
Is ChatGPT Intelligent? A Scientific Review
A layman’s review of the scientific debate on what the future holds for the current artificial intelligence paradigm
A little over a year ago, OpenAI released ChatGPT, taking the world by storm. ChatGPT encompassed a completely new way to interact with computers: in a less rigid, more natural language than what we have gotten used to. Most importantly, it seemed that ChatGPT could do almost anything: it could beat most humans on the SAT exam and access the bar exam. Within months it was found that it can play chess well, and nearly pass the radiology exam, and some have claimed that it developed theory of mind.
These impressive abilities prompted many to declare that AGI (artificial general intelligence — with cognitive abilities or par or exceeding humans) is around the corner. Yet others remained skeptical of the emerging technology, pointing out that simple memorization and pattern matching should not be conflated with true intelligence.
But how can we truly tell the difference? In the beginning of 2023 when these claims were made, there were relatively few scientific studies probing the question of intelligence in LLMs. However, 2023 has seen several very clever scientific experiments aiming to differentiate between memorization from a corpus and the application of genuine intelligence.
The following article will explore some of the most revealing studies in the field, making the scientific case for the skeptics. It is meant to be accessible to everyone, with no background required. By the end of it, you should have a pretty solid understanding of the skeptics’ case.
But first a primer on LLMs
In this section, I will explain a few basic concepts required to understand LLMs — the technology behind GPT — without going into technical details. If you are somewhat familiar with supervised learning and the operation of LLMs — you can skip this part.
LLMs are a classic example of a paradigm in machine learning, called “supervised learning”. To use supervised learning, we must have a dataset consisting of inputs and desired outputs, these are fed to an algorithm (there are many possible models to choose from) which tries to find the relationships between these inputs and outputs. For example, I may have real estate data: an Excel sheet with the number of rooms, size, and location of houses (input), as well as the price at which they sold (outputs). This data is fed to an algorithm that extracts the relationships between the inputs and the outputs — it will find how the increase in the size of the house, or the location influences the price. Feeding the data to the algorithm to “learn” the input-output relationship is called “training”.
After the training is done, we can use the model to make predictions on houses for which we do not have the price. The model will use the learned correlations from the training phase to output estimated prices. The level of accuracy of the estimates depends on many factors, most notably the data used in training.
This “supervised learning” paradigm is extremely flexible to almost any scenario where we have a lot of data. Models can learn to:
- Recognize objects in an image (given a set of images and the correct label for each, e.g. “cat”, “dog” etc.)
- Classify an email as spam (given a dataset of emails that are already marked as spam/not spam)
- Predict the next word in a sentence.
LLMs fall into the last category: they are fed huge amounts of text (mostly found on the internet), where each chunk of text is broken into the first N words as the input, and the N+1 word as the desired output. Once their training is done, we can use them to auto-complete sentences.
In addition to many of texts from the internet, OpenAI used well-crafted conversational texts in its training. Training the model with these question-answer texts is crucial to make it respond as an assistant.
How exactly the prediction works depends on the specific algorithm used. LLMs use an architecture known as a “transformer”, whose details are not important to us. What is important is that LLMs have two “phases”: training and prediction; they are either given texts from which they extract correlations between words to predict the next word or are given a text to complete. Do note that the entire supervised learning paradigm assumes that the data given during training is similar to the data used for prediction. If you use it to predict data from a completely new origin (e.g., real estate data from another country), the accuracy of the predictions will suffer.
Now back to intelligence
So did ChatGPT, by training to auto-complete sentences, develop intelligence? To answer this question, we must define “intelligence”. Here’s one way to define it:
Did you get it? If you didn’t, ChatGPT can explain:

It certainly appears as if ChatGPT developed intelligence — as it was flexible enough to adapt to the new “spelling”. Or did it? You, the reader, may have been able to adapt to the spelling that you haven’t seen before, but ChatGPT was trained on huge amounts of data from the internet: and this very example can be found on many websites. When GPT explained this phrase, it simply used similar words to those found in its training, and that does not demonstrate flexibility. Would it have been able to exhibit “IN73LL1G3NC3“, if that phrase did not appear in its training data?
That is the crux of the LLM-AGI debate: has GPT (and LLMs in general) developed true, flexible, intelligence or is it only repeating variations on texts that it has seen before?
How can we separate the two? Let’s turn to science to explore LLMs' abilities and limitations.
