
Editing Text in Images with AI
Research Review for Scene Text Editing: STEFANN, SRNet, TextDiffuser, AnyText and more.
If you ever tried to change the text in an image, you know it’s not trivial. Preserving the background, textures, and shadows takes a Photoshop license and hard-earned designer skills. In the video below, a Photoshop expert takes 13 minutes to fix a few misspelled characters in a poster that is not even stylistically complex. The good news is — in our relentless pursuit of AGI, humanity is also building AI models that are actually useful in real life. Like the ones that allow us to edit text in images with minimal effort.
https://medium.com/media/a69b190d401f00fd690b47fcf624f447/href
The task of automatically updating the text in an image is formally known as Scene Text Editing (STE). This article describes how STE model architectures have evolved over time and the capabilities they have unlocked. We will also talk about their limitations and the work that remains to be done. Prior familiarity with GANs and Diffusion models will be helpful, but not strictly necessary.
Disclaimer: I am the cofounder of Storia AI, building an AI copilot for visual editing. This literature review was done as part of developing Textify, a feature that allows users to seamlessly change text in images. While Textify is closed-source, we open-sourced a related library, Detextify, which automatically removes text from a corpus of images.
The Task of Scene Text Editing (STE)
Definition
Scene Text Editing (STE) is the task of automatically modifying text in images that capture a visual scene (as opposed to images that mainly contain text, such as scanned documents). The goal is to change the text while preserving the original aesthetics (typography, calligraphy, background etc.) without the inevitably expensive human labor.
Use Cases
Scene Text Editing might seem like a contrived task, but it actually has multiple practical uses cases:
(1) Synthetic data generation for Scene Text Recognition (STR)

When I started researching this task, I was surprised to discover that Alibaba (an e-commerce platform) and Baidu (a search engine) are consistently publishing research on STE.
At least in Alibaba’s case, it is likely their research is in support of AMAP, their alternative to Google Maps [source]. In order to map the world, you need a robust text recognition system that can read traffic and street signs in a variety of fonts, under various real-world conditions like occlusions or geometric distortions, potentially in multiple languages.
In order to build a training set for Scene Text Recognition, one could collect real-world data and have it annotated by humans. But this approach is bottlenecked by human labor, and might not guarantee enough data variety. Instead, synthetic data generation provides a virtually unlimited source of diverse data, with automatic labels.
(2) Control over AI-generated images

AI image generators like Midjourney, Stability and Leonardo have democratized visual asset creation. Small business owners and social media marketers can now create images without the help of an artist or a designer by simply typing a text prompt. However, the text-to-image paradigm lacks the controllability needed for practical assets that go beyond concept art — event posters, advertisements, or social media posts.
Such assets often need to include textual information (a date and time, contact details, or the name of the company). Spelling correctly has been historically difficult for text-to-image models, though there has been recent process — DeepFloyd IF, Midjourney v6. But even when these models do eventually learn to spell perfectly, the UX constraints of the text-to-image interface remain. It is tedious to describe in words where and how to place a piece of text.
(3) Automatic localization of visual media
Movies and games are often localized for various geographies. Sometimes this might entail switching a broccoli for a green pepper, but most times it requires translating the text that is visible on screen. With other aspects of the film and gaming industries getting automated (like dubbing and lip sync), there is no reason for visual text editing to remain manual.
Timeline of Architectures: from GANs to Diffusion
The training techniques and model architectures used for Scene Text Editing largely follow the trends of the larger task of image generation.
The GAN Era (2019–2021)
GANs (Generative Adversarial Networks) dominated the mid-2010s for image generation tasks. GAN refers to a particular training framework (rather than prescribing a model architecture) that is adversarial in nature. A generator model is trained to capture the data distribution (and thus has the capability to generate new data), while a discriminator is trained to distinguish the output of the generator from real data. The training process is finalized when the discriminator’s guess is as good as a random coin toss. During inference, the discriminator is discarded.
GANs are particularly suited for image generation because they can perform unsupervised learning — that is, learn the data distribution without requiring labeled data. Following the general trend of image generation, the initial Scene Text Editing models also leveraged GANs.
GAN Epoch #1: Character-Level Editing — STEFANN
STEFANN, recognized as the first work to modify text in scene images, operates at a character level. The character editing problem is broken into two: font adaptation and color adaptation.
