
Making Causal Discovery work in real-world business settings
Causal AI, exploring the integration of causal reasoning into machine learning
What is this series of articles about?
Welcome to my series on Causal AI, where we will explore the integration of causal reasoning into machine learning models. Expect to explore a number of practical applications across different business contexts.
In the first article we explored using Causal Graphs to answer causal questions. This time round we will delve into making Causal Discovery work in real-world business settings.
If you missed the first article on Causal Graphs, check it out here:
Using Causal Graphs to answer causal questions
Introduction
This article aims to help you navigate the world of causal discovery.
It is aimed at anyone who wants to understand more about:
- What causal discovery is, including what assumptions it makes.
- A deep dive into conditional independence tests, the building blocks of causal discovery.
- An overview of the PC algorithm, a popular causal discovery algorithm.
- A worked case study in Python illustrating how to apply the PC algorithm.
- Guidance on making causal discovery work in real-world business settings.
The full notebook can be found here:
What is Causal Discovery?
In my last article, I covered how causal graphs could be used to answer causal questions.
Often referred to as a DAG (directed acyclic graph), a causal graph contains nodes and edges — Edges link nodes that causally related.
There are two ways to determine a causal graph:
- Expert domain knowledge
- Causal discovery algorithms
We don’t always have the expert domain knowledge to determine a causal graph. In this notebook we will explore how to take observational data and determine the causal graph using causal discovery algorithms.
Algorithms
Causal discovery is a heavily researched area in academia with four groups of methods proposed:
It isn’t clear from currently available research which method is best. One of the challenges in answering this question is the lack of realistic ground truth benchmark datasets.
In this blog we are going to focus on understanding the PC algorithm, a constraint-based method that uses conditional independence tests.
Assumptions
Before we introduce the PC algorithm, let’s cover the key assumptions made by causal discovery algorithms:
- Causal Markov Condition: Each variable is conditionally independent of its non-descendants, given its direct causes. This tells us that if we know the causes of a variable, we don’t gain any additional power by knowing the variables that are not directly influenced by those causes. This fundamental assumption simplifies the modelling of causal relationships enabling us to make causal inferences.
- Causal Faithfulness: If statistical independence holds in the data, then there is no direct causal relationships between the corresponding variables. Testing this assumption is challenging and violations may indicate model misspecification or missing variables.
- Causal Sufficiency: Are the variables included sufficient to make causal claims about the variables of interest? In other words, we need all confounders of the variables included to be observed. Testing this assumption involves sensitivity analysis which assesses the impact of potentially unobserved confounders.
- Acyclicity: No cycles in the graph.
In practice, while these assumptions are necessary for causal discovery, they are often treated as assumptions rather than directly tested.
Even with making these assumptions, we can end up with a Markov equivalence class. We have a Markov equivalence class when we have multiple causal graphs each as likely as each other.
Conditional Independence tests
Conditional independence tests are the building blocks of causal discovery and are used by the PC algorithm (which we will cover shortly).
Let’s start by understanding independence. Independence between two variables implies that knowing the value of one variable provides no information about the value of the other. In this case, it is fairly safe to assume that neither directly causes the other. However, if two variables aren’t independent, it would be wrong to blindly assume causation.
Conditional independence tests can be used to determine whether two variables are independent of each other given the presence of one or more other variables. If two variables are conditionally independent, we can then infer that they are not causally related.
The Fisher’s exact test can be used to determine if there is a significant association between two variables whilst controlling for the effects of one or more additional variables (use the additional variables to split the data into subsets, the test can then be applied to each subset of data). The null hypothesis assumes that there is no association between the two variables of interest. A p-value can then be calculated and if it is below 0.05 the null hypothesis will be rejected suggesting that there is significant association between the variables.
Identifying spurious correlations
We can use an example of a spurious correlation to illustrate how to use conditional independence tests.