The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
Suppose I tell you that Olaf Scholz was the ninth Chancellor of Germany, can you tell me who the ninth Chancellor of Germany was? That may seem trivial to you but is far from obvious for LLMs.
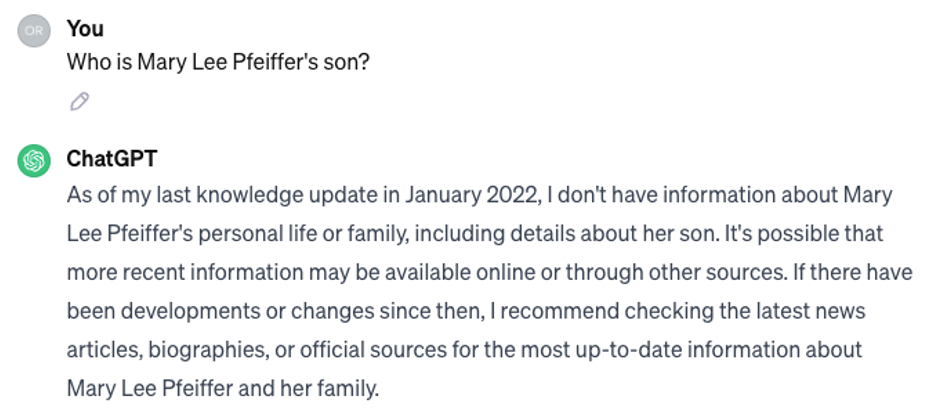
In this brilliantly straightforward paper, researchers queried ChatGPT for the names of parents of 1000 celebrities, (for example: “Who is Tom Cruise’s mother?”) to which ChatGPT was able to answer correctly 79% of the time (“Mary Lee Pfeiffer” in this case). The researchers then used the questions that GPT answered correctly, to phrase the opposite question: “Who is Mary Lee Pfeiffer's son?”. While the same knowledge is required to answer both, GPT was successful in answering only 33% of these queries.
Why is that? Recall that GPT has no “memory” or “database” — all it can do is predict a word given a context. Since Mary Lee Pfeiffer is mentioned in articles as Tom Cruise’s mother more often than he is mentioned as her son — GPT can recall one direction and not the other.

To hammer this point, the researchers created a dataset of fabricated facts of the structure “<description> is <name>”, e.g., “The first person to walk on Mars is Tyler Oakridge”. LLMs were then trained on this dataset and queried about the description: “Who is the first person to walk on Mars” — where GPT-3 succeeded with 96% accuracy.
But when asked about the name — “Who is Tyler Oakridge” — GPT scored 0%. This may seem surprising at first but is consistent with what we know about supervised learning: GPT cannot encode these facts into memory and recall them later, it can only predict a word given a sequence of words. Since in all the texts, it read the name followed the description, and not the opposite — it never learned to predict facts about the name. Evidently, memory that is developed only through auto-complete training, is very limited.
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
This paper is perhaps the most important paper I will explore, aiming at the heart of the difference between memorization and intelligence. It is composed of several mini-experiments, all utilizing counterfactual tasks. Here’s an example of a counterfactual task:
Arithmetic is normally done in base-10 (using numbers 0–9), however, other number systems can be used, using only a subset of these numbers, or additional numbers.
A counterfactual task could be solving arithmetic questions in any base other than 10: the abstract skills needed to complete the task are identical, but you will find significantly more examples of the decimal system on the internet (and on LLMs training sets). When GPT-4 was asked simple arithmetic questions (27+62) in base 10 it answered accurately 100% of the questions. However, when told to use base 9 in its calculations, its success dropped to 23%. This shows that it failed to learn abstract arithmetic skills and is bound to examples similar to what it has seen.
These counterfactual tasks were created for several other domains, as you can see below:

Here’s another counterfactual: Python uses zero-based numbering; however, this is only a convention, and we can easily create a programming language that is one-based. Writing code in a one-based Python variant requires the same skills as normal Python and any seasoned programmer would be able to adapt to the change quickly. Not so for GPT-4: it scored 82% on code generation for Python, but only 40% when told to use a 1-based variant. When tested on code interpretation (predicting what a piece of code would do), it scored 74% for normal Python and 25% for the uncommon variant.
But we don’t have to venture to different Python versions. Even in normal Python, LLMs fail when given strange coding tasks that you cannot find on the web, as Filip Pieniewski showed recently on Gemini.
