
Revolutionizing Culinary Experiences with AI: Introducing FIRE (Food Image to REcipe generation)
From Visual Delights to Culinary Recipes: How AI Transforms Food Images into Recipes?
Introduction:
Food is an essential source of nutrition and also an integral part of our cultural identity, describing our lifestyle, traditions, and social relations [1]. A person’s physical appearance and cognitive abilities usually contain evidence of their dietary habits because selecting nutritious food contributes to the overall well-being of the body and mind of a person [2]. The rapid growth of social media enables everyone to share stunning visuals of the delicious food they consume. A simple search for hashtags like #food or #foodie yields millions of posts, emphasizing the immense value of food in our society [3]. The importance of food, followed by large amounts of publicly available food datasets, has encouraged food computing applications that associate visual depictions of dishes with symbolic knowledge. An ambitious goal of food computing is to produce the recipe for a given food image, with applications such as food recommendation according to user preferences, recipe customization to accommodate cultural or religious factors, and automating cooking execution for higher efficiency and precision [4].
“Tell me what you eat, and I will tell you who you are.” This saying emphasizes the idea that an individual’s dietary choices reflect their identity.
Before delving deep into the proposed work, I would like to mention that this work is published and available at the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) — 2024, a conference recognized for its contributions and advancements in computer vision. ✨✨✨
Poster: https://drive.google.com/file/d/1zf2NA6ga8PWndZAgu5QjSwO8EPsvt-yt/view
The Inspiration Behind this Work:
Our motivation behind creating an end-to-end method for recipe generation from food images came from the interest of the Computer Vision (CV) community in food computing. CV has been used for food quality assurance for around three decades [5]. Despite advances in deep learning techniques for food image processing, existing methods have achieved limited performance in extracting ingredients from a given food image [6, 7]. Moreover, recipe generation from a set of ingredients could be treated as a language-generation task or, more precisely, as a seq-to-seq use case, which is also unexplored in the current literature. Additionally, previous methods have not thoroughly combined CV and NLP research to devise a comprehensive system that translates food images into complete recipes. Therefore, the current food computing methods have yet to leverage recent breakthroughs in NLP and CV, such as vision transformers and advanced language modeling. This gap in technology and application motivated us to develop an end-to-end pipeline, which we name FIRE (🔥), desiring to join these dots and push the limits of food computing. FIRE is a multimodal model that is designed to generate comprehensive recipe, including food titles, ingredients, and cooking instructions, based on given input food images, as shown in Figure 1.
The contributions of our paper are as follows:
- Our approach uses Vision Transformers (ViT) to extract detailed embeddings from food images, which are then used as an input by an attention-based decoder which further identifies recipe ingredients.
- We have developed a detailed design to generate recipe titles and cooking instructions, using state-of-the-art (SotA) vision (BLIP) and language (T5) models.
- Our multimodal approach surpasses existing models in performance based on ingredient extraction accuracy and the quality of generated cooking instructions.
- We demonstrate FIRE’s versatility via two innovative applications, (i) Recipe Customization and (ii) Recipe to Code Generation, displaying its significance in integrating large language models (LLMs) using few-shot prompting.
Unveiling FIRE: Breaking Down the Process
FIRE contains three components: (1) title generation from food images by using SotA image captioning, (2) ingredient extraction from images using vision transformers and decoder layers with attention, and (3) cooking instruction generation based on the generated title and extracted ingredients using an encoder-decoder model. Please refer to Figure 2 for more details about the proposed architecture.