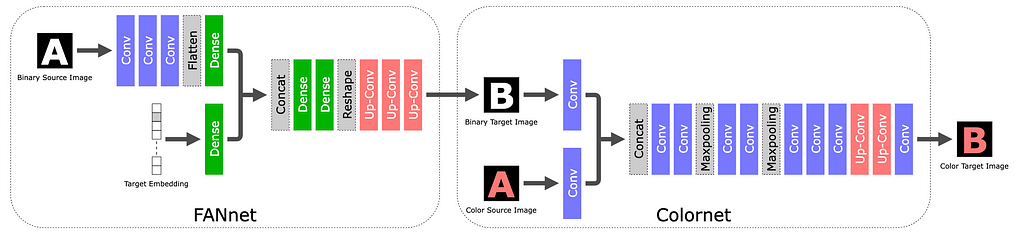
STEFANN is recognized as the first work to modify text in scene images. It builds on prior work in the space of font synthesis (the task of creating new fonts or text styles that closely resemble the ones observed in input data), and adds the constraint that the output needs to blend seamlessly back into the original image. Compared to previous work, STEFANN takes a pure machine learning approach (as opposed to e.g. explicit geometrical modeling) and does not depend on character recognition to label the source character.
The STEFANN model architecture is based on CNNs (Convolutional Neural Networks) and decomposes the problem into (1) font adaptation via FANnet — turning a binarized version of the source character into a binarized target character, (2) color adaptation via Colornet — colorizing the output of FANnet to match the rest of the text in the image, and (3) character placement — blending the target character back into the original image using previously-established techniques like inpainting and seam carving. The first two modules are trained with a GAN objective.
https://medium.com/media/238a90e6825284af1a55c44ed644c4df/href
While STEFANN paved the way for Scene Text Editing, it has multiple limitations that restrict its use in practice. It can only operate on one character at a time; changing an entire word requires multiple calls (one per letter) and constrains the target word to have the same length as the source word. Also, the character placement algorithm in step (3) assumes that the characters are non-overlapping.
GAN Epoch #2: Word-Level Editing — SRNet and 3-Module Networks
SRNet was the first model to perform scene text editing at the word level. SRNet decomposed the STE task into three (jointly-trained) modules: text conversion, background inpainting and fusion.
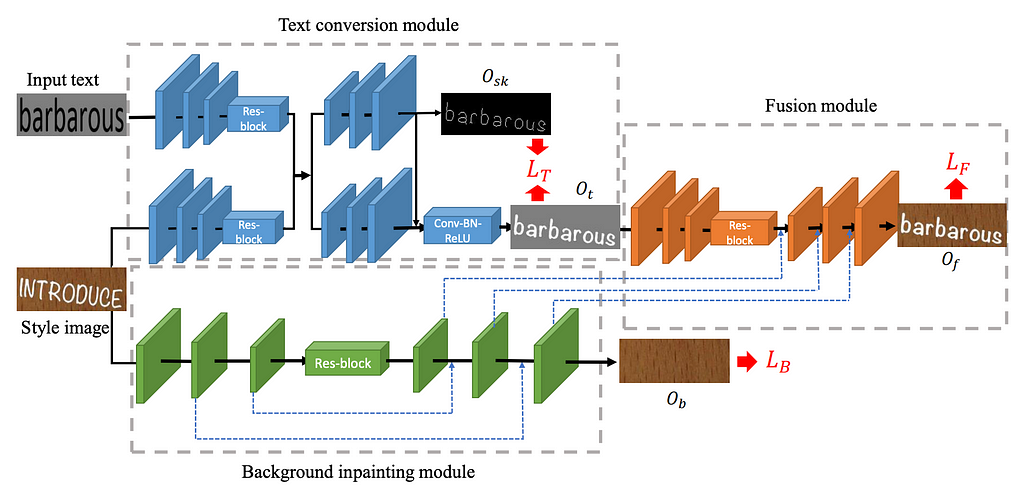
SRNet was the first model to perform scene text editing at the word level. SRNet decomposed the STE task into three (jointly-trained) modules:
- The text conversion module (in blue) takes a programatic rendering of the target text (“barbarous” in the figure above) and aims to render it in the same typeface as the input word (“introduce”) on a plain background.
- The background inpainting module (in green) erases the text from the input image and fills in the gaps to reconstruct the original background.
- The fusion module (in orange) pastes the rendered target text onto the background.
SRNet architecture. All three modules are flavors of Fully Convolutional Networks (FCNs), with the background inpainting module in particular resembling U-Net (an FCN with the specific property that encoder layers are skip-connected to decoder layers of the same size).
SRNet training. Each module has its own loss, and the network is jointly trained on the sum of losses (LT + LB + LF), where the latter two are trained via GAN. While this modularization is conceptually elegant, it comes with the drawback of requiring paired training data, with supervision for each intermediate step. Realistically, this can only be achieved with artificial data. For each data point, one chooses a random image (from a dataset like COCO), selects two arbitrary words from a dictionary, and renders them with an arbitrary typeface to simulate the “before” and “after” images. As a consequence, the training set doesn’t include any photorealistic examples (though it can somewhat generalize beyond rendered fonts).