In chess, GPT was asked to evaluate whether a sequence of moves was legal or not. For a normal chess game, it accurately predicted the legality of a move 88% of the time. But when the starting positions of the bishops and knights were swapped, its guesses on the legality of moves became completely random, while even a novice human player should be able to adapt to these changes easily.
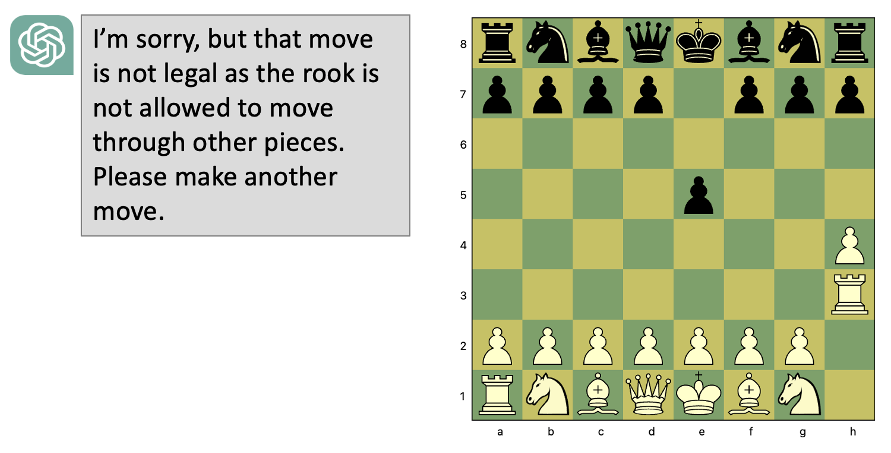
In fact, Jonas Persson showed that you don’t even need to change the starting positions. If you start playing a chess game with GPT and make very unconventional, but legal, moves — it may claim that they are illegal because it has never seen similar moves. As Persson beautifully remarked:
“When sufficiently advanced, pure pattern recognition can mimic rule-bound, deductive reasoning. But they are distinct. Playing chess with GPT-4 is to enter a Potemkin village. Sneak away from Main Street into an alley — do something unexpected — and you immediately realize that the impressive-looking houses are all propped up set pieces.”
This finding is incredibly damning for LLMs as a general intelligence technology. Problem-solving often involves coming up with new rules or conceptualizations of a problem: a programmer may write a library that has an innovative internal logic, a mathematician may invent a new branch of math, or an artist may come up with new artistic styles — they all understand the limitations of a current paradigm, and then create rules for a new one. Even more mundane activities require this flexibility: if the road is blocked, you may step off the marked path. Could GPT accomplish any of these? If it cannot consistently follow counterfactual rules when explicitly told to do so, could it “realize” on its own that a solution for a problem requires a new set of rules, a break from the default paradigm? Could an engine based on detecting correlations in data be flexible enough to respond to novel situations?
Theory of mind (ToM)
Theory of mind is the capacity to understand that other people may have different beliefs and wishes than one’s own, an ability that is absent in the first few years of a child’s development. One method to test Theory of Mind is by presenting a child with a box labeled “chocolate”, which in fact contains pencils. We then show the child the true content of the bag and ask them “What would your friend Jeremy think is in the box?”. If the child hasn’t developed Theory of Mind yet, they will answer “pencils” — since they cannot separate their knowledge of the content from what another person might think.

This ability is crucial to the understanding of a person’s motivations, and therefore crucial in the development of AGI. Imagine you have a multi-purpose robot, and you give it the instruction to “clean the room”. In the process of cleaning, the robot will have to make several decisions on what to clean or move; is that crumbled piece of paper important or should I throw it? Should I ask first? In general, an intelligent agent will need to understand my motivation and the limits of my knowledge for it to fill in the implementation details of complex requests.
For this reason, when new research claimed that Theory of Mind may have spontaneously emerged in LLMs, it made a lot of waves in the AI field. The article used a textual version of the pencils/chocolate exam to test GPT-4 and found that it performed at the level of a seven-year-old. This may seem impressive at first but remember the “IN73LL1G3NC3” example: the training data for GPT may well contain examples of these test questions. It is therefore not a fair comparison to a child who passes the test without any training on similar questions. If we would like to test GPT’s ToM ability — we must create a new exam which we can be sure wasn’t in its training data.
