
Large Language Model Training – Guide in 2023
Large language models (LLMs) took the internet by storm at the end of 2022 as ChatGPT from OpenAI reached 1 million users just 5 days after its launch. ChatGPT’s capabilities and wide applications can be accredited to the 175 billion parameters the GPT-3 language model has.
Although it is easy to use end-product language models like ChatGPT, developing a large language model takes significant computer science knowledge, time, and resources. We created this article to inform business leaders on:
- Definition of large language models
- Examples of large language models
- Architecture of large language models
- The training process of large language models,
So that they can leverage artificial intelligence and machine learning effectively.
What is a large language model?
A large language model is a type of machine learning model that is trained on a large corpus of text data to generate outputs for various natural language processing (NLP) tasks, such as text generation, question answering, and machine translation.
Large language models are typically based on deep learning neural networks such as the Transformer architecture and are trained on massive amounts of text data, often involving billions of words. Larger models, such as Google’s BERT model, are trained with a large dataset from various data sources which allows them to generate output for many tasks.
Top large language models by parameter size
We compiled the 7 largest large language models by parameter size in the table below.1
| Model | Developer | Parameter Size |
|---|---|---|
| WuDao 2.0 | Beijing Academy of Artificial Intelligence | 1.75 trillion |
| MT-NLG | Nvidia and Microsoft | 530 billion |
| Bloom | Hugging Face and BigScience | 176 billion |
| GPT-3 | OpenAI | 175 billion |
| LaMDA | 137 billion | |
| ESMFold | Meta AI | 15 billion |
| Gato | DeepMind | 1.18 billion |
Architecture of large language models
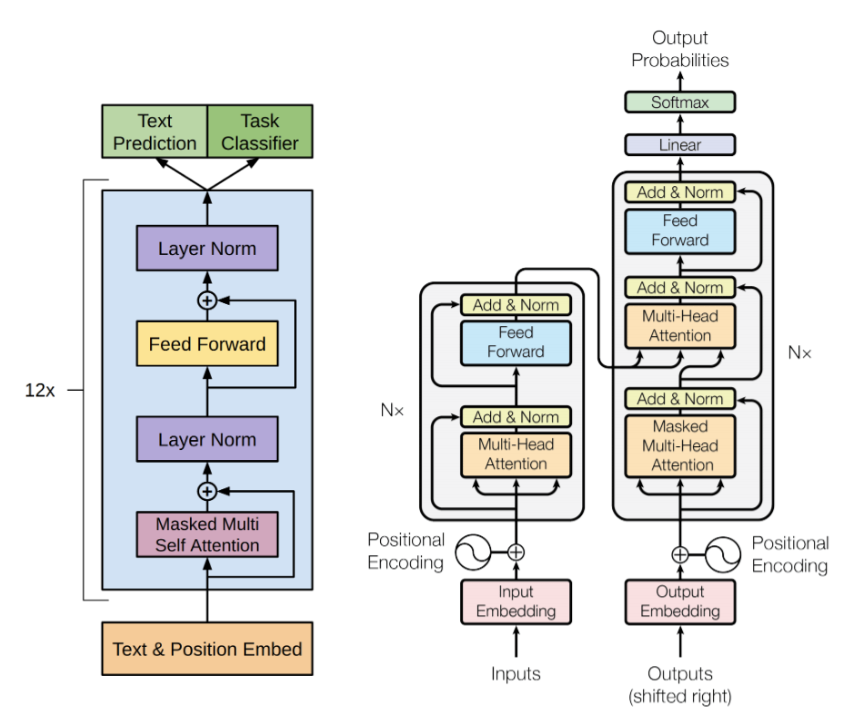
The architecture of large language models, such as OpenAI’s GPT-3, is based on a type of deep learning called the Transformer architecture. It consists of the following main components (see Figure 1):
Figure 1: Transformer architecture
Source:2
1. Input embedding
The input sequence is first transformed into a dense vector representation, known as an embedding, which captures the relationships between words in the input.
2. Multi-head self-attention
The core component of the transformer block architecture is the multi-head self-attention mechanism, which allows the model to attend to different parts of the input sequence to capture its relationships and dependencies.
3. Feed-forward network
After the self-attention mechanism, the output is fed into a feed-forward neural network, which performs a non-linear transformation to generate a new representation.
