
Getting Started with the Polars DataFrame Library | by Wei-Meng Lee | Jul, 2022
Learn how to manipulate tabular data using the Polars dataframe library (and replace Pandas)
Most Data Scientists/Analysts using Python are familiar with Pandas. And if you are in the data science field, you probably have invested quite a significant amount of time learning how to use them to manipulate your data. However, one of the main complains about Pandas is its speed and inefficiencies when dealing with large datasets. Fortunately, there is a new dataframe library that attempts to address this main complain about Pandas — Polars.
Polars is a DataFrame library that is completly written in Rust. In this article, I will walk you through the basics of Polars and how it can be used in place of Pandas. In subsequent articles, I will dive into the details of the various features of Polars.
The best way to understand Polars is that it is a better dataframe library than Pandas. Here are some advantages of Polars over Pandas:
- Polars does not use an index for the dataframe. Eliminating the index makes it much easier to manipulate the dataframe (the index is mostly redundant in Pandas dataframe anyway).
- Polars represents data internally using Apache Arrow arrays while Pandas stores data internally using NumPy arrays. Apache Arrow arrays is much more efficient in areas like load time, memory usage, and computation.
- Polars supports more parallel operations than Pandas. As Polars is written in Rust, it can run many operations in parallel.
- Polars supports lazy evaluation. Based on your query, Polars will examine your queries, optimize them, and look for ways to accelerate the query or reduce memory usage. Pandas, on the other hand, support only eager evaluation, which immediately evaluates an expression as soon as it encounters one.
To install Polars, you can simply use the pip command:
pip install polars
Or, use the conda command:
conda install polars
For this article, I am going to assume that you have Anaconda installed and that you are familiar with Jupyter Notebook.
The best way to learn a new library is to get your hands dirty. So let’s get started by importing the polars module and creating a Polars Dataframe:
import polars as pldf = pl.DataFrame(
{
'Model': ['iPhone X','iPhone XS','iPhone 12',
'iPhone 13','Samsung S11','Samsung S12',
'Mi A1','Mi A2'],
'Sales': [80,170,130,205,400,30,14,8],
'Company': ['Apple','Apple','Apple','Apple',
'Samsung','Samsung','Xiao Mi','Xiao Mi'],
}
)
df
Like Pandas, Polars pretty-print the dataframe when it is displayed in Jupyter Notebook:

Polars expects the column header names to be of string type. Consider the following example:
df2 = pl.DataFrame(
{
0 : [1,2,3],
1 : [80,170,130],
}
)
The above code snippet will not work as the keys in the dictionary are of type integer (0 and 1). To make it work, you need to make sure the keys are of string type (“0” and “1”):
import polars as pl
df2 = pl.DataFrame(
{
"0" : [1,2,3],
"1" : [80,170,130],
}
)
Besides displaying the header name for each column, Polars also display the data type of each column. If you want to explicitly display the data type of each column, use the dtypes properties:
df.dtypes
For the above example, you will see the following output:
[polars.datatypes.Utf8,
polars.datatypes.Int64,
polars.datatypes.Utf8]
To get the column names, use the columns property:
df.columns # ['Model', 'Sales', 'Company']
To get the content of the dataframe as a list of tuples, use the rows() method:
df.rows()
For the above example, you will see the following output:
[('iPhone X', 80, 'Apple'),
('iPhone XS', 170, 'Apple'),
('iPhone 12', 130, 'Apple'),
('iPhone 13', 205, 'Apple'),
('Samsung S11', 400, 'Samsung'),
('Samsung S12', 30, 'Samsung'),
('Mi A1', 14, 'Xiao Mi'),
('Mi A2', 8, 'Xiao Mi')]
Polars does not have the concept of index, unlike Pandas. The design philosophy of Polars explicitly states that index is not useful in dataframes.
Selecting column(s) in Polars is straight-forward — simply specify the column name using the select() method:
df.select(
'Model'
)
The above statement returns a Polars DataFrame containing the Model column:

Polars also support the square bracket indexing method, the method that most Pandas developers are familiar with. However, the documentation for Polars specifically mentioned that the square bracket indexing method is an anti-pattern for Polars. While you can do the above using
df[:,[0]], there is a possibility that the square bracket indexing method may be removed in a future version of Polars.
If you want multiple columns, supply the column names as a list:
df.select(
['Model','Company']
)

If you want to retrieve all the integer (specifically Int64) columns in the dataframe, you can use an expression within the select() method:
df.select(
pl.col(pl.Int64)
)
The statement pl.col(pl.Int64) is known as an expression in Polars. This expression is interpreted as “get me all the columns whose data type is Int64”. The above code snippet produces the following output:

Expressions are very powerful in Polars. For example, you can pipe together expressions, like this:
df.select(
pl.col(['Model','Sales']).sort_by('Sales')
)
The above expression selects the Model and Sales columns, and then sort the rows based on the values in the Sales column:

If you want multiple columns, you can enclose your expression in a list:
df.select(
[pl.col(pl.Int64),'Company']
)

If you want to get all the string-type columns, use the pl.Utf8 property:
df.select(
[pl.col(pl.Utf8)]
)

I will talk more about expressions in a future article.
To select a single row in a dataframe, pass in the row number using the row() method:
df.row(0) # get the first row
The result is a tuple:
('iPhone X', 80, 'Apple')
If you need to get multiple rows based on row numbers, you need to use the square bracket indexing method, although it is not the recommended way to do in Polars. Here are some examples:
df[:2]# first 2 rowsdf[[1,3]] # second and fourth row
To select multiple rows, Polars recommends using the filter() function. For example, if you want to retrieve all Apple’s products, you can use the following expression:
df.filter(
pl.col('Company') == 'Apple'
)

You can also specify multiple conditions using the logical operator:
df.filter(
(pl.col('Company') == 'Apple') |
(pl.col('Company') == 'Samsung')
)

You can use the following logical operators in Polars:
|— OR
&— AND
~— Not
Very often, you need to select rows and columns at the same time. You can do so by chaining the filter() and select() methods, like this:
df.filter(
pl.col('Company') == 'Apple'
).select('Model')
The above statement selects all the rows containing Apple and then only shows the Model column:
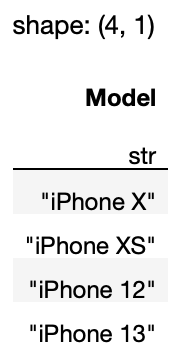
If you also want to display the Sales column, pass in a list to the select() method:
df.filter(
pl.col('Company') == 'Apple'
).select(['Model','Sales'])
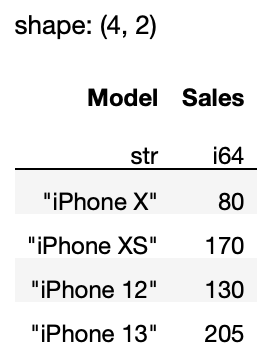
In this article, I have shown you the basics of the Polars DataFrame. You have learned the basics of extracting rows and columns and the use of the select() and filter() methods. Here is a quick summary of when to use them:

Learn how to manipulate tabular data using the Polars dataframe library (and replace Pandas)
Most Data Scientists/Analysts using Python are familiar with Pandas. And if you are in the data science field, you probably have invested quite a significant amount of time learning how to use them to manipulate your data. However, one of the main complains about Pandas is its speed and inefficiencies when dealing with large datasets. Fortunately, there is a new dataframe library that attempts to address this main complain about Pandas — Polars.
Polars is a DataFrame library that is completly written in Rust. In this article, I will walk you through the basics of Polars and how it can be used in place of Pandas. In subsequent articles, I will dive into the details of the various features of Polars.
The best way to understand Polars is that it is a better dataframe library than Pandas. Here are some advantages of Polars over Pandas:
- Polars does not use an index for the dataframe. Eliminating the index makes it much easier to manipulate the dataframe (the index is mostly redundant in Pandas dataframe anyway).
- Polars represents data internally using Apache Arrow arrays while Pandas stores data internally using NumPy arrays. Apache Arrow arrays is much more efficient in areas like load time, memory usage, and computation.
- Polars supports more parallel operations than Pandas. As Polars is written in Rust, it can run many operations in parallel.
- Polars supports lazy evaluation. Based on your query, Polars will examine your queries, optimize them, and look for ways to accelerate the query or reduce memory usage. Pandas, on the other hand, support only eager evaluation, which immediately evaluates an expression as soon as it encounters one.
To install Polars, you can simply use the pip command:
pip install polars
Or, use the conda command:
conda install polars
For this article, I am going to assume that you have Anaconda installed and that you are familiar with Jupyter Notebook.
The best way to learn a new library is to get your hands dirty. So let’s get started by importing the polars module and creating a Polars Dataframe:
import polars as pldf = pl.DataFrame(
{
'Model': ['iPhone X','iPhone XS','iPhone 12',
'iPhone 13','Samsung S11','Samsung S12',
'Mi A1','Mi A2'],
'Sales': [80,170,130,205,400,30,14,8],
'Company': ['Apple','Apple','Apple','Apple',
'Samsung','Samsung','Xiao Mi','Xiao Mi'],
}
)
df
Like Pandas, Polars pretty-print the dataframe when it is displayed in Jupyter Notebook:
Polars expects the column header names to be of string type. Consider the following example:
df2 = pl.DataFrame(
{
0 : [1,2,3],
1 : [80,170,130],
}
)
The above code snippet will not work as the keys in the dictionary are of type integer (0 and 1). To make it work, you need to make sure the keys are of string type (“0” and “1”):
import polars as pl
df2 = pl.DataFrame(
{
"0" : [1,2,3],
"1" : [80,170,130],
}
)
Besides displaying the header name for each column, Polars also display the data type of each column. If you want to explicitly display the data type of each column, use the dtypes properties:
df.dtypes
For the above example, you will see the following output:
[polars.datatypes.Utf8,
polars.datatypes.Int64,
polars.datatypes.Utf8]
To get the column names, use the columns property:
df.columns # ['Model', 'Sales', 'Company']
To get the content of the dataframe as a list of tuples, use the rows() method:
df.rows()
For the above example, you will see the following output:
[('iPhone X', 80, 'Apple'),
('iPhone XS', 170, 'Apple'),
('iPhone 12', 130, 'Apple'),
('iPhone 13', 205, 'Apple'),
('Samsung S11', 400, 'Samsung'),
('Samsung S12', 30, 'Samsung'),
('Mi A1', 14, 'Xiao Mi'),
('Mi A2', 8, 'Xiao Mi')]
Polars does not have the concept of index, unlike Pandas. The design philosophy of Polars explicitly states that index is not useful in dataframes.
Selecting column(s) in Polars is straight-forward — simply specify the column name using the select() method:
df.select(
'Model'
)
The above statement returns a Polars DataFrame containing the Model column:
Polars also support the square bracket indexing method, the method that most Pandas developers are familiar with. However, the documentation for Polars specifically mentioned that the square bracket indexing method is an anti-pattern for Polars. While you can do the above using
df[:,[0]], there is a possibility that the square bracket indexing method may be removed in a future version of Polars.
If you want multiple columns, supply the column names as a list:
df.select(
['Model','Company']
)
If you want to retrieve all the integer (specifically Int64) columns in the dataframe, you can use an expression within the select() method:
df.select(
pl.col(pl.Int64)
)
The statement pl.col(pl.Int64) is known as an expression in Polars. This expression is interpreted as “get me all the columns whose data type is Int64”. The above code snippet produces the following output:
Expressions are very powerful in Polars. For example, you can pipe together expressions, like this:
df.select(
pl.col(['Model','Sales']).sort_by('Sales')
)
The above expression selects the Model and Sales columns, and then sort the rows based on the values in the Sales column:
If you want multiple columns, you can enclose your expression in a list:
df.select(
[pl.col(pl.Int64),'Company']
)
If you want to get all the string-type columns, use the pl.Utf8 property:
df.select(
[pl.col(pl.Utf8)]
)
I will talk more about expressions in a future article.
To select a single row in a dataframe, pass in the row number using the row() method:
df.row(0) # get the first row
The result is a tuple:
('iPhone X', 80, 'Apple')
If you need to get multiple rows based on row numbers, you need to use the square bracket indexing method, although it is not the recommended way to do in Polars. Here are some examples:
df[:2]# first 2 rowsdf[[1,3]] # second and fourth row
To select multiple rows, Polars recommends using the filter() function. For example, if you want to retrieve all Apple’s products, you can use the following expression:
df.filter(
pl.col('Company') == 'Apple'
)
You can also specify multiple conditions using the logical operator:
df.filter(
(pl.col('Company') == 'Apple') |
(pl.col('Company') == 'Samsung')
)
You can use the following logical operators in Polars:
|— OR
&— AND
~— Not
Very often, you need to select rows and columns at the same time. You can do so by chaining the filter() and select() methods, like this:
df.filter(
pl.col('Company') == 'Apple'
).select('Model')
The above statement selects all the rows containing Apple and then only shows the Model column:
If you also want to display the Sales column, pass in a list to the select() method:
df.filter(
pl.col('Company') == 'Apple'
).select(['Model','Sales'])
In this article, I have shown you the basics of the Polars DataFrame. You have learned the basics of extracting rows and columns and the use of the select() and filter() methods. Here is a quick summary of when to use them:
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.