
Nine Rules for SIMD Acceleration of your Rust Code (Part 2)
General lessons from Boosting Data Ingestion in the range-set-blaze Crate by 7x
Thanks to Ben Lichtman (B3NNY) at the Seattle Rust Meetup for pointing me in the right direction on SIMD.
This is Part 2 of an article about creating SIMD code in Rust. (See Part 1.) We will look at rules 7 to 9:
- 7. Use Criterion benchmarking to pick an algorithm and to discover that LANES should (almost) always be 32 or 64.
- 8. Integrate your best SIMD algorithm into your project with as_simd, special code for i128/u128, and additional in-context benchmarking.
- 9. Extricate your best SIMD algorithm from your project (for now) with an optional cargo feature.
Recall rules 1 to 6:
- Use nightly Rust and core::simd, Rust’s experimental standard SIMD module.
- CCC: Check, Control, and Choose your computer’s SIMD capabilities.
- Learn core::simd, but selectively.
- Brainstorm candidate algorithms.
- Use Godbolt and AI to understand your code’s assembly, even if you don’t know assembly language.
- Generalize to all types and LANES with in-lined generics, (and when that doesn’t work) macros, and (when that doesn’t work) traits.
These rules are informed by my experience trying to speed up range-set-blaze, a Rust crate for manipulating sets of “clumpy” integers.
Recall that Rule 6, from Part 1, shows how to make Rust SIMD algorithms fully generic across type and LANES. We next need to pick our algorithm and set LANES.
Rule 7: Use Criterion benchmarking to pick an algorithm and to discover that LANES should (almost) always be 32 or 64.
In this rule, we’ll see how to use the popular criterion crate to benchmark and evaluate our algorithms and options. In the context of range-set-blaze, we’ll evaluate:
- 5 algorithms — Regular, Splat0, Splat1, Splat2, Rotate
- 3 SIMD extension levels — sse2 (128 bit), avx2 (256 bit), avx512f (512 bit)
- 10 element types — i8, u8, i16, u16, i32, u32, i64, u64, isize, usize
- 5 lane numbers — 4, 8, 16, 32, 64
- 4 input lengths — 1024; 10,240; 102,400; 1,024,000
- 2 CPUs — AMD 7950X with avx512f, Intel i5–8250U with avx2
The benchmark measures the average time to run each combination. We then compute throughput in Mbytes/sec.
See this new companion article on getting started with Criterion. That article also shows how to push (abuse?) Criterion to measure the effects of compiler settings, such as SIMD extension level.
Running the benchmarks results in a 5000-line *.csv file that starts:
Group,Id,Parameter,Mean(ns),StdErr(ns)
vector,regular,avx2,256,i16,16,16,1024,291.47,0.080141
vector,regular,avx2,256,i16,16,16,10240,2821.6,3.3949
vector,regular,avx2,256,i16,16,16,102400,28224,7.8341
vector,regular,avx2,256,i16,16,16,1024000,287220,67.067
vector,regular,avx2,256,i16,16,32,1024,285.89,0.59509
...
This file is suitable for analysis via spreadsheet pivot tables or data frame tools such as Polars.
Algorithms and Lanes
Here is an Excel pivot table showing — for each algorithm — throughput (MBytes/sec) vs. SIMD Lanes. The table averages throughput across SIMD extension levels, element types, and input length.
