
Maximizing the Utility of Scarce AI Resources: A Kubernetes Approach
Optimizing the use of limited AI training accelerators
In the ever-evolving landscape of AI development, nothing rings truer than the old saying (attributed to Heraclitus), “the only constant in life is change”. In the case of AI, it seems that change is indeed constant, but the pace of change is forever increasing. Staying relevant in these unique and exciting times amounts to an unprecedented test of the capacity of AI teams to consistently adapt and adjust their development processes. AI development teams that fail to adapt, or are slow to adapt, may quickly become obsolete.
One of the most challenging developments of the past few years in AI development has been the increasing difficulty to attain the hardware required to train AI models. Whether it be due to an ongoing crisis in the global supply chain or a significant increase in the demand for AI chips, getting your hands on the GPUs (or alternative training accelerators) that you need for AI development, has gotten much harder. This is evidenced by the huge wait time for new GPU orders and by the fact that cloud service providers (CSPs) that once offered virtually infinite capacity of GPU machines, now struggle to keep up with the demand.
The changing times are forcing AI development teams that may have once relied on endless capacity of AI accelerators to adapt to a world with reduced accessibility and, in some cases, higher costs. Development processes that once took for granted the ability to spin up a new GPU machine at will, must be modified to meet the demands of a world of scarce AI resources that are often shared by multiple projects and/or teams. Those that fail to adapt risk annihilation.
In this post we will demonstrate the use of Kubernetes in the orchestration of AI-model training workloads in a world of scarce AI resources. We will start by specifying the goals we wish to achieve. We will then describe why Kubernetes is an appropriate tool for addressing this challenge. Last, we will provide a simple demonstration of how Kubernetes can be used to maximize the use of a scarce AI compute resource. In subsequent posts, we plan to enhance the Kubernetes-based solution and show how to apply it to a cloud-based training environment.
Disclaimers
While this post does not assume prior experience with Kubernetes, some basic familiarity would certainly be helpful. This post should not, in any way, be viewed as a Kubernetes tutorial. To learn about Kubernetes, we refer the reader to the many great online resources on the subject. Here we will discuss just a few properties of Kubernetes as they pertain to the topic of maximizing and prioritizing resource utilization.
There are many alternative tools and techniques to the method we put forth here, each with their own pros and cons. Our intention in this post is purely educational; Please do not view any of the choices we make as an endorsement.
Lastly, the Kubernetes platform remains under constant development, as do many of the frameworks and tools in the field of AI development. Please take into account the possibility that some of the statements, examples, and/or external links in this post may become outdated by the time you read this and be sure to take into account the most up-to-date solutions available before making your own design decisions.
Adapting to Scarce AI Compute Resources
To simplify our discussion, let’s assume that we have a single worker node at our disposal for training our models. This could be a local machine with a GPU or a reserved compute-accelerated instance in the cloud, such as a p5.48xlarge instance in AWS or a TPU node in GCP. In our example below we will refer to this node as “my precious”. Typically, we will have spent a lot of money on this machine. We will further assume that we have multiple training workloads all competing for our single compute resource where each workload could take anywhere from a few minutes to a few days. Naturally, we would like to maximize the utility of our compute resource by ensuring that it is in constant use and that the most important jobs get prioritized. What we need is some form of a priority queue and an associated priority-based scheduling algorithm. Let’s try to be a bit more specific about the behaviors that we desire.
Scheduling Requirements
- Maximize Utilization: We would like for our resource to be in constant use. Specifically, as soon as it completes a workload, it will promptly (and automatically) start working on a new one.
- Queue Pending Workloads: We require the existence of a queue of training workloads that are waiting to be processed by our unique resource. We also require associated APIs for creating and submitting new jobs to the queue, as well as monitoring and managing the state of the queue.
- Support Prioritization: We would like each training job to have an associated priority such that workloads with higher priority will be run before workloads with a lower priority.
- Preemption: Moreover, in the case that an urgent job is submitted to the queue while our resource is working on a lower priority job, we would like for the running job to be preempted and replaced by the urgent job. The preempted job should be returned to the queue.
One approach to developing a solution that satisfies these requirements could be to take an existing API for submitting jobs to a training resource and wrap it with a customized implementation of a priority queue with the desired properties. At a minimum, this approach would require a data structure for storing a list of pending jobs, a dedicated process for choosing and submitting jobs from the queue to the training resource, and some form of mechanism for identifying when a job has been completed and the resource has become available.
