
Reframing LLM ‘Chat with Data’: Introducing LLM-Assisted Data Recipes
TL;DR
In this article, we cover some of the limitations in using Large Language Models (LLMs) to ‘Chat with Data’, proposing a ‘Data Recipes’ methodology which may be an alternative in some situations. Data Recipes extends the idea of reusable code snippets but includes data and has the advantage of being programmed conversationally using an LLM. This enables the creation of a reusable Data Recipes Library — for accessing data and generating insights — which offers more transparency for LLM-generated code with a human-in-the-loop to moderate recipes as required. Cached results from recipes — sourced from SQL queries or calls to external APIs — can be refreshed asynchronously for improved response times. The proposed solution is a variation of the LLMs As Tool Makers (LATM) architecture which splits the workflow into two streams: (i) A low transaction volume / high-cost stream for creating recipes; and (ii) A high transaction volume / low-cost stream for end-users to use recipes. Finally, by having a library of recipes and associated data integration, it is possible to create a ‘Data Recipes Hub’ with the possibility of community contribution.
Using LLMs for conversational data analysis
There are some very clever patterns now that allow people to ask questions in natural language about data, where a Large Language Model (LLM) generates calls to get the data and summarizes the output for the user. Often referred to as ‘Chat with Data’, I’ve previously posted some articles illustrating this technique, for example using Open AI assistants to help people prepare for climate change. There are many more advanced examples out there it can be an amazing way to lower the technical barrier for people to gain insights from complicated data.
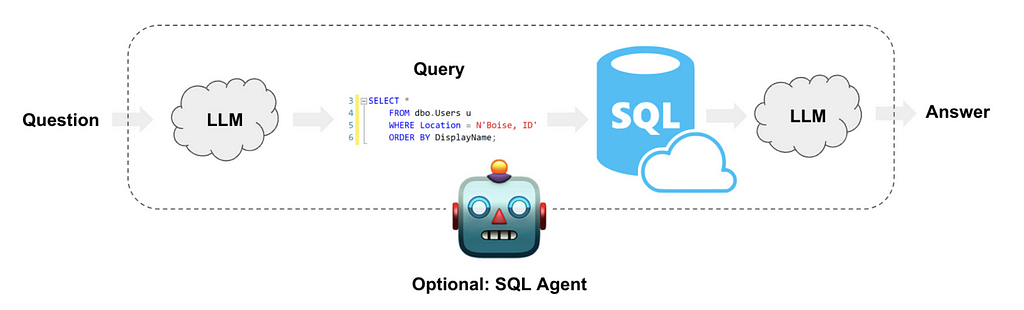

The method for accessing data typically falls into the following categories …
- Generating Database queries: The LLM converts natural language to a query language such as SQL or Cypher
- Generating API Queries: The LLM converts natural language to text used to call APIs
The application executes the LLM-provided suggestion to get the data, then usually passes the results back to the LLM to summarize.
Getting the Data Can be a Problem
It’s amazing that these techniques now exist, but in turning them into production solutions each has its advantages and disadvantages …
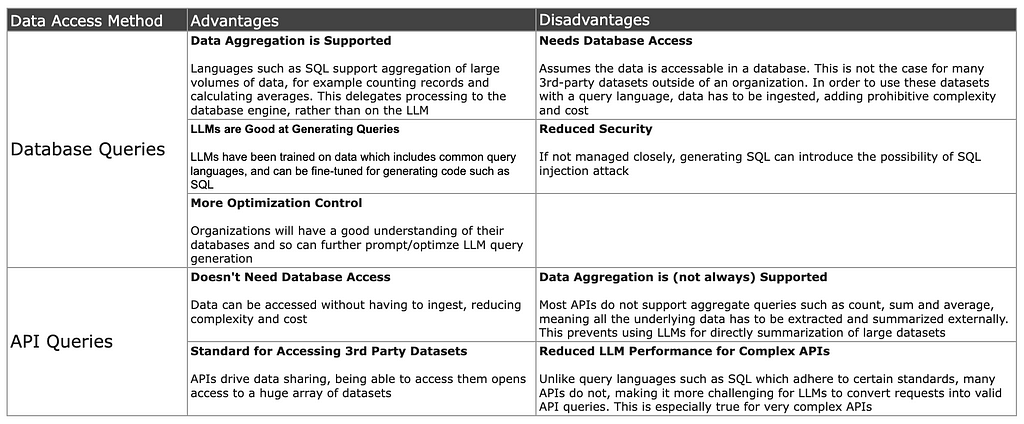
For example, generating SQL supports all the amazing things a modern database query language can do, such as aggregation across large volumes of data. However, the data might not already be in a database where SQL can be used. It could be ingested and then queried with SQL, but building pipelines like this can be complex and costly to manage.