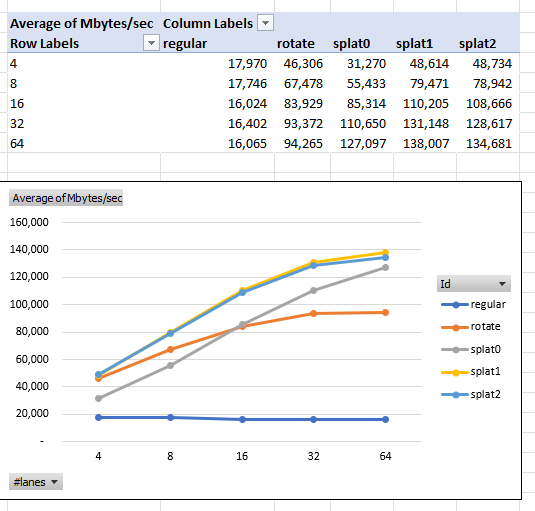
On my AMD desktop machine:
On an Intel laptop machine:
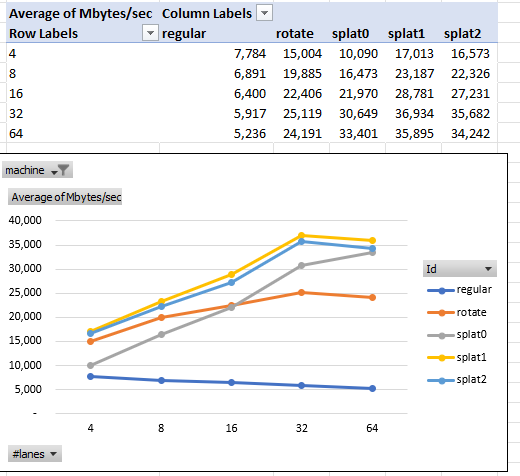
The tables show Splat1 and Splat2 doing best. They also show more lanes always being better up to 32 or 64.
How can, for example,sse2 (128-bits wide) process 64 lanes of i64 (4096-bits wide)? The Rust core::simd module makes this magic possible by automatically and efficiently dividing the 4096-bits into 32 chunks of 128-bits each. Processing the 32 128-bit chunks together (apparently) enables optimizations beyond processing the 128-bit chunks independently.
SIMD Extension Levels
Let’s set LANES to 64 and compare different SIMD extension levels on the AMD machine. The table averages throughput across element type and input length.
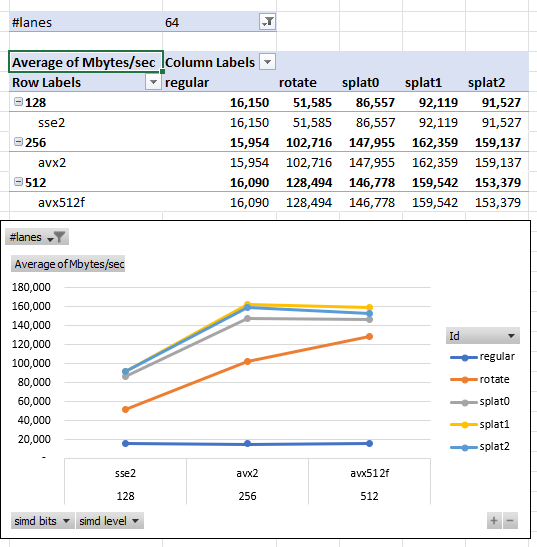
On my AMD machine, when using 64-lanes, sse2 is slowest. Comparingavx2 to avx512f, the results are mixed. Again, algorithm Splat1 and Splat2 do best.
Element Types
Let’s next set our SIMD extension level to avx512f and compare different element types. We keep LANES at 64 and average throughput across input length.
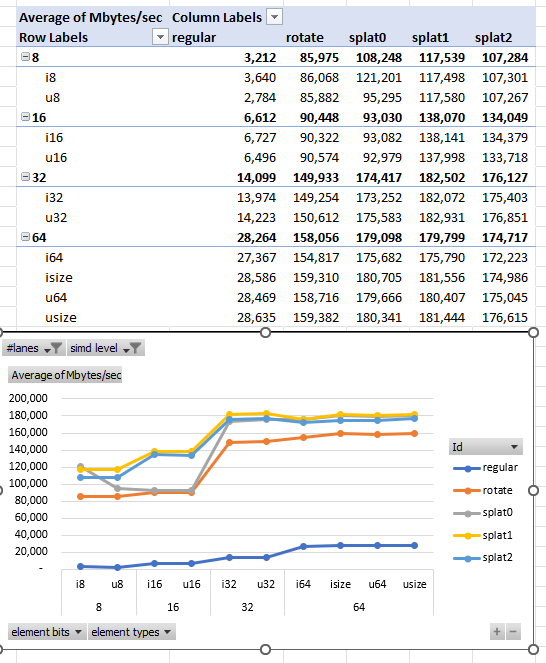
We see the bit-per-bit, 32-bit and 64-bit elements are processed fastest. (However, per element, smaller types are faster.) Splat1 and Splat2 are the fastest algorithms, with Splat1 being slightly better.