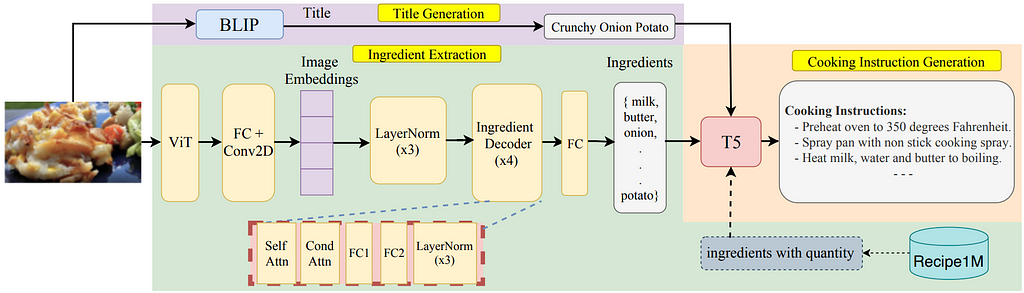
1. Title Generation
Using the BLIP model, we generate recipe titles from food images [8]. In our initial experiments with the off-the-shelf BLIP model, we observed BLIP’s prediction accuracy was lower because of the domain shift between its training data and the food domain. BLIP tends to capture extraneous details impertinent to our goal because it was originally designed to provide a comprehensive image caption for various settings. As an illustration, when presented with an image of a muffin, BLIP produced the description ‘a muffin positioned atop a wooden cutting board’. To better align the generated captions with recipe titles, we fine-tune the BLIP model using a subset of the Recipe1M dataset. We observe that the fine-tuned version of BLIP shows promising improvements in generating accurate, aligned, and pertinent titles for food images. For the same example image the fine-tuned BLIP model provides a shorter string ‘muffin’, removing the additional extraneous information.
2. Ingredient Extraction
Extracting ingredients from a given food image is a challenging task due to the inherent complexity and variability of food compositions. We develop an ingredient extraction pipeline (shown in Figure 2) that is built on top of the one proposed by [7].
Feature Extractor: We extract the image’s features using ViT [9]. ViT’s attention mechanism handles the feature representations with stable and notably high resolution. This capability precisely meets the requirements of dense prediction tasks such as ingredient extraction from food images.
Ingredient Decoder: The feature extractor produces image embeddings. We pass these image embeddings through three normalization layers (layerNorm) and subsequently feed the output into our ingredient decoder responsible for extracting ingredients. The decoder consists of four consecutive blocks, each having multiple sequential layers: self-attention, conditional attention, two fully connected layers, and three normalization layers. In the last step, the decoder output is processed by a fully connected layer with a node count equivalent to the vocabulary size, resulting in a predicted set of ingredients.
3. Cooking Instruction Generation
Considering the remarkable accomplishments of LMs in natural language applications like text generation and question answering [10], we pose cooking instruction generation as a language modeling task.
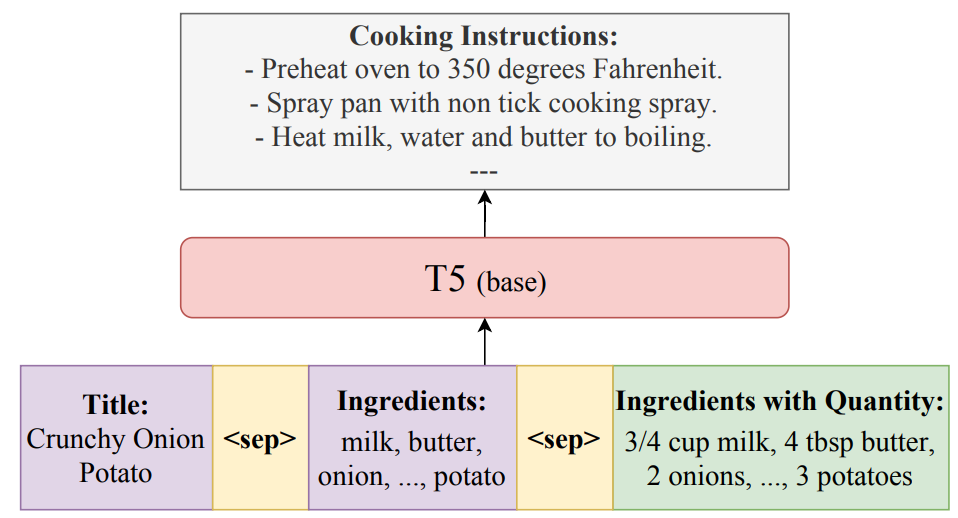
Refining the LMs for downstream tasks has demonstrated remarkable outcomes in various NLP tasks. While we expect that large LMs would be capable of generating cooking instructions after fine-tuning, they require high computational resources given their large number of parameters. Given the available resources and our research objective, we adopt the popular encoder-decoder model, T5 [11], for generating cooking instructions. During fine-tuning, we pass the title and ingredients of the recipe as a formatted string (see Figure 3), inspired by prior work [12].
