
Model Quantization for Edge AI
Deep learning is witnessing a growing history of success. However, the large/heavy models that must be run on a high-performance computing system are far from optimal. Artificial intelligence is already widely used in business applications. The computational demands of AI inference and training are increasing. As a result, a relatively new class of deep learning approaches known as quantized neural network models has emerged to address this disparity. Memory has been one of the biggest challenges for deep learning architectures. It was an evolution of the gaming industry that led to the rapid development of hardware leading to GPUs, enabling 50 layer networks of today. Still, the hunger for memory by newer and powerful networks is now pushing for evolutions of Deep Learning model compression techniques to put a leash on this requirement, as AI is quickly moving towards edge devices to give near to real-time results for captured data. Model quantization is one such rapidly growing technology that has allowed deep learning models to be deployed on edge devices with less power, memory, and computational capacity than a full-fledged computer.
How Did AI Migrate From Cloud to Edge?
Many businesses use clouds as their primary AI engine. It can host required data via a cloud data center for performing intelligent decisions. This process of uploading data to cloud storage and interaction with data centers induces a delay in making real-time decisions. The cloud will not be a viable choice in the future as demand for IoT applications and their real-time responses grows. As a result, AI on the edge is becoming more popular.
Edge AI mostly works in a decentralized fashion. Small clusters of computer devices now work together to drive decision-making rather than going to a large processing center. Edge computing boosts the device’s real-time response significantly. Another advantage of edge AI over cloud AI is the lower cost of operation, bandwidth, and connectivity. Now, this is not easy as it sounds. Running AI models on the edge devices while maintaining the inference time and high throughput is equally challenging. Model Quantization is the key to solving this problem.
The Need for Quantization?
Now before going into quantization, let’s see why a neural network in general takes so much memory.
As shown in the above figure, a standard artificial neural network will consist of layers of interconnected neurons, with each having its own weight, bias, and activation function. These weights and biases are referred to as the “parameters” of a neural network. This gets stored physically in memory by a neural network. Standard 32-bit floating-point values are a standard representation for them, allowing a high level of precision and accuracy for the neural network.
Getting this accuracy makes any neural network take up a lot of memory. Imagine a neural network with millions of parameters and activations, getting stored as a 32-bit value, and the memory it will consume. For example, a 50-layer ResNet architecture will contain roughly 26 million weights and 16 million activations. So, using 32-bit floating-point values for both the weights and activations would make the entire architecture consume around 168 MB of storage. Quantization is the big terminology that includes different techniques to convert the input values from a large set to output values in a smaller set. The deep learning models that we use for inferencing are nothing but matrices with complex and iterative mathematical operations, which mostly include multiplications. Converting those 32-bit floating values to the 8-bit integer will lower the precision of the weights used.
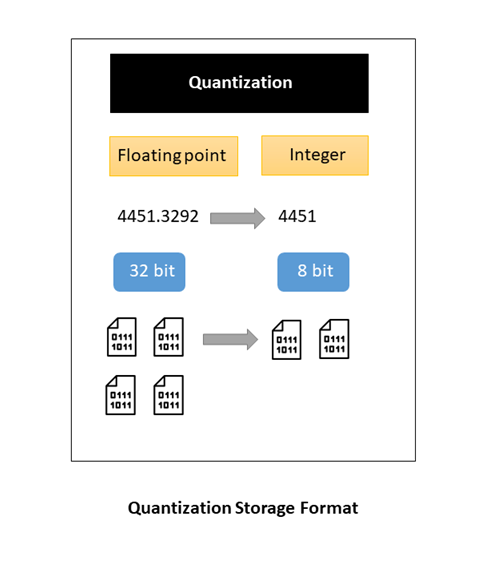