Input Length
Finally, let’s set our element type to i32 and see input length vs. throughput.
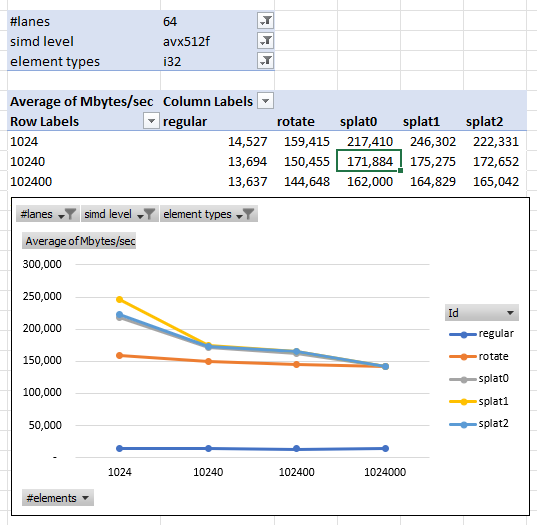
We see all the SIMD algorithms doing about the same at 1 million inputs. Splat1 apparently does better than other algorithms on short inputs.
It also looks like shorter is faster than longer. This could be the result of caching, or it could be an artifact of the benchmarks throwing away un-aligned data.
Benchmark Conclusions
Based on these benchmarks, we’ll use the Splat1 algorithm. For now, we’ll set LANES to 32 or 64, but see the next rule for a complication. Finally, we’ll advise users to set their SIMD extension level to at least avx2.
Rule 8: Integrate your best SIMD algorithm into your project with as_simd, special code for i128/u128, and additional in-context benchmarking.
as_simd
Before adding SIMD support, RangeSetBlaze’s main constructor was from_iter:
let a = RangeSetBlaze::from_iter([1, 2, 3]);
SIMD operations, however, work best on arrays, not iterators. Moreover, constructing a RangeSetBlaze from an array is often a natural thing to do, so I added a new from_slice constructor:
#[inline]
pub fn from_slice(slice: impl AsRef<[T]>) -> Self {
T::from_slice(slice)
}
The new constructor does an in-line call to each integer’s own from_slice method. For all the integer types, except i128/u128, this next calls:
let (prefix, middle, suffix) = slice.as_simd();
Rust’s nightly as_simd method safely and quickly transmutes the slice into:
- an unaligned prefix — which we process with from_iter, as before.
- middle, an aligned array of Simd struct chunks
- An unaligned suffix — which we process with from_iter, as before.
Think of middle as chunking our input integers into size-16 chunks (or whatever size LANES is set to). We then iterate the chunks through our is_consecutive function, looking for runs of true. Each run becomes a single range. For example, a run of 160 individual, consecutive integers from 1000 to 1159 (inclusive) would be identified and replaced with a single Rust RangeInclusive 1000..=1159. This range is then processed by from_iter much faster than from_iter would have processed the 160 individual integers. When is_consecutive returns false, we fall back to processing the chunk’s individual integers with from_iter.
i128/u128
How to we handle arrays of types that core::simd doesn't handle, namelyi128/u128? For now, I just process them with the slower from_iter.
In-Context Benchmarks
As a final step, benchmark your SIMD code in the context of your main code, ideally on representative data.
The range-set-blaze crate already includes benchmarks. One benchmark measures performance ingesting 1,000,000 integers with various levels of clumpiness. Average clump size ranges from 1 (no clump) to 100,000 clumps. Let’s run that benchmark with LANES set at 4, 8, 16, 32, and 64. We’ll use algorithm Splat1 and SIMD extension level avx512f.
For each clump size, the bars show the relative speed of ingesting 1,000,000 integers. For each clump size, the fastest LANES is set to 100%.