The T5 is fine-tuned on three inputs: title, ingredients, and ingredients with quantity to incorporate maximum information from the dataset. However, we do not have ingredients with quantities at the inference time; hence, we pass only the title and ingredients. Moreover, excluding the quantity information from our model ensures a fair comparison with previous approaches. It investigates whether our model’s advantage stems from a well-structured architecture rather than relying solely on augmenting additional knowledge. By removing the influence of quantity information during inference, we aim to highlight the inherent capabilities of T5 and its ability to generate high-quality cooking instructions.
FIRE Results:
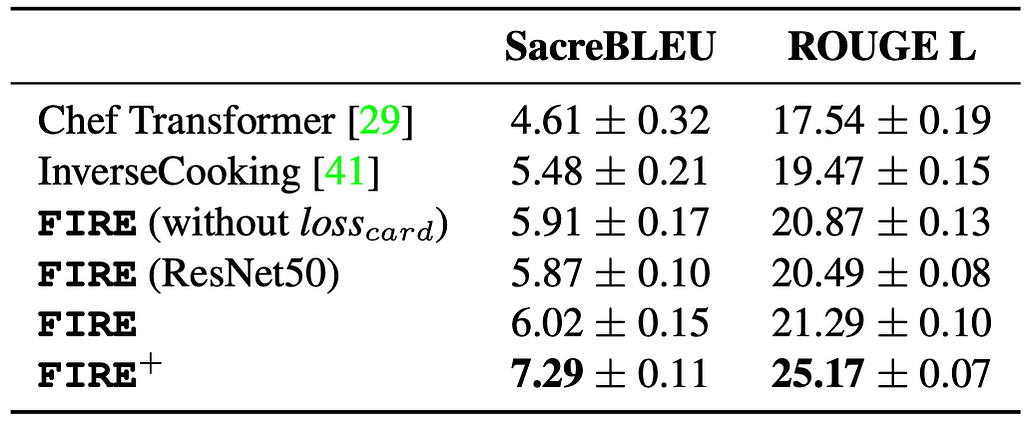
The results in Table 1 show that FIRE performs better than the SotA baselines, InverseCooking [7] and Chef Transformer [13]. These results demonstrate our proposed pipeline’s ability to generate precise and coherent recipes, corroborating the effectiveness of FIRE and emphasizing the value of language generation models for high-quality recipe generation. These results also support our expectation that the FIRE method can generalize well without ingredient quantity information given at inference time, even when they were present during training. Meanwhile, training with extra information results in fewer hallucinations, especially regarding ingredients quantity (e.g., 2 tablespoons of salt) and cooking time (e.g., heat for 10–12 minutes).
In this article, we mostly focus on the critical aspects of our proposed work, considering the article length constraints. We encourage readers to check out our detailed paper for a deeper dive into our experimental results and comprehensive analysis. 😁
Error Analysis
To gain further insight into the performance of our recipe generation method, we inspected its performance on individual images. FIRE is often able to generate a correct recipe for dishes similar to those present in the Recipe1M dataset. For Pav Bhaji (a popular Indian dish not present in Recipe1M), it gave a result that is unrelated to the intended dish, as illustrated in Figure. 4. Therefore, we want to highlight the importance of developing better evaluation metrics because conventional evaluation metrics such as SacreBLEU and ROUGE failed to capture the accuracy of the recipes generated and detect specific text hallucinations.

Beyond the Kitchen: The Future of Food Computing with FIRE:
While FIRE achieves SotA performance on the ambitious task of generating recipes from images, we go a step further and investigate its integration into larger pipelines for food computing applications. Namely, considering the promise of few-shot prompting of large language models, we describe how FIRE and large LMs can be integrated to support recipe customization and recipe-to-machine-code generation.