An alternative approach and the one we take in this post, is to leverage an existing solution for priority-based scheduling that fulfils our requirements and align our training development workflow to its use. The default scheduler that comes with Kubernetes is an example of one such solution. In the next sections we will demonstrate how it can be used to address the problem of optimizing the use of scarce AI training resources.
ML Orchestration with Kubernetes
In this section we will get a bit philosophical about the application of Kubernetes to the orchestration of ML training workloads. If you have no patience for such discussions (totally fair) and want to get straight to the practical examples, please feel free to skip to the next section.
Kubernetes is (another) one of those software/technological solutions that tend to elicit strong reactions in many developers. There are some that swear by it and use it extensively, and others that find it overbearing, clumsy, and unnecessary (e.g., see here for some of the arguments for and against using Kubernetes). As with many other heated debates, it is the author’s opinion that the truth lies somewhere in between — there are situations where Kubernetes provides an ideal framework that can significantly increase productivity, and other situations where its use borders on an insult to the SW development profession. The big question is, where on the spectrum does ML development lie? Is Kubernetes the appropriate framework for training ML models? Although a cursory online search might give the impression that the general consensus is an emphatic “yes”, we will make some arguments for why that may not be the case. But first, we need to be clear about what we mean by “ML training orchestration using Kubernetes”.
While there are many online resources that address the topic of ML using Kubernetes, it is important to be aware of the fact that they are not always referring to the same mode of use. Some resources (e.g., here) use Kubernetes only for deploying a cluster; once the cluster is up and running they start the training job outside the context of Kubernetes. Others (e.g., here) use Kubernetes to define a pipeline in which a dedicated module starts up a training job (and associated resources) using a completely different system. In contrast to these two examples, many other resources define the training workload as a Kubernetes Job artifact that runs on a Kubernetes Node. However, they too vary greatly in the particular attributes on which they focus. Some (e.g., here) emphasize the auto-scaling properties and others (e.g., here) the Multi-Instance GPU (MIG) support. They also vary greatly in the details of implementation, such as the precise artifact (Job extension) for representing a training job (e.g., ElasticJob, TrainingWorkload, JobSet, VolcanoJob, etc.). In the context of this post, we too will assume that the training workload is defined as a Kubernetes Job. However, in order to simplify the discussion, we will stick with the core Kubernetes objects and leave the discussion of Kubernetes extensions for ML for a future post.
Arguments Against Kubernetes for ML
Here are some arguments that could be made against the use of Kubernetes for training ML models.
- Complexity: Even its greatest proponents have to admit that Kubernetes can be hard. Using Kubernetes effectively, requires a high level of expertise, has a steep learning curve, and, realistically speaking, typically requires a dedicated devops team. Designing a training solution based on Kubernetes increases dependencies on dedicated experts and by extension, increases the risk that things could go wrong, and that development could be delayed. Many alternative ML training solutions enable a greater level of developer independence and freedom and entail a reduced risk of bugs in the development process.
- Fixed Resource Requirements: One of the most touted properties of Kubernetes is its scalability — its ability to automatically and seamlessly scale its pool of compute resources up and down according to the number of jobs, the number of clients (in the case of a service application), resource capacity, etc. However, one could argue that in the case of an ML training workload, where the number of resources that are required is (usually) fixed throughout training, auto-scaling is unnecessary.
- Fixed Instance Type: Due to the fact that Kubernetes orchestrates containerized applications, Kubernetes enables a great deal of flexibility when it comes to the types of machines in its node pool. However, when it comes to ML, we typically require very specific machinery with dedicated accelerators (such as GPUs). Moreover, our workloads are often tuned to run optimally on one very specific instance type.
- Monolithic Application Architecture: It is common practice in the development of modern-day applications to break them down into small elements called microservices. Kubernetes is often seen as a key component in this design. ML training applications tend to be quite monolithic in their design and, one could argue, that they do not lend themselves naturally to a microservice architecture.
- Resource Overhead: The dedicated processes that are required to run Kubernetes requires some system resources on each of the nodes in its pool. Consequently, it may incur a certain performance penalty on our training jobs. Given the expense of the resources required for training, we may prefer to avoid this.
