
Nine Rules for Accessing Cloud Files from Your Rust Code
Practical lessons from upgrading Bed-Reader, a bioinformatics library
Would you like your Rust program to seamlessly access data from files in the cloud? When I refer to “files in the cloud,” I mean data housed on web servers or within cloud storage solutions like AWS S3, Azure Blob Storage, or Google Cloud Storage. The term “read”, here, encompasses both the sequential retrieval of file contents — be they text or binary, from beginning to end —and the capability to pinpoint and extract specific sections of the file as needed.
Upgrading your program to access cloud files can reduce annoyance and complication: the annoyance of downloading to local storage and the complication of periodically checking that a local copy is up to date.
Sadly, upgrading your program to access cloud files can also increase annoyance and complication: the annoyance of URLs and credential information, and the complication of asynchronous programming.
Bed-Reader is a Python package and Rust crate for reading PLINK Bed Files, a binary format used in bioinformatics to store genotype (DNA) data. At a user’s request, I recently updated Bed-Reader to optionally read data directly from cloud storage. Along the way, I learned nine rules that can help you add cloud-file support to your programs. The rules are:
- Use crate object_store (and, perhaps, cloud-file) to sequentially read the bytes of a cloud file.
- Sequentially read text lines from cloud files via two nested loops.
- Randomly access cloud files, even giant ones, with “range” methods, while respecting server-imposed limits.
- Use URL strings and option strings to access HTTP, Local Files, AWS S3, Azure, and Google Cloud.
- Test via tokio::test on http and local files.
If other programs call your program — in other words, if your program offers an API (application program interface) — four additional rules apply:
6. For maximum performance, add cloud-file support to your Rust library via an async API.
7. Alternatively, for maximum convenience, add cloud-file support to your Rust library via a traditional (“synchronous”) API.
8. Follow the rules of good API design in part by using hidden lines in your doc tests.
9. Include a runtime, but optionally.
Aside: To avoid wishy-washiness, I call these “rules”, but they are, of course, just suggestions.
Rule 1: Use crate object_store (and, perhaps, cloud-file) to sequentially read the bytes of a cloud file.
The powerful object_store crate provides full content access to files stored on http, AWS S3, Azure, Google Cloud, and local files. It is part of the Apache Arrow project and has over 2.4 million downloads.
For this article, I also created a new crate called cloud-file. It simplifies the use of the object_store crate. It wraps and focuses on a useful subset of object_store’s features. You can either use it directly, or pull-out its code for your own use.
Let’s look at an example. We’ll count the lines of a cloud file by counting the number of newline characters it contains.
use cloud_file::{CloudFile, CloudFileError};
use futures_util::StreamExt; // Enables `.next()` on streams.
async fn count_lines(cloud_file: &CloudFile) -> Result<usize, CloudFileError> {
let mut chunks = cloud_file.stream_chunks().await?;
let mut newline_count: usize = 0;
while let Some(chunk) = chunks.next().await {
let chunk = chunk?;
newline_count += bytecount::count(&chunk, b'\n');
}
Ok(newline_count)
}
#[tokio::main]
async fn main() -> Result<(), CloudFileError> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/toydata.5chrom.fam";
let options = [("timeout", "10s")];
let cloud_file = CloudFile::new_with_options(url, options)?;
let line_count = count_lines(&cloud_file).await?;
println!("line_count: {line_count}");
Ok(())
}
When we run this code, it returns:
line_count: 500
Some points of interest:
- We use async (and, here, tokio). We’ll discuss this choice more in Rules 6 and 7.
- We turn a URL string and string options into a CloudFile instance with CloudFile::new_with_options(url, options)?. We use ? to catch malformed URLs).
- We create a stream of binary chunks with cloud_file.stream_chunks().await?. This is the first place that the code tries to access the cloud file. If the file doesn’t exist or we can’t open it, the ? will return an error.
- We use chunks.next().await to retrieve the file’s next binary chunk. (Note the use futures_util::StreamExt;.) The next method returns None after all chunks have been retrieved.
- What if there is a next chunk but also a problem retrieving it? We’ll catch any problem with let chunk = chunk?;.
- Finally, we use the fast bytecount crate to count newline characters.
In contrast with this cloud solution, think about how you would write a simple line counter for a local file. You might write this:
use std::fs::File;
use std::io::{self, BufRead, BufReader};
fn main() -> io::Result<()> {
let path = "examples/line_counts_local.rs";
let reader = BufReader::new(File::open(path)?);
let mut line_count = 0;
for line in reader.lines() {
let _line = line?;
line_count += 1;
}
println!("line_count: {line_count}");
Ok(())
}
Between the cloud-file version and the local-file version, three differences stand out. First, we can easily read local files as text. By default, we read cloud files as binary (but see Rule 2). Second, by default, we read local files synchronously, blocking program execution until completion. On the other hand, we usually access cloud files asynchronously, allowing other parts of the program to continue running while waiting for the relatively slow network access to complete. Third, iterators such as lines() support for. However, streams such as stream_chunks() do not, so we use while let.
I mentioned earlier that you didn’t need to use the cloud-file wrapper and that you could use the object_store crate directly. Let’s see what it looks like when we count the newlines in a cloud file using only object_store methods:
use futures_util::StreamExt; // Enables `.next()` on streams.
pub use object_store::path::Path as StorePath;
use object_store::{parse_url_opts, ObjectStore};
use std::sync::Arc;
use url::Url;
async fn count_lines(
object_store: &Arc<Box<dyn ObjectStore>>,
store_path: StorePath,
) -> Result<usize, anyhow::Error> {
let mut chunks = object_store.get(&store_path).await?.into_stream();
let mut newline_count: usize = 0;
while let Some(chunk) = chunks.next().await {
let chunk = chunk?;
newline_count += bytecount::count(&chunk, b'\n');
}
Ok(newline_count)
}
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/toydata.5chrom.fam";
let options = [("timeout", "10s")];
let url = Url::parse(url)?;
let (object_store, store_path) = parse_url_opts(&url, options)?;
let object_store = Arc::new(object_store); // enables cloning and borrowing
let line_count = count_lines(&object_store, store_path).await?;
println!("line_count: {line_count}");
Ok(())
}
You’ll see the code is very similar to the cloud-file code. The differences are:
- Instead of one CloudFile input, most methods take two inputs: an ObjectStore and a StorePath. Because ObjectStore is a non-cloneable trait, here the count_lines function specifically uses &Arc<Box<dyn ObjectStore>>. Alternatively, we could make the function generic and use &Arc<impl ObjectStore>.
- Creating the ObjectStore instance, the StorePath instance, and the stream requires a few extra steps compared to creating a CloudFile instance and a stream.
- Instead of dealing with one error type (namely, CloudFileError), multiple error types are possible, so we fall back to using the anyhow crate.
Whether you use object_store (with 2.4 million downloads) directly or indirectly via cloud-file (currently, with 124 downloads 😀), is up to you.
For the rest of this article, I’ll focus on cloud-file. If you want to translate a cloud-file method into pure object_store code, look up the cloud-file method’s documentation and follow the "source" link. The source is usually only a line or two.
We’ve seen how to sequentially read the bytes of a cloud file. Let’s look next at sequentially reading its lines.
Rule 2: Sequentially read text lines from cloud files via two nested loops.
We often want to sequentially read the lines of a cloud file. To do that with cloud-file (or object_store) requires two nested loops.
The outer loop yields binary chunks, as before, but with a key modification: we now ensure that each chunk only contains complete lines, starting from the first character of a line and ending with a newline character. In other words, chunks may consist of one or more complete lines but no partial lines. The inner loop turns the chunk into text and iterates over the resultant one or more lines.
In this example, given a cloud file and a number n, we find the line at index position n:
use cloud_file::CloudFile;
use futures::StreamExt; // Enables `.next()` on streams.
use std::str::from_utf8;
async fn nth_line(cloud_file: &CloudFile, n: usize) -> Result<String, anyhow::Error> {
// Each binary line_chunk contains one or more lines, that is, each chunk ends with a newline.
let mut line_chunks = cloud_file.stream_line_chunks().await?;
let mut index_iter = 0usize..;
while let Some(line_chunk) = line_chunks.next().await {
let line_chunk = line_chunk?;
let lines = from_utf8(&line_chunk)?.lines();
for line in lines {
let index = index_iter.next().unwrap(); // safe because we know the iterator is infinite
if index == n {
return Ok(line.to_string());
}
}
}
Err(anyhow::anyhow!("Not enough lines in the file"))
}
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/toydata.5chrom.fam";
let n = 4;
let cloud_file = CloudFile::new(url)?;
let line = nth_line(&cloud_file, n).await?;
println!("line at index {n}: {line}");
Ok(())
}
The code prints:
line at index 4: per4 per4 0 0 2 0.452591
Some points of interest:
- The key method is .stream_line_chunks().
