
Exploring Alternatives to Python’s Built-in Data Structures | by Aashish Nair | May, 2022
Leverage data containers using a powerful yet underrated module
Python‘s built-in data structures serve as the backbone for many operations. That being said, users that leverage these data structures soon have to come to terms with their limitations.
Fortunately, Python offers the collections package that provides alternative data containers that can be superior for certain tasks. The package contains a variety of data structures that can be used as substitutes for traditional lists, tuples, or dictionaries.
Here, I offer a glimpse into a few container data types in this module that should be in your programming arsenal.
1. Default Dict
Dictionaries are the go-to data structure when it comes to handling key-value pairs. That being said, they do have a caveat: accessing a key that doesn’t exist will return a KeyError.
For instance, suppose you have the following list of tuples.
You could store these values in a dictionary with the following:
It’s a feasible approach, but anticipating non-existent keys requires the inclusion of an if statement. Otherwise, you would get an error when searching for a sport that is not in the dictionary.
For instance, accessing the “Rugby” key in the dictionary will raise a KeyError since the key is non-existent.
The default dict offers a solution to this dilemma. It assigns a default data type to a key that hasn’t yet been created.
Let’s repeat the previous task with a default dict.
When the default dict object is created, any keys that haven’t been created will be assigned an empty list when accessed. Thus, searching for a non-existent key will not raise any error.
This time, a search for the “Rugby” key will return an empty list as opposed to a KeyError.
Thanks to this feature, there is no need to perform an initial check to search for keys in the dictionary. As a result, the operation can be executed with fewer lines of code.
2. Named Tuple
The collection module’s named tuple is a variant of Python’s built-in tuple. It is equal in terms of memory efficiency but stands out due to its distinct feature, which allows users to name the indexes of the tuple.
Suppose that you have a tuple that stores an athlete and their respective sport.
If you wished to obtain the sport in the tuple, you could access the element that contains that information by calling the index.
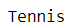
There is a completely valid approach. However, this line of code could be difficult to interpret in the eyes of a reader. After all, the index number in tuples can be arbitrary, so the functionality of the code might be difficult to decipher at a glance (especially when you’re dealing with a larger number of indexes).
To avoid hampering the readability of the code, the named tuple can be the preferable alternative.
Using named tuples entails creating a named tuple object, which contains the name of the tuple as well as the label for each index.
After that, you can define athletes with the named tuple.
The benefit of this approach is that users can now call certain elements by their label as opposed to their index numbers. Here is how you can obtain the sport element from the named tuple.
This approach removes all ambiguity and enables the readers to understand exactly what piece of information is being extracted.
3. Counter
The collection module’s counter is the ideal tool for deriving a count for a given collection of data.
It stores elements and their corresponding frequencies as key-value pairs.
Suppose you have the following list of sports:
Manually obtaining a count for each sport can be accomplished with a dictionary:
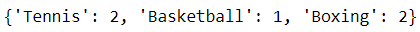
While this is an acceptable solution, the Counter allows users to attain the same results with a simple one-liner.

In addition, the counter boasts numerous methods that can facilitate subsequent tasks.
One can find the N most frequently occurring elements in the given data with the most_common method.
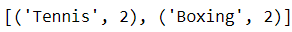
One can also use counters to compare different collections of data. In the following example, we find the count of elements that are in the first list but not in the second list.
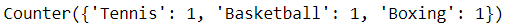
Conclusion
Ultimately, there are alternatives to Python’s built-in data structures that are worth considering. I encourage trying out such tools since they can present a more suitable solution for certain use cases.
Many of the container data types in the collections module are powerful yet underutilized. Understanding and implementing them should be easy since they are variants of Python’s built-in data structures.
That being said, this is not a comprehensive rundown of the utility of the collections module. If you’re interested in the other container datatypes in this module, feel free to learn about them in the module’s documentation.
Happy coding!
Leverage data containers using a powerful yet underrated module

Python‘s built-in data structures serve as the backbone for many operations. That being said, users that leverage these data structures soon have to come to terms with their limitations.
Fortunately, Python offers the collections package that provides alternative data containers that can be superior for certain tasks. The package contains a variety of data structures that can be used as substitutes for traditional lists, tuples, or dictionaries.
Here, I offer a glimpse into a few container data types in this module that should be in your programming arsenal.
1. Default Dict
Dictionaries are the go-to data structure when it comes to handling key-value pairs. That being said, they do have a caveat: accessing a key that doesn’t exist will return a KeyError.
For instance, suppose you have the following list of tuples.
You could store these values in a dictionary with the following:
It’s a feasible approach, but anticipating non-existent keys requires the inclusion of an if statement. Otherwise, you would get an error when searching for a sport that is not in the dictionary.
For instance, accessing the “Rugby” key in the dictionary will raise a KeyError since the key is non-existent.
The default dict offers a solution to this dilemma. It assigns a default data type to a key that hasn’t yet been created.
Let’s repeat the previous task with a default dict.
When the default dict object is created, any keys that haven’t been created will be assigned an empty list when accessed. Thus, searching for a non-existent key will not raise any error.
This time, a search for the “Rugby” key will return an empty list as opposed to a KeyError.
Thanks to this feature, there is no need to perform an initial check to search for keys in the dictionary. As a result, the operation can be executed with fewer lines of code.
2. Named Tuple
The collection module’s named tuple is a variant of Python’s built-in tuple. It is equal in terms of memory efficiency but stands out due to its distinct feature, which allows users to name the indexes of the tuple.
Suppose that you have a tuple that stores an athlete and their respective sport.
If you wished to obtain the sport in the tuple, you could access the element that contains that information by calling the index.
There is a completely valid approach. However, this line of code could be difficult to interpret in the eyes of a reader. After all, the index number in tuples can be arbitrary, so the functionality of the code might be difficult to decipher at a glance (especially when you’re dealing with a larger number of indexes).
To avoid hampering the readability of the code, the named tuple can be the preferable alternative.
Using named tuples entails creating a named tuple object, which contains the name of the tuple as well as the label for each index.
After that, you can define athletes with the named tuple.
The benefit of this approach is that users can now call certain elements by their label as opposed to their index numbers. Here is how you can obtain the sport element from the named tuple.
This approach removes all ambiguity and enables the readers to understand exactly what piece of information is being extracted.
3. Counter
The collection module’s counter is the ideal tool for deriving a count for a given collection of data.
It stores elements and their corresponding frequencies as key-value pairs.
Suppose you have the following list of sports:
Manually obtaining a count for each sport can be accomplished with a dictionary:
While this is an acceptable solution, the Counter allows users to attain the same results with a simple one-liner.
In addition, the counter boasts numerous methods that can facilitate subsequent tasks.
One can find the N most frequently occurring elements in the given data with the most_common method.
One can also use counters to compare different collections of data. In the following example, we find the count of elements that are in the first list but not in the second list.
Conclusion
Ultimately, there are alternatives to Python’s built-in data structures that are worth considering. I encourage trying out such tools since they can present a more suitable solution for certain use cases.
Many of the container data types in the collections module are powerful yet underutilized. Understanding and implementing them should be easy since they are variants of Python’s built-in data structures.
That being said, this is not a comprehensive rundown of the utility of the collections module. If you’re interested in the other container datatypes in this module, feel free to learn about them in the module’s documentation.
Happy coding!
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.