Honorable mentions. SwapText followed the same GAN-based 3-module network approach to Scene Text Editing and proposed improvements to the text conversion module.
GAN Epoch #3: Self-supervised and Hybrid Networks
Leap to unsupervised learning. The next leap in STE research was to adopt a self-supervised training approach, where models are trained on unpaired data (i.e., a mere repository of images containing text). To achieve this, one had to remove the label-dependent intermediate losses LT and LB. And due to the design of GANs, the remaining final loss does not require a label either; the model is simply trained on the discriminator’s ability to distinguish between real images and the ones produced by the generator. TextStyleBrush pioneered self-supervised training for STE, while RewriteNet and MOSTEL made the best of both worlds by training in two stages: one supervised (advantage: abundance of synthetic labeled data) and one self-supervised (advantage: realism of natural unlabeled data).
Disentangling text content & style. To remove the intermediate losses, TextStyleBrush and RewriteNet reframe the problem into disentangling text content from text style. To reiterate, the inputs to an STE system are (a) an image with original text, and (b) the desired text — more specifically, a programatic rendering of the desired text on a white or gray background, with a fixed font like Arial. The goal is to combine the style from (a) with the content from (b). In other words, we complementarily aim to discard the content from (a) and the style of (b). This is why it’s necessary to disentangle the text content from the style in a given image.
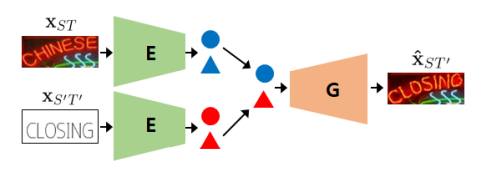
TextStyleBrush and why GANs went out of fashion. While the idea of disentangling text content from style is straightforward, achieving it in practice required complicated architectures. TextStyleBrush, the most prominent paper in this category, used no less than seven jointly-trained subnetworks, a pre-trained typeface classifier, a pre-trained OCR model and multiple losses. Designing such a system must have been expensive, since all of these components require ablation studies to determine their effect. This, coupled with the fact that GANs are notoriously difficult to train (in theory, the generator and discriminator need to reach Nash equilibrium), made STE researchers eager to switch to diffusion models once they proved so apt for image generation.
The Diffusion Era (2022 — present)
At the beginning of 2022, the image generation world shifted away from GANs towards Latent Diffusion Models (LDM). A comprehensive explanation of LDMs is out of scope here, but you can refer to The Illustrated Stable Diffusion for an excellent tutorial. Here I will focus on the parts of the LDM architecture that are most relevant to the Scene Text Editing task.
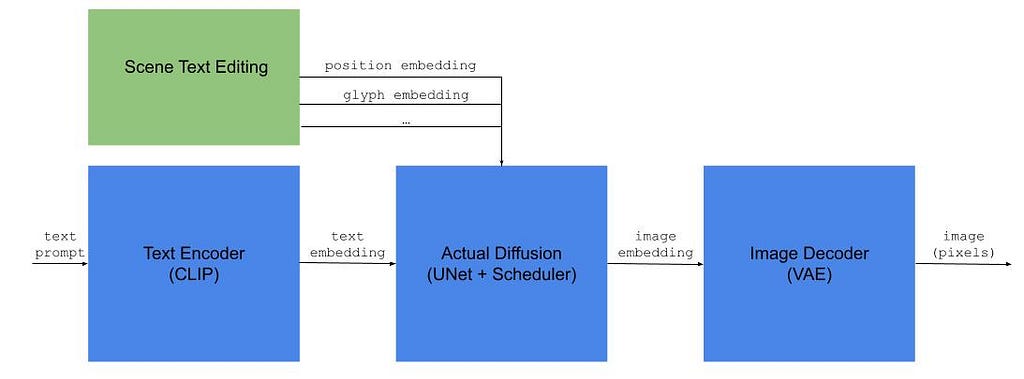
As illustrated above, an LDM-based text-to-image model has three main components: (1) a text encoder — typically CLIP, (2) the actual diffusion module — which converts the text embedding into an image embedding in latent space, and (3) an image decoder — which upscales the latent image into a fully-sized image.
Scene Text Editing as a Diffusion Inpainting Task
Text-to-image is not the only paradigm supported by diffusion models. After all, CLIP is equally a text and image encoder, so the embedding passed to the image information creator module can also encode an image. In fact, it can encode any modality, or a concatenation of multiple inputs.