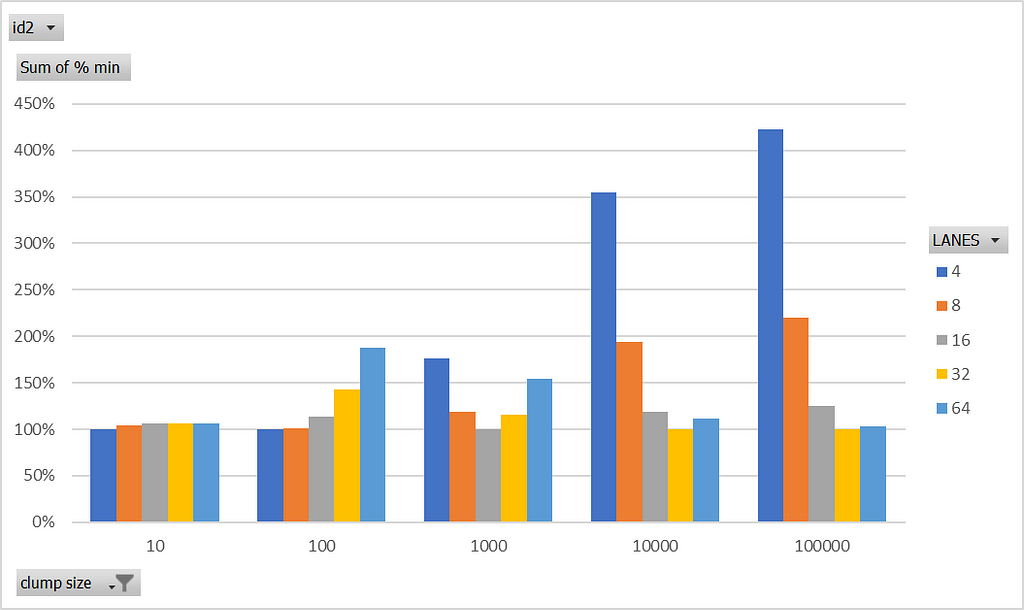
We see that for clumps of size 10 and 100, LANES=4 is best. With clumps of size 100,000, however, LANES=4 is 4 times worse than the best. At the other extreme, LANES=64 looks good with clumps of size 100,000, but it is 1.8 and 1.5 times worse than the best at 100 and 1000, respectively.
I decided to set LANES to 16. It is the best for clumps of size 1000. Moreover, it is never more than 1.25 times worse than the best.
With this setting, we can run other benchmarks. The chart below shows various range set libraries (including range-set-blaze) working on the same task — ingesting 1,000,000 integers of varying clumpiness. The y-axis is milliseconds with lower being better.
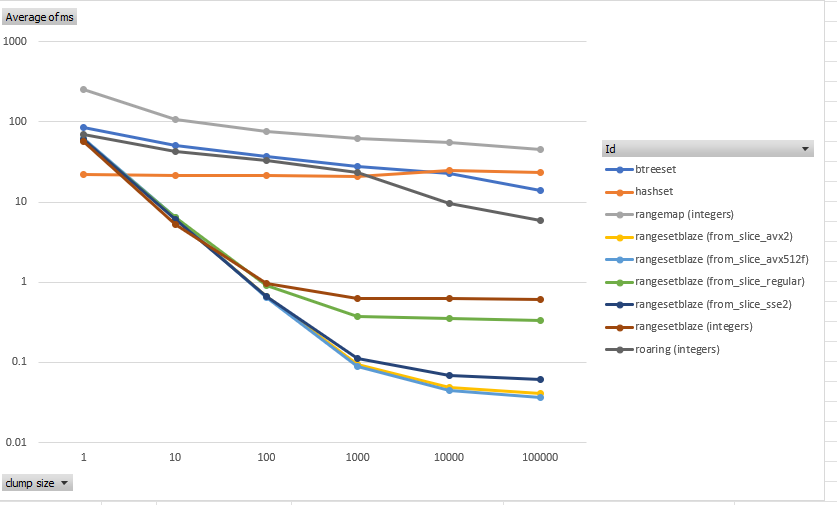
With clumps of size 1000, the existing RangeSetBlaze::into_iter method (red) was already 30 times faster than HashSet (orange). Note the scale is logarithmic. With avx512f, the new SIMD-powered RangeSetBlaze::into_slice algorithm (light blue) is 230 times faster than HashSet. With sse2 (dark blue), it is 220 times faster. With avx2 (yellow), it is 180 times faster. On this benchmark, compared to RangeSetBlaze::into_iter, avx512f RangeSetBlaze::into_slice is 7 times faster.