4. Normalization and residual connections
To stabilize the training process, the output from each layer is normalized, and a residual connection is added to allow the input to be passed directly to the output, allowing the model to learn which parts of the input are most important.
These components are repeated several times to form a deep neural network, which can process long sequences of text and generate high-quality outputs for various language tasks, such as text generation, question answering, and translation.
Developers continue to develop large language models by implementing new techniques to:
- Simplify the model (decrease model size or memory required to train),
- Improve performance,
- Lower price,
- Decrease model training time.
Training large language models
There are four steps to training large language models:
1. Data collection and preprocessing
The first step is to gather the training data set, which is the resource that the LLM will be trained on. The data can come from various sources such as books, websites, articles, and open datasets.
Popular public sources to find datasets are:
- Kaggle
- Google Dataset Search
- Hugging Face
- Data.gov
- Wikipedia database
The data then needs to be cleaned and prepared for training. This may involve converting the dataset to lowercase, removing stop words, and tokenizing the text into sequences of tokens that make up the text.
2. Model selection and configuration
Large models such as Google’s BERT and OpenAI’s GPT-3 both use transformer deep learning architecture, which is the common choice for sophisticated NLP applications in recent years. Some key elements of the model such as:
- Number of layers in transformer blocks
- Number of attention heads
- Loss function
- Hyperparameters
need to be specified when configuring a transformer neural network. The configuration can depend on the desired use case and the training data. The configuration of the model directly influences the training time of the model.
3. Model training
The model is trained on the pre-processed text data using supervised learning. During training, the model is presented with a sequence of words and is trained to predict the next word in the sequence. The model adjusts its weights based on the difference between its prediction and the actual next word. This process is repeated millions of times until the model reaches a satisfactory level of performance.
Since the models and data are large in size, it requires immense computation power to train models. To decrease training time, a technique called model parallelism is used. Model parallelism enables different parts of a large model to be spread across multiple GPUs, allowing the model to be trained in a distributed manner with AI chips.
By dividing the model into smaller parts, each part can be trained in parallel, resulting in a faster training process compared to training the entire model on a single GPU or processor. This results in faster convergence and better overall performance, making it possible to train even larger language models than before. Common types of model parallelism include:
Training a large language model from the ground up requires significant investment, a more economical alternative is to fine-tune an existing language model to tailor it to your specific use case. A single training run for GPT-3 is estimated to cost around $5 million.
4. Evaluation and fine-tuning
After training, the model is evaluated on a test dataset that has not been used as a training data set to measure the model’s performance. Based on the evaluation results, the model may require some fine-tuning by adjusting its hyperparameters, changing the architecture, or training on additional data to improve its performance.
If you have further questions on large language models, do not hesitate to contact us:
- Wodecki, Ben (July 22, 2022). “7 language models you need to know“. AI Business. Retrieved February 3, 2023.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. Neural Information Processing Systems, 30, 5998–6008. https://arxiv.org/pdf/1706.03762v5

Berke is an industry analyst at AIMultiple. His passion for emerging tech and writing led him to pursue a career in IT consultancy, specializing in Extended Reality (AR, VR, MR) and conversational AI.
Berke earned his degrees in Business Administration and Mechanical Engineering at Koç University.

Large language models (LLMs) took the internet by storm at the end of 2022 as ChatGPT from OpenAI reached 1 million users just 5 days after its launch. ChatGPT’s capabilities and wide applications can be accredited to the 175 billion parameters the GPT-3 language model has.
Although it is easy to use end-product language models like ChatGPT, developing a large language model takes significant computer science knowledge, time, and resources. We created this article to inform business leaders on:
- Definition of large language models
- Examples of large language models
- Architecture of large language models
- The training process of large language models,
So that they can leverage artificial intelligence and machine learning effectively.
What is a large language model?
A large language model is a type of machine learning model that is trained on a large corpus of text data to generate outputs for various natural language processing (NLP) tasks, such as text generation, question answering, and machine translation.
Large language models are typically based on deep learning neural networks such as the Transformer architecture and are trained on massive amounts of text data, often involving billions of words. Larger models, such as Google’s BERT model, are trained with a large dataset from various data sources which allows them to generate output for many tasks.