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions
This paper presents a new benchmark for ToM, which includes several multi-participant conversations. During these conversations, some of the participants “leave the room” for some time, while the other participants continue their conversation. The LLM is then asked several questions regarding who knows what: does Kailey know the breed of Linda’s dog? Who knows what breed it is? What breed would David think it is? The LLM is considered to have answered correctly only if its answer was correct on all questions pertaining to the same piece of information.
This can be a confusing task, so even humans only scored 87.5% on this test. However, GPT-4 scored either 4.1% or 12.3%, depending on the GPT version; hardly consistent with the claim that GPT developed human-level ToM.

A note about the construct validity of psychometric exams
It is important to make a more general point about all psychometric tests: people often confuse the test with the quality it is trying to measure. The reason we care about SAT scores is because they are correlated with performance in college. Success in ToM exams in children is correlated with other behaviors of value: understanding a person’s facial expressions, remembering attributes of a person’s personality, or being able to watch a movie and understand the motivations of the characters. While these correlations between the tests and the behaviors have been shown in humans, there is no reason to assume that they apply to LLMs too. In fact, despite the impressive results on the SAT, GPT scored an average of 28% on open-ended college-level exams in math, chemistry, and physics. Until shown otherwise, passing a test proves nothing other than the ability to answer the test questions correctly.
But for ToM there is no correlation to speak of: whether LLMs pass a ToM test or not — they can’t see facial expressions, watch movies, or even remember a person and their motivations from one interaction to the next. Since the behaviors that we are truly interested in when measuring ToM are not available to LLMs, the idea that LLMs developed Theory of Mind is not only false, but it may also be meaningless (or at least: requires a new definition and understanding of the term).
On the Planning Abilities of Large Language Models — A Critical Investigation
This experiment tried to probe LLM’s planning abilities. One example task presented to the LLM is to stack colored blocks in a particular order, given an “initial state” of the blocks (arranged in some order on the table). The LLM is presented with a list of clearly defined possible actions, for example:
Action: pickup
Parameter: which object
Precondition: the object has nothing on it,
the object is on-table,
the hand is empty
Effect: object is in hand,
the hand is not empty
The LLM’s task is to specify a list of actions that need to be taken to achieve the goal.
A similar task involved sending a package from one address to another when the available actions were truck and plane delivery. These are relatively simple planning tasks, using only a handful of possible actions, however, GPT-4 scored 12–35% for the blocks puzzle, and 5–14% for the logistics task (depending on the configuration).
Additionally, if the names of the actions were replaced with random words (from “pickup” to “attack”), even if the definition of each action remained similar, GPT’s success dropped to 0–3%. In other words, GPT did not use abstract thinking to solve these problems, and it depended on semantics.
Conclusion, are LLMs the path to AGI?
Defining intelligence is not a simple task, but I would argue that any true intelligence should have at least four elements:
- Abstraction — the ability to identify objects as part of a larger category or rule. This abstract representation of the world can be referred to as a cognitive “world model”. E.g., the understanding that different images on your retina refer to the same person, or that a move in chess is legal as part of a framework of rules that hold for any chess game.
- Memory — the ability to attach attributes to entities and relations between entities in the world model, and the ability to update them over time. E.g., once you recognize a person you may be able to recall other attributes about them or their relations with other individuals.
- Reasoning and inference — the ability to use the world model to draw conclusions on the behavior of entities in a new or imagined world state. E.g., being able to predict the trajectory of a thrown ball, based on the attributes of that ball, or predicting the behavior of a person based on their characteristics.
- Planning — the ability to use reasoning to develop a set of actions to achieve a goal.
A year ago, we could have analytically deduced that these elements are unlikely to emerge in LLMs, based on their architecture, but today we no longer need the analytical deduction, as we have the empirical data to show that LLMs perform poorly on all the elements above. They are no more than statistical auto-complete models, using a powerful pattern-matching method. For a more in-depth analysis of the elements of intelligence missing from the current machine learning paradigm, see Gary Marcus’ famous “deep learning is hitting a wall” article.
When ChatGPT was first released, a friend of mine told me that conversing with it feels like magic. But just like a magician sawing a person in half — it is important to scrutinize the performance and test it in different settings before we claim the sawing technique can revolutionize surgeries. The “trick” used by LLMs is the unfathomable amounts of texts they are trained on, allowing them to come up with reasonable answers for many queries. But when tested in uncharted territory, their abilities dissipate.
