
Risk Prediction with EHR Data using Hierarchical Attention Mechanism | by Satyam Kumar | May, 2022
Essential guide to LSAN: Modeling Long-term dependencies and Short-term correlations with Hierarchical Attention
Electronic Health Records (EHR) are comprehensive historical health records that contain the symptoms of a patient when he/she visits a doctor. EHR data has a two-level hierarchical structure that consists of a set of time-ordered visits, and within each visit, there is a set of unordered diagnosis codes. The diagnosis codes can belong to the ICD-9 or ICD-10 format that denotes the symptoms of a certain disease.
Risk Prediction is one of the popular problem statements in the healthcare industry. Risk Prediction refers to the prediction of members who are at high risk of a certain disease in the future. Existing approaches focus on modeling temporal visits and ignore the importance of modeling diagnosis codes within visits, and a lot of task-unrelated information within visits usually leads to unsatisfactory performance of existing approaches.
In this article, we will discuss how to perform Risk Prediction by preserving the long-term dependencies and short-term correlation with hierarchical attention.
Reference Paper: LSAN-Modeling Long-term Dependencies and Short-term Correlations with Hierarchical Attention for Risk Prediction
EHR data consists of a two-level hierarchical structure: the hierarchy of visits and the second the hierarchy of diagnosis codes for each visit.
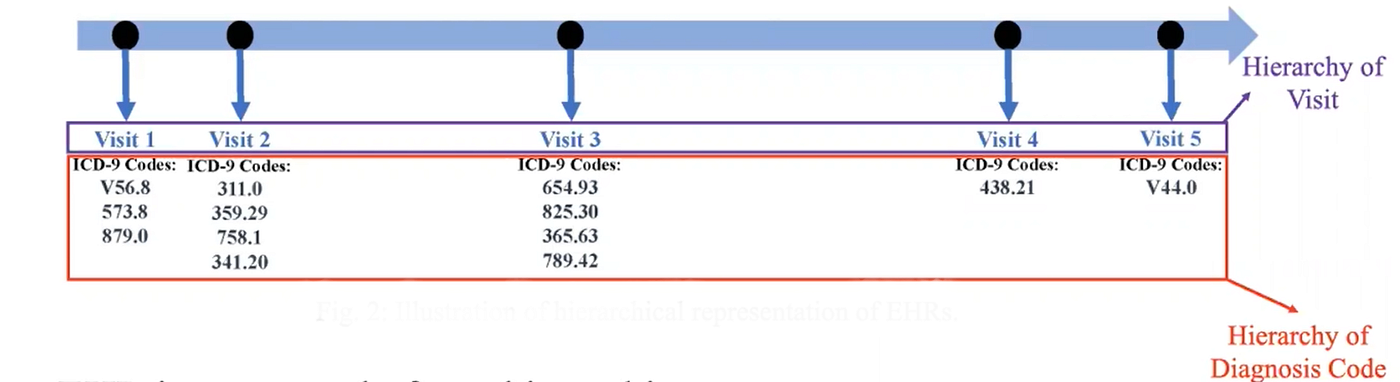
This paper proposes an LSAN deep neural network model to model both the hierarchical structure of EHR data.
The task is to compute a function f that can predict certain diseases of patient ‘p’ that may occur in the future using the longitudinal EHR data 𝑯 ∈ R𝑚×n. The main concern of the function is to extract hidden disease progression information from patient data H and deal with the issue of noise information.
Input Notation:
For each patient ‘p’, it expects historical diagnostic results as a sequential list 𝑯 = [𝒉1, 𝒉2,…, 𝒉𝑛], where 𝒉𝑖 is the diagnostic results of the 𝑖-the visit, n is the number of visits.
Each visit diagnostic result consists of a subset of ICD-9 codes 𝑪 = {𝒄1,𝒄2,…,𝒄𝑚} where 𝑚 is the number of unique diagnosis codes in the dataset.

Here hiCj=1 if diagnosis results ith visit contains cj diag code, else hiCj=0
LSAN is an end-to-end model,
- HAM (In Hierarchy of Diagnosis Code): It learns visit embeddings with the designed diagnosis-code-level attention.
