
Dynamic Coalescing in Apache Spark
Use of Coalesce in Spark applications is set to increase with the default enablement of ‘Dynamic Coalescing’ in Spark 3.0. Now, you don’t need to do manual adjustments of partitions for shuffles any more, nor you would feel restricted from ‘spark.sql.shuffle.partitions’ value. Read this story to know more about it..
Importance of Partitioning: Right set of partitions is like a holy grail for optimum execution of a Spark application. A Spark application achieves optimum efficiency when each of its constituent stages execute optimally. This in turn implies that each of the stage should run on optimum number of partitions which could differ from stage to stage. The difference in optimum number of partitions is there because of the fact that both, the amount of input data and the nature of computation generally differs from stage to stage.
Too many small partitions increases Spark overhead of bookkeeping and scheduling, while large partitions lead to loss of desired parallelism. Similarly, heavy and memory intensive computations prefer small sized partitions while large sized partitions are natural fit for light computations. If you wish to know more into Spark Partitioning aspects, you can refer, ‘Guide to Spark Partitioning’.
Shuffle born Stages: Most stages in a Spark Job comes into existence due to the shuffle exchange operators being inserted by the Spark Execution engine. Further, each of the shuffle exchange operator use config parameter “spark.sql.shuffle.partitions” to decide on the number of shuffle partitions. Therefore, all shuffle born stages (stages which do shuffle read) run on similar number of partitions. But, the similar number of configured shuffle partitions may not be optimum for all the shuffle born stages, causing the affected stages to run non-optimally. This in turn brings down the overall efficiency of underlying the Spark Job. (You could refer to Revealing Apache Spark Shuffling Magic to know more about Spark shuffling process)
Here is a code snippet to simulate the fact that all shuffle born stages runs with partitions number equal to “spark.sql.shuffle.partitions” when Dynamic Coalescing is not enabled.

Here is the stage execution snapshot when the logic presented in Figure 1 is executed on a Spark Cluster:
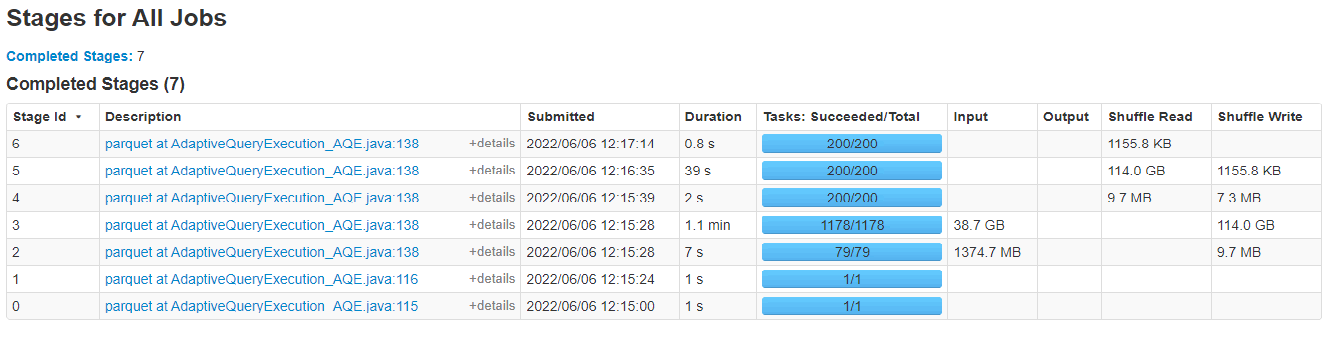
From Figure 2, it can be seen that stages 3,5 and 6 are shuffle born stages and each of them is ran on default value of “spark.sql.shuffle.partitions” which is set to 200.
To overcome the limitation imposed by “spark.sql.shuffle.partitions”, Spark developers usually resort to manual and indirect adjustment of shuffle partitions using either the ‘repartition’ or ‘coalesce’ transformations. The adjustments are done around the transformations requiring data shuffle, such as ‘groupby’ and ‘Join’.
