
Modelling New York City Bicycle Volumes Using Generalised Linear Models | by Egor Howell | Jul, 2022
A simple project walkthrough in fitting Generalised Linear Models in Python
Despite writing several articles on the topic and working in the insurance industry, I have actually never fitted a Generalised Linear Model (GLM) from scratch.
Shocking I know.
So, I have decided to spread my wings and carry out a small project where I can put all my theoretical knowledge into practise!
In this article, I want to walk you through a simple project using GLMs to model the bicycle crossing volumes in New York City. We will also briefly cover the main technical details behind GLMs and the motivations for their use.
The data used for this project was from the New York City Department of Transportation and is available here on Kaggle with a CC0 licence. Kaggle actually sourced this dataset fron NYC Open Data which you find here.
For the purpose of completeness, I will discuss the main concepts behind GLMs in this post. However, for a more in-depth understanding, I highly recommend you check out my previous articles that really deep-dive into their technical details:
Motivation
Generalised Linear Models literally ‘generalise’ Linear Regression to a target variable that is non-normal.
For example, here we are going to be modelling the bicycle crossing volumes in New York City. If we were going to model this as a Linear Regression problem, we would be assuming that the bicycle count against our features would follow a Normal distribution.
There are two issues with this:
- Normal distribution is continuous, whereas bicycle count is discrete.
- Normal distribution can be negative, but bicycle count is positive.
Hence, we use GLMs to overcome these issues and limitations of regular Linear Regression.
Mathematics
The general formula for Linear Regression is:

Where X are the features, β are the coefficients with β_0 being the intercept and E[Y | X] is the expected value (mean) of Y given our data X.
To transform this Linear Regression formula to incorporate non-normal distributions, we attach something called the link function, g():

The link function literally ‘links’ your linear combination input to your desired target distribution.
The link function can either be found empirically or mathematically for each distribution. In the articles I have linked above, I go through deriving the link functions for some distributions.
Not every distibution is covered under the GLM umbrella. The distributions have to be part of the exponential family. However, most of your common distributions: Gamma, Poisson, Binomial and Bernoulli are all part of this family.
The link function for the Normal distribution (Linear Regression) is called the identity.
Poisson Regression
To model our bicycle volumes we will use the Poisson distribution. This distribution describes the probability of a certain number of events occurring in a given timeframe with a mean occurrence rate.
To learn more about the Poisson distribution check out my article about it here.
For Poisson Regression, the link function is the natural log:
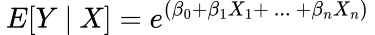
As you can see, our output will now always be positive as we are using the exponential. This means we will avoid any possible non-sensical results, unlike if we used Linear Regression where the output could have been negative.
Again, I haven’t done a full thorough analysis of GLMs as it would be exhaustive and I have previously covered these topics. If you are interested in learning more about GLMs, make sure to check out my articles I linked above or any of the hyperlinks I have provided throughout!
Packages
We will first download the basic Data Science packages and also the statsmodels package for GLM modelling.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import statsmodels.api as sm
from statsmodels.formula.api import glm
Data
Read in and print the data:
data = pd.read_csv('nyc-east-river-bicycle-counts.csv')
data.head()

Here we have the bike volumes across the four bridges: Brooklyn, Manhattan, Williamsburg and Queensboro with their sum under the ‘Total’ feature.
There are duplicate columns for ‘Date’ and the index, so lets clean that up:
data.drop(['Unnamed: 0', 'Day'], axis=1, inplace=True)
data.head()

Notice there are two columns for temperature: high and low. Lets make that a single column by taking their mean:
data['Mean_Temp'] = (data['High Temp (°F)'] + data['Low Temp (°F)'])/2
data.head()

The precipitation column contains some strings, so lets remove those:
data['Precipitation'].replace(to_replace='0.47 (S)', value=0.47, inplace=True)
data['Precipitation'].replace(to_replace='T', value=0, inplace=True)
data['Precipitation'] = data['Precipitation'].astype(np.float16)
data.head()

