
Extensible and Customisable Vertex AI MLOps Platform
MLOps Platform
Building scalable Kubeflow ML pipelines on Vertex AI and ‘jailbreaking’ Google prebuilt containers
When I decided to write an article on building scalable pipelines with Vertex AI last year, I contemplated the different formats it could take. I finally settled on building a fully functioning MLOps platform, as lean as possible due to time restriction, and open source the platform for the community to gradually develop. But time proved a limiting factor and I keep dillydallying. On some weekends, when I finally decided to put together the material, I found a litany of issues which I have now documented to serve as guide to others who might tread the same path.
This is what led to the development of mlops-platform, an initiative designed to demonstrate a streamlined, end-to-end process of building scalable and operationalised machine learning models on VertexAI using Kubeflow pipelines. The major features of the platform can be broken down in fourfold: firstly, it encapsulates a modular and flexible pipeline architecture that accommodates various stages of the machine learning lifecycle, from data loading and preprocessing to model training, evaluation, deployment and inference. Secondly, it leverages Google Cloud’s Vertex AI services for seamless integration, ensuring optimal performance, scalability, and resource efficiency. Thirdly, it is scaffolded with a series of operations that are frequently used to automate ML workflows. Lastly, it documents common challenges experienced when building projects of this scale and their respective workarounds.
I have built the mlops platform with two major purposes in mind:
- To serve as an educational place where the community can learn about the fundamental components of MLOps platform including the various operations that enable such platform
- To serve as building blocks for teams with little to no engineering support so they can self serve when developing data science and ML engineering projects
I hope the platform will continue to grow from contributions from the community.
Though Google has a GitHub repo containing numerous examples of using Vertex AI pipeline, the repo is daunting to navigate. Moreover, you often need a multiple of ops wrappers around your application for organisation purposes as you would have multiple teams using the platform. And more often, there are issues that crop up during development that do not get addressed enough, leaving developers frustrated. Google support might be insufficient especially when chasing production deadlines. On a personal experience, even though my company have enhanced support, I have an issue raised with Google Vertex engineering team which drags on for more than four months. In addition, due to the rapid pace at which technology is evolving, posting on forums might not yield desired solution since only few people might have experienced the issue being posted about. So having a working end to end platform to build upon with community support is invaluable.
By the way, have you heard about pain driven development (PDD)? It is analogous to test or behaviour driven development. In PDD, the development is driven by pain points. This means changes are made to codebase when the team feels impacted and could justify the trade off. It follows the mantra of if it ain’t broke, don’t fix. Not to worry, this post will save some pains (emanating from frustration) when using Google Vertex AI, especially the prebuilt containers, for building scalable ML pipelines. But more appropriately, in line with the PDD principle, I have deliberately made it a working platform with some pain points. I have detailed those pain points hoping that interested parties from the community would join me in gradually integrating the fixes. With those house keeping out of the way, lets cut to the chase!
Google Vertex AI pipelines provides a framework to run ML workflows using pipelines that are designed with Kubeflow or Tensorflow Extended frameworks. In this way, Vertex AI serves as an orchestration platform that allows composing a number of ML tasks and automating their executions on GCP infrastructure. This is an important distinction to make since we don’t write the pipelines with Vertex AI rather, it serves as the platform for orchestrating the pipelines. The underlying Kubeflow or Tensorflow Extended pipeline follows common framework used for orchestrating tasks in modern architecture. The framework separates logic from computing environment. The logic, in the case of ML workflow, is the ML code while the computing environment is a container. Both together are referred to as a component. When multiple components are grouped together, they are referred to as pipeline. There is modality in place, similar to other orchestration platforms, to pass data between the components. The best place to learn in depth about pipelines is from Kubeflow documentation and several other blog posts which I have linked in the references section.
I mentioned the general architecture of orchestration platforms previously. Some other tools using similar architecture as Vertex AI where logic are separated from compute are Airflow (tasks and executors), GitHub actions (jobs and runners), CircleCI (jobs and executors) and so on. I have an article in the pipeline on how having a good grasp of the principle of separation of concerns integrated in this modern workflow architecture can significantly help in the day to day use of the tools and their troubleshooting. Though Vertex AI is synonymous for orchestrating ML pipelines, in theory any logic such as Python script, data pipeline or any containerised application could be run on the platform. Composer, which is a managed Apache Airflow environment, was the main orchestrating platform on GCP prior to Vertex AI. The two platforms have pros and cons that should be considered when making a decision to use either.
I am going to avoid spamming this post with code which are easily accessible from the platform repository. However, I will run through the important parts of the mlops platform architecture. Please refer to the repo to follow along.
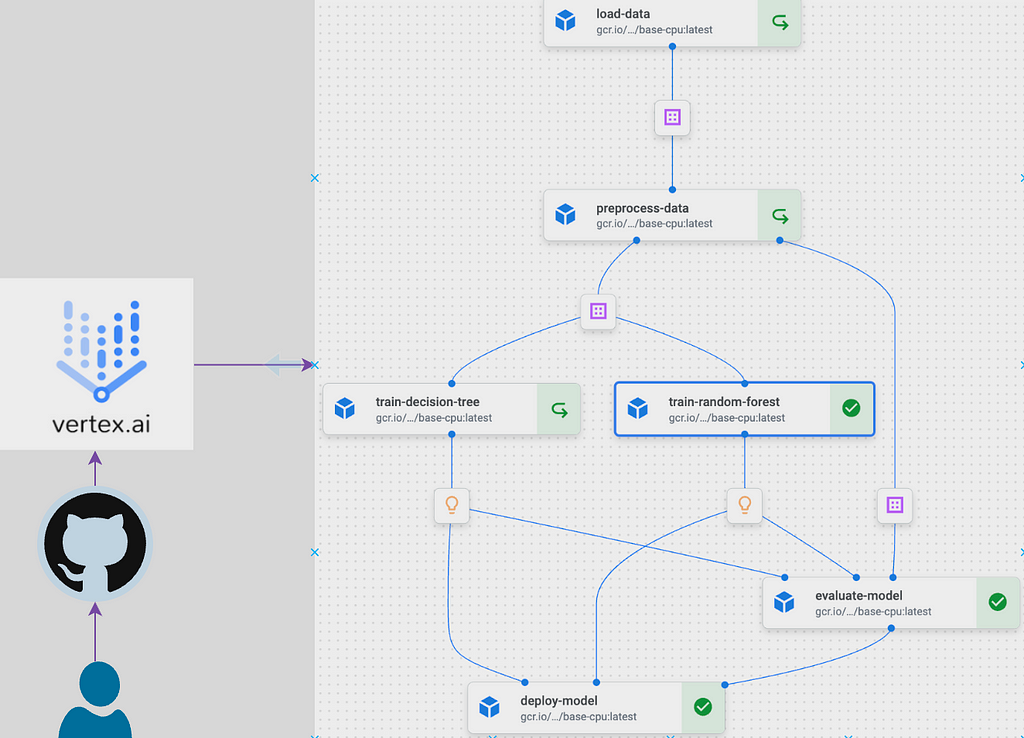
Components
The architecture of the platform revolves around a set of well-defined components housed within the components directory. These components, such as data loading, preprocessing, model training, evaluation, and deployment, provide a modular structure, allowing for easy customisation and extension. Lets look through one of the components, the preprocess_data.py, to understand the general structure of a component.