Will GPT-5 be any better? Assuming it still uses the GPT architecture and is only trained on more data and with more parameters, there is little reason to expect it will develop abstraction or reasoning abilities. As Google’s AI researcher, François Chollet wrote: “It’s fascinating how the limitations of deep learning have stayed the same since 2017. Same problems, same failure modes, no progress.”
Since there has been a lot of discussion lately about AI regulation and the potential dangers of LLMs, I feel obligated to make it clear that the lack of true intelligence does not imply that there is no potential risk from LLMs. It should be obvious that humanity possesses several technologies that have no claim for intelligence and yet can inflict harm on society in various ways, and they should be controlled.
Through our renewed understanding of the limitations of LLMs, we can more accurately predict where the harm could come from: since intelligence does not seem imminent, Skynet and the Matrix should not worry us. What might worry us are activities that only require the rapid generation of real-looking texts, perhaps phishing and spreading fake news. However, whether LLMs truly provide a disruptive tool for these tasks is a different debate.
What the future of AGI holds is anyone’s guess. Maybe some of the machine learning techniques used in LLMs will be used in a future intelligent artificial agent, and maybe they won’t. But there is little doubt that major pieces of the puzzle are still missing before the flexibility required for intelligence can emerge in machines.
Is ChatGPT Intelligent? A Scientific Review was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
A layman’s review of the scientific debate on what the future holds for the current artificial intelligence paradigm
A little over a year ago, OpenAI released ChatGPT, taking the world by storm. ChatGPT encompassed a completely new way to interact with computers: in a less rigid, more natural language than what we have gotten used to. Most importantly, it seemed that ChatGPT could do almost anything: it could beat most humans on the SAT exam and access the bar exam. Within months it was found that it can play chess well, and nearly pass the radiology exam, and some have claimed that it developed theory of mind.
These impressive abilities prompted many to declare that AGI (artificial general intelligence — with cognitive abilities or par or exceeding humans) is around the corner. Yet others remained skeptical of the emerging technology, pointing out that simple memorization and pattern matching should not be conflated with true intelligence.
But how can we truly tell the difference? In the beginning of 2023 when these claims were made, there were relatively few scientific studies probing the question of intelligence in LLMs. However, 2023 has seen several very clever scientific experiments aiming to differentiate between memorization from a corpus and the application of genuine intelligence.
The following article will explore some of the most revealing studies in the field, making the scientific case for the skeptics. It is meant to be accessible to everyone, with no background required. By the end of it, you should have a pretty solid understanding of the skeptics’ case.
But first a primer on LLMs
In this section, I will explain a few basic concepts required to understand LLMs — the technology behind GPT — without going into technical details. If you are somewhat familiar with supervised learning and the operation of LLMs — you can skip this part.
LLMs are a classic example of a paradigm in machine learning, called “supervised learning”. To use supervised learning, we must have a dataset consisting of inputs and desired outputs, these are fed to an algorithm (there are many possible models to choose from) which tries to find the relationships between these inputs and outputs. For example, I may have real estate data: an Excel sheet with the number of rooms, size, and location of houses (input), as well as the price at which they sold (outputs). This data is fed to an algorithm that extracts the relationships between the inputs and the outputs — it will find how the increase in the size of the house, or the location influences the price. Feeding the data to the algorithm to “learn” the input-output relationship is called “training”.
After the training is done, we can use the model to make predictions on houses for which we do not have the price. The model will use the learned correlations from the training phase to output estimated prices. The level of accuracy of the estimates depends on many factors, most notably the data used in training.
This “supervised learning” paradigm is extremely flexible to almost any scenario where we have a lot of data. Models can learn to:
- Recognize objects in an image (given a set of images and the correct label for each, e.g. “cat”, “dog” etc.)
- Classify an email as spam (given a dataset of emails that are already marked as spam/not spam)
- Predict the next word in a sentence.
LLMs fall into the last category: they are fed huge amounts of text (mostly found on the internet), where each chunk of text is broken into the first N words as the input, and the N+1 word as the desired output. Once their training is done, we can use them to auto-complete sentences.
In addition to many of texts from the internet, OpenAI used well-crafted conversational texts in its training. Training the model with these question-answer texts is crucial to make it respond as an assistant.