Accessing data directly through APIs means the data doesn’t have to be in a database and opens up a huge world of publically available datasets, but there is a catch. Many APIs do not support aggregate queries like those supported by SQL, so the only option is to extract the low-level data, and then aggregate it. This puts more burden on the LLM application and can require extraction of large amounts of data.
So both techniques have limitations.
Passing Data Directly through LLMs Doesn’t Scale
On top of this, another major challenge quickly emerges when operationalizing LLMs for data analysis. Most solutions, such as Open AI Assistants can generate function calls for the caller to execute to extract data, but the output is then passed back to the LLM. It’s unclear exactly what happens internally at OpenAI, but it’s not very difficult to pass enough data to cause a token limit breach, suggesting the LLM is being used to process the raw data in a prompt. Many patterns do something along these lines, passing the output of function calling back to the LLM. This, of course, does not scale in the real world where data volumes required to answer a question can be large. It soon becomes expensive and often fails.
LLM Code Generation Can be Slow, Expensive, and Unstable
One way around this is to instead perform the analysis by having the LLM generate the code for the task. For example, if the user asks for a count of records in a dataset, have the LLM generate a snippet of Python to count records in the raw data, execute it, and pass that information back to the user. This requires far fewer tokens compared to passing in the raw data to the LLM.
It is fairly well established that LLMs are pretty good at generating code. Not yet perfect, for sure, but a lot of the world right now is using tools like GitHub Copilot for software development. It is becoming a common pattern in LLM applications to have them generate and execute code as part of solving tasks. OpenAI’s code interpreter and frameworks such as autogen and Open AI assistants take this a step further in implementing iterative processes that can even debug generated code. Also, the concept of LLMs As Tool Makers (LATM) is established (see for example Cai et al, 2023).
But here there are some challenges too.
Any LLM process generating code, especially if that process goes through an iterative cycle to debug code, can quickly incur significant costs. This is because the best models needed for high-quality code generation are often the most expensive, and to debug code a history of previous attempts is required at each step in an iterative process, burning through tokens. It’s also quite slow, depending on the number of iterations required, leading to a poor user experience.
As many of us have also found, code generation is not perfect — yet — and will on occasion fail. Agents can get themselves lost in code debugging loops and though generated code may run as expected, the results may simply be incorrect due to bugs. For most applications, a human still needs to be in the loop.
Remembering Data ‘Facts’ Has Limitations
Code generation cost and performance can be improved by implementing some sort of memory where information from previous identical requests can be retrieved, eliminating the requirement for repeat LLM calls. Solutions such as memgpt work with frameworks like autogen and offer a neat way of doing this.
Two issues arise from this. First, data is often volatile and any specific answer (ie ‘Fact’) based on data can change over time. If asked today “Which humanitarian organizations are active in the education sector in Afghanistan?”, the answer will likely be different next month. Various memory strategies could be applied to ignore memory after some time, but the most trustworthy method is to simply get the information again.
Another issue is that our application may have generated an answer for a particular situation, for example, the population of a specific country. The memory will work well if another user asks exactly the same question, but isn’t useful if they ask about a different country. Saving ‘Facts’ is only half of the story if we are hoping to be able to reuse previous LLM responses.
