
LLM Fine-Tuning Strategies for Domain-Specific Applications
Large language models(LLMs) are advanced artificial intelligence(AI) models engineered to understand human language as well as generate human-like responses. These are trained on a large amount of text data sets — hence the name “large” — built on a type of neural network called a transformer model. These are used in chatbots and virtual assistants, content generation, summarization, translation, code generation, etc.
A notable feature of LLMs is their ability to be fine-tuned. These can be further trained to enhance their overall performance and allow them to adapt to new, specialized domains, showcasing their adaptability and versatility.
What Is LLM Fine-Tuning?
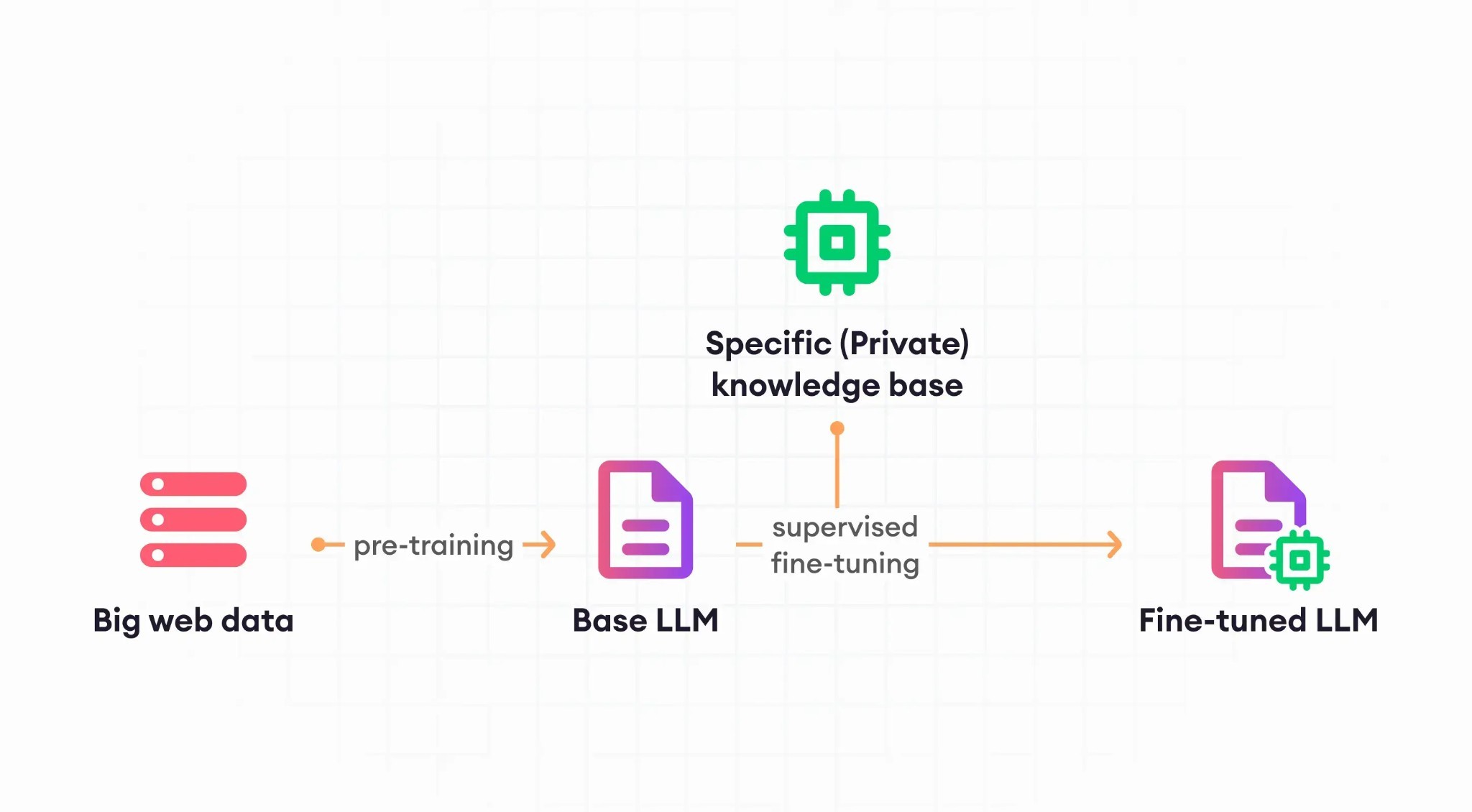
Large language models (LLMs) are powerful AI models trained on massive amounts of data from various domains. While these pre-trained models can perform well in general scenarios, they may not be perfectly suited for specific tasks or domains. Fine-tuning is a technique that bridges this gap by adapting an LLM to a specific domain or task.
Imagine ChatGPT as a general-purpose language model capable of understanding and responding to user queries. However, when applied as an assistant on a website, ChatGPT might not always provide relevant or accurate answers due to the unique context and requirements of the website. This is where fine-tuning comes into play.