from config.config import base_image
from kfp.v2 import dsl
from kfp.v2.dsl import Dataset, Input, Output
@dsl.component(base_image=base_image)
def preprocess_data(
input_dataset: Input[Dataset],
train_dataset: Output[Dataset],
test_dataset: Output[Dataset],
train_ratio: float = 0.7,
):
"""
Preprocess data by partitioning it into training and testing sets.
"""
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv(input_dataset.path)
df = df.dropna()
if set(df.iloc[:, -1].unique()) == {'Yes', 'No'}:
df.iloc[:, -1] = df.iloc[:, -1].map({'Yes': 1, 'No': 0})
train_data, test_data = train_test_split(df, train_size=train_ratio, random_state=42)
train_data.to_csv(train_dataset.path, index=False)
test_data.to_csv(test_dataset.path, index=False)
A closer look at the script above would show a familiar data science workflow. All the script does is read in some data, split them for model development and write the splits to some path where it can be readily accessed by downstream tasks. However, since this function would be run on Vertex AI, it is decorated by a Kubeflow pipeline @dsl.component(base_image=base_image) which marks the function as a Kubeflow pipeline component to be run within the base_image container. I will talk about the base_image later. This is all is required to run a function within a container on Vertex AI. Once we structured all our other functions in similar manner and decorate them as Kubeflow pipeline components, the mlpipeline.py function will import each components to structure the pipeline.
#mlpipeline.py
from kfp.v2 import dsl, compiler
from kfp.v2.dsl import pipeline
from components.load_data import load_data
from components.preprocess_data import preprocess_data
from components.train_random_forest import train_random_forest
from components.train_decision_tree import train_decision_tree
from components.evaluate_model import evaluate_model
from components.deploy_model import deploy_model
from config.config import gcs_url, train_ratio, project_id, region, serving_image, service_account, pipeline_root
from google.cloud import aiplatform
@pipeline(
name="ml-platform-pipeline",
description="A pipeline that performs data loading, preprocessing, model training, evaluation, and deployment",
pipeline_root= pipeline_root
)
def mlplatform_pipeline(
gcs_url: str = gcs_url,
train_ratio: float = train_ratio,
):
load_data_op = load_data(gcs_url=gcs_url)
preprocess_data_op = preprocess_data(input_dataset=load_data_op.output,
train_ratio=train_ratio
)
train_rf_op = train_random_forest(train_dataset=preprocess_data_op.outputs['train_dataset'])
train_dt_op = train_decision_tree(train_dataset=preprocess_data_op.outputs['train_dataset'])
evaluate_op = evaluate_model(
test_dataset=preprocess_data_op.outputs['test_dataset'],
dt_model=train_dt_op.output,
rf_model=train_rf_op.output
)
deploy_model_op = deploy_model(
optimal_model_name=evaluate_op.outputs['optimal_model'],
project=project_id,
region=region,
serving_image=serving_image,
rf_model=train_rf_op.output,
dt_model=train_dt_op.output
)
if __name__ == "__main__":
pipeline_filename = "mlplatform_pipeline.json"
compiler.Compiler().compile(
pipeline_func=mlplatform_pipeline,
package_path=pipeline_filename
)
aiplatform.init(project=project_id, location=region)
_ = aiplatform.PipelineJob(
display_name="ml-platform-pipeline",
template_path=pipeline_filename,
parameter_values={
"gcs_url": gcs_url,
"train_ratio": train_ratio
},
enable_caching=True
).submit(service_account=service_account)
@pipeline decorator enables the function mlplatform_pipeline to be run as a pipeline. The pipeline is then compiled to the specified pipeline filename. Here, I have specified JSON configuration extension for the compiled file but I think Google is moving toYAML. The compiled file is then picked up by aiplatform and submitted to Vertex AI platform for execution.
The only other thing I found puzzling while starting out with the kubeflow pipelines are the parameters and artifacts set up so have a look to get up to speed.
Configuration
The configuration file in the config directory facilitates the adjustment of parameters and settings across different stages of the pipeline. Along with the config file, I have also included a dot.env file which has comments on the variables specifics and is meant to be a guide for the nature of the variables that are loaded into the config file.
Notebooks
I mostly start my workflow and exploration within notebooks as it enable easy interaction. As a result, I have included notebooks directory as a means of experimenting with the different components logics.
Testing
Testing plays a very important role in ensuring the robustness and reliability of machine learning workflows and pipelines. Comprehensive testing establishes a systematic approach to assess the functionality of each component and ensures that they behave as intended. This reduces the instances of errors and malfunctioning during the execution stage. I have included a test_mlpipeline.py script mostly as a guide for the testing process. It uses pytest to illustrate testing concept and provides a framework to build upon.
Project Dependencies
Managing dependencies can be a nightmare when developing enterprise scale applications. And given the myriads of packages required in a ML workflow, combined with the various software applications needed to operationalise it, it can become a Herculean task managing the dependencies in a sane manner. One package that is slowly gaining traction is Poetry. It is a tool for dependency management and packaging in Python. The key files generated by Poetry are pyproject.toml and poetry.lock. pyproject.tomlfile is a configuration file for storing project metadata and dependencies while the poetry.lock file locks the exact versions of dependencies, ensuring consistent and reproducible builds across different environments. Together, these two files enhance dependency resolution. I have demonstrated how the two files replace the use of requirement.txt within a container by using them to generate the training container image for this project.
Makefile
A Makefile is a build automation tool that facilitates the compilation and execution of a project’s tasks through a set of predefined rules. Developers commonly use Makefiles to streamline workflows, automate repetitive tasks, and ensure consistent and reproducible builds. The Makefile within mlops-platform has predefined commands to seamlessly run the entire pipeline and ensure the reliability of the components. For example, the all target, specified as the default, efficiently orchestrates the execution of both the ML pipeline (run_pipeline) and tests (run_tests). Additionally, the Makefile provides a clean target for tidying up temporary files while the help target offers a quick reference to the available commands.