So What Can We Do About It?
Given all of the above, we have these key issues to solve:
- We need an approach that would work with databases and APIs
- We want to be able to support aggregate queries using API data
- We want to avoid using LLMs to summarize data and instead use code
- We want to save on costs and performance by using memory
- Memory needs to be kept up-to-date with data sources
- Memory should be generalizable, containing skills as well as facts
- Any code used needs to be reviewed by a human for accuracy and safety
Phew! That’s a lot to ask.
Introducing LLM-Assisted Data Recipes
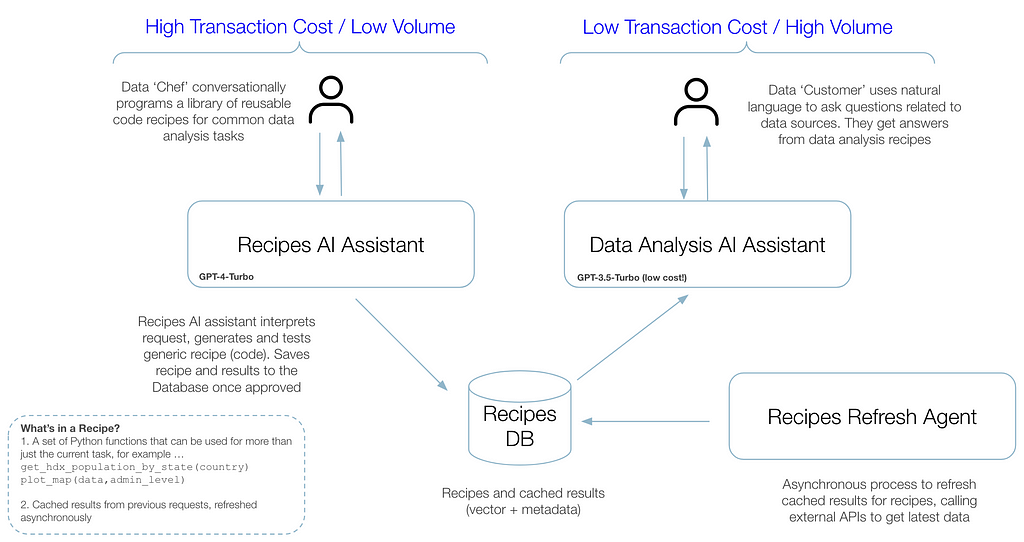
The idea is that we split the workflow into two streams to optimize costs and stability, as proposed with the LATM architecture, with some additional enhancements for managing data and memories specific to Data Recipes …
Stream 1: Recipes Assistant
This stream uses LLM agents and more powerful models to generate code snippets (recipes) via a conversational interface. The LLM is instructed with information about data sources — API specifications and Database Schema — so that the person creating recipes can more easily conversationally program new skills. Importantly, the process implements a review stage where generated code and results can be verified and modified by a human before being committed to memory. For best code generation, this stream uses more powerful models and autonomous agents, incurring higher costs per request. However, there is less traffic so costs are controlled.
Stream 2: Data Analysis Assistant
This stream is used by the wider group of end-users who are asking questions about data. The system checks memory to see if their request exists as a fact, e.g. “What’s the population of Mali?”. If not, it checks recipes to see if it has a skill to get the answer, eg ‘How to get the population of any country’. If no memory or skill exists, a request is sent to the recipes assistant queue for the recipe to be added. Ideally, the system can be pre-populated with recipes before launch, but the recipes library can actively grow over time based on user telemetry. Note that the end user stream does not generate code or queries on the fly and therefore can use less powerful LLMs, is more stable and secure, and incurs lower costs.
