
Mini-Max Optimization Design of Generative Adversarial Networks (GAN)
Nested bi-level optimization and equilibrium seeking objective
Introduction
Generative Adversarial Networks (GAN) demonstrated outstanding performance in generating realistic synthetic data which were indistinguishable from the real data. Unfortunately, GAN caught the public’s attention because of its illegit applications, Deep Fake. (Knight, 2018)
As its name suggests, Generative Adversarial Nets (GAN) is composed of two networks: the generative network (the generator) and the adversarial network (the discriminator). Incorporating an adversarial scheme into its architecture makes GAN a special type of generative network.
Importantly, GAN is non-parametric, therefore, would not impose statistical requirements such as the Markov chain. Instead of imposing statistical assumptions, with the help of the adversary network, the generative network learns the probability distribution of the real data through back-propagation in deep neural networks.
In order to generate realistic synthetic data, GAN pits these two agents against each other within its architecture. In this game, while the generator attempts to simulate synthetic samples which imitate real samples, the discriminator attempts to distinguish between the real samples and the synthetic ones. In other words, while the generator, G, tries to deceive the discriminator by counterfeiting, the discriminator, D, plays a role of the police to detect the synthetic (fake) data. (Goodfellow, et al., 2014, p. 1) In a way, these two agents attempt to achieve diametrically opposite objectives.
As they improve their skills, the synthetic data becomes indistinguishable from the real data. Thanks to its adversary (the discriminator), the generator learns how to better imitate the probability distribution of the given real data.
Since within its architecture GAN has to train two learners that attempt to achieve contrasting objectives through interactions, it has a unique optimization design (bi-level training mechanism and equilibrium seeking objectives). In this context, it took me a while to digest the architectural design of GAN.
In this article, I want to share my journey of GAN with those who are new to GAN so that they can comprehend the architectural peculiarity of GAN more smoothly. I hope that the readers find this article useful as a supplementary note.
As a precaution, GAN is heuristic. And there are many variants of GAN today. This article discusses only the architectural design of the original GAN.
The Original GAN Design
The base architecture of the original GAN was introduced in a seminal paper: “Generative Adversarial Nets” (Goodfellow, et al., 2014). In this original GAN paper, in order to train these two agents which pursue the diametrically opposite objectives, the co-authors designed a “bi-level optimization (training)” architecture, in which one internal training block (training of the discriminator) is nested within another high-level training block (training of the generator). And GAN trains these two agents alternately in this bi-level training framework.
Discriminator and Generator
Now, let’s see what these two agents do in their learning process.
It is straight-forward that the discriminator is a binary classifier by design. Given mixed samples from the real data and the synthetic data, it classifies whether each sample is real (label=1) or fake/synthetic (label=0).
On the other hand, the generator is a noise distribution by design. And it is trained to imitate the probability distribution of the real dataset through an iteration. At every step of the training iteration, the learned generative model (updated generator) is copied and used as the new noise distribution. Thereafter, the new noise distribution is used to train the discriminator. (Goodfellow I. , 2015, p. 2).
Let’s set the following:

We take the input noise, z, and calculate its prior distribution, G(z), to define the generator. Say the learned distribution of the generator follows
In this setting, the ultimate goal of the generator is to deceive the discriminator by transforming its own distribution as close as the distribution of the real dataset.
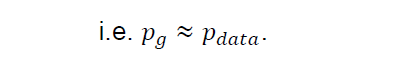
Two Objective Functions: Mini-Max Game
Repeatedly, GAN has two agents to train within its architecture. And these agents have confronting objectives. Therefore, GAN has two objective functions: one for the discriminator and the other for the generator.
On one hand, the discriminator, D, as a binary classifier, needs to maximize the probability of correctly assigning labels to both the real data (label=1) and the synthetic data (label=0).
On the other hand, the ultimate goal of the generator is to fool the classifier by creating synthetic data which is indistinguishable from the real data. Therefore, the generator attempts to deceive the classifier so that the discriminator would classify the synthetic data with label 1. In other words, the objective of the generator is “to maximize the probability of D making a mistake.” (Goodfellow, et al., 2014, p. 1)
At a conceptual level, in order to achieve their diametrically opposite objectives, these two agents can refer to the following general log-likelihood formula, V, typically used for a binary classification problem.

While GAN trains the discriminator to maximize the objective function, it trains the generator to minimize the second term of the objective function. And the co-authors called the overall objective “minimax game”. (Goodfellow, et al., 2014, p. 3) In this sense, the co-authors of the original GAN designed mini-max optimization for its training process.
Non-saturation Modification:
In its implementation, the co-authors encountered a problem of saturation during the early stage of training the generator.
