
Prompt and Retrieval Augmented Generation
Prompt Engineering
Prompt engineering is the first step toward talking with Generative AI models (LLMs). Essentially, it’s the process of crafting meaningful instructions to generative AI models so they can produce better results and responses. The prompts can include relevant context, explicit constraints, or specific formatting requirements to obtain the desired results.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs’ generative process. It improves the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal information. Implementing RAG in an LLM-based question-answering system has two main benefits: it ensures that the model has access to the most current, reliable facts and that users have visibility to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted. In this accelerator, we will:
- Connect to Elasticsearch and load some input data. This could be from a pdf or html page as per the user’s requirement.
- Split and index the documents in Elasticsearch for search and retrieval
- Deploy a Python function that performs the RAG steps for a given input prompt and builds a response
- Finally, a question/answer based interaction with the deployed function to accelerate the process end-to-end
Prompt Engineering Best Practices
Best practices in prompt engineering involve understanding the capabilities and limitations of the model, crafting clear and concise prompts, and iteratively testing and refining prompts based on the model’s responses.
Clarity and Specificity
Be clear about your desired outcome with specific instructions, desired format, and output length. Think of it as providing detailed directions to your child or brother, not just pointing in a general direction.
Word Choice Matters
Choose clear, direct, and unambiguous language. Avoid slang, metaphors, or overly complex vocabulary. Remember, the model interprets literally, so think of it as speaking plainly and clearly to ensure understanding.
Iteration and Experimentation
Don’t expect perfect results in one try. Be prepared to revise your prompts, change context cues, and try different examples. Think of it as fine-tuning the recipe until you get the perfect food test.
Model Awareness
Understand the capabilities and limitations of the specific model you’re using.
AI Governance
LLM models should be built with governance at the center of the place where trust is key for Generative AI projects.
How to generate automated code, test case generation, and code conversion using different prompt models.
- Generate OpenAPI
- Generate NodeJS Microservice from OpenAPI
- Generate Python Code from MS word file
- Test case generation
- Java/.NET Code Review
- Generate a code from plain text
IBM Watsonx is a GenAI platform for developers that has different Generative AI use cases available as examples where we can implement models and build generative AI use cases.
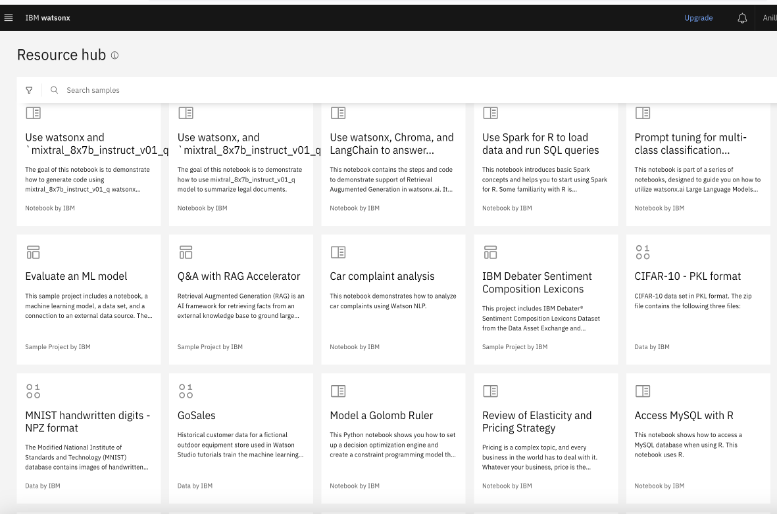
The above diagram shows the different prompt use cases that are implemented through the RAG framework and ML models. IBM Watsonx platform has the largest collection of foundation models that developers can leverage to build these models.
Below are detailed steps to create the project and build use cases using the RAG model in the IBM Watsonx project.
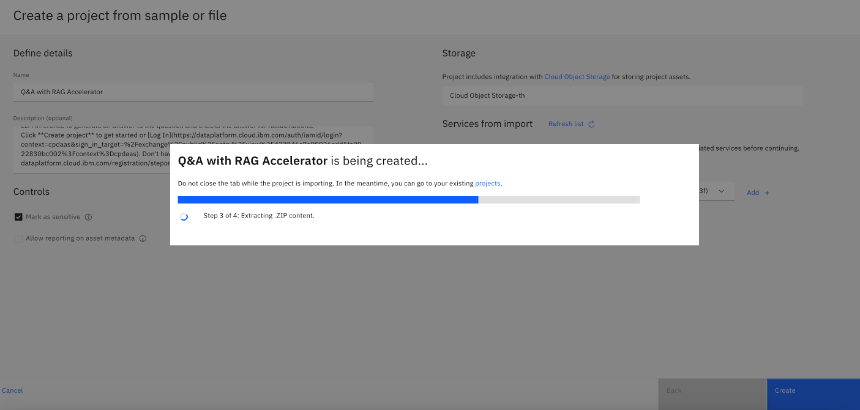
Once the Q&A RAG accelerator is completed 100% then developer can create their own use cases using these models based on their requirement.
The below snapshot shows how the Q&A asks your questions, and RAG generates the response.