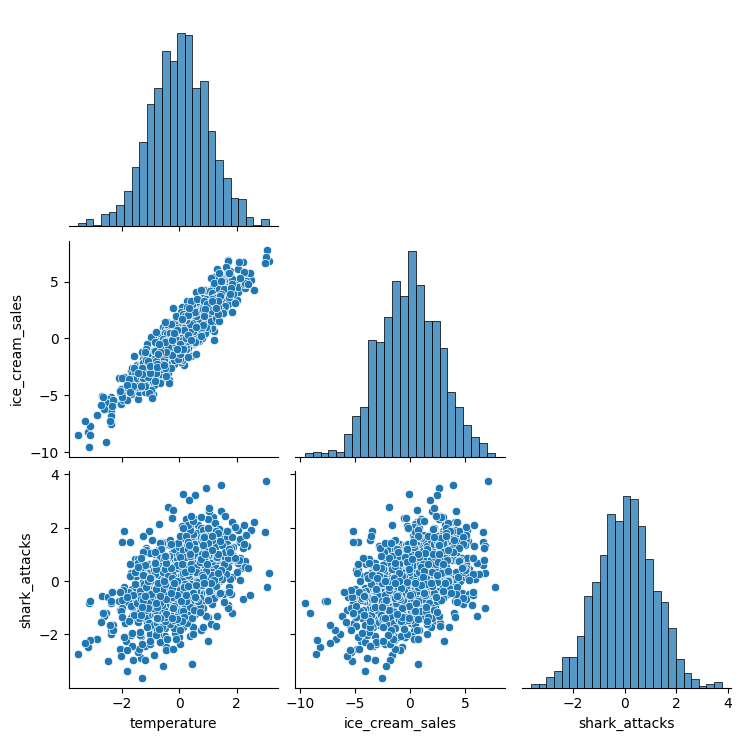
Two variables have a spurious correlation when they have a common cause e.g. High temperatures increasing the number of ice cream sales and shark attacks.
np.random.seed(999)
# Create dataset with spurious correlation
temperature = np.random.normal(loc=0, scale=1, size=1000)
ice_cream_sales = 2.5 * temperature + np.random.normal(loc=0, scale=1, size=1000)
shark_attacks = 0.5 * temperature + np.random.normal(loc=0, scale=1, size=1000)
df_spurious = pd.DataFrame(data=dict(temperature=temperature, ice_cream_sales=ice_cream_sales, shark_attacks=shark_attacks))
# Pairplot
sns.pairplot(df_spurious, corner=True)
# Create node lookup variables
node_lookup = {0: 'Temperature',
1: 'Ice cream sales',
2: 'Shark attacks'
}
total_nodes = len(node_lookup)
# Create adjacency matrix - this is the base for our graph
graph_actual = np.zeros((total_nodes, total_nodes))
# Create graph using expert domain knowledge
graph_actual[0, 1] = 1.0 # Temperature -> Ice cream sales
graph_actual[0, 2] = 1.0 # Temperature -> Shark attacks
plot_graph(input_graph=graph_actual, node_lookup=node_lookup)

The following conditional independence tests can be used to determine the causal graph:
# Run first conditional independence test
test_id_1 = round(gcm.independence_test(ice_cream_sales, shark_attacks, conditioned_on=temperature), 2)
# Run second conditional independence test
test_id_2 = round(gcm.independence_test(ice_cream_sales, temperature, conditioned_on=shark_attacks), 2)
# Run third conditional independence test
test_id_3 = round(gcm.independence_test(shark_attacks, temperature, conditioned_on=ice_cream_sales), 2)

Although we don’t know the direction of the relationships, we can correctly infer that temperature is causally related to both ice cream sales and shark attacks.
PC algorithm
The PC algorithm (named after its inventors Peter and Clark) is a constraint-based causal discovery algorithm that uses conditional independence tests.
It can be summarised into 2 main steps:
- It starts with a fully connected graph and then uses conditional independence tests to remove edges and identify the undirected causal graph (nodes linked but with no direction).
- It then (partially) directs the edges using various orientation tricks.