Visualisations
The two main independent variables that affect bicycle volumes are temperature and precipitation. We can plot these two variables against the target variable ‘Total’:
fig = plt.figure(figsize=(22,7))
ax = fig.add_subplot(121)
ax.scatter(data['Mean_Temp'], data['Total'], linewidth=4, color='blue')
ax.tick_params(axis="x", labelsize=22)
ax.tick_params(axis="y", labelsize=22)
ax.set_xlabel('Mean Temperature', fontsize=22)
ax.set_ylabel('Total Bikes', fontsize=22)
ax2 = fig.add_subplot(122)
ax2.scatter(data['Precipitation'], data['Total'], linewidth=4, color='red')
ax2.tick_params(axis="x", labelsize=22)
ax2.tick_params(axis="y", labelsize=22)
ax2.set_xlabel('Precipitation', fontsize=22)
ax2.set_ylabel('Total Bikes', fontsize=22)

Modelling
We can now build a model to predict ‘Total’ using the mean temperature feature through the statsmodel package. As this relationship is Poisson, we will use the natural log link function:
model = glm('Total ~ Mean_Temp', data = data[['Total','Mean_Temp']], family = sm.families.Poisson())
results = model.fit()
results.summary()

We used the R-style formula for the GLM as that gives better performance in the backend.
Analysis
From the output above, we see that the coefficient for the mean temperature is 0.0263 and the intercept is 8.1461.
Using the Poisson Regression formula we presented above, the equation of our line is then:

x = np.linspace(data['Mean_Temp'].min(),data['Mean_Temp'].max(),100)
y = np.exp(x*results.params[1] + results.params[0])plt.figure(figsize=(10,6))
plt.scatter(data['Mean_Temp'], data['Total'], linewidth=3, color='blue')
plt.plot(x, y, label = 'Poisson Regression', color='red', linewidth=3)
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.xlabel('Mean Temperature', fontsize=18)
plt.ylabel('Total Count', fontsize=18 )
plt.legend(fontsize=18)
plt.show()