Repartition and Coalesce: ‘Repartition’ transformation allows user to repartition a dataset into higher or lower number of partitions as compared to the original number of partitions in the dataset. This is usually done by specifying a repartitioning key being derived from one or more attributes of a record. If ‘repartition’ is used before groupby transformation, the repartitioning key is same as grouping key while if ‘repartition’ is used before Join transformation, the repartitioning key is same as join key.
Developers usually resort to ‘repartition’ before shuffle causing transformations when they manually want to increase the number of shuffle partitions more than than the ones dictated by “spark.sql.shuffle.partitions”.
‘Coalesce’ transformation allows user to repartition a dataset into only lower number of partitions as compared to the original number of partitions in a dataset. Here, there is no no need to specify any key.
Developers usually resort to ‘Coalesce’ after the shuffle causing transformations when they manually want to decrease the number of shuffle partitions as compared to the ones dictated by “spark.sql.shuffle.partitions”.
Although available, manual adjustments of stage partitions across shuffling via ‘repartition’ or ‘coalesce’ is an iterative and cumbersome process and requires good understanding of Spark’s execution engine. To address this problem, Spark supports ‘Dynamic Coalescing’ as one of the feature of a bigger runtime optimization module, ‘Advanced Query Execution (AQE)’ being introduced for the first time in Spark 1.6.
Apart from ‘Dynamic Coalescing’, other features of AQE include ‘Switching Join Strategies to broadcast Join’ and ‘Optimization of Skew Join’. AQE was disabled by default before Spark 3.0 as it was still maturing, but with Spark 3.0, AQE comes enabled by default to auto optimize the Spark Jobs during runtime.
To use ‘Dynamic Coalescing’, one has to set the following configurations to ‘true’.

Understanding ‘Dynamic Coalescing’ : As already known, a shuffle is made up of two consecutive stages. The first one is a map stage that writes the shuffle blocks (corresponding to configured shuffle partitions number). The Map stage is followed by a reduce stage that reads relevant shuffle blocks , combines them with respect to their shuffle partitions number, and then subsequently runs the reducer logic on each of the combined data block.
It is between map and reduce stages of a shuffle where ‘Dynamic Coalescing’ operates. Actually, what happens is that after the map stage before a shuffle gets completed (after writing all the shuffle data blocks), it reports lot of stats, such as number of records and size of each of the shuffle partition, about the resulting shuffle partitions (as dictated by the config “spark.sql.shuffle.partitions”) to the Spark execution engine.
These reported stats prompts the execution engine to consult ‘Dynamic Coalescing’ module to inspect for a potential optimization opportuning when the shuffle partitions are coalesced to a lower number.
‘Dynamic Coalescing’ consults the stats produced by the map side of a shuffle and some other configurable parameters (to provide flexibility in behavior) in order to compute a optimum target size for a coalesced partition. Based on the computed target size, estimation is done for the number of coalesced shuffle partitions. In case if the estimated number comes below the number dictated by “spark.sql.shuffle.partitions”, ‘Dynamic Coalescing’ module inserts dynamically, at runtime, a subsequent coalesce transformation having input parameter as the estimated number of coalesced shuffle partitions.

Figure 4 provides an illustration of ‘Dynamic Coalescing’. As shown, ‘spark.sql.shuffle.partitions’ is set to be 4. Therefore two map tasks (corresponding to 2 partitions) in the map stage of the shuffle write 4 shuffle blocks corresponding to configured shuffle partitions. However, after Spark Execution engine has used ‘Dynamic Coalescing’ , 2nd and 3rd shuffle partitions are coalesced, and therefore the total number of shuffle partitions becomes 3 instead of 4 in the reducer stage (the shuffle born stage) after the shuffle.