- We must also call std::str::from_utf8 to create text. (Possibly returning a Utf8Error.) Also, we call the .lines() method to create an iterator of lines.
- If we want a line index, we must make it ourselves. Here we use:
let mut index_iter = 0usize..;
...
let index = index_iter.next().unwrap(); // safe because we know the iterator is infinite
Aside: Why two loops? Why doesn’t cloud-file define a new stream that returns one line at a time? Because I don’t know how. If anyone can figure it out, please send me a pull request with the solution!
I wish this was simpler. I’m happy it is efficient. Let’s return to simplicity by next look at randomly accessing cloud files.
Rule 3: Randomly access cloud files, even giant ones, with range methods, while respecting server-imposed limits.
I work with a genomics file format called PLINK Bed 1.9. Files can be as large as 1 TB. Too big for web access? Not necessarily. We sometimes only need a fraction of the file. Moreover, modern cloud services (including most web servers) can efficiently retrieve regions of interest from a cloud file.
Let’s look at an example. This test code uses a CloudFile method called read_range_and_file_size It reads a *.bed file’s first 3 bytes, checks that the file starts with the expected bytes, and then checks for the expected length.
#[tokio::test]
async fn check_file_signature() -> Result<(), CloudFileError> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/plink_sim_10s_100v_10pmiss.bed";
let cloud_file = CloudFile::new(url)?;
let (bytes, size) = cloud_file.read_range_and_file_size(0..3).await?;
assert_eq!(bytes.len(), 3);
assert_eq!(bytes[0], 0x6c);
assert_eq!(bytes[1], 0x1b);
assert_eq!(bytes[2], 0x01);
assert_eq!(size, 303);
Ok(())
}
Notice that in one web call, this method returns not just the bytes requested, but also the size of the whole file.
Here is a list of high-level CloudFile methods and what they can retrieve in one web call:
- read_all — Whole file contents as an in-memory Bytes
- read_range — Bytes from a specified range
- read_ranges — Vec of Bytes from specified ranges
- read_range_and_file_size — Bytes from a specified range & the file’s size
- read_file_size — Size of the file
These methods can run into two problems if we ask for too much data at a time. First, our cloud service may limit the number of bytes we can retrieve in one call. Second, we may get faster results by making multiple simultaneous requests rather than just one at a time.
Consider this example: We want to gather statistics on the frequency of adjacent ASCII characters in a file of any size. For example, in a random sample of 10,000 adjacent characters, perhaps “th” appears 171 times.
Suppose our web server is happy with 10 concurrent requests but only wants us to retrieve 750 bytes per call. (8 MB would be a more normal limit).
Thanks to Ben Lichtman (B3NNY) at the Seattle Rust Meetup for pointing me in the right direction on adding limits to async streams.
Our main function could look like this:
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
let url = "https://www.gutenberg.org/cache/epub/100/pg100.txt";
let options = [("timeout", "30s")];
let cloud_file = CloudFile::new_with_options(url, options)?;
let seed = Some(0u64);
let sample_count = 10_000;
let max_chunk_bytes = 750; // 8_000_000 is a good default when chunks are bigger.
let max_concurrent_requests = 10; // 10 is a good default
count_bigrams(
cloud_file,
sample_count,
seed,
max_concurrent_requests,
max_chunk_bytes,
)
.await?;
Ok(())
}
The count_bigrams function can start by creating a random number generator and making a call to find the size of the cloud file:
#[cfg(not(target_pointer_width = "64"))]
compile_error!("This code requires a 64-bit target architecture.");
use cloud_file::CloudFile;
use futures::pin_mut;
use futures_util::StreamExt; // Enables `.next()` on streams.
use rand::{rngs::StdRng, Rng, SeedableRng};
use std::{cmp::max, collections::HashMap, ops::Range};
async fn count_bigrams(
cloud_file: CloudFile,
sample_count: usize,
seed: Option<u64>,
max_concurrent_requests: usize,
max_chunk_bytes: usize,
) -> Result<(), anyhow::Error> {
// Create a random number generator
let mut rng = if let Some(s) = seed {
StdRng::seed_from_u64(s)
} else {
StdRng::from_entropy()
};
// Find the document size
let file_size = cloud_file.read_file_size().await?;
//...
Next, based on the file size, the function can create a vector of 10,000 random two-byte ranges.
// Randomly choose the two-byte ranges to sample
let range_samples: Vec<Range<usize>> = (0..sample_count)
.map(|_| rng.gen_range(0..file_size - 1))
.map(|start| start..start + 2)
.collect();
For example, it might produce the vector [4122418..4122420, 4361192..4361194, 145726..145728, … ]. But retrieving 20,000 bytes at once (we are pretending) is too much. So, we divide the vector into 27 chunks of no more than 750 bytes:
// Divide the ranges into chunks respecting the max_chunk_bytes limit
const BYTES_PER_BIGRAM: usize = 2;
let chunk_count = max(1, max_chunk_bytes / BYTES_PER_BIGRAM);
let range_chunks = range_samples.chunks(chunk_count);
Using a little async magic, we create an iterator of future work for each of the 27 chunks and then we turn that iterator into a stream. We tell the stream to do up to 10 simultaneous calls. Also, we say that out-of-order results are fine.
// Create an iterator of future work
let work_chunks_iterator = range_chunks.map(|chunk| {
let cloud_file = cloud_file.clone(); // by design, clone is cheap
async move { cloud_file.read_ranges(chunk).await }
});
// Create a stream of futures to run out-of-order and with constrained concurrency.
let work_chunks_stream =
futures_util::stream::iter(work_chunks_iterator).buffer_unordered(max_concurrent_requests);
pin_mut!(work_chunks_stream); // The compiler says we need this
In the last section of code, we first do the work in the stream and — as we get results — tabulate. Finally, we sort and print the top results.
// Run the futures and, as result bytes come in, tabulate.
let mut bigram_counts = HashMap::new();
while let Some(result) = work_chunks_stream.next().await {
let bytes_vec = result?;
for bytes in bytes_vec.iter() {
let bigram = (bytes[0], bytes[1]);
let count = bigram_counts.entry(bigram).or_insert(0);
*count += 1;
}
}
// Sort the bigrams by count and print the top 10
let mut bigram_count_vec: Vec<(_, usize)> = bigram_counts.into_iter().collect();
bigram_count_vec.sort_by(|a, b| b.1.cmp(&a.1));
for (bigram, count) in bigram_count_vec.into_iter().take(10) {
let char0 = (bigram.0 as char).escape_default();
let char1 = (bigram.1 as char).escape_default();
println!("Bigram ('{}{}') occurs {} times", char0, char1, count);
}
Ok(())
}
The output is:
Bigram ('\r\n') occurs 367 times
Bigram ('e ') occurs 221 times
Bigram (' t') occurs 184 times
Bigram ('th') occurs 171 times
Bigram ('he') occurs 158 times
Bigram ('s ') occurs 143 times
Bigram ('.\r') occurs 136 times
Bigram ('d ') occurs 133 times
Bigram (', ') occurs 127 times
Bigram (' a') occurs 121 times
The code for the Bed-Reader genomics crate uses the same technique to retrieve information from scattered DNA regions of interest. As the DNA information comes in, perhaps out of order, the code fills in the correct columns of an output array.
Aside: This method uses an iterator, a stream, and a loop. I wish it were simpler. If you can figure out a simpler way to retrieve a vector of regions while limiting the maximum chunk size and the maximum number of concurrent requests, please send me a pull request.
That covers access to files stored on an HTTP server, but what about AWS S3 and other cloud services? What about local files?
Rule 4: Use URL strings and option strings to access HTTP, Local Files, AWS S3, Azure, and Google Cloud.
The object_store crate (and the cloud-file wrapper crate) supports specifying files either via a URL string or via structs. I recommend sticking with URL strings, but the choice is yours.
Let’s consider an AWS S3 example. As you can see, AWS access requires credential information.
use cloud_file::CloudFile;
use rusoto_credential::{CredentialsError, ProfileProvider, ProvideAwsCredentials};
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
// get credentials from ~/.aws/credentials
let credentials = if let Ok(provider) = ProfileProvider::new() {
provider.credentials().await
} else {
Err(CredentialsError::new("No credentials found"))
};
let Ok(credentials) = credentials else {
eprintln!("Skipping example because no AWS credentials found");
return Ok(());
};
let url = "s3://bedreader/v1/toydata.5chrom.bed";
let options = [
("aws_region", "us-west-2"),
("aws_access_key_id", credentials.aws_access_key_id()),
("aws_secret_access_key", credentials.aws_secret_access_key()),
];
let cloud_file = CloudFile::new_with_options(url, options)?;
assert_eq!(cloud_file.read_file_size().await?, 1_250_003);
Ok(())
}
The key part is:
let url = "s3://bedreader/v1/toydata.5chrom.bed";
let options = [
("aws_region", "us-west-2"),
("aws_access_key_id", credentials.aws_access_key_id()),
("aws_secret_access_key", credentials.aws_secret_access_key()),
];
let cloud_file = CloudFile::new_with_options(url, options)?;
If we wish to use structs instead of URL strings, this becomes:
use object_store::{aws::AmazonS3Builder, path::Path as StorePath};
let s3 = AmazonS3Builder::new()
.with_region("us-west-2")
.with_bucket_name("bedreader")
.with_access_key_id(credentials.aws_access_key_id())
.with_secret_access_key(credentials.aws_secret_access_key())
.build()?;
let store_path = StorePath::parse("v1/toydata.5chrom.bed")?;
let cloud_file = CloudFile::from_structs(s3, store_path);
I prefer the URL approach over structs. I find URLs slightly simpler, much more uniform across cloud services, and vastly easier for interop (with, for example, Python).