Granted, we have taken a very one-sided view in the Kubernetes-for-ML debate. Based solely on the arguments above, you might conclude that we would need a darn good reason for choosing Kubernetes as a framework for ML training. It is our opinion that the challenge put forth in this post, i.e., the desire to maximize the utility of scarce AI compute resources, is exactly the type of justification that warrants the use of Kubernetes despite the arguments made above. As we will demonstrate, the default scheduler that is built-in to Kubernetes, combined with its support for priority and preemption makes it a front-runner for fulfilling the requirements stated above.
Toy Example
In this section we will share a brief example that demonstrates the priority scheduling support that is built in to Kubernetes. For the purposes of our demonstration, we will use Minikube (version v1.32.0). Minikube is a tool that enables you to run a Kubernetes cluster in a local environment and is an ideal playground for experimenting with Kubernetes. Please see the official documentation on installing and getting started with Minikube.
Cluster Creation
Let’s start by creating a two-node cluster using the Minikube start command:
minikube start --nodes 2
The result is a local Kubernetes cluster consisting of a master (“control-plane”) node named minikube, and a single worker node, named minikube-m02, which will simulate our single AI resource. Let’s apply the label my-precious to identify it as a unique resource type:
kubectl label nodes minikube-m02 node-type=my-precious
We can use the Minikube dashboard to visualize the results. In a separate shell run the command below and open the generated browser link.
minikube dashboard
If you press on the Nodes tab on the left-hand pane, you should see a summary of our cluster’s nodes:
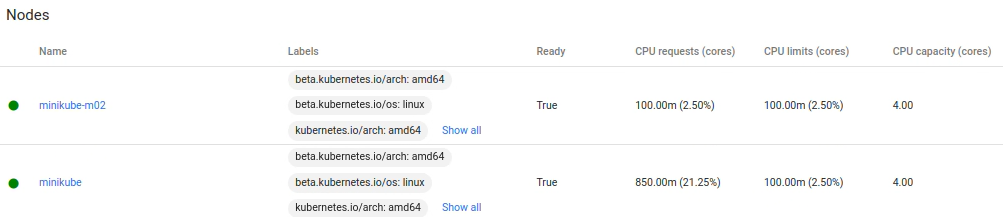
PriorityClass Definitions
Next, we define two PriorityClasses, low-priority and high-priority, as in the priorities.yaml file displayed below. New jobs will receive the low-priority assignment, by default.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 0
globalDefault: true
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
To apply our new classes to our cluster, we run:
kubectl apply -f priorities.yaml
Create a Job
We define a simple job using a job.yaml file displayed in the code block below. For the purpose of our demonstration, we define a Kubernetes Job that does nothing more than sleep for 100 seconds. We use busybox as its Docker image. In practice, this would be replaced with a training script and an appropriate ML Docker image. We define the job to run on our special instance, my-precious, using the nodeSelector field, and specify the resource requirements so that only a single instance of the job can run on the instance at a time. The priority of the job defaults to low-priority as defined above.
apiVersion: batch/v1
kind: Job
metadata:
name: test
spec:
template:
spec:
containers:
- name: test
image: busybox
command: # simple sleep command
- sleep
- '100'
resources: # require all available resources
limits:
cpu: "2"
requests:
cpu: "2"
nodeSelector: # specify our unique resource
node-type: my-precious
restartPolicy: Never
We submit the job with the following command:
kubectl apply -f job.yaml
Create a Queue of Jobs
To demonstrate the manner in which Kubernetes queues jobs for processing, we create three identical copies of the job defined above, named test1, test2, and test3. We group the three jobs in a single file, jobs.yaml, and submit them for processing:
kubectl apply -f jobs.yaml
The image below captures the Workload Status of our cluster in the Minikube dashboard shortly after the submission. You can see that my-precious has begun processing test1, while the other jobs are pending as they wait their turn.