We can use the previous spurious correlation example to illustrate the first step:
- Start with a fully connected graph
- Test ID 1: Accept the null hypothesis and delete edge, no causal link between ice cream sales and shark attacks
- Test ID 2: Reject the null hypothesis and keep the edge, causal link between ice cream sales and temperature
- Test ID 3: Reject the null hypothesis and keep the edge, causal link between shark attacks and ice cream sales
Evaluating results
One of the key challenges in causal discovery is evaluating the results. If we knew the causal graph, we wouldn’t need to apply a causal discovery algorithm! However, we can create synthetic datasets to evaluate how well causal discovery algorithms perform.
There are several metrics we can use to evaluate causal discovery algorithms:

- True positives: Identify causal link correctly
- False positives: Identify causal link incorrectly
- True negatives: Correctly identify no causal link
- False negatives: Incorrectly identify no causal link
- Reversed edges: Identify causal link correctly but in the wrong direction
We want a high number of True positives, but this should not be at the expense of a high number of False positives (as when we come to build an SCM, wrong causal links can be very damaging). Therefore GScore seems to capture this well whilst giving an interpretable ratio between 0 and 1.
Call Centre case study
We will revisit the call centre case study from my previous article. First of all, we determine the causal graph (to be used as ground truth) and then use our knowledge of the data-generating process to create some samples.
The ground truth causal graph and generated samples will enable us to evaluate the PC algorithm.
# Create node lookup for channels
node_lookup = {0: 'Demand',
1: 'Call waiting time',
2: 'Call abandoned',
3: 'Reported problems',
4: 'Discount sent',
5: 'Churn'
}
total_nodes = len(node_lookup)
# Create adjacency matrix - this is the base for our graph
graph_actual = np.zeros((total_nodes, total_nodes))
# Create graph using expert domain knowledge
graph_actual[0, 1] = 1.0 # Demand -> Call waiting time
graph_actual[0, 2] = 1.0 # Demand -> Call abandoned
graph_actual[0, 3] = 1.0 # Demand -> Reported problems
graph_actual[1, 2] = 1.0 # Call waiting time -> Call abandoned
graph_actual[1, 5] = 1.0 # Call waiting time -> Churn
graph_actual[2, 3] = 1.0 # Call abandoned -> Reported problems