We should also consider the worst case, namely, ingesting data with no clumps. I ran that benchmark. It showed the existing RangeSetBlaze::into_iter is about 2.2 times slower than HashSet. The new RangeSetBlaze::into_slice is 2.4 times slower than HashSet.
So, on balance, the new SIMD code offers a huge upside for data that is assumed to be clumpy. If the assumption is wrong, it is slower, but not catastrophically so.
With the SIMD code integrated into our project, we’re ready to ship, right? Sadly, no. Because our code depends on Rust nightly, we should make it optional. We’ll see how to do that in the next rule.
Rule 9: Extricate your best SIMD algorithm from your project (for now) with an optional cargo feature.
Our beautiful new SIMD code depends on Rust nightly which can and does change nightly. Requiring users to depend on Rust nightly would be cruel. (Also, getting complaints when things break would be annoying.) The solution is to hide the SIMD code behind a cargo feature.
Feature, Feature, Feature — In the context of working with SIMD and Rust, the word “feature” is used three different ways. First, “CPU/target features” — these describe a CPU’s capabilities, including which SIMD extensions it supports. See target-feature and is_x86_feature_detected!. Second, “nightly feature gates” — Rust controls the visibility of new language features in Rust nightly with feature gates. For example, #![feature(portable_simd)]. Third, “cargo features”— these let any Rust crate or library offer/limit access to part of their capabilities. You see these in your Cargo.toml when you, for example, add a dependency to itertools/use_std.
Here are the steps that the range-set-blaze crate takes to make the nightly-dependent SIMD code optional:
- In Cargo.toml, define a cargo feature related to the SIMD code:
[features]
from_slice = []
- At the top lib.rs file, make the nightly portable_simd feature gate, depend on the from_slice, cargo feature:
#![cfg_attr(feature = "from_slice", feature(portable_simd))]
- Use the conditional compilation attribute, for example, #[cfg(feature = “from_slice”)], to include the SIMD code selectively. This includes tests.
/// Creates a [`RangeSetBlaze`] from a collection of integers. It is typically many
/// times faster than [`from_iter`][1]/[`collect`][1].
/// On a representative benchmark, the speed up was 6×.
///
/// **Warning: Requires the nightly compiler. Also, you must enable the `from_slice`
/// feature in your `Cargo.toml`. For example, with the command:**
/// ```bash
/// cargo add range-set-blaze --features "from_slice"
/// ```
///
/// **Caution**: Compiling with `-C target-cpu=native` optimizes the binary for your current CPU architecture,
/// which may lead to compatibility issues on other machines with different architectures.
/// This is particularly important for distributing the binary or running it in varied environments.
/// [1]: struct.RangeSetBlaze.html#impl-FromIterator<T>-for-RangeSetBlaze<T>
#[cfg(feature = "from_slice")]
#[inline]
pub fn from_slice(slice: impl AsRef<[T]>) -> Self {
T::from_slice(slice)
}
- As shown in the docs above, add warnings and cautions to the documentation.
- Use –features from_slice to check or test your SIMD code.
cargo check --features from_slice
cargo test --features from_slice
- Use –all-features to run all tests, generate all documentation, and publish all cargo features:
cargo test --all-features --doc
cargo doc --no-deps --all-features --open
cargo publish --all-features --dry-run
Conclusion
So, there you have it: nine rules for adding SIMD operations to your Rust code. The ease of this process reflects the core::simd library’s excellent design. Should you always use SIMD where applicable? Eventually, yes, when the library moves from Rust nightly to stable. For now, use SIMD where its performance benefits are crucial, or make its use optional.
Ideas for improving the SIMD experience in Rust? The quality of core::simd is already high; the main need is to stabilize it.
Thank you for joining me for this journey into SIMD programming. I hope that if you have a SIMD-appropriate problem, these steps will help you accelerate it.
Please follow Carl on Medium. I write on scientific programming in Rust and Python, machine learning, and statistics. I tend to write about one article per month.
