
Feature Selection with Boruta in Python | by Andrew D #datascience
Learn how the Boruta algorithm works for feature selection. Explanation + template
The feature selection process is fundamental in any machine learning project. In this post we’ll go through the Boruta algorithm, which allows us to create a ranking of our features, from the most important to the least impacting for our model. Boruta is simple to use and a powerful technique that analysts should incorporate in their pipeline.
Boruta is not a stand-alone algorithm: it sits on top of the Random Forest algorithm. In fact, the name Boruta comes from the name of the spirit of the forest in Slavic mythology. To understand how the algorithm works we’ll make a brief introduction to Random Forest.
Random Forest is based on the concept of bagging — which is about creating many random samples from the training set and training a different statistical model for each one. For a classification task the result is the majority of votes from the models, while for a regression task the result is the average of the various models.
The difference between canonical bagging and Random Forest is that the latter always uses only decision trees models. For each sample considered, the decision tree takes into account a limited set of features. This allows the Random Forest algorithm to be able to estimate the importance of each feature, since it stores the error in the predictions based on the split of features considered.
Let’s consider a classification task. The way RF estimates feature importance works in two phases. First, each decision tree creates and stores a prediction. Second, the values of certain features are randomly permuted through the various training samples and the previous step is repeated, tracing the result of the predictions again. The importance of a feature of a single decision tree is calculated as the difference in performance between the model using the original features versus the model using the permuted features divided by the number of examples in the training set. The importance of a feature is the average of the measurements across all trees for that feature. What is not done during this procedure is to calculate the z-scores for each feature. This is where Boruta comes into play.
The idea underlying Boruta is both fascinating and simple at the same time: for all the features in the original dataset, we are going to create random copies of them (called shadow features) and train classifiers based on this extended dataset. To understand the importance of a feature, we compare it to all the generated shadow features. Only features that are statistically more important than these synthetic features are retained as they contribute more to model performance. Let’s see the steps in a bit more detail.
- Creates a copy of the training set features and merges them with the original features
- Creates random permutations on these synthetic features to remove any kind of correlation between them and the target variable y — basically, these synthetic features are randomized combinations of the original feature from which they derive
- Synthetic features are randomized at each new iteration
- At each new iteration, computes the z-score of all original and synthetic features. A feature is considered relevant if its importance is higher than the maximum importance of all synthetic features
- Applies a statistical test on all original features and keeps memory of its results. The null hypothesis is that the importance of a feature is equal to the maximal importance of synthetic features. The statistical test tests the equality between the original and synthetic features. The null hypothesis is rejected when the importance of a feature is significantly higher or lower than one of those of synthetic features
- Removes features that are considered unimportant from both the original and synthetic dataset
- Repeat all the steps for an n number of iterations until all features are removed or considered important
It should be noted that Boruta acts as an heuristic: there are no guarantees of its performance. It is therefore advisable to run the process several times and evaluate the results iteratively.
Let’s see how Boruta works in Python with its dedicated library. We will use Sklearn.datasets’ load_diabetes() dataset to test Boruta on a regression problem.
The feature set X is made up of the variables
- age (in years)
- sex
- bmi (body mass index)
- bp (mean blood pressure)
- s1 (tc, total cholesterol)
- s2 (ldl, low-density lipoproteins)
- s3 (hdl, high-density lipoproteins)
- s4 (tch, total / HDL cholesterol)
- s5 (ltg, log of the triglyceride level)
- s6 (glu, blood sugar level)
target y is the progression of diabetes recorded over time.
By running the script we will see in the terminal how Boruta is building its inferences

The report is also very readable
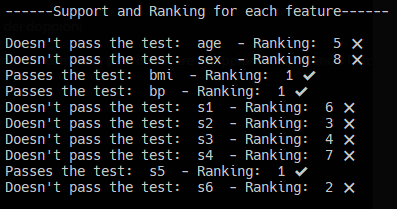
According to Boruta, bmi, bp, s5 and s6 are the features that contribute the most to building our predictive model. To filter our dataset and select only the features that are important for Boruta we use feat_selector.transform(np.array (X)) which will return a Numpy array.
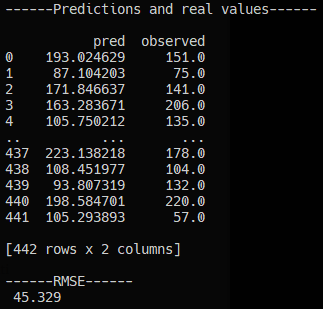
We are now ready to provide our RandomForestRegressor model with a selected set of X features. We train the model and print the Root Mean Squared Error (RMSE).
Here are the training results
Boruta is a powerful yet simple feature selection algorithm that has found wide use and appreciation online, especially on Kaggle. Its effectiveness and ease of interpretation is what adds value to a data scientist’s toolkit, as it extends from the famous decision / random forest algorithms.
