
OpenAI vs Open-Source Multilingual Embedding Models
Choosing the model that works best for your data
OpenAI recently released their new generation of embedding models, called embedding v3, which they describe as their most performant embedding models, with higher multilingual performances. The models come in two classes: a smaller one called text-embedding-3-small, and a larger and more powerful one called text-embedding-3-large.
Very little information was disclosed concerning the way these models were designed and trained. As their previous embedding model release (December 2022 with the ada-002 model class), OpenAI again chooses a closed-source approach where the models may only be accessed through a paid API.
But are the performances so good that they make it worth paying?
The motivation for this post is to empirically compare the performances of these new models with their open-source counterparts. We’ll rely on a data retrieval workflow, where the most relevant documents in a corpus have to be found given a user query.
Our corpus will be the European AI Act, which is currently in its final stages of validation. An interesting characteristic of this corpus, besides being the first-ever legal framework on AI worldwide, is its availability in 24 languages. This makes it possible to compare the accuracy of data retrieval across different families of languages.
The post will go through the two main following steps:
- Generate a custom synthetic question/answer dataset from a multilingual text corpus
- Compare the accuracy of OpenAI and state-of-the-art open-source embedding models on this custom dataset.
The code and data to reproduce the results presented in this post are made available in this Github repository. Note that the EU AI Act is used as an example, and the methodology followed in this post can be adapted to other data corpus.
Generate a custom Q/A dataset
Let us first start by generating a dataset of questions and answers (Q/A) on custom data, which will be used to assess the performance of different embedding models. The benefits of generating a custom Q/A dataset are twofold. First, it avoids biases by ensuring that the dataset has not been part of the training of an embedding model, which may happen on reference benchmarks such as MTEB. Second, it allows to tailor the assessment to a specific corpus of data, which can be relevant in the case of retrieval augmented applications (RAG) for example.
We will follow the simple process suggested by Llama Index in their documentation. The corpus is first split into a set of chunks. Then, for each chunk, a set of synthetic questions are generated by means of a large language model (LLM), such that the answer lies in the corresponding chunk. The process is illustrated below:
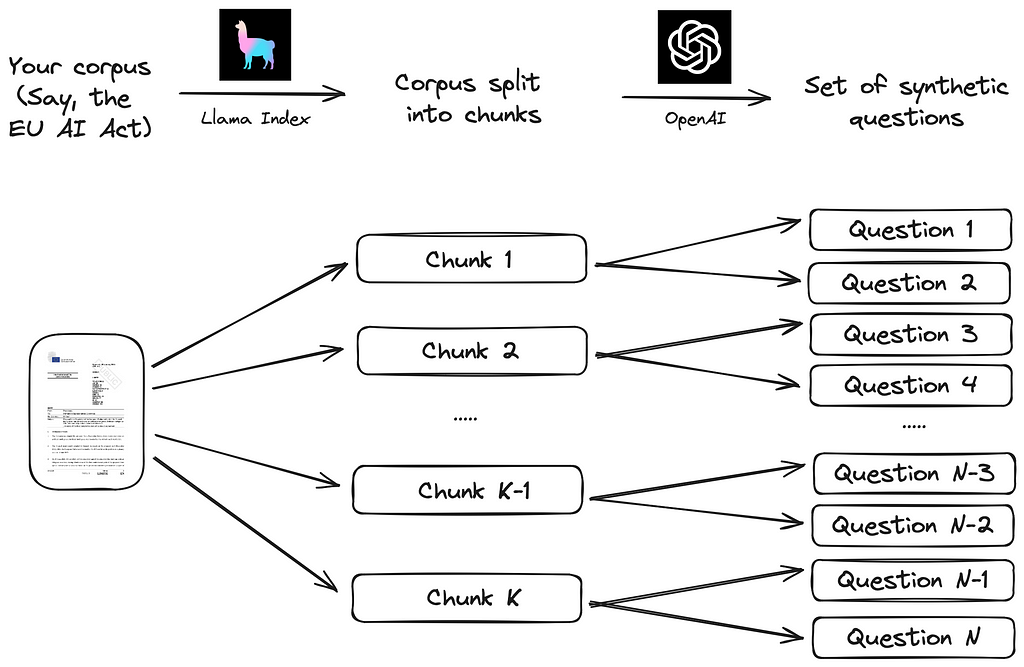
Implementing this strategy is straightforward with a data framework for LLM such as Llama Index. The loading of the corpus and splitting of text can be conveniently carried out using high-level functions, as illustrated with the following code.
