
Designing and Deploying a Machine Learning Python Application (Part 2)
You don’t have to be Atlas to get your model into the cloud
Now that we have our trained Detectron2 model (see Part 1), let’s deploy it as a part of an application to provide its inferencing abilities to others.
Even though Part 1 and 2 of this series use Detectron2 for Object Detection, no matter the machine learning library you are using (Detectron, Yolo, PyTorch, Tensorflow, etc) and no matter your use case (Computer Vision, Natural Language Processing, Deep Learning, etc), various topics discussed here concerning model deployment will be useful for all those developing ML processes.
Although the fields of Data Science and Computer Science overlap in many ways, training and deploying an ML model combines the two, as those concerned with developing an efficient and accurate model are not typically the ones trying to deploy it and vice versa. On the other hand, someone more CS oriented may not have the understanding of ML or its associated libraries to determine whether application bottlenecks could be fixed with configurations to the ML process or rather the backend and hosting service/s.
In order to aid you in your quest to deploy an application that utilizes ML, this article will begin by discussing: (1) high level CS design concepts that can help DS folks makes decisions in order to balance load and mitigate bottlenecks and (2) low level design by walking through deploying a Detectron2 inferencing process using the Python web framework Django, an API using Django Rest Framework, the distributed task queue Celery, Docker, Heroku, and AWS S3.
For following along with this article, it will be helpful to have in advance:
- Strong Python Knowledge
- Understanding of Django, Django Rest Framework, Docker, Celery, and AWS
- Familiarity with Heroku
High Level Design
In order to dig into the high level design, let’s discuss a couple key problems and potential solutions.
Problem 1: Memory
The saved ML model from Part 1, titled model_final.pth, will start off at ~325MB. With more training data, the model will increase in size, with models trained on large datasets (100,000+ annotated images) increasing to ~800MB. Additionally, an application based on (1) a Python runtime, (2) Detectron2, (3) large dependencies such as Torch, and (4) a Django web framework will utilize ~150MB of memory on deployment.
So at minimum, we are looking at ~475MB of memory utilized right off the bat.
We could load the Detectron2 model only when the ML process needs to run, but this would still mean that our application would eat up ~475MB eventually. If you have a tight budget and are unable to vertically scale your application, memory now becomes a substantial limitation on many hosting platforms. For example, Heroku offers containers to run applications, termed “dynos”, that started with 512MB RAM for base payment plans, will begin writing to disk beyond the 512MB threshold, and will crash and restart the dyno at 250% utilization (1280MB).
On the topic of memory, Detectron2 inferencing will cause spikes in memory usage depending on the amount of objects detected in an image, so it is important to ensure memory is available during this process.
For those of you trying to speed up inferencing, but are cautious of memory constraints, batch inferencing will be of no help here either. As noted by one of the contributors to the Detectron2 repo, with batch inferencing:
N images use N times more memory than 1 image…You can predict on N images one by one in a loop instead.
Overall, this summarizes problem #1:
running a long ML processes as a part of an application will most likely be memory intensive, due to the size of the model, ML dependencies, and inferencing process.
Problem 2: Time
A deployed application that incorporates ML will likely need to be designed to manage a long-running process.
Using the example of an application that uses Detectron2, the model would be sent an image as input and output inference coordinates. With one image, inference may only take a few seconds, but say for instance we are processing a long PDF document with one image per page (as per the training data in Part 1), this could take a while.
During this process, Detectron2 inferencing would be either CPU or GPU bound, depending on your configurations. See the below Python code block to change this (CPU is entirely fine for inferencing, however, GPU/Cuda is necessary for training as mentioned in Part 1):
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.MODEL.DEVICE = "cpu" #or "cuda"
Additionally, saving images after inferencing, say to AWS S3 for example, would introduce I/O bound processes. Altogether, this could serve to clog up the backend, which introduces problem #2:
single-threaded Python applications will not process additional HTTP requests, concurrently or otherwise, while running a process.
Problem 3: Scale
When considering the horizontal scalability of a Python application, it is important to note that Python (assuming it is compiled/interpreted by CPython) suffers from the limitations of the Global Interpreter Lock (GIL), which allows only one thread to hold the control of the Python interpreter. Thus, the paradigm of multithreading doesn’t correctly apply to Python, as applications can still implement multithreading, using web servers such as Gunicorn, but will do so concurrently, meaning that the threads aren’t running in parallel.
I know all of this sounds fairly abstract, perhaps especially for the Data Science folks, so let me provide an example to illustrate this problem.
You are your application and right now your hardware, brain, is processing two requests, cleaning the counter and texting on your phone. With two arms to do this, you are now a multithreaded Python application, doing both simultaneously. But you’re not actually thinking about both at the same exact time, you start your hand in a cleaning motion, then switch your attention to your phone to look at what you are typing, then look back at the counter to make sure you didn’t miss a spot.
In actuality, you are processing these tasks concurrently.
The GIL functions in the same way, processing one thread at a time but switching between them for concurrency. This means that multithreading a Python application is still useful for running background or I/O bound-oriented tasks, such as downloading a file, while the main execution’s thread is still running. To take the analogy this far, your background task of cleaning the counter (i.e. downloading a file) continues to happen while you are thinking about texting, but you still need to change your focus back to your cleaning hand in order to process the next step.