Documentation
The project is documented in the README.md file, which provides a comprehensive guide to the project. It includes detailed instructions on installation, usage, and setting up Google Cloud Platform services.
Orchestration with CI/CD
GitHub Actions workflow defined in .github/workflows directory is crucial for automating the process of testing, building, and deploying the machine learning pipeline to Vertex AI. This CI/CD approach ensures that changes made to the codebase are consistently validated and deployed, enhancing the project’s reliability and reducing the likelihood of errors. The workflow triggers on each push to the main branch or can be manually executed, providing a seamless and reliable integration process.
Inference Pipeline
There are multiple ways to implement inference or prediction pipeline. I have gone the good old way here by loading in both the prediction features and the uploaded model, getting predictions from the model and writing the predictions to a BigQuery table. It is worth noting that for all the talk about prediction containers, they are not really needed if all is required is batch prediction. We might as well use the training container for our batch prediction as demonstrated in the platform. However, the prediction container is required for online prediction. I have also included modality for local testing of the batch prediction pipeline which can be generalised to test any of the other components or any scripts for that matter. Local testing can be done by navigating to batch_prediction/batch_prediction_test directory, substituting for placeholder variables and running the following commands:
# First build the image using Docker
docker build -f Dockerfile.batch -t batch_predict .
# The run batch prediction pipeline locally using the built image from above
docker run -it \
-v {/local/path/to/service_acount-key.json}:/secrets/google/key.json \
-e GOOGLE_APPLICATION_CREDENTIALS=/secrets/google/key.json \
batch_predict \
--model_gcs_path={gs://path/to/gcs/bucket/model.joblib} \
--input_data_gcs_path={gs://path/to/gcs/bucket/prediction_data.csv} \
--table_ref={project_id.dataset.table_name} \
--project={project_id}
The service account needs proper access on GCP to execute the task above, it should have permission to read from the GCP bucket and write to the BigQuery table.
Challenges and Solutions: `Jailbreaking’ Google Vertex AI prebuilt containers
Some of the challenges encountered during the building of this project emanates from the use of container images and the associated package versions within the Google prebuilt containers. I presume the main goal of Google when creating prebuilt containers is to lift off major engineering tasks for the data scientists and enable them to focus mainly on ML logics. However, more work would be required to ensure this aim is achieved as the prebuilt containers have various versions mismatch requiring significant debugging effort to resolve. I have detailed some of the challenges and some possible fixes.
- Multi-Architectural image build: While using macOS has its upsides, building container image on them to be deployed on cloud platforms might not be one of them. The main challenge is that most cloud platforms supports Linux running on amd64 architecture while latest macOS systems run on arm64 architecture. As a result, binaries compiled on macOS would ordinarily not be compatible with Linux. This means that built images that compile successfully on macOS might fail when run on most cloud platforms. And what is more, the log messages that result from this error is tacit and unhelpful, making it challenging to debug. It should be noted that this is an issue with most modern cloud platforms and not peculiar to GCP. As a result, there are multiple workarounds to overcome this challenge.
- Use BuildX: Buildx is a Docker CLI plugin that allows building a multi-architecture container image that can run on multiple platforms. Ensure Docker desktop is installed as it is required to build image locally. Alternatively, the image can be built from Google cloud shell. The following script would build a compatible container image on macOS and push it to GCP artifact registry.
# start Docker Desktop (can also open manually)
open -a Docker
# authentucate to GCP if desired to push the image to GCP artifact repo
gcloud auth login
gcloud auth configure-docker "{region}-docker.pkg.dev" --quiet
# create and use a buildx builder instance (only needed once)
docker buildx create --name mybuilder --use
docker buildx inspect --bootstrap
# build and push a multi-architecture Docker image with buildx
docker buildx build --platform linux/amd64,linux/arm64 -t "{region}-docker.pkg.dev/{project_id}/{artifact_repo}/{image-name}:latest" -f Dockerfile --push .
The name of the container follows Google specific format for naming containers.
- Set Docker environment variable : Set DOCKER_DEFAULT_PLATFORM permanently in the macOS system config file to ensure that Docker always build image compatible with Linux amd64.
# open Zsh config file (I use visual code but it could be other editor like nano)
code ~/.zshrc
# insert at the end of file
export DOCKER_DEFAULT_PLATFORM=linux/amd64
# save and close file then apply changes
source ~/.zshrc
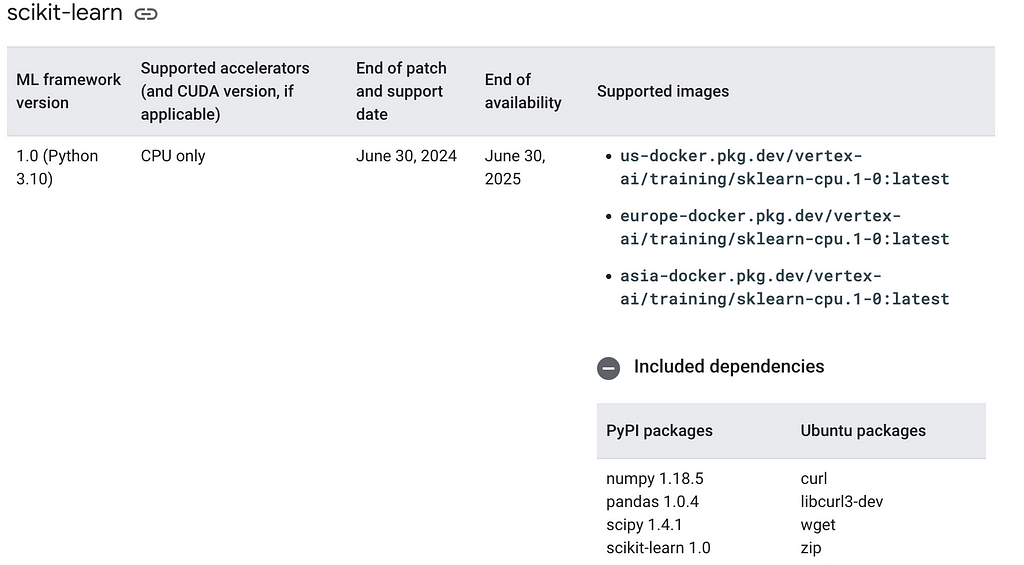
2. Conflicting versions in prebuilt container images: Google maintains a host of prebuilt images for prediction and training tasks. These container images are available for common ML frameworks in different versions. However, I found that the documented versions sometimes don’t match the actual version and this constitute a major point of failure when using these container images. Giving what the community has gone through in standardising versions and dependencies and the fact that container technology is developed to mainly address reliable execution of applications, I think Google should strive to address the conflicting versions in the prebuilt container images. Make no mistake, battling with version mismatch can be frustrating which is why I encourage ‘jailbreaking’ the prebuilt images prior to using them. When developing this tutorial, I decided to useeurope-docker.pkg.dev/vertex-ai/training/sklearn-gpu.1-0:latest and europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest. From the naming conventions, both are supposed to be compatible and should havesklearn==1.0. In fact, this is confirmed on the site as shown in the screenshot below and also, on the container image artifact registry.