Due to this storage format, the footprint of the model in the memory gets reduced, and it drastically improves the performance of models. In deep learning, weights, and biases are stored as 32-bit floating-point numbers. When the model is trained, it can be reduced to 8-bit integers, which eventually reduces the model size. One can either reduce it to 16-bit floating points (2x size reduction) or 8-bit integers (4x size reduction). This will come with a trade-off in the accuracy of the model’s predictions. However, it has been empirically proven in many situations that a quantized model does not suffer from a significant decay or no decay at all in some scenarios.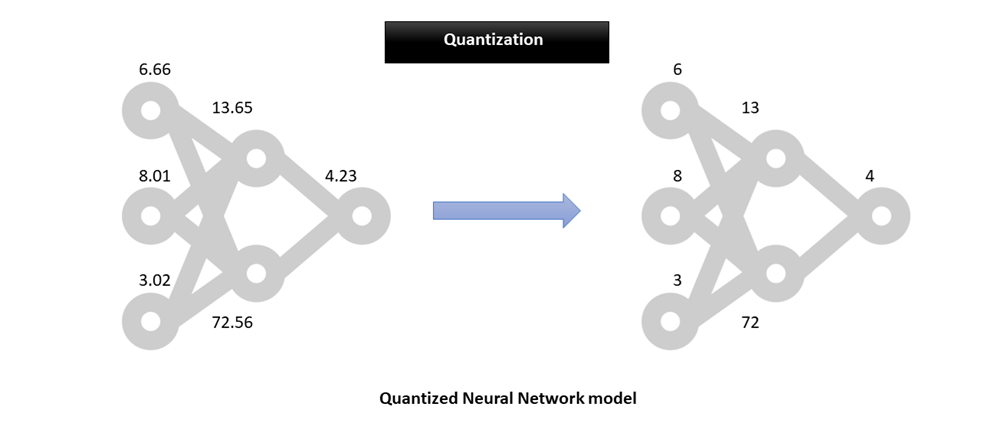
How Does the Quantization Process Work?
There are two ways to do model quantization, as explained below.
Post Training Quantization
As the name suggests, post-training quantization is a process of converting a pre-trained model to a quantized model, viz. converting the model parameters from 32-bit to 16-bit or 8-bit. It can further be of two types. One is hybrid quantization, where you just quantize weights and do not touch other parameters of the model. Another is Full Quantization, where you quantize both the weights and parameters of the model.
Quantization Aware Training
As the name suggests, here we quantize the model during the training time. Modifications are made to the network before initial training (using dummy quantize nodes) and it learns the 8-bit weights through training rather than going for conversion later.
Benefits and Drawbacks of Quantization
Quantized neural networks, in addition to improving performance, significantly improve power efficiency due to two factors: lower memory access costs and better computation efficiency. Lower-bit quantized data necessitates less data movement on both sides of the chip, reducing memory bandwidth and conserving a great deal of energy.
As mentioned earlier, it is proven empirically that quantized models don’t suffer from significant decay. Still, there are times when quantization greatly reduces models’ accuracy. Hence, with a good application of post-quantization or quantization-aware training, one can overcome this drop inaccuracy.
Model quantization is vital when it comes to developing and deploying AI models on edge devices that have low power, memory, and computing. It adds intelligence to the IoT ecosystem smoothly.
Deep learning is witnessing a growing history of success. However, the large/heavy models that must be run on a high-performance computing system are far from optimal. Artificial intelligence is already widely used in business applications. The computational demands of AI inference and training are increasing. As a result, a relatively new class of deep learning approaches known as quantized neural network models has emerged to address this disparity. Memory has been one of the biggest challenges for deep learning architectures. It was an evolution of the gaming industry that led to the rapid development of hardware leading to GPUs, enabling 50 layer networks of today. Still, the hunger for memory by newer and powerful networks is now pushing for evolutions of Deep Learning model compression techniques to put a leash on this requirement, as AI is quickly moving towards edge devices to give near to real-time results for captured data. Model quantization is one such rapidly growing technology that has allowed deep learning models to be deployed on edge devices with less power, memory, and computational capacity than a full-fledged computer.
How Did AI Migrate From Cloud to Edge?
Many businesses use clouds as their primary AI engine. It can host required data via a cloud data center for performing intelligent decisions. This process of uploading data to cloud storage and interaction with data centers induces a delay in making real-time decisions. The cloud will not be a viable choice in the future as demand for IoT applications and their real-time responses grows. As a result, AI on the edge is becoming more popular.
