run into in AWS pertains to roles between different services.
For this to flow neatly we’ll have to make sure we set up a few things before we start setting up a task definition and an ECS cluster.
To do this, we first have to create a task role — this role is the role that will need access to services in the AWS ecosystem from our container — and then the execution role — so the container will be able to pull the docker image from ECR.
aws iam create-role --role-name etl-pipeline-task-role --assume-role-policy-document file://ecs-tasks-trust-policy.json
aws iam create-role - role-name etl-pipeline-execution-role - assume-role-policy-document file://ecs-tasks-trust-policy.json
I have specified a json file called ecs-tasks-trust-policy.json in your folder locally that it will use to create these roles.
For the script that we are pushing, it won’t need to have permission to access other AWS services so for now there is no need to attach policies to the task role. Nevertheless, you may want to do this later.
However, for the execution role though we will need to give it ECR access to pull the docker image.
To attach the policy AmazonECSTaskExecutionRolePolicy to the execution role run this command.
aws iam attach-role-policy --role-name etl-pipeline-execution-role --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
We also create one last role while we’re at it, a service role.
aws iam create-service-linked-role - aws-service-name ecs.amazonaws.com
If you don’t create the service role you may end up with an errors such as ‘Unable to assume the service linked role. Please verify that the ECS service linked role exists’ when you try to run a task.
The last thing we create a log group. Creating a log group is essential for capturing and accessing logs generated by your container.
To create a log group you can run this command.
aws logs create-log-group - log-group-name /ecs/etl-pipeline-logs
Once you’ve created the execution role, the task role, the service role and then the log group we can continue to set up the ECS task definition.
Create an ECS Task Definition
A task definition is a blueprint for your tasks, specifying what container image to use, how much CPU and memory is needed, and other configurations. We use this blueprint to run tasks in our ECS cluster.
I have already set up the task definition in your code at task-definition.json. However, you need to set your account id as well as region in there to make sure it runs as it should.
{
"family": "my-etl-task",
"taskRoleArn": "arn:aws:iam::ACCOUNT_ID:role/etl-pipeline-task-role",
"executionRoleArn": "arn:aws:iam::ACCOUNT_ID:role/etl-pipeline-execution-role",
"networkMode": "awsvpc",
"containerDefinitions": [
{
"name": "my-etl-container",
"image": "ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/bigquery-etl-pipeline:latest",
"cpu": 256,
"memory": 512,
"essential": true,
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/etl-pipeline-logs",
"awslogs-region": "REGION",
"awslogs-stream-prefix": "ecs"
}
}
}
],
"requiresCompatibilities": ["FARGATE"],
"cpu": "256",
"memory": "512"
}
Remember the URI we got back when we created the ECR repository? This is where we’ll use it. Remember the execution role, the task role and the log group? We’ll use it there as well.
If you’ve named the ECR repository along with the roles and log group exactly what I named mine then you can simply change the account ID and Region in this json otherwise make sure the URI is the correct one.
You can also set CPU and memory here for what you’ll need to run your task — i.e. your code. I’ve set .25 vCPU and 512 mb as memory.
Once you’re satisfied you can register the task definition in your terminal.
aws ecs register-task-definition --cli-input-json file://task-definition.json
Now you should be able to go into Amazon Elastic Container Service and then find the task we’ve created under Task Definitions.
This task — i.e. blueprint — won’t run on it’s own, we need to invoke it later.
Create an ECS Cluster
An ECS Cluster serves as a logical grouping of tasks or services. You specify this cluster when running tasks or creating services.
To create a cluster via the CLI run this command.
aws ecs create-cluster --cluster-name etl-pipeline-cluster
Once you run this command, you’ll be able to see this cluster in ECS in your AWS console if you look there.
We’ll attach the Task Definition we just created to this cluster when we run it for the next part.
Run Task
Before we can run the task we need to get ahold of the subnets that are available to us along with a security group id.
We can do this directly in the terminal via the CLI.
Run this command in the terminal to get the available subnets.
aws ec2 describe-subnets
You’ll get back an array of objects here, and you’re looking for the SubnetId for each object.
If you run into issues here, make sure your IAM has the appropriate permissions. See the aws_iam_user.json file in your root folder for the permissions the IAM user connected to the CLI will need. I will stress this, because it’s the main issues that I always run into.