This is the principle behind inpainting, the task of modifying only a subregion of an input image based on given instructions, in a way that looks coherent with the rest of the image. The image information creator ingests an encoding that captures the input image, the mask of the region to be inpainted, and a textual instruction.
Scene Text Editing can be regarded as a specialized form of inpainting. Most of the STE research reduces to the following question: How can we augment the text embedding with additional information about the task (i.e., the original image, the desired text and its positioning, etc.)? Formally, this is known as conditional guidance.
The research papers that fall into this bucket (TextDiffuser, TextDiffuser 2, GlyphDraw, AnyText, etc.) propose various forms of conditional guidance.
Positional guidance
Evidently, there needs to be a way of specifying where to make changes to the original image. This can be a text instruction (e.g. “Change the title at the bottom”), a granular indication of the text line, or more fine-grained positional information for each target character.
Positional guidance via image masks. One way of indicating the desired text position is via grayscale mask images, which can then be encoded into latent space via CLIP or an alternative image encoder. For instance, the DiffUTE model simply uses a black image with a white strip indicating the desired text location.

TextDiffuser produces character-level segmentation masks: first, it roughly renders the desired text in the right position (black text in Arial font on a white image), then passes this rendering through a segmenter to obtain a grayscale image with individual bounding boxes for each character. The segmenter is a U-Net model trained separately from the main network on 4M of synthetic instances.
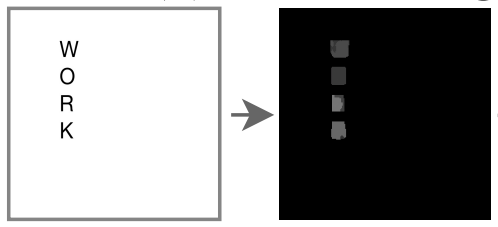
Positional guidance via language modeling. In A Unified Sequence Inference for Vision Tasks, the authors show that large language models (LLMs) can act as effective descriptors of object positions within an image by simply generating numerical tokens. Arguably, this was an unintuitive discovery. Since LLMs learn language based on statistical frequency (i.e., by observing how often tokens occur in the same context), it feels unrealistic to expect them to generate the right numerical tokens. But the massive scale of current LLMs often defies our expectations nowadays.
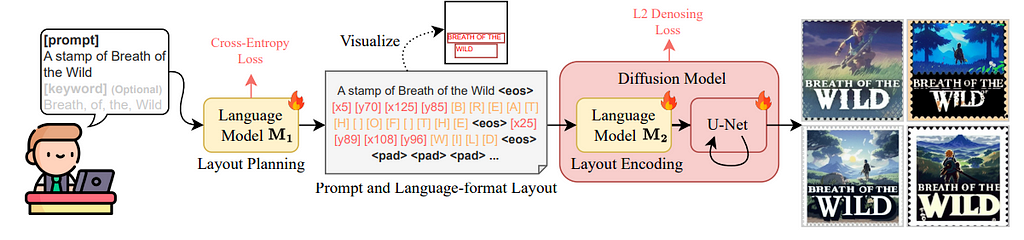
TextDiffuser 2 leverage this discovery in an interesting way. They fine-tune an LLM on a synthetic corpus of <text, OCR detection> pairs, teaching it to generate the top-left and bottom-right coordinates of text bounding boxes, as show in the figure below. Notably, they decide to generate bounding boxes for text lines (as opposed to characters), giving the image generator more flexibility. They also run an interesting ablation study that uses a single point to encode text position (either top-left or center of the box), but observe poorer spelling performance — the model often hallucinates additional characters when not explicitly told where the text should end.
Glyph guidance
In addition to position, another piece of information that can be fed into the image generator is the shape of the characters. One could argue that shape information is redundant. After all, when we prompt a text-to-image model to generate a flamingo, we generally don’t need to pass any additional information about its long legs or the color of its feathers — the model has presumably learnt these details from the training data. However, in practice, the trainings sets (such as Stable Diffusion’s LAION-5B) are dominated by natural pictures, in which text is underrepresented (and non-Latin scripts even more so).
Multiple studies (DiffUTE, GlyphControl, GlyphDraw, GlyphDiffusion, AnyText etc.) attempt to make up for this imbalance via explicit glyph guidance — effectively rendering the glyphs programmatically with a standard font, and then passing an encoding of the rendering to the image generator. Some simply place the glyphs in the center of the additional image, some close to the target positions (reminiscent of ControlNet).