“Early in learning, when G is poor, D can reject samples with high confidence because they are clearly different from the training data. In this case, log(1 — D(G(z))) saturates.”
In order to resolve the saturation issue, they converted the second term of the original log-likelihood objective function as follows and recommended to maximize it for the generator:
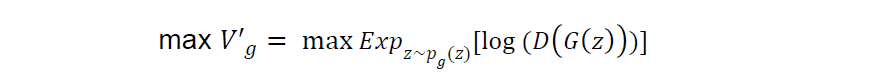
Evaluation
During the training, the generator continues creating better synthetic data indistinguishable by the discriminator, while the discriminator is improving its detecting ability. In this sense, the ultimate objective of GAN’s overall optimization is not to search for the global maximum of either of these objective functions. It is rather to seek an equilibrium point, where neither of agents can improve the performance. In a sese, at the equilibrium point, the discriminator is unable to distinguish between the real data and the synthetic data.
This goal setting of the objective function is very unique for GAN. And one of the co-authors, Ian Goodfellow, describe the equilibrium point as follows:
“it corresponds to a saddle point that is a local maximum for the classifier and a local minimum for the generator” (Goodfellow I. , 2015, p. 2).
More specifically, the equilibrium point can be conceptually represented by the probability of random guessing, 0.5 (50%).
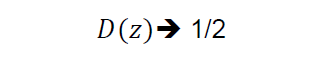
Alternating Training Process: Nested Bi-level Optimization
In order to achieve this ultimate goal, GAN designed an alternating learning process in a “bi-level optimization” framework, in which the training loop of the discriminator is nested within another higher training loop of the generator. This bi-level optimization framework enables GAN to alternate the training process between these two agents: k-steps of training D and one step of training G (Goodfellow, et al., 2014, p. 3). During the alternation of the two models, it is important to freeze the learning process of the other while training one model; “the generator is updated while holding the discriminator fixed, and vice versa” (Goodfellow I. , 2015, p. 3).
The following algorithm revised the original algorithm presented in the original GAN paper in order to fully reflect the recommended modification of the log-likelihood for the generator.

As you see in the algorithm, while GAN takes samples from both the generative model (generator) and the real data during the forward propagation, it trains the both agents during the backpropagation. (Goodfellow, et al., 2014, p. 2) It follows the convention of deep neural networks.
And GAN trains the discriminator first in the nested block, then trains the generator to fool the trained discriminator at every iteration at the upper loop. Then, it continues the iteration of the bi-level training until it arrives at an equilibrium point as discussed earlier.
Overall, technically, GAN learns the probability distribution of the real data through the generator; the discriminator is just one inner component built in the nested block within the generator’s learning mechanism. The objective function of the generator reflects the trained discriminator model on the piecemeal basis in its formula. In other words, for every iteration, the generator keeps updating its objective function once the discriminator gets trained within the nested optimization block.
That pretty much paints GAN’s algorithmic design of model optimization.
Summary
In order to alternately train two agents — the discriminator and the generator — GAN adopted a bi-level optimization framework, where the discriminator is trained in the inner block nested within the training block of the generator.
Since these two agents have diametrically opposite objectives (in the sense that the discriminator aims at maximizing its binary classifier’s objective function and the generator at minimizing it), the co-authors called the overall objective “minimax game”. (Goodfellow, et al., 2014, p. 3) Overall, GAN aims its mini-max optimization (training) objective at seeking an equilibrium point, where the discriminator is no longer able to distinguish between the real data and the synthetic data that the generator creates.
Its nested bi-level training framework and its equilibrium seeking objective setting (in contrast to maximization objectives) characterize the mini-max optimization framework of GAN.
At last, it is important to note that the leading author, Ian Goodfellow, characterizes that the original GAN is heuristic and has theoretical limitations. For example, convergence is not guaranteed when the objective function is not convex. And he articulated that GAN is open for further innovative improvements. As a matter of fact, a wide range of evaluation measures have been explored for variants of GAN application (Borji, 2018). In this sense, I would like to emphasize that the architectural design outlined in this article describes only the prototype of GAN that was introduced in the original GAN paper. Therefore, the architectural design introduced in this article is neither comprehensive nor universal for GAN.
Given that the precautionary note is well communicated with the readers, I hope that this article is useful for those who are new to GAN in starting their own journey with GAN.