from llama_index.readers.web import SimpleWebPageReader
from llama_index.core.node_parser import SentenceSplitter
language = "EN"
url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206"
documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc])
parser = SentenceSplitter(chunk_size=1000)
nodes = parser.get_nodes_from_documents(documents, show_progress=True)
In this example, the corpus is the EU AI Act in English, taken directly from the Web using this official URL. We use the draft version from April 2021, as the final version is not yet available for all European languages. In this version, English language can be replaced in the URL by any of the 23 other EU official languages to retrieve the text in a different language (BG for Bulgarian, ES for Spanish, CS for Czech, and so forth).

We use the SentenceSplitter object to split the document in chunks of 1000 tokens. For English, this results in about 100 chunks.
Each chunk is then provided as context to the following prompt (the default prompt suggested in the Llama Index library):
prompts={}
prompts["EN"] = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, generate only questions based on the below query.
You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination.
The questions should be diverse in nature across the document. Restrict the questions to the context information provided."
"""
The prompt aims at generating questions about the document chunk, as if a teacher were preparing an upcoming quiz. The number of questions to generate for each chunk is passed as the parameter ‘num_questions_per_chunk’, which we set to two. Questions can then be generated by calling the generate_qa_embedding_pairs from the Llama Index library:
from llama_index.llms import OpenAI
from llama_index.legacy.finetuning import generate_qa_embedding_pairs
qa_dataset = generate_qa_embedding_pairs(
llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),
nodes=nodes,
qa_generate_prompt_tmpl = prompts[language],
num_questions_per_chunk=2
)
We rely for this task on the GPT-3.5-turbo-0125 mode from OpenAI, which is according to OpenAI the flagship model of this family, supporting a 16K context window and optimized for dialog (https://platform.openai.com/docs/models/gpt-3-5-turbo).
The resulting objet ‘qa_dataset’ contains the questions and answers (chunks) pairs. As an example of generated questions, here is the result for the first two questions (for which the ‘answer’ is the first chunk of text):
1) What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
2) How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
The number of chunks and questions depends on the language, ranging from around 100 chunks and 200 questions for English, to 200 chunks and 400 questions for Hungarian.
Evaluation of OpenAI embedding models
Our evaluation function follows the Llama Index documentation and consists in two main steps. First, the embeddings for all answers (document chunks) are stored in a VectorStoreIndex for efficient retrieval. Then, the evaluation function loops over all queries, retrieves the top k most similar documents, and the accuracy of the retrieval in assessed in terms of MRR (Mean Reciprocal Rank).
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):
# Get corpus, queries, and relevant documents from the qa_dataset object
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs
# Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddings
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(
nodes, embed_model=embed_model, insert_batch_size=insert_batch_size
)
retriever = index.as_retriever(similarity_top_k=top_k)
# Prepare to collect evaluation results
eval_results = []
# Iterate over each query in the dataset to evaluate retrieval performance
for query_id, query in tqdm(queries.items()):
# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documents
retrieved_nodes = retriever.retrieve(query)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
# Check if the expected document was among the retrieved documents
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query
# Calculate the Mean Reciprocal Rank (MRR) and append to results
if is_hit:
rank = retrieved_ids.index(expected_id) + 1
mrr = 1 / rank
else:
mrr = 0
eval_results.append(mrr)
# Return the average MRR across all queries as the final evaluation metric
return np.average(eval_results)
The embedding model is passed to the evaluation function by means of the `embed_model` argument, which for OpenAI models is an OpenAIEmbedding object initialised with the name of the model, and the model dimension.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
The dimensions API parameter can shorten embeddings (i.e. remove some numbers from the end of the sequence) without the embedding losing its concept-representing properties. OpenAI for example suggests in their annoucement that on the MTEB benchmark, an embedding can be shortened to a size of 256 while still outperforming an unshortened text-embedding-ada-002 embedding with a size of 1536.
We ran the evaluation function on four different OpenAI embedding models:
- two versions of text-embedding-3-large : one with the lowest possible dimension (256), and the other one with the highest possible dimension (3072). These are called ‘OAI-large-256’ and ‘OAI-large-3072’.
