
How to Use GROUP BY Clause in SQL
Data Science
Easy to complex SQL GROUP BY use-cases, in under 10 minutes
GROUP BY in SQL, Explained
SQL — Structured Query Language — is widely used tool to extract the data from relational database and transform it.
Data transformation is incomplete without data aggregation, which is important concept in SQL. And data aggregation is impossible without GROUP BY! Therefore, it is important to master GROUP BY to easily perform all types of data transformations and aggregations.
In SQL, GROUP BY is used for data aggregation, using aggregate functions. such as SUM(), MIN(), MAX(), AVG() and COUNT() .
But, why are aggregation function used in conjunction with GROUP BY?
In SQL, a GROUP BY clause is used to group the rows together. So when you use aggregate function on a column, the result describes the data for that specific group of rows.
In this article, I am explaining 5 examples of using GROUP BY clause in SQL query which will help you to use GROUP BY without any struggle.
I kept this article pretty short, so that you can finish it quickly and master one of the important concepts in SQL.
You can quickly navigate to your favorite part using this index.
· GROUP BY with Aggregate Functions
· GROUP BY without Aggregate Functions
· GROUP BY with HAVING
· GROUP BY with ORDER BY
· GROUP BY with WHERE, HAVING and ORDER BY
📍 Note: I’m using SQLite DB Browser and a self created Sales Data created using Faker . You can get it on my Github repo for free under the MIT License!
It is a simple 9999 x 11 dataset as below.

Okay, here we go…
Well, before going ahead, always remember below one rule of GROUP BY..
When you use GROUP BY in your SQL query, then each column in SELECT statement must be either present in GROUP BY clause or occur as parameter in an aggregated function.
Now, let’s start with the simplest use-case.
This is the most commonly used scenario, where you apply aggregate function on one or more columns. As mentioned above, GROUP BY simply groups the rows together which have similar values in the columns specified in it.
For an instance, suppose, you want get statistical summary of unit price by each product category. This example specifically explains how to use all the aggregate functions.
You can get such statistical summary using the query —
SELECT Product_Category,
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category

As you see in the above query, you used two columns — Product_Category and UnitPrice — And the later is always used in a aggregate functions. Therefore, GROUP BY clause contains only one remaining column.
You can notice, the first record in Product_Category is NULL, which means GROUP BY combined all the NULL values in Product_Category in single group. This aligns with the SQL standard as specified by Microsoft —
“If a grouping column contains NULL values, all NULL values are considered equal and they are collected into a single group.”
Also, by default, the result table is ordered in Ascending order of the columns in GROUP BY with NULL (if present) at the top. If you don’t want NULL to be part of your result table, you can anytime use COALESCE function and give a meaningful name for NULL, as shown below.
SELECT COALESCE(Product_Category,'Undefined_Category') AS Product_Category,
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category
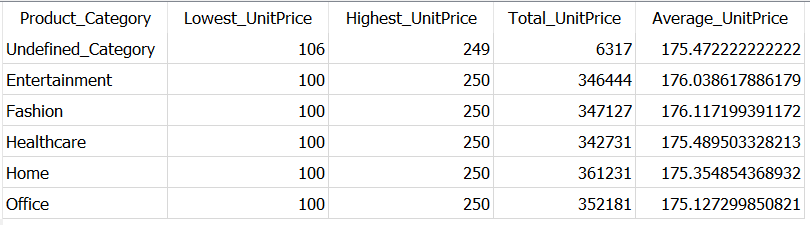
🚩 An important point to note here —
Although
COALESCEis applied on Product_Category column, you are not actually aggregating values from this column. So, it must be the part of GROUP BY.
In this way, you can add as many columns you need in the SELECT statement, apply aggregate function on some or all columns and mention the remaining column names in the GROUP BY clause, to get the desired results.
Well, this was about using GROUP BY along with aggregation function. But, you can also use this clause without aggregate functions, as explained further.
Although most of the times GROUP BY is used along with aggregate functions, it can still still used without aggregate functions — to find unique records.
For example, suppose you want to retrieve all the unique combinations of Sales_Manager and Product_Category. Using GROUP BY, this is extremely simple. All you need to do is, mention all the column names in GROUP BY which you mention in the SELECT, as shown below.
SELECT Product_Category,
Sales_Manager
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager

At this point, some might argue that, the same results can be obtained using DISTINCT keyword before column names.
However, here are the two main reasons why you should choose GROUP BY over DISTINCT to get unique records.
- Results obtained by GROUP BY clause are by default ordered in ascending order. So, you don’t need to sort the records separately.
- DISTINCT can be expensive when you are working on dataset with millions of rows and your SQL query contains JOINs
So, using GROUP BY does an awesome job to get unique records from the database efficiently, even if you are using multiple JOINs in the query.
You can read about another interesting use-case of GROUP BY clause in one of my previous article —
Moving ahead, let’s learn more about how you can limit the output obtained by GROUP BY clause, in an efficient way.
In SQL, HAVING works on the same logic as WHERE clause, the only difference is that it filters a group of records, rather than filtering every other record.
For instance suppose you want to get the unique records with Product category, sales manager & shipping cost, where shipping cost is more than 34.
This can be achieved using WHERE as well as HAVING clause as given below.
-- WHERE clauseSELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
WHERE Shipping_Cost >= 34
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost-- HAVING clauseSELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost
HAVING Shipping_Cost >= 34

Although above both queries generate the same output, the logic is totally different. The WHERE clause is executed before GROUP BY, so essentially it scans entire dataset for the given condition.
However, HAVING is executed after GROUP BY, so it scans comparatively small number of records as rows are already grouped together. So HAVING is a time-saver.
Well, let’s say you are not much concerned about efficiency. But, now you want all the product categories and sales manager where total shipping cost is more than 6000. And this is when HAVING comes handy.
Here, to filter the records here you need to use the condition SUM(Shipping_Cost) > 6000 and you can not use any aggregate function in the WHERE clause.
You can use HAVING like below in this situation —
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
HAVING SUM(Shipping_Cost) > 6000
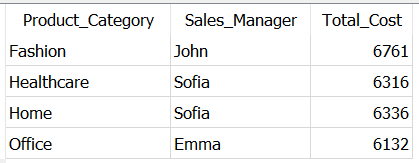
As you used aggregation on Shipping_Cost, you don’t need to mention it in GROUP BY. Logically, all the rows grouped together based on product category and sales manager and then HAVING scans for the given condition in all these groups.
Therefore, HAVING used in conjunction with GROUP BY is an optimized way to filter rows based on a condition.
🚩 Note: As HAVING is executed before SELECT, you cannot use column aliases in conditions in HAVING clause.
Further, although GROUP BY arranges the records in ascending or alphabetical order, sometimes you might want to arrange the records as per aggregated columns. And that’s when ORDER BY jumps in.
In SQL, ORDER BY is used to sort the results and by default it sorts them in ascending order. However, to get the result in descending order, you need to simply add keyword DESC after column names in ORDER BY clause.
Let’s continue with the above example. You can see the last result is ordered in ascending (alphabetical) order, first by column Product_Category and then by Sales_Manager. However, the values in last column — Total_Cost — are not ordered.
This can be specifically achieved using ORDER BY clause, as mentioned below.
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
ORDER BY Total_Cost DESC

Clearly, the last column is now arranged in the descending order. Also, you can see that, now there is no specific order for values in first two columns. And that’s because, you included them only in GROUP BY but not in in the ORDER BY clause.
This problem can be solved by mentioning them in the ORDER BY clause, as below —
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
ORDER BY Product_Category,
Sales_Manager,
Total_Cost DESC

Now, the first two columns are arranged in the ascending order and only the last column — Total_Cost — is arranged in the descending order. And it is because the keyword DESC is used only after this column name.
🚩 This gives you an important learning takeaway —
You can arrange a SQL result dataset by multiple columns in different orders i.e. arrange some columns in ascending and the remaining in descending order. But, pay attention to the order in which the column names are mentioned in ORDER BY, as it changes the result set.
In this case it is important to understand how GROUP BY worked. Did you ask yourself a question —
Why you can’t see all the values in the
Total_Costcolumn in descending order❓
It is because only the first two columns are mentioned in GROUP BY. All the records are arranged in groups based on values in these two columns only and total cost is calculated by aggregating values in Shipping_Cost column.
So, ultimately, total cost values in the result are arranged based on these groups and not on entire table.
Going ahead, let’s explore an example which will further help you to understand the difference between filtering records and when to use WHERE and HAVING in conjunction with GROUP BY.
As you already read all the concepts in the article so far, let’s directly start with an example.
Suppose you want to get the list of sales managers and product categories for all the orders which are Not Delivered to customer. At the same time, you want to display only those sales managers who spent more than 1600 USD on shipping products in a specific product category.
Now, you can solve this problem with the below 3 steps —
- Filter all the records using condition
Status = ‘Not Delivered’. As this is a non aggregated column, you can use WHERE for that. - Filter records based on total shipping cost using condition
SUM(Shipping_Cost) > 1600. As this is an aggregated column, you should use HAVING for that. - To calculate total shipping cost, you need to group the records by sales manager and product category, using
GROUP BY
If you are following along, your query should look like —
SELECT Sales_Manager,
Product_Category,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
WHERE Status = 'Not Delivered'
GROUP BY Sales_Manager,
Product_Category
HAVING SUM(Shipping_Cost) > 1600