References
- Borji, A. (2018, 10 24). Pros and Cons of GAN Evaluation Measures. Retrieved from ArXvi: https://arxiv.org/abs/1802.03446
- Goodfellow, I. (2015, 5 21). On distinguishability criteria for estimating generative models. Retrieved from ArXiv: https://arxiv.org/abs/1412.6515
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengioz, Y. (2014, 6 10). Generative Adversarial Nets. Retrieved from arXiv: https://arxiv.org/abs/1406.2661
- Knight, W. (2018, 8 17). Fake America great again. Retrieved from MIT Technology Review: https://www.technologyreview.com/2018/08/17/240305/fake-america-great-again/
Mini-Max Optimization Design of Generative Adversarial Networks (GAN) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Nested bi-level optimization and equilibrium seeking objective
Introduction
Generative Adversarial Networks (GAN) demonstrated outstanding performance in generating realistic synthetic data which were indistinguishable from the real data. Unfortunately, GAN caught the public’s attention because of its illegit applications, Deep Fake. (Knight, 2018)
As its name suggests, Generative Adversarial Nets (GAN) is composed of two networks: the generative network (the generator) and the adversarial network (the discriminator). Incorporating an adversarial scheme into its architecture makes GAN a special type of generative network.
Importantly, GAN is non-parametric, therefore, would not impose statistical requirements such as the Markov chain. Instead of imposing statistical assumptions, with the help of the adversary network, the generative network learns the probability distribution of the real data through back-propagation in deep neural networks.
In order to generate realistic synthetic data, GAN pits these two agents against each other within its architecture. In this game, while the generator attempts to simulate synthetic samples which imitate real samples, the discriminator attempts to distinguish between the real samples and the synthetic ones. In other words, while the generator, G, tries to deceive the discriminator by counterfeiting, the discriminator, D, plays a role of the police to detect the synthetic (fake) data. (Goodfellow, et al., 2014, p. 1) In a way, these two agents attempt to achieve diametrically opposite objectives.
As they improve their skills, the synthetic data becomes indistinguishable from the real data. Thanks to its adversary (the discriminator), the generator learns how to better imitate the probability distribution of the given real data.
Since within its architecture GAN has to train two learners that attempt to achieve contrasting objectives through interactions, it has a unique optimization design (bi-level training mechanism and equilibrium seeking objectives). In this context, it took me a while to digest the architectural design of GAN.
In this article, I want to share my journey of GAN with those who are new to GAN so that they can comprehend the architectural peculiarity of GAN more smoothly. I hope that the readers find this article useful as a supplementary note.
As a precaution, GAN is heuristic. And there are many variants of GAN today. This article discusses only the architectural design of the original GAN.
The Original GAN Design
The base architecture of the original GAN was introduced in a seminal paper: “Generative Adversarial Nets” (Goodfellow, et al., 2014). In this original GAN paper, in order to train these two agents which pursue the diametrically opposite objectives, the co-authors designed a “bi-level optimization (training)” architecture, in which one internal training block (training of the discriminator) is nested within another high-level training block (training of the generator). And GAN trains these two agents alternately in this bi-level training framework.

Discriminator and Generator
Now, let’s see what these two agents do in their learning process.
It is straight-forward that the discriminator is a binary classifier by design. Given mixed samples from the real data and the synthetic data, it classifies whether each sample is real (label=1) or fake/synthetic (label=0).
On the other hand, the generator is a noise distribution by design. And it is trained to imitate the probability distribution of the real dataset through an iteration. At every step of the training iteration, the learned generative model (updated generator) is copied and used as the new noise distribution. Thereafter, the new noise distribution is used to train the discriminator. (Goodfellow I. , 2015, p. 2).
Let’s set the following:
We take the input noise, z, and calculate its prior distribution, G(z), to define the generator. Say the learned distribution of the generator follows
In this setting, the ultimate goal of the generator is to deceive the discriminator by transforming its own distribution as close as the distribution of the real dataset.
Two Objective Functions: Mini-Max Game
Repeatedly, GAN has two agents to train within its architecture. And these agents have confronting objectives. Therefore, GAN has two objective functions: one for the discriminator and the other for the generator.
On one hand, the discriminator, D, as a binary classifier, needs to maximize the probability of correctly assigning labels to both the real data (label=1) and the synthetic data (label=0).
On the other hand, the ultimate goal of the generator is to fool the classifier by creating synthetic data which is indistinguishable from the real data. Therefore, the generator attempts to deceive the classifier so that the discriminator would classify the synthetic data with label 1. In other words, the objective of the generator is “to maximize the probability of D making a mistake.” (Goodfellow, et al., 2014, p. 1)
At a conceptual level, in order to achieve their diametrically opposite objectives, these two agents can refer to the following general log-likelihood formula, V, typically used for a binary classification problem.
While GAN trains the discriminator to maximize the objective function, it trains the generator to minimize the second term of the objective function. And the co-authors called the overall objective “minimax game”. (Goodfellow, et al., 2014, p. 3) In this sense, the co-authors of the original GAN designed mini-max optimization for its training process.
Non-saturation Modification:
In its implementation, the co-authors encountered a problem of saturation during the early stage of training the generator.