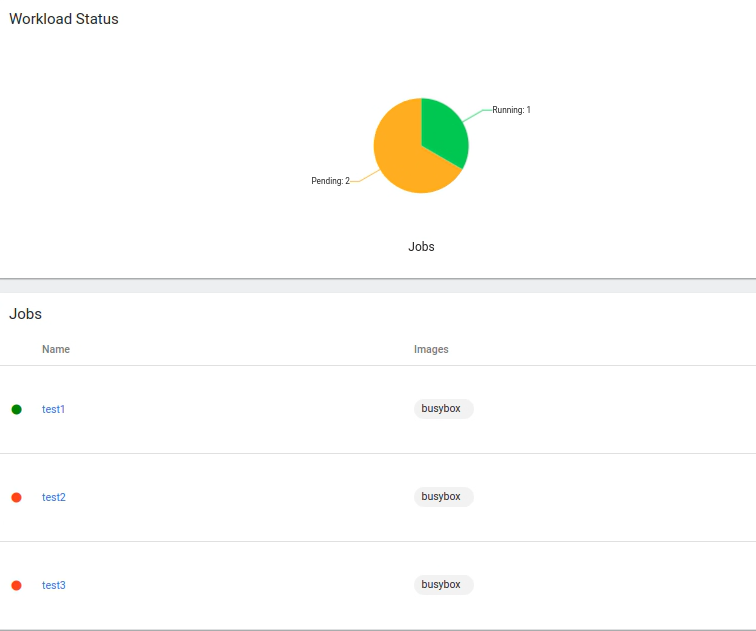
Once test1 is completed, processing of test2 begins:
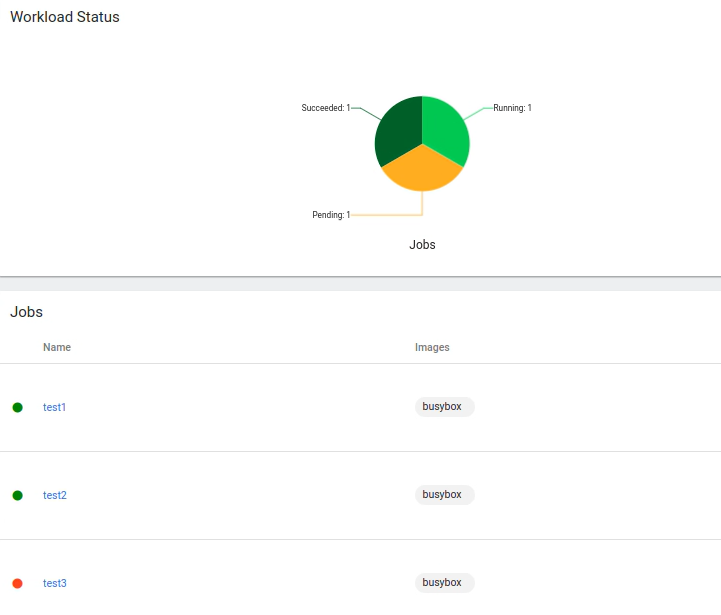
So long as no other jobs with higher priority are submitted, our jobs would continue to be processed one at a time until they are all completed.
Job Preemption
We now demonstrate Kubernetes’ built-in support for job preemption by showing what happens when we submit a fourth job, this time with the high-priority setting:
apiVersion: batch/v1
kind: Job
metadata:
name: test-p1
spec:
template:
spec:
containers:
- name: test-p1
image: busybox
command:
- sleep
- '100'
resources:
limits:
cpu: "2"
requests:
cpu: "2"
restartPolicy: Never
priorityClassName: high-priority # high priority job
nodeSelector:
node-type: my-precious
The impact on the Workload Status is displayed in the image below:
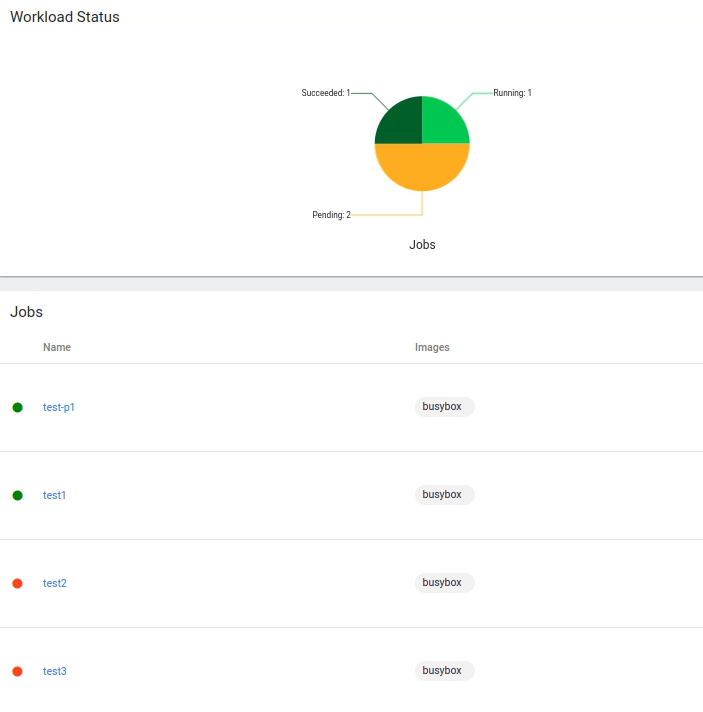
The test2 job has been preempted — its processing has been stopped and it has returned to the pending state. In its stead, my-precious has begun processing the higher priority test-p1 job. Only once test-p1 is completed will processing of the lower priority jobs resume. (In the case where the preempted job is a ML training workload, we would program it to resume from the most recent saved model model checkpoint).
