
Recipe Cuisine Classification. BERT Transformer & Food-Drug Negative… | by Luís Rita | Jun, 2022
BERT Transformer & Food-Drug Negative Interactions
Several model architectures can be used to perform cuisine classification. Some of the most popular, in increasing order of complexity, are SVMs (Pouladzadeh et al., 2015), BERT (Devlin et al., 2018), RoBERTa (Liu et al., 2019) or GPT-3 (Brown et al., 2020) models.
Transformers
Unlike in Computer Vision, in Natural Language Processing (NLP), pre-trained models only became widely available recently. In part due to the scarcity of text datasets, NLP had a slow progression until the release of Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2018).
There are two pre-trained models available of BERT: base and large. Although both use the same architecture, the first contains 110 million parameters, while the second 345 million. Being able to use a pre-trained model and fine-tune it to a different task means that model overfitting can be avoided even in the absence of enough data to train a model with millions of parameters. Larger models usually have a better performance (Devlin et al., 2018).
While fine-tuning BERT, there are three possibilities (Devlin et al., 2018):
- Train all architecture
- Train some layers and freezing others
- Freeze entire network and attach extra layers to the model
Alike other neural network architectures, as bigger the amount of training data provided, as better it will perform. Thus, an important takeaway is that running BERT for a higher number of generations will lead to higher accuracy, with enough data. In terms of computational power required, it is the equivalent to several days of training using multiple state-of-the-art GPUs (Devlin et al., 2018).
Another distinctive point of BERT is its bidirectional approach. In contrast to previous efforts which looked at a text sequence either from left to right or combined left-to-right and right-to-left training (Devlin et al., 2018).
One advantage of BERT over Recurrent Neural Networks and Long Short-Term Memory Neural Networks is that it can be parallelized. This means it can be accelerated by training it in multiple GPUs. In case the input data are text sequences, it means it can take more than one token as input at a time (Devlin et al., 2018).
Two posterior implementations of transformers are Robustly Optimized BERT Pretraining Approach (RoBERTa) (Liu et al., 2019) and Generative Pre-trained Transformer 3 (GPT-3) (Brown et al., 2020) from Facebook Research and OpenAI, respectively.
BERT transformer was used to build a cuisine prediction model from lists of ingredients. This enables minimization of negative food-drug interactions of drugs being used to treat AD, at the cuisine level.
Cuisine/Drugs Negative Interactions
Because BERT models were previously trained with millions of samples, they can be repurposed by a wide range of applications with fewer fine-tunning data (Devlin et al., 2018). In this specific case, cuisine prediction.
Ingredient and recipe choices are highly influenced by geography and culture. Some recipes are more enriched in ingredients with known AD and/or COVID-19 (Laponogov et al., 2021) beating properties than others. Accounting for this variation at the cuisine level allow us to predict at the cuisine level the most likely to reduce number of negative interactions with drugs, even if not having this information for all ingredients. Food-drug interactions can lead to strong reductions on the drug bioavailability, either by direct interaction between the food molecules and a chemical component of a drug, or by the physiological response of the food intake. Some of the most sold drugs in the world are the antineoplastic and targeting nervous system disorders. Information provided in Figure 1 help us estimating recipe’s health benefits based on its cuisine (Jovanovik et al., 2015).
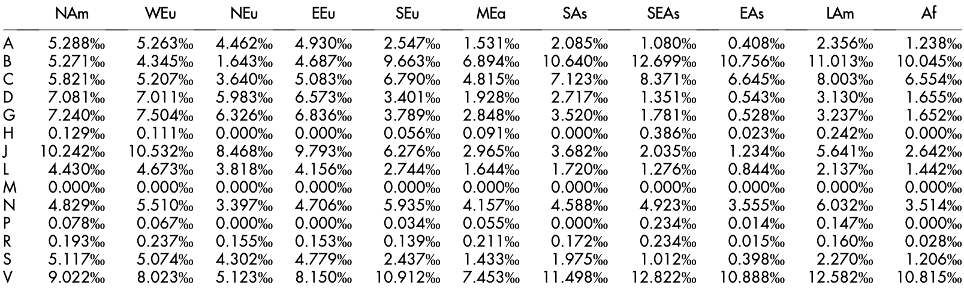
On the other side, as common to other industries, recommendation systems often classify their products in multiple categories. Food recommendation systems may benefit with cuisine classification by guiding users towards their most preferred choices (Anderson et al., 2018).