This “change in focus” may not seem like a big deal when concurrently processing multiple requests, but when you need to handle hundreds of requests simultaneously, suddenly this becomes a limiting factor for large scale applications that need to be adequately responsive to end users.
Thus, we have problem #3:
the GIL prevents multithreading from being a good scalability solution for Python applications.
Solutions
Now that we have identified key problems, let’s discuss a few potential solutions.
The aforementioned problems are ordered in terms of importance, as we need to manage memory first and foremost (problem #1) to ensure the application doesn’t crash, then leave room for the app to process more than one request at a time (problem #2) while still ensuring our means of simultaneous request handling is effective at scale (problem #3).
So, let’s jump right into addressing problem #1.
Depending on the hosting platform, we will need to be fully aware of the configurations available in order to scale. As we will be using Heroku, feel free to check out the guidance on dyno scaling. Without having to vertically scale up your dyno, we can scale out by adding another process. For instance, with the Basic dyno type, a developer is able to deploy both a web process and a worker process on the same dyno. A few reasons this is useful:
- This enables a means of multiprocessing.
- The dyno resources are now duplicated, meaning each process has a 512MB RAM threshold.
- Cost wise, we are looking at $7 per month per process (so $14 a month with both a web and worker process). Much cheaper than vertically scaling the dyno to get more RAM, with $50 a month per dyno if you want to increase the 512MB allocation to 1024MB.
Hopping back to the previous analogy of cleaning the counter and texting on your phone, instead of threading yourself further by adding additional arms to your body, we can now have two people (multiprocessing in parallel) to perform the separate tasks. We are scaling out by increasing workload diversity as opposed to scaling up, in turn saving us money.
Okay, but with two separate processes, what’s the difference?
Using Django, our web process will be initialized with:
python manage.py runserver
And using a distributed task queue, such as Celery, the worker will be initialized with:
celery -A <DJANGO_APP_NAME_HERE> worker
As intended by Heroku, the web process is the server for our core web framework and the worker process is intended for queuing libraries, cron jobs, or other work performed in the background. Both represent an instance of the deployed application, so will be running at ~150MB given the core dependencies and runtime. However, we can ensure that the worker is the only process that runs the ML tasks, saving the web process from using ~325MB+ in RAM. This has multiple benefits:
- Memory usage, although still high for the worker, will be distributed to a node outside of the system, ensuring any problems encountered during the execution of an ML task can be handled and monitored separately from the web process. This helps to mitigate problem #1.
- The newly found means of parallelism ensures that the web process can still respond to requests during a long-running ML task, helping to address problem #2.
- We are preparing for scale by implementing a means of multiprocessing, helping to address problem #3.
As we haven’t quite solved the key problems, let’s dig in just a bit further before getting into the low-level nitty-gritty. As stated by Heroku:
Web applications that process incoming HTTP requests concurrently make much more efficient use of dyno resources than web applications that only process one request at a time. Because of this, we recommend using web servers that support concurrent request processing whenever developing and running production services.
The Django and Flask web frameworks feature convenient built-in web servers, but these blocking servers only process a single request at a time. If you deploy with one of these servers on Heroku, your dyno resources will be underutilized and your application will feel unresponsive.
We are already ahead of the game by utilizing worker multiprocessing for the ML task, but can take this a step further by using Gunicorn:
Gunicorn is a pure-Python HTTP server for WSGI applications. It allows you to run any Python application concurrently by running multiple Python processes within a single dyno. It provides a perfect balance of performance, flexibility, and configuration simplicity.
Okay, awesome, now we can utilize even more processes, but there’s a catch: each new worker Gunicorn worker process will represent a copy of the application, meaning that they too will utilize the base ~150MB RAM in addition to the Heroku process. So, say we pip install gunicorn and now initialize the Heroku web process with the following command:
gunicorn <DJANGO_APP_NAME_HERE>.wsgi:application --workers=2 --bind=0.0.0.0:$PORT
The base ~150MB RAM in the web process turns into ~300MB RAM (base memory usage multipled by # gunicorn workers).
While being cautious of the limitations to multithreading a Python application, we can add threads to workers as well using:
gunicorn <DJANGO_APP_NAME_HERE>.wsgi:application --threads=2 --worker-class=gthread --bind=0.0.0.0:$PORT
Even with problem #3, we can still find a use for threads, as we want to ensure our web process is capable of processing more than one request at a time while being careful of the application’s memory footprint. Here, our threads could process miniscule requests while ensuring the ML task is distributed elsewhere.
Either way, by utilizing gunicorn workers, threads, or both, we are setting our Python application up to process more than one request at a time. We’ve more or less solved problem #2 by incorporating various ways to implement concurrency and/or parallel task handling while ensuring our application’s critical ML task doesn’t rely on potential pitfalls, such as multithreading, setting us up for scale and getting to the root of problem #3.
Okay so what about that tricky problem #1. At the end of the day, ML processes will typically end up taxing the hardware in one way or another, whether that would be memory, CPU, and/or GPU. However, by using a distributed system, our ML task is integrally linked to the main web process yet handled in parallel via a Celery worker. We can track the start and end of the ML task via the chosen Celery broker, as well as review metrics in a more isolated manner. Here, curtailing Celery and Heroku worker process configurations are up to you, but it is an excellent starting point for integrating a long-running, memory-intensive ML process into your application.