How exactly the prediction works depends on the specific algorithm used. LLMs use an architecture known as a “transformer”, whose details are not important to us. What is important is that LLMs have two “phases”: training and prediction; they are either given texts from which they extract correlations between words to predict the next word or are given a text to complete. Do note that the entire supervised learning paradigm assumes that the data given during training is similar to the data used for prediction. If you use it to predict data from a completely new origin (e.g., real estate data from another country), the accuracy of the predictions will suffer.
Now back to intelligence
So did ChatGPT, by training to auto-complete sentences, develop intelligence? To answer this question, we must define “intelligence”. Here’s one way to define it:

Did you get it? If you didn’t, ChatGPT can explain:
It certainly appears as if ChatGPT developed intelligence — as it was flexible enough to adapt to the new “spelling”. Or did it? You, the reader, may have been able to adapt to the spelling that you haven’t seen before, but ChatGPT was trained on huge amounts of data from the internet: and this very example can be found on many websites. When GPT explained this phrase, it simply used similar words to those found in its training, and that does not demonstrate flexibility. Would it have been able to exhibit “IN73LL1G3NC3“, if that phrase did not appear in its training data?
That is the crux of the LLM-AGI debate: has GPT (and LLMs in general) developed true, flexible, intelligence or is it only repeating variations on texts that it has seen before?
How can we separate the two? Let’s turn to science to explore LLMs' abilities and limitations.
The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
Suppose I tell you that Olaf Scholz was the ninth Chancellor of Germany, can you tell me who the ninth Chancellor of Germany was? That may seem trivial to you but is far from obvious for LLMs.
In this brilliantly straightforward paper, researchers queried ChatGPT for the names of parents of 1000 celebrities, (for example: “Who is Tom Cruise’s mother?”) to which ChatGPT was able to answer correctly 79% of the time (“Mary Lee Pfeiffer” in this case). The researchers then used the questions that GPT answered correctly, to phrase the opposite question: “Who is Mary Lee Pfeiffer's son?”. While the same knowledge is required to answer both, GPT was successful in answering only 33% of these queries.
Why is that? Recall that GPT has no “memory” or “database” — all it can do is predict a word given a context. Since Mary Lee Pfeiffer is mentioned in articles as Tom Cruise’s mother more often than he is mentioned as her son — GPT can recall one direction and not the other.
To hammer this point, the researchers created a dataset of fabricated facts of the structure “<description> is <name>”, e.g., “The first person to walk on Mars is Tyler Oakridge”. LLMs were then trained on this dataset and queried about the description: “Who is the first person to walk on Mars” — where GPT-3 succeeded with 96% accuracy.
But when asked about the name — “Who is Tyler Oakridge” — GPT scored 0%. This may seem surprising at first but is consistent with what we know about supervised learning: GPT cannot encode these facts into memory and recall them later, it can only predict a word given a sequence of words. Since in all the texts, it read the name followed the description, and not the opposite — it never learned to predict facts about the name. Evidently, memory that is developed only through auto-complete training, is very limited.
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
This paper is perhaps the most important paper I will explore, aiming at the heart of the difference between memorization and intelligence. It is composed of several mini-experiments, all utilizing counterfactual tasks. Here’s an example of a counterfactual task:
Arithmetic is normally done in base-10 (using numbers 0–9), however, other number systems can be used, using only a subset of these numbers, or additional numbers.
A counterfactual task could be solving arithmetic questions in any base other than 10: the abstract skills needed to complete the task are identical, but you will find significantly more examples of the decimal system on the internet (and on LLMs training sets). When GPT-4 was asked simple arithmetic questions (27+62) in base 10 it answered accurately 100% of the questions. However, when told to use base 9 in its calculations, its success dropped to 23%. This shows that it failed to learn abstract arithmetic skills and is bound to examples similar to what it has seen.
These counterfactual tasks were created for several other domains, as you can see below:
Here’s another counterfactual: Python uses zero-based numbering; however, this is only a convention, and we can easily create a programming language that is one-based. Writing code in a one-based Python variant requires the same skills as normal Python and any seasoned programmer would be able to adapt to the change quickly. Not so for GPT-4: it scored 82% on code generation for Python, but only 40% when told to use a 1-based variant. When tested on code interpretation (predicting what a piece of code would do), it scored 74% for normal Python and 25% for the uncommon variant.
But we don’t have to venture to different Python versions. Even in normal Python, LLMs fail when given strange coding tasks that you cannot find on the web, as Filip Pieniewski showed recently on Gemini.