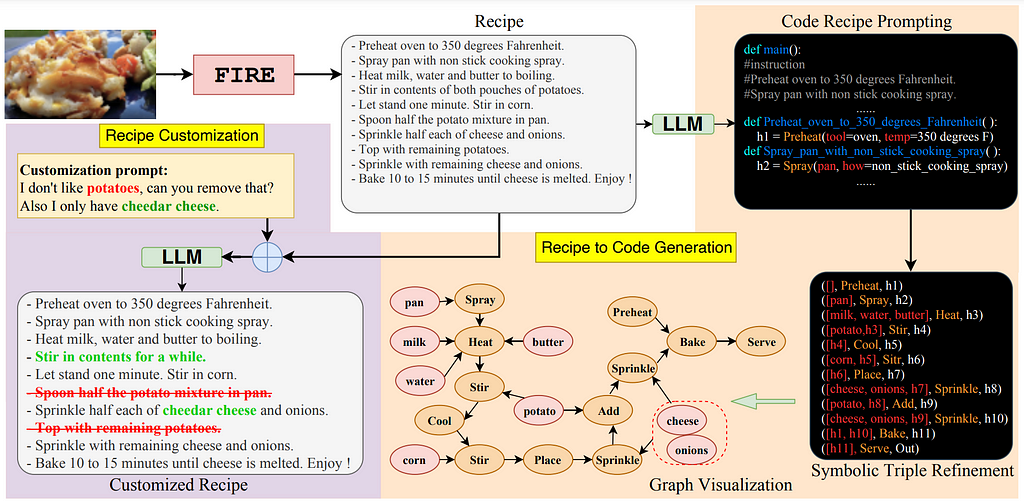
1. Recipe Customization
Recipe customization is crucial due to the connection between food, customs, and individual preferences. Additionally, it becomes essential when addressing allergies or dietary restrictions. Surprisingly, despite the evident demand, existing literature lacks dedicated efforts in recipe customization. Our work aims to bridge the research gap by enabling personalized recipe customization, considering individual taste profiles and dietary restrictions.
To guide future research in this area, we showcase the ability of FIRE to support a recipe customization approach that focuses on a wide range of topics (e.g., ingredient replacement, taste adjustment, calorie adjustment, cooking time adaptation) to test few-shot performance thoroughly. As shown in the purple part of Figure 5, we remove ingredients to trim the potatoes from the recipe. Two sentences related to potatoes are deleted in the modified version, and one sentence is changed to ensure consistency. Specifically, we perform ingredient addition to replace ‘cheese’ with ‘cheddar cheese’ and recognize that it should be added before baking, resulting in the modified sentence ‘Sprinkle half each of cheddar cheese and onions.’
2. Generating Machine Code for Image-based Recipes
Converting recipes to machine code enables automation, scalability, and integration with various existing systems, thus reducing manual intervention, saving labor costs, and reducing human errors while preparing the food. To facilitate this task, we combine FIRE’s recipe generation strength with the ability of large LMs to manipulate code-style prompts for structural tasks [14]. We show an example approach for generating Python-style code representations of recipes developed by FIRE, by prompting GPT-3 (please refer to orange part in Figure 5).
Conclusion & Future Work:
We introduced FIRE, a methodology tailored for food computing, focusing on generating food titles, extracting ingredients, and generating cooking instructions solely from image inputs. We leveraged recent CV and language modeling advancements to achieve superior performance against solid baselines. Furthermore, we demonstrated practical applications of FIRE for recipe customization and recipe-to-code generation, showcasing the adaptability and automation potential of our approach.
We list three challenges that should be addressed in future research:
- Existing and proposed recipe generation models lack a reliable mechanism to verify the accuracy of the generated recipes. Conventional evaluation metrics fall short in this aspect. Hence, we would like to create a new metric that assesses the coherence and plausibility of recipes, providing a more thorough evaluation.
- The diversity and availability of recipes are influenced by geographical, climatic, and religious factors, which may limit their applicability. Incorporating knowledge graphs that account for these contextual factors and ingredient relationships can offer alternative ingredient suggestions, addressing this issue.
- Hallucination in recipe generation using language and vision models poses a significant challenge. Future work would explore the state-tracking methods to improve the generation process, ensuring the production of more realistic and accurate recipes.
