
Retrieval Augmented Generation (RAG) Inference Engines with LangChain on CPUs
Exploring scale, fidelity, and latency in AI applications with RAG
While Retrieval Augmented Generation (RAG) is extensively covered, particularly in its application to chat-based LLMs, in this article we aim to view it from a different perspective and analyze its prowess as a powerful operational tool. We will also provide a useful hands-on example to get practical experience with RAG-based applications. By the end of the article, you’ll develop a unique vantage point on RAG — understanding its role and potential in scalable inference within production-scale LLM deployments.
But first, let’s refresh our understanding of inference
Inference is the process that transforms data into predictions. This component of the ML lifecycle is often cradled by data pipelines that manage pre-processing and post-processing tasks. Let’s evaluate a practical example, consider a music streaming service’s recommendation system, as shown in Figure 1. When a user visits the streaming platform, an intelligently curated list of top 10 songs is presented in the application’s interface. The recommendation system responsible for this list relies on a trained model and robust data pipelines to ensure a high-quality result.

The pre-processing stage, represented by yellow boxes in our diagram, is crucial for ensuring that the model’s prediction closely aligns with the user’s unique taste. Starting with the last 250 songs played by the user, the pipeline processes the data and generates a set of contextual features before passing it to a trained model for inference. The inference step predicts what this user might like and yields an output that passes to a post-processing stage (illustrated in orange). In this final step, the model’s top recommendations are enriched with additional metadata — album art, song titles, artist names, and their ranking. This information is then displayed on the user’s interface for consumption.
In the workflow described above, it’s clear how proximal the inference step is to the user in the application topology. Unlike other AI lifecycle components like data collection and model optimization, which tend to operate in the background, the inference engine is in the frontline, interacting closely with the user interface (UI) and user experience (UX).

We can use the diagram above (Figure 2) to illustrate the proximity of various components of the AI lifecycle to the user. While many components like data collection and annotation sit “behind the scenes,” the inference engine stands as a critical bridge between the AI’s internal processes and what end-users are exposed to. It’s not just another backend mechanism, it is a core part of the user’s tangible experience with the application.
Given this critical role in shaping user experience, it is essential that the inference engine — encompassing the inference process and its peripheral components like pre/post-processing, API management, and compute management — operates flawlessly. To establish boundary conditions for inference engine quality, I introduce the “Inference Quality (IQ) Triangle,” depicted in Figure 3. This qualitative figure highlights three pivotal aspects to focus on when enhancing the performance of an inference workload:
- Latency: if the inference engine takes less time to yield a response, it reduces overhead for the application and leads to a better user experience.
- Fidelity: inference needs to provide answers that users can trust and feel confident in. This includes but is not limited to ensuring high accuracy of responses and reducing hallucinations.
- Scalability: As the load on the AI system fluctuates, the ability to scale infrastructure is key to optimizing cost and enabling the right-sizing of computing resources.

As we progress through the article, we will reference the IQ Triangle to dive deeply into how these three components — latency, fidelity, and scale — align well with the RAG workload.
Brief Introduction to Retrieval Augmented Generation
Retrieval augmented generation, also known as RAG, is a technique introduced initially by Piktus et al. (2021) in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks and has since been adapted in various frameworks and applications. RAG falls under the category of in-context learning techniques, which focus on providing additional knowledge to pre-trained models in an effort to augment the quality of their responses.
The hallmark of RAG is in the intelligent retrieval of additional information from relevant data sources, typically vector databases using algorithms like similarity search. The retrieved data is combined with the user’s query, enriching the input provided to the generative model. A standard RAG workflow is depicted in Figure 4.

To grasp RAG’s real value, let’s consider a practical scenario: a financial analyst at a major corporation (Figure 5) is grappling with the task of building a quarterly earnings report. Executing this task in a traditional fashion would be a time-intensive endeavor. LLM-based applications offer significant efficiency improvements, but there’s a catch — the need for up-to-date, proprietary information, which isn’t accessible at the time of training foundational open-source models. This could be partially resolved by fine-tuning but the rapid pace of business operations means this process would require continuous fine-tuning to keep models current.