- OAI-small: The text-embedding-3-small embedding model, with a dimension of 1536.
- OAI-ada-002: The legacy text-embedding-ada-002 model, with a dimension of 1536.
Each model was evaluated on four different languages: English (EN), French (FR), Czech (CS) and Hungarian (HU), covering examples of Germanic, Romance, Slavic and Uralic language, respectively.
embeddings_model_spec = {
}
embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256}
embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072}
embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536}
embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
# Get model
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
# Assess embedding score (in terms of MRR)
score = evaluate(qa_dataset, embed_model)
results.append([language, model_name, score])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])
The resulting accuracy in terms of MRR is reported below:
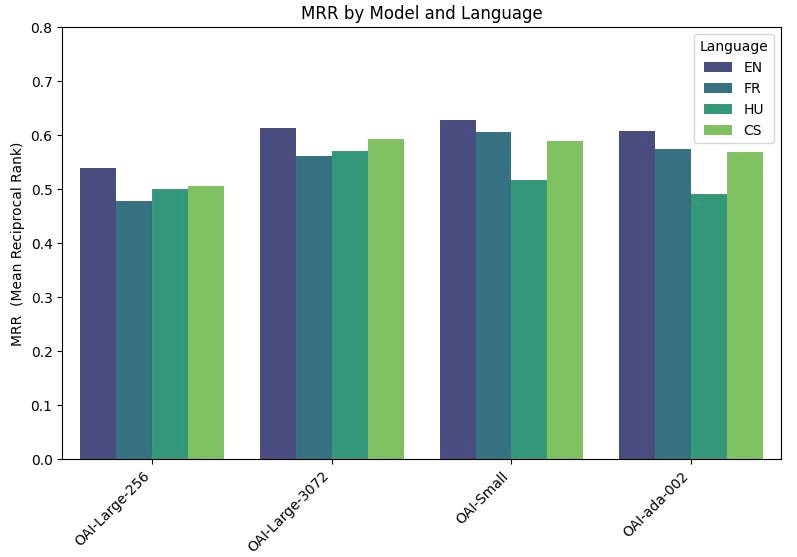
As expected, for the large model, better performances are observed with the larger embedding size of 3072. Compared with the small and legacy Ada models, the large model is however smaller than we would have expected. For comparison, we also report below the performances obtained by the OpenAI models on the MTEB benchmark.

It is interesting to note that the differences in performances between the large, small and Ada models are much less pronounced in our assessment than in the MTEB benchmark, reflecting the fact that the average performances observed in large benchmarks do not necessarily reflect those obtained on custom datasets.
Evaluation of open-source embedding models
The open-source research around embeddings is quite active, and new models are regularly published. A good place to keep updated about the latest published models is the Hugging Face 😊 MTEB leaderboard.
For the comparison in this article, we selected a set of four embedding models recently published (2024). The criteria for selection were their average score on the MTEB leaderboard and their ability to deal with multilingual data. A summary of the main characteristics of the selected models are reported below.
https://medium.com/media/40d49624c644634c450716e8806fc312/href
- E5-Mistral-7B-instruct (E5-mistral-7b): This E5 embedding model by Microsoft is initialized from Mistral-7B-v0.1 and fine-tuned on a mixture of multilingual datasets. The model performs best on the MTEB leaderboard, but is also by far the biggest one (14GB).
- multilingual-e5-large-instruct (ML-E5-large): Another E5 model from Microsoft, meant to better handle multilingual data. It is initialized from xlm-roberta-large and trained on a mixture of multilingual datasets. It is much smaller (10 times) than E5-Mistral, but also has a much lower context size (514).
- BGE-M3: The model was designed by the Beijing Academy of Artificial Intelligence, and is their state-of-the-art embedding model for multilingual data, supporting more than 100 working languages. It was not yet benchmarked on the MTEB leaderboard as of 22/02/2024.
- nomic-embed-text-v1 (Nomic-Embed): The model was designed by Nomic, and claims better performances than OpenAI Ada-002 and text-embedding-3-small while being only 0.55GB in size. Interestingly, the model is the first to be fully reproducible and auditable (open data and open-source training code).