However, the reality is different. I ran into version mismatch errors when deploying the built model to an endpoint. A section of the error message is shown below.
Trying to unpickle estimator OneHotEncoder from version 1.0.2 when using version 1.0
Suprise! Suprise! Suprise! Basically, what the log says is that you have pickled with version 1.0.2 but attempting to unpickle with version 1.0. To make progress, I decided to do some ‘jailbreaking’ and looked under the hood of the prebuilt container images. It is a very basic procedure but opened many can of worms.
- From the terminal or Google cloud shell
- Pull the respective image from Google artifact registry
docker pull europe-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest
3. Run the image, overide its entrypoint command and drop onto its bash shell terminal
docker run -it --entrypoint /bin/bash europe-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest
4. Check the sklearn version
python -c "import sklearn; print(sklearn.__version__)"
The output, as of the time of writing this post, is shown in the screenshot below:

Conducting similar exercise for europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-3:latest , the sklearn version is 1.3.2 and 1.2.2 for the 1.2version. What is even more baffling is that pandas is missing from both version 1–2and 1-3 which begs the question of whether the prebuilt containers are being actively maintained. Of course, the issue is not the minor update but the fact that the corresponding prediction image did not have similar update which results in the mismatch error shown above.
When I contacted Google support to report the mismatch, the Vertex AI engineering team mentioned alternatives such as Custom prediction routines (CPR) and SklearnPredictor. And I was pointed to newer image versions with similar issues and missing pandas!
Moving on, if you are feeling like a Braveheart and want to explore further, you can access all the other files that Google runs when launching prebuilt containers by running ls command from within the container and looking through the files and folders.
Build Base Image
So having discovered the issue, what can be done in order to still take advantage of prebuilt containers? What I did was to extract all the relevant packages from the container.
pip freeze > requirement.txt
cat requirement.txt
The commands above will extract all the installed packages and print them to the container terminal. The packages can then be copied and used in creating a custom container image, ensuring that the ML framework version in both the training and prediction container matches. If you prefer to copy the file content to your local directory then use the following command:
# If on local terminal, copy requirements.txt into current directory
docker cp {running-container}:/requirements.txt .
Some of the packages in the prebuilt containers would not be needed for individual project so it is better to select the ones that matches your workflow. The most important one to lock down is the ML framework version whether it is sklearn or xgboost, making sure both training and prediction versions match.
I have basically locked the sklearn version to match the version of the prebuilt prediction image. In this case, it is version 1.0 and I have left all the other packages as they are.
Then to build the custom training image, use the following commands:
# commands to build the docker
#first authenticate to gcloud
# gcloud auth login
gcloud auth configure-docker
# Build the image using Docker
docker build -f docker/Dockerfile.poetry -t {region}-docker.pkg.dev/{gcp-project-id}/{gcp-artifact-repo}/{image-name}:latest .
The above is saying is:
- docker: hey Docker!
- build: build an image for me
- -f: use the following file
- -t: tag (or name) it the following
- . : use files in this directory (current directory in this case) if needed
Then the built image can be pushed to the artifact registry as follows:
# Push to artifact registry
docker push {region}-docker.pkg.dev/{gcp-project-id}/{gcp-artifact-repo}/{image-name}:latest
Vision
There are numerous extensions to be added to this project and I will invite willing contributors to actively pick on any of them. Some of my thoughts are detailed below but feel free to suggest any other improvements. Contributions are welcomed via PR. I hope the repo can be actively developed by those who wants to learn end to end MLOps as well as serve as a base on which small teams can build upon.
- Monitoring pipeline: Observability is integral to MLOps platform. It enables team to proactively monitors the state and behaviour of their platform and take appropriate action in the event of an anomaly. The mlops-platform is missing a monitoring pipeline and it would be a good addition. I plan to write on custom implementation of monitoring pipeline but in the mean time, Vertex AI has monitoring pipeline that can be integrated.
- Inference pipeline: Vertex AI has batch prediction method that could be integrated. An argument can be put forward on whether the current custom batch prediction in the mlops platform would scale. The main issue is that the prediction features are loaded into the predicting environment which might run into memory issue with very large dataset. I havent experienced this issue previously but it can be envisaged. Prior to Google rebranding aiplatform to Vertex AI, I have always deployed models to the aiplatform to benefit from its model versioning but would run the batch prediction pipeline within Composer. I prefer this approach as it gives flexibility in terms of pre and post processing. Moreover, Google batch prediction method is fiddly and tricky to debug when things go wrong. Nevertheless, I think it will improve with time so would be a good addition to the platform.
- Refactoring: While I have coupled together computing and logic code in the implementation on same file, I think it would be cleaner if they are separated. Decoupling both would improve the modularity of the code and enable reusability. In addition, there should be a pipeline directory for the different pipeline files with potential integration of monitoring pipeline.
- Full customisation: Containers should be fully customised in order to have fine-grained control and flexibility. This means having both training and prediction containers custom built.
- Testing: I have integrated a testing framework which runs successfully within the platform but it is not a functional test logic. It does provide a framework to build proper tests covering data quality, components and pipelines functional tests.
- Containerisation integration: The creation of the container base image is done manually at the moment but should be integrated in both the makefile and GitHub action workflow.
- Documentation: The documentation would need updating to reflect additional features being added and ensure people with different skill sets can easily navigate through the platform. Please update the READ.me file for now but this project should use Sphinx in the long run.
- Pre-commit hooks: This is an important automation tool that can be employed to good use. Pre-commit hooks are configuration scripts executed prior to actioning a commit to help enforce styles and policy. For example, the hooks in the platform enforced linting and prevent committing large files as well as committing to the main branch. However, my main thought was to use it for dynamically updating GitHub secrets from the values in .env file. The GitHub secrets are statically typed in the current implementation so when certain variables change, they don’t get automatically propagated to GitHub secrets. Similar thing would occur when new variables are added which then needs to be manually propagated to GitHub. Pre-commit can be used to address this problem by instructing it to automatically propagate changes in the local .envfile to GitHub secrets.