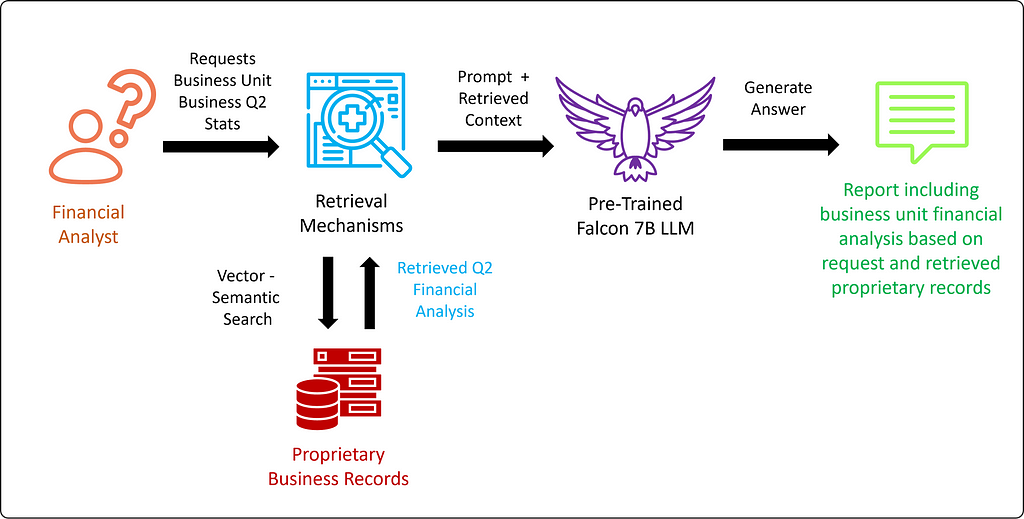
RAG tackles these challenges by retrieving relevant, live data, allowing models to be dynamically updated with the latest information. This puts pressure on the quality of the underlying database, but at least data management is more empirical and predictable than LLM hallucinations and neural network extrapolation. As an additional bonus, this approach safeguards sensitive data within the organization’s data infrastructure.
Many applied AI engineers agree that there should be a shift toward a hybrid strategy focusing on periodic fine-tuning and robust RAG pipelines. In practice, this strategy experiences improved alignment with domain-specific tasks and increases model relevance in applications with fast-evolving data environments.
In the hands-on example, you can toggle RAG on/off to see the impacts of pre-trained model response quality with and without the context provided by the intelligent retrieval mechanisms. See Figure 10.
Operational RAG Systems in Support of Quality Inference Engines
Now that we have a foundational understanding of RAG and its role in LLM-based applications, we will focus on implementing these systems’ practical and operational aspects.
As promised, let’s revisit the IQ Triangle (Figure 3) which underscores three vital aspects of high-quality operational inference engines. We will analyze the opportunity to address all three of these aspects — scalability, latency, and fidelity — using the stack illustrated below (Figure 6), which focuses on an inference engine composed of RAG pipelines and heavily optimized models running on CPUs.

RAG’s Architectural Benefits
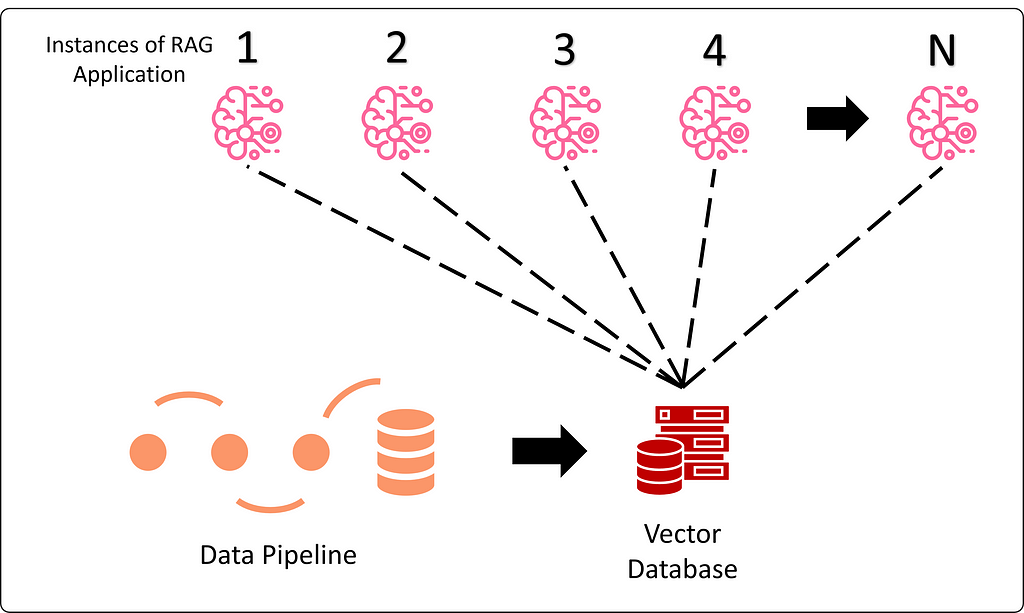
RAG-based applications bring significant architectural benefits. From a scalability perspective, all data-centric components of the pipeline converge on a single (or few) vector databases (Figure 7), allowing the fresh data benefits of RAG to scale well with increasing/decreasing user requests. This unified approach can significantly improve the fidelity of responses to domain-specific tasks while greatly simplifying data governance.