The code for evaluating these open-source models is similar to the code used for OpenAI models. The main change lies in the model specifications, where additional details such as maximum context length and pooling types have to be specified. We then evaluate each model for each of the four languages:
embeddings_model_spec = {
}
embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token',
'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}}
embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
print("Processing model : "+str(model_spec))
# Get model
tokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])
embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs'])
if model_name=="Nomic-Embed":
embed_model.to('cuda')
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
start_time_assessment=time.time()
# Assess embedding score (in terms of hit rate at k=5)
score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type'])
# Get duration of score assessment
duration_assessment = time.time()-start_time_assessment
results.append([language, model_name, score, duration_assessment])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])
The resulting accuracies in terms of MRR are reported below.
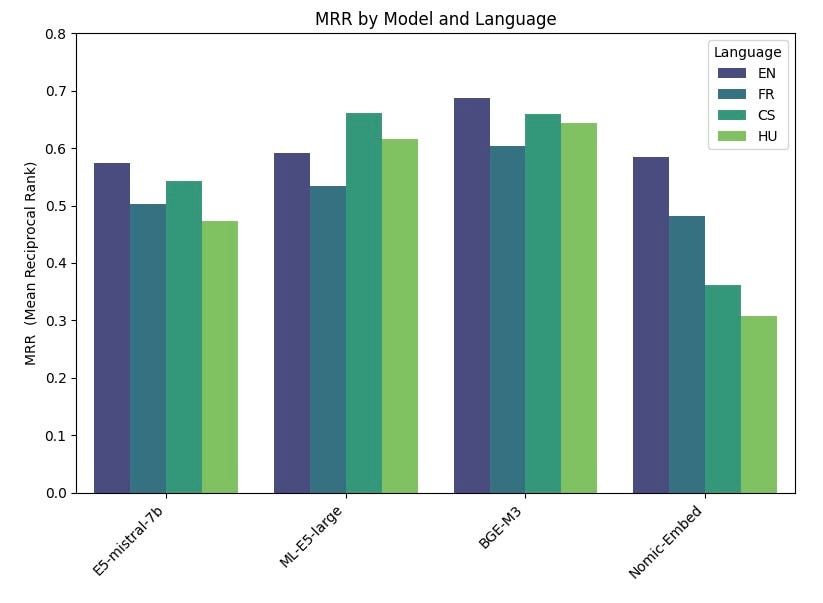
BGE-M3 turns out to provide the best performances, followed on average by ML-E5-Large, E5-mistral-7b and Nomic-Embed. BGE-M3 model is not yet benchmarked on the MTEB leaderboard, and our results indicate that it could rank higher than other models. It is also interesting to note that while BGE-M3 is optimized for multilingual data, it also performs better for English than the other models.
We additionally report the processing times for each embedding model below.
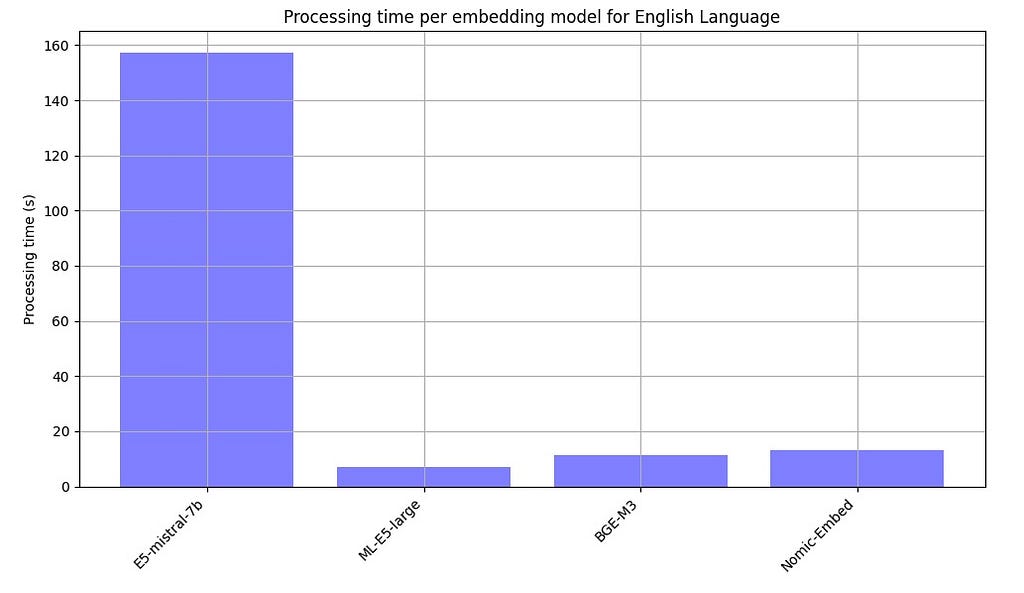
The E5-mistral-7b, which is more than 10 times larger than the other models, is without surprise by far the slowest model.
