
How To Read Multiple CSV Files Non-Iteratively (and Without Pandas) | by Avi Chawla | May, 2022
Say no to Pandas’ Read CSV method!
One major caveat of Pandas is its inability to expand to multiple CPU cores (usually). Essentially, when you run any operation, where ideally parallelization is possible, Pandas would still stick to the traditional single-core execution and the other cores would sit idle. This gets especially concerning when you are building large-scale applications.
Working with large-scale data-driven applications demands faster execution through optimized algorithms and eliminating/reducing the run-time in every possible bit of the pipeline. One such area, which is often overlooked in my opinion, is optimizing the input-output operations.
Imagine you have 100s of CSV files that you need to read into your python environment. Undoubtedly, your first choice would be Pandas. On a side note, even if you are not dealing with numerous CSV files, I always recommend doing away with all the CSV files and converting them to relatively faster and storage-efficient alternatives like Pickle, Feather, or Parquet.
If even you are bound to use CSVs, I personally never recommend using the CSV read and write functions available in Pandas, the answer to which you can find in my post below.
So returning to our scenario of 100s of CSV files, here, a naive approach to reading multiple CSV files could be to iterate over them in a loop, obtain a list of Pandas DataFrames and concatenate the list into a single DataFrame. This is demonstrated below.
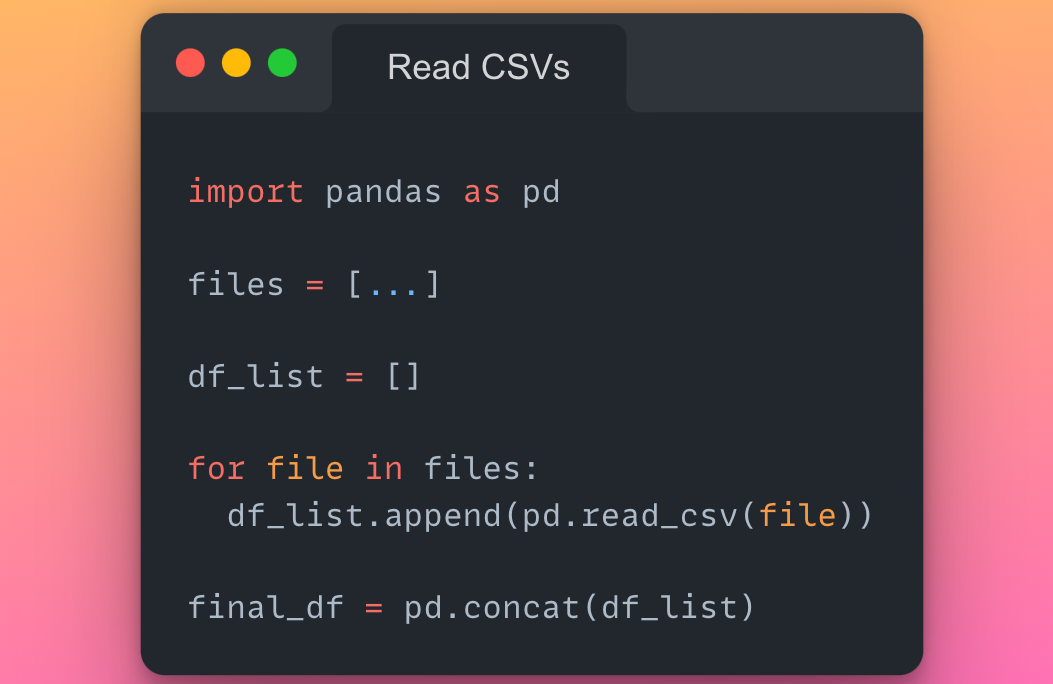
However, there are a few issues with this approach:
- The loop inevitably introduces an iterative process, i.e., only one CSV file can be read at once — leading to an under-utilization of resources.
- The Pandas read-csv method itself is a serialized process.
This post aims to address both of the above-mentioned issues associated with Pandas with respect to reading multiple CSV files, and we will be exploring DataTable in this post.
Datatable is a python library for manipulating tabular data. It supports out-of-memory datasets, multi-threaded data processing, and flexible API.
The code snippet below demonstrates how to read multiple CSV files using DataTable.

- For experimentation purposes, I generated ten different and random CSV files in Python with 0.1 million rows each and thirty columns — encompassing string, float, and integer data types.
- I repeated the experiment described below five times to reduce randomness and draw fair conclusions from the observed results. The figures I report below are averages across the five experiments.