A cuisine classifier was trained, tested, and validated to predict negative interaction between neurological (AD) and anti-infective (COVID-19) drugs with cuisine identified recipes.
Using a BERT transformer, a model that predicts cuisines from lists of ingredients was trained, validated, and tested.
Kaggle and Nature dataset containing, approximately, 100000 recipes was used to train the transformer. Each recipe consists of a list of ingredients, plus the corresponding cuisine. An alphabetically ordered list of ingredients was given to the model. 80% of the dataset was used for training, 10% for validation and 10% for testing.
Before training the model, using a BERT tokenizer, a tokenization step split each recipe in 50 tokens. All parameters of the initial transformer were frozen.
Architecture chosen for the neural network includes a dropout layer, a dense layer 1 containing 768 layers of 512 nodes and a layer 2 containing 512 layers, each with 11 nodes (same as the number of cuisines).
While training, an optimizer that implements Adam algorithm with a weight decay of 1e-3 was used. Negative log likelihood loss was used as the loss function. And 40 epochs were needed for the model to converge. Training was performed in a GPU in Google Collab.
Model’s performance was assessed using precision, recall and f1-score for each of the cuisines.
Finally, cuisines with the lowest number of negative food-drug interactions with ani-infective (targeting COVID-19) and neurological (targeting AD) categories are presented.
Cuisine Classification
In Figure 2, Kaggle & Nature dataset distribution of the number of recipes based on the number of ingredients is represented.

According to previous figure, most recipes in Kaggle and Nature dataset contain between 6 and 8 ingredients. On average, each recipe has 12 ingredients. No recipe contains more than 60 ingredients.
In Figure 3, number of recipes across per cuisine in the Kaggle & Nature dataset was represented.

There are a total of 96250 recipes across 11 cuisines. The three cuisines with most recipes are North American, South European, and Latin American with 45843, 14178 and 11892 recipes, respectively.
In Table 1, cuisine classifier precision, recall and F1-score were represented.

Southern European, Latin American, North American, and East Asian present a F1-score higher than 55%.
In Figure 4 is the geographical representation of the cuisines with the lowest number of negative food-drug interactions with neurological (AD) and anti-infective drugs (COVID-19).

Latin American and Western European cuisines show the lowest number of negative interactions with neurological and anti-infective drugs, respectively.
Kaggle & Nature database contains unbalanced number of recipes distributed across cuisines. Although BERT model was trained accounting for an unbalanced dataset, this might still have affected predictive capacity of the model. Accounting only for lists of ingredients and not the respective recipe instructions might have led to poorer detection. As well as the limited size of the recipe dataset for some cuisines — Northern European. Low precision, recall and f1-scores in some cuisines might be related to the lack of unique ingredients.
Aligned with the goal of training a more accurate cuisine classifier, we will optimize architecture of the current transformer (considering RoBERTa and GPT-3 implementations) and account for cooking processes instead of ingredients alone. Using a cuisine labelled dataset with more recipes will also contribute for higher detection rates across the eleven cuisines.
Pouladzadeh, P., Shirmohammadi, S., Bakirov, A., Bulut, A., & Yassine, A. (2015). Cloud-based SVM for food categorization. Multimedia Tools and Applications, 74(14), 5243–5260. https://doi.org/10.1007/s11042-014-2116-x
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners.