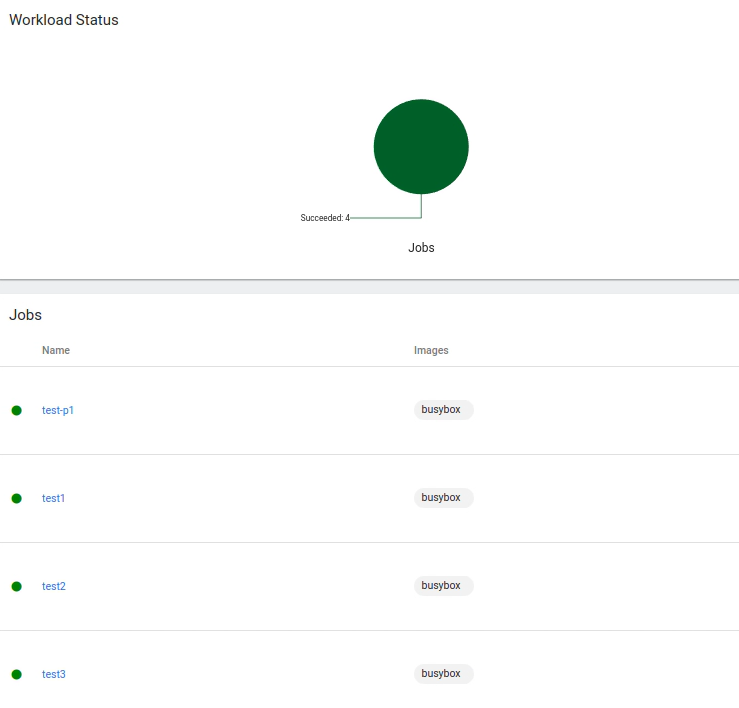
The image below displays the Workload Status once all jobs have been completed.
Kubernetes Extensions
The solution we demonstrated for priority-based scheduling and preemption relied only on core components of Kubernetes. In practice, you may choose to take advantage of enhancements to the basic functionality introduced by extensions such as Kueue and/or dedicated, ML-specific features offered by platforms build on top of Kubernetes, such as Run:AI or Volcano. But keep in mind that to fulfill the basic requirements for maximizing the utility of a scarce AI compute resource all we need is the core Kubernetes.
Summary
The reduced availability of dedicated AI silicon has forced ML teams to adjust their development processes. Unlike in the past, when developers could spin up new AI resources at will, they now face limitations on AI compute capacity. This necessitates the procurement of AI instances through means such as purchasing dedicated units and/or reserving cloud instances. Moreover, developers must come to terms with the likelihood of needing to share these resources with other users and projects. To ensure that the scarce AI compute power is appropriated towards maximum utility, dedicated scheduling algorithms must be defined that minimize idle time and prioritize critical workloads. In this post we have demonstrated how the Kubernetes scheduler can be used to accomplish these goals. As emphasized above, this is just one of many approaches to address the challenge of maximizing the utility of scarce AI resources. Naturally, the approach you choose, and the details of your implementation will depend on the specific needs of your AI development.
Maximizing the Utility of Scarce AI Resources: A Kubernetes Approach was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Optimizing the use of limited AI training accelerators

In the ever-evolving landscape of AI development, nothing rings truer than the old saying (attributed to Heraclitus), “the only constant in life is change”. In the case of AI, it seems that change is indeed constant, but the pace of change is forever increasing. Staying relevant in these unique and exciting times amounts to an unprecedented test of the capacity of AI teams to consistently adapt and adjust their development processes. AI development teams that fail to adapt, or are slow to adapt, may quickly become obsolete.
One of the most challenging developments of the past few years in AI development has been the increasing difficulty to attain the hardware required to train AI models. Whether it be due to an ongoing crisis in the global supply chain or a significant increase in the demand for AI chips, getting your hands on the GPUs (or alternative training accelerators) that you need for AI development, has gotten much harder. This is evidenced by the huge wait time for new GPU orders and by the fact that cloud service providers (CSPs) that once offered virtually infinite capacity of GPU machines, now struggle to keep up with the demand.