“Early in learning, when G is poor, D can reject samples with high confidence because they are clearly different from the training data. In this case, log(1 — D(G(z))) saturates.”
In order to resolve the saturation issue, they converted the second term of the original log-likelihood objective function as follows and recommended to maximize it for the generator:
Evaluation
During the training, the generator continues creating better synthetic data indistinguishable by the discriminator, while the discriminator is improving its detecting ability. In this sense, the ultimate objective of GAN’s overall optimization is not to search for the global maximum of either of these objective functions. It is rather to seek an equilibrium point, where neither of agents can improve the performance. In a sese, at the equilibrium point, the discriminator is unable to distinguish between the real data and the synthetic data.
This goal setting of the objective function is very unique for GAN. And one of the co-authors, Ian Goodfellow, describe the equilibrium point as follows:
“it corresponds to a saddle point that is a local maximum for the classifier and a local minimum for the generator” (Goodfellow I. , 2015, p. 2).
More specifically, the equilibrium point can be conceptually represented by the probability of random guessing, 0.5 (50%).
Alternating Training Process: Nested Bi-level Optimization
In order to achieve this ultimate goal, GAN designed an alternating learning process in a “bi-level optimization” framework, in which the training loop of the discriminator is nested within another higher training loop of the generator. This bi-level optimization framework enables GAN to alternate the training process between these two agents: k-steps of training D and one step of training G (Goodfellow, et al., 2014, p. 3). During the alternation of the two models, it is important to freeze the learning process of the other while training one model; “the generator is updated while holding the discriminator fixed, and vice versa” (Goodfellow I. , 2015, p. 3).
The following algorithm revised the original algorithm presented in the original GAN paper in order to fully reflect the recommended modification of the log-likelihood for the generator.
As you see in the algorithm, while GAN takes samples from both the generative model (generator) and the real data during the forward propagation, it trains the both agents during the backpropagation. (Goodfellow, et al., 2014, p. 2) It follows the convention of deep neural networks.
And GAN trains the discriminator first in the nested block, then trains the generator to fool the trained discriminator at every iteration at the upper loop. Then, it continues the iteration of the bi-level training until it arrives at an equilibrium point as discussed earlier.
Overall, technically, GAN learns the probability distribution of the real data through the generator; the discriminator is just one inner component built in the nested block within the generator’s learning mechanism. The objective function of the generator reflects the trained discriminator model on the piecemeal basis in its formula. In other words, for every iteration, the generator keeps updating its objective function once the discriminator gets trained within the nested optimization block.
That pretty much paints GAN’s algorithmic design of model optimization.
Summary
In order to alternately train two agents — the discriminator and the generator — GAN adopted a bi-level optimization framework, where the discriminator is trained in the inner block nested within the training block of the generator.
Since these two agents have diametrically opposite objectives (in the sense that the discriminator aims at maximizing its binary classifier’s objective function and the generator at minimizing it), the co-authors called the overall objective “minimax game”. (Goodfellow, et al., 2014, p. 3) Overall, GAN aims its mini-max optimization (training) objective at seeking an equilibrium point, where the discriminator is no longer able to distinguish between the real data and the synthetic data that the generator creates.
Its nested bi-level training framework and its equilibrium seeking objective setting (in contrast to maximization objectives) characterize the mini-max optimization framework of GAN.
At last, it is important to note that the leading author, Ian Goodfellow, characterizes that the original GAN is heuristic and has theoretical limitations. For example, convergence is not guaranteed when the objective function is not convex. And he articulated that GAN is open for further innovative improvements. As a matter of fact, a wide range of evaluation measures have been explored for variants of GAN application (Borji, 2018). In this sense, I would like to emphasize that the architectural design outlined in this article describes only the prototype of GAN that was introduced in the original GAN paper. Therefore, the architectural design introduced in this article is neither comprehensive nor universal for GAN.
Given that the precautionary note is well communicated with the readers, I hope that this article is useful for those who are new to GAN in starting their own journey with GAN.
References
- Borji, A. (2018, 10 24). Pros and Cons of GAN Evaluation Measures. Retrieved from ArXvi: https://arxiv.org/abs/1802.03446
- Goodfellow, I. (2015, 5 21). On distinguishability criteria for estimating generative models. Retrieved from ArXiv: https://arxiv.org/abs/1412.6515
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengioz, Y. (2014, 6 10). Generative Adversarial Nets. Retrieved from arXiv: https://arxiv.org/abs/1406.2661
- Knight, W. (2018, 8 17). Fake America great again. Retrieved from MIT Technology Review: https://www.technologyreview.com/2018/08/17/240305/fake-america-great-again/
Mini-Max Optimization Design of Generative Adversarial Networks (GAN) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.