- TAM (Temporal Aggregation Module): It captures both long-term dependencies and short-term correlations among visits.
- HAM (In Hierarchy of Visit): The outputs of TAM are used to learn the final comprehensive patient representation by the visit level attention in HAM.
- Classifier: The comprehensive representation is used to make a prediction
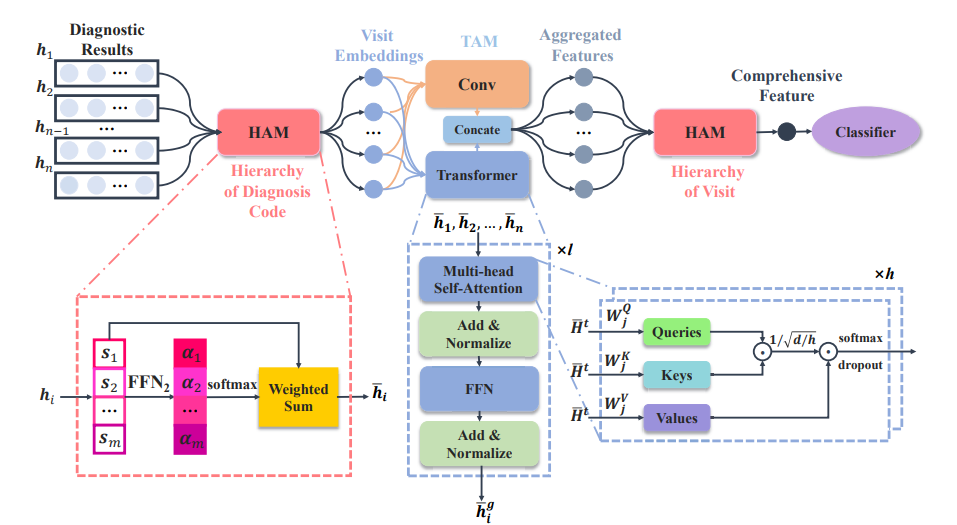
The function of HAM is to utilize the hierarchical representation of the HER, and it has an attention mechanism to remove the noise in EHR data.
HAM (In Hierarchy of Diagnosis Code):
Purpose:
In the hierarchy of diagnosis code, we should reduce the noise information to learn a better embedding for each visit. Within each visit, there may exist diagnosis codes that are unrelated to the target class. So, we need to distinguish the importance of the diagnosis code within each visit.
HAM utilizes a hierarchical attention mechanism to pay more attention to the diagnosis codes that are related to our target disease and less attention to other codes.
Implementation:
- Since 𝑯 ∈ R^(m*n) is a sparse matrix and not good for representation learning, so idea is to learn a dense embedding for each code
- HAM first encodes each diagnosis code 𝒄𝑖 into a dense embedding 𝒆𝑖 ∈ R𝑑 through a 1-layer feedforward network FFN1
- HAM first encodes each diagnosis code 𝒄𝑖 into a dense embedding 𝒆𝑖 ∈ R𝑑 through a 1-layer feedforward network FFN1
𝒆𝑖 = FFN1 (𝒄𝑖) = ReLU(𝑾1𝒄𝑖 + 𝒃1), where 𝑾1 ∈ R𝑑×𝑚, 𝒃1 ∈ R^d - 𝑬 = [𝒆1,…, 𝒆𝑚] ∈ R^(𝑑×m), d-dim dense representation for m unique diagnosis codes
- For the 𝑖-th visit, we obtain a dense embedding set 𝑺𝑖 = [𝒔1,…,𝒔𝑚] where 𝒔𝑗 = 𝒆𝑗 if 𝒉𝑖𝑗 = 1 to reflect the existence of a certain symptom or disease, otherwise 𝒔𝑗 = 0
- Still, 𝑺𝑖 ∈ R𝑑×m is redundant for the learning process. Now HAM extracts latent information for each visit and represents it as
𝒉¯𝑖 ∈ R𝑑 - To extract latent information of visits HAM uses a 3-layer feedforward network (FFN_2). FFN_2 learns the attention weight of each dense embedding 𝑺𝑖 and attends them together.