Laponogov, I., Gonzalez, G., Shepherd, M., Qureshi, A., Veselkov, D., Charkoftaki, G., Vasiliou, V., Youssef, J., Mirnezami, R., Bronstein, M., & Veselkov, K. (2021). Network machine learning maps phytochemically rich “Hyperfoods” to fight COVID-19. Human Genomics, 15(1), 1. https://doi.org/10.1186/s40246-020-00297-x
Jovanovik, M., Bogojeska, A., Trajanov, D., & Kocarev, L. (2015). Inferring Cuisine — Drug Interactions Using the Linked Data Approach. Scientific Reports, 5(1), 9346. https://doi.org/10.1038/srep09346
BERT Transformer & Food-Drug Negative Interactions
Several model architectures can be used to perform cuisine classification. Some of the most popular, in increasing order of complexity, are SVMs (Pouladzadeh et al., 2015), BERT (Devlin et al., 2018), RoBERTa (Liu et al., 2019) or GPT-3 (Brown et al., 2020) models.
Transformers
Unlike in Computer Vision, in Natural Language Processing (NLP), pre-trained models only became widely available recently. In part due to the scarcity of text datasets, NLP had a slow progression until the release of Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2018).
There are two pre-trained models available of BERT: base and large. Although both use the same architecture, the first contains 110 million parameters, while the second 345 million. Being able to use a pre-trained model and fine-tune it to a different task means that model overfitting can be avoided even in the absence of enough data to train a model with millions of parameters. Larger models usually have a better performance (Devlin et al., 2018).
While fine-tuning BERT, there are three possibilities (Devlin et al., 2018):
- Train all architecture
- Train some layers and freezing others
- Freeze entire network and attach extra layers to the model
Alike other neural network architectures, as bigger the amount of training data provided, as better it will perform. Thus, an important takeaway is that running BERT for a higher number of generations will lead to higher accuracy, with enough data. In terms of computational power required, it is the equivalent to several days of training using multiple state-of-the-art GPUs (Devlin et al., 2018).
Another distinctive point of BERT is its bidirectional approach. In contrast to previous efforts which looked at a text sequence either from left to right or combined left-to-right and right-to-left training (Devlin et al., 2018).
One advantage of BERT over Recurrent Neural Networks and Long Short-Term Memory Neural Networks is that it can be parallelized. This means it can be accelerated by training it in multiple GPUs. In case the input data are text sequences, it means it can take more than one token as input at a time (Devlin et al., 2018).
Two posterior implementations of transformers are Robustly Optimized BERT Pretraining Approach (RoBERTa) (Liu et al., 2019) and Generative Pre-trained Transformer 3 (GPT-3) (Brown et al., 2020) from Facebook Research and OpenAI, respectively.
BERT transformer was used to build a cuisine prediction model from lists of ingredients. This enables minimization of negative food-drug interactions of drugs being used to treat AD, at the cuisine level.
Cuisine/Drugs Negative Interactions
Because BERT models were previously trained with millions of samples, they can be repurposed by a wide range of applications with fewer fine-tunning data (Devlin et al., 2018). In this specific case, cuisine prediction.
Ingredient and recipe choices are highly influenced by geography and culture. Some recipes are more enriched in ingredients with known AD and/or COVID-19 (Laponogov et al., 2021) beating properties than others. Accounting for this variation at the cuisine level allow us to predict at the cuisine level the most likely to reduce number of negative interactions with drugs, even if not having this information for all ingredients. Food-drug interactions can lead to strong reductions on the drug bioavailability, either by direct interaction between the food molecules and a chemical component of a drug, or by the physiological response of the food intake. Some of the most sold drugs in the world are the antineoplastic and targeting nervous system disorders. Information provided in Figure 1 help us estimating recipe’s health benefits based on its cuisine (Jovanovik et al., 2015).
On the other side, as common to other industries, recommendation systems often classify their products in multiple categories. Food recommendation systems may benefit with cuisine classification by guiding users towards their most preferred choices (Anderson et al., 2018).