STE via Diffusion is (Still) Complicated
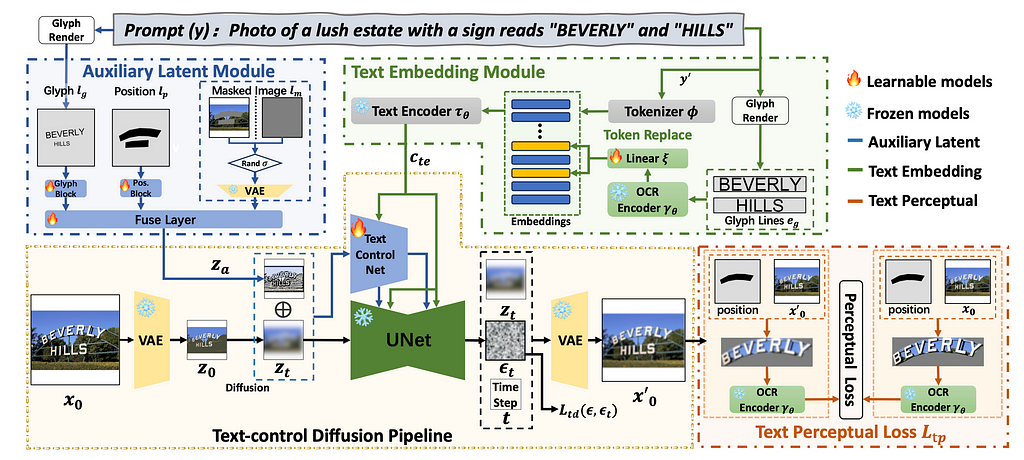
While the training process for diffusion models is more stable than GANs, the diffusion architectures for STE in particular are still quite complicated. The figure below shows the AnyText architecture, which includes (1) an auxiliary latent module (including the positional and glyph guidance discussed above), (2) a text embedding module that, among other components, requires a pre-trained OCR module, and (3) the standard diffusion pipeline for image generation. It is hard to argue this is conceptually much simpler than the GAN-based TextStyleBrush.
The Future of Scene Text Editing
When the status quo is too complicated, we have a natural tendency to keep working on it until it converges to a clean solution. In a way, this is what happened to the natural language processing field: computational linguistics theories, grammars, dependency parsing — all collapsed under Transformers, which make a very simple statement: the meaning of a token depends on all others around it. Evidently, Scene Text Editing is miles away from this clarity. Architectures contain many jointly-trained subnetworks, pre-trained components, and require specific training data.
Text-to-image models will inevitably become better at certain aspects of text generation (spelling, typeface diversity, and how crisp the characters look), with the right amount and quality of training data. But controllability will remain a problem for a much longer time. And even when models do eventually learn to follow your instructions to the t, the text-to-image paradigm might still be a subpar user experience — would you rather describe the position, look and feel of a piece of text in excruciating detail, or would you rather just draw an approximate box and choose an inspiration color from a color picker?
Epilogue: Preventing Abuse
Generative AI has brought to light many ethical questions, from authorship / copyright / licensing to authenticity and misinformation. While all these loom large in our common psyche and manifest in various abstract ways, the misuses of Scene Text Editing are down-to-earth and obvious — people faking documents.
While building Textify, we’ve seen it all. Some people bump up their follower count in Instagram screenshots. Others increase their running speed in Strava screenshots. And yes, some attempt to fake IDs, credit cards and diplomas. The temporary solution is to build classifiers for certain types of documents and simply refuse to edit them, but, long-term the generative AI community needs to invest in automated ways of determining document authenticity, be it a text snippet, an image or a video.
Editing Text in Images with AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Research Review for Scene Text Editing: STEFANN, SRNet, TextDiffuser, AnyText and more.
If you ever tried to change the text in an image, you know it’s not trivial. Preserving the background, textures, and shadows takes a Photoshop license and hard-earned designer skills. In the video below, a Photoshop expert takes 13 minutes to fix a few misspelled characters in a poster that is not even stylistically complex. The good news is — in our relentless pursuit of AGI, humanity is also building AI models that are actually useful in real life. Like the ones that allow us to edit text in images with minimal effort.
https://medium.com/media/a69b190d401f00fd690b47fcf624f447/href
The task of automatically updating the text in an image is formally known as Scene Text Editing (STE). This article describes how STE model architectures have evolved over time and the capabilities they have unlocked. We will also talk about their limitations and the work that remains to be done. Prior familiarity with GANs and Diffusion models will be helpful, but not strictly necessary.
Disclaimer: I am the cofounder of Storia AI, building an AI copilot for visual editing. This literature review was done as part of developing Textify, a feature that allows users to seamlessly change text in images. While Textify is closed-source, we open-sourced a related library, Detextify, which automatically removes text from a corpus of images.