Asynchronous Data Refresh
To improve response times for end-users, recipes are refreshed asynchronously where feasible. The recipe memory contains code that can be run on a set schedule. Recipes can be preemptively executed to prepopulate the system, for example, retrieving the total population of all countries before end-users have requested them. Also, cases that require aggregation across large volumes of data extracted from APIs can be run out-of-hours, mitigating —albeit in part— the limitation of aggregate queries using API data.
Memory Hierarchy — remembering skills as well as facts
The above implements a hierarchy of memory to save ‘facts’ which can be promoted to more general ‘skills’. Memory retrieval promotion to recipes are achieved through a combination of semantic search and LLM reranking and transformation, for example prompting an LLM to generate a general intent and code, eg ‘Get total population for any country’ from a specific intent and code, eg ‘What’s the total population of Mali?’.
Additionally, by automatically including recipes as available functions to the code generation LLM, its reusable toolkit grows such that new recipes are efficient and call prior recipes rather than generating all code from scratch.
Some Additional Benefits of Data Recipes
By capturing data analysis requests from users and making these highly visible in the system, transparency is increased. LLM-generated code can be closely scrutinized, optimized, and adjusted, and answers produced by such code are well-understood and reproducible. This acts to reduce the uncertainty many LLM applications face around factual grounding and hallucination.
Another interesting aspect of this architecture is that it captures specific data analysis requirements and the frequency these are requested by users. This can be used to invest in more heavily utilized recipes bringing benefits to end users. For example, if a recipe for generating a humanitarian response situation report is accessed frequently, the recipe code for that report can improved proactively.
Data Recipes Hub
This approach opens up the possibility of a community-maintained library of data recipes spanning multiple domains — a Data Recipes Hub. Similar to code snippet websites that already exist, it would add the dimension of data as well as help users in creation by providing LLM-assisted conversational programming. Recipes could receive reputation points and other such social platform feedback.

Limitations of Data Recipes
As with any architecture, it may not work well in all situations. A big part of data recipes is geared towards reducing costs and risks associated with creating code on the fly and instead building a reusable library with more transparency and human-in-the-loop intervention. It will of course be the case that a user can request something new not already supported in the recipe library. We can build a queue for these requests to be processed, and by providing LLM-assisted programming expect development times to be reduced, but there will be a delay to the end-user. However, this is an acceptable trade-off in many situations where it is undesirable to let loose LLM-generated, unmoderated code.
Another thing to consider is the asynchronous refresh of recipes. Depending on the amount of data required, this may become costly. Also, this refresh might not work well in cases where the source data changes rapidly and users require this information very quickly. In such cases, the recipe would be run every time rather than the result retrieved from memory.
The refresh mechanism should help with data aggregation tasks where data is sourced from APIs, but there still looms the fact that the underlying raw data will be ingested as part of the recipe. This of course will not work well for massive data volumes, but it’s at least limiting ingestion based on user demand rather than trying to ingest an entire remote dataset.
Finally, as with all ‘Chat with Data’ applications, they are only ever going to be as good as the data they have access to. If the desired data doesn’t exist or is of low quality, then perceived performance will be poor. Additionally, common inequity and bias exist in datasets so it’s important a data audit is carried out before presenting insights to the user. This isn’t specific to Data Recipes of course, but one of the biggest challenges posed in operationalizing such techniques. Garbage in, garbage out!
Conclusions
The proposed architecture aims to address some of the challenges faced with LLM “Chat With Data”, by being …
- Transparent — Recipes are highly visible and reviewed by a human before being promoted, mitigating issues around LLM hallucination and summarization
- Deterministic — Being code, they will produce the same results each time, unlike LLM summarization of data
- Performant — Implementing a memory that captures not only facts but skills, which can be refreshed asynchronously, improves response times
- Inexpensive— By structuring the workflow into two streams, the high-volume end-user stream can use lower-cost LLMs
- Secure — The main group of end-users do not trigger the generation and execution of code or queries on the fly, and any code undergoes human assessment for safety and accuracy
I will be posting a set of follow-up blog posts detailing the technical implementation of Data Recipes as we work through user testing at DataKind.