Here are example URLs for the three web services I have used:
- HTTP — https://www.gutenberg.org/cache/epub/100/pg100.txt
- local file — file:///M:/data%20files/small.bed — use the cloud_file::abs_path_to_url_string function to properly encode a full file path into a URL
- AWS S3 — s3://bedreader/v1/toydata.5chrom.bed
Local files don’t need options. For the other services, here are links to their supported options and selected examples:
- HTTP — ClientConfigKey — [("timeout", "30s")]
- AWS S3 — AmazonS3ConfigKey — [("aws_region", "us-west-2"), ("aws_access_key_id", …), ("aws_secret_access_key", …)]
- Azure — AzureConfigKey
- Google — GoogleConfigKey
Now that we can specify and read cloud files, we should create tests.
Rule 5: Test via tokio::test on http and local files.
The object_store crate (and cloud-file) supports any async runtime. For testing, the Tokio runtime makes it easy to test your code on cloud files. Here is a test on an http file:
[tokio::test]
async fn cloud_file_extension() -> Result<(), CloudFileError> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/plink_sim_10s_100v_10pmiss.bed";
let mut cloud_file = CloudFile::new(url)?;
assert_eq!(cloud_file.read_file_size().await?, 303);
cloud_file.set_extension("fam")?;
assert_eq!(cloud_file.read_file_size().await?, 130);
Ok(())
}
Run this test with:
cargo test
If you don’t want to hit an outside web server with your tests, you can instead test against local files as though they were in the cloud.
#[tokio::test]
async fn local_file() -> Result<(), CloudFileError> {
use std::env;
let apache_url = abs_path_to_url_string(env::var("CARGO_MANIFEST_DIR").unwrap()
+ "/LICENSE-APACHE")?;
let cloud_file = CloudFile::new(&apache_url)?;
assert_eq!(cloud_file.read_file_size().await?, 9898);
Ok(())
}
This uses the standard Rust environment variable CARGO_MANIFEST_DIR to find the full path to a text file. It then uses cloud_file::abs_path_to_url_string to correctly encode that full path into a URL.
Whether you test on http files or local files, the power of object_store means that your code should work on any cloud service, including AWS S3, Azure, and Google Cloud.
If you only need to access cloud files for your own use, you can stop reading the rules here and skip to the conclusion. If you are adding cloud access to a library (Rust crate) for others, keep reading.
Rule 6: For maximum performance, add cloud-file support to your Rust library via an async API.
If you offer a Rust crate to others, supporting cloud files offers great convenience to your users, but not without a cost. Let’s look at Bed-Reader, the genomics crate to which I added cloud support.
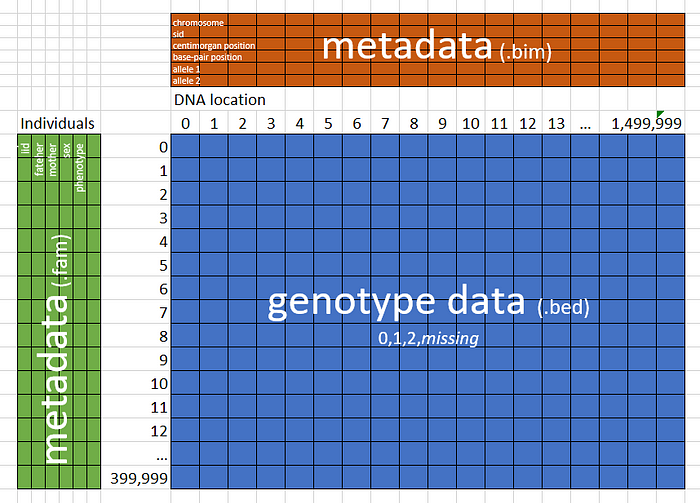
As previously mentioned, Bed-Reader is a library for reading and writing PLINK Bed Files, a binary format used in bioinformatics to store genotype (DNA) data. Files in Bed format can be as large as a terabyte. Bed-Reader gives users fast, random access to large subsets of the data. It returns a 2-D array in the user’s choice of int8, float32, or float64. Bed-Reader also gives users access to 12 pieces of metadata, six associated with individuals and six associated with SNPs (roughly speaking, DNA locations). The genotype data is often 100,000 times larger than the metadata.
Aside: In this context, an “API” refers to an Application Programming Interface. It is the public structs, methods, etc., provided by library code such as Bed-Reader for another program to call.
Here is some sample code using Bed-Reader’s original “local file” API. This code lists the first five individual ids, the first five SNP ids, and every unique chromosome number. It then reads every genomic value in chromosome 5:
#[test]
fn lib_intro() -> Result<(), Box<BedErrorPlus>> {
let file_name = sample_bed_file("some_missing.bed")?;
let mut bed = Bed::new(file_name)?;
println!("{:?}", bed.iid()?.slice(s![..5])); // Outputs ndarray: ["iid_0", "iid_1", "iid_2", "iid_3", "iid_4"]
println!("{:?}", bed.sid()?.slice(s![..5])); // Outputs ndarray: ["sid_0", "sid_1", "sid_2", "sid_3", "sid_4"]
println!("{:?}", bed.chromosome()?.iter().collect::<HashSet<_>>());
// Outputs: {"12", "10", "4", "8", "19", "21", "9", "15", "6", "16", "13", "7", "17", "18", "1", "22", "11", "2", "20", "3", "5", "14"}
let _ = ReadOptions::builder()
.sid_index(bed.chromosome()?.map(|elem| elem == "5"))
.f64()
.read(&mut bed)?;
Ok(())
}
And here is the same code using the new cloud file API:
#[tokio::test]
async fn cloud_lib_intro() -> Result<(), Box<BedErrorPlus>> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/some_missing.bed";
let cloud_options = [("timeout", "10s")];
let mut bed_cloud = BedCloud::new_with_options(url, cloud_options).await?;
println!("{:?}", bed_cloud.iid().await?.slice(s![..5])); // Outputs ndarray: ["iid_0", "iid_1", "iid_2", "iid_3", "iid_4"]
println!("{:?}", bed_cloud.sid().await?.slice(s![..5])); // Outputs ndarray: ["sid_0", "sid_1", "sid_2", "sid_3", "sid_4"]
println!(
"{:?}",
bed_cloud.chromosome().await?.iter().collect::<HashSet<_>>()
);
// Outputs: {"12", "10", "4", "8", "19", "21", "9", "15", "6", "16", "13", "7", "17", "18", "1", "22", "11", "2", "20", "3", "5", "14"}
let _ = ReadOptions::builder()
.sid_index(bed_cloud.chromosome().await?.map(|elem| elem == "5"))
.f64()
.read_cloud(&mut bed_cloud)
.await?;
Ok(())
}
When switching to cloud data, a Bed-Reader user must make these changes:
- They must run in an async environment, here #[tokio::test].
- They must use a new struct, BedCloud instead of Bed. (Also, not shown, BedCloudBuilder rather than BedBuilder.)
- They give a URL string and optional string options rather than a local file path.
- They must use .await in many, rather unpredictable, places. (Happily, the compiler gives a good error message if they miss a place.)
- The ReadOptionsBuilder gets a new method, read_cloud, to go along with its previous read method.
From the library developer’s point of view, adding the new BedCloud and BedCloudBuilder structs costs many lines of main and test code. In my case, 2,200 lines of new main code and 2,400 lines of new test code.
Aside: Also, see Mario Ortiz Manero’s article “The bane of my existence: Supporting both async and sync code in Rust”.
The benefit users get from these changes is the ability to read data from cloud files with async’s high efficiency.
Is this benefit worth it? If not, there is an alternative that we’ll look at next.
Rule 7: Alternatively, for maximum convenience, add cloud-file support to your Rust library via a traditional (“synchronous”) API.
If adding an efficient async API seems like too much work for you or seems too confusing for your users, there is an alternative. Namely, you can offer a traditional (“synchronous”) API. I do this for the Python version of Bed-Reader and for the Rust code that supports the Python version.
Aside: See: Nine Rules for Writing Python Extensions in Rust: Practical Lessons from Upgrading Bed-Reader, a Python Bioinformatics Package in Towards Data Science.