Optimized Models: Efficiency and Performance
Models can achieve smaller computational and environmental footprints through model compression and parameter-efficient fine-tuning techniques. While fine-tuning can help tailor models to specific tasks, enhancing their predictive accuracy (fidelity), compression methods like quantization can shrink model sizes, significantly improving inference latency. These lean and tuned models are easier to deploy in the data center and enable AI applications at the edge, opening the door for various innovative use cases.

CPUs in Support of RAG
Regarding workflows involving complex logic, like RAG, CPUs stand out for their ubiquity and cost-efficiency. This enables improved scale since almost any organization can access enterprise-grade CPUs in the cloud, unlike specialized accelerators, which are harder to come by.
Modern CPUs also come equipped with low-level optimizations — take, for instance, Intel Advanced Matrix Extensions in their 4th Generation Xeon Processors — which improve memory management and matrix operations in deep learning training and inference phases. Their support for lower precision data types (such as bf16 and int8) makes them well-suited for achieving low latency during inference.
Furthermore, the compatibility of CPUs with the multiple components of a RAG pipeline (Figure 9), including vector databases and intelligent search (for example, similarity search), streamlines infrastructure management, making scaled deployment more straightforward and efficient.

Before moving on, I must disclose my affiliation with Intel and the product used below. As a Senior AI Engineer at Intel, the following hands-on sample is run on the Intel Developer Cloud (IDC). We will use IDC as a free and convenient way to access Compute to get practical experience with the concepts described in this article.
Hands-On Example: Implementing RAG with LangChain on the Intel Developer Cloud (IDC)
To follow along with the following hands-on example, create a free account on the Intel Developer Cloud and navigate to the “Training and Workshops” page. Under the Gen AI Essentials section, select Retrieval Augmented Generation (RAG) with LangChain option. Follow the instructions on the webpage to launch a JupyterLab window and automatically load the notebook with all of the sample code.
The notebook includes detailed docstrings and descriptions of the code. This article will discuss the high-level mechanics while providing context for specific functions.
Setting up Dependencies
We start by installing all of the required packages into the base environment. You’re welcome to create your conda environment, but this is a quick and easy way to start.
import sys
import os
!{sys.executable} -m pip install langchain==0.0.335 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install pygpt4all==1.1.0 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install gpt4all==1.0.12 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install transformers==4.35.1 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install datasets==2.14.6 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install tiktoken==0.4.0 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install chromadb==0.4.15 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install sentence_transformers==2.2.2 --no-warn-script-location > /dev/null
These commands will install all the necessary packages into your base environment.
The Data and Model
We will be using a quantized version of Falcon 7B (gpt4all-falcon-q4_0) from the GPT4All project. You can learn more about this model on the GPT4ALL page in the “Model Explorer” section. The model has been stored on disk to simplify the model access process.
The following logic downloads the available datasets from a Hugging Face project called FunDialogues. The selected data will be passed through an embedding model and placed in our vector database in a subsequent step.
def download_dataset(self, dataset):
"""
Downloads the specified dataset and saves it to the data path.
Parameters
----------
dataset : str
The name of the dataset to be downloaded.
"""
self.data_path = dataset + '_dialogues.txt'
if not os.path.isfile(self.data_path):
datasets = {"robot maintenance": "FunDialogues/customer-service-robot-support",
"basketball coach": "FunDialogues/sports-basketball-coach",
"physics professor": "FunDialogues/academia-physics-office-hours",
"grocery cashier" : "FunDialogues/customer-service-grocery-cashier"}
# Download the dialogue from hugging face
dataset = load_dataset(f"{datasets[dataset]}")
# Convert the dataset to a pandas dataframe
dialogues = dataset['train']
df = pd.DataFrame(dialogues, columns=['id', 'description', 'dialogue'])
# Print the first 5 rows of the dataframe
df.head()
# only keep the dialogue column
dialog_df = df['dialogue']
# save the data to txt file
dialog_df.to_csv(self.data_path, sep=' ', index=False)
else:
print('data already exists in path.')