References
Large Language Models as Tool Makers, Cai et al, 2023.
Unless otherwise noted, all images are by the author.
Please like this article if inclined and I’d be delighted if you followed me! You can find more articles here.
Reframing LLM ‘Chat with Data’: Introducing LLM-Assisted Data Recipes was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.

TL;DR
In this article, we cover some of the limitations in using Large Language Models (LLMs) to ‘Chat with Data’, proposing a ‘Data Recipes’ methodology which may be an alternative in some situations. Data Recipes extends the idea of reusable code snippets but includes data and has the advantage of being programmed conversationally using an LLM. This enables the creation of a reusable Data Recipes Library — for accessing data and generating insights — which offers more transparency for LLM-generated code with a human-in-the-loop to moderate recipes as required. Cached results from recipes — sourced from SQL queries or calls to external APIs — can be refreshed asynchronously for improved response times. The proposed solution is a variation of the LLMs As Tool Makers (LATM) architecture which splits the workflow into two streams: (i) A low transaction volume / high-cost stream for creating recipes; and (ii) A high transaction volume / low-cost stream for end-users to use recipes. Finally, by having a library of recipes and associated data integration, it is possible to create a ‘Data Recipes Hub’ with the possibility of community contribution.
Using LLMs for conversational data analysis
There are some very clever patterns now that allow people to ask questions in natural language about data, where a Large Language Model (LLM) generates calls to get the data and summarizes the output for the user. Often referred to as ‘Chat with Data’, I’ve previously posted some articles illustrating this technique, for example using Open AI assistants to help people prepare for climate change. There are many more advanced examples out there it can be an amazing way to lower the technical barrier for people to gain insights from complicated data.
The method for accessing data typically falls into the following categories …
- Generating Database queries: The LLM converts natural language to a query language such as SQL or Cypher
- Generating API Queries: The LLM converts natural language to text used to call APIs
The application executes the LLM-provided suggestion to get the data, then usually passes the results back to the LLM to summarize.
Getting the Data Can be a Problem
It’s amazing that these techniques now exist, but in turning them into production solutions each has its advantages and disadvantages …
For example, generating SQL supports all the amazing things a modern database query language can do, such as aggregation across large volumes of data. However, the data might not already be in a database where SQL can be used. It could be ingested and then queried with SQL, but building pipelines like this can be complex and costly to manage.
Accessing data directly through APIs means the data doesn’t have to be in a database and opens up a huge world of publically available datasets, but there is a catch. Many APIs do not support aggregate queries like those supported by SQL, so the only option is to extract the low-level data, and then aggregate it. This puts more burden on the LLM application and can require extraction of large amounts of data.
So both techniques have limitations.
Passing Data Directly through LLMs Doesn’t Scale
On top of this, another major challenge quickly emerges when operationalizing LLMs for data analysis. Most solutions, such as Open AI Assistants can generate function calls for the caller to execute to extract data, but the output is then passed back to the LLM. It’s unclear exactly what happens internally at OpenAI, but it’s not very difficult to pass enough data to cause a token limit breach, suggesting the LLM is being used to process the raw data in a prompt. Many patterns do something along these lines, passing the output of function calling back to the LLM. This, of course, does not scale in the real world where data volumes required to answer a question can be large. It soon becomes expensive and often fails.
LLM Code Generation Can be Slow, Expensive, and Unstable
One way around this is to instead perform the analysis by having the LLM generate the code for the task. For example, if the user asks for a count of records in a dataset, have the LLM generate a snippet of Python to count records in the raw data, execute it, and pass that information back to the user. This requires far fewer tokens compared to passing in the raw data to the LLM.
It is fairly well established that LLMs are pretty good at generating code. Not yet perfect, for sure, but a lot of the world right now is using tools like GitHub Copilot for software development. It is becoming a common pattern in LLM applications to have them generate and execute code as part of solving tasks. OpenAI’s code interpreter and frameworks such as autogen and Open AI assistants take this a step further in implementing iterative processes that can even debug generated code. Also, the concept of LLMs As Tool Makers (LATM) is established (see for example Cai et al, 2023).