Here is the Rust function that Python calls to check if a *.bed file starts with the correct file signature.
use tokio::runtime;
// ...
#[pyfn(m)]
fn check_file_cloud(location: &str, options: HashMap<&str, String>) -> Result<(), PyErr> {
runtime::Runtime::new()?.block_on(async {
BedCloud::new_with_options(location, options).await?;
Ok(())
})
}
Notice that this is not an async function. It is a normal “synchronous” function. Inside this synchronous function, Rust makes an async call:
BedCloud::new_with_options(location, options).await?;
We make the async call synchronous by wrapping it in a Tokio runtime:
use tokio::runtime;
// ...
runtime::Runtime::new()?.block_on(async {
BedCloud::new_with_options(location, options).await?;
Ok(())
})
Bed-Reader’s Python users could previously open a local file for reading with the command open_bed(file_name_string). Now, they can also open a cloud file for reading with the same command open_bed(url_string). The only difference is the format of the string they pass in.
Here is the example from Rule 6, in Python, using the updated Python API:
with open_bed(
"https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/some_missing.bed",
cloud_options={"timeout": "30s"},
) as bed:
print(bed.iid[:5])
print(bed.sid[:5])
print(np.unique(bed.chromosome))
val = bed.read(index=np.s_[:, bed.chromosome == "5"])
print(val.shape)
Notice the Python API also offers a new optional parameter called cloud_options. Also, behind the scenes, a tiny bit of new code distinguishes between strings representing local files and strings representing URLs.
In Rust, you can use the same trick to make calls to object_cloud synchronous. Specifically, you can wrap async calls in a runtime. The benefit is a simpler interface and less library code. The cost is less efficiency compared to offering an async API.
If you decide against the “synchronous” alternative and choose to offer an async API, you’ll discover a new problem: providing async examples in your documentation. We will look at that issue next.
Rule 8: Follow the rules of good API design in part by using hidden lines in your doc tests.
All the rules from the article Nine Rules for Elegant Rust Library APIs: Practical Lessons from Porting Bed-Reader, a Bioinformatics Library, from Python to Rust in Towards Data Science apply. Of particular importance are these two:
Write good documentation to keep your design honest.
Create examples that don’t embarrass you.
These suggest that we should give examples in our documentation, but how can we do that with async methods and awaits? The trick is “hidden lines” in our doc tests. For example, here is the documentation for CloudFile::read_ranges:
/// Return the `Vec` of [`Bytes`](https://docs.rs/bytes/latest/bytes/struct.Bytes.html) from specified ranges.
///
/// # Example
/// ```
/// use cloud_file::CloudFile;
///
/// # Runtime::new().unwrap().block_on(async {
/// let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/plink_sim_10s_100v_10pmiss.bim";
/// let cloud_file = CloudFile::new(url)?;
/// let bytes_vec = cloud_file.read_ranges(&[0..10, 1000..1010]).await?;
/// assert_eq!(bytes_vec.len(), 2);
/// assert_eq!(bytes_vec[0].as_ref(), b"1\t1:1:A:C\t");
/// assert_eq!(bytes_vec[1].as_ref(), b":A:C\t0.0\t4");
/// # Ok::<(), CloudFileError>(())}).unwrap();
/// # use {tokio::runtime::Runtime, cloud_file::CloudFileError};
/// ```
The doc test starts with “`. Within the doc test, lines starting with /// # disappear from the documentation:
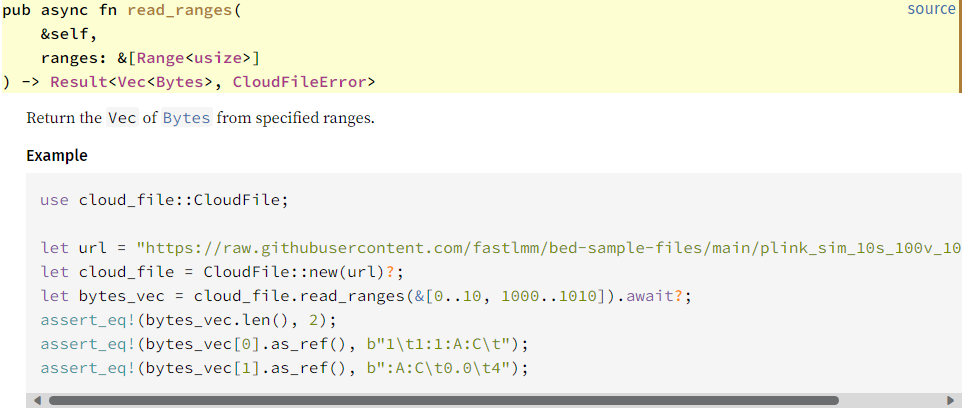
The hidden lines, however, will still be run by cargo test.
In my library crates, I try to include a working example with every method. If such an example turns out overly complex or otherwise embarrassing, I try to fix the issue by improving the API.
Notice that in this rule and the previous Rule 7, we added a runtime to the code. Unfortunately, including a runtime can easily double the size of your user’s programs, even if they don’t read files from the cloud. Making this extra size optional is the topic of Rule 9.
Rule 9: Include a runtime, but optionally.
If you follow Rule 6 and provide async methods, your users gain the freedom to choose their own runtime. Opting for a runtime like Tokio may significantly increase their compiled program’s size. However, if they use no async methods, selecting a runtime becomes unnecessary, keeping the compiled program lean. This embodies the “zero cost principle”, where one incurs costs only for the features one uses.
On the other hand, if you follow Rule 7 and wrap async calls inside traditional, “synchronous” methods, then you must provide a runtime. This will increase the size of the resultant program. To mitigate this cost, you should make the inclusion of any runtime optional.
Bed-Reader includes a runtime under two conditions. First, when used as a Python extension. Second, when testing the async methods. To handle the first condition, we create a Cargo feature called extension-module that pulls in optional dependencies pyo3 and tokio. Here are the relevant sections of Cargo.toml:
[features]
extension-module = ["pyo3/extension-module", "tokio/full"]
default = []
[dependencies]
#...
pyo3 = { version = "0.20.0", features = ["extension-module"], optional = true }
tokio = { version = "1.35.0", features = ["full"], optional = true }
Also, because I’m using Maturin to create a Rust extension for Python, I include this text in pyproject.toml:
[tool.maturin]
features = ["extension-module"]
I put all the Rust code related to extending Python in a file called python_modules.rs. It starts with this conditional compilation attribute:
#![cfg(feature = "extension-module")] // ignore file if feature not 'on'
This starting line ensures that the compiler includes the extension code only when needed.
With the Python extension code taken care of, we turn next to providing an optional runtime for testing our async methods. I again choose Tokio as the runtime. I put the tests for the async code in their own file called tests_api_cloud.rs. To ensure that that async tests are run only when the tokio dependency feature is “on”, I start the file with this line:
#![cfg(feature = "tokio")]
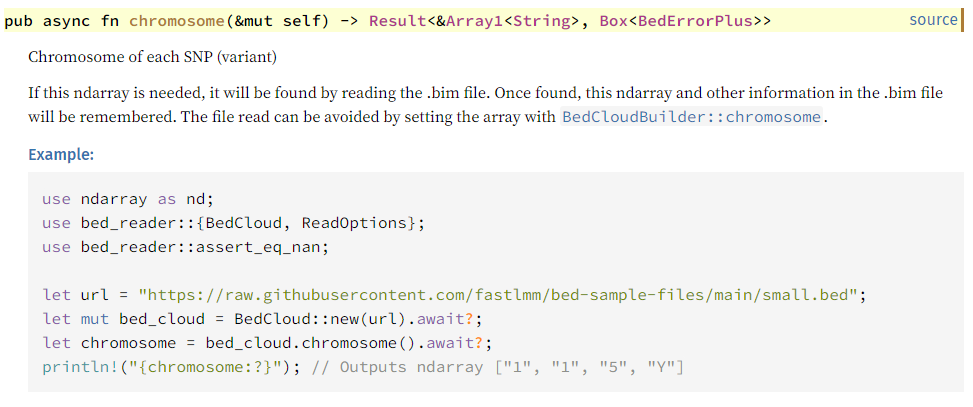
As per Rule 5, we should also include examples in our documentation of the async methods. These examples also serve as “doc tests”. The doc tests need conditional compilation attributes. Below is the documentation for the method that retrieves chromosome metadata. Notice that the example includes two hidden lines that start
/// # #[cfg(feature = "tokio")]
/// Chromosome of each SNP (variant)
/// [...]