Fine-tuning involves training the LLM on a dataset specifically curated for the target domain or task. This dataset contains examples of the desired responses, allowing the LLM to learn the nuances and expectations of the particular application. By comparing its generated outputs to the labeled examples, the LLM adjusts its parameters, gradually refining its ability to produce contextually relevant and accurate responses.
The fine-tuning process typically includes the following steps:
1. Data Selection or Generation: A dataset specific to the domain or task is either selected or generated. This dataset should contain examples of the desired responses, such as correct answers to user queries or well-structured summaries of text.
2. Data Splitting: The dataset is divided into training and testing sets.
3. Model Training: The training set is fed to the LLM, and the model generates outputs based on its current understanding of the language. These outputs are then compared to the corresponding labeled examples to calculate the difference or error.
4. Parameter Adjustment: The LLM uses the calculated error to adjust its parameters, and the weights associated with its internal connections. This adjustment process is repeated over multiple iterations, allowing the LLM to gradually learn the patterns and relationships within the domain-specific data.
5. Performance Evaluation: The fine-tuned LLM is evaluated on the testing set to assess its improvement in handling the specific domain or task.
Fine-tuning is an essential technique for enhancing the performance and applicability of LLMs in real-world scenarios. By adapting these powerful models to specific domains and tasks, we can unlock their full potential and revolutionize various industries.
Fine Tuning Strategies for Domain-Specific Applications
There are various LLM fine-tuning strategies for domain-specific applications. We will dive into a few of the popular methods:
Prompt Engineering
The prompt engineering fine-tuning strategy involves using the model’s context window and considerably crafted prompts to guide the model to generate the desired output. This method uses the model’s language comprehension and reasoning abilities to produce task-specific outputs without modifying internal architecture.
One-shot learning or few-shot learning can be used to provide examples along with the prompt for the model to learn from. The model then generates output to new prompts based on this data.
This is a very efficient and flexible way of fine-tuning, but adding examples might require a considerable amount of storage, and thus, this might not be suitable for smaller models.
Full Fine-Tuning
Full fine-tuning, as the name suggests, requires training every parameter in the basic model to adapt to the given task. This resulting model is highly tailored with great performance.
This fine-tuning method is not often used due to the cost involved in terms of resources and computations. Therefore, other models requiring less cost can be used to train a few parameters to get almost similar results.
Instruction or Supervised Fine-Tuning
One of the strategies to fine-tune the LLM model is supervised fine-tuning. It involves training the machine learning model with the example of the prompt as well as the response to that prompt. It aims to provide detailed instructions to the model rather than within the context window.
Sometimes when a model learns new information, the weights are updated and some information may be lost due to minimized weights. This phenomenon is known as catastrophic forgetting. We aim to minimize catastrophic forgetting, i.e., previously learned information while learning new things.
Parameter Efficient Fine-Tuning (PEFT)
Parameter efficient tuning is a tuning method that retains or “freezes” the model’s pre-trained parameters and only fine-tuning small subset. In this way, we can minimize catastrophic forgetting, as original LLM are preserved and only task-specific parameters are tuned.
It is a balance between retaining valuable pre-trained knowledge and adapting to specific tasks with fewer parameters, and minimal catastrophic forgetting, reduced computational and storage expenses associated with traditional fine-tuning.
Another advantage of PEFT is they can be swapped in and out of models, i.e., one model can be tuned to accomplish a task traditionally meant for a different model.
Low-Rank Adaptation (LoRA)
LoRA is a variation of PEFT in which another set of parameters are added to the network weight parameters. In a lower dimensional space than regular parameters, these low dimensional parameters are the only ones modified. The remaining parameters are frozen.
LoRA uses singular value decomposition (SVD) to transform high-rank matrices into low-rank matrices. LoRA adapters are modular and can be preserved and employed independently as distinct modules in different models.
Conclusion
LLM fine-tuning is a two-step process that includes pre-training the model with a huge amount of data and fine-tuning the model for domain-specific learning.
Prompt engineering makes use of the model’s context window to generate prompts and generate desired output. Supervised or instruction fine-tuning is similar to prompt engineering except that it provides detailed instructions to the model.
Full fine-tuning trains every parameter and results in a highly tailored model which can be costly. PEFT involves preserving the pre-trained parameters and only tuning on a small subset of parameters reducing the risk of catastrophic forgetting. LoRA is a variation of PEFT that allows additional parameters to be added to the network of weight.
Large language models(LLMs) are advanced artificial intelligence(AI) models engineered to understand human language as well as generate human-like responses. These are trained on a large amount of text data sets — hence the name “large” — built on a type of neural network called a transformer model. These are used in chatbots and virtual assistants, content generation, summarization, translation, code generation, etc.
A notable feature of LLMs is their ability to be fine-tuned. These can be further trained to enhance their overall performance and allow them to adapt to new, specialized domains, showcasing their adaptability and versatility.
What Is LLM Fine-Tuning?