- Python environment and libraries:
- Python 3.9.12
- Pandas 1.4.2
- DataTable 1.0.0
The plot below depicts the time taken (in seconds) by Pandas and DataTable to read ten CSV files and generate a single Pandas DataFrame.
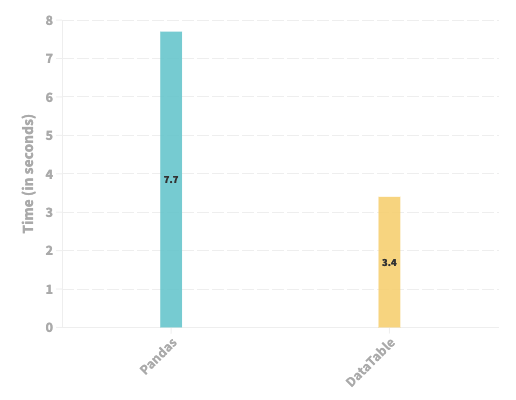
- Experimental results suggest that DataTable can provide speed-ups of over two times compared to Pandas for reading CSV files.
- In contrast to Pandas, these results also serve as an evidence for the multi-threaded approach adopted by DataTable.
I am not a big fan of CSVs, to be honest. If you thoroughly read my earlier posts (which I linked above) and the post you are reading right now, you might also resonate with me. Since I discovered the numerous issues associated with CSVs, I have stopped using them as much as possible.
To conclude, I would say that unless you need to view your DataFrame outside a non-pythonic environment such as Excel, YOU DON’T NEED A CSV AT ALL. Prefer formats like Parquet, Feather, or Pickle to store your DataFrames to. Still, if you see no other options, at least optimize your input and output operations by leveraging DataTable instead of Pandas.
Say no to Pandas’ Read CSV method!
One major caveat of Pandas is its inability to expand to multiple CPU cores (usually). Essentially, when you run any operation, where ideally parallelization is possible, Pandas would still stick to the traditional single-core execution and the other cores would sit idle. This gets especially concerning when you are building large-scale applications.
Working with large-scale data-driven applications demands faster execution through optimized algorithms and eliminating/reducing the run-time in every possible bit of the pipeline. One such area, which is often overlooked in my opinion, is optimizing the input-output operations.
Imagine you have 100s of CSV files that you need to read into your python environment. Undoubtedly, your first choice would be Pandas. On a side note, even if you are not dealing with numerous CSV files, I always recommend doing away with all the CSV files and converting them to relatively faster and storage-efficient alternatives like Pickle, Feather, or Parquet.
If even you are bound to use CSVs, I personally never recommend using the CSV read and write functions available in Pandas, the answer to which you can find in my post below.
So returning to our scenario of 100s of CSV files, here, a naive approach to reading multiple CSV files could be to iterate over them in a loop, obtain a list of Pandas DataFrames and concatenate the list into a single DataFrame. This is demonstrated below.
However, there are a few issues with this approach:
- The loop inevitably introduces an iterative process, i.e., only one CSV file can be read at once — leading to an under-utilization of resources.
- The Pandas read-csv method itself is a serialized process.
This post aims to address both of the above-mentioned issues associated with Pandas with respect to reading multiple CSV files, and we will be exploring DataTable in this post.
Datatable is a python library for manipulating tabular data. It supports out-of-memory datasets, multi-threaded data processing, and flexible API.
The code snippet below demonstrates how to read multiple CSV files using DataTable.
- For experimentation purposes, I generated ten different and random CSV files in Python with 0.1 million rows each and thirty columns — encompassing string, float, and integer data types.
- I repeated the experiment described below five times to reduce randomness and draw fair conclusions from the observed results. The figures I report below are averages across the five experiments.
- Python environment and libraries:
- Python 3.9.12
- Pandas 1.4.2
- DataTable 1.0.0
The plot below depicts the time taken (in seconds) by Pandas and DataTable to read ten CSV files and generate a single Pandas DataFrame.
- Experimental results suggest that DataTable can provide speed-ups of over two times compared to Pandas for reading CSV files.
- In contrast to Pandas, these results also serve as an evidence for the multi-threaded approach adopted by DataTable.
I am not a big fan of CSVs, to be honest. If you thoroughly read my earlier posts (which I linked above) and the post you are reading right now, you might also resonate with me. Since I discovered the numerous issues associated with CSVs, I have stopped using them as much as possible.
To conclude, I would say that unless you need to view your DataFrame outside a non-pythonic environment such as Excel, YOU DON’T NEED A CSV AT ALL. Prefer formats like Parquet, Feather, or Pickle to store your DataFrames to. Still, if you see no other options, at least optimize your input and output operations by leveraging DataTable instead of Pandas.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.