In the code snippet above, you can select from 4 different synthetic datasets:
- Robot Maintenance: conversations between a technician and a customer support agent while troubleshooting a robot arm.
- Basketball Coach: conversations between basketball coaches and players during a game.
- Physics Professor: conversations between students and physics professor during office hours.
- Grocery Cashier: conversations between a grocery store cashier and customers
Configuring the Model
The GPT4ALL extension in the LangChain API takes care of loading the model into memory and establishing a variety of parameters, such as:
- model_path: This line specifies the file path for a pre-trained model.
- n_threads: Sets the number of threads to be used, which might influence parallel processing or inference speed. This is especially relevant for multi-core systems.
- max_tokens: Limits the number of tokens (words or subwords) for the input or output sequences, ensuring that the data fed into or produced by the model does not exceed this length.
- repeat_penalty: This parameter possibly penalizes repetitive content in the model’s output. A value greater than 1.0 prevents the model from generating repeated sequences.
- n_batch: Specifies the batch size for processing data. This can help optimize processing speed and memory usage.
- top_k: Defines the “top-k” sampling strategy during the model’s generation. When generating text, the model will consider only the top k most probable next tokens.
def load_model(self, n_threads, max_tokens, repeat_penalty, n_batch, top_k, temp):
"""
Loads the model with specified parameters for parallel processing.
Parameters
----------
n_threads : int
The number of threads for parallel processing.
max_tokens : int
The maximum number of tokens for model prediction.
repeat_penalty : float
The penalty for repeated tokens in generation.
n_batch : int
The number of batches for processing.
top_k : int
The number of top k tokens to be considered in sampling.
"""
# Callbacks support token-wise streaming
callbacks = [StreamingStdOutCallbackHandler()]
# Verbose is required to pass to the callback manager
self.llm = GPT4All(model=self.model_path, callbacks=callbacks, verbose=False,
n_threads=n_threads, n_predict=max_tokens, repeat_penalty=repeat_penalty,
n_batch=n_batch, top_k=top_k, temp=temp)
Building the Vector Database with ChromaDB
The Chroma vector database is an integral part of our RAG setup, where we store and manage our data efficiently. Here’s how we build it:
def build_vectordb(self, chunk_size, overlap):
"""
Builds a vector database from the dataset for retrieval purposes.
Parameters
----------
chunk_size : int
The size of text chunks for vectorization.
overlap : int
The overlap size between chunks.
"""
loader = TextLoader(self.data_path)
# Text Splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)
# Embed the document and store into chroma DB
self.index = VectorstoreIndexCreator(embedding= HuggingFaceEmbeddings(), text_splitter=text_splitter).from_loaders([loader])
Executing the Retrieval Mechanism
Upon receiving a user’s query, we use similarity search to search our vector DB for similar data. Once a k number of matching results are found, they are retrieved and used to add the context to the user’s query. We use the PromptTemplate function to build a template and embed the user’s query alongside the retrieved context. Once the template has been populated, we move on to the inference component.
def retrieval_mechanism(self, user_input, top_k=1, context_verbosity = False, rag_off= False):
"""
Retrieves relevant document snippets based on the user's query.
Parameters
----------
user_input : str
The user's input or query.
top_k : int, optional
The number of top results to return, by default 1.
context_verbosity : bool, optional
If True, additional context information is printed, by default False.
rag_off : bool, optional
If True, disables the retrieval-augmented generation, by default False.
"""
self.user_input = user_input
self.context_verbosity = context_verbosity
# perform a similarity search and retrieve the context from our documents
results = self.index.vectorstore.similarity_search(self.user_input, k=top_k)
# join all context information into one string
context = "\n".join([document.page_content for document in results])
if self.context_verbosity:
print(f"Retrieving information related to your question...")
print(f"Found this content which is most similar to your question: {context}")
if rag_off:
template = """Question: {question}
Answer: This is the response: """
self.prompt = PromptTemplate(template=template, input_variables=["question"])
else:
template = """ Don't just repeat the following context, use it in combination with your knowledge to improve your answer to the question:{context}
Question: {question}
"""
self.prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
The LangChain LLMChain utility to execute inference based on the query passed by the user and the configured template. The result is returned to the user.
def inference(self):
"""
Performs inference to generate a response based on the user's query.