Conclusion
Let us put side-by-side of the performance of the eight tested models in a single figure.
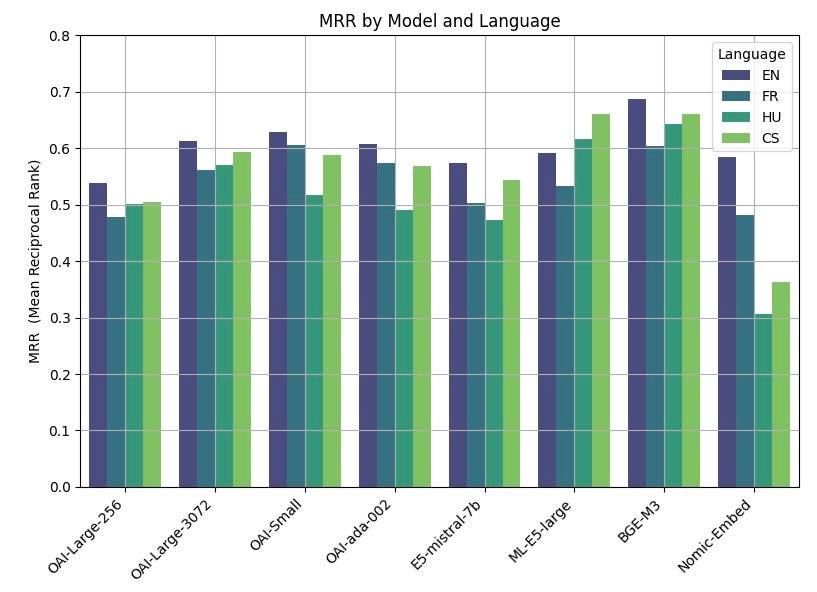
The key observations from these results are:
- Best performances were obtained by open-source models. The BGE-M3 model, developed by the Beijing Academy of Artificial Intelligence, emerged as the top performer. The model has the same context length as OpenAI models (8K), for a size of 2.2GB.
- Consistency Across OpenAI’s Range. The performances of the large (3072), small and legacy OpenAI models were very similar. Reducing the embedding size of the large model (256) however led to a degradation of performances.
- Language Sensitivity. Almost all models (except ML-E5-large) performed best on English. Significant variations in performances were observed in languages like Czech and Hungarian.
Should you therefore go for a paid OpenAI subscription, or for hosting an open-source embedding model?
OpenAI’s recent price revision has made access to their API significantly more affordable, with the cost now standing at $0.13 per million tokens. Dealing with one million queries per month (and assuming that each query involves around 1K token) would therefore cost on the order of $130. Depending on your use case, it may therefore not be cost-effective to rent and maintain your own embedding server.
Cost-effectiveness is however not the sole consideration. Other factors such as latency, privacy, and control over data processing workflows may also need to be considered. Open-source models offer the advantage of complete data control, enhancing privacy and customization. On the other hand, latency issues have been observed with OpenAI’s API, sometimes resulting in extended response times.
In conclusion, the choice between open-source models and proprietary solutions like OpenAI’s does not lend itself to a straightforward answer. Open-source embeddings present a compelling option, combining performance with greater control over data. Conversely, OpenAI’s offerings may still appeal to those prioritizing convenience, especially if privacy concerns are secondary.
Useful links
- Companion Github repository: https://github.com/Yannael/multilingual-embeddings
- Everything you wanted to know about sentence embeddings (and maybe a bit more)
- OpenAI blog announcement: New embedding models and API updates
- Embeddings: OpenAI guide
- MTEB: Massive Text Embedding Benchmark and Hugging Face MTEB leaderboard
- Text Embeddings: Comprehensive Guide
- A Practitioners Guide to Retrieval Augmented Generation (RAG)
- How to Find the Best Multilingual Embedding Model for Your RAG
Notes:
- Unless otherwise noted, all images are by the author
- The EU AI act draft is published under the Commission’s document reuse policy based on Decision 2011/833/EU, and can be re-used for commercial or non-commercial purposes.