Low Level Design and Setup
Now that we’ve had a chance to really dig in and get a high level picture of the system we are building, let’s put it together and focus on the specifics.
For your convenience, here is the repo I will be mentioning in this section.
First we will begin by setting up Django and Django Rest Framework, with installation guides here and here respectively. All requirements for this app can be found in the repo’s requirements.txt file (and Detectron2 and Torch will be built from Python wheels specified in the Dockerfile, in order to keep the Docker image size small).
The next part will be setting up the Django app, configuring the backend to save to AWS S3, and exposing an endpoint using DRF, so if you are already comfortable doing this, feel free to skip ahead and go straight to the ML Task Setup and Deployment section.
Django Setup
Go ahead and create a folder for the Django project and cd into it. Activate the virtual/conda env you are using, ensure Detectron2 is installed as per the installation instructions in Part 1, and install the requirements as well.
Issue the following command in a terminal:
django-admin startproject mltutorial
This will create a Django project root directory titled “mltutorial”. Go ahead and cd into it to find a manage.py file and a mltutorial sub directory (which is the actual Python package for your project).
mltutorial/
manage.py
mltutorial/
__init__.py
settings.py
urls.py
asgi.py
wsgi.py
Open settings.py and add ‘rest_framework’, ‘celery’, and ‘storages’ (needed for boto3/AWS) in the INSTALLED_APPS list to register those packages with the Django project.
In the root dir, let’s create an app which will house the core functionality of our backend. Issue another terminal command:
python manage.py startapp docreader
This will create an app in the root dir called docreader.
Let’s also create a file in docreader titled mltask.py. In it, define a simple function for testing our setup that takes in a variable, file_path, and prints it out:
def mltask(file_path):
return print(file_path)
Now getting to structure, Django apps use the Model View Controller (MVC) design pattern, defining the Model in models.py, View in views.py, and Controller in Django Templates and urls.py. Using Django Rest Framework, we will include serialization in this pipeline, which provide a way of serializing and deserializing native Python dative structures into representations such as json. Thus, the application logic for exposing an endpoint is as follows:
Database ← → models.py ← → serializers.py ← → views.py ← → urls.py
In docreader/models.py, write the following:
from django.db import models
from django.dispatch import receiver
from .mltask import mltask
from django.db.models.signals import(
post_save
)
class Document(models.Model):
title = models.CharField(max_length=200)
file = models.FileField(blank=False, null=False)
@receiver(post_save, sender=Document)
def user_created_handler(sender, instance, *args, **kwargs):
mltask(str(instance.file.file))
This sets up a model Document that will require a title and file for each entry saved in the database. Once saved, the @receiver decorator listens for a post save signal, meaning that the specified model, Document, was saved in the database. Once saved, user_created_handler() takes the saved instance’s file field and passes it to, what will become, our Machine Learning function.
Anytime changes are made to models.py, you will need to run the following two commands:
python manage.py makemigrations
python manage.py migrate
Moving forward, create a serializers.py file in docreader, allowing for the serialization and deserialization of the Document’s title and file fields. Write in it:
from rest_framework import serializers
from .models import Document
class DocumentSerializer(serializers.ModelSerializer):
class Meta:
model = Document
fields = [
'title',
'file'
]
Next in views.py, where we can define our CRUD operations, let’s define the ability to create, as well as list, Document entries using generic views (which essentially allows you to quickly write views using an abstraction of common view patterns):
from django.shortcuts import render
from rest_framework import generics
from .models import Document
from .serializers import DocumentSerializer
class DocumentListCreateAPIView(
generics.ListCreateAPIView):
queryset = Document.objects.all()
serializer_class = DocumentSerializer
Finally, update urls.py in mltutorial:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path('api/', include('docreader.urls')),
]
And create urls.py in docreader app dir and write:
from django.urls import path
from . import views
urlpatterns = [
path('create/', views.DocumentListCreateAPIView.as_view(), name='document-list'),
]
Now we are all setup to save a Document entry, with title and field fields, at the /api/create/ endpoint, which will call mltask() post save! So, let’s test this out.
To help visualize testing, let’s register our Document model with the Django admin interface, so we can see when a new entry has been created.
In docreader/admin.py write:
from django.contrib import admin
from .models import Document
admin.site.register(Document)
Create a user that can login to the Django admin interface using:
python manage.py createsuperuser
Now, let’s test the endpoint we exposed.
To do this without a frontend, run the Django server and go to Postman. Send the following POST request with a PDF file attached:
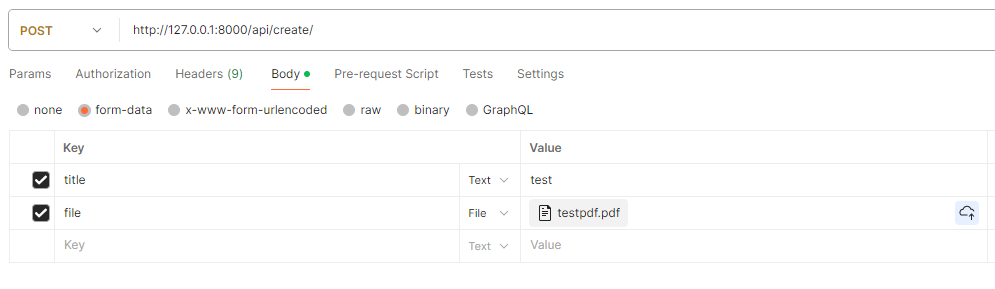
If we check our Django logs, we should see the file path printed out, as specified in the post save mltask() function call.