Configuring ‘Dynamic Coalescing’: The various configurable parameters which affects decision process of ‘Dynamic Coalescing’ are listed below:
Before Spark 3.0: Before Spark 3.0, there was only one such parameter:
“spark.sql.adaptive.shuffle.targetPostShuffleInputSize”: Controls target size after coalescing. The coalesced partition sizes will be close to but no bigger than this target size. (Default: 64MB)
Spark 3.0 onwards: With Spark 3.0, multiple parameters were introduced to fine tune the behavior of ‘Dynamic Coalescing’ to maintain balance between desired parallelism and max size of coalesced shuffle partition. All these parameters are explained below:
“spark.sql.adaptive.advisoryPartitionSizeInBytes” : Controls target size after coalescing. The coalesced partition sizes will be close to but no bigger than this target size. (Default: 64MB)
“spark.sql.adaptive.coalescePartitions.minPartitionNum”: Controls the minimum number of partitions after coalescing. If it is not set, it is assumed by default to be equal to ‘spark.default.parallelism’.
“spark.sql.adaptive.coalescePartitions.minPartitionSize”: This is a newly introduced parameter in Spark 3.2. It controls the minimum size of partitions after coalescing. The coalesced partition sizes will be no smaller than this size. (Default: 1MB)
Therefore, it can be seen that before Spark 3.2, only a fixed upper limit is specified for the coalesced partition size using “spark.sql.adaptive.shuffle.targetPostShuffleInputSize”. However, with Spark 3.2 , both a upper and a lower fixed limit can be specified for a coalesced partition size based on the values of “spark.sql.adaptive.shuffle.targetPostShuffleInputSize” and “spark.sql.adaptive.coalescePartitions.minPartitionSize” respectively.
Here is the snapshot of stages produced by Spark when logic given in Figure 1 is executed again but with ‘Dynamic Coalescing’ being turned on:

As can be seen from Figure 5, with ‘Dynamic Coalescing’ enabled, the number of shuffle partitions got reduced to 1 in stages 5 and 14 which corresponds to stages 4 and 6 respectively in Figure 1, while the number of partitions remained at 200 for stage 9 which corresponds to stage 5 in Figure 1 . (Notice that after enabling the AQE, the stage numbering gets changed a bit due to introduction of multiple skipped stages)
I hope the above story has given you a good perspective of Coalesce operation in general and the reasoning behind the “Dynamic Coalescing” feature. With this background, I would encourage you all to explore optimization opportunity in your existing Spark Jobs by either using the manual coalesce operation or enabling the Dynamic Coalescing feature.
Regarding the guidelines to use “Dynamic Coalescing”, I will try to cover in next part of this story, till then you can connect me over LinkedIn in case of any queries, feedback or suggestions @ https://www.linkedin.com/in/ajaywlan/.

Use of Coalesce in Spark applications is set to increase with the default enablement of ‘Dynamic Coalescing’ in Spark 3.0. Now, you don’t need to do manual adjustments of partitions for shuffles any more, nor you would feel restricted from ‘spark.sql.shuffle.partitions’ value. Read this story to know more about it..
Importance of Partitioning: Right set of partitions is like a holy grail for optimum execution of a Spark application. A Spark application achieves optimum efficiency when each of its constituent stages execute optimally. This in turn implies that each of the stage should run on optimum number of partitions which could differ from stage to stage. The difference in optimum number of partitions is there because of the fact that both, the amount of input data and the nature of computation generally differs from stage to stage.
Too many small partitions increases Spark overhead of bookkeeping and scheduling, while large partitions lead to loss of desired parallelism. Similarly, heavy and memory intensive computations prefer small sized partitions while large sized partitions are natural fit for light computations. If you wish to know more into Spark Partitioning aspects, you can refer, ‘Guide to Spark Partitioning’.