graph_actual[2, 5] = 1.0 # Call abandoned -> Churn
graph_actual[3, 4] = 1.0 # Reported problems -> Discount sent
graph_actual[3, 5] = 1.0 # Reported problems -> Churn
graph_actual[4, 5] = 1.0 # Discount sent -> Churn
plot_graph(input_graph=graph_actual, node_lookup=node_lookup)

def data_generator(max_call_waiting, inbound_calls, call_reduction):
'''
A data generating function that has the flexibility to reduce the value of node 0 (Call waiting time) - this enables us to calculate ground truth counterfactuals
Args:
max_call_waiting (int): Maximum call waiting time in seconds
inbound_calls (int): Total number of inbound calls (observations in data)
call_reduction (float): Reduction to apply to call waiting time
Returns:
DataFrame: Generated data
'''
df = pd.DataFrame(columns=node_lookup.values())
df[node_lookup[0]] = np.random.randint(low=10, high=max_call_waiting, size=(inbound_calls)) # Demand
df[node_lookup[1]] = (df[node_lookup[0]] * 0.5) * (call_reduction) + np.random.normal(loc=0, scale=40, size=inbound_calls) # Call waiting time
df[node_lookup[2]] = (df[node_lookup[1]] * 0.5) + (df[node_lookup[0]] * 0.2) + np.random.normal(loc=0, scale=30, size=inbound_calls) # Call abandoned
df[node_lookup[3]] = (df[node_lookup[2]] * 0.6) + (df[node_lookup[0]] * 0.3) + np.random.normal(loc=0, scale=20, size=inbound_calls) # Reported problems
df[node_lookup[4]] = (df[node_lookup[3]] * 0.7) + np.random.normal(loc=0, scale=10, size=inbound_calls) # Discount sent
df[node_lookup[5]] = (0.10 * df[node_lookup[1]] ) + (0.30 * df[node_lookup[2]]) + (0.15 * df[node_lookup[3]]) + (-0.20 * df[node_lookup[4]]) # Churn
return df
# Generate data
np.random.seed(999)
df = data_generator(max_call_waiting=600, inbound_calls=10000, call_reduction=1.00)
# Pairplot
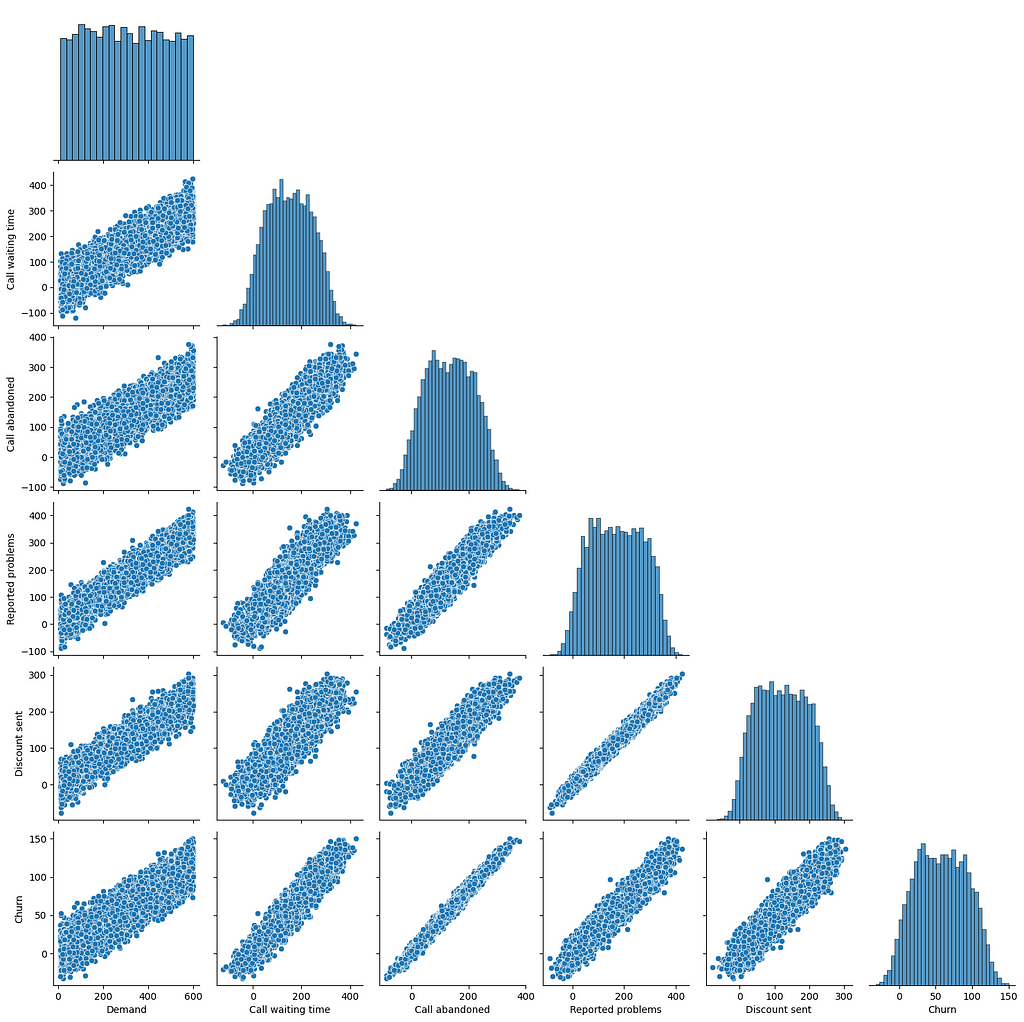
sns.pairplot(df, corner=True)
Applying the PC algorithm
The Python package gCastle has several causal discovery algorithms implemented, including the PC algorithm:
trustworthyAI/gcastle at master · huawei-noah/trustworthyAI
When we feed the algorithm our samples we receive back the learned causal graph (in the form of an adjacency matrix).
# Apply PC method to learn graph
pc = PC(variant='stable')
pc.learn(df)
graph_pred = pc.causal_matrix
graph_pred

gCastle also has several evaluation metrics available, including gScore. The GScore of our learned graph is 0! Why has it done so poorly?