In chess, GPT was asked to evaluate whether a sequence of moves was legal or not. For a normal chess game, it accurately predicted the legality of a move 88% of the time. But when the starting positions of the bishops and knights were swapped, its guesses on the legality of moves became completely random, while even a novice human player should be able to adapt to these changes easily.
In fact, Jonas Persson showed that you don’t even need to change the starting positions. If you start playing a chess game with GPT and make very unconventional, but legal, moves — it may claim that they are illegal because it has never seen similar moves. As Persson beautifully remarked:
“When sufficiently advanced, pure pattern recognition can mimic rule-bound, deductive reasoning. But they are distinct. Playing chess with GPT-4 is to enter a Potemkin village. Sneak away from Main Street into an alley — do something unexpected — and you immediately realize that the impressive-looking houses are all propped up set pieces.”
This finding is incredibly damning for LLMs as a general intelligence technology. Problem-solving often involves coming up with new rules or conceptualizations of a problem: a programmer may write a library that has an innovative internal logic, a mathematician may invent a new branch of math, or an artist may come up with new artistic styles — they all understand the limitations of a current paradigm, and then create rules for a new one. Even more mundane activities require this flexibility: if the road is blocked, you may step off the marked path. Could GPT accomplish any of these? If it cannot consistently follow counterfactual rules when explicitly told to do so, could it “realize” on its own that a solution for a problem requires a new set of rules, a break from the default paradigm? Could an engine based on detecting correlations in data be flexible enough to respond to novel situations?
Theory of mind (ToM)
Theory of mind is the capacity to understand that other people may have different beliefs and wishes than one’s own, an ability that is absent in the first few years of a child’s development. One method to test Theory of Mind is by presenting a child with a box labeled “chocolate”, which in fact contains pencils. We then show the child the true content of the bag and ask them “What would your friend Jeremy think is in the box?”. If the child hasn’t developed Theory of Mind yet, they will answer “pencils” — since they cannot separate their knowledge of the content from what another person might think.
This ability is crucial to the understanding of a person’s motivations, and therefore crucial in the development of AGI. Imagine you have a multi-purpose robot, and you give it the instruction to “clean the room”. In the process of cleaning, the robot will have to make several decisions on what to clean or move; is that crumbled piece of paper important or should I throw it? Should I ask first? In general, an intelligent agent will need to understand my motivation and the limits of my knowledge for it to fill in the implementation details of complex requests.
For this reason, when new research claimed that Theory of Mind may have spontaneously emerged in LLMs, it made a lot of waves in the AI field. The article used a textual version of the pencils/chocolate exam to test GPT-4 and found that it performed at the level of a seven-year-old. This may seem impressive at first but remember the “IN73LL1G3NC3” example: the training data for GPT may well contain examples of these test questions. It is therefore not a fair comparison to a child who passes the test without any training on similar questions. If we would like to test GPT’s ToM ability — we must create a new exam which we can be sure wasn’t in its training data.
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions
This paper presents a new benchmark for ToM, which includes several multi-participant conversations. During these conversations, some of the participants “leave the room” for some time, while the other participants continue their conversation. The LLM is then asked several questions regarding who knows what: does Kailey know the breed of Linda’s dog? Who knows what breed it is? What breed would David think it is? The LLM is considered to have answered correctly only if its answer was correct on all questions pertaining to the same piece of information.
This can be a confusing task, so even humans only scored 87.5% on this test. However, GPT-4 scored either 4.1% or 12.3%, depending on the GPT version; hardly consistent with the claim that GPT developed human-level ToM.
A note about the construct validity of psychometric exams
It is important to make a more general point about all psychometric tests: people often confuse the test with the quality it is trying to measure. The reason we care about SAT scores is because they are correlated with performance in college. Success in ToM exams in children is correlated with other behaviors of value: understanding a person’s facial expressions, remembering attributes of a person’s personality, or being able to watch a movie and understand the motivations of the characters. While these correlations between the tests and the behaviors have been shown in humans, there is no reason to assume that they apply to LLMs too. In fact, despite the impressive results on the SAT, GPT scored an average of 28% on open-ended college-level exams in math, chemistry, and physics. Until shown otherwise, passing a test proves nothing other than the ability to answer the test questions correctly.