Nine Rules for SIMD Acceleration of your Rust Code (Part 2) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
General lessons from Boosting Data Ingestion in the range-set-blaze Crate by 7x

Thanks to Ben Lichtman (B3NNY) at the Seattle Rust Meetup for pointing me in the right direction on SIMD.
This is Part 2 of an article about creating SIMD code in Rust. (See Part 1.) We will look at rules 7 to 9:
- 7. Use Criterion benchmarking to pick an algorithm and to discover that LANES should (almost) always be 32 or 64.
- 8. Integrate your best SIMD algorithm into your project with as_simd, special code for i128/u128, and additional in-context benchmarking.
- 9. Extricate your best SIMD algorithm from your project (for now) with an optional cargo feature.
Recall rules 1 to 6:
- Use nightly Rust and core::simd, Rust’s experimental standard SIMD module.
- CCC: Check, Control, and Choose your computer’s SIMD capabilities.
- Learn core::simd, but selectively.
- Brainstorm candidate algorithms.
- Use Godbolt and AI to understand your code’s assembly, even if you don’t know assembly language.
- Generalize to all types and LANES with in-lined generics, (and when that doesn’t work) macros, and (when that doesn’t work) traits.
These rules are informed by my experience trying to speed up range-set-blaze, a Rust crate for manipulating sets of “clumpy” integers.
Recall that Rule 6, from Part 1, shows how to make Rust SIMD algorithms fully generic across type and LANES. We next need to pick our algorithm and set LANES.
Rule 7: Use Criterion benchmarking to pick an algorithm and to discover that LANES should (almost) always be 32 or 64.
In this rule, we’ll see how to use the popular criterion crate to benchmark and evaluate our algorithms and options. In the context of range-set-blaze, we’ll evaluate:
- 5 algorithms — Regular, Splat0, Splat1, Splat2, Rotate
- 3 SIMD extension levels — sse2 (128 bit), avx2 (256 bit), avx512f (512 bit)
- 10 element types — i8, u8, i16, u16, i32, u32, i64, u64, isize, usize
- 5 lane numbers — 4, 8, 16, 32, 64
- 4 input lengths — 1024; 10,240; 102,400; 1,024,000
- 2 CPUs — AMD 7950X with avx512f, Intel i5–8250U with avx2
The benchmark measures the average time to run each combination. We then compute throughput in Mbytes/sec.
See this new companion article on getting started with Criterion. That article also shows how to push (abuse?) Criterion to measure the effects of compiler settings, such as SIMD extension level.
Running the benchmarks results in a 5000-line *.csv file that starts:
Group,Id,Parameter,Mean(ns),StdErr(ns)
vector,regular,avx2,256,i16,16,16,1024,291.47,0.080141
vector,regular,avx2,256,i16,16,16,10240,2821.6,3.3949
vector,regular,avx2,256,i16,16,16,102400,28224,7.8341
vector,regular,avx2,256,i16,16,16,1024000,287220,67.067
vector,regular,avx2,256,i16,16,32,1024,285.89,0.59509
...
This file is suitable for analysis via spreadsheet pivot tables or data frame tools such as Polars.
Algorithms and Lanes
Here is an Excel pivot table showing — for each algorithm — throughput (MBytes/sec) vs. SIMD Lanes. The table averages throughput across SIMD extension levels, element types, and input length.
On my AMD desktop machine:
On an Intel laptop machine:
The tables show Splat1 and Splat2 doing best. They also show more lanes always being better up to 32 or 64.
How can, for example,sse2 (128-bits wide) process 64 lanes of i64 (4096-bits wide)? The Rust core::simd module makes this magic possible by automatically and efficiently dividing the 4096-bits into 32 chunks of 128-bits each. Processing the 32 128-bit chunks together (apparently) enables optimizations beyond processing the 128-bit chunks independently.
SIMD Extension Levels
Let’s set LANES to 64 and compare different SIMD extension levels on the AMD machine. The table averages throughput across element type and input length.
On my AMD machine, when using 64-lanes, sse2 is slowest. Comparingavx2 to avx512f, the results are mixed. Again, algorithm Splat1 and Splat2 do best.