AWS Setup
You will notice that the PDF was saved to the project’s root dir. Let’s ensure any media is instead saved to AWS S3, getting our app ready for deployment.
Go to the S3 console (and create an account and get our your account’s Access and Secret keys if you haven’t already). Create a new bucket, here we will be titling it ‘djangomltest’. Update the permissions to ensure the bucket is public for testing (and revert back, as needed, for production).
Now, let’s configure Django to work with AWS.
Add your model_final.pth, trained in Part 1, into the docreader dir. Create a .env file in the root dir and write the following:
AWS_ACCESS_KEY_ID = <Add your Access Key Here>
AWS_SECRET_ACCESS_KEY = <Add your Secret Key Here>
AWS_STORAGE_BUCKET_NAME = 'djangomltest'
MODEL_PATH = './docreader/model_final.pth'
Update settings.py to include AWS configurations:
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
# AWS
AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID']
AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY']
AWS_STORAGE_BUCKET_NAME = os.environ['AWS_STORAGE_BUCKET_NAME']
#AWS Config
AWS_DEFAULT_ACL = 'public-read'
AWS_S3_CUSTOM_DOMAIN = f'{AWS_STORAGE_BUCKET_NAME}.s3.amazonaws.com'
AWS_S3_OBJECT_PARAMETERS = {'CacheControl': 'max-age=86400'}
#Boto3
STATICFILES_STORAGE = 'mltutorial.storage_backends.StaticStorage'
DEFAULT_FILE_STORAGE = 'mltutorial.storage_backends.PublicMediaStorage'
#AWS URLs
STATIC_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/static/'
MEDIA_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/media/'
Optionally, with AWS serving our static and media files, you will want to run the following command in order to serve static assets to the admin interface using S3:
python manage.py collectstatic
If we run the server again, our admin should appear the same as how it would with our static files served locally.
Once again, let’s run the Django server and test the endpoint to make sure the file is now saved to S3.
ML Task Setup and Deployment
With Django and AWS properly configured, let’s set up our ML process in mltask.py. As the file is long, see the repo here for reference (with comments added in to help with understanding the various code blocks).
What’s important to see is that Detectron2 is imported and the model is loaded only when the function is called. Here, we will call the function only through a Celery task, ensuring the memory used during inferencing will be isolated to the Heroku worker process.
So finally, let’s setup Celery and then deploy to Heroku.
In mltutorial/_init__.py write:
from .celery import app as celery_app
__all__ = ('celery_app',)
Create celery.py in the mltutorial dir and write:
import os
from celery import Celery
# Set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'mltutorial.settings')
# We will specify Broker_URL on Heroku
app = Celery('mltutorial', broker=os.environ['CLOUDAMQP_URL'])
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Load task modules from all registered Django apps.
app.autodiscover_tasks()
@app.task(bind=True, ignore_result=True)
def debug_task(self):
print(f'Request: {self.request!r}')
Lastly, make a tasks.py in docreader and write:
from celery import shared_task
from .mltask import mltask
@shared_task
def ml_celery_task(file_path):
mltask(file_path)
return "DONE"
This Celery task, ml_celery_task(), should now be imported into models.py and used with the post save signal instead of the mltask function pulled directly from mltask.py. Update the post_save signal block to the following:
@receiver(post_save, sender=Document)
def user_created_handler(sender, instance, *args, **kwargs):
ml_celery_task.delay(str(instance.file.file))
And to test Celery, let’s deploy!
In the root project dir, include a Dockerfile and heroku.yml file, both specified in the repo. Most importantly, editing the heroku.yml commands will allow you to configure the gunicorn web process and the Celery worker process, which can aid in further mitigating potential problems.
Make a Heroku account and create a new app called “mlapp” and gitignore the .env file. Then initialize git in the projects root dir and change the Heroku app’s stack to container (in order to deploy using Docker):
$ heroku login
$ git init
$ heroku git:remote -a mlapp
$ git add .
$ git commit -m "initial heroku commit"
$ heroku stack:set container
$ git push heroku master
Once pushed, we just need to add our env variables into the Heroku app.
Go to settings in the online interface, scroll down to Config Vars, click Reveal Config Vars, and add each line listed in the .env file.

You may have noticed there was a CLOUDAMQP_URL variable specified in celery.py. We need to provision a Celery Broker on Heroku, for which there are a variety of options. I will be using CloudAMQP which has a free tier. Go ahead and add this to your app. Once added, the CLOUDAMQP_URL environment variable will be included automatically in the Config Vars.
Finally, let’s test the final product.
To monitor requests, run:
$ heroku logs --tail
Issue another Postman POST request to the Heroku app’s url at the /api/create/ endpoint. You will see the POST request come through, Celery receive the task, load the model, and start running pages:

We will continue to see the “Running for page…” until the end of the process and you can check the AWS S3 bucket as it runs.