# GScore
metrics = MetricsDAG(
B_est=graph_pred,
B_true=graph_actual)
metrics.metrics['gscore']

On closer inspection of the learned graph, we can see that it correctly identified the undirected graph and then struggled to orient the edges.
plot_graph(input_graph=graph_pred, node_lookup=node_lookup)

Evaluating the undirected graph
To build on the learning from applying the PC algorithm, we can use gCastle to extract the undirected causal graph that was learned.
# Apply PC method to learn skeleton
skeleton_pred, sep_set = find_skeleton(df.to_numpy(), 0.05, 'fisherz')
skeleton_pred

If we transform our ground truth graph into an undirected adjacency matrix, we can then use it to calculate the Gscore of the undirected graph.
# Transform the ground truth graph into an undirected adjacency matrix
skeleton_actual = graph_actual + graph_actual.T
skeleton_actual = np.where(skeleton_actual > 0, 1, 0)
Using the learned undirected causal graph we get a GScore of 1.00.
# GScore
metrics = MetricsDAG(
B_est=skeleton_pred,
B_true=skeleton_actual)
metrics.metrics['gscore']
We have accurately learned an undirected graph — could we use expert domain knowledge to direct the edges? The answer to this will vary across different use cases, but it is a reasonable strategy.
plot_graph(input_graph=skeleton_pred, node_lookup=node_lookup)

Making Causal Discovery work in real-world business settings
We need to start seeing causal discovery as an essential EDA step in any causal inference project:
- However, we also need to be transparent about its limitations.
- Causal discovery is a tool that needs complementing with expert domain knowledge.
Be pragmatic with the assumptions:
- Can we ever expect to observe all confounders? Probably not. However, with the correct domain knowledge and extensive data gathering, it is feasible that we could observe all the key confounders.
Pick an algorithm where we can apply constraints to incorporate expert domain knowledge — gCastle allows us to apply constraints to the PC algorithm:
- Initially work on identifying the undirected causal graph and then share this output with domain experts and use them to help orient the graph.
Be cautious when using proxy variables and consider enforcing constraints on relationships we strongly believe exist:
- For example, if include Google trends data as a proxy for product demand, we may need to enforce constraints in terms of this driving sales.
Future work
- What if we have non-linear relationships? Can the PC algorithm handle this?
- What happens if we have unobserved confounders? Can the FCI algorithm deal with this situation effectively?
- How do constraint-based, score-based, functional-based and gradient-based methods compare?
Follow me if you want to continue this journey into Causal AI — In the next article we will understand how Double Machine Learning can help de-bias treatment effects.
Making Causal Discovery work in real-world business settings was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Causal AI, exploring the integration of causal reasoning into machine learning
What is this series of articles about?
Welcome to my series on Causal AI, where we will explore the integration of causal reasoning into machine learning models. Expect to explore a number of practical applications across different business contexts.
In the first article we explored using Causal Graphs to answer causal questions. This time round we will delve into making Causal Discovery work in real-world business settings.
If you missed the first article on Causal Graphs, check it out here:
Using Causal Graphs to answer causal questions
Introduction
This article aims to help you navigate the world of causal discovery.
It is aimed at anyone who wants to understand more about:
- What causal discovery is, including what assumptions it makes.
- A deep dive into conditional independence tests, the building blocks of causal discovery.
- An overview of the PC algorithm, a popular causal discovery algorithm.
- A worked case study in Python illustrating how to apply the PC algorithm.
- Guidance on making causal discovery work in real-world business settings.
The full notebook can be found here:
What is Causal Discovery?
In my last article, I covered how causal graphs could be used to answer causal questions.
Often referred to as a DAG (directed acyclic graph), a causal graph contains nodes and edges — Edges link nodes that causally related.
There are two ways to determine a causal graph:
- Expert domain knowledge
- Causal discovery algorithms
We don’t always have the expert domain knowledge to determine a causal graph. In this notebook we will explore how to take observational data and determine the causal graph using causal discovery algorithms.