Shuffle born Stages: Most stages in a Spark Job comes into existence due to the shuffle exchange operators being inserted by the Spark Execution engine. Further, each of the shuffle exchange operator use config parameter “spark.sql.shuffle.partitions” to decide on the number of shuffle partitions. Therefore, all shuffle born stages (stages which do shuffle read) run on similar number of partitions. But, the similar number of configured shuffle partitions may not be optimum for all the shuffle born stages, causing the affected stages to run non-optimally. This in turn brings down the overall efficiency of underlying the Spark Job. (You could refer to Revealing Apache Spark Shuffling Magic to know more about Spark shuffling process)
Here is a code snippet to simulate the fact that all shuffle born stages runs with partitions number equal to “spark.sql.shuffle.partitions” when Dynamic Coalescing is not enabled.
Here is the stage execution snapshot when the logic presented in Figure 1 is executed on a Spark Cluster:
From Figure 2, it can be seen that stages 3,5 and 6 are shuffle born stages and each of them is ran on default value of “spark.sql.shuffle.partitions” which is set to 200.
To overcome the limitation imposed by “spark.sql.shuffle.partitions”, Spark developers usually resort to manual and indirect adjustment of shuffle partitions using either the ‘repartition’ or ‘coalesce’ transformations. The adjustments are done around the transformations requiring data shuffle, such as ‘groupby’ and ‘Join’.
Repartition and Coalesce: ‘Repartition’ transformation allows user to repartition a dataset into higher or lower number of partitions as compared to the original number of partitions in the dataset. This is usually done by specifying a repartitioning key being derived from one or more attributes of a record. If ‘repartition’ is used before groupby transformation, the repartitioning key is same as grouping key while if ‘repartition’ is used before Join transformation, the repartitioning key is same as join key.
Developers usually resort to ‘repartition’ before shuffle causing transformations when they manually want to increase the number of shuffle partitions more than than the ones dictated by “spark.sql.shuffle.partitions”.
‘Coalesce’ transformation allows user to repartition a dataset into only lower number of partitions as compared to the original number of partitions in a dataset. Here, there is no no need to specify any key.
Developers usually resort to ‘Coalesce’ after the shuffle causing transformations when they manually want to decrease the number of shuffle partitions as compared to the ones dictated by “spark.sql.shuffle.partitions”.
Although available, manual adjustments of stage partitions across shuffling via ‘repartition’ or ‘coalesce’ is an iterative and cumbersome process and requires good understanding of Spark’s execution engine. To address this problem, Spark supports ‘Dynamic Coalescing’ as one of the feature of a bigger runtime optimization module, ‘Advanced Query Execution (AQE)’ being introduced for the first time in Spark 1.6.
Apart from ‘Dynamic Coalescing’, other features of AQE include ‘Switching Join Strategies to broadcast Join’ and ‘Optimization of Skew Join’. AQE was disabled by default before Spark 3.0 as it was still maturing, but with Spark 3.0, AQE comes enabled by default to auto optimize the Spark Jobs during runtime.
To use ‘Dynamic Coalescing’, one has to set the following configurations to ‘true’.
Understanding ‘Dynamic Coalescing’ : As already known, a shuffle is made up of two consecutive stages. The first one is a map stage that writes the shuffle blocks (corresponding to configured shuffle partitions number). The Map stage is followed by a reduce stage that reads relevant shuffle blocks , combines them with respect to their shuffle partitions number, and then subsequently runs the reducer logic on each of the combined data block.
It is between map and reduce stages of a shuffle where ‘Dynamic Coalescing’ operates. Actually, what happens is that after the map stage before a shuffle gets completed (after writing all the shuffle data blocks), it reports lot of stats, such as number of records and size of each of the shuffle partition, about the resulting shuffle partitions (as dictated by the config “spark.sql.shuffle.partitions”) to the Spark execution engine.
These reported stats prompts the execution engine to consult ‘Dynamic Coalescing’ module to inspect for a potential optimization opportuning when the shuffle partitions are coalesced to a lower number.