The Task of Scene Text Editing (STE)
Definition
Scene Text Editing (STE) is the task of automatically modifying text in images that capture a visual scene (as opposed to images that mainly contain text, such as scanned documents). The goal is to change the text while preserving the original aesthetics (typography, calligraphy, background etc.) without the inevitably expensive human labor.
Use Cases
Scene Text Editing might seem like a contrived task, but it actually has multiple practical uses cases:
(1) Synthetic data generation for Scene Text Recognition (STR)
When I started researching this task, I was surprised to discover that Alibaba (an e-commerce platform) and Baidu (a search engine) are consistently publishing research on STE.
At least in Alibaba’s case, it is likely their research is in support of AMAP, their alternative to Google Maps [source]. In order to map the world, you need a robust text recognition system that can read traffic and street signs in a variety of fonts, under various real-world conditions like occlusions or geometric distortions, potentially in multiple languages.
In order to build a training set for Scene Text Recognition, one could collect real-world data and have it annotated by humans. But this approach is bottlenecked by human labor, and might not guarantee enough data variety. Instead, synthetic data generation provides a virtually unlimited source of diverse data, with automatic labels.
(2) Control over AI-generated images
AI image generators like Midjourney, Stability and Leonardo have democratized visual asset creation. Small business owners and social media marketers can now create images without the help of an artist or a designer by simply typing a text prompt. However, the text-to-image paradigm lacks the controllability needed for practical assets that go beyond concept art — event posters, advertisements, or social media posts.
Such assets often need to include textual information (a date and time, contact details, or the name of the company). Spelling correctly has been historically difficult for text-to-image models, though there has been recent process — DeepFloyd IF, Midjourney v6. But even when these models do eventually learn to spell perfectly, the UX constraints of the text-to-image interface remain. It is tedious to describe in words where and how to place a piece of text.
(3) Automatic localization of visual media
Movies and games are often localized for various geographies. Sometimes this might entail switching a broccoli for a green pepper, but most times it requires translating the text that is visible on screen. With other aspects of the film and gaming industries getting automated (like dubbing and lip sync), there is no reason for visual text editing to remain manual.
Timeline of Architectures: from GANs to Diffusion
The training techniques and model architectures used for Scene Text Editing largely follow the trends of the larger task of image generation.
The GAN Era (2019–2021)
GANs (Generative Adversarial Networks) dominated the mid-2010s for image generation tasks. GAN refers to a particular training framework (rather than prescribing a model architecture) that is adversarial in nature. A generator model is trained to capture the data distribution (and thus has the capability to generate new data), while a discriminator is trained to distinguish the output of the generator from real data. The training process is finalized when the discriminator’s guess is as good as a random coin toss. During inference, the discriminator is discarded.
GANs are particularly suited for image generation because they can perform unsupervised learning — that is, learn the data distribution without requiring labeled data. Following the general trend of image generation, the initial Scene Text Editing models also leveraged GANs.
GAN Epoch #1: Character-Level Editing — STEFANN
STEFANN, recognized as the first work to modify text in scene images, operates at a character level. The character editing problem is broken into two: font adaptation and color adaptation.
STEFANN is recognized as the first work to modify text in scene images. It builds on prior work in the space of font synthesis (the task of creating new fonts or text styles that closely resemble the ones observed in input data), and adds the constraint that the output needs to blend seamlessly back into the original image. Compared to previous work, STEFANN takes a pure machine learning approach (as opposed to e.g. explicit geometrical modeling) and does not depend on character recognition to label the source character.
The STEFANN model architecture is based on CNNs (Convolutional Neural Networks) and decomposes the problem into (1) font adaptation via FANnet — turning a binarized version of the source character into a binarized target character, (2) color adaptation via Colornet — colorizing the output of FANnet to match the rest of the text in the image, and (3) character placement — blending the target character back into the original image using previously-established techniques like inpainting and seam carving. The first two modules are trained with a GAN objective.
https://medium.com/media/238a90e6825284af1a55c44ed644c4df/href
While STEFANN paved the way for Scene Text Editing, it has multiple limitations that restrict its use in practice. It can only operate on one character at a time; changing an entire word requires multiple calls (one per letter) and constrains the target word to have the same length as the source word. Also, the character placement algorithm in step (3) assumes that the characters are non-overlapping.
GAN Epoch #2: Word-Level Editing — SRNet and 3-Module Networks
SRNet was the first model to perform scene text editing at the word level. SRNet decomposed the STE task into three (jointly-trained) modules: text conversion, background inpainting and fusion.