Call-to-Action:
I hope this overview has provided you the insight into the inspiration and development of FIRE, our innovative tool for converting food images into detailed recipes. For a more in-depth exploration of our approach, I invite you to check out our full paper, which is published in the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) — 2024. If our research contribute to your work, we would be happy if you cite it. 😊
@InProceedings{Chhikara_2024_WACV,
author = {Chhikara, Prateek and Chaurasia, Dhiraj and Jiang, Yifan and Masur, Omkar and Ilievski, Filip},
title = {FIRE: Food Image to REcipe Generation},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {8184-8194}
}
References:
[1] Weiqing Min, Shuqiang Jiang, Linhu Liu, Yong Rui, and Ramesh Jain. A survey on food computing. ACM Comput. Surv., 52(5), sep 2019.
[2] Sutter Health. Eating Well for Mental Health. https://www.sutterhealth.org/health/nutrition/eating-wellfor-mental-health. Accessed on March 24, 2023.
[3] Kiely Kuligowski. 12 Reasons to Use Instagram for Your Business. https://www.business.com/articles/10-reasons-touse-instagram-for-business/. Accessed on May 12, 2023.
[4] Dim P. Papadopoulos, Enrique Mora, Nadiia Chepurko, Kuan Wei Huang, Ferda Ofli, and Antonio Torralba. Learning program representations for food images and cooking recipes, 2022.
[5] Sundaram Gunasekaran. Computer vision technology for food quality assurance. Trends in Food Science & Technology, 7(8):245–256, 1996.
[6] Yoshiyuki Kawano and Keiji Yanai. Food image recognition with deep convolutional features. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, pages 589– 593, 2014
[7] Amaia Salvador, Michal Drozdzal, Xavier Giro-i Nieto, and ´ Adriana Romero. Inverse cooking: Recipe generation from food images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10453– 10462, 2019.
[8] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888– 12900. PMLR, 2022.
[9] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[10] Prateek Chhikara, Ujjwal Pasupulety, John Marshall, Dhiraj Chaurasia, and Shweta Kumari. Privacy aware questionanswering system for online mental health risk assessment. In The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, pages 215– 222, Toronto, Canada, July 2023. Association for Computational Linguistics.
[11] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
[12] Chunting Zhou, Graham Neubig, Jiatao Gu, Mona Diab, Francisco Guzman, Luke Zettlemoyer, and Marjan ´ Ghazvininejad. Detecting hallucinated content in conditional neural sequence generation. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1393–1404, 2021.
[13] Mehrdad Farahani and Kartik Godawat and Haswanth Aekula and Deepak Pandian and Nicholas Broad. Chef Transformer. https://huggingface.co/flax-community/t5- recipe-generation. Accessed on April 12, 2023.
[14] Aman Madaan, Shuyan Zhou, Uri Alon, Yiming Yang, and Graham Neubig. Language models of code are few-shot commonsense learners. In Findings of the Association for Computational Linguistics: EMNLP 2022, 2022
Revolutionizing Culinary Experiences with AI: Introducing FIRE (Food Image to REcipe generation) 🔥 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
From Visual Delights to Culinary Recipes: How AI Transforms Food Images into Recipes?

Introduction:
Food is an essential source of nutrition and also an integral part of our cultural identity, describing our lifestyle, traditions, and social relations [1]. A person’s physical appearance and cognitive abilities usually contain evidence of their dietary habits because selecting nutritious food contributes to the overall well-being of the body and mind of a person [2]. The rapid growth of social media enables everyone to share stunning visuals of the delicious food they consume. A simple search for hashtags like #food or #foodie yields millions of posts, emphasizing the immense value of food in our society [3]. The importance of food, followed by large amounts of publicly available food datasets, has encouraged food computing applications that associate visual depictions of dishes with symbolic knowledge. An ambitious goal of food computing is to produce the recipe for a given food image, with applications such as food recommendation according to user preferences, recipe customization to accommodate cultural or religious factors, and automating cooking execution for higher efficiency and precision [4].
“Tell me what you eat, and I will tell you who you are.” This saying emphasizes the idea that an individual’s dietary choices reflect their identity.