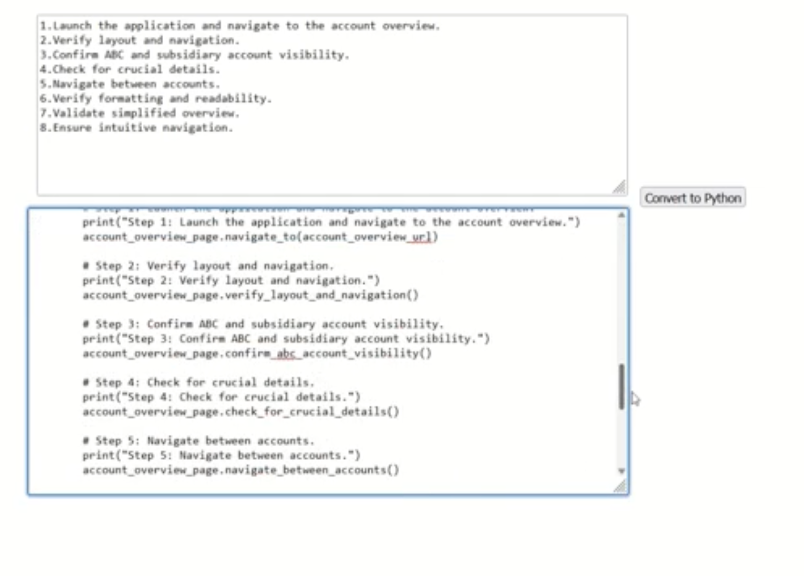
Use Case: Code Generation From Plain Text to Any Programming Language
Using the foundation model, such as llama and other available models in IBM watsonx.ai, you can build different use cases that will assist different roles within the software development life cycle. Below is an example of how plain English will be read by the model and generate a code in the target language. These use cases are generated based on input data provided by the developer and iterated based on use case requirements.
Prompt Engineering
Prompt engineering is the first step toward talking with Generative AI models (LLMs). Essentially, it’s the process of crafting meaningful instructions to generative AI models so they can produce better results and responses. The prompts can include relevant context, explicit constraints, or specific formatting requirements to obtain the desired results. 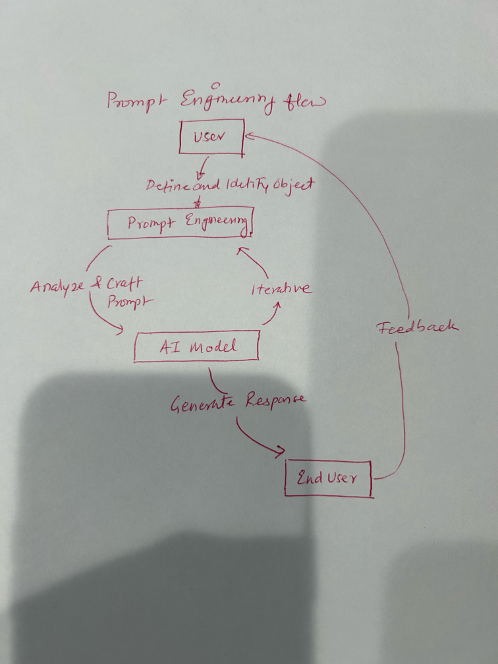
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs’ generative process. It improves the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal information. Implementing RAG in an LLM-based question-answering system has two main benefits: it ensures that the model has access to the most current, reliable facts and that users have visibility to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted. In this accelerator, we will:
- Connect to Elasticsearch and load some input data. This could be from a pdf or html page as per the user’s requirement.
- Split and index the documents in Elasticsearch for search and retrieval
- Deploy a Python function that performs the RAG steps for a given input prompt and builds a response
- Finally, a question/answer based interaction with the deployed function to accelerate the process end-to-end
Prompt Engineering Best Practices
Best practices in prompt engineering involve understanding the capabilities and limitations of the model, crafting clear and concise prompts, and iteratively testing and refining prompts based on the model’s responses.
Clarity and Specificity
Be clear about your desired outcome with specific instructions, desired format, and output length. Think of it as providing detailed directions to your child or brother, not just pointing in a general direction.
Word Choice Matters
Choose clear, direct, and unambiguous language. Avoid slang, metaphors, or overly complex vocabulary. Remember, the model interprets literally, so think of it as speaking plainly and clearly to ensure understanding.
Iteration and Experimentation
Don’t expect perfect results in one try. Be prepared to revise your prompts, change context cues, and try different examples. Think of it as fine-tuning the recipe until you get the perfect food test.
Model Awareness
Understand the capabilities and limitations of the specific model you’re using.
AI Governance
LLM models should be built with governance at the center of the place where trust is key for Generative AI projects.
How to generate automated code, test case generation, and code conversion using different prompt models.
- Generate OpenAPI
- Generate NodeJS Microservice from OpenAPI
- Generate Python Code from MS word file
- Test case generation
- Java/.NET Code Review
- Generate a code from plain text
IBM Watsonx is a GenAI platform for developers that has different Generative AI use cases available as examples where we can implement models and build generative AI use cases.
The above diagram shows the different prompt use cases that are implemented through the RAG framework and ML models. IBM Watsonx platform has the largest collection of foundation models that developers can leverage to build these models.
Below are detailed steps to create the project and build use cases using the RAG model in the IBM Watsonx project.
Once the Q&A RAG accelerator is completed 100% then developer can create their own use cases using these models based on their requirement.
The below snapshot shows how the Q&A asks your questions, and RAG generates the response.
Use Case: Code Generation From Plain Text to Any Programming Language
Using the foundation model, such as llama and other available models in IBM watsonx.ai, you can build different use cases that will assist different roles within the software development life cycle. Below is an example of how plain English will be read by the model and generate a code in the target language. These use cases are generated based on input data provided by the developer and iterated based on use case requirements.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.