It gives out all the unique combinations of sales manager and product categories satisfying the conditions mentioned in the example.
You can notice, the first two columns are arranged in ascending order. Also, the two rows encircled in red, shows ascending order of product category for same sales manager. This is the evidence that, GROUP BY arranges the records in ascending order by default.
That’s all about GROUP BY!
Data Science
Easy to complex SQL GROUP BY use-cases, in under 10 minutes

GROUP BY in SQL, Explained
SQL — Structured Query Language — is widely used tool to extract the data from relational database and transform it.
Data transformation is incomplete without data aggregation, which is important concept in SQL. And data aggregation is impossible without GROUP BY! Therefore, it is important to master GROUP BY to easily perform all types of data transformations and aggregations.
In SQL, GROUP BY is used for data aggregation, using aggregate functions. such as SUM(), MIN(), MAX(), AVG() and COUNT() .
But, why are aggregation function used in conjunction with GROUP BY?
In SQL, a GROUP BY clause is used to group the rows together. So when you use aggregate function on a column, the result describes the data for that specific group of rows.
In this article, I am explaining 5 examples of using GROUP BY clause in SQL query which will help you to use GROUP BY without any struggle.
I kept this article pretty short, so that you can finish it quickly and master one of the important concepts in SQL.
You can quickly navigate to your favorite part using this index.
· GROUP BY with Aggregate Functions
· GROUP BY without Aggregate Functions
· GROUP BY with HAVING
· GROUP BY with ORDER BY
· GROUP BY with WHERE, HAVING and ORDER BY
📍 Note: I’m using SQLite DB Browser and a self created Sales Data created using Faker . You can get it on my Github repo for free under the MIT License!
It is a simple 9999 x 11 dataset as below.
Okay, here we go…
Well, before going ahead, always remember below one rule of GROUP BY..
When you use GROUP BY in your SQL query, then each column in SELECT statement must be either present in GROUP BY clause or occur as parameter in an aggregated function.
Now, let’s start with the simplest use-case.
This is the most commonly used scenario, where you apply aggregate function on one or more columns. As mentioned above, GROUP BY simply groups the rows together which have similar values in the columns specified in it.
For an instance, suppose, you want get statistical summary of unit price by each product category. This example specifically explains how to use all the aggregate functions.
You can get such statistical summary using the query —
SELECT Product_Category,
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category
As you see in the above query, you used two columns — Product_Category and UnitPrice — And the later is always used in a aggregate functions. Therefore, GROUP BY clause contains only one remaining column.
You can notice, the first record in Product_Category is NULL, which means GROUP BY combined all the NULL values in Product_Category in single group. This aligns with the SQL standard as specified by Microsoft —
“If a grouping column contains NULL values, all NULL values are considered equal and they are collected into a single group.”
Also, by default, the result table is ordered in Ascending order of the columns in GROUP BY with NULL (if present) at the top. If you don’t want NULL to be part of your result table, you can anytime use COALESCE function and give a meaningful name for NULL, as shown below.
SELECT COALESCE(Product_Category,'Undefined_Category') AS Product_Category,
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category
🚩 An important point to note here —
Although
COALESCEis applied on Product_Category column, you are not actually aggregating values from this column. So, it must be the part of GROUP BY.
In this way, you can add as many columns you need in the SELECT statement, apply aggregate function on some or all columns and mention the remaining column names in the GROUP BY clause, to get the desired results.
Well, this was about using GROUP BY along with aggregation function. But, you can also use this clause without aggregate functions, as explained further.
Although most of the times GROUP BY is used along with aggregate functions, it can still still used without aggregate functions — to find unique records.
For example, suppose you want to retrieve all the unique combinations of Sales_Manager and Product_Category. Using GROUP BY, this is extremely simple. All you need to do is, mention all the column names in GROUP BY which you mention in the SELECT, as shown below.
SELECT Product_Category,
Sales_Manager
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
At this point, some might argue that, the same results can be obtained using DISTINCT keyword before column names.
However, here are the two main reasons why you should choose GROUP BY over DISTINCT to get unique records.
- Results obtained by GROUP BY clause are by default ordered in ascending order. So, you don’t need to sort the records separately.
- DISTINCT can be expensive when you are working on dataset with millions of rows and your SQL query contains JOINs
So, using GROUP BY does an awesome job to get unique records from the database efficiently, even if you are using multiple JOINs in the query.
You can read about another interesting use-case of GROUP BY clause in one of my previous article —
Moving ahead, let’s learn more about how you can limit the output obtained by GROUP BY clause, in an efficient way.
In SQL, HAVING works on the same logic as WHERE clause, the only difference is that it filters a group of records, rather than filtering every other record.