Returns
-------
str
The generated response.
"""
if self.context_verbosity:
print(f"Your Query: {self.prompt}")
llm_chain = LLMChain(prompt=self.prompt, llm=self.llm)
print("Processing the information with gpt4all...\n")
response = llm_chain.run(self.user_input)
return response
Interactive Experimentation
To help you get started quickly, the notebook includes integrated ipywidget components. You must run all the cells in the notebook to enable these components. We encourage you to adjust the parameters and evaluate the impact on the latency and fidelity of the system’s response. Remember, this is just a starting point and a basic demonstration of RAG’s capabilities.

Summary and Discussion
No one wants to interact with slow, unstable chatbots that respond with bogus information. There are a plethora of technical stack combinations to help developers avoid building systems that yield terrible user experiences. In this article, we have interpreted the importance of inference engine quality to the user experience from the perspective of a stack that enables scale, fidelity, and latency benefits. The combination of RAG, CPUs, and model optimization techniques checks all corners of the IQ Triangle (Figure 3), aligning well with the needs of operational LLM-based AI chat applications.
A few exciting things to try would be:
- Edit the prompt template found in the retrieval_mechanism method to engineer better prompts in tandem with the retrieved context.
- Adjust the various model and RAG-specific parameters and evaluate the impact on inference latency and response quality.
- Add new datasets that are meaningful to your domain and test the viability of using RAG to build your AI chat-based applications.
- This example’s model (gpt4all-falcon-q4_0) is not optimized for Xeon processors. Explore using models that are optimized for CPU platforms and evaluate the inference latency benefits.
Thank you for reading! Don’t forget to follow my profile for more articles like this!
Retrieval Augmented Generation (RAG) Inference Engines with LangChain on CPUs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.

Exploring scale, fidelity, and latency in AI applications with RAG
While Retrieval Augmented Generation (RAG) is extensively covered, particularly in its application to chat-based LLMs, in this article we aim to view it from a different perspective and analyze its prowess as a powerful operational tool. We will also provide a useful hands-on example to get practical experience with RAG-based applications. By the end of the article, you’ll develop a unique vantage point on RAG — understanding its role and potential in scalable inference within production-scale LLM deployments.
But first, let’s refresh our understanding of inference
Inference is the process that transforms data into predictions. This component of the ML lifecycle is often cradled by data pipelines that manage pre-processing and post-processing tasks. Let’s evaluate a practical example, consider a music streaming service’s recommendation system, as shown in Figure 1. When a user visits the streaming platform, an intelligently curated list of top 10 songs is presented in the application’s interface. The recommendation system responsible for this list relies on a trained model and robust data pipelines to ensure a high-quality result.
The pre-processing stage, represented by yellow boxes in our diagram, is crucial for ensuring that the model’s prediction closely aligns with the user’s unique taste. Starting with the last 250 songs played by the user, the pipeline processes the data and generates a set of contextual features before passing it to a trained model for inference. The inference step predicts what this user might like and yields an output that passes to a post-processing stage (illustrated in orange). In this final step, the model’s top recommendations are enriched with additional metadata — album art, song titles, artist names, and their ranking. This information is then displayed on the user’s interface for consumption.
In the workflow described above, it’s clear how proximal the inference step is to the user in the application topology. Unlike other AI lifecycle components like data collection and model optimization, which tend to operate in the background, the inference engine is in the frontline, interacting closely with the user interface (UI) and user experience (UX).
We can use the diagram above (Figure 2) to illustrate the proximity of various components of the AI lifecycle to the user. While many components like data collection and annotation sit “behind the scenes,” the inference engine stands as a critical bridge between the AI’s internal processes and what end-users are exposed to. It’s not just another backend mechanism, it is a core part of the user’s tangible experience with the application.
Given this critical role in shaping user experience, it is essential that the inference engine — encompassing the inference process and its peripheral components like pre/post-processing, API management, and compute management — operates flawlessly. To establish boundary conditions for inference engine quality, I introduce the “Inference Quality (IQ) Triangle,” depicted in Figure 3. This qualitative figure highlights three pivotal aspects to focus on when enhancing the performance of an inference workload:
- Latency: if the inference engine takes less time to yield a response, it reduces overhead for the application and leads to a better user experience.