The changing times are forcing AI development teams that may have once relied on endless capacity of AI accelerators to adapt to a world with reduced accessibility and, in some cases, higher costs. Development processes that once took for granted the ability to spin up a new GPU machine at will, must be modified to meet the demands of a world of scarce AI resources that are often shared by multiple projects and/or teams. Those that fail to adapt risk annihilation.
In this post we will demonstrate the use of Kubernetes in the orchestration of AI-model training workloads in a world of scarce AI resources. We will start by specifying the goals we wish to achieve. We will then describe why Kubernetes is an appropriate tool for addressing this challenge. Last, we will provide a simple demonstration of how Kubernetes can be used to maximize the use of a scarce AI compute resource. In subsequent posts, we plan to enhance the Kubernetes-based solution and show how to apply it to a cloud-based training environment.
Disclaimers
While this post does not assume prior experience with Kubernetes, some basic familiarity would certainly be helpful. This post should not, in any way, be viewed as a Kubernetes tutorial. To learn about Kubernetes, we refer the reader to the many great online resources on the subject. Here we will discuss just a few properties of Kubernetes as they pertain to the topic of maximizing and prioritizing resource utilization.
There are many alternative tools and techniques to the method we put forth here, each with their own pros and cons. Our intention in this post is purely educational; Please do not view any of the choices we make as an endorsement.
Lastly, the Kubernetes platform remains under constant development, as do many of the frameworks and tools in the field of AI development. Please take into account the possibility that some of the statements, examples, and/or external links in this post may become outdated by the time you read this and be sure to take into account the most up-to-date solutions available before making your own design decisions.
Adapting to Scarce AI Compute Resources
To simplify our discussion, let’s assume that we have a single worker node at our disposal for training our models. This could be a local machine with a GPU or a reserved compute-accelerated instance in the cloud, such as a p5.48xlarge instance in AWS or a TPU node in GCP. In our example below we will refer to this node as “my precious”. Typically, we will have spent a lot of money on this machine. We will further assume that we have multiple training workloads all competing for our single compute resource where each workload could take anywhere from a few minutes to a few days. Naturally, we would like to maximize the utility of our compute resource by ensuring that it is in constant use and that the most important jobs get prioritized. What we need is some form of a priority queue and an associated priority-based scheduling algorithm. Let’s try to be a bit more specific about the behaviors that we desire.
Scheduling Requirements
- Maximize Utilization: We would like for our resource to be in constant use. Specifically, as soon as it completes a workload, it will promptly (and automatically) start working on a new one.
- Queue Pending Workloads: We require the existence of a queue of training workloads that are waiting to be processed by our unique resource. We also require associated APIs for creating and submitting new jobs to the queue, as well as monitoring and managing the state of the queue.
- Support Prioritization: We would like each training job to have an associated priority such that workloads with higher priority will be run before workloads with a lower priority.
- Preemption: Moreover, in the case that an urgent job is submitted to the queue while our resource is working on a lower priority job, we would like for the running job to be preempted and replaced by the urgent job. The preempted job should be returned to the queue.
One approach to developing a solution that satisfies these requirements could be to take an existing API for submitting jobs to a training resource and wrap it with a customized implementation of a priority queue with the desired properties. At a minimum, this approach would require a data structure for storing a list of pending jobs, a dedicated process for choosing and submitting jobs from the queue to the training resource, and some form of mechanism for identifying when a job has been completed and the resource has become available.
An alternative approach and the one we take in this post, is to leverage an existing solution for priority-based scheduling that fulfils our requirements and align our training development workflow to its use. The default scheduler that comes with Kubernetes is an example of one such solution. In the next sections we will demonstrate how it can be used to address the problem of optimizing the use of scarce AI training resources.
ML Orchestration with Kubernetes
In this section we will get a bit philosophical about the application of Kubernetes to the orchestration of ML training workloads. If you have no patience for such discussions (totally fair) and want to get straight to the practical examples, please feel free to skip to the next section.