Element Types
Let’s next set our SIMD extension level to avx512f and compare different element types. We keep LANES at 64 and average throughput across input length.
We see the bit-per-bit, 32-bit and 64-bit elements are processed fastest. (However, per element, smaller types are faster.) Splat1 and Splat2 are the fastest algorithms, with Splat1 being slightly better.
Input Length
Finally, let’s set our element type to i32 and see input length vs. throughput.
We see all the SIMD algorithms doing about the same at 1 million inputs. Splat1 apparently does better than other algorithms on short inputs.
It also looks like shorter is faster than longer. This could be the result of caching, or it could be an artifact of the benchmarks throwing away un-aligned data.
Benchmark Conclusions
Based on these benchmarks, we’ll use the Splat1 algorithm. For now, we’ll set LANES to 32 or 64, but see the next rule for a complication. Finally, we’ll advise users to set their SIMD extension level to at least avx2.
Rule 8: Integrate your best SIMD algorithm into your project with as_simd, special code for i128/u128, and additional in-context benchmarking.
as_simd
Before adding SIMD support, RangeSetBlaze’s main constructor was from_iter:
let a = RangeSetBlaze::from_iter([1, 2, 3]);
SIMD operations, however, work best on arrays, not iterators. Moreover, constructing a RangeSetBlaze from an array is often a natural thing to do, so I added a new from_slice constructor:
#[inline]
pub fn from_slice(slice: impl AsRef<[T]>) -> Self {
T::from_slice(slice)
}
The new constructor does an in-line call to each integer’s own from_slice method. For all the integer types, except i128/u128, this next calls:
let (prefix, middle, suffix) = slice.as_simd();
Rust’s nightly as_simd method safely and quickly transmutes the slice into:
- an unaligned prefix — which we process with from_iter, as before.
- middle, an aligned array of Simd struct chunks
- An unaligned suffix — which we process with from_iter, as before.
Think of middle as chunking our input integers into size-16 chunks (or whatever size LANES is set to). We then iterate the chunks through our is_consecutive function, looking for runs of true. Each run becomes a single range. For example, a run of 160 individual, consecutive integers from 1000 to 1159 (inclusive) would be identified and replaced with a single Rust RangeInclusive 1000..=1159. This range is then processed by from_iter much faster than from_iter would have processed the 160 individual integers. When is_consecutive returns false, we fall back to processing the chunk’s individual integers with from_iter.
i128/u128
How to we handle arrays of types that core::simd doesn't handle, namelyi128/u128? For now, I just process them with the slower from_iter.
In-Context Benchmarks
As a final step, benchmark your SIMD code in the context of your main code, ideally on representative data.
The range-set-blaze crate already includes benchmarks. One benchmark measures performance ingesting 1,000,000 integers with various levels of clumpiness. Average clump size ranges from 1 (no clump) to 100,000 clumps. Let’s run that benchmark with LANES set at 4, 8, 16, 32, and 64. We’ll use algorithm Splat1 and SIMD extension level avx512f.
For each clump size, the bars show the relative speed of ingesting 1,000,000 integers. For each clump size, the fastest LANES is set to 100%.
We see that for clumps of size 10 and 100, LANES=4 is best. With clumps of size 100,000, however, LANES=4 is 4 times worse than the best. At the other extreme, LANES=64 looks good with clumps of size 100,000, but it is 1.8 and 1.5 times worse than the best at 100 and 1000, respectively.
I decided to set LANES to 16. It is the best for clumps of size 1000. Moreover, it is never more than 1.25 times worse than the best.
With this setting, we can run other benchmarks. The chart below shows various range set libraries (including range-set-blaze) working on the same task — ingesting 1,000,000 integers of varying clumpiness. The y-axis is milliseconds with lower being better.
With clumps of size 1000, the existing RangeSetBlaze::into_iter method (red) was already 30 times faster than HashSet (orange). Note the scale is logarithmic. With avx512f, the new SIMD-powered RangeSetBlaze::into_slice algorithm (light blue) is 230 times faster than HashSet. With sse2 (dark blue), it is 220 times faster. With avx2 (yellow), it is 180 times faster. On this benchmark, compared to RangeSetBlaze::into_iter, avx512f RangeSetBlaze::into_slice is 7 times faster.