- Fidelity: inference needs to provide answers that users can trust and feel confident in. This includes but is not limited to ensuring high accuracy of responses and reducing hallucinations.
- Scalability: As the load on the AI system fluctuates, the ability to scale infrastructure is key to optimizing cost and enabling the right-sizing of computing resources.
As we progress through the article, we will reference the IQ Triangle to dive deeply into how these three components — latency, fidelity, and scale — align well with the RAG workload.
Brief Introduction to Retrieval Augmented Generation
Retrieval augmented generation, also known as RAG, is a technique introduced initially by Piktus et al. (2021) in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks and has since been adapted in various frameworks and applications. RAG falls under the category of in-context learning techniques, which focus on providing additional knowledge to pre-trained models in an effort to augment the quality of their responses.
The hallmark of RAG is in the intelligent retrieval of additional information from relevant data sources, typically vector databases using algorithms like similarity search. The retrieved data is combined with the user’s query, enriching the input provided to the generative model. A standard RAG workflow is depicted in Figure 4.
To grasp RAG’s real value, let’s consider a practical scenario: a financial analyst at a major corporation (Figure 5) is grappling with the task of building a quarterly earnings report. Executing this task in a traditional fashion would be a time-intensive endeavor. LLM-based applications offer significant efficiency improvements, but there’s a catch — the need for up-to-date, proprietary information, which isn’t accessible at the time of training foundational open-source models. This could be partially resolved by fine-tuning but the rapid pace of business operations means this process would require continuous fine-tuning to keep models current.
RAG tackles these challenges by retrieving relevant, live data, allowing models to be dynamically updated with the latest information. This puts pressure on the quality of the underlying database, but at least data management is more empirical and predictable than LLM hallucinations and neural network extrapolation. As an additional bonus, this approach safeguards sensitive data within the organization’s data infrastructure.
Many applied AI engineers agree that there should be a shift toward a hybrid strategy focusing on periodic fine-tuning and robust RAG pipelines. In practice, this strategy experiences improved alignment with domain-specific tasks and increases model relevance in applications with fast-evolving data environments.
In the hands-on example, you can toggle RAG on/off to see the impacts of pre-trained model response quality with and without the context provided by the intelligent retrieval mechanisms. See Figure 10.
Operational RAG Systems in Support of Quality Inference Engines
Now that we have a foundational understanding of RAG and its role in LLM-based applications, we will focus on implementing these systems’ practical and operational aspects.
As promised, let’s revisit the IQ Triangle (Figure 3) which underscores three vital aspects of high-quality operational inference engines. We will analyze the opportunity to address all three of these aspects — scalability, latency, and fidelity — using the stack illustrated below (Figure 6), which focuses on an inference engine composed of RAG pipelines and heavily optimized models running on CPUs.
RAG’s Architectural Benefits
RAG-based applications bring significant architectural benefits. From a scalability perspective, all data-centric components of the pipeline converge on a single (or few) vector databases (Figure 7), allowing the fresh data benefits of RAG to scale well with increasing/decreasing user requests. This unified approach can significantly improve the fidelity of responses to domain-specific tasks while greatly simplifying data governance.
Optimized Models: Efficiency and Performance
Models can achieve smaller computational and environmental footprints through model compression and parameter-efficient fine-tuning techniques. While fine-tuning can help tailor models to specific tasks, enhancing their predictive accuracy (fidelity), compression methods like quantization can shrink model sizes, significantly improving inference latency. These lean and tuned models are easier to deploy in the data center and enable AI applications at the edge, opening the door for various innovative use cases.
CPUs in Support of RAG
Regarding workflows involving complex logic, like RAG, CPUs stand out for their ubiquity and cost-efficiency. This enables improved scale since almost any organization can access enterprise-grade CPUs in the cloud, unlike specialized accelerators, which are harder to come by.
Modern CPUs also come equipped with low-level optimizations — take, for instance, Intel Advanced Matrix Extensions in their 4th Generation Xeon Processors — which improve memory management and matrix operations in deep learning training and inference phases. Their support for lower precision data types (such as bf16 and int8) makes them well-suited for achieving low latency during inference.
Furthermore, the compatibility of CPUs with the multiple components of a RAG pipeline (Figure 9), including vector databases and intelligent search (for example, similarity search), streamlines infrastructure management, making scaled deployment more straightforward and efficient.