- Infrastructure provisioning: Artifact registry, GCP bucket, BigQuery table and service account are all provisioned manually but their creation should be automated via Terraform.
- Scheduler: If this is a batch prediction or continuous training pipeline, we would want to schedule it to run at some specified time and frequency. Vertex AI gives a number of options to configure schedules. Indeed, an orchestration platform would not be complete without this feature.
- Additional models: There are two models (Random forest and Decision trees) within the platfrom now but should be straightforward adding other frameworks, such as xgboost and light GBM, for modelling tabular data.
- Security: The GitHub action uses service account for authentication to GCP services but should ideally be using workflow identity federation.
- Distribution: The platform is suitable in the current state for educational purpose and perhaps individual projects. However, it would require adaptation for bigger team. Think about individuals that make up teams with different skill set and varying challenges. In this regard, the platform interface can be improved using click as detailed in this post. Afterwards, it can be packaged and distributed to ensure easy installation. Also, distribution enables us to make changes to the package and centralise its updates so that it propagates as needed. Poetry can be used for the packaging and distribution so using it for dependency management has laid a good foundation.
Summary
The MLOps platform provides a modular and scalable pipeline architecture for implementing different ML lifecycle stages. It includes various operations that enable such platform to work seamlessly. Most importantly, it provides a learning opportunity for would be contributors and should serve as a good base on which teams can build upon in their machine learning tasks.
Conclusion
Well, that is it people! Congratulations and well done if you are able to make it here. I hope you have benefited from this post. Your comments and feedback are most welcome and please lets connect on Linkedln. If you found this to be valuable, then don’t forget to like the post and give the MLOps platform repository a star.
References
MLOps repo: https://github.com/kbakande/mlops-platform
https://medium.com/google-cloud/machine-learning-pipeline-development-on-google-cloud-5cba36819058
https://datatonic.com/insights/vertex-ai-improving-debugging-batch-prediction/
https://econ-project-templates.readthedocs.io/en/v0.5.2/pre-commit.html
Extensible and Customisable Vertex AI MLOps Platform was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
MLOps Platform
Building scalable Kubeflow ML pipelines on Vertex AI and ‘jailbreaking’ Google prebuilt containers
When I decided to write an article on building scalable pipelines with Vertex AI last year, I contemplated the different formats it could take. I finally settled on building a fully functioning MLOps platform, as lean as possible due to time restriction, and open source the platform for the community to gradually develop. But time proved a limiting factor and I keep dillydallying. On some weekends, when I finally decided to put together the material, I found a litany of issues which I have now documented to serve as guide to others who might tread the same path.
This is what led to the development of mlops-platform, an initiative designed to demonstrate a streamlined, end-to-end process of building scalable and operationalised machine learning models on VertexAI using Kubeflow pipelines. The major features of the platform can be broken down in fourfold: firstly, it encapsulates a modular and flexible pipeline architecture that accommodates various stages of the machine learning lifecycle, from data loading and preprocessing to model training, evaluation, deployment and inference. Secondly, it leverages Google Cloud’s Vertex AI services for seamless integration, ensuring optimal performance, scalability, and resource efficiency. Thirdly, it is scaffolded with a series of operations that are frequently used to automate ML workflows. Lastly, it documents common challenges experienced when building projects of this scale and their respective workarounds.
I have built the mlops platform with two major purposes in mind:
- To serve as an educational place where the community can learn about the fundamental components of MLOps platform including the various operations that enable such platform
- To serve as building blocks for teams with little to no engineering support so they can self serve when developing data science and ML engineering projects
I hope the platform will continue to grow from contributions from the community.
Though Google has a GitHub repo containing numerous examples of using Vertex AI pipeline, the repo is daunting to navigate. Moreover, you often need a multiple of ops wrappers around your application for organisation purposes as you would have multiple teams using the platform. And more often, there are issues that crop up during development that do not get addressed enough, leaving developers frustrated. Google support might be insufficient especially when chasing production deadlines. On a personal experience, even though my company have enhanced support, I have an issue raised with Google Vertex engineering team which drags on for more than four months. In addition, due to the rapid pace at which technology is evolving, posting on forums might not yield desired solution since only few people might have experienced the issue being posted about. So having a working end to end platform to build upon with community support is invaluable.
By the way, have you heard about pain driven development (PDD)? It is analogous to test or behaviour driven development. In PDD, the development is driven by pain points. This means changes are made to codebase when the team feels impacted and could justify the trade off. It follows the mantra of if it ain’t broke, don’t fix. Not to worry, this post will save some pains (emanating from frustration) when using Google Vertex AI, especially the prebuilt containers, for building scalable ML pipelines. But more appropriately, in line with the PDD principle, I have deliberately made it a working platform with some pain points. I have detailed those pain points hoping that interested parties from the community would join me in gradually integrating the fixes. With those house keeping out of the way, lets cut to the chase!
Google Vertex AI pipelines provides a framework to run ML workflows using pipelines that are designed with Kubeflow or Tensorflow Extended frameworks. In this way, Vertex AI serves as an orchestration platform that allows composing a number of ML tasks and automating their executions on GCP infrastructure. This is an important distinction to make since we don’t write the pipelines with Vertex AI rather, it serves as the platform for orchestrating the pipelines. The underlying Kubeflow or Tensorflow Extended pipeline follows common framework used for orchestrating tasks in modern architecture. The framework separates logic from computing environment. The logic, in the case of ML workflow, is the ML code while the computing environment is a container. Both together are referred to as a component. When multiple components are grouped together, they are referred to as pipeline. There is modality in place, similar to other orchestration platforms, to pass data between the components. The best place to learn in depth about pipelines is from Kubeflow documentation and several other blog posts which I have linked in the references section.
I mentioned the general architecture of orchestration platforms previously. Some other tools using similar architecture as Vertex AI where logic are separated from compute are Airflow (tasks and executors), GitHub actions (jobs and runners), CircleCI (jobs and executors) and so on. I have an article in the pipeline on how having a good grasp of the principle of separation of concerns integrated in this modern workflow architecture can significantly help in the day to day use of the tools and their troubleshooting. Though Vertex AI is synonymous for orchestrating ML pipelines, in theory any logic such as Python script, data pipeline or any containerised application could be run on the platform. Composer, which is a managed Apache Airflow environment, was the main orchestrating platform on GCP prior to Vertex AI. The two platforms have pros and cons that should be considered when making a decision to use either.