Congrats! You’ve now deployed and ran a Python backend using Machine Learning as a part of a distributed task queue running in parallel to the main web process!
As mentioned, you will want to adjust the heroku.yml commands to incorporate gunicorn threads and/or worker processes and fine tune celery. For further learning, here’s a great article on configuring gunicorn to meet your app’s needs, one for digging into Celery for production, and another for exploring Celery worker pools, in order to help with properly managing your resources.
Happy coding!
Unless otherwise noted, all images used in this article are by the author
Designing and Deploying a Machine Learning Python Application (Part 2) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
You don’t have to be Atlas to get your model into the cloud

Now that we have our trained Detectron2 model (see Part 1), let’s deploy it as a part of an application to provide its inferencing abilities to others.
Even though Part 1 and 2 of this series use Detectron2 for Object Detection, no matter the machine learning library you are using (Detectron, Yolo, PyTorch, Tensorflow, etc) and no matter your use case (Computer Vision, Natural Language Processing, Deep Learning, etc), various topics discussed here concerning model deployment will be useful for all those developing ML processes.
Although the fields of Data Science and Computer Science overlap in many ways, training and deploying an ML model combines the two, as those concerned with developing an efficient and accurate model are not typically the ones trying to deploy it and vice versa. On the other hand, someone more CS oriented may not have the understanding of ML or its associated libraries to determine whether application bottlenecks could be fixed with configurations to the ML process or rather the backend and hosting service/s.
In order to aid you in your quest to deploy an application that utilizes ML, this article will begin by discussing: (1) high level CS design concepts that can help DS folks makes decisions in order to balance load and mitigate bottlenecks and (2) low level design by walking through deploying a Detectron2 inferencing process using the Python web framework Django, an API using Django Rest Framework, the distributed task queue Celery, Docker, Heroku, and AWS S3.
For following along with this article, it will be helpful to have in advance:
- Strong Python Knowledge
- Understanding of Django, Django Rest Framework, Docker, Celery, and AWS
- Familiarity with Heroku
High Level Design
In order to dig into the high level design, let’s discuss a couple key problems and potential solutions.
Problem 1: Memory
The saved ML model from Part 1, titled model_final.pth, will start off at ~325MB. With more training data, the model will increase in size, with models trained on large datasets (100,000+ annotated images) increasing to ~800MB. Additionally, an application based on (1) a Python runtime, (2) Detectron2, (3) large dependencies such as Torch, and (4) a Django web framework will utilize ~150MB of memory on deployment.
So at minimum, we are looking at ~475MB of memory utilized right off the bat.
We could load the Detectron2 model only when the ML process needs to run, but this would still mean that our application would eat up ~475MB eventually. If you have a tight budget and are unable to vertically scale your application, memory now becomes a substantial limitation on many hosting platforms. For example, Heroku offers containers to run applications, termed “dynos”, that started with 512MB RAM for base payment plans, will begin writing to disk beyond the 512MB threshold, and will crash and restart the dyno at 250% utilization (1280MB).
On the topic of memory, Detectron2 inferencing will cause spikes in memory usage depending on the amount of objects detected in an image, so it is important to ensure memory is available during this process.
For those of you trying to speed up inferencing, but are cautious of memory constraints, batch inferencing will be of no help here either. As noted by one of the contributors to the Detectron2 repo, with batch inferencing:
N images use N times more memory than 1 image…You can predict on N images one by one in a loop instead.
Overall, this summarizes problem #1:
running a long ML processes as a part of an application will most likely be memory intensive, due to the size of the model, ML dependencies, and inferencing process.
Problem 2: Time
A deployed application that incorporates ML will likely need to be designed to manage a long-running process.
Using the example of an application that uses Detectron2, the model would be sent an image as input and output inference coordinates. With one image, inference may only take a few seconds, but say for instance we are processing a long PDF document with one image per page (as per the training data in Part 1), this could take a while.
During this process, Detectron2 inferencing would be either CPU or GPU bound, depending on your configurations. See the below Python code block to change this (CPU is entirely fine for inferencing, however, GPU/Cuda is necessary for training as mentioned in Part 1):
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.MODEL.DEVICE = "cpu" #or "cuda"
Additionally, saving images after inferencing, say to AWS S3 for example, would introduce I/O bound processes. Altogether, this could serve to clog up the backend, which introduces problem #2:
single-threaded Python applications will not process additional HTTP requests, concurrently or otherwise, while running a process.
Problem 3: Scale
When considering the horizontal scalability of a Python application, it is important to note that Python (assuming it is compiled/interpreted by CPython) suffers from the limitations of the Global Interpreter Lock (GIL), which allows only one thread to hold the control of the Python interpreter. Thus, the paradigm of multithreading doesn’t correctly apply to Python, as applications can still implement multithreading, using web servers such as Gunicorn, but will do so concurrently, meaning that the threads aren’t running in parallel.
I know all of this sounds fairly abstract, perhaps especially for the Data Science folks, so let me provide an example to illustrate this problem.
You are your application and right now your hardware, brain, is processing two requests, cleaning the counter and texting on your phone. With two arms to do this, you are now a multithreaded Python application, doing both simultaneously. But you’re not actually thinking about both at the same exact time, you start your hand in a cleaning motion, then switch your attention to your phone to look at what you are typing, then look back at the counter to make sure you didn’t miss a spot.