Large language models (LLMs) are powerful AI models trained on massive amounts of data from various domains. While these pre-trained models can perform well in general scenarios, they may not be perfectly suited for specific tasks or domains. Fine-tuning is a technique that bridges this gap by adapting an LLM to a specific domain or task.
Imagine ChatGPT as a general-purpose language model capable of understanding and responding to user queries. However, when applied as an assistant on a website, ChatGPT might not always provide relevant or accurate answers due to the unique context and requirements of the website. This is where fine-tuning comes into play.
Fine-tuning involves training the LLM on a dataset specifically curated for the target domain or task. This dataset contains examples of the desired responses, allowing the LLM to learn the nuances and expectations of the particular application. By comparing its generated outputs to the labeled examples, the LLM adjusts its parameters, gradually refining its ability to produce contextually relevant and accurate responses.
The fine-tuning process typically includes the following steps:
1. Data Selection or Generation: A dataset specific to the domain or task is either selected or generated. This dataset should contain examples of the desired responses, such as correct answers to user queries or well-structured summaries of text.
2. Data Splitting: The dataset is divided into training and testing sets.
3. Model Training: The training set is fed to the LLM, and the model generates outputs based on its current understanding of the language. These outputs are then compared to the corresponding labeled examples to calculate the difference or error.
4. Parameter Adjustment: The LLM uses the calculated error to adjust its parameters, and the weights associated with its internal connections. This adjustment process is repeated over multiple iterations, allowing the LLM to gradually learn the patterns and relationships within the domain-specific data.
5. Performance Evaluation: The fine-tuned LLM is evaluated on the testing set to assess its improvement in handling the specific domain or task.
Fine-tuning is an essential technique for enhancing the performance and applicability of LLMs in real-world scenarios. By adapting these powerful models to specific domains and tasks, we can unlock their full potential and revolutionize various industries.
Fine Tuning Strategies for Domain-Specific Applications
There are various LLM fine-tuning strategies for domain-specific applications. We will dive into a few of the popular methods:
Prompt Engineering
The prompt engineering fine-tuning strategy involves using the model’s context window and considerably crafted prompts to guide the model to generate the desired output. This method uses the model’s language comprehension and reasoning abilities to produce task-specific outputs without modifying internal architecture.
One-shot learning or few-shot learning can be used to provide examples along with the prompt for the model to learn from. The model then generates output to new prompts based on this data.
This is a very efficient and flexible way of fine-tuning, but adding examples might require a considerable amount of storage, and thus, this might not be suitable for smaller models.
Full Fine-Tuning
Full fine-tuning, as the name suggests, requires training every parameter in the basic model to adapt to the given task. This resulting model is highly tailored with great performance.
This fine-tuning method is not often used due to the cost involved in terms of resources and computations. Therefore, other models requiring less cost can be used to train a few parameters to get almost similar results.
Instruction or Supervised Fine-Tuning
One of the strategies to fine-tune the LLM model is supervised fine-tuning. It involves training the machine learning model with the example of the prompt as well as the response to that prompt. It aims to provide detailed instructions to the model rather than within the context window.
Sometimes when a model learns new information, the weights are updated and some information may be lost due to minimized weights. This phenomenon is known as catastrophic forgetting. We aim to minimize catastrophic forgetting, i.e., previously learned information while learning new things.
Parameter Efficient Fine-Tuning (PEFT)
Parameter efficient tuning is a tuning method that retains or “freezes” the model’s pre-trained parameters and only fine-tuning small subset. In this way, we can minimize catastrophic forgetting, as original LLM are preserved and only task-specific parameters are tuned.
It is a balance between retaining valuable pre-trained knowledge and adapting to specific tasks with fewer parameters, and minimal catastrophic forgetting, reduced computational and storage expenses associated with traditional fine-tuning.
Another advantage of PEFT is they can be swapped in and out of models, i.e., one model can be tuned to accomplish a task traditionally meant for a different model.
Low-Rank Adaptation (LoRA)
LoRA is a variation of PEFT in which another set of parameters are added to the network weight parameters. In a lower dimensional space than regular parameters, these low dimensional parameters are the only ones modified. The remaining parameters are frozen.
LoRA uses singular value decomposition (SVD) to transform high-rank matrices into low-rank matrices. LoRA adapters are modular and can be preserved and employed independently as distinct modules in different models.
Conclusion
LLM fine-tuning is a two-step process that includes pre-training the model with a huge amount of data and fine-tuning the model for domain-specific learning.
Prompt engineering makes use of the model’s context window to generate prompts and generate desired output. Supervised or instruction fine-tuning is similar to prompt engineering except that it provides detailed instructions to the model.
Full fine-tuning trains every parameter and results in a highly tailored model which can be costly. PEFT involves preserving the pre-trained parameters and only tuning on a small subset of parameters reducing the risk of catastrophic forgetting. LoRA is a variation of PEFT that allows additional parameters to be added to the network of weight.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.