I am going to avoid spamming this post with code which are easily accessible from the platform repository. However, I will run through the important parts of the mlops platform architecture. Please refer to the repo to follow along.
Components
The architecture of the platform revolves around a set of well-defined components housed within the components directory. These components, such as data loading, preprocessing, model training, evaluation, and deployment, provide a modular structure, allowing for easy customisation and extension. Lets look through one of the components, the preprocess_data.py, to understand the general structure of a component.
from config.config import base_image
from kfp.v2 import dsl
from kfp.v2.dsl import Dataset, Input, Output
@dsl.component(base_image=base_image)
def preprocess_data(
input_dataset: Input[Dataset],
train_dataset: Output[Dataset],
test_dataset: Output[Dataset],
train_ratio: float = 0.7,
):
"""
Preprocess data by partitioning it into training and testing sets.
"""
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv(input_dataset.path)
df = df.dropna()
if set(df.iloc[:, -1].unique()) == {'Yes', 'No'}:
df.iloc[:, -1] = df.iloc[:, -1].map({'Yes': 1, 'No': 0})
train_data, test_data = train_test_split(df, train_size=train_ratio, random_state=42)
train_data.to_csv(train_dataset.path, index=False)
test_data.to_csv(test_dataset.path, index=False)
A closer look at the script above would show a familiar data science workflow. All the script does is read in some data, split them for model development and write the splits to some path where it can be readily accessed by downstream tasks. However, since this function would be run on Vertex AI, it is decorated by a Kubeflow pipeline @dsl.component(base_image=base_image) which marks the function as a Kubeflow pipeline component to be run within the base_image container. I will talk about the base_image later. This is all is required to run a function within a container on Vertex AI. Once we structured all our other functions in similar manner and decorate them as Kubeflow pipeline components, the mlpipeline.py function will import each components to structure the pipeline.
#mlpipeline.py
from kfp.v2 import dsl, compiler
from kfp.v2.dsl import pipeline
from components.load_data import load_data
from components.preprocess_data import preprocess_data
from components.train_random_forest import train_random_forest
from components.train_decision_tree import train_decision_tree
from components.evaluate_model import evaluate_model
from components.deploy_model import deploy_model
from config.config import gcs_url, train_ratio, project_id, region, serving_image, service_account, pipeline_root
from google.cloud import aiplatform
@pipeline(
name="ml-platform-pipeline",
description="A pipeline that performs data loading, preprocessing, model training, evaluation, and deployment",
pipeline_root= pipeline_root
)
def mlplatform_pipeline(
gcs_url: str = gcs_url,
train_ratio: float = train_ratio,
):
load_data_op = load_data(gcs_url=gcs_url)
preprocess_data_op = preprocess_data(input_dataset=load_data_op.output,
train_ratio=train_ratio
)
train_rf_op = train_random_forest(train_dataset=preprocess_data_op.outputs['train_dataset'])
train_dt_op = train_decision_tree(train_dataset=preprocess_data_op.outputs['train_dataset'])
evaluate_op = evaluate_model(
test_dataset=preprocess_data_op.outputs['test_dataset'],
dt_model=train_dt_op.output,
rf_model=train_rf_op.output
)
deploy_model_op = deploy_model(
optimal_model_name=evaluate_op.outputs['optimal_model'],
project=project_id,
region=region,
serving_image=serving_image,
rf_model=train_rf_op.output,
dt_model=train_dt_op.output
)
if __name__ == "__main__":
pipeline_filename = "mlplatform_pipeline.json"
compiler.Compiler().compile(
pipeline_func=mlplatform_pipeline,
package_path=pipeline_filename
)
aiplatform.init(project=project_id, location=region)
_ = aiplatform.PipelineJob(
display_name="ml-platform-pipeline",
template_path=pipeline_filename,
parameter_values={
"gcs_url": gcs_url,
"train_ratio": train_ratio
},
enable_caching=True
).submit(service_account=service_account)
@pipeline decorator enables the function mlplatform_pipeline to be run as a pipeline. The pipeline is then compiled to the specified pipeline filename. Here, I have specified JSON configuration extension for the compiled file but I think Google is moving toYAML. The compiled file is then picked up by aiplatform and submitted to Vertex AI platform for execution.
The only other thing I found puzzling while starting out with the kubeflow pipelines are the parameters and artifacts set up so have a look to get up to speed.
Configuration
The configuration file in the config directory facilitates the adjustment of parameters and settings across different stages of the pipeline. Along with the config file, I have also included a dot.env file which has comments on the variables specifics and is meant to be a guide for the nature of the variables that are loaded into the config file.
Notebooks
I mostly start my workflow and exploration within notebooks as it enable easy interaction. As a result, I have included notebooks directory as a means of experimenting with the different components logics.
Testing
Testing plays a very important role in ensuring the robustness and reliability of machine learning workflows and pipelines. Comprehensive testing establishes a systematic approach to assess the functionality of each component and ensures that they behave as intended. This reduces the instances of errors and malfunctioning during the execution stage. I have included a test_mlpipeline.py script mostly as a guide for the testing process. It uses pytest to illustrate testing concept and provides a framework to build upon.
Project Dependencies
Managing dependencies can be a nightmare when developing enterprise scale applications. And given the myriads of packages required in a ML workflow, combined with the various software applications needed to operationalise it, it can become a Herculean task managing the dependencies in a sane manner. One package that is slowly gaining traction is Poetry. It is a tool for dependency management and packaging in Python. The key files generated by Poetry are pyproject.toml and poetry.lock. pyproject.tomlfile is a configuration file for storing project metadata and dependencies while the poetry.lock file locks the exact versions of dependencies, ensuring consistent and reproducible builds across different environments. Together, these two files enhance dependency resolution. I have demonstrated how the two files replace the use of requirement.txt within a container by using them to generate the training container image for this project.
Makefile
A Makefile is a build automation tool that facilitates the compilation and execution of a project’s tasks through a set of predefined rules. Developers commonly use Makefiles to streamline workflows, automate repetitive tasks, and ensure consistent and reproducible builds. The Makefile within mlops-platform has predefined commands to seamlessly run the entire pipeline and ensure the reliability of the components. For example, the all target, specified as the default, efficiently orchestrates the execution of both the ML pipeline (run_pipeline) and tests (run_tests). Additionally, the Makefile provides a clean target for tidying up temporary files while the help target offers a quick reference to the available commands.
Documentation
The project is documented in the README.md file, which provides a comprehensive guide to the project. It includes detailed instructions on installation, usage, and setting up Google Cloud Platform services.