In actuality, you are processing these tasks concurrently.
The GIL functions in the same way, processing one thread at a time but switching between them for concurrency. This means that multithreading a Python application is still useful for running background or I/O bound-oriented tasks, such as downloading a file, while the main execution’s thread is still running. To take the analogy this far, your background task of cleaning the counter (i.e. downloading a file) continues to happen while you are thinking about texting, but you still need to change your focus back to your cleaning hand in order to process the next step.
This “change in focus” may not seem like a big deal when concurrently processing multiple requests, but when you need to handle hundreds of requests simultaneously, suddenly this becomes a limiting factor for large scale applications that need to be adequately responsive to end users.
Thus, we have problem #3:
the GIL prevents multithreading from being a good scalability solution for Python applications.
Solutions
Now that we have identified key problems, let’s discuss a few potential solutions.
The aforementioned problems are ordered in terms of importance, as we need to manage memory first and foremost (problem #1) to ensure the application doesn’t crash, then leave room for the app to process more than one request at a time (problem #2) while still ensuring our means of simultaneous request handling is effective at scale (problem #3).
So, let’s jump right into addressing problem #1.
Depending on the hosting platform, we will need to be fully aware of the configurations available in order to scale. As we will be using Heroku, feel free to check out the guidance on dyno scaling. Without having to vertically scale up your dyno, we can scale out by adding another process. For instance, with the Basic dyno type, a developer is able to deploy both a web process and a worker process on the same dyno. A few reasons this is useful:
- This enables a means of multiprocessing.
- The dyno resources are now duplicated, meaning each process has a 512MB RAM threshold.
- Cost wise, we are looking at $7 per month per process (so $14 a month with both a web and worker process). Much cheaper than vertically scaling the dyno to get more RAM, with $50 a month per dyno if you want to increase the 512MB allocation to 1024MB.
Hopping back to the previous analogy of cleaning the counter and texting on your phone, instead of threading yourself further by adding additional arms to your body, we can now have two people (multiprocessing in parallel) to perform the separate tasks. We are scaling out by increasing workload diversity as opposed to scaling up, in turn saving us money.
Okay, but with two separate processes, what’s the difference?
Using Django, our web process will be initialized with:
python manage.py runserver
And using a distributed task queue, such as Celery, the worker will be initialized with:
celery -A <DJANGO_APP_NAME_HERE> worker
As intended by Heroku, the web process is the server for our core web framework and the worker process is intended for queuing libraries, cron jobs, or other work performed in the background. Both represent an instance of the deployed application, so will be running at ~150MB given the core dependencies and runtime. However, we can ensure that the worker is the only process that runs the ML tasks, saving the web process from using ~325MB+ in RAM. This has multiple benefits:
- Memory usage, although still high for the worker, will be distributed to a node outside of the system, ensuring any problems encountered during the execution of an ML task can be handled and monitored separately from the web process. This helps to mitigate problem #1.
- The newly found means of parallelism ensures that the web process can still respond to requests during a long-running ML task, helping to address problem #2.
- We are preparing for scale by implementing a means of multiprocessing, helping to address problem #3.
As we haven’t quite solved the key problems, let’s dig in just a bit further before getting into the low-level nitty-gritty. As stated by Heroku:
Web applications that process incoming HTTP requests concurrently make much more efficient use of dyno resources than web applications that only process one request at a time. Because of this, we recommend using web servers that support concurrent request processing whenever developing and running production services.
The Django and Flask web frameworks feature convenient built-in web servers, but these blocking servers only process a single request at a time. If you deploy with one of these servers on Heroku, your dyno resources will be underutilized and your application will feel unresponsive.
We are already ahead of the game by utilizing worker multiprocessing for the ML task, but can take this a step further by using Gunicorn:
Gunicorn is a pure-Python HTTP server for WSGI applications. It allows you to run any Python application concurrently by running multiple Python processes within a single dyno. It provides a perfect balance of performance, flexibility, and configuration simplicity.
Okay, awesome, now we can utilize even more processes, but there’s a catch: each new worker Gunicorn worker process will represent a copy of the application, meaning that they too will utilize the base ~150MB RAM in addition to the Heroku process. So, say we pip install gunicorn and now initialize the Heroku web process with the following command:
gunicorn <DJANGO_APP_NAME_HERE>.wsgi:application --workers=2 --bind=0.0.0.0:$PORT
The base ~150MB RAM in the web process turns into ~300MB RAM (base memory usage multipled by # gunicorn workers).
While being cautious of the limitations to multithreading a Python application, we can add threads to workers as well using:
gunicorn <DJANGO_APP_NAME_HERE>.wsgi:application --threads=2 --worker-class=gthread --bind=0.0.0.0:$PORT
Even with problem #3, we can still find a use for threads, as we want to ensure our web process is capable of processing more than one request at a time while being careful of the application’s memory footprint. Here, our threads could process miniscule requests while ensuring the ML task is distributed elsewhere.
Either way, by utilizing gunicorn workers, threads, or both, we are setting our Python application up to process more than one request at a time. We’ve more or less solved problem #2 by incorporating various ways to implement concurrency and/or parallel task handling while ensuring our application’s critical ML task doesn’t rely on potential pitfalls, such as multithreading, setting us up for scale and getting to the root of problem #3.