- We get an attention score 𝛼𝑖 ∈ R for each diagnosis code (𝛼𝑖 = FFN2 (𝒔𝑖)), if 𝒔𝑖 = 0, we set 𝛼𝑖 = −∞. Normalizing the attention score with softmax:
𝑎𝑖 = exp(𝛼𝑖)/( Σ𝑗=1tom exp(𝛼𝑗) ), here 𝑎𝑖 is normalized weight - Now we obtain a single embedding 𝒉¯𝑖 for the 𝑖-th visit
(𝒉¯𝑖 = Σ𝑖=(1 to m) 𝑎𝑖 · 𝒔𝑖).As a result, in the hierarchy of diagnosis codes, we gain a set of attended features𝑯¯ = [𝒉¯1,…, 𝒉¯𝑛] ∈ R𝑑×𝑛for a patient ‘p’.
TAM (In Hierarchy of Diagnosis Code):
Purpose:
TAM aggregates the visit embedding with two kinds of temporal information from global and temporal structures. When features of all visits are put into TAM,
- It models long-term dependencies in global structure by Transformer such as how each visit relates to others in a patient’s complete medical journey.
- Short-term correlations in local structure by convolutional layer such as how every visit relates to others in a short time period.
Implementation:
- TAM in Short-term Correlations Modelling by Convolution: It filters out the noise coming from irrelevant diagnosis codes is to extract the correlated disease progression information in each stage for temporal aggregation
2. TAM in Long-term Dependencies Modelling by Transformer:
a. Transformer attends all visit features in parallel and does not obscure the details of each feature
b. We use a multi-head self-attention mechanism in Transformer for feature attending, and the Transformer encoder in TAM has 𝑙 layers, where the computations are the same in each layer
c. Add positional encoding into the 𝑖-th input visit, 𝒉¯𝑡 𝑖 = 𝒉¯𝑖 + 𝒕I, where 𝒕𝑖 is the positional encoding
d. Each layer of the Transformer has ‘ℎ’ head,
The two temporal information are both beneficial to the robustness of learned features, so we concatenate 𝒉¯𝑔 𝑖 and 𝒉¯𝑙 𝑖 to get a feature 𝒉𝑖 ∈ R2𝑑 for risk prediction,
𝒉𝑖 = Concate(𝒉¯𝑔 𝑖 , 𝒉¯𝑙 𝑖)
Finally, TAM outputs a matrix 𝑯 = [𝒉~1,…, 𝒉~𝑛] ∈ R2𝑑×n
HAM (In Hierarchy of Visit):
Purpose:
In the hierarchy of visits, we should pay attention to the correlations among visits. It captures the temporal patterns of disease. Filtering out noise by extracting local temporal correlations among neighboring visits and utilizing the long-term dependencies information.
It focuses on extracting overall semantics from all the visits.
Implementation:
- Similar to HAM in the hierarchy of diagnosis code, it first employs a 3-layer feedforward network FFN4 to learn attention scores 𝛽𝑖 ∈ R,
𝛽𝑖 = FFN4 ( 𝒉𝑖). - We then get the normalized attention weights 𝑏𝑖 ∈ R with softmax function
b𝑖 = exp(𝛽𝑖)/( Σ𝑗 =1m exp(𝛽𝑗) - The comprehensive feature 𝒙 ∈ R2𝑑 for risk prediction is learned by the attention mechanism, where
𝒙 = Σ𝑖=1n (𝑏𝑖 · 𝒉~𝑖)
Classifier:
- Finally, we utilize 𝒙 for risk prediction, 𝑦ˆ = 𝜎(𝒘T𝒙 + 𝑏), where 𝒘 ∈ R2d and b ∈ R
- With the training set T, we use binary cross-entropy loss L to train the model and get the learned parameters 𝜽
Essential guide to LSAN: Modeling Long-term dependencies and Short-term correlations with Hierarchical Attention

Electronic Health Records (EHR) are comprehensive historical health records that contain the symptoms of a patient when he/she visits a doctor. EHR data has a two-level hierarchical structure that consists of a set of time-ordered visits, and within each visit, there is a set of unordered diagnosis codes. The diagnosis codes can belong to the ICD-9 or ICD-10 format that denotes the symptoms of a certain disease.