Kubernetes is (another) one of those software/technological solutions that tend to elicit strong reactions in many developers. There are some that swear by it and use it extensively, and others that find it overbearing, clumsy, and unnecessary (e.g., see here for some of the arguments for and against using Kubernetes). As with many other heated debates, it is the author’s opinion that the truth lies somewhere in between — there are situations where Kubernetes provides an ideal framework that can significantly increase productivity, and other situations where its use borders on an insult to the SW development profession. The big question is, where on the spectrum does ML development lie? Is Kubernetes the appropriate framework for training ML models? Although a cursory online search might give the impression that the general consensus is an emphatic “yes”, we will make some arguments for why that may not be the case. But first, we need to be clear about what we mean by “ML training orchestration using Kubernetes”.
While there are many online resources that address the topic of ML using Kubernetes, it is important to be aware of the fact that they are not always referring to the same mode of use. Some resources (e.g., here) use Kubernetes only for deploying a cluster; once the cluster is up and running they start the training job outside the context of Kubernetes. Others (e.g., here) use Kubernetes to define a pipeline in which a dedicated module starts up a training job (and associated resources) using a completely different system. In contrast to these two examples, many other resources define the training workload as a Kubernetes Job artifact that runs on a Kubernetes Node. However, they too vary greatly in the particular attributes on which they focus. Some (e.g., here) emphasize the auto-scaling properties and others (e.g., here) the Multi-Instance GPU (MIG) support. They also vary greatly in the details of implementation, such as the precise artifact (Job extension) for representing a training job (e.g., ElasticJob, TrainingWorkload, JobSet, VolcanoJob, etc.). In the context of this post, we too will assume that the training workload is defined as a Kubernetes Job. However, in order to simplify the discussion, we will stick with the core Kubernetes objects and leave the discussion of Kubernetes extensions for ML for a future post.
Arguments Against Kubernetes for ML
Here are some arguments that could be made against the use of Kubernetes for training ML models.
- Complexity: Even its greatest proponents have to admit that Kubernetes can be hard. Using Kubernetes effectively, requires a high level of expertise, has a steep learning curve, and, realistically speaking, typically requires a dedicated devops team. Designing a training solution based on Kubernetes increases dependencies on dedicated experts and by extension, increases the risk that things could go wrong, and that development could be delayed. Many alternative ML training solutions enable a greater level of developer independence and freedom and entail a reduced risk of bugs in the development process.
- Fixed Resource Requirements: One of the most touted properties of Kubernetes is its scalability — its ability to automatically and seamlessly scale its pool of compute resources up and down according to the number of jobs, the number of clients (in the case of a service application), resource capacity, etc. However, one could argue that in the case of an ML training workload, where the number of resources that are required is (usually) fixed throughout training, auto-scaling is unnecessary.
- Fixed Instance Type: Due to the fact that Kubernetes orchestrates containerized applications, Kubernetes enables a great deal of flexibility when it comes to the types of machines in its node pool. However, when it comes to ML, we typically require very specific machinery with dedicated accelerators (such as GPUs). Moreover, our workloads are often tuned to run optimally on one very specific instance type.
- Monolithic Application Architecture: It is common practice in the development of modern-day applications to break them down into small elements called microservices. Kubernetes is often seen as a key component in this design. ML training applications tend to be quite monolithic in their design and, one could argue, that they do not lend themselves naturally to a microservice architecture.
- Resource Overhead: The dedicated processes that are required to run Kubernetes requires some system resources on each of the nodes in its pool. Consequently, it may incur a certain performance penalty on our training jobs. Given the expense of the resources required for training, we may prefer to avoid this.
Granted, we have taken a very one-sided view in the Kubernetes-for-ML debate. Based solely on the arguments above, you might conclude that we would need a darn good reason for choosing Kubernetes as a framework for ML training. It is our opinion that the challenge put forth in this post, i.e., the desire to maximize the utility of scarce AI compute resources, is exactly the type of justification that warrants the use of Kubernetes despite the arguments made above. As we will demonstrate, the default scheduler that is built-in to Kubernetes, combined with its support for priority and preemption makes it a front-runner for fulfilling the requirements stated above.
Toy Example
In this section we will share a brief example that demonstrates the priority scheduling support that is built in to Kubernetes. For the purposes of our demonstration, we will use Minikube (version v1.32.0). Minikube is a tool that enables you to run a Kubernetes cluster in a local environment and is an ideal playground for experimenting with Kubernetes. Please see the official documentation on installing and getting started with Minikube.
