
Measuring string similarity in BigQuery using SQL | by Romain Granger | Jun, 2022
Use Levenshtein distance to discover similar or duplicated values, clean your data, and more!
Using the Levenshtein distance method
This method can be used among others (Soundex, LIKE statement, Regexp) to perform string similarity or string matching in order to identify two elements (text, strings, inputs) that are similar but not identical.
This method can be used for a variety of applications, including identifying duplicates, handling misspelled user input data, cleaning customer data, and so on.
The idea of the Levenshtein method is to compute the minimal edit distance between two strings.
But what is an “edit” distance? It’s composed of three actions: insertions, substitutions, and deletions. These three actions are given equal weight by the algorithm, basically a 1.
To help understand the mechanisms, here are a few examples:
- Bigquer → Bigquery: The letter
yis added at the end, so the distance will be 1 (we made 1 addition). - music → mujic: The letter
jis a substitute for the lettersfrom music, the distance is also 1 (we made 1 substitution). - french fries → frij: The letters
frenchand space were added, the letterjis a substitute foreand the letterswas deleted. (We made 7 additions, 1 substitution, and 1 deletion)
This method is particularly effective when comparing a full string to another full string (and performs less well when comparing keywords within a sentence or comparing a sentence against another sentence).
You can find further information on the algorithm on Wikipedia.
And now that we’ve learned the theory and applications, let’s look at how we might apply it in SQL.
Creating a persistent function
You can define a UDFs as either persistent or temporary. The main difference is that persistent functions can be reused and accessed by multiple queries (it’s like creating a dataset in your project) while temporary functions only work for the query you are currently running in your editor.
Personally, I enjoy working with a dataset that I call utility since it allows me to store tables and functions that I can reuse across other datasets and queries.
Here is the Javascript UDF function we will in BigQuery:
When executing this query, it would then appear in your project structure as follow:
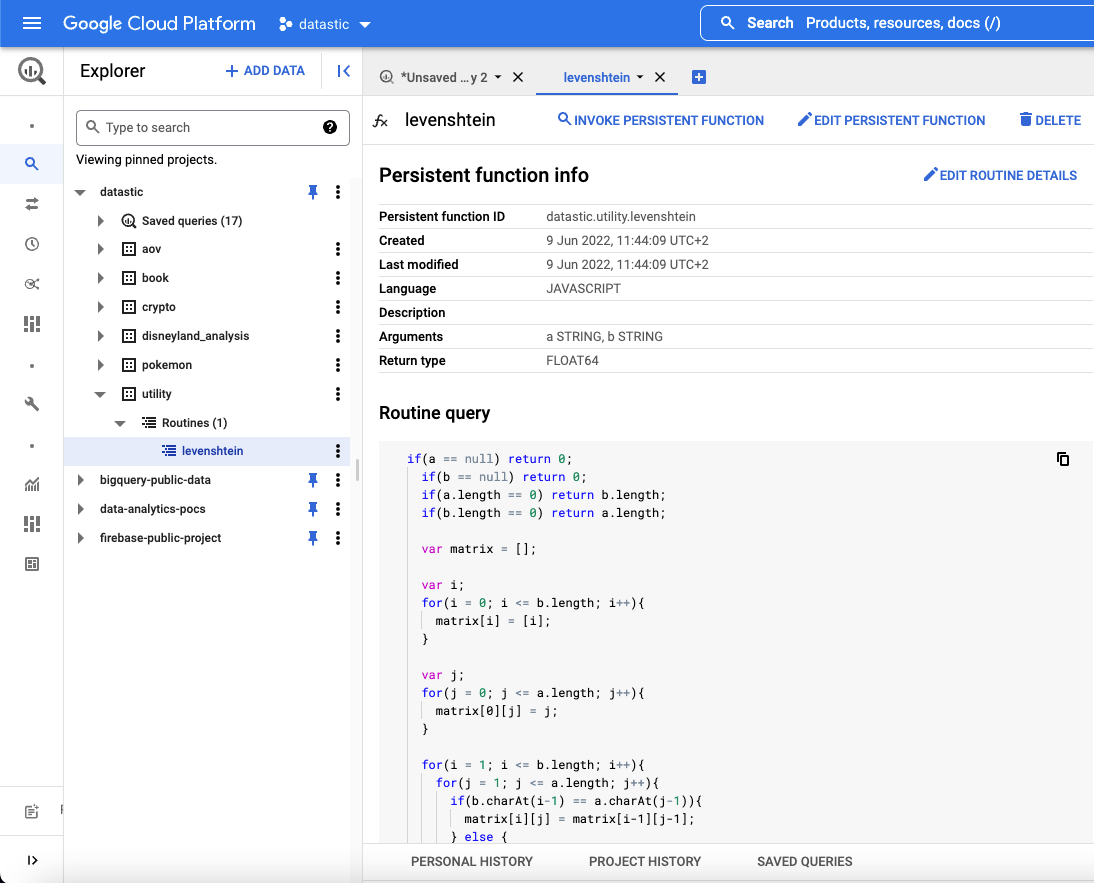
Note that this function, instead of returning the actual difference as a number of editions (returning 1 if we were making 1 addition), will return a value on a 0 to 1 scale. Where 1 means completely similar and 0 means not similar at all.