Risk Prediction is one of the popular problem statements in the healthcare industry. Risk Prediction refers to the prediction of members who are at high risk of a certain disease in the future. Existing approaches focus on modeling temporal visits and ignore the importance of modeling diagnosis codes within visits, and a lot of task-unrelated information within visits usually leads to unsatisfactory performance of existing approaches.
In this article, we will discuss how to perform Risk Prediction by preserving the long-term dependencies and short-term correlation with hierarchical attention.
Reference Paper: LSAN-Modeling Long-term Dependencies and Short-term Correlations with Hierarchical Attention for Risk Prediction
EHR data consists of a two-level hierarchical structure: the hierarchy of visits and the second the hierarchy of diagnosis codes for each visit.
This paper proposes an LSAN deep neural network model to model both the hierarchical structure of EHR data.
The task is to compute a function f that can predict certain diseases of patient ‘p’ that may occur in the future using the longitudinal EHR data 𝑯 ∈ R𝑚×n. The main concern of the function is to extract hidden disease progression information from patient data H and deal with the issue of noise information.
Input Notation:
For each patient ‘p’, it expects historical diagnostic results as a sequential list 𝑯 = [𝒉1, 𝒉2,…, 𝒉𝑛], where 𝒉𝑖 is the diagnostic results of the 𝑖-the visit, n is the number of visits.
Each visit diagnostic result consists of a subset of ICD-9 codes 𝑪 = {𝒄1,𝒄2,…,𝒄𝑚} where 𝑚 is the number of unique diagnosis codes in the dataset.
Here hiCj=1 if diagnosis results ith visit contains cj diag code, else hiCj=0
LSAN is an end-to-end model,
- HAM (In Hierarchy of Diagnosis Code): It learns visit embeddings with the designed diagnosis-code-level attention.
- TAM (Temporal Aggregation Module): It captures both long-term dependencies and short-term correlations among visits.
- HAM (In Hierarchy of Visit): The outputs of TAM are used to learn the final comprehensive patient representation by the visit level attention in HAM.
- Classifier: The comprehensive representation is used to make a prediction
The function of HAM is to utilize the hierarchical representation of the HER, and it has an attention mechanism to remove the noise in EHR data.
HAM (In Hierarchy of Diagnosis Code):
Purpose:
In the hierarchy of diagnosis code, we should reduce the noise information to learn a better embedding for each visit. Within each visit, there may exist diagnosis codes that are unrelated to the target class. So, we need to distinguish the importance of the diagnosis code within each visit.
HAM utilizes a hierarchical attention mechanism to pay more attention to the diagnosis codes that are related to our target disease and less attention to other codes.
Implementation:
- Since 𝑯 ∈ R^(m*n) is a sparse matrix and not good for representation learning, so idea is to learn a dense embedding for each code
- HAM first encodes each diagnosis code 𝒄𝑖 into a dense embedding 𝒆𝑖 ∈ R𝑑 through a 1-layer feedforward network FFN1
- HAM first encodes each diagnosis code 𝒄𝑖 into a dense embedding 𝒆𝑖 ∈ R𝑑 through a 1-layer feedforward network FFN1
𝒆𝑖 = FFN1 (𝒄𝑖) = ReLU(𝑾1𝒄𝑖 + 𝒃1), where 𝑾1 ∈ R𝑑×𝑚, 𝒃1 ∈ R^d - 𝑬 = [𝒆1,…, 𝒆𝑚] ∈ R^(𝑑×m), d-dim dense representation for m unique diagnosis codes
- For the 𝑖-th visit, we obtain a dense embedding set 𝑺𝑖 = [𝒔1,…,𝒔𝑚] where 𝒔𝑗 = 𝒆𝑗 if 𝒉𝑖𝑗 = 1 to reflect the existence of a certain symptom or disease, otherwise 𝒔𝑗 = 0
- Still, 𝑺𝑖 ∈ R𝑑×m is redundant for the learning process. Now HAM extracts latent information for each visit and represents it as
𝒉¯𝑖 ∈ R𝑑 - To extract latent information of visits HAM uses a 3-layer feedforward network (FFN_2). FFN_2 learns the attention weight of each dense embedding 𝑺𝑖 and attends them together.