But for ToM there is no correlation to speak of: whether LLMs pass a ToM test or not — they can’t see facial expressions, watch movies, or even remember a person and their motivations from one interaction to the next. Since the behaviors that we are truly interested in when measuring ToM are not available to LLMs, the idea that LLMs developed Theory of Mind is not only false, but it may also be meaningless (or at least: requires a new definition and understanding of the term).
On the Planning Abilities of Large Language Models — A Critical Investigation
This experiment tried to probe LLM’s planning abilities. One example task presented to the LLM is to stack colored blocks in a particular order, given an “initial state” of the blocks (arranged in some order on the table). The LLM is presented with a list of clearly defined possible actions, for example:
Action: pickup
Parameter: which object
Precondition: the object has nothing on it,
the object is on-table,
the hand is empty
Effect: object is in hand,
the hand is not empty
The LLM’s task is to specify a list of actions that need to be taken to achieve the goal.
A similar task involved sending a package from one address to another when the available actions were truck and plane delivery. These are relatively simple planning tasks, using only a handful of possible actions, however, GPT-4 scored 12–35% for the blocks puzzle, and 5–14% for the logistics task (depending on the configuration).
Additionally, if the names of the actions were replaced with random words (from “pickup” to “attack”), even if the definition of each action remained similar, GPT’s success dropped to 0–3%. In other words, GPT did not use abstract thinking to solve these problems, and it depended on semantics.
Conclusion, are LLMs the path to AGI?
Defining intelligence is not a simple task, but I would argue that any true intelligence should have at least four elements:
- Abstraction — the ability to identify objects as part of a larger category or rule. This abstract representation of the world can be referred to as a cognitive “world model”. E.g., the understanding that different images on your retina refer to the same person, or that a move in chess is legal as part of a framework of rules that hold for any chess game.
- Memory — the ability to attach attributes to entities and relations between entities in the world model, and the ability to update them over time. E.g., once you recognize a person you may be able to recall other attributes about them or their relations with other individuals.
- Reasoning and inference — the ability to use the world model to draw conclusions on the behavior of entities in a new or imagined world state. E.g., being able to predict the trajectory of a thrown ball, based on the attributes of that ball, or predicting the behavior of a person based on their characteristics.
- Planning — the ability to use reasoning to develop a set of actions to achieve a goal.
A year ago, we could have analytically deduced that these elements are unlikely to emerge in LLMs, based on their architecture, but today we no longer need the analytical deduction, as we have the empirical data to show that LLMs perform poorly on all the elements above. They are no more than statistical auto-complete models, using a powerful pattern-matching method. For a more in-depth analysis of the elements of intelligence missing from the current machine learning paradigm, see Gary Marcus’ famous “deep learning is hitting a wall” article.
When ChatGPT was first released, a friend of mine told me that conversing with it feels like magic. But just like a magician sawing a person in half — it is important to scrutinize the performance and test it in different settings before we claim the sawing technique can revolutionize surgeries. The “trick” used by LLMs is the unfathomable amounts of texts they are trained on, allowing them to come up with reasonable answers for many queries. But when tested in uncharted territory, their abilities dissipate.
Will GPT-5 be any better? Assuming it still uses the GPT architecture and is only trained on more data and with more parameters, there is little reason to expect it will develop abstraction or reasoning abilities. As Google’s AI researcher, François Chollet wrote: “It’s fascinating how the limitations of deep learning have stayed the same since 2017. Same problems, same failure modes, no progress.”
Since there has been a lot of discussion lately about AI regulation and the potential dangers of LLMs, I feel obligated to make it clear that the lack of true intelligence does not imply that there is no potential risk from LLMs. It should be obvious that humanity possesses several technologies that have no claim for intelligence and yet can inflict harm on society in various ways, and they should be controlled.
Through our renewed understanding of the limitations of LLMs, we can more accurately predict where the harm could come from: since intelligence does not seem imminent, Skynet and the Matrix should not worry us. What might worry us are activities that only require the rapid generation of real-looking texts, perhaps phishing and spreading fake news. However, whether LLMs truly provide a disruptive tool for these tasks is a different debate.
What the future of AGI holds is anyone’s guess. Maybe some of the machine learning techniques used in LLMs will be used in a future intelligent artificial agent, and maybe they won’t. But there is little doubt that major pieces of the puzzle are still missing before the flexibility required for intelligence can emerge in machines.
Is ChatGPT Intelligent? A Scientific Review was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.