Give it a try and enjoy a higher performing model that takes in a bit more signal than noise 😉
If you want to support my content creation activity, feel free to follow my referral link below and join Medium’s membership program. I will receive a portion of your investment and you’ll be able to access Medium’s plethora of articles on data science and more in a seamless way.
Here’s the copy-paste version of the entire code presented in this post.
Learn how the Boruta algorithm works for feature selection. Explanation + template

The feature selection process is fundamental in any machine learning project. In this post we’ll go through the Boruta algorithm, which allows us to create a ranking of our features, from the most important to the least impacting for our model. Boruta is simple to use and a powerful technique that analysts should incorporate in their pipeline.
Boruta is not a stand-alone algorithm: it sits on top of the Random Forest algorithm. In fact, the name Boruta comes from the name of the spirit of the forest in Slavic mythology. To understand how the algorithm works we’ll make a brief introduction to Random Forest.
Random Forest is based on the concept of bagging — which is about creating many random samples from the training set and training a different statistical model for each one. For a classification task the result is the majority of votes from the models, while for a regression task the result is the average of the various models.
The difference between canonical bagging and Random Forest is that the latter always uses only decision trees models. For each sample considered, the decision tree takes into account a limited set of features. This allows the Random Forest algorithm to be able to estimate the importance of each feature, since it stores the error in the predictions based on the split of features considered.
Let’s consider a classification task. The way RF estimates feature importance works in two phases. First, each decision tree creates and stores a prediction. Second, the values of certain features are randomly permuted through the various training samples and the previous step is repeated, tracing the result of the predictions again. The importance of a feature of a single decision tree is calculated as the difference in performance between the model using the original features versus the model using the permuted features divided by the number of examples in the training set. The importance of a feature is the average of the measurements across all trees for that feature. What is not done during this procedure is to calculate the z-scores for each feature. This is where Boruta comes into play.
The idea underlying Boruta is both fascinating and simple at the same time: for all the features in the original dataset, we are going to create random copies of them (called shadow features) and train classifiers based on this extended dataset. To understand the importance of a feature, we compare it to all the generated shadow features. Only features that are statistically more important than these synthetic features are retained as they contribute more to model performance. Let’s see the steps in a bit more detail.
- Creates a copy of the training set features and merges them with the original features
- Creates random permutations on these synthetic features to remove any kind of correlation between them and the target variable y — basically, these synthetic features are randomized combinations of the original feature from which they derive
- Synthetic features are randomized at each new iteration
- At each new iteration, computes the z-score of all original and synthetic features. A feature is considered relevant if its importance is higher than the maximum importance of all synthetic features
- Applies a statistical test on all original features and keeps memory of its results. The null hypothesis is that the importance of a feature is equal to the maximal importance of synthetic features. The statistical test tests the equality between the original and synthetic features. The null hypothesis is rejected when the importance of a feature is significantly higher or lower than one of those of synthetic features
- Removes features that are considered unimportant from both the original and synthetic dataset
- Repeat all the steps for an n number of iterations until all features are removed or considered important
It should be noted that Boruta acts as an heuristic: there are no guarantees of its performance. It is therefore advisable to run the process several times and evaluate the results iteratively.
Let’s see how Boruta works in Python with its dedicated library. We will use Sklearn.datasets’ load_diabetes() dataset to test Boruta on a regression problem.
The feature set X is made up of the variables
- age (in years)
- sex
- bmi (body mass index)
- bp (mean blood pressure)
- s1 (tc, total cholesterol)
- s2 (ldl, low-density lipoproteins)
- s3 (hdl, high-density lipoproteins)
- s4 (tch, total / HDL cholesterol)
- s5 (ltg, log of the triglyceride level)
- s6 (glu, blood sugar level)
target y is the progression of diabetes recorded over time.
By running the script we will see in the terminal how Boruta is building its inferences
The report is also very readable
According to Boruta, bmi, bp, s5 and s6 are the features that contribute the most to building our predictive model. To filter our dataset and select only the features that are important for Boruta we use feat_selector.transform(np.array (X)) which will return a Numpy array.
We are now ready to provide our RandomForestRegressor model with a selected set of X features. We train the model and print the Root Mean Squared Error (RMSE).
Here are the training results
Boruta is a powerful yet simple feature selection algorithm that has found wide use and appreciation online, especially on Kaggle. Its effectiveness and ease of interpretation is what adds value to a data scientist’s toolkit, as it extends from the famous decision / random forest algorithms.
Give it a try and enjoy a higher performing model that takes in a bit more signal than noise 😉
If you want to support my content creation activity, feel free to follow my referral link below and join Medium’s membership program. I will receive a portion of your investment and you’ll be able to access Medium’s plethora of articles on data science and more in a seamless way.
Here’s the copy-paste version of the entire code presented in this post.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.