But here there are some challenges too.
Any LLM process generating code, especially if that process goes through an iterative cycle to debug code, can quickly incur significant costs. This is because the best models needed for high-quality code generation are often the most expensive, and to debug code a history of previous attempts is required at each step in an iterative process, burning through tokens. It’s also quite slow, depending on the number of iterations required, leading to a poor user experience.
As many of us have also found, code generation is not perfect — yet — and will on occasion fail. Agents can get themselves lost in code debugging loops and though generated code may run as expected, the results may simply be incorrect due to bugs. For most applications, a human still needs to be in the loop.
Remembering Data ‘Facts’ Has Limitations
Code generation cost and performance can be improved by implementing some sort of memory where information from previous identical requests can be retrieved, eliminating the requirement for repeat LLM calls. Solutions such as memgpt work with frameworks like autogen and offer a neat way of doing this.
Two issues arise from this. First, data is often volatile and any specific answer (ie ‘Fact’) based on data can change over time. If asked today “Which humanitarian organizations are active in the education sector in Afghanistan?”, the answer will likely be different next month. Various memory strategies could be applied to ignore memory after some time, but the most trustworthy method is to simply get the information again.
Another issue is that our application may have generated an answer for a particular situation, for example, the population of a specific country. The memory will work well if another user asks exactly the same question, but isn’t useful if they ask about a different country. Saving ‘Facts’ is only half of the story if we are hoping to be able to reuse previous LLM responses.
So What Can We Do About It?
Given all of the above, we have these key issues to solve:
- We need an approach that would work with databases and APIs
- We want to be able to support aggregate queries using API data
- We want to avoid using LLMs to summarize data and instead use code
- We want to save on costs and performance by using memory
- Memory needs to be kept up-to-date with data sources
- Memory should be generalizable, containing skills as well as facts
- Any code used needs to be reviewed by a human for accuracy and safety
Phew! That’s a lot to ask.
Introducing LLM-Assisted Data Recipes
The idea is that we split the workflow into two streams to optimize costs and stability, as proposed with the LATM architecture, with some additional enhancements for managing data and memories specific to Data Recipes …
Stream 1: Recipes Assistant
This stream uses LLM agents and more powerful models to generate code snippets (recipes) via a conversational interface. The LLM is instructed with information about data sources — API specifications and Database Schema — so that the person creating recipes can more easily conversationally program new skills. Importantly, the process implements a review stage where generated code and results can be verified and modified by a human before being committed to memory. For best code generation, this stream uses more powerful models and autonomous agents, incurring higher costs per request. However, there is less traffic so costs are controlled.
Stream 2: Data Analysis Assistant
This stream is used by the wider group of end-users who are asking questions about data. The system checks memory to see if their request exists as a fact, e.g. “What’s the population of Mali?”. If not, it checks recipes to see if it has a skill to get the answer, eg ‘How to get the population of any country’. If no memory or skill exists, a request is sent to the recipes assistant queue for the recipe to be added. Ideally, the system can be pre-populated with recipes before launch, but the recipes library can actively grow over time based on user telemetry. Note that the end user stream does not generate code or queries on the fly and therefore can use less powerful LLMs, is more stable and secure, and incurs lower costs.
Asynchronous Data Refresh
To improve response times for end-users, recipes are refreshed asynchronously where feasible. The recipe memory contains code that can be run on a set schedule. Recipes can be preemptively executed to prepopulate the system, for example, retrieving the total population of all countries before end-users have requested them. Also, cases that require aggregation across large volumes of data extracted from APIs can be run out-of-hours, mitigating —albeit in part— the limitation of aggregate queries using API data.