Top large language models by parameter size
We compiled the 7 largest large language models by parameter size in the table below.1
| Model | Developer | Parameter Size |
|---|---|---|
| WuDao 2.0 | Beijing Academy of Artificial Intelligence | 1.75 trillion |
| MT-NLG | Nvidia and Microsoft | 530 billion |
| Bloom | Hugging Face and BigScience | 176 billion |
| GPT-3 | OpenAI | 175 billion |
| LaMDA | 137 billion | |
| ESMFold | Meta AI | 15 billion |
| Gato | DeepMind | 1.18 billion |
Architecture of large language models
The architecture of large language models, such as OpenAI’s GPT-3, is based on a type of deep learning called the Transformer architecture. It consists of the following main components (see Figure 1):
Figure 1: Transformer architecture
Source:2
1. Input embedding
The input sequence is first transformed into a dense vector representation, known as an embedding, which captures the relationships between words in the input.
2. Multi-head self-attention
The core component of the transformer block architecture is the multi-head self-attention mechanism, which allows the model to attend to different parts of the input sequence to capture its relationships and dependencies.
3. Feed-forward network
After the self-attention mechanism, the output is fed into a feed-forward neural network, which performs a non-linear transformation to generate a new representation.
4. Normalization and residual connections
To stabilize the training process, the output from each layer is normalized, and a residual connection is added to allow the input to be passed directly to the output, allowing the model to learn which parts of the input are most important.
These components are repeated several times to form a deep neural network, which can process long sequences of text and generate high-quality outputs for various language tasks, such as text generation, question answering, and translation.
Developers continue to develop large language models by implementing new techniques to:
- Simplify the model (decrease model size or memory required to train),
- Improve performance,
- Lower price,
- Decrease model training time.
Training large language models
There are four steps to training large language models:
1. Data collection and preprocessing
The first step is to gather the training data set, which is the resource that the LLM will be trained on. The data can come from various sources such as books, websites, articles, and open datasets.
Popular public sources to find datasets are:
- Kaggle
- Google Dataset Search
- Hugging Face
- Data.gov
- Wikipedia database
The data then needs to be cleaned and prepared for training. This may involve converting the dataset to lowercase, removing stop words, and tokenizing the text into sequences of tokens that make up the text.
2. Model selection and configuration
Large models such as Google’s BERT and OpenAI’s GPT-3 both use transformer deep learning architecture, which is the common choice for sophisticated NLP applications in recent years. Some key elements of the model such as:
- Number of layers in transformer blocks
- Number of attention heads
- Loss function
- Hyperparameters
need to be specified when configuring a transformer neural network. The configuration can depend on the desired use case and the training data. The configuration of the model directly influences the training time of the model.
3. Model training
The model is trained on the pre-processed text data using supervised learning. During training, the model is presented with a sequence of words and is trained to predict the next word in the sequence. The model adjusts its weights based on the difference between its prediction and the actual next word. This process is repeated millions of times until the model reaches a satisfactory level of performance.
Since the models and data are large in size, it requires immense computation power to train models. To decrease training time, a technique called model parallelism is used. Model parallelism enables different parts of a large model to be spread across multiple GPUs, allowing the model to be trained in a distributed manner with AI chips.
By dividing the model into smaller parts, each part can be trained in parallel, resulting in a faster training process compared to training the entire model on a single GPU or processor. This results in faster convergence and better overall performance, making it possible to train even larger language models than before. Common types of model parallelism include:
Training a large language model from the ground up requires significant investment, a more economical alternative is to fine-tune an existing language model to tailor it to your specific use case. A single training run for GPT-3 is estimated to cost around $5 million.
4. Evaluation and fine-tuning
After training, the model is evaluated on a test dataset that has not been used as a training data set to measure the model’s performance. Based on the evaluation results, the model may require some fine-tuning by adjusting its hyperparameters, changing the architecture, or training on additional data to improve its performance.
If you have further questions on large language models, do not hesitate to contact us:
- Wodecki, Ben (July 22, 2022). “7 language models you need to know“. AI Business. Retrieved February 3, 2023.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. Neural Information Processing Systems, 30, 5998–6008. https://arxiv.org/pdf/1706.03762v5
Berke is an industry analyst at AIMultiple. His passion for emerging tech and writing led him to pursue a career in IT consultancy, specializing in Extended Reality (AR, VR, MR) and conversational AI.
Berke earned his degrees in Business Administration and Mechanical Engineering at Koç University.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.