Edge AI mostly works in a decentralized fashion. Small clusters of computer devices now work together to drive decision-making rather than going to a large processing center. Edge computing boosts the device’s real-time response significantly. Another advantage of edge AI over cloud AI is the lower cost of operation, bandwidth, and connectivity. Now, this is not easy as it sounds. Running AI models on the edge devices while maintaining the inference time and high throughput is equally challenging. Model Quantization is the key to solving this problem.
The Need for Quantization?
Now before going into quantization, let’s see why a neural network in general takes so much memory.
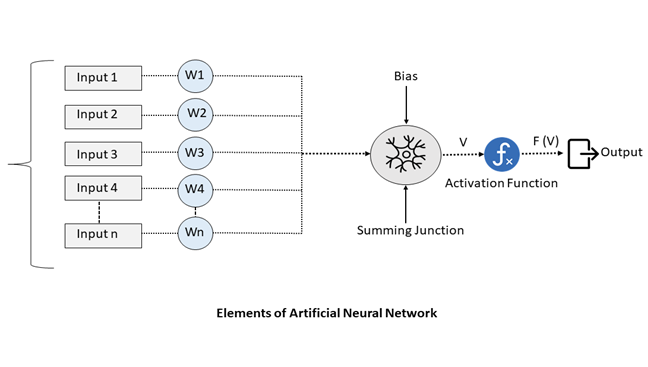
As shown in the above figure, a standard artificial neural network will consist of layers of interconnected neurons, with each having its own weight, bias, and activation function. These weights and biases are referred to as the “parameters” of a neural network. This gets stored physically in memory by a neural network. Standard 32-bit floating-point values are a standard representation for them, allowing a high level of precision and accuracy for the neural network.
Getting this accuracy makes any neural network take up a lot of memory. Imagine a neural network with millions of parameters and activations, getting stored as a 32-bit value, and the memory it will consume. For example, a 50-layer ResNet architecture will contain roughly 26 million weights and 16 million activations. So, using 32-bit floating-point values for both the weights and activations would make the entire architecture consume around 168 MB of storage. Quantization is the big terminology that includes different techniques to convert the input values from a large set to output values in a smaller set. The deep learning models that we use for inferencing are nothing but matrices with complex and iterative mathematical operations, which mostly include multiplications. Converting those 32-bit floating values to the 8-bit integer will lower the precision of the weights used.
Due to this storage format, the footprint of the model in the memory gets reduced, and it drastically improves the performance of models. In deep learning, weights, and biases are stored as 32-bit floating-point numbers. When the model is trained, it can be reduced to 8-bit integers, which eventually reduces the model size. One can either reduce it to 16-bit floating points (2x size reduction) or 8-bit integers (4x size reduction). This will come with a trade-off in the accuracy of the model’s predictions. However, it has been empirically proven in many situations that a quantized model does not suffer from a significant decay or no decay at all in some scenarios.
How Does the Quantization Process Work?
There are two ways to do model quantization, as explained below.
Post Training Quantization
As the name suggests, post-training quantization is a process of converting a pre-trained model to a quantized model, viz. converting the model parameters from 32-bit to 16-bit or 8-bit. It can further be of two types. One is hybrid quantization, where you just quantize weights and do not touch other parameters of the model. Another is Full Quantization, where you quantize both the weights and parameters of the model.
Quantization Aware Training
As the name suggests, here we quantize the model during the training time. Modifications are made to the network before initial training (using dummy quantize nodes) and it learns the 8-bit weights through training rather than going for conversion later.
Benefits and Drawbacks of Quantization
Quantized neural networks, in addition to improving performance, significantly improve power efficiency due to two factors: lower memory access costs and better computation efficiency. Lower-bit quantized data necessitates less data movement on both sides of the chip, reducing memory bandwidth and conserving a great deal of energy.
As mentioned earlier, it is proven empirically that quantized models don’t suffer from significant decay. Still, there are times when quantization greatly reduces models’ accuracy. Hence, with a good application of post-quantization or quantization-aware training, one can overcome this drop inaccuracy.
Model quantization is vital when it comes to developing and deploying AI models on edge devices that have low power, memory, and computing. It adds intelligence to the IoT ecosystem smoothly.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.