Eureka! We have fitted a GLM!
For the interested reader, the algorithm used by statsmodels to fit the GLM is called iteratively reweighted least squares.
The full code/notebook is available at my GitHub here:
In this article we had a short discussion of the short-comings of Linear Regression and how GLMs solve this issue by providing a wider and generic framework for regression models. We then fit a basic Poisson Regression line to model the number of bicycles in New York City as a function of daily average temperature.
A simple project walkthrough in fitting Generalised Linear Models in Python
Despite writing several articles on the topic and working in the insurance industry, I have actually never fitted a Generalised Linear Model (GLM) from scratch.
Shocking I know.
So, I have decided to spread my wings and carry out a small project where I can put all my theoretical knowledge into practise!
In this article, I want to walk you through a simple project using GLMs to model the bicycle crossing volumes in New York City. We will also briefly cover the main technical details behind GLMs and the motivations for their use.
The data used for this project was from the New York City Department of Transportation and is available here on Kaggle with a CC0 licence. Kaggle actually sourced this dataset fron NYC Open Data which you find here.
For the purpose of completeness, I will discuss the main concepts behind GLMs in this post. However, for a more in-depth understanding, I highly recommend you check out my previous articles that really deep-dive into their technical details:
Motivation
Generalised Linear Models literally ‘generalise’ Linear Regression to a target variable that is non-normal.
For example, here we are going to be modelling the bicycle crossing volumes in New York City. If we were going to model this as a Linear Regression problem, we would be assuming that the bicycle count against our features would follow a Normal distribution.
There are two issues with this:
- Normal distribution is continuous, whereas bicycle count is discrete.
- Normal distribution can be negative, but bicycle count is positive.
Hence, we use GLMs to overcome these issues and limitations of regular Linear Regression.
Mathematics
The general formula for Linear Regression is:
Where X are the features, β are the coefficients with β_0 being the intercept and E[Y | X] is the expected value (mean) of Y given our data X.
To transform this Linear Regression formula to incorporate non-normal distributions, we attach something called the link function, g():
The link function literally ‘links’ your linear combination input to your desired target distribution.
The link function can either be found empirically or mathematically for each distribution. In the articles I have linked above, I go through deriving the link functions for some distributions.
Not every distibution is covered under the GLM umbrella. The distributions have to be part of the exponential family. However, most of your common distributions: Gamma, Poisson, Binomial and Bernoulli are all part of this family.
The link function for the Normal distribution (Linear Regression) is called the identity.
Poisson Regression
To model our bicycle volumes we will use the Poisson distribution. This distribution describes the probability of a certain number of events occurring in a given timeframe with a mean occurrence rate.
To learn more about the Poisson distribution check out my article about it here.
For Poisson Regression, the link function is the natural log:
As you can see, our output will now always be positive as we are using the exponential. This means we will avoid any possible non-sensical results, unlike if we used Linear Regression where the output could have been negative.
Again, I haven’t done a full thorough analysis of GLMs as it would be exhaustive and I have previously covered these topics. If you are interested in learning more about GLMs, make sure to check out my articles I linked above or any of the hyperlinks I have provided throughout!
Packages
We will first download the basic Data Science packages and also the statsmodels package for GLM modelling.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import statsmodels.api as sm
from statsmodels.formula.api import glm
Data
Read in and print the data:
data = pd.read_csv('nyc-east-river-bicycle-counts.csv')
data.head()
Here we have the bike volumes across the four bridges: Brooklyn, Manhattan, Williamsburg and Queensboro with their sum under the ‘Total’ feature.
There are duplicate columns for ‘Date’ and the index, so lets clean that up:
data.drop(['Unnamed: 0', 'Day'], axis=1, inplace=True)
data.head()
Notice there are two columns for temperature: high and low. Lets make that a single column by taking their mean:
data['Mean_Temp'] = (data['High Temp (°F)'] + data['Low Temp (°F)'])/2
data.head()
The precipitation column contains some strings, so lets remove those:
data['Precipitation'].replace(to_replace='0.47 (S)', value=0.47, inplace=True)
data['Precipitation'].replace(to_replace='T', value=0, inplace=True)
data['Precipitation'] = data['Precipitation'].astype(np.float16)
data.head()
Visualisations
The two main independent variables that affect bicycle volumes are temperature and precipitation. We can plot these two variables against the target variable ‘Total’:
fig = plt.figure(figsize=(22,7))
ax = fig.add_subplot(121)
ax.scatter(data['Mean_Temp'], data['Total'], linewidth=4, color='blue')
ax.tick_params(axis="x", labelsize=22)
ax.tick_params(axis="y", labelsize=22)
ax.set_xlabel('Mean Temperature', fontsize=22)
ax.set_ylabel('Total Bikes', fontsize=22)
ax2 = fig.add_subplot(122)
ax2.scatter(data['Precipitation'], data['Total'], linewidth=4, color='red')
ax2.tick_params(axis="x", labelsize=22)
ax2.tick_params(axis="y", labelsize=22)
ax2.set_xlabel('Precipitation', fontsize=22)
ax2.set_ylabel('Total Bikes', fontsize=22)
Modelling
We can now build a model to predict ‘Total’ using the mean temperature feature through the statsmodel package. As this relationship is Poisson, we will use the natural log link function:
model = glm('Total ~ Mean_Temp', data = data[['Total','Mean_Temp']], family = sm.families.Poisson())
results = model.fit()
results.summary()
We used the R-style formula for the GLM as that gives better performance in the backend.
Analysis
From the output above, we see that the coefficient for the mean temperature is 0.0263 and the intercept is 8.1461.
Using the Poisson Regression formula we presented above, the equation of our line is then:
x = np.linspace(data['Mean_Temp'].min(),data['Mean_Temp'].max(),100)
y = np.exp(x*results.params[1] + results.params[0])plt.figure(figsize=(10,6))
plt.scatter(data['Mean_Temp'], data['Total'], linewidth=3, color='blue')
plt.plot(x, y, label = 'Poisson Regression', color='red', linewidth=3)
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.xlabel('Mean Temperature', fontsize=18)
plt.ylabel('Total Count', fontsize=18 )
plt.legend(fontsize=18)
plt.show()
Eureka! We have fitted a GLM!
For the interested reader, the algorithm used by statsmodels to fit the GLM is called iteratively reweighted least squares.
The full code/notebook is available at my GitHub here:
In this article we had a short discussion of the short-comings of Linear Regression and how GLMs solve this issue by providing a wider and generic framework for regression models. We then fit a basic Poisson Regression line to model the number of bicycles in New York City as a function of daily average temperature.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.