OpenAI vs Open-Source Multilingual Embedding Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Choosing the model that works best for your data

OpenAI recently released their new generation of embedding models, called embedding v3, which they describe as their most performant embedding models, with higher multilingual performances. The models come in two classes: a smaller one called text-embedding-3-small, and a larger and more powerful one called text-embedding-3-large.
Very little information was disclosed concerning the way these models were designed and trained. As their previous embedding model release (December 2022 with the ada-002 model class), OpenAI again chooses a closed-source approach where the models may only be accessed through a paid API.
But are the performances so good that they make it worth paying?
The motivation for this post is to empirically compare the performances of these new models with their open-source counterparts. We’ll rely on a data retrieval workflow, where the most relevant documents in a corpus have to be found given a user query.
Our corpus will be the European AI Act, which is currently in its final stages of validation. An interesting characteristic of this corpus, besides being the first-ever legal framework on AI worldwide, is its availability in 24 languages. This makes it possible to compare the accuracy of data retrieval across different families of languages.
The post will go through the two main following steps:
- Generate a custom synthetic question/answer dataset from a multilingual text corpus
- Compare the accuracy of OpenAI and state-of-the-art open-source embedding models on this custom dataset.
The code and data to reproduce the results presented in this post are made available in this Github repository. Note that the EU AI Act is used as an example, and the methodology followed in this post can be adapted to other data corpus.
Generate a custom Q/A dataset
Let us first start by generating a dataset of questions and answers (Q/A) on custom data, which will be used to assess the performance of different embedding models. The benefits of generating a custom Q/A dataset are twofold. First, it avoids biases by ensuring that the dataset has not been part of the training of an embedding model, which may happen on reference benchmarks such as MTEB. Second, it allows to tailor the assessment to a specific corpus of data, which can be relevant in the case of retrieval augmented applications (RAG) for example.
We will follow the simple process suggested by Llama Index in their documentation. The corpus is first split into a set of chunks. Then, for each chunk, a set of synthetic questions are generated by means of a large language model (LLM), such that the answer lies in the corresponding chunk. The process is illustrated below:
Implementing this strategy is straightforward with a data framework for LLM such as Llama Index. The loading of the corpus and splitting of text can be conveniently carried out using high-level functions, as illustrated with the following code.
from llama_index.readers.web import SimpleWebPageReader
from llama_index.core.node_parser import SentenceSplitter
language = "EN"
url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206"
documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc])
parser = SentenceSplitter(chunk_size=1000)
nodes = parser.get_nodes_from_documents(documents, show_progress=True)
In this example, the corpus is the EU AI Act in English, taken directly from the Web using this official URL. We use the draft version from April 2021, as the final version is not yet available for all European languages. In this version, English language can be replaced in the URL by any of the 23 other EU official languages to retrieve the text in a different language (BG for Bulgarian, ES for Spanish, CS for Czech, and so forth).
We use the SentenceSplitter object to split the document in chunks of 1000 tokens. For English, this results in about 100 chunks.
Each chunk is then provided as context to the following prompt (the default prompt suggested in the Llama Index library):
prompts={}
prompts["EN"] = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, generate only questions based on the below query.
You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination.
The questions should be diverse in nature across the document. Restrict the questions to the context information provided."
"""
The prompt aims at generating questions about the document chunk, as if a teacher were preparing an upcoming quiz. The number of questions to generate for each chunk is passed as the parameter ‘num_questions_per_chunk’, which we set to two. Questions can then be generated by calling the generate_qa_embedding_pairs from the Llama Index library:
from llama_index.llms import OpenAI
from llama_index.legacy.finetuning import generate_qa_embedding_pairs
qa_dataset = generate_qa_embedding_pairs(
llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),
nodes=nodes,
qa_generate_prompt_tmpl = prompts[language],
num_questions_per_chunk=2
)
We rely for this task on the GPT-3.5-turbo-0125 mode from OpenAI, which is according to OpenAI the flagship model of this family, supporting a 16K context window and optimized for dialog (https://platform.openai.com/docs/models/gpt-3-5-turbo).