Algorithms
Causal discovery is a heavily researched area in academia with four groups of methods proposed:
It isn’t clear from currently available research which method is best. One of the challenges in answering this question is the lack of realistic ground truth benchmark datasets.

In this blog we are going to focus on understanding the PC algorithm, a constraint-based method that uses conditional independence tests.
Assumptions
Before we introduce the PC algorithm, let’s cover the key assumptions made by causal discovery algorithms:
- Causal Markov Condition: Each variable is conditionally independent of its non-descendants, given its direct causes. This tells us that if we know the causes of a variable, we don’t gain any additional power by knowing the variables that are not directly influenced by those causes. This fundamental assumption simplifies the modelling of causal relationships enabling us to make causal inferences.
- Causal Faithfulness: If statistical independence holds in the data, then there is no direct causal relationships between the corresponding variables. Testing this assumption is challenging and violations may indicate model misspecification or missing variables.
- Causal Sufficiency: Are the variables included sufficient to make causal claims about the variables of interest? In other words, we need all confounders of the variables included to be observed. Testing this assumption involves sensitivity analysis which assesses the impact of potentially unobserved confounders.
- Acyclicity: No cycles in the graph.
In practice, while these assumptions are necessary for causal discovery, they are often treated as assumptions rather than directly tested.
Even with making these assumptions, we can end up with a Markov equivalence class. We have a Markov equivalence class when we have multiple causal graphs each as likely as each other.
Conditional Independence tests
Conditional independence tests are the building blocks of causal discovery and are used by the PC algorithm (which we will cover shortly).
Let’s start by understanding independence. Independence between two variables implies that knowing the value of one variable provides no information about the value of the other. In this case, it is fairly safe to assume that neither directly causes the other. However, if two variables aren’t independent, it would be wrong to blindly assume causation.
Conditional independence tests can be used to determine whether two variables are independent of each other given the presence of one or more other variables. If two variables are conditionally independent, we can then infer that they are not causally related.
The Fisher’s exact test can be used to determine if there is a significant association between two variables whilst controlling for the effects of one or more additional variables (use the additional variables to split the data into subsets, the test can then be applied to each subset of data). The null hypothesis assumes that there is no association between the two variables of interest. A p-value can then be calculated and if it is below 0.05 the null hypothesis will be rejected suggesting that there is significant association between the variables.
Identifying spurious correlations
We can use an example of a spurious correlation to illustrate how to use conditional independence tests.
Two variables have a spurious correlation when they have a common cause e.g. High temperatures increasing the number of ice cream sales and shark attacks.
np.random.seed(999)
# Create dataset with spurious correlation
temperature = np.random.normal(loc=0, scale=1, size=1000)
ice_cream_sales = 2.5 * temperature + np.random.normal(loc=0, scale=1, size=1000)
shark_attacks = 0.5 * temperature + np.random.normal(loc=0, scale=1, size=1000)
df_spurious = pd.DataFrame(data=dict(temperature=temperature, ice_cream_sales=ice_cream_sales, shark_attacks=shark_attacks))
# Pairplot
sns.pairplot(df_spurious, corner=True)
# Create node lookup variables
node_lookup = {0: 'Temperature',
1: 'Ice cream sales',
2: 'Shark attacks'
}
total_nodes = len(node_lookup)
# Create adjacency matrix - this is the base for our graph
graph_actual = np.zeros((total_nodes, total_nodes))
# Create graph using expert domain knowledge
graph_actual[0, 1] = 1.0 # Temperature -> Ice cream sales
graph_actual[0, 2] = 1.0 # Temperature -> Shark attacks
plot_graph(input_graph=graph_actual, node_lookup=node_lookup)
The following conditional independence tests can be used to determine the causal graph:
# Run first conditional independence test
test_id_1 = round(gcm.independence_test(ice_cream_sales, shark_attacks, conditioned_on=temperature), 2)
# Run second conditional independence test
test_id_2 = round(gcm.independence_test(ice_cream_sales, temperature, conditioned_on=shark_attacks), 2)
# Run third conditional independence test
test_id_3 = round(gcm.independence_test(shark_attacks, temperature, conditioned_on=ice_cream_sales), 2)
Although we don’t know the direction of the relationships, we can correctly infer that temperature is causally related to both ice cream sales and shark attacks.
