
Sensemaking at Scale: Navigating Current Trends in Computer Vision
A survey of recent developments in vision and multimodal models along with considerations for leaders as they position their organizations to capitalize on the coming wave of AI fueled change.
I. Introduction
The past 18 months have ushered in tremendous change that is disrupting the very nature of work. Generative Artificial Intelligence (GenAI), Large Language Models (LLMs), and foundation models have become ubiquitous in vernacular. These models, containing billions of parameters and trained on massive amounts of data using self-supervised methods, are performing complex natural language tasks and exhibiting more generalized intelligence compared to earlier models [i][ii]; fueling unparallel productivity gains across diverse industries through numerous use cases such as personalized customer care and self-service [iii], knowledge management [iv] and content creation [v], research and development [vi], fraud detection [vii][viii], language translation [ix], and even forecasting of life expectancy [x].
Closely following in this wake are emerging developments in computer vision methods and approaches. At the forefront of this shift are advancements in vision transformer (ViT) architectures that are propelling computer vision capabilities into unprecedented levels of sophistication. Awareness of the rapid development and maturation of these capabilities is crucial to navigating the rapidly evolving AI landscape. Now, more than ever, defense leaders need to understand and harness these capabilities within Processing, Exploitation, and Dissemination (PED) and mission planning workflows to enable sensemaking at scale.
II. Rise