The resulting objet ‘qa_dataset’ contains the questions and answers (chunks) pairs. As an example of generated questions, here is the result for the first two questions (for which the ‘answer’ is the first chunk of text):
1) What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
2) How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
The number of chunks and questions depends on the language, ranging from around 100 chunks and 200 questions for English, to 200 chunks and 400 questions for Hungarian.
Evaluation of OpenAI embedding models
Our evaluation function follows the Llama Index documentation and consists in two main steps. First, the embeddings for all answers (document chunks) are stored in a VectorStoreIndex for efficient retrieval. Then, the evaluation function loops over all queries, retrieves the top k most similar documents, and the accuracy of the retrieval in assessed in terms of MRR (Mean Reciprocal Rank).
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):
# Get corpus, queries, and relevant documents from the qa_dataset object
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs
# Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddings
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(
nodes, embed_model=embed_model, insert_batch_size=insert_batch_size
)
retriever = index.as_retriever(similarity_top_k=top_k)
# Prepare to collect evaluation results
eval_results = []
# Iterate over each query in the dataset to evaluate retrieval performance
for query_id, query in tqdm(queries.items()):
# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documents
retrieved_nodes = retriever.retrieve(query)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
# Check if the expected document was among the retrieved documents
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query
# Calculate the Mean Reciprocal Rank (MRR) and append to results
if is_hit:
rank = retrieved_ids.index(expected_id) + 1
mrr = 1 / rank
else:
mrr = 0
eval_results.append(mrr)
# Return the average MRR across all queries as the final evaluation metric
return np.average(eval_results)
The embedding model is passed to the evaluation function by means of the `embed_model` argument, which for OpenAI models is an OpenAIEmbedding object initialised with the name of the model, and the model dimension.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
The dimensions API parameter can shorten embeddings (i.e. remove some numbers from the end of the sequence) without the embedding losing its concept-representing properties. OpenAI for example suggests in their annoucement that on the MTEB benchmark, an embedding can be shortened to a size of 256 while still outperforming an unshortened text-embedding-ada-002 embedding with a size of 1536.
We ran the evaluation function on four different OpenAI embedding models:
- two versions of text-embedding-3-large : one with the lowest possible dimension (256), and the other one with the highest possible dimension (3072). These are called ‘OAI-large-256’ and ‘OAI-large-3072’.
- OAI-small: The text-embedding-3-small embedding model, with a dimension of 1536.
- OAI-ada-002: The legacy text-embedding-ada-002 model, with a dimension of 1536.
Each model was evaluated on four different languages: English (EN), French (FR), Czech (CS) and Hungarian (HU), covering examples of Germanic, Romance, Slavic and Uralic language, respectively.
embeddings_model_spec = {
}
embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256}
embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072}
embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536}
embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
# Get model
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
# Assess embedding score (in terms of MRR)
score = evaluate(qa_dataset, embed_model)
results.append([language, model_name, score])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])
The resulting accuracy in terms of MRR is reported below:
As expected, for the large model, better performances are observed with the larger embedding size of 3072. Compared with the small and legacy Ada models, the large model is however smaller than we would have expected. For comparison, we also report below the performances obtained by the OpenAI models on the MTEB benchmark.
It is interesting to note that the differences in performances between the large, small and Ada models are much less pronounced in our assessment than in the MTEB benchmark, reflecting the fact that the average performances observed in large benchmarks do not necessarily reflect those obtained on custom datasets.
Evaluation of open-source embedding models
The open-source research around embeddings is quite active, and new models are regularly published. A good place to keep updated about the latest published models is the Hugging Face 😊 MTEB leaderboard.
For the comparison in this article, we selected a set of four embedding models recently published (2024). The criteria for selection were their average score on the MTEB leaderboard and their ability to deal with multilingual data. A summary of the main characteristics of the selected models are reported below.
https://medium.com/media/40d49624c644634c450716e8806fc312/href
- E5-Mistral-7B-instruct (E5-mistral-7b): This E5 embedding model by Microsoft is initialized from Mistral-7B-v0.1 and fine-tuned on a mixture of multilingual datasets. The model performs best on the MTEB leaderboard, but is also by far the biggest one (14GB).