///
/// # Example:
/// ```
/// use ndarray as nd;
/// use bed_reader::{BedCloud, ReadOptions};
/// use bed_reader::assert_eq_nan;
///
/// # #[cfg(feature = "tokio")] Runtime::new().unwrap().block_on(async {
/// let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/small.bed";
/// let mut bed_cloud = BedCloud::new(url).await?;
/// let chromosome = bed_cloud.chromosome().await?;
/// println!("{chromosome:?}"); // Outputs ndarray ["1", "1", "5", "Y"]
/// # Ok::<(), Box<BedErrorPlus>>(())}).unwrap();
/// # #[cfg(feature = "tokio")] use {tokio::runtime::Runtime, bed_reader::BedErrorPlus};
/// ```
In this doc test, when the tokio feature is ‘on’, the example, uses tokio and runs four lines of code inside a Tokio runtime. When the tokio feature is ‘off’, the code within the #[cfg(feature = "tokio")] block disappears, effectively skipping the asynchronous operations.
When formatting the documentation, Rust includes documentation for all features by default, so we see the four lines of code:
To summarize Rule 9: By using Cargo features and conditional compilation we can ensure that users only pay for the features that they use.
Conclusion
So, there you have it: nine rules for reading cloud files in your Rust program. Thanks to the power of the object_store crate, your programs can move beyond your local drive and load data from the web, AWS S3, Azure, and Google Cloud. To make this a little simpler, you can also use the new cloud-file wrapping crate that I wrote for this article.
I should also mention that this article explored only a subset of object_store’s features. In addition to what we’ve seen, the object_store crate also handles writing files and working with folders and subfolders. The cloud-file crate, on the other hand, only handles reading files. (But, hey, I’m open to pull requests).
Should you add cloud file support to your program? It, of course, depends. Supporting cloud files offers a huge convenience to your program’s users. The cost is the extra complexity of using/providing an async interface. The cost also includes the increased file size of runtimes like Tokio. On the other hand, I think the tools for adding such support are good and trying them is easy, so give it a try!
Thank you for joining me on this journey into the cloud. I hope that if you choose to support cloud files, these steps will help you do it.
Please follow Carl on Medium. I write on scientific programming in Rust and Python, machine learning, and statistics. I tend to write about one article per month.
Nine Rules for Accessing Cloud Files from Your Rust Code was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Practical lessons from upgrading Bed-Reader, a bioinformatics library

Would you like your Rust program to seamlessly access data from files in the cloud? When I refer to “files in the cloud,” I mean data housed on web servers or within cloud storage solutions like AWS S3, Azure Blob Storage, or Google Cloud Storage. The term “read”, here, encompasses both the sequential retrieval of file contents — be they text or binary, from beginning to end —and the capability to pinpoint and extract specific sections of the file as needed.
Upgrading your program to access cloud files can reduce annoyance and complication: the annoyance of downloading to local storage and the complication of periodically checking that a local copy is up to date.
Sadly, upgrading your program to access cloud files can also increase annoyance and complication: the annoyance of URLs and credential information, and the complication of asynchronous programming.
Bed-Reader is a Python package and Rust crate for reading PLINK Bed Files, a binary format used in bioinformatics to store genotype (DNA) data. At a user’s request, I recently updated Bed-Reader to optionally read data directly from cloud storage. Along the way, I learned nine rules that can help you add cloud-file support to your programs. The rules are:
- Use crate object_store (and, perhaps, cloud-file) to sequentially read the bytes of a cloud file.
- Sequentially read text lines from cloud files via two nested loops.
- Randomly access cloud files, even giant ones, with “range” methods, while respecting server-imposed limits.
- Use URL strings and option strings to access HTTP, Local Files, AWS S3, Azure, and Google Cloud.
- Test via tokio::test on http and local files.
If other programs call your program — in other words, if your program offers an API (application program interface) — four additional rules apply:
6. For maximum performance, add cloud-file support to your Rust library via an async API.
7. Alternatively, for maximum convenience, add cloud-file support to your Rust library via a traditional (“synchronous”) API.
8. Follow the rules of good API design in part by using hidden lines in your doc tests.
9. Include a runtime, but optionally.
Aside: To avoid wishy-washiness, I call these “rules”, but they are, of course, just suggestions.
Rule 1: Use crate object_store (and, perhaps, cloud-file) to sequentially read the bytes of a cloud file.
The powerful object_store crate provides full content access to files stored on http, AWS S3, Azure, Google Cloud, and local files. It is part of the Apache Arrow project and has over 2.4 million downloads.
For this article, I also created a new crate called cloud-file. It simplifies the use of the object_store crate. It wraps and focuses on a useful subset of object_store’s features. You can either use it directly, or pull-out its code for your own use.
Let’s look at an example. We’ll count the lines of a cloud file by counting the number of newline characters it contains.
use cloud_file::{CloudFile, CloudFileError};
use futures_util::StreamExt; // Enables `.next()` on streams.
async fn count_lines(cloud_file: &CloudFile) -> Result<usize, CloudFileError> {
let mut chunks = cloud_file.stream_chunks().await?;
let mut newline_count: usize = 0;
while let Some(chunk) = chunks.next().await {
let chunk = chunk?;
newline_count += bytecount::count(&chunk, b'\n');
}
Ok(newline_count)
}
#[tokio::main]
async fn main() -> Result<(), CloudFileError> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/toydata.5chrom.fam";
let options = [("timeout", "10s")];
let cloud_file = CloudFile::new_with_options(url, options)?;
let line_count = count_lines(&cloud_file).await?;
println!("line_count: {line_count}");
Ok(())
}
When we run this code, it returns:
line_count: 500
Some points of interest:
- We use async (and, here, tokio). We’ll discuss this choice more in Rules 6 and 7.
- We turn a URL string and string options into a CloudFile instance with CloudFile::new_with_options(url, options)?. We use ? to catch malformed URLs).
- We create a stream of binary chunks with cloud_file.stream_chunks().await?. This is the first place that the code tries to access the cloud file. If the file doesn’t exist or we can’t open it, the ? will return an error.
- We use chunks.next().await to retrieve the file’s next binary chunk. (Note the use futures_util::StreamExt;.) The next method returns None after all chunks have been retrieved.
- What if there is a next chunk but also a problem retrieving it? We’ll catch any problem with let chunk = chunk?;.
- Finally, we use the fast bytecount crate to count newline characters.
In contrast with this cloud solution, think about how you would write a simple line counter for a local file. You might write this:
use std::fs::File;
use std::io::{self, BufRead, BufReader};
fn main() -> io::Result<()> {
let path = "examples/line_counts_local.rs";
let reader = BufReader::new(File::open(path)?);
let mut line_count = 0;
for line in reader.lines() {
let _line = line?;
line_count += 1;
}
println!("line_count: {line_count}");
Ok(())
}
Between the cloud-file version and the local-file version, three differences stand out. First, we can easily read local files as text. By default, we read cloud files as binary (but see Rule 2). Second, by default, we read local files synchronously, blocking program execution until completion. On the other hand, we usually access cloud files asynchronously, allowing other parts of the program to continue running while waiting for the relatively slow network access to complete. Third, iterators such as lines() support for. However, streams such as stream_chunks() do not, so we use while let.
I mentioned earlier that you didn’t need to use the cloud-file wrapper and that you could use the object_store crate directly. Let’s see what it looks like when we count the newlines in a cloud file using only object_store methods:
use futures_util::StreamExt; // Enables `.next()` on streams.
pub use object_store::path::Path as StorePath;
use object_store::{parse_url_opts, ObjectStore};
use std::sync::Arc;
use url::Url;
async fn count_lines(
object_store: &Arc<Box<dyn ObjectStore>>,
store_path: StorePath,
) -> Result<usize, anyhow::Error> {
let mut chunks = object_store.get(&store_path).await?.into_stream();
let mut newline_count: usize = 0;
while let Some(chunk) = chunks.next().await {
let chunk = chunk?;
newline_count += bytecount::count(&chunk, b'\n');
}
Ok(newline_count)
}
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/toydata.5chrom.fam";
let options = [("timeout", "10s")];
let url = Url::parse(url)?;
let (object_store, store_path) = parse_url_opts(&url, options)?;
let object_store = Arc::new(object_store); // enables cloning and borrowing
let line_count = count_lines(&object_store, store_path).await?;
println!("line_count: {line_count}");
Ok(())
}
You’ll see the code is very similar to the cloud-file code. The differences are:
- Instead of one CloudFile input, most methods take two inputs: an ObjectStore and a StorePath. Because ObjectStore is a non-cloneable trait, here the count_lines function specifically uses &Arc<Box<dyn ObjectStore>>. Alternatively, we could make the function generic and use &Arc<impl ObjectStore>.
- Creating the ObjectStore instance, the StorePath instance, and the stream requires a few extra steps compared to creating a CloudFile instance and a stream.
- Instead of dealing with one error type (namely, CloudFileError), multiple error types are possible, so we fall back to using the anyhow crate.
Whether you use object_store (with 2.4 million downloads) directly or indirectly via cloud-file (currently, with 124 downloads 😀), is up to you.
For the rest of this article, I’ll focus on cloud-file. If you want to translate a cloud-file method into pure object_store code, look up the cloud-file method’s documentation and follow the "source" link. The source is usually only a line or two.