SRNet was the first model to perform scene text editing at the word level. SRNet decomposed the STE task into three (jointly-trained) modules:
- The text conversion module (in blue) takes a programatic rendering of the target text (“barbarous” in the figure above) and aims to render it in the same typeface as the input word (“introduce”) on a plain background.
- The background inpainting module (in green) erases the text from the input image and fills in the gaps to reconstruct the original background.
- The fusion module (in orange) pastes the rendered target text onto the background.
SRNet architecture. All three modules are flavors of Fully Convolutional Networks (FCNs), with the background inpainting module in particular resembling U-Net (an FCN with the specific property that encoder layers are skip-connected to decoder layers of the same size).
SRNet training. Each module has its own loss, and the network is jointly trained on the sum of losses (LT + LB + LF), where the latter two are trained via GAN. While this modularization is conceptually elegant, it comes with the drawback of requiring paired training data, with supervision for each intermediate step. Realistically, this can only be achieved with artificial data. For each data point, one chooses a random image (from a dataset like COCO), selects two arbitrary words from a dictionary, and renders them with an arbitrary typeface to simulate the “before” and “after” images. As a consequence, the training set doesn’t include any photorealistic examples (though it can somewhat generalize beyond rendered fonts).
Honorable mentions. SwapText followed the same GAN-based 3-module network approach to Scene Text Editing and proposed improvements to the text conversion module.
GAN Epoch #3: Self-supervised and Hybrid Networks
Leap to unsupervised learning. The next leap in STE research was to adopt a self-supervised training approach, where models are trained on unpaired data (i.e., a mere repository of images containing text). To achieve this, one had to remove the label-dependent intermediate losses LT and LB. And due to the design of GANs, the remaining final loss does not require a label either; the model is simply trained on the discriminator’s ability to distinguish between real images and the ones produced by the generator. TextStyleBrush pioneered self-supervised training for STE, while RewriteNet and MOSTEL made the best of both worlds by training in two stages: one supervised (advantage: abundance of synthetic labeled data) and one self-supervised (advantage: realism of natural unlabeled data).
Disentangling text content & style. To remove the intermediate losses, TextStyleBrush and RewriteNet reframe the problem into disentangling text content from text style. To reiterate, the inputs to an STE system are (a) an image with original text, and (b) the desired text — more specifically, a programatic rendering of the desired text on a white or gray background, with a fixed font like Arial. The goal is to combine the style from (a) with the content from (b). In other words, we complementarily aim to discard the content from (a) and the style of (b). This is why it’s necessary to disentangle the text content from the style in a given image.
TextStyleBrush and why GANs went out of fashion. While the idea of disentangling text content from style is straightforward, achieving it in practice required complicated architectures. TextStyleBrush, the most prominent paper in this category, used no less than seven jointly-trained subnetworks, a pre-trained typeface classifier, a pre-trained OCR model and multiple losses. Designing such a system must have been expensive, since all of these components require ablation studies to determine their effect. This, coupled with the fact that GANs are notoriously difficult to train (in theory, the generator and discriminator need to reach Nash equilibrium), made STE researchers eager to switch to diffusion models once they proved so apt for image generation.
The Diffusion Era (2022 — present)
At the beginning of 2022, the image generation world shifted away from GANs towards Latent Diffusion Models (LDM). A comprehensive explanation of LDMs is out of scope here, but you can refer to The Illustrated Stable Diffusion for an excellent tutorial. Here I will focus on the parts of the LDM architecture that are most relevant to the Scene Text Editing task.
As illustrated above, an LDM-based text-to-image model has three main components: (1) a text encoder — typically CLIP, (2) the actual diffusion module — which converts the text embedding into an image embedding in latent space, and (3) an image decoder — which upscales the latent image into a fully-sized image.
Scene Text Editing as a Diffusion Inpainting Task
Text-to-image is not the only paradigm supported by diffusion models. After all, CLIP is equally a text and image encoder, so the embedding passed to the image information creator module can also encode an image. In fact, it can encode any modality, or a concatenation of multiple inputs.
This is the principle behind inpainting, the task of modifying only a subregion of an input image based on given instructions, in a way that looks coherent with the rest of the image. The image information creator ingests an encoding that captures the input image, the mask of the region to be inpainted, and a textual instruction.
Scene Text Editing can be regarded as a specialized form of inpainting. Most of the STE research reduces to the following question: How can we augment the text embedding with additional information about the task (i.e., the original image, the desired text and its positioning, etc.)? Formally, this is known as conditional guidance.
The research papers that fall into this bucket (TextDiffuser, TextDiffuser 2, GlyphDraw, AnyText, etc.) propose various forms of conditional guidance.