Before delving deep into the proposed work, I would like to mention that this work is published and available at the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) — 2024, a conference recognized for its contributions and advancements in computer vision. ✨✨✨
Poster: https://drive.google.com/file/d/1zf2NA6ga8PWndZAgu5QjSwO8EPsvt-yt/view
The Inspiration Behind this Work:
Our motivation behind creating an end-to-end method for recipe generation from food images came from the interest of the Computer Vision (CV) community in food computing. CV has been used for food quality assurance for around three decades [5]. Despite advances in deep learning techniques for food image processing, existing methods have achieved limited performance in extracting ingredients from a given food image [6, 7]. Moreover, recipe generation from a set of ingredients could be treated as a language-generation task or, more precisely, as a seq-to-seq use case, which is also unexplored in the current literature. Additionally, previous methods have not thoroughly combined CV and NLP research to devise a comprehensive system that translates food images into complete recipes. Therefore, the current food computing methods have yet to leverage recent breakthroughs in NLP and CV, such as vision transformers and advanced language modeling. This gap in technology and application motivated us to develop an end-to-end pipeline, which we name FIRE (🔥), desiring to join these dots and push the limits of food computing. FIRE is a multimodal model that is designed to generate comprehensive recipe, including food titles, ingredients, and cooking instructions, based on given input food images, as shown in Figure 1.
The contributions of our paper are as follows:
- Our approach uses Vision Transformers (ViT) to extract detailed embeddings from food images, which are then used as an input by an attention-based decoder which further identifies recipe ingredients.
- We have developed a detailed design to generate recipe titles and cooking instructions, using state-of-the-art (SotA) vision (BLIP) and language (T5) models.
- Our multimodal approach surpasses existing models in performance based on ingredient extraction accuracy and the quality of generated cooking instructions.
- We demonstrate FIRE’s versatility via two innovative applications, (i) Recipe Customization and (ii) Recipe to Code Generation, displaying its significance in integrating large language models (LLMs) using few-shot prompting.
Unveiling FIRE: Breaking Down the Process
FIRE contains three components: (1) title generation from food images by using SotA image captioning, (2) ingredient extraction from images using vision transformers and decoder layers with attention, and (3) cooking instruction generation based on the generated title and extracted ingredients using an encoder-decoder model. Please refer to Figure 2 for more details about the proposed architecture.
1. Title Generation
Using the BLIP model, we generate recipe titles from food images [8]. In our initial experiments with the off-the-shelf BLIP model, we observed BLIP’s prediction accuracy was lower because of the domain shift between its training data and the food domain. BLIP tends to capture extraneous details impertinent to our goal because it was originally designed to provide a comprehensive image caption for various settings. As an illustration, when presented with an image of a muffin, BLIP produced the description ‘a muffin positioned atop a wooden cutting board’. To better align the generated captions with recipe titles, we fine-tune the BLIP model using a subset of the Recipe1M dataset. We observe that the fine-tuned version of BLIP shows promising improvements in generating accurate, aligned, and pertinent titles for food images. For the same example image the fine-tuned BLIP model provides a shorter string ‘muffin’, removing the additional extraneous information.
2. Ingredient Extraction
Extracting ingredients from a given food image is a challenging task due to the inherent complexity and variability of food compositions. We develop an ingredient extraction pipeline (shown in Figure 2) that is built on top of the one proposed by [7].
Feature Extractor: We extract the image’s features using ViT [9]. ViT’s attention mechanism handles the feature representations with stable and notably high resolution. This capability precisely meets the requirements of dense prediction tasks such as ingredient extraction from food images.
Ingredient Decoder: The feature extractor produces image embeddings. We pass these image embeddings through three normalization layers (layerNorm) and subsequently feed the output into our ingredient decoder responsible for extracting ingredients. The decoder consists of four consecutive blocks, each having multiple sequential layers: self-attention, conditional attention, two fully connected layers, and three normalization layers. In the last step, the decoder output is processed by a fully connected layer with a node count equivalent to the vocabulary size, resulting in a predicted set of ingredients.
3. Cooking Instruction Generation
Considering the remarkable accomplishments of LMs in natural language applications like text generation and question answering [10], we pose cooking instruction generation as a language modeling task.