In our first theoric example, Bigquer → Bigquery: The letter y was added, meaning a distance of 1. Our function will first compute the number of editions divided by the longest inputted string, in this case, Bigquery with 8 characters (1 addition / 8 length) which is the distance.
For getting the similarity, we simply reverse it, using 1-(1/8) = 0,875
But first, let’s look at a real SQL query!
Using the function in a SQL query
Now that the function has been saved as a persistent UDF, you can simply call it by writing its location. In our example, it will be called using the following:
`datastic.utility.levenshtein`(source,target)
We prepared several cases to test the similarity score produced by our method.
The query will output the following results:
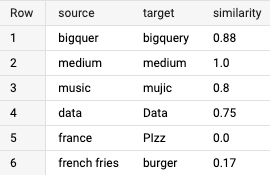
In the first case, there is an addition of one letter, which leads to a similarity between the two words of 0.88!
The two extremes are also demonstrated: with the identical combination of words medium | medium, the result is a similarity of 1, and with the opposite combination of words france | PIzz, the result is a similarity of 0.
A real-world example with publicly available data
The use case we want to solve is correcting user country data from our CRM. We noticed that there was a lot of misspelled data, and we will use BigQuery public data to help us.
This table contains the data provided by BigQuery,
and contains all country names in the following format:

Now, our CRM data table contains the following information, an email and a country (apparently with a number of misspelled words)

Let’s try to solve our real-world use case. For that, we’ll perform the following query, which will consist of four steps:
- Loading country data from BigQuery
- Loading our CRM data
- Applying a
CROSS JOINstatement and computing our Levenshtein function - Ranking the results to find the most similar country
And, tadam 🎉, the results are as follows:
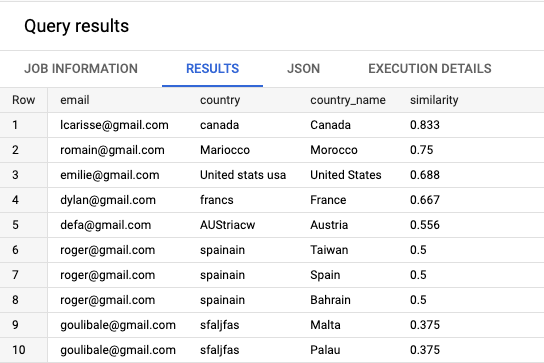
As you can see, this method has some caveats as we have sometimes more than one row returned because two sets of strings are very similar (this is the case for spainiain which is equally close to Spain, Bahrain, and Taiwan)
We decided to use a CROSS JOINstatement to join our two data tables. It means that we will compare each row of our CRM table with all the possible countries present in the country table. In our example, our CRM data has 7 rows and our country data set has 250, which will create the result of 7×250=1750 rows.
This result is reduced by using the QUALIFY clause to rank the country that is most similar, But depending on your use case, the CROSS JOINsolution will require a lot of computing.
Going further with bigger datasets
For our example, we used a small CRM dataset (7 rows). In comparison, I reused the same country table (250 rows) on a dataset of 8 million customers, and it took around 33 seconds with BigQuery, which is still quite fast. If you were to use even bigger datasets (maybe in billion rows), then I would recommend using ARRAYS than using JOINS, which in BigQuery would result in fewer resources needed.
The second difficulty to solve is selecting the best similarity when our Levenshtein distance function returns more than one result. My recommendation would be to combine the Levenshtein method with additional ones, like Regular Expressions or Soundex, which would give additional weight to the similarity score and probably allow a better selection.
Use Levenshtein distance to discover similar or duplicated values, clean your data, and more!