PC algorithm
The PC algorithm (named after its inventors Peter and Clark) is a constraint-based causal discovery algorithm that uses conditional independence tests.
It can be summarised into 2 main steps:
- It starts with a fully connected graph and then uses conditional independence tests to remove edges and identify the undirected causal graph (nodes linked but with no direction).
- It then (partially) directs the edges using various orientation tricks.
We can use the previous spurious correlation example to illustrate the first step:
- Start with a fully connected graph
- Test ID 1: Accept the null hypothesis and delete edge, no causal link between ice cream sales and shark attacks
- Test ID 2: Reject the null hypothesis and keep the edge, causal link between ice cream sales and temperature
- Test ID 3: Reject the null hypothesis and keep the edge, causal link between shark attacks and ice cream sales
Evaluating results
One of the key challenges in causal discovery is evaluating the results. If we knew the causal graph, we wouldn’t need to apply a causal discovery algorithm! However, we can create synthetic datasets to evaluate how well causal discovery algorithms perform.
There are several metrics we can use to evaluate causal discovery algorithms:
- True positives: Identify causal link correctly
- False positives: Identify causal link incorrectly
- True negatives: Correctly identify no causal link
- False negatives: Incorrectly identify no causal link
- Reversed edges: Identify causal link correctly but in the wrong direction
We want a high number of True positives, but this should not be at the expense of a high number of False positives (as when we come to build an SCM, wrong causal links can be very damaging). Therefore GScore seems to capture this well whilst giving an interpretable ratio between 0 and 1.
Call Centre case study
We will revisit the call centre case study from my previous article. First of all, we determine the causal graph (to be used as ground truth) and then use our knowledge of the data-generating process to create some samples.
The ground truth causal graph and generated samples will enable us to evaluate the PC algorithm.
# Create node lookup for channels
node_lookup = {0: 'Demand',
1: 'Call waiting time',
2: 'Call abandoned',
3: 'Reported problems',
4: 'Discount sent',
5: 'Churn'
}
total_nodes = len(node_lookup)
# Create adjacency matrix - this is the base for our graph
graph_actual = np.zeros((total_nodes, total_nodes))
# Create graph using expert domain knowledge
graph_actual[0, 1] = 1.0 # Demand -> Call waiting time
graph_actual[0, 2] = 1.0 # Demand -> Call abandoned
graph_actual[0, 3] = 1.0 # Demand -> Reported problems
graph_actual[1, 2] = 1.0 # Call waiting time -> Call abandoned
graph_actual[1, 5] = 1.0 # Call waiting time -> Churn
graph_actual[2, 3] = 1.0 # Call abandoned -> Reported problems
graph_actual[2, 5] = 1.0 # Call abandoned -> Churn
graph_actual[3, 4] = 1.0 # Reported problems -> Discount sent
graph_actual[3, 5] = 1.0 # Reported problems -> Churn
graph_actual[4, 5] = 1.0 # Discount sent -> Churn
plot_graph(input_graph=graph_actual, node_lookup=node_lookup)
def data_generator(max_call_waiting, inbound_calls, call_reduction):
'''
A data generating function that has the flexibility to reduce the value of node 0 (Call waiting time) - this enables us to calculate ground truth counterfactuals
Args:
max_call_waiting (int): Maximum call waiting time in seconds
inbound_calls (int): Total number of inbound calls (observations in data)
call_reduction (float): Reduction to apply to call waiting time
Returns:
DataFrame: Generated data
'''
df = pd.DataFrame(columns=node_lookup.values())
df[node_lookup[0]] = np.random.randint(low=10, high=max_call_waiting, size=(inbound_calls)) # Demand
df[node_lookup[1]] = (df[node_lookup[0]] * 0.5) * (call_reduction) + np.random.normal(loc=0, scale=40, size=inbound_calls) # Call waiting time
df[node_lookup[2]] = (df[node_lookup[1]] * 0.5) + (df[node_lookup[0]] * 0.2) + np.random.normal(loc=0, scale=30, size=inbound_calls) # Call abandoned
df[node_lookup[3]] = (df[node_lookup[2]] * 0.6) + (df[node_lookup[0]] * 0.3) + np.random.normal(loc=0, scale=20, size=inbound_calls) # Reported problems
df[node_lookup[4]] = (df[node_lookup[3]] * 0.7) + np.random.normal(loc=0, scale=10, size=inbound_calls) # Discount sent
df[node_lookup[5]] = (0.10 * df[node_lookup[1]] ) + (0.30 * df[node_lookup[2]]) + (0.15 * df[node_lookup[3]]) + (-0.20 * df[node_lookup[4]]) # Churn
return df
# Generate data
np.random.seed(999)
df = data_generator(max_call_waiting=600, inbound_calls=10000, call_reduction=1.00)
# Pairplot
sns.pairplot(df, corner=True)
Applying the PC algorithm
The Python package gCastle has several causal discovery algorithms implemented, including the PC algorithm:
trustworthyAI/gcastle at master · huawei-noah/trustworthyAI
When we feed the algorithm our samples we receive back the learned causal graph (in the form of an adjacency matrix).