Memory Hierarchy — remembering skills as well as facts
The above implements a hierarchy of memory to save ‘facts’ which can be promoted to more general ‘skills’. Memory retrieval promotion to recipes are achieved through a combination of semantic search and LLM reranking and transformation, for example prompting an LLM to generate a general intent and code, eg ‘Get total population for any country’ from a specific intent and code, eg ‘What’s the total population of Mali?’.
Additionally, by automatically including recipes as available functions to the code generation LLM, its reusable toolkit grows such that new recipes are efficient and call prior recipes rather than generating all code from scratch.
Some Additional Benefits of Data Recipes
By capturing data analysis requests from users and making these highly visible in the system, transparency is increased. LLM-generated code can be closely scrutinized, optimized, and adjusted, and answers produced by such code are well-understood and reproducible. This acts to reduce the uncertainty many LLM applications face around factual grounding and hallucination.
Another interesting aspect of this architecture is that it captures specific data analysis requirements and the frequency these are requested by users. This can be used to invest in more heavily utilized recipes bringing benefits to end users. For example, if a recipe for generating a humanitarian response situation report is accessed frequently, the recipe code for that report can improved proactively.
Data Recipes Hub
This approach opens up the possibility of a community-maintained library of data recipes spanning multiple domains — a Data Recipes Hub. Similar to code snippet websites that already exist, it would add the dimension of data as well as help users in creation by providing LLM-assisted conversational programming. Recipes could receive reputation points and other such social platform feedback.
Limitations of Data Recipes
As with any architecture, it may not work well in all situations. A big part of data recipes is geared towards reducing costs and risks associated with creating code on the fly and instead building a reusable library with more transparency and human-in-the-loop intervention. It will of course be the case that a user can request something new not already supported in the recipe library. We can build a queue for these requests to be processed, and by providing LLM-assisted programming expect development times to be reduced, but there will be a delay to the end-user. However, this is an acceptable trade-off in many situations where it is undesirable to let loose LLM-generated, unmoderated code.
Another thing to consider is the asynchronous refresh of recipes. Depending on the amount of data required, this may become costly. Also, this refresh might not work well in cases where the source data changes rapidly and users require this information very quickly. In such cases, the recipe would be run every time rather than the result retrieved from memory.
The refresh mechanism should help with data aggregation tasks where data is sourced from APIs, but there still looms the fact that the underlying raw data will be ingested as part of the recipe. This of course will not work well for massive data volumes, but it’s at least limiting ingestion based on user demand rather than trying to ingest an entire remote dataset.
Finally, as with all ‘Chat with Data’ applications, they are only ever going to be as good as the data they have access to. If the desired data doesn’t exist or is of low quality, then perceived performance will be poor. Additionally, common inequity and bias exist in datasets so it’s important a data audit is carried out before presenting insights to the user. This isn’t specific to Data Recipes of course, but one of the biggest challenges posed in operationalizing such techniques. Garbage in, garbage out!
Conclusions
The proposed architecture aims to address some of the challenges faced with LLM “Chat With Data”, by being …
- Transparent — Recipes are highly visible and reviewed by a human before being promoted, mitigating issues around LLM hallucination and summarization
- Deterministic — Being code, they will produce the same results each time, unlike LLM summarization of data
- Performant — Implementing a memory that captures not only facts but skills, which can be refreshed asynchronously, improves response times
- Inexpensive— By structuring the workflow into two streams, the high-volume end-user stream can use lower-cost LLMs
- Secure — The main group of end-users do not trigger the generation and execution of code or queries on the fly, and any code undergoes human assessment for safety and accuracy
I will be posting a set of follow-up blog posts detailing the technical implementation of Data Recipes as we work through user testing at DataKind.
References
Large Language Models as Tool Makers, Cai et al, 2023.
Unless otherwise noted, all images are by the author.
Please like this article if inclined and I’d be delighted if you followed me! You can find more articles here.
Reframing LLM ‘Chat with Data’: Introducing LLM-Assisted Data Recipes was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.