Before moving on, I must disclose my affiliation with Intel and the product used below. As a Senior AI Engineer at Intel, the following hands-on sample is run on the Intel Developer Cloud (IDC). We will use IDC as a free and convenient way to access Compute to get practical experience with the concepts described in this article.
Hands-On Example: Implementing RAG with LangChain on the Intel Developer Cloud (IDC)
To follow along with the following hands-on example, create a free account on the Intel Developer Cloud and navigate to the “Training and Workshops” page. Under the Gen AI Essentials section, select Retrieval Augmented Generation (RAG) with LangChain option. Follow the instructions on the webpage to launch a JupyterLab window and automatically load the notebook with all of the sample code.
The notebook includes detailed docstrings and descriptions of the code. This article will discuss the high-level mechanics while providing context for specific functions.
Setting up Dependencies
We start by installing all of the required packages into the base environment. You’re welcome to create your conda environment, but this is a quick and easy way to start.
import sys
import os
!{sys.executable} -m pip install langchain==0.0.335 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install pygpt4all==1.1.0 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install gpt4all==1.0.12 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install transformers==4.35.1 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install datasets==2.14.6 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install tiktoken==0.4.0 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install chromadb==0.4.15 --no-warn-script-location > /dev/null
!{sys.executable} -m pip install sentence_transformers==2.2.2 --no-warn-script-location > /dev/null
These commands will install all the necessary packages into your base environment.
The Data and Model
We will be using a quantized version of Falcon 7B (gpt4all-falcon-q4_0) from the GPT4All project. You can learn more about this model on the GPT4ALL page in the “Model Explorer” section. The model has been stored on disk to simplify the model access process.
The following logic downloads the available datasets from a Hugging Face project called FunDialogues. The selected data will be passed through an embedding model and placed in our vector database in a subsequent step.
def download_dataset(self, dataset):
"""
Downloads the specified dataset and saves it to the data path.
Parameters
----------
dataset : str
The name of the dataset to be downloaded.
"""
self.data_path = dataset + '_dialogues.txt'
if not os.path.isfile(self.data_path):
datasets = {"robot maintenance": "FunDialogues/customer-service-robot-support",
"basketball coach": "FunDialogues/sports-basketball-coach",
"physics professor": "FunDialogues/academia-physics-office-hours",
"grocery cashier" : "FunDialogues/customer-service-grocery-cashier"}
# Download the dialogue from hugging face
dataset = load_dataset(f"{datasets[dataset]}")
# Convert the dataset to a pandas dataframe
dialogues = dataset['train']
df = pd.DataFrame(dialogues, columns=['id', 'description', 'dialogue'])
# Print the first 5 rows of the dataframe
df.head()
# only keep the dialogue column
dialog_df = df['dialogue']
# save the data to txt file
dialog_df.to_csv(self.data_path, sep=' ', index=False)
else:
print('data already exists in path.')
In the code snippet above, you can select from 4 different synthetic datasets:
- Robot Maintenance: conversations between a technician and a customer support agent while troubleshooting a robot arm.
- Basketball Coach: conversations between basketball coaches and players during a game.
- Physics Professor: conversations between students and physics professor during office hours.
- Grocery Cashier: conversations between a grocery store cashier and customers
Configuring the Model
The GPT4ALL extension in the LangChain API takes care of loading the model into memory and establishing a variety of parameters, such as:
- model_path: This line specifies the file path for a pre-trained model.
- n_threads: Sets the number of threads to be used, which might influence parallel processing or inference speed. This is especially relevant for multi-core systems.
- max_tokens: Limits the number of tokens (words or subwords) for the input or output sequences, ensuring that the data fed into or produced by the model does not exceed this length.
- repeat_penalty: This parameter possibly penalizes repetitive content in the model’s output. A value greater than 1.0 prevents the model from generating repeated sequences.
- n_batch: Specifies the batch size for processing data. This can help optimize processing speed and memory usage.
- top_k: Defines the “top-k” sampling strategy during the model’s generation. When generating text, the model will consider only the top k most probable next tokens.
def load_model(self, n_threads, max_tokens, repeat_penalty, n_batch, top_k, temp):
"""
Loads the model with specified parameters for parallel processing.
Parameters
----------
n_threads : int
The number of threads for parallel processing.
max_tokens : int
The maximum number of tokens for model prediction.
repeat_penalty : float
The penalty for repeated tokens in generation.
n_batch : int
The number of batches for processing.
top_k : int
The number of top k tokens to be considered in sampling.