Okay so what about that tricky problem #1. At the end of the day, ML processes will typically end up taxing the hardware in one way or another, whether that would be memory, CPU, and/or GPU. However, by using a distributed system, our ML task is integrally linked to the main web process yet handled in parallel via a Celery worker. We can track the start and end of the ML task via the chosen Celery broker, as well as review metrics in a more isolated manner. Here, curtailing Celery and Heroku worker process configurations are up to you, but it is an excellent starting point for integrating a long-running, memory-intensive ML process into your application.
Low Level Design and Setup
Now that we’ve had a chance to really dig in and get a high level picture of the system we are building, let’s put it together and focus on the specifics.
For your convenience, here is the repo I will be mentioning in this section.
First we will begin by setting up Django and Django Rest Framework, with installation guides here and here respectively. All requirements for this app can be found in the repo’s requirements.txt file (and Detectron2 and Torch will be built from Python wheels specified in the Dockerfile, in order to keep the Docker image size small).
The next part will be setting up the Django app, configuring the backend to save to AWS S3, and exposing an endpoint using DRF, so if you are already comfortable doing this, feel free to skip ahead and go straight to the ML Task Setup and Deployment section.
Django Setup
Go ahead and create a folder for the Django project and cd into it. Activate the virtual/conda env you are using, ensure Detectron2 is installed as per the installation instructions in Part 1, and install the requirements as well.
Issue the following command in a terminal:
django-admin startproject mltutorial
This will create a Django project root directory titled “mltutorial”. Go ahead and cd into it to find a manage.py file and a mltutorial sub directory (which is the actual Python package for your project).
mltutorial/
manage.py
mltutorial/
__init__.py
settings.py
urls.py
asgi.py
wsgi.py
Open settings.py and add ‘rest_framework’, ‘celery’, and ‘storages’ (needed for boto3/AWS) in the INSTALLED_APPS list to register those packages with the Django project.
In the root dir, let’s create an app which will house the core functionality of our backend. Issue another terminal command:
python manage.py startapp docreader
This will create an app in the root dir called docreader.
Let’s also create a file in docreader titled mltask.py. In it, define a simple function for testing our setup that takes in a variable, file_path, and prints it out:
def mltask(file_path):
return print(file_path)
Now getting to structure, Django apps use the Model View Controller (MVC) design pattern, defining the Model in models.py, View in views.py, and Controller in Django Templates and urls.py. Using Django Rest Framework, we will include serialization in this pipeline, which provide a way of serializing and deserializing native Python dative structures into representations such as json. Thus, the application logic for exposing an endpoint is as follows:
Database ← → models.py ← → serializers.py ← → views.py ← → urls.py
In docreader/models.py, write the following:
from django.db import models
from django.dispatch import receiver
from .mltask import mltask
from django.db.models.signals import(
post_save
)
class Document(models.Model):
title = models.CharField(max_length=200)
file = models.FileField(blank=False, null=False)
@receiver(post_save, sender=Document)
def user_created_handler(sender, instance, *args, **kwargs):
mltask(str(instance.file.file))
This sets up a model Document that will require a title and file for each entry saved in the database. Once saved, the @receiver decorator listens for a post save signal, meaning that the specified model, Document, was saved in the database. Once saved, user_created_handler() takes the saved instance’s file field and passes it to, what will become, our Machine Learning function.
Anytime changes are made to models.py, you will need to run the following two commands:
python manage.py makemigrations
python manage.py migrate
Moving forward, create a serializers.py file in docreader, allowing for the serialization and deserialization of the Document’s title and file fields. Write in it:
from rest_framework import serializers
from .models import Document
class DocumentSerializer(serializers.ModelSerializer):
class Meta:
model = Document
fields = [
'title',
'file'
]
Next in views.py, where we can define our CRUD operations, let’s define the ability to create, as well as list, Document entries using generic views (which essentially allows you to quickly write views using an abstraction of common view patterns):
from django.shortcuts import render
from rest_framework import generics
from .models import Document
from .serializers import DocumentSerializer
class DocumentListCreateAPIView(
generics.ListCreateAPIView):
queryset = Document.objects.all()
serializer_class = DocumentSerializer
Finally, update urls.py in mltutorial:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path('api/', include('docreader.urls')),
]
And create urls.py in docreader app dir and write:
from django.urls import path
from . import views
urlpatterns = [
path('create/', views.DocumentListCreateAPIView.as_view(), name='document-list'),
]
Now we are all setup to save a Document entry, with title and field fields, at the /api/create/ endpoint, which will call mltask() post save! So, let’s test this out.
To help visualize testing, let’s register our Document model with the Django admin interface, so we can see when a new entry has been created.
In docreader/admin.py write:
from django.contrib import admin
from .models import Document
admin.site.register(Document)
Create a user that can login to the Django admin interface using:
python manage.py createsuperuser
Now, let’s test the endpoint we exposed.
To do this without a frontend, run the Django server and go to Postman. Send the following POST request with a PDF file attached:
If we check our Django logs, we should see the file path printed out, as specified in the post save mltask() function call.
AWS Setup
You will notice that the PDF was saved to the project’s root dir. Let’s ensure any media is instead saved to AWS S3, getting our app ready for deployment.