Cluster Creation
Let’s start by creating a two-node cluster using the Minikube start command:
minikube start --nodes 2
The result is a local Kubernetes cluster consisting of a master (“control-plane”) node named minikube, and a single worker node, named minikube-m02, which will simulate our single AI resource. Let’s apply the label my-precious to identify it as a unique resource type:
kubectl label nodes minikube-m02 node-type=my-precious
We can use the Minikube dashboard to visualize the results. In a separate shell run the command below and open the generated browser link.
minikube dashboard
If you press on the Nodes tab on the left-hand pane, you should see a summary of our cluster’s nodes:
PriorityClass Definitions
Next, we define two PriorityClasses, low-priority and high-priority, as in the priorities.yaml file displayed below. New jobs will receive the low-priority assignment, by default.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 0
globalDefault: true
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
To apply our new classes to our cluster, we run:
kubectl apply -f priorities.yaml
Create a Job
We define a simple job using a job.yaml file displayed in the code block below. For the purpose of our demonstration, we define a Kubernetes Job that does nothing more than sleep for 100 seconds. We use busybox as its Docker image. In practice, this would be replaced with a training script and an appropriate ML Docker image. We define the job to run on our special instance, my-precious, using the nodeSelector field, and specify the resource requirements so that only a single instance of the job can run on the instance at a time. The priority of the job defaults to low-priority as defined above.
apiVersion: batch/v1
kind: Job
metadata:
name: test
spec:
template:
spec:
containers:
- name: test
image: busybox
command: # simple sleep command
- sleep
- '100'
resources: # require all available resources
limits:
cpu: "2"
requests:
cpu: "2"
nodeSelector: # specify our unique resource
node-type: my-precious
restartPolicy: Never
We submit the job with the following command:
kubectl apply -f job.yaml
Create a Queue of Jobs
To demonstrate the manner in which Kubernetes queues jobs for processing, we create three identical copies of the job defined above, named test1, test2, and test3. We group the three jobs in a single file, jobs.yaml, and submit them for processing:
kubectl apply -f jobs.yaml
The image below captures the Workload Status of our cluster in the Minikube dashboard shortly after the submission. You can see that my-precious has begun processing test1, while the other jobs are pending as they wait their turn.
Once test1 is completed, processing of test2 begins:
So long as no other jobs with higher priority are submitted, our jobs would continue to be processed one at a time until they are all completed.
Job Preemption
We now demonstrate Kubernetes’ built-in support for job preemption by showing what happens when we submit a fourth job, this time with the high-priority setting:
apiVersion: batch/v1
kind: Job
metadata:
name: test-p1
spec:
template:
spec:
containers:
- name: test-p1
image: busybox
command:
- sleep
- '100'
resources:
limits:
cpu: "2"
requests:
cpu: "2"
restartPolicy: Never
priorityClassName: high-priority # high priority job
nodeSelector:
node-type: my-precious
The impact on the Workload Status is displayed in the image below:
The test2 job has been preempted — its processing has been stopped and it has returned to the pending state. In its stead, my-precious has begun processing the higher priority test-p1 job. Only once test-p1 is completed will processing of the lower priority jobs resume. (In the case where the preempted job is a ML training workload, we would program it to resume from the most recent saved model model checkpoint).
The image below displays the Workload Status once all jobs have been completed.
Kubernetes Extensions
The solution we demonstrated for priority-based scheduling and preemption relied only on core components of Kubernetes. In practice, you may choose to take advantage of enhancements to the basic functionality introduced by extensions such as Kueue and/or dedicated, ML-specific features offered by platforms build on top of Kubernetes, such as Run:AI or Volcano. But keep in mind that to fulfill the basic requirements for maximizing the utility of a scarce AI compute resource all we need is the core Kubernetes.
Summary
The reduced availability of dedicated AI silicon has forced ML teams to adjust their development processes. Unlike in the past, when developers could spin up new AI resources at will, they now face limitations on AI compute capacity. This necessitates the procurement of AI instances through means such as purchasing dedicated units and/or reserving cloud instances. Moreover, developers must come to terms with the likelihood of needing to share these resources with other users and projects. To ensure that the scarce AI compute power is appropriated towards maximum utility, dedicated scheduling algorithms must be defined that minimize idle time and prioritize critical workloads. In this post we have demonstrated how the Kubernetes scheduler can be used to accomplish these goals. As emphasized above, this is just one of many approaches to address the challenge of maximizing the utility of scarce AI resources. Naturally, the approach you choose, and the details of your implementation will depend on the specific needs of your AI development.
Maximizing the Utility of Scarce AI Resources: A Kubernetes Approach was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.