"""
# Callbacks support token-wise streaming
callbacks = [StreamingStdOutCallbackHandler()]
# Verbose is required to pass to the callback manager
self.llm = GPT4All(model=self.model_path, callbacks=callbacks, verbose=False,
n_threads=n_threads, n_predict=max_tokens, repeat_penalty=repeat_penalty,
n_batch=n_batch, top_k=top_k, temp=temp)
Building the Vector Database with ChromaDB
The Chroma vector database is an integral part of our RAG setup, where we store and manage our data efficiently. Here’s how we build it:
def build_vectordb(self, chunk_size, overlap):
"""
Builds a vector database from the dataset for retrieval purposes.
Parameters
----------
chunk_size : int
The size of text chunks for vectorization.
overlap : int
The overlap size between chunks.
"""
loader = TextLoader(self.data_path)
# Text Splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap)
# Embed the document and store into chroma DB
self.index = VectorstoreIndexCreator(embedding= HuggingFaceEmbeddings(), text_splitter=text_splitter).from_loaders([loader])
Executing the Retrieval Mechanism
Upon receiving a user’s query, we use similarity search to search our vector DB for similar data. Once a k number of matching results are found, they are retrieved and used to add the context to the user’s query. We use the PromptTemplate function to build a template and embed the user’s query alongside the retrieved context. Once the template has been populated, we move on to the inference component.
def retrieval_mechanism(self, user_input, top_k=1, context_verbosity = False, rag_off= False):
"""
Retrieves relevant document snippets based on the user's query.
Parameters
----------
user_input : str
The user's input or query.
top_k : int, optional
The number of top results to return, by default 1.
context_verbosity : bool, optional
If True, additional context information is printed, by default False.
rag_off : bool, optional
If True, disables the retrieval-augmented generation, by default False.
"""
self.user_input = user_input
self.context_verbosity = context_verbosity
# perform a similarity search and retrieve the context from our documents
results = self.index.vectorstore.similarity_search(self.user_input, k=top_k)
# join all context information into one string
context = "\n".join([document.page_content for document in results])
if self.context_verbosity:
print(f"Retrieving information related to your question...")
print(f"Found this content which is most similar to your question: {context}")
if rag_off:
template = """Question: {question}
Answer: This is the response: """
self.prompt = PromptTemplate(template=template, input_variables=["question"])
else:
template = """ Don't just repeat the following context, use it in combination with your knowledge to improve your answer to the question:{context}
Question: {question}
"""
self.prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
The LangChain LLMChain utility to execute inference based on the query passed by the user and the configured template. The result is returned to the user.
def inference(self):
"""
Performs inference to generate a response based on the user's query.
Returns
-------
str
The generated response.
"""
if self.context_verbosity:
print(f"Your Query: {self.prompt}")
llm_chain = LLMChain(prompt=self.prompt, llm=self.llm)
print("Processing the information with gpt4all...\n")
response = llm_chain.run(self.user_input)
return response
Interactive Experimentation
To help you get started quickly, the notebook includes integrated ipywidget components. You must run all the cells in the notebook to enable these components. We encourage you to adjust the parameters and evaluate the impact on the latency and fidelity of the system’s response. Remember, this is just a starting point and a basic demonstration of RAG’s capabilities.
Summary and Discussion
No one wants to interact with slow, unstable chatbots that respond with bogus information. There are a plethora of technical stack combinations to help developers avoid building systems that yield terrible user experiences. In this article, we have interpreted the importance of inference engine quality to the user experience from the perspective of a stack that enables scale, fidelity, and latency benefits. The combination of RAG, CPUs, and model optimization techniques checks all corners of the IQ Triangle (Figure 3), aligning well with the needs of operational LLM-based AI chat applications.
A few exciting things to try would be:
- Edit the prompt template found in the retrieval_mechanism method to engineer better prompts in tandem with the retrieved context.
- Adjust the various model and RAG-specific parameters and evaluate the impact on inference latency and response quality.
- Add new datasets that are meaningful to your domain and test the viability of using RAG to build your AI chat-based applications.
- This example’s model (gpt4all-falcon-q4_0) is not optimized for Xeon processors. Explore using models that are optimized for CPU platforms and evaluate the inference latency benefits.
Thank you for reading! Don’t forget to follow my profile for more articles like this!
Retrieval Augmented Generation (RAG) Inference Engines with LangChain on CPUs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.