We’ve seen how to sequentially read the bytes of a cloud file. Let’s look next at sequentially reading its lines.
Rule 2: Sequentially read text lines from cloud files via two nested loops.
We often want to sequentially read the lines of a cloud file. To do that with cloud-file (or object_store) requires two nested loops.
The outer loop yields binary chunks, as before, but with a key modification: we now ensure that each chunk only contains complete lines, starting from the first character of a line and ending with a newline character. In other words, chunks may consist of one or more complete lines but no partial lines. The inner loop turns the chunk into text and iterates over the resultant one or more lines.
In this example, given a cloud file and a number n, we find the line at index position n:
use cloud_file::CloudFile;
use futures::StreamExt; // Enables `.next()` on streams.
use std::str::from_utf8;
async fn nth_line(cloud_file: &CloudFile, n: usize) -> Result<String, anyhow::Error> {
// Each binary line_chunk contains one or more lines, that is, each chunk ends with a newline.
let mut line_chunks = cloud_file.stream_line_chunks().await?;
let mut index_iter = 0usize..;
while let Some(line_chunk) = line_chunks.next().await {
let line_chunk = line_chunk?;
let lines = from_utf8(&line_chunk)?.lines();
for line in lines {
let index = index_iter.next().unwrap(); // safe because we know the iterator is infinite
if index == n {
return Ok(line.to_string());
}
}
}
Err(anyhow::anyhow!("Not enough lines in the file"))
}
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/toydata.5chrom.fam";
let n = 4;
let cloud_file = CloudFile::new(url)?;
let line = nth_line(&cloud_file, n).await?;
println!("line at index {n}: {line}");
Ok(())
}
The code prints:
line at index 4: per4 per4 0 0 2 0.452591
Some points of interest:
- The key method is .stream_line_chunks().
- We must also call std::str::from_utf8 to create text. (Possibly returning a Utf8Error.) Also, we call the .lines() method to create an iterator of lines.
- If we want a line index, we must make it ourselves. Here we use:
let mut index_iter = 0usize..;
...
let index = index_iter.next().unwrap(); // safe because we know the iterator is infinite
Aside: Why two loops? Why doesn’t cloud-file define a new stream that returns one line at a time? Because I don’t know how. If anyone can figure it out, please send me a pull request with the solution!
I wish this was simpler. I’m happy it is efficient. Let’s return to simplicity by next look at randomly accessing cloud files.
Rule 3: Randomly access cloud files, even giant ones, with range methods, while respecting server-imposed limits.
I work with a genomics file format called PLINK Bed 1.9. Files can be as large as 1 TB. Too big for web access? Not necessarily. We sometimes only need a fraction of the file. Moreover, modern cloud services (including most web servers) can efficiently retrieve regions of interest from a cloud file.
Let’s look at an example. This test code uses a CloudFile method called read_range_and_file_size It reads a *.bed file’s first 3 bytes, checks that the file starts with the expected bytes, and then checks for the expected length.
#[tokio::test]
async fn check_file_signature() -> Result<(), CloudFileError> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/plink_sim_10s_100v_10pmiss.bed";
let cloud_file = CloudFile::new(url)?;
let (bytes, size) = cloud_file.read_range_and_file_size(0..3).await?;
assert_eq!(bytes.len(), 3);
assert_eq!(bytes[0], 0x6c);
assert_eq!(bytes[1], 0x1b);
assert_eq!(bytes[2], 0x01);
assert_eq!(size, 303);
Ok(())
}
Notice that in one web call, this method returns not just the bytes requested, but also the size of the whole file.
Here is a list of high-level CloudFile methods and what they can retrieve in one web call:
- read_all — Whole file contents as an in-memory Bytes
- read_range — Bytes from a specified range
- read_ranges — Vec of Bytes from specified ranges
- read_range_and_file_size — Bytes from a specified range & the file’s size
- read_file_size — Size of the file
These methods can run into two problems if we ask for too much data at a time. First, our cloud service may limit the number of bytes we can retrieve in one call. Second, we may get faster results by making multiple simultaneous requests rather than just one at a time.
Consider this example: We want to gather statistics on the frequency of adjacent ASCII characters in a file of any size. For example, in a random sample of 10,000 adjacent characters, perhaps “th” appears 171 times.
Suppose our web server is happy with 10 concurrent requests but only wants us to retrieve 750 bytes per call. (8 MB would be a more normal limit).
Thanks to Ben Lichtman (B3NNY) at the Seattle Rust Meetup for pointing me in the right direction on adding limits to async streams.
Our main function could look like this:
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
let url = "https://www.gutenberg.org/cache/epub/100/pg100.txt";
let options = [("timeout", "30s")];
let cloud_file = CloudFile::new_with_options(url, options)?;
let seed = Some(0u64);
let sample_count = 10_000;
let max_chunk_bytes = 750; // 8_000_000 is a good default when chunks are bigger.
let max_concurrent_requests = 10; // 10 is a good default
count_bigrams(
cloud_file,
sample_count,
seed,
max_concurrent_requests,
max_chunk_bytes,
)
.await?;
Ok(())
}
The count_bigrams function can start by creating a random number generator and making a call to find the size of the cloud file:
#[cfg(not(target_pointer_width = "64"))]
compile_error!("This code requires a 64-bit target architecture.");
use cloud_file::CloudFile;
use futures::pin_mut;
use futures_util::StreamExt; // Enables `.next()` on streams.
use rand::{rngs::StdRng, Rng, SeedableRng};
use std::{cmp::max, collections::HashMap, ops::Range};
async fn count_bigrams(
cloud_file: CloudFile,
sample_count: usize,
seed: Option<u64>,
max_concurrent_requests: usize,
max_chunk_bytes: usize,
) -> Result<(), anyhow::Error> {
// Create a random number generator
let mut rng = if let Some(s) = seed {
StdRng::seed_from_u64(s)
} else {
StdRng::from_entropy()
};
// Find the document size
let file_size = cloud_file.read_file_size().await?;
//...
Next, based on the file size, the function can create a vector of 10,000 random two-byte ranges.
// Randomly choose the two-byte ranges to sample
let range_samples: Vec<Range<usize>> = (0..sample_count)
.map(|_| rng.gen_range(0..file_size - 1))
.map(|start| start..start + 2)
.collect();
For example, it might produce the vector [4122418..4122420, 4361192..4361194, 145726..145728, … ]. But retrieving 20,000 bytes at once (we are pretending) is too much. So, we divide the vector into 27 chunks of no more than 750 bytes:
// Divide the ranges into chunks respecting the max_chunk_bytes limit
const BYTES_PER_BIGRAM: usize = 2;
let chunk_count = max(1, max_chunk_bytes / BYTES_PER_BIGRAM);
let range_chunks = range_samples.chunks(chunk_count);
Using a little async magic, we create an iterator of future work for each of the 27 chunks and then we turn that iterator into a stream. We tell the stream to do up to 10 simultaneous calls. Also, we say that out-of-order results are fine.
// Create an iterator of future work
let work_chunks_iterator = range_chunks.map(|chunk| {
let cloud_file = cloud_file.clone(); // by design, clone is cheap
async move { cloud_file.read_ranges(chunk).await }
});
// Create a stream of futures to run out-of-order and with constrained concurrency.
let work_chunks_stream =
futures_util::stream::iter(work_chunks_iterator).buffer_unordered(max_concurrent_requests);
pin_mut!(work_chunks_stream); // The compiler says we need this
In the last section of code, we first do the work in the stream and — as we get results — tabulate. Finally, we sort and print the top results.
// Run the futures and, as result bytes come in, tabulate.
let mut bigram_counts = HashMap::new();
while let Some(result) = work_chunks_stream.next().await {
let bytes_vec = result?;
for bytes in bytes_vec.iter() {
let bigram = (bytes[0], bytes[1]);
let count = bigram_counts.entry(bigram).or_insert(0);
*count += 1;
}
}
// Sort the bigrams by count and print the top 10
let mut bigram_count_vec: Vec<(_, usize)> = bigram_counts.into_iter().collect();
bigram_count_vec.sort_by(|a, b| b.1.cmp(&a.1));
for (bigram, count) in bigram_count_vec.into_iter().take(10) {
let char0 = (bigram.0 as char).escape_default();
let char1 = (bigram.1 as char).escape_default();
println!("Bigram ('{}{}') occurs {} times", char0, char1, count);
}
Ok(())
}
The output is:
Bigram ('\r\n') occurs 367 times
Bigram ('e ') occurs 221 times
Bigram (' t') occurs 184 times
Bigram ('th') occurs 171 times
Bigram ('he') occurs 158 times
Bigram ('s ') occurs 143 times
Bigram ('.\r') occurs 136 times
Bigram ('d ') occurs 133 times
Bigram (', ') occurs 127 times
Bigram (' a') occurs 121 times
The code for the Bed-Reader genomics crate uses the same technique to retrieve information from scattered DNA regions of interest. As the DNA information comes in, perhaps out of order, the code fills in the correct columns of an output array.