# Apply PC method to learn graph
pc = PC(variant='stable')
pc.learn(df)
graph_pred = pc.causal_matrix
graph_pred
gCastle also has several evaluation metrics available, including gScore. The GScore of our learned graph is 0! Why has it done so poorly?
# GScore
metrics = MetricsDAG(
B_est=graph_pred,
B_true=graph_actual)
metrics.metrics['gscore']
On closer inspection of the learned graph, we can see that it correctly identified the undirected graph and then struggled to orient the edges.
plot_graph(input_graph=graph_pred, node_lookup=node_lookup)
Evaluating the undirected graph
To build on the learning from applying the PC algorithm, we can use gCastle to extract the undirected causal graph that was learned.
# Apply PC method to learn skeleton
skeleton_pred, sep_set = find_skeleton(df.to_numpy(), 0.05, 'fisherz')
skeleton_pred
If we transform our ground truth graph into an undirected adjacency matrix, we can then use it to calculate the Gscore of the undirected graph.
# Transform the ground truth graph into an undirected adjacency matrix
skeleton_actual = graph_actual + graph_actual.T
skeleton_actual = np.where(skeleton_actual > 0, 1, 0)
Using the learned undirected causal graph we get a GScore of 1.00.
# GScore
metrics = MetricsDAG(
B_est=skeleton_pred,
B_true=skeleton_actual)
metrics.metrics['gscore']
We have accurately learned an undirected graph — could we use expert domain knowledge to direct the edges? The answer to this will vary across different use cases, but it is a reasonable strategy.
plot_graph(input_graph=skeleton_pred, node_lookup=node_lookup)
Making Causal Discovery work in real-world business settings
We need to start seeing causal discovery as an essential EDA step in any causal inference project:
- However, we also need to be transparent about its limitations.
- Causal discovery is a tool that needs complementing with expert domain knowledge.
Be pragmatic with the assumptions:
- Can we ever expect to observe all confounders? Probably not. However, with the correct domain knowledge and extensive data gathering, it is feasible that we could observe all the key confounders.
Pick an algorithm where we can apply constraints to incorporate expert domain knowledge — gCastle allows us to apply constraints to the PC algorithm:
- Initially work on identifying the undirected causal graph and then share this output with domain experts and use them to help orient the graph.
Be cautious when using proxy variables and consider enforcing constraints on relationships we strongly believe exist:
- For example, if include Google trends data as a proxy for product demand, we may need to enforce constraints in terms of this driving sales.
Future work
- What if we have non-linear relationships? Can the PC algorithm handle this?
- What happens if we have unobserved confounders? Can the FCI algorithm deal with this situation effectively?
- How do constraint-based, score-based, functional-based and gradient-based methods compare?
Follow me if you want to continue this journey into Causal AI — In the next article we will understand how Double Machine Learning can help de-bias treatment effects.
Making Causal Discovery work in real-world business settings was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.