A cuisine classifier was trained, tested, and validated to predict negative interaction between neurological (AD) and anti-infective (COVID-19) drugs with cuisine identified recipes.
Using a BERT transformer, a model that predicts cuisines from lists of ingredients was trained, validated, and tested.
Kaggle and Nature dataset containing, approximately, 100000 recipes was used to train the transformer. Each recipe consists of a list of ingredients, plus the corresponding cuisine. An alphabetically ordered list of ingredients was given to the model. 80% of the dataset was used for training, 10% for validation and 10% for testing.
Before training the model, using a BERT tokenizer, a tokenization step split each recipe in 50 tokens. All parameters of the initial transformer were frozen.
Architecture chosen for the neural network includes a dropout layer, a dense layer 1 containing 768 layers of 512 nodes and a layer 2 containing 512 layers, each with 11 nodes (same as the number of cuisines).
While training, an optimizer that implements Adam algorithm with a weight decay of 1e-3 was used. Negative log likelihood loss was used as the loss function. And 40 epochs were needed for the model to converge. Training was performed in a GPU in Google Collab.
Model’s performance was assessed using precision, recall and f1-score for each of the cuisines.
Finally, cuisines with the lowest number of negative food-drug interactions with ani-infective (targeting COVID-19) and neurological (targeting AD) categories are presented.
Cuisine Classification
In Figure 2, Kaggle & Nature dataset distribution of the number of recipes based on the number of ingredients is represented.
According to previous figure, most recipes in Kaggle and Nature dataset contain between 6 and 8 ingredients. On average, each recipe has 12 ingredients. No recipe contains more than 60 ingredients.
In Figure 3, number of recipes across per cuisine in the Kaggle & Nature dataset was represented.
There are a total of 96250 recipes across 11 cuisines. The three cuisines with most recipes are North American, South European, and Latin American with 45843, 14178 and 11892 recipes, respectively.
In Table 1, cuisine classifier precision, recall and F1-score were represented.
Southern European, Latin American, North American, and East Asian present a F1-score higher than 55%.
In Figure 4 is the geographical representation of the cuisines with the lowest number of negative food-drug interactions with neurological (AD) and anti-infective drugs (COVID-19).
Latin American and Western European cuisines show the lowest number of negative interactions with neurological and anti-infective drugs, respectively.
Kaggle & Nature database contains unbalanced number of recipes distributed across cuisines. Although BERT model was trained accounting for an unbalanced dataset, this might still have affected predictive capacity of the model. Accounting only for lists of ingredients and not the respective recipe instructions might have led to poorer detection. As well as the limited size of the recipe dataset for some cuisines — Northern European. Low precision, recall and f1-scores in some cuisines might be related to the lack of unique ingredients.
Aligned with the goal of training a more accurate cuisine classifier, we will optimize architecture of the current transformer (considering RoBERTa and GPT-3 implementations) and account for cooking processes instead of ingredients alone. Using a cuisine labelled dataset with more recipes will also contribute for higher detection rates across the eleven cuisines.
Pouladzadeh, P., Shirmohammadi, S., Bakirov, A., Bulut, A., & Yassine, A. (2015). Cloud-based SVM for food categorization. Multimedia Tools and Applications, 74(14), 5243–5260. https://doi.org/10.1007/s11042-014-2116-x
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners.
Laponogov, I., Gonzalez, G., Shepherd, M., Qureshi, A., Veselkov, D., Charkoftaki, G., Vasiliou, V., Youssef, J., Mirnezami, R., Bronstein, M., & Veselkov, K. (2021). Network machine learning maps phytochemically rich “Hyperfoods” to fight COVID-19. Human Genomics, 15(1), 1. https://doi.org/10.1186/s40246-020-00297-x
Jovanovik, M., Bogojeska, A., Trajanov, D., & Kocarev, L. (2015). Inferring Cuisine — Drug Interactions Using the Linked Data Approach. Scientific Reports, 5(1), 9346. https://doi.org/10.1038/srep09346
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.