Aside: This method uses an iterator, a stream, and a loop. I wish it were simpler. If you can figure out a simpler way to retrieve a vector of regions while limiting the maximum chunk size and the maximum number of concurrent requests, please send me a pull request.
That covers access to files stored on an HTTP server, but what about AWS S3 and other cloud services? What about local files?
Rule 4: Use URL strings and option strings to access HTTP, Local Files, AWS S3, Azure, and Google Cloud.
The object_store crate (and the cloud-file wrapper crate) supports specifying files either via a URL string or via structs. I recommend sticking with URL strings, but the choice is yours.
Let’s consider an AWS S3 example. As you can see, AWS access requires credential information.
use cloud_file::CloudFile;
use rusoto_credential::{CredentialsError, ProfileProvider, ProvideAwsCredentials};
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
// get credentials from ~/.aws/credentials
let credentials = if let Ok(provider) = ProfileProvider::new() {
provider.credentials().await
} else {
Err(CredentialsError::new("No credentials found"))
};
let Ok(credentials) = credentials else {
eprintln!("Skipping example because no AWS credentials found");
return Ok(());
};
let url = "s3://bedreader/v1/toydata.5chrom.bed";
let options = [
("aws_region", "us-west-2"),
("aws_access_key_id", credentials.aws_access_key_id()),
("aws_secret_access_key", credentials.aws_secret_access_key()),
];
let cloud_file = CloudFile::new_with_options(url, options)?;
assert_eq!(cloud_file.read_file_size().await?, 1_250_003);
Ok(())
}
The key part is:
let url = "s3://bedreader/v1/toydata.5chrom.bed";
let options = [
("aws_region", "us-west-2"),
("aws_access_key_id", credentials.aws_access_key_id()),
("aws_secret_access_key", credentials.aws_secret_access_key()),
];
let cloud_file = CloudFile::new_with_options(url, options)?;
If we wish to use structs instead of URL strings, this becomes:
use object_store::{aws::AmazonS3Builder, path::Path as StorePath};
let s3 = AmazonS3Builder::new()
.with_region("us-west-2")
.with_bucket_name("bedreader")
.with_access_key_id(credentials.aws_access_key_id())
.with_secret_access_key(credentials.aws_secret_access_key())
.build()?;
let store_path = StorePath::parse("v1/toydata.5chrom.bed")?;
let cloud_file = CloudFile::from_structs(s3, store_path);
I prefer the URL approach over structs. I find URLs slightly simpler, much more uniform across cloud services, and vastly easier for interop (with, for example, Python).
Here are example URLs for the three web services I have used:
- HTTP — https://www.gutenberg.org/cache/epub/100/pg100.txt
- local file — file:///M:/data%20files/small.bed — use the cloud_file::abs_path_to_url_string function to properly encode a full file path into a URL
- AWS S3 — s3://bedreader/v1/toydata.5chrom.bed
Local files don’t need options. For the other services, here are links to their supported options and selected examples:
- HTTP — ClientConfigKey — [("timeout", "30s")]
- AWS S3 — AmazonS3ConfigKey — [("aws_region", "us-west-2"), ("aws_access_key_id", …), ("aws_secret_access_key", …)]
- Azure — AzureConfigKey
- Google — GoogleConfigKey
Now that we can specify and read cloud files, we should create tests.
Rule 5: Test via tokio::test on http and local files.
The object_store crate (and cloud-file) supports any async runtime. For testing, the Tokio runtime makes it easy to test your code on cloud files. Here is a test on an http file:
[tokio::test]
async fn cloud_file_extension() -> Result<(), CloudFileError> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/plink_sim_10s_100v_10pmiss.bed";
let mut cloud_file = CloudFile::new(url)?;
assert_eq!(cloud_file.read_file_size().await?, 303);
cloud_file.set_extension("fam")?;
assert_eq!(cloud_file.read_file_size().await?, 130);
Ok(())
}
Run this test with:
cargo test
If you don’t want to hit an outside web server with your tests, you can instead test against local files as though they were in the cloud.
#[tokio::test]
async fn local_file() -> Result<(), CloudFileError> {
use std::env;
let apache_url = abs_path_to_url_string(env::var("CARGO_MANIFEST_DIR").unwrap()
+ "/LICENSE-APACHE")?;
let cloud_file = CloudFile::new(&apache_url)?;
assert_eq!(cloud_file.read_file_size().await?, 9898);
Ok(())
}
This uses the standard Rust environment variable CARGO_MANIFEST_DIR to find the full path to a text file. It then uses cloud_file::abs_path_to_url_string to correctly encode that full path into a URL.
Whether you test on http files or local files, the power of object_store means that your code should work on any cloud service, including AWS S3, Azure, and Google Cloud.
If you only need to access cloud files for your own use, you can stop reading the rules here and skip to the conclusion. If you are adding cloud access to a library (Rust crate) for others, keep reading.
Rule 6: For maximum performance, add cloud-file support to your Rust library via an async API.
If you offer a Rust crate to others, supporting cloud files offers great convenience to your users, but not without a cost. Let’s look at Bed-Reader, the genomics crate to which I added cloud support.
As previously mentioned, Bed-Reader is a library for reading and writing PLINK Bed Files, a binary format used in bioinformatics to store genotype (DNA) data. Files in Bed format can be as large as a terabyte. Bed-Reader gives users fast, random access to large subsets of the data. It returns a 2-D array in the user’s choice of int8, float32, or float64. Bed-Reader also gives users access to 12 pieces of metadata, six associated with individuals and six associated with SNPs (roughly speaking, DNA locations). The genotype data is often 100,000 times larger than the metadata.
Aside: In this context, an “API” refers to an Application Programming Interface. It is the public structs, methods, etc., provided by library code such as Bed-Reader for another program to call.
Here is some sample code using Bed-Reader’s original “local file” API. This code lists the first five individual ids, the first five SNP ids, and every unique chromosome number. It then reads every genomic value in chromosome 5:
#[test]
fn lib_intro() -> Result<(), Box<BedErrorPlus>> {
let file_name = sample_bed_file("some_missing.bed")?;
let mut bed = Bed::new(file_name)?;
println!("{:?}", bed.iid()?.slice(s![..5])); // Outputs ndarray: ["iid_0", "iid_1", "iid_2", "iid_3", "iid_4"]
println!("{:?}", bed.sid()?.slice(s![..5])); // Outputs ndarray: ["sid_0", "sid_1", "sid_2", "sid_3", "sid_4"]
println!("{:?}", bed.chromosome()?.iter().collect::<HashSet<_>>());
// Outputs: {"12", "10", "4", "8", "19", "21", "9", "15", "6", "16", "13", "7", "17", "18", "1", "22", "11", "2", "20", "3", "5", "14"}
let _ = ReadOptions::builder()
.sid_index(bed.chromosome()?.map(|elem| elem == "5"))
.f64()
.read(&mut bed)?;
Ok(())
}
And here is the same code using the new cloud file API:
#[tokio::test]
async fn cloud_lib_intro() -> Result<(), Box<BedErrorPlus>> {
let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/some_missing.bed";
let cloud_options = [("timeout", "10s")];
let mut bed_cloud = BedCloud::new_with_options(url, cloud_options).await?;
println!("{:?}", bed_cloud.iid().await?.slice(s![..5])); // Outputs ndarray: ["iid_0", "iid_1", "iid_2", "iid_3", "iid_4"]
println!("{:?}", bed_cloud.sid().await?.slice(s![..5])); // Outputs ndarray: ["sid_0", "sid_1", "sid_2", "sid_3", "sid_4"]
println!(
"{:?}",
bed_cloud.chromosome().await?.iter().collect::<HashSet<_>>()
);
// Outputs: {"12", "10", "4", "8", "19", "21", "9", "15", "6", "16", "13", "7", "17", "18", "1", "22", "11", "2", "20", "3", "5", "14"}
let _ = ReadOptions::builder()
.sid_index(bed_cloud.chromosome().await?.map(|elem| elem == "5"))
.f64()
.read_cloud(&mut bed_cloud)
.await?;
Ok(())
}
When switching to cloud data, a Bed-Reader user must make these changes:
- They must run in an async environment, here #[tokio::test].
- They must use a new struct, BedCloud instead of Bed. (Also, not shown, BedCloudBuilder rather than BedBuilder.)
- They give a URL string and optional string options rather than a local file path.
- They must use .await in many, rather unpredictable, places. (Happily, the compiler gives a good error message if they miss a place.)
- The ReadOptionsBuilder gets a new method, read_cloud, to go along with its previous read method.
From the library developer’s point of view, adding the new BedCloud and BedCloudBuilder structs costs many lines of main and test code. In my case, 2,200 lines of new main code and 2,400 lines of new test code.
Aside: Also, see Mario Ortiz Manero’s article “The bane of my existence: Supporting both async and sync code in Rust”.