Positional guidance
Evidently, there needs to be a way of specifying where to make changes to the original image. This can be a text instruction (e.g. “Change the title at the bottom”), a granular indication of the text line, or more fine-grained positional information for each target character.
Positional guidance via image masks. One way of indicating the desired text position is via grayscale mask images, which can then be encoded into latent space via CLIP or an alternative image encoder. For instance, the DiffUTE model simply uses a black image with a white strip indicating the desired text location.
TextDiffuser produces character-level segmentation masks: first, it roughly renders the desired text in the right position (black text in Arial font on a white image), then passes this rendering through a segmenter to obtain a grayscale image with individual bounding boxes for each character. The segmenter is a U-Net model trained separately from the main network on 4M of synthetic instances.
Positional guidance via language modeling. In A Unified Sequence Inference for Vision Tasks, the authors show that large language models (LLMs) can act as effective descriptors of object positions within an image by simply generating numerical tokens. Arguably, this was an unintuitive discovery. Since LLMs learn language based on statistical frequency (i.e., by observing how often tokens occur in the same context), it feels unrealistic to expect them to generate the right numerical tokens. But the massive scale of current LLMs often defies our expectations nowadays.
TextDiffuser 2 leverage this discovery in an interesting way. They fine-tune an LLM on a synthetic corpus of <text, OCR detection> pairs, teaching it to generate the top-left and bottom-right coordinates of text bounding boxes, as show in the figure below. Notably, they decide to generate bounding boxes for text lines (as opposed to characters), giving the image generator more flexibility. They also run an interesting ablation study that uses a single point to encode text position (either top-left or center of the box), but observe poorer spelling performance — the model often hallucinates additional characters when not explicitly told where the text should end.
Glyph guidance
In addition to position, another piece of information that can be fed into the image generator is the shape of the characters. One could argue that shape information is redundant. After all, when we prompt a text-to-image model to generate a flamingo, we generally don’t need to pass any additional information about its long legs or the color of its feathers — the model has presumably learnt these details from the training data. However, in practice, the trainings sets (such as Stable Diffusion’s LAION-5B) are dominated by natural pictures, in which text is underrepresented (and non-Latin scripts even more so).
Multiple studies (DiffUTE, GlyphControl, GlyphDraw, GlyphDiffusion, AnyText etc.) attempt to make up for this imbalance via explicit glyph guidance — effectively rendering the glyphs programmatically with a standard font, and then passing an encoding of the rendering to the image generator. Some simply place the glyphs in the center of the additional image, some close to the target positions (reminiscent of ControlNet).
STE via Diffusion is (Still) Complicated
While the training process for diffusion models is more stable than GANs, the diffusion architectures for STE in particular are still quite complicated. The figure below shows the AnyText architecture, which includes (1) an auxiliary latent module (including the positional and glyph guidance discussed above), (2) a text embedding module that, among other components, requires a pre-trained OCR module, and (3) the standard diffusion pipeline for image generation. It is hard to argue this is conceptually much simpler than the GAN-based TextStyleBrush.
The Future of Scene Text Editing
When the status quo is too complicated, we have a natural tendency to keep working on it until it converges to a clean solution. In a way, this is what happened to the natural language processing field: computational linguistics theories, grammars, dependency parsing — all collapsed under Transformers, which make a very simple statement: the meaning of a token depends on all others around it. Evidently, Scene Text Editing is miles away from this clarity. Architectures contain many jointly-trained subnetworks, pre-trained components, and require specific training data.
Text-to-image models will inevitably become better at certain aspects of text generation (spelling, typeface diversity, and how crisp the characters look), with the right amount and quality of training data. But controllability will remain a problem for a much longer time. And even when models do eventually learn to follow your instructions to the t, the text-to-image paradigm might still be a subpar user experience — would you rather describe the position, look and feel of a piece of text in excruciating detail, or would you rather just draw an approximate box and choose an inspiration color from a color picker?
Epilogue: Preventing Abuse
Generative AI has brought to light many ethical questions, from authorship / copyright / licensing to authenticity and misinformation. While all these loom large in our common psyche and manifest in various abstract ways, the misuses of Scene Text Editing are down-to-earth and obvious — people faking documents.
While building Textify, we’ve seen it all. Some people bump up their follower count in Instagram screenshots. Others increase their running speed in Strava screenshots. And yes, some attempt to fake IDs, credit cards and diplomas. The temporary solution is to build classifiers for certain types of documents and simply refuse to edit them, but, long-term the generative AI community needs to invest in automated ways of determining document authenticity, be it a text snippet, an image or a video.
Editing Text in Images with AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.