- We get an attention score 𝛼𝑖 ∈ R for each diagnosis code (𝛼𝑖 = FFN2 (𝒔𝑖)), if 𝒔𝑖 = 0, we set 𝛼𝑖 = −∞. Normalizing the attention score with softmax:
𝑎𝑖 = exp(𝛼𝑖)/( Σ𝑗=1tom exp(𝛼𝑗) ), here 𝑎𝑖 is normalized weight - Now we obtain a single embedding 𝒉¯𝑖 for the 𝑖-th visit
(𝒉¯𝑖 = Σ𝑖=(1 to m) 𝑎𝑖 · 𝒔𝑖).As a result, in the hierarchy of diagnosis codes, we gain a set of attended features𝑯¯ = [𝒉¯1,…, 𝒉¯𝑛] ∈ R𝑑×𝑛for a patient ‘p’.
TAM (In Hierarchy of Diagnosis Code):
Purpose:
TAM aggregates the visit embedding with two kinds of temporal information from global and temporal structures. When features of all visits are put into TAM,
- It models long-term dependencies in global structure by Transformer such as how each visit relates to others in a patient’s complete medical journey.
- Short-term correlations in local structure by convolutional layer such as how every visit relates to others in a short time period.
Implementation:
- TAM in Short-term Correlations Modelling by Convolution: It filters out the noise coming from irrelevant diagnosis codes is to extract the correlated disease progression information in each stage for temporal aggregation
2. TAM in Long-term Dependencies Modelling by Transformer:
a. Transformer attends all visit features in parallel and does not obscure the details of each feature
b. We use a multi-head self-attention mechanism in Transformer for feature attending, and the Transformer encoder in TAM has 𝑙 layers, where the computations are the same in each layer
c. Add positional encoding into the 𝑖-th input visit, 𝒉¯𝑡 𝑖 = 𝒉¯𝑖 + 𝒕I, where 𝒕𝑖 is the positional encoding
d. Each layer of the Transformer has ‘ℎ’ head,
The two temporal information are both beneficial to the robustness of learned features, so we concatenate 𝒉¯𝑔 𝑖 and 𝒉¯𝑙 𝑖 to get a feature 𝒉𝑖 ∈ R2𝑑 for risk prediction,
𝒉𝑖 = Concate(𝒉¯𝑔 𝑖 , 𝒉¯𝑙 𝑖)
Finally, TAM outputs a matrix 𝑯 = [𝒉~1,…, 𝒉~𝑛] ∈ R2𝑑×n
HAM (In Hierarchy of Visit):
Purpose:
In the hierarchy of visits, we should pay attention to the correlations among visits. It captures the temporal patterns of disease. Filtering out noise by extracting local temporal correlations among neighboring visits and utilizing the long-term dependencies information.
It focuses on extracting overall semantics from all the visits.
Implementation:
- Similar to HAM in the hierarchy of diagnosis code, it first employs a 3-layer feedforward network FFN4 to learn attention scores 𝛽𝑖 ∈ R,
𝛽𝑖 = FFN4 ( 𝒉𝑖). - We then get the normalized attention weights 𝑏𝑖 ∈ R with softmax function
b𝑖 = exp(𝛽𝑖)/( Σ𝑗 =1m exp(𝛽𝑗) - The comprehensive feature 𝒙 ∈ R2𝑑 for risk prediction is learned by the attention mechanism, where
𝒙 = Σ𝑖=1n (𝑏𝑖 · 𝒉~𝑖)
Classifier:
- Finally, we utilize 𝒙 for risk prediction, 𝑦ˆ = 𝜎(𝒘T𝒙 + 𝑏), where 𝒘 ∈ R2d and b ∈ R
- With the training set T, we use binary cross-entropy loss L to train the model and get the learned parameters 𝜽
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.