Using the Levenshtein distance method
This method can be used among others (Soundex, LIKE statement, Regexp) to perform string similarity or string matching in order to identify two elements (text, strings, inputs) that are similar but not identical.
This method can be used for a variety of applications, including identifying duplicates, handling misspelled user input data, cleaning customer data, and so on.
The idea of the Levenshtein method is to compute the minimal edit distance between two strings.
But what is an “edit” distance? It’s composed of three actions: insertions, substitutions, and deletions. These three actions are given equal weight by the algorithm, basically a 1.
To help understand the mechanisms, here are a few examples:
- Bigquer → Bigquery: The letter
yis added at the end, so the distance will be 1 (we made 1 addition). - music → mujic: The letter
jis a substitute for the lettersfrom music, the distance is also 1 (we made 1 substitution). - french fries → frij: The letters
frenchand space were added, the letterjis a substitute foreand the letterswas deleted. (We made 7 additions, 1 substitution, and 1 deletion)
This method is particularly effective when comparing a full string to another full string (and performs less well when comparing keywords within a sentence or comparing a sentence against another sentence).
You can find further information on the algorithm on Wikipedia.
And now that we’ve learned the theory and applications, let’s look at how we might apply it in SQL.
Creating a persistent function
You can define a UDFs as either persistent or temporary. The main difference is that persistent functions can be reused and accessed by multiple queries (it’s like creating a dataset in your project) while temporary functions only work for the query you are currently running in your editor.
Personally, I enjoy working with a dataset that I call utility since it allows me to store tables and functions that I can reuse across other datasets and queries.
Here is the Javascript UDF function we will in BigQuery:
When executing this query, it would then appear in your project structure as follow:
Note that this function, instead of returning the actual difference as a number of editions (returning 1 if we were making 1 addition), will return a value on a 0 to 1 scale. Where 1 means completely similar and 0 means not similar at all.
In our first theoric example, Bigquer → Bigquery: The letter y was added, meaning a distance of 1. Our function will first compute the number of editions divided by the longest inputted string, in this case, Bigquery with 8 characters (1 addition / 8 length) which is the distance.
For getting the similarity, we simply reverse it, using 1-(1/8) = 0,875
But first, let’s look at a real SQL query!
Using the function in a SQL query
Now that the function has been saved as a persistent UDF, you can simply call it by writing its location. In our example, it will be called using the following:
`datastic.utility.levenshtein`(source,target)
We prepared several cases to test the similarity score produced by our method.
The query will output the following results:
In the first case, there is an addition of one letter, which leads to a similarity between the two words of 0.88!
The two extremes are also demonstrated: with the identical combination of words medium | medium, the result is a similarity of 1, and with the opposite combination of words france | PIzz, the result is a similarity of 0.
A real-world example with publicly available data
The use case we want to solve is correcting user country data from our CRM. We noticed that there was a lot of misspelled data, and we will use BigQuery public data to help us.
This table contains the data provided by BigQuery,
and contains all country names in the following format:
Now, our CRM data table contains the following information, an email and a country (apparently with a number of misspelled words)
Let’s try to solve our real-world use case. For that, we’ll perform the following query, which will consist of four steps:
- Loading country data from BigQuery
- Loading our CRM data
- Applying a
CROSS JOINstatement and computing our Levenshtein function - Ranking the results to find the most similar country
And, tadam 🎉, the results are as follows:
As you can see, this method has some caveats as we have sometimes more than one row returned because two sets of strings are very similar (this is the case for spainiain which is equally close to Spain, Bahrain, and Taiwan)
We decided to use a CROSS JOINstatement to join our two data tables. It means that we will compare each row of our CRM table with all the possible countries present in the country table. In our example, our CRM data has 7 rows and our country data set has 250, which will create the result of 7×250=1750 rows.
This result is reduced by using the QUALIFY clause to rank the country that is most similar, But depending on your use case, the CROSS JOINsolution will require a lot of computing.
Going further with bigger datasets
For our example, we used a small CRM dataset (7 rows). In comparison, I reused the same country table (250 rows) on a dataset of 8 million customers, and it took around 33 seconds with BigQuery, which is still quite fast. If you were to use even bigger datasets (maybe in billion rows), then I would recommend using ARRAYS than using JOINS, which in BigQuery would result in fewer resources needed.
The second difficulty to solve is selecting the best similarity when our Levenshtein distance function returns more than one result. My recommendation would be to combine the Levenshtein method with additional ones, like Regular Expressions or Soundex, which would give additional weight to the similarity score and probably allow a better selection.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.