- multilingual-e5-large-instruct (ML-E5-large): Another E5 model from Microsoft, meant to better handle multilingual data. It is initialized from xlm-roberta-large and trained on a mixture of multilingual datasets. It is much smaller (10 times) than E5-Mistral, but also has a much lower context size (514).
- BGE-M3: The model was designed by the Beijing Academy of Artificial Intelligence, and is their state-of-the-art embedding model for multilingual data, supporting more than 100 working languages. It was not yet benchmarked on the MTEB leaderboard as of 22/02/2024.
- nomic-embed-text-v1 (Nomic-Embed): The model was designed by Nomic, and claims better performances than OpenAI Ada-002 and text-embedding-3-small while being only 0.55GB in size. Interestingly, the model is the first to be fully reproducible and auditable (open data and open-source training code).
The code for evaluating these open-source models is similar to the code used for OpenAI models. The main change lies in the model specifications, where additional details such as maximum context length and pooling types have to be specified. We then evaluate each model for each of the four languages:
embeddings_model_spec = {
}
embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token',
'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}}
embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
print("Processing model : "+str(model_spec))
# Get model
tokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])
embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs'])
if model_name=="Nomic-Embed":
embed_model.to('cuda')
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
start_time_assessment=time.time()
# Assess embedding score (in terms of hit rate at k=5)
score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type'])
# Get duration of score assessment
duration_assessment = time.time()-start_time_assessment
results.append([language, model_name, score, duration_assessment])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])
The resulting accuracies in terms of MRR are reported below.
BGE-M3 turns out to provide the best performances, followed on average by ML-E5-Large, E5-mistral-7b and Nomic-Embed. BGE-M3 model is not yet benchmarked on the MTEB leaderboard, and our results indicate that it could rank higher than other models. It is also interesting to note that while BGE-M3 is optimized for multilingual data, it also performs better for English than the other models.
We additionally report the processing times for each embedding model below.
The E5-mistral-7b, which is more than 10 times larger than the other models, is without surprise by far the slowest model.
Conclusion
Let us put side-by-side of the performance of the eight tested models in a single figure.
The key observations from these results are:
- Best performances were obtained by open-source models. The BGE-M3 model, developed by the Beijing Academy of Artificial Intelligence, emerged as the top performer. The model has the same context length as OpenAI models (8K), for a size of 2.2GB.
- Consistency Across OpenAI’s Range. The performances of the large (3072), small and legacy OpenAI models were very similar. Reducing the embedding size of the large model (256) however led to a degradation of performances.
- Language Sensitivity. Almost all models (except ML-E5-large) performed best on English. Significant variations in performances were observed in languages like Czech and Hungarian.
Should you therefore go for a paid OpenAI subscription, or for hosting an open-source embedding model?
OpenAI’s recent price revision has made access to their API significantly more affordable, with the cost now standing at $0.13 per million tokens. Dealing with one million queries per month (and assuming that each query involves around 1K token) would therefore cost on the order of $130. Depending on your use case, it may therefore not be cost-effective to rent and maintain your own embedding server.
Cost-effectiveness is however not the sole consideration. Other factors such as latency, privacy, and control over data processing workflows may also need to be considered. Open-source models offer the advantage of complete data control, enhancing privacy and customization. On the other hand, latency issues have been observed with OpenAI’s API, sometimes resulting in extended response times.
In conclusion, the choice between open-source models and proprietary solutions like OpenAI’s does not lend itself to a straightforward answer. Open-source embeddings present a compelling option, combining performance with greater control over data. Conversely, OpenAI’s offerings may still appeal to those prioritizing convenience, especially if privacy concerns are secondary.
Useful links
- Companion Github repository: https://github.com/Yannael/multilingual-embeddings
- Everything you wanted to know about sentence embeddings (and maybe a bit more)
- OpenAI blog announcement: New embedding models and API updates
- Embeddings: OpenAI guide
- MTEB: Massive Text Embedding Benchmark and Hugging Face MTEB leaderboard
- Text Embeddings: Comprehensive Guide
- A Practitioners Guide to Retrieval Augmented Generation (RAG)
- How to Find the Best Multilingual Embedding Model for Your RAG
Notes:
- Unless otherwise noted, all images are by the author
- The EU AI act draft is published under the Commission’s document reuse policy based on Decision 2011/833/EU, and can be re-used for commercial or non-commercial purposes.
OpenAI vs Open-Source Multilingual Embedding Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.