‘Dynamic Coalescing’ consults the stats produced by the map side of a shuffle and some other configurable parameters (to provide flexibility in behavior) in order to compute a optimum target size for a coalesced partition. Based on the computed target size, estimation is done for the number of coalesced shuffle partitions. In case if the estimated number comes below the number dictated by “spark.sql.shuffle.partitions”, ‘Dynamic Coalescing’ module inserts dynamically, at runtime, a subsequent coalesce transformation having input parameter as the estimated number of coalesced shuffle partitions.
Figure 4 provides an illustration of ‘Dynamic Coalescing’. As shown, ‘spark.sql.shuffle.partitions’ is set to be 4. Therefore two map tasks (corresponding to 2 partitions) in the map stage of the shuffle write 4 shuffle blocks corresponding to configured shuffle partitions. However, after Spark Execution engine has used ‘Dynamic Coalescing’ , 2nd and 3rd shuffle partitions are coalesced, and therefore the total number of shuffle partitions becomes 3 instead of 4 in the reducer stage (the shuffle born stage) after the shuffle.
Configuring ‘Dynamic Coalescing’: The various configurable parameters which affects decision process of ‘Dynamic Coalescing’ are listed below:
Before Spark 3.0: Before Spark 3.0, there was only one such parameter:
“spark.sql.adaptive.shuffle.targetPostShuffleInputSize”: Controls target size after coalescing. The coalesced partition sizes will be close to but no bigger than this target size. (Default: 64MB)
Spark 3.0 onwards: With Spark 3.0, multiple parameters were introduced to fine tune the behavior of ‘Dynamic Coalescing’ to maintain balance between desired parallelism and max size of coalesced shuffle partition. All these parameters are explained below:
“spark.sql.adaptive.advisoryPartitionSizeInBytes” : Controls target size after coalescing. The coalesced partition sizes will be close to but no bigger than this target size. (Default: 64MB)
“spark.sql.adaptive.coalescePartitions.minPartitionNum”: Controls the minimum number of partitions after coalescing. If it is not set, it is assumed by default to be equal to ‘spark.default.parallelism’.
“spark.sql.adaptive.coalescePartitions.minPartitionSize”: This is a newly introduced parameter in Spark 3.2. It controls the minimum size of partitions after coalescing. The coalesced partition sizes will be no smaller than this size. (Default: 1MB)
Therefore, it can be seen that before Spark 3.2, only a fixed upper limit is specified for the coalesced partition size using “spark.sql.adaptive.shuffle.targetPostShuffleInputSize”. However, with Spark 3.2 , both a upper and a lower fixed limit can be specified for a coalesced partition size based on the values of “spark.sql.adaptive.shuffle.targetPostShuffleInputSize” and “spark.sql.adaptive.coalescePartitions.minPartitionSize” respectively.
Here is the snapshot of stages produced by Spark when logic given in Figure 1 is executed again but with ‘Dynamic Coalescing’ being turned on:
As can be seen from Figure 5, with ‘Dynamic Coalescing’ enabled, the number of shuffle partitions got reduced to 1 in stages 5 and 14 which corresponds to stages 4 and 6 respectively in Figure 1, while the number of partitions remained at 200 for stage 9 which corresponds to stage 5 in Figure 1 . (Notice that after enabling the AQE, the stage numbering gets changed a bit due to introduction of multiple skipped stages)
I hope the above story has given you a good perspective of Coalesce operation in general and the reasoning behind the “Dynamic Coalescing” feature. With this background, I would encourage you all to explore optimization opportunity in your existing Spark Jobs by either using the manual coalesce operation or enabling the Dynamic Coalescing feature.
Regarding the guidelines to use “Dynamic Coalescing”, I will try to cover in next part of this story, till then you can connect me over LinkedIn in case of any queries, feedback or suggestions @ https://www.linkedin.com/in/ajaywlan/.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.