For instance suppose you want to get the unique records with Product category, sales manager & shipping cost, where shipping cost is more than 34.
This can be achieved using WHERE as well as HAVING clause as given below.
-- WHERE clauseSELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
WHERE Shipping_Cost >= 34
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost-- HAVING clauseSELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost
HAVING Shipping_Cost >= 34
Although above both queries generate the same output, the logic is totally different. The WHERE clause is executed before GROUP BY, so essentially it scans entire dataset for the given condition.
However, HAVING is executed after GROUP BY, so it scans comparatively small number of records as rows are already grouped together. So HAVING is a time-saver.
Well, let’s say you are not much concerned about efficiency. But, now you want all the product categories and sales manager where total shipping cost is more than 6000. And this is when HAVING comes handy.
Here, to filter the records here you need to use the condition SUM(Shipping_Cost) > 6000 and you can not use any aggregate function in the WHERE clause.
You can use HAVING like below in this situation —
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
HAVING SUM(Shipping_Cost) > 6000
As you used aggregation on Shipping_Cost, you don’t need to mention it in GROUP BY. Logically, all the rows grouped together based on product category and sales manager and then HAVING scans for the given condition in all these groups.
Therefore, HAVING used in conjunction with GROUP BY is an optimized way to filter rows based on a condition.
🚩 Note: As HAVING is executed before SELECT, you cannot use column aliases in conditions in HAVING clause.
Further, although GROUP BY arranges the records in ascending or alphabetical order, sometimes you might want to arrange the records as per aggregated columns. And that’s when ORDER BY jumps in.
In SQL, ORDER BY is used to sort the results and by default it sorts them in ascending order. However, to get the result in descending order, you need to simply add keyword DESC after column names in ORDER BY clause.
Let’s continue with the above example. You can see the last result is ordered in ascending (alphabetical) order, first by column Product_Category and then by Sales_Manager. However, the values in last column — Total_Cost — are not ordered.
This can be specifically achieved using ORDER BY clause, as mentioned below.
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
ORDER BY Total_Cost DESC
Clearly, the last column is now arranged in the descending order. Also, you can see that, now there is no specific order for values in first two columns. And that’s because, you included them only in GROUP BY but not in in the ORDER BY clause.
This problem can be solved by mentioning them in the ORDER BY clause, as below —
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
ORDER BY Product_Category,
Sales_Manager,
Total_Cost DESC
Now, the first two columns are arranged in the ascending order and only the last column — Total_Cost — is arranged in the descending order. And it is because the keyword DESC is used only after this column name.
🚩 This gives you an important learning takeaway —
You can arrange a SQL result dataset by multiple columns in different orders i.e. arrange some columns in ascending and the remaining in descending order. But, pay attention to the order in which the column names are mentioned in ORDER BY, as it changes the result set.
In this case it is important to understand how GROUP BY worked. Did you ask yourself a question —
Why you can’t see all the values in the
Total_Costcolumn in descending order❓
It is because only the first two columns are mentioned in GROUP BY. All the records are arranged in groups based on values in these two columns only and total cost is calculated by aggregating values in Shipping_Cost column.
So, ultimately, total cost values in the result are arranged based on these groups and not on entire table.
Going ahead, let’s explore an example which will further help you to understand the difference between filtering records and when to use WHERE and HAVING in conjunction with GROUP BY.
As you already read all the concepts in the article so far, let’s directly start with an example.
Suppose you want to get the list of sales managers and product categories for all the orders which are Not Delivered to customer. At the same time, you want to display only those sales managers who spent more than 1600 USD on shipping products in a specific product category.
Now, you can solve this problem with the below 3 steps —
- Filter all the records using condition
Status = ‘Not Delivered’. As this is a non aggregated column, you can use WHERE for that. - Filter records based on total shipping cost using condition
SUM(Shipping_Cost) > 1600. As this is an aggregated column, you should use HAVING for that. - To calculate total shipping cost, you need to group the records by sales manager and product category, using
GROUP BY
If you are following along, your query should look like —
SELECT Sales_Manager,
Product_Category,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
WHERE Status = 'Not Delivered'
GROUP BY Sales_Manager,
Product_Category
HAVING SUM(Shipping_Cost) > 1600
It gives out all the unique combinations of sales manager and product categories satisfying the conditions mentioned in the example.
You can notice, the first two columns are arranged in ascending order. Also, the two rows encircled in red, shows ascending order of product category for same sales manager. This is the evidence that, GROUP BY arranges the records in ascending order by default.
That’s all about GROUP BY!
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.