Refining the LMs for downstream tasks has demonstrated remarkable outcomes in various NLP tasks. While we expect that large LMs would be capable of generating cooking instructions after fine-tuning, they require high computational resources given their large number of parameters. Given the available resources and our research objective, we adopt the popular encoder-decoder model, T5 [11], for generating cooking instructions. During fine-tuning, we pass the title and ingredients of the recipe as a formatted string (see Figure 3), inspired by prior work [12].
The T5 is fine-tuned on three inputs: title, ingredients, and ingredients with quantity to incorporate maximum information from the dataset. However, we do not have ingredients with quantities at the inference time; hence, we pass only the title and ingredients. Moreover, excluding the quantity information from our model ensures a fair comparison with previous approaches. It investigates whether our model’s advantage stems from a well-structured architecture rather than relying solely on augmenting additional knowledge. By removing the influence of quantity information during inference, we aim to highlight the inherent capabilities of T5 and its ability to generate high-quality cooking instructions.
FIRE Results:
The results in Table 1 show that FIRE performs better than the SotA baselines, InverseCooking [7] and Chef Transformer [13]. These results demonstrate our proposed pipeline’s ability to generate precise and coherent recipes, corroborating the effectiveness of FIRE and emphasizing the value of language generation models for high-quality recipe generation. These results also support our expectation that the FIRE method can generalize well without ingredient quantity information given at inference time, even when they were present during training. Meanwhile, training with extra information results in fewer hallucinations, especially regarding ingredients quantity (e.g., 2 tablespoons of salt) and cooking time (e.g., heat for 10–12 minutes).
In this article, we mostly focus on the critical aspects of our proposed work, considering the article length constraints. We encourage readers to check out our detailed paper for a deeper dive into our experimental results and comprehensive analysis. 😁
Error Analysis
To gain further insight into the performance of our recipe generation method, we inspected its performance on individual images. FIRE is often able to generate a correct recipe for dishes similar to those present in the Recipe1M dataset. For Pav Bhaji (a popular Indian dish not present in Recipe1M), it gave a result that is unrelated to the intended dish, as illustrated in Figure. 4. Therefore, we want to highlight the importance of developing better evaluation metrics because conventional evaluation metrics such as SacreBLEU and ROUGE failed to capture the accuracy of the recipes generated and detect specific text hallucinations.
Beyond the Kitchen: The Future of Food Computing with FIRE:
While FIRE achieves SotA performance on the ambitious task of generating recipes from images, we go a step further and investigate its integration into larger pipelines for food computing applications. Namely, considering the promise of few-shot prompting of large language models, we describe how FIRE and large LMs can be integrated to support recipe customization and recipe-to-machine-code generation.
1. Recipe Customization
Recipe customization is crucial due to the connection between food, customs, and individual preferences. Additionally, it becomes essential when addressing allergies or dietary restrictions. Surprisingly, despite the evident demand, existing literature lacks dedicated efforts in recipe customization. Our work aims to bridge the research gap by enabling personalized recipe customization, considering individual taste profiles and dietary restrictions.
To guide future research in this area, we showcase the ability of FIRE to support a recipe customization approach that focuses on a wide range of topics (e.g., ingredient replacement, taste adjustment, calorie adjustment, cooking time adaptation) to test few-shot performance thoroughly. As shown in the purple part of Figure 5, we remove ingredients to trim the potatoes from the recipe. Two sentences related to potatoes are deleted in the modified version, and one sentence is changed to ensure consistency. Specifically, we perform ingredient addition to replace ‘cheese’ with ‘cheddar cheese’ and recognize that it should be added before baking, resulting in the modified sentence ‘Sprinkle half each of cheddar cheese and onions.’
2. Generating Machine Code for Image-based Recipes
Converting recipes to machine code enables automation, scalability, and integration with various existing systems, thus reducing manual intervention, saving labor costs, and reducing human errors while preparing the food. To facilitate this task, we combine FIRE’s recipe generation strength with the ability of large LMs to manipulate code-style prompts for structural tasks [14]. We show an example approach for generating Python-style code representations of recipes developed by FIRE, by prompting GPT-3 (please refer to orange part in Figure 5).