Go to the S3 console (and create an account and get our your account’s Access and Secret keys if you haven’t already). Create a new bucket, here we will be titling it ‘djangomltest’. Update the permissions to ensure the bucket is public for testing (and revert back, as needed, for production).
Now, let’s configure Django to work with AWS.
Add your model_final.pth, trained in Part 1, into the docreader dir. Create a .env file in the root dir and write the following:
AWS_ACCESS_KEY_ID = <Add your Access Key Here>
AWS_SECRET_ACCESS_KEY = <Add your Secret Key Here>
AWS_STORAGE_BUCKET_NAME = 'djangomltest'
MODEL_PATH = './docreader/model_final.pth'
Update settings.py to include AWS configurations:
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
# AWS
AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID']
AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY']
AWS_STORAGE_BUCKET_NAME = os.environ['AWS_STORAGE_BUCKET_NAME']
#AWS Config
AWS_DEFAULT_ACL = 'public-read'
AWS_S3_CUSTOM_DOMAIN = f'{AWS_STORAGE_BUCKET_NAME}.s3.amazonaws.com'
AWS_S3_OBJECT_PARAMETERS = {'CacheControl': 'max-age=86400'}
#Boto3
STATICFILES_STORAGE = 'mltutorial.storage_backends.StaticStorage'
DEFAULT_FILE_STORAGE = 'mltutorial.storage_backends.PublicMediaStorage'
#AWS URLs
STATIC_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/static/'
MEDIA_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/media/'
Optionally, with AWS serving our static and media files, you will want to run the following command in order to serve static assets to the admin interface using S3:
python manage.py collectstatic
If we run the server again, our admin should appear the same as how it would with our static files served locally.
Once again, let’s run the Django server and test the endpoint to make sure the file is now saved to S3.
ML Task Setup and Deployment
With Django and AWS properly configured, let’s set up our ML process in mltask.py. As the file is long, see the repo here for reference (with comments added in to help with understanding the various code blocks).
What’s important to see is that Detectron2 is imported and the model is loaded only when the function is called. Here, we will call the function only through a Celery task, ensuring the memory used during inferencing will be isolated to the Heroku worker process.
So finally, let’s setup Celery and then deploy to Heroku.
In mltutorial/_init__.py write:
from .celery import app as celery_app
__all__ = ('celery_app',)
Create celery.py in the mltutorial dir and write:
import os
from celery import Celery
# Set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'mltutorial.settings')
# We will specify Broker_URL on Heroku
app = Celery('mltutorial', broker=os.environ['CLOUDAMQP_URL'])
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Load task modules from all registered Django apps.
app.autodiscover_tasks()
@app.task(bind=True, ignore_result=True)
def debug_task(self):
print(f'Request: {self.request!r}')
Lastly, make a tasks.py in docreader and write:
from celery import shared_task
from .mltask import mltask
@shared_task
def ml_celery_task(file_path):
mltask(file_path)
return "DONE"
This Celery task, ml_celery_task(), should now be imported into models.py and used with the post save signal instead of the mltask function pulled directly from mltask.py. Update the post_save signal block to the following:
@receiver(post_save, sender=Document)
def user_created_handler(sender, instance, *args, **kwargs):
ml_celery_task.delay(str(instance.file.file))
And to test Celery, let’s deploy!
In the root project dir, include a Dockerfile and heroku.yml file, both specified in the repo. Most importantly, editing the heroku.yml commands will allow you to configure the gunicorn web process and the Celery worker process, which can aid in further mitigating potential problems.
Make a Heroku account and create a new app called “mlapp” and gitignore the .env file. Then initialize git in the projects root dir and change the Heroku app’s stack to container (in order to deploy using Docker):
$ heroku login
$ git init
$ heroku git:remote -a mlapp
$ git add .
$ git commit -m "initial heroku commit"
$ heroku stack:set container
$ git push heroku master
Once pushed, we just need to add our env variables into the Heroku app.
Go to settings in the online interface, scroll down to Config Vars, click Reveal Config Vars, and add each line listed in the .env file.
You may have noticed there was a CLOUDAMQP_URL variable specified in celery.py. We need to provision a Celery Broker on Heroku, for which there are a variety of options. I will be using CloudAMQP which has a free tier. Go ahead and add this to your app. Once added, the CLOUDAMQP_URL environment variable will be included automatically in the Config Vars.
Finally, let’s test the final product.
To monitor requests, run:
$ heroku logs --tail
Issue another Postman POST request to the Heroku app’s url at the /api/create/ endpoint. You will see the POST request come through, Celery receive the task, load the model, and start running pages:
We will continue to see the “Running for page…” until the end of the process and you can check the AWS S3 bucket as it runs.
Congrats! You’ve now deployed and ran a Python backend using Machine Learning as a part of a distributed task queue running in parallel to the main web process!
As mentioned, you will want to adjust the heroku.yml commands to incorporate gunicorn threads and/or worker processes and fine tune celery. For further learning, here’s a great article on configuring gunicorn to meet your app’s needs, one for digging into Celery for production, and another for exploring Celery worker pools, in order to help with properly managing your resources.
Happy coding!
Unless otherwise noted, all images used in this article are by the author
Designing and Deploying a Machine Learning Python Application (Part 2) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.