To get the security group ID you can run this command.
aws ec2 describe-security-groups
You are looking for GroupId here in the terminal.
If you got at least one SubnetId and then a GroupId for a security group, we’re ready to run the task to test that the blueprint — i.e. task definition — works.
aws ecs run-task \
--cluster etl-pipeline-cluster \
--launch-type FARGATE \
--task-definition my-etl-task \
--count 1 \
--network-configuration "awsvpcConfiguration={subnets=[SUBNET_ID],securityGroups=[SECURITY_GROUP_ID],assignPublicIp=ENABLED}"
Do remember to change the names if you’ve named your cluster and task definition differently. Remember to also set your subnet ID and security group ID.
Now you can navigate to the AWS console to see the task running.
If you are having issues you can look into the logs.
If successful, you should see a few transformed rows added to BigQuery.
EventBridge Schedule
Now, we’ve managed to set up the task to run in an ECS cluster. But what we’re interested in is to make it run on a schedule. This is where EventBridge comes in.
EventBridge will set up our scheduled events, and we can set this up using the CLI as well. However, before we set up the schedule we first need to create a new role.
This is life when working with AWS, everything needs to have permission to interact with each other.
In this case, EventBridge will need permission to call the ECS cluster on our behalf.
In the repository you have a file called trust-policy-for-eventbridge.json that I have already put there, we’ll use this file to create this EventBridge role.
Paste this into the terminal and run it.
aws iam create-role \
--role-name ecsEventsRole \
--assume-role-policy-document file://trust-policy-for-eventbridge.json
We then have to attach a policy to this role.
aws iam attach-role-policy \
--role-name ecsEventsRole \
--policy-arn arn:aws:iam::aws:policy/AmazonECS_FullAccess
We need it to at least be able to have ecs:RunTask but we’ve given it full access. If you prefer to limit the permissions, you can create a custom policy with just the necessary permissions instead.
Now let’s set up the rule to schedule the task to run with the task definition every day at 5 am UTC. This is usually the time I’d like for it to process data for me so if it fails I can look into it after breakfast.
aws events put-rule \
--name "ETLPipelineDailyRun" \
--schedule-expression "cron(0 5 * * ? *)" \
--state ENABLED
You should receive back an object with a field called RuleArn here. This is just to confirm that it worked.
Next step is now to associate the rule with the ECS task definition.
aws events put-targets --rule "ETLPipelineDailyRun" \
--targets "[{\"Id\":\"1\",\"Arn\":\"arn:aws:ecs:REGION:ACCOUNT_NUMBER:cluster/etl-pipeline-cluster\",\"RoleArn\":\"arn:aws:iam::ACCOUNT_NUMBER:role/ecsEventsRole\",\"EcsParameters\":{\"TaskDefinitionArn\":\"arn:aws:ecs:REGION:ACCOUNT_NUMBER:task-definition/my-etl-task\",\"TaskCount\":1,\"LaunchType\":\"FARGATE\",\"NetworkConfiguration\":{\"awsvpcConfiguration\":{\"Subnets\":[\"SUBNET_ID\"],\"SecurityGroups\":[\"SECURITY_GROUP_ID\"],\"AssignPublicIp\":\"ENABLED\"}}}}]"
Remember to set your own values here for region, account number, subnet and security group.
Use the subnets and security group that we got earlier. You can set multiple subnets.
Once you’ve run the command the task is scheduled for 5 am every day and you’ll find it under Scheduled Tasks in the AWS Console.
AWS Secrets Manager (Optional)
So keeping your Google credentials in the root folder isn’t ideal, even if you’ve limited access to your datasets for the Google service account.
Here we can add on the option of moving these credentials to another AWS service and then accessing it from our container.
For this to work you’ll have to move the credentials file to Secrets Manager, tweak the code so it can fetch it to authenticate and make sure that the task role has permissions to access AWS Secrets Manager on your behalf.
When you’re done you can simply push the updated docker image to your ECR repo you set up before.
The End Result
Now you’ve got a very simple ETL pipeline running in a container on AWS on a schedule. The idea is that you add to it to do your own data transformations.
Hopefully this was a useful piece for anyone that is transitioning to setting up their long-running data transformation scripts on ECS in a simple, cost effective and straightforward way.
Let me know if you run into any issues in case there is something I missed to include.
❤
Deploy Long-Running ETL Pipelines to ECS with Fargate was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.