Conclusion & Future Work:
We introduced FIRE, a methodology tailored for food computing, focusing on generating food titles, extracting ingredients, and generating cooking instructions solely from image inputs. We leveraged recent CV and language modeling advancements to achieve superior performance against solid baselines. Furthermore, we demonstrated practical applications of FIRE for recipe customization and recipe-to-code generation, showcasing the adaptability and automation potential of our approach.
We list three challenges that should be addressed in future research:
- Existing and proposed recipe generation models lack a reliable mechanism to verify the accuracy of the generated recipes. Conventional evaluation metrics fall short in this aspect. Hence, we would like to create a new metric that assesses the coherence and plausibility of recipes, providing a more thorough evaluation.
- The diversity and availability of recipes are influenced by geographical, climatic, and religious factors, which may limit their applicability. Incorporating knowledge graphs that account for these contextual factors and ingredient relationships can offer alternative ingredient suggestions, addressing this issue.
- Hallucination in recipe generation using language and vision models poses a significant challenge. Future work would explore the state-tracking methods to improve the generation process, ensuring the production of more realistic and accurate recipes.
Call-to-Action:
I hope this overview has provided you the insight into the inspiration and development of FIRE, our innovative tool for converting food images into detailed recipes. For a more in-depth exploration of our approach, I invite you to check out our full paper, which is published in the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) — 2024. If our research contribute to your work, we would be happy if you cite it. 😊
@InProceedings{Chhikara_2024_WACV,
author = {Chhikara, Prateek and Chaurasia, Dhiraj and Jiang, Yifan and Masur, Omkar and Ilievski, Filip},
title = {FIRE: Food Image to REcipe Generation},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {8184-8194}
}
References:
[1] Weiqing Min, Shuqiang Jiang, Linhu Liu, Yong Rui, and Ramesh Jain. A survey on food computing. ACM Comput. Surv., 52(5), sep 2019.
[2] Sutter Health. Eating Well for Mental Health. https://www.sutterhealth.org/health/nutrition/eating-wellfor-mental-health. Accessed on March 24, 2023.
[3] Kiely Kuligowski. 12 Reasons to Use Instagram for Your Business. https://www.business.com/articles/10-reasons-touse-instagram-for-business/. Accessed on May 12, 2023.
[4] Dim P. Papadopoulos, Enrique Mora, Nadiia Chepurko, Kuan Wei Huang, Ferda Ofli, and Antonio Torralba. Learning program representations for food images and cooking recipes, 2022.
[5] Sundaram Gunasekaran. Computer vision technology for food quality assurance. Trends in Food Science & Technology, 7(8):245–256, 1996.
[6] Yoshiyuki Kawano and Keiji Yanai. Food image recognition with deep convolutional features. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, pages 589– 593, 2014
[7] Amaia Salvador, Michal Drozdzal, Xavier Giro-i Nieto, and ´ Adriana Romero. Inverse cooking: Recipe generation from food images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10453– 10462, 2019.
[8] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888– 12900. PMLR, 2022.
[9] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[10] Prateek Chhikara, Ujjwal Pasupulety, John Marshall, Dhiraj Chaurasia, and Shweta Kumari. Privacy aware questionanswering system for online mental health risk assessment. In The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, pages 215– 222, Toronto, Canada, July 2023. Association for Computational Linguistics.
[11] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
[12] Chunting Zhou, Graham Neubig, Jiatao Gu, Mona Diab, Francisco Guzman, Luke Zettlemoyer, and Marjan ´ Ghazvininejad. Detecting hallucinated content in conditional neural sequence generation. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1393–1404, 2021.
[13] Mehrdad Farahani and Kartik Godawat and Haswanth Aekula and Deepak Pandian and Nicholas Broad. Chef Transformer. https://huggingface.co/flax-community/t5- recipe-generation. Accessed on April 12, 2023.
[14] Aman Madaan, Shuyan Zhou, Uri Alon, Yiming Yang, and Graham Neubig. Language models of code are few-shot commonsense learners. In Findings of the Association for Computational Linguistics: EMNLP 2022, 2022
Revolutionizing Culinary Experiences with AI: Introducing FIRE (Food Image to REcipe generation) 🔥 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.