We should also consider the worst case, namely, ingesting data with no clumps. I ran that benchmark. It showed the existing RangeSetBlaze::into_iter is about 2.2 times slower than HashSet. The new RangeSetBlaze::into_slice is 2.4 times slower than HashSet.
So, on balance, the new SIMD code offers a huge upside for data that is assumed to be clumpy. If the assumption is wrong, it is slower, but not catastrophically so.
With the SIMD code integrated into our project, we’re ready to ship, right? Sadly, no. Because our code depends on Rust nightly, we should make it optional. We’ll see how to do that in the next rule.
Rule 9: Extricate your best SIMD algorithm from your project (for now) with an optional cargo feature.
Our beautiful new SIMD code depends on Rust nightly which can and does change nightly. Requiring users to depend on Rust nightly would be cruel. (Also, getting complaints when things break would be annoying.) The solution is to hide the SIMD code behind a cargo feature.
Feature, Feature, Feature — In the context of working with SIMD and Rust, the word “feature” is used three different ways. First, “CPU/target features” — these describe a CPU’s capabilities, including which SIMD extensions it supports. See target-feature and is_x86_feature_detected!. Second, “nightly feature gates” — Rust controls the visibility of new language features in Rust nightly with feature gates. For example, #![feature(portable_simd)]. Third, “cargo features”— these let any Rust crate or library offer/limit access to part of their capabilities. You see these in your Cargo.toml when you, for example, add a dependency to itertools/use_std.
Here are the steps that the range-set-blaze crate takes to make the nightly-dependent SIMD code optional:
- In Cargo.toml, define a cargo feature related to the SIMD code:
[features]
from_slice = []
- At the top lib.rs file, make the nightly portable_simd feature gate, depend on the from_slice, cargo feature:
#![cfg_attr(feature = "from_slice", feature(portable_simd))]
- Use the conditional compilation attribute, for example, #[cfg(feature = “from_slice”)], to include the SIMD code selectively. This includes tests.
/// Creates a [`RangeSetBlaze`] from a collection of integers. It is typically many
/// times faster than [`from_iter`][1]/[`collect`][1].
/// On a representative benchmark, the speed up was 6×.
///
/// **Warning: Requires the nightly compiler. Also, you must enable the `from_slice`
/// feature in your `Cargo.toml`. For example, with the command:**
/// ```bash
/// cargo add range-set-blaze --features "from_slice"
/// ```
///
/// **Caution**: Compiling with `-C target-cpu=native` optimizes the binary for your current CPU architecture,
/// which may lead to compatibility issues on other machines with different architectures.
/// This is particularly important for distributing the binary or running it in varied environments.
/// [1]: struct.RangeSetBlaze.html#impl-FromIterator<T>-for-RangeSetBlaze<T>
#[cfg(feature = "from_slice")]
#[inline]
pub fn from_slice(slice: impl AsRef<[T]>) -> Self {
T::from_slice(slice)
}
- As shown in the docs above, add warnings and cautions to the documentation.
- Use –features from_slice to check or test your SIMD code.
cargo check --features from_slice
cargo test --features from_slice
- Use –all-features to run all tests, generate all documentation, and publish all cargo features:
cargo test --all-features --doc
cargo doc --no-deps --all-features --open
cargo publish --all-features --dry-run
Conclusion
So, there you have it: nine rules for adding SIMD operations to your Rust code. The ease of this process reflects the core::simd library’s excellent design. Should you always use SIMD where applicable? Eventually, yes, when the library moves from Rust nightly to stable. For now, use SIMD where its performance benefits are crucial, or make its use optional.
Ideas for improving the SIMD experience in Rust? The quality of core::simd is already high; the main need is to stabilize it.
Thank you for joining me for this journey into SIMD programming. I hope that if you have a SIMD-appropriate problem, these steps will help you accelerate it.
Please follow Carl on Medium. I write on scientific programming in Rust and Python, machine learning, and statistics. I tend to write about one article per month.
Nine Rules for SIMD Acceleration of your Rust Code (Part 2) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.