The benefit users get from these changes is the ability to read data from cloud files with async’s high efficiency.
Is this benefit worth it? If not, there is an alternative that we’ll look at next.
Rule 7: Alternatively, for maximum convenience, add cloud-file support to your Rust library via a traditional (“synchronous”) API.
If adding an efficient async API seems like too much work for you or seems too confusing for your users, there is an alternative. Namely, you can offer a traditional (“synchronous”) API. I do this for the Python version of Bed-Reader and for the Rust code that supports the Python version.
Aside: See: Nine Rules for Writing Python Extensions in Rust: Practical Lessons from Upgrading Bed-Reader, a Python Bioinformatics Package in Towards Data Science.
Here is the Rust function that Python calls to check if a *.bed file starts with the correct file signature.
use tokio::runtime;
// ...
#[pyfn(m)]
fn check_file_cloud(location: &str, options: HashMap<&str, String>) -> Result<(), PyErr> {
runtime::Runtime::new()?.block_on(async {
BedCloud::new_with_options(location, options).await?;
Ok(())
})
}
Notice that this is not an async function. It is a normal “synchronous” function. Inside this synchronous function, Rust makes an async call:
BedCloud::new_with_options(location, options).await?;
We make the async call synchronous by wrapping it in a Tokio runtime:
use tokio::runtime;
// ...
runtime::Runtime::new()?.block_on(async {
BedCloud::new_with_options(location, options).await?;
Ok(())
})
Bed-Reader’s Python users could previously open a local file for reading with the command open_bed(file_name_string). Now, they can also open a cloud file for reading with the same command open_bed(url_string). The only difference is the format of the string they pass in.
Here is the example from Rule 6, in Python, using the updated Python API:
with open_bed(
"https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/some_missing.bed",
cloud_options={"timeout": "30s"},
) as bed:
print(bed.iid[:5])
print(bed.sid[:5])
print(np.unique(bed.chromosome))
val = bed.read(index=np.s_[:, bed.chromosome == "5"])
print(val.shape)
Notice the Python API also offers a new optional parameter called cloud_options. Also, behind the scenes, a tiny bit of new code distinguishes between strings representing local files and strings representing URLs.
In Rust, you can use the same trick to make calls to object_cloud synchronous. Specifically, you can wrap async calls in a runtime. The benefit is a simpler interface and less library code. The cost is less efficiency compared to offering an async API.
If you decide against the “synchronous” alternative and choose to offer an async API, you’ll discover a new problem: providing async examples in your documentation. We will look at that issue next.
Rule 8: Follow the rules of good API design in part by using hidden lines in your doc tests.
All the rules from the article Nine Rules for Elegant Rust Library APIs: Practical Lessons from Porting Bed-Reader, a Bioinformatics Library, from Python to Rust in Towards Data Science apply. Of particular importance are these two:
Write good documentation to keep your design honest.
Create examples that don’t embarrass you.
These suggest that we should give examples in our documentation, but how can we do that with async methods and awaits? The trick is “hidden lines” in our doc tests. For example, here is the documentation for CloudFile::read_ranges:
/// Return the `Vec` of [`Bytes`](https://docs.rs/bytes/latest/bytes/struct.Bytes.html) from specified ranges.
///
/// # Example
/// ```
/// use cloud_file::CloudFile;
///
/// # Runtime::new().unwrap().block_on(async {
/// let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/plink_sim_10s_100v_10pmiss.bim";
/// let cloud_file = CloudFile::new(url)?;
/// let bytes_vec = cloud_file.read_ranges(&[0..10, 1000..1010]).await?;
/// assert_eq!(bytes_vec.len(), 2);
/// assert_eq!(bytes_vec[0].as_ref(), b"1\t1:1:A:C\t");
/// assert_eq!(bytes_vec[1].as_ref(), b":A:C\t0.0\t4");
/// # Ok::<(), CloudFileError>(())}).unwrap();
/// # use {tokio::runtime::Runtime, cloud_file::CloudFileError};
/// ```
The doc test starts with “`. Within the doc test, lines starting with /// # disappear from the documentation:
The hidden lines, however, will still be run by cargo test.
In my library crates, I try to include a working example with every method. If such an example turns out overly complex or otherwise embarrassing, I try to fix the issue by improving the API.
Notice that in this rule and the previous Rule 7, we added a runtime to the code. Unfortunately, including a runtime can easily double the size of your user’s programs, even if they don’t read files from the cloud. Making this extra size optional is the topic of Rule 9.
Rule 9: Include a runtime, but optionally.
If you follow Rule 6 and provide async methods, your users gain the freedom to choose their own runtime. Opting for a runtime like Tokio may significantly increase their compiled program’s size. However, if they use no async methods, selecting a runtime becomes unnecessary, keeping the compiled program lean. This embodies the “zero cost principle”, where one incurs costs only for the features one uses.
On the other hand, if you follow Rule 7 and wrap async calls inside traditional, “synchronous” methods, then you must provide a runtime. This will increase the size of the resultant program. To mitigate this cost, you should make the inclusion of any runtime optional.
Bed-Reader includes a runtime under two conditions. First, when used as a Python extension. Second, when testing the async methods. To handle the first condition, we create a Cargo feature called extension-module that pulls in optional dependencies pyo3 and tokio. Here are the relevant sections of Cargo.toml:
[features]
extension-module = ["pyo3/extension-module", "tokio/full"]
default = []
[dependencies]
#...
pyo3 = { version = "0.20.0", features = ["extension-module"], optional = true }
tokio = { version = "1.35.0", features = ["full"], optional = true }
Also, because I’m using Maturin to create a Rust extension for Python, I include this text in pyproject.toml:
[tool.maturin]
features = ["extension-module"]
I put all the Rust code related to extending Python in a file called python_modules.rs. It starts with this conditional compilation attribute:
#![cfg(feature = "extension-module")] // ignore file if feature not 'on'
This starting line ensures that the compiler includes the extension code only when needed.
With the Python extension code taken care of, we turn next to providing an optional runtime for testing our async methods. I again choose Tokio as the runtime. I put the tests for the async code in their own file called tests_api_cloud.rs. To ensure that that async tests are run only when the tokio dependency feature is “on”, I start the file with this line:
#![cfg(feature = "tokio")]
As per Rule 5, we should also include examples in our documentation of the async methods. These examples also serve as “doc tests”. The doc tests need conditional compilation attributes. Below is the documentation for the method that retrieves chromosome metadata. Notice that the example includes two hidden lines that start
/// # #[cfg(feature = "tokio")]
/// Chromosome of each SNP (variant)
/// [...]
///
/// # Example:
/// ```
/// use ndarray as nd;
/// use bed_reader::{BedCloud, ReadOptions};
/// use bed_reader::assert_eq_nan;
///
/// # #[cfg(feature = "tokio")] Runtime::new().unwrap().block_on(async {
/// let url = "https://raw.githubusercontent.com/fastlmm/bed-sample-files/main/small.bed";
/// let mut bed_cloud = BedCloud::new(url).await?;
/// let chromosome = bed_cloud.chromosome().await?;
/// println!("{chromosome:?}"); // Outputs ndarray ["1", "1", "5", "Y"]
/// # Ok::<(), Box<BedErrorPlus>>(())}).unwrap();
/// # #[cfg(feature = "tokio")] use {tokio::runtime::Runtime, bed_reader::BedErrorPlus};
/// ```
In this doc test, when the tokio feature is ‘on’, the example, uses tokio and runs four lines of code inside a Tokio runtime. When the tokio feature is ‘off’, the code within the #[cfg(feature = "tokio")] block disappears, effectively skipping the asynchronous operations.
When formatting the documentation, Rust includes documentation for all features by default, so we see the four lines of code:
To summarize Rule 9: By using Cargo features and conditional compilation we can ensure that users only pay for the features that they use.
Conclusion
So, there you have it: nine rules for reading cloud files in your Rust program. Thanks to the power of the object_store crate, your programs can move beyond your local drive and load data from the web, AWS S3, Azure, and Google Cloud. To make this a little simpler, you can also use the new cloud-file wrapping crate that I wrote for this article.
I should also mention that this article explored only a subset of object_store’s features. In addition to what we’ve seen, the object_store crate also handles writing files and working with folders and subfolders. The cloud-file crate, on the other hand, only handles reading files. (But, hey, I’m open to pull requests).
Should you add cloud file support to your program? It, of course, depends. Supporting cloud files offers a huge convenience to your program’s users. The cost is the extra complexity of using/providing an async interface. The cost also includes the increased file size of runtimes like Tokio. On the other hand, I think the tools for adding such support are good and trying them is easy, so give it a try!
Thank you for joining me on this journey into the cloud. I hope that if you choose to support cloud files, these steps will help you do it.
Please follow Carl on Medium. I write on scientific programming in Rust and Python, machine learning, and statistics. I tend to write about one article per month.
Nine Rules for Accessing Cloud Files from Your Rust Code was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.