Orchestration with CI/CD
GitHub Actions workflow defined in .github/workflows directory is crucial for automating the process of testing, building, and deploying the machine learning pipeline to Vertex AI. This CI/CD approach ensures that changes made to the codebase are consistently validated and deployed, enhancing the project’s reliability and reducing the likelihood of errors. The workflow triggers on each push to the main branch or can be manually executed, providing a seamless and reliable integration process.
Inference Pipeline
There are multiple ways to implement inference or prediction pipeline. I have gone the good old way here by loading in both the prediction features and the uploaded model, getting predictions from the model and writing the predictions to a BigQuery table. It is worth noting that for all the talk about prediction containers, they are not really needed if all is required is batch prediction. We might as well use the training container for our batch prediction as demonstrated in the platform. However, the prediction container is required for online prediction. I have also included modality for local testing of the batch prediction pipeline which can be generalised to test any of the other components or any scripts for that matter. Local testing can be done by navigating to batch_prediction/batch_prediction_test directory, substituting for placeholder variables and running the following commands:
# First build the image using Docker
docker build -f Dockerfile.batch -t batch_predict .
# The run batch prediction pipeline locally using the built image from above
docker run -it \
-v {/local/path/to/service_acount-key.json}:/secrets/google/key.json \
-e GOOGLE_APPLICATION_CREDENTIALS=/secrets/google/key.json \
batch_predict \
--model_gcs_path={gs://path/to/gcs/bucket/model.joblib} \
--input_data_gcs_path={gs://path/to/gcs/bucket/prediction_data.csv} \
--table_ref={project_id.dataset.table_name} \
--project={project_id}
The service account needs proper access on GCP to execute the task above, it should have permission to read from the GCP bucket and write to the BigQuery table.
Challenges and Solutions: `Jailbreaking’ Google Vertex AI prebuilt containers
Some of the challenges encountered during the building of this project emanates from the use of container images and the associated package versions within the Google prebuilt containers. I presume the main goal of Google when creating prebuilt containers is to lift off major engineering tasks for the data scientists and enable them to focus mainly on ML logics. However, more work would be required to ensure this aim is achieved as the prebuilt containers have various versions mismatch requiring significant debugging effort to resolve. I have detailed some of the challenges and some possible fixes.
- Multi-Architectural image build: While using macOS has its upsides, building container image on them to be deployed on cloud platforms might not be one of them. The main challenge is that most cloud platforms supports Linux running on amd64 architecture while latest macOS systems run on arm64 architecture. As a result, binaries compiled on macOS would ordinarily not be compatible with Linux. This means that built images that compile successfully on macOS might fail when run on most cloud platforms. And what is more, the log messages that result from this error is tacit and unhelpful, making it challenging to debug. It should be noted that this is an issue with most modern cloud platforms and not peculiar to GCP. As a result, there are multiple workarounds to overcome this challenge.
- Use BuildX: Buildx is a Docker CLI plugin that allows building a multi-architecture container image that can run on multiple platforms. Ensure Docker desktop is installed as it is required to build image locally. Alternatively, the image can be built from Google cloud shell. The following script would build a compatible container image on macOS and push it to GCP artifact registry.
# start Docker Desktop (can also open manually)
open -a Docker
# authentucate to GCP if desired to push the image to GCP artifact repo
gcloud auth login
gcloud auth configure-docker "{region}-docker.pkg.dev" --quiet
# create and use a buildx builder instance (only needed once)
docker buildx create --name mybuilder --use
docker buildx inspect --bootstrap
# build and push a multi-architecture Docker image with buildx
docker buildx build --platform linux/amd64,linux/arm64 -t "{region}-docker.pkg.dev/{project_id}/{artifact_repo}/{image-name}:latest" -f Dockerfile --push .
The name of the container follows Google specific format for naming containers.
- Set Docker environment variable : Set DOCKER_DEFAULT_PLATFORM permanently in the macOS system config file to ensure that Docker always build image compatible with Linux amd64.
# open Zsh config file (I use visual code but it could be other editor like nano)
code ~/.zshrc
# insert at the end of file
export DOCKER_DEFAULT_PLATFORM=linux/amd64
# save and close file then apply changes
source ~/.zshrc
2. Conflicting versions in prebuilt container images: Google maintains a host of prebuilt images for prediction and training tasks. These container images are available for common ML frameworks in different versions. However, I found that the documented versions sometimes don’t match the actual version and this constitute a major point of failure when using these container images. Giving what the community has gone through in standardising versions and dependencies and the fact that container technology is developed to mainly address reliable execution of applications, I think Google should strive to address the conflicting versions in the prebuilt container images. Make no mistake, battling with version mismatch can be frustrating which is why I encourage ‘jailbreaking’ the prebuilt images prior to using them. When developing this tutorial, I decided to useeurope-docker.pkg.dev/vertex-ai/training/sklearn-gpu.1-0:latest and europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest. From the naming conventions, both are supposed to be compatible and should havesklearn==1.0. In fact, this is confirmed on the site as shown in the screenshot below and also, on the container image artifact registry.
However, the reality is different. I ran into version mismatch errors when deploying the built model to an endpoint. A section of the error message is shown below.
Trying to unpickle estimator OneHotEncoder from version 1.0.2 when using version 1.0
Suprise! Suprise! Suprise! Basically, what the log says is that you have pickled with version 1.0.2 but attempting to unpickle with version 1.0. To make progress, I decided to do some ‘jailbreaking’ and looked under the hood of the prebuilt container images. It is a very basic procedure but opened many can of worms.
- From the terminal or Google cloud shell
- Pull the respective image from Google artifact registry
docker pull europe-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest
3. Run the image, overide its entrypoint command and drop onto its bash shell terminal
docker run -it --entrypoint /bin/bash europe-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest
4. Check the sklearn version
python -c "import sklearn; print(sklearn.__version__)"
The output, as of the time of writing this post, is shown in the screenshot below:
Conducting similar exercise for europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-3:latest , the sklearn version is 1.3.2 and 1.2.2 for the 1.2version. What is even more baffling is that pandas is missing from both version 1–2and 1-3 which begs the question of whether the prebuilt containers are being actively maintained. Of course, the issue is not the minor update but the fact that the corresponding prediction image did not have similar update which results in the mismatch error shown above.
When I contacted Google support to report the mismatch, the Vertex AI engineering team mentioned alternatives such as Custom prediction routines (CPR) and SklearnPredictor. And I was pointed to newer image versions with similar issues and missing pandas!
Moving on, if you are feeling like a Braveheart and want to explore further, you can access all the other files that Google runs when launching prebuilt containers by running ls command from within the container and looking through the files and folders.
Build Base Image
So having discovered the issue, what can be done in order to still take advantage of prebuilt containers? What I did was to extract all the relevant packages from the container.
pip freeze > requirement.txt
cat requirement.txt
The commands above will extract all the installed packages and print them to the container terminal. The packages can then be copied and used in creating a custom container image, ensuring that the ML framework version in both the training and prediction container matches. If you prefer to copy the file content to your local directory then use the following command:
# If on local terminal, copy requirements.txt into current directory
docker cp {running-container}:/requirements.txt .
Some of the packages in the prebuilt containers would not be needed for individual project so it is better to select the ones that matches your workflow. The most important one to lock down is the ML framework version whether it is sklearn or xgboost, making sure both training and prediction versions match.
I have basically locked the sklearn version to match the version of the prebuilt prediction image. In this case, it is version 1.0 and I have left all the other packages as they are.
Then to build the custom training image, use the following commands:
# commands to build the docker
#first authenticate to gcloud
# gcloud auth login
gcloud auth configure-docker
# Build the image using Docker
docker build -f docker/Dockerfile.poetry -t {region}-docker.pkg.dev/{gcp-project-id}/{gcp-artifact-repo}/{image-name}:latest .
The above is saying is:
- docker: hey Docker!
- build: build an image for me
- -f: use the following file
- -t: tag (or name) it the following
- . : use files in this directory (current directory in this case) if needed
Then the built image can be pushed to the artifact registry as follows:
# Push to artifact registry
docker push {region}-docker.pkg.dev/{gcp-project-id}/{gcp-artifact-repo}/{image-name}:latest
Vision
There are numerous extensions to be added to this project and I will invite willing contributors to actively pick on any of them. Some of my thoughts are detailed below but feel free to suggest any other improvements. Contributions are welcomed via PR. I hope the repo can be actively developed by those who wants to learn end to end MLOps as well as serve as a base on which small teams can build upon.
- Monitoring pipeline: Observability is integral to MLOps platform. It enables team to proactively monitors the state and behaviour of their platform and take appropriate action in the event of an anomaly. The mlops-platform is missing a monitoring pipeline and it would be a good addition. I plan to write on custom implementation of monitoring pipeline but in the mean time, Vertex AI has monitoring pipeline that can be integrated.
- Inference pipeline: Vertex AI has batch prediction method that could be integrated. An argument can be put forward on whether the current custom batch prediction in the mlops platform would scale. The main issue is that the prediction features are loaded into the predicting environment which might run into memory issue with very large dataset. I havent experienced this issue previously but it can be envisaged. Prior to Google rebranding aiplatform to Vertex AI, I have always deployed models to the aiplatform to benefit from its model versioning but would run the batch prediction pipeline within Composer. I prefer this approach as it gives flexibility in terms of pre and post processing. Moreover, Google batch prediction method is fiddly and tricky to debug when things go wrong. Nevertheless, I think it will improve with time so would be a good addition to the platform.
- Refactoring: While I have coupled together computing and logic code in the implementation on same file, I think it would be cleaner if they are separated. Decoupling both would improve the modularity of the code and enable reusability. In addition, there should be a pipeline directory for the different pipeline files with potential integration of monitoring pipeline.
- Full customisation: Containers should be fully customised in order to have fine-grained control and flexibility. This means having both training and prediction containers custom built.
- Testing: I have integrated a testing framework which runs successfully within the platform but it is not a functional test logic. It does provide a framework to build proper tests covering data quality, components and pipelines functional tests.
- Containerisation integration: The creation of the container base image is done manually at the moment but should be integrated in both the makefile and GitHub action workflow.
- Documentation: The documentation would need updating to reflect additional features being added and ensure people with different skill sets can easily navigate through the platform. Please update the READ.me file for now but this project should use Sphinx in the long run.
- Pre-commit hooks: This is an important automation tool that can be employed to good use. Pre-commit hooks are configuration scripts executed prior to actioning a commit to help enforce styles and policy. For example, the hooks in the platform enforced linting and prevent committing large files as well as committing to the main branch. However, my main thought was to use it for dynamically updating GitHub secrets from the values in .env file. The GitHub secrets are statically typed in the current implementation so when certain variables change, they don’t get automatically propagated to GitHub secrets. Similar thing would occur when new variables are added which then needs to be manually propagated to GitHub. Pre-commit can be used to address this problem by instructing it to automatically propagate changes in the local .envfile to GitHub secrets.
- Infrastructure provisioning: Artifact registry, GCP bucket, BigQuery table and service account are all provisioned manually but their creation should be automated via Terraform.
- Scheduler: If this is a batch prediction or continuous training pipeline, we would want to schedule it to run at some specified time and frequency. Vertex AI gives a number of options to configure schedules. Indeed, an orchestration platform would not be complete without this feature.
- Additional models: There are two models (Random forest and Decision trees) within the platfrom now but should be straightforward adding other frameworks, such as xgboost and light GBM, for modelling tabular data.
- Security: The GitHub action uses service account for authentication to GCP services but should ideally be using workflow identity federation.
- Distribution: The platform is suitable in the current state for educational purpose and perhaps individual projects. However, it would require adaptation for bigger team. Think about individuals that make up teams with different skill set and varying challenges. In this regard, the platform interface can be improved using click as detailed in this post. Afterwards, it can be packaged and distributed to ensure easy installation. Also, distribution enables us to make changes to the package and centralise its updates so that it propagates as needed. Poetry can be used for the packaging and distribution so using it for dependency management has laid a good foundation.
Summary
The MLOps platform provides a modular and scalable pipeline architecture for implementing different ML lifecycle stages. It includes various operations that enable such platform to work seamlessly. Most importantly, it provides a learning opportunity for would be contributors and should serve as a good base on which teams can build upon in their machine learning tasks.
Conclusion
Well, that is it people! Congratulations and well done if you are able to make it here. I hope you have benefited from this post. Your comments and feedback are most welcome and please lets connect on Linkedln. If you found this to be valuable, then don’t forget to like the post and give the MLOps platform repository a star.
References
MLOps repo: https://github.com/kbakande/mlops-platform
https://medium.com/google-cloud/machine-learning-pipeline-development-on-google-cloud-5cba36819058
https://datatonic.com/insights/vertex-ai-improving-debugging-batch-prediction/
https://econ-project-templates.readthedocs.io/en/v0.5.2/pre-commit.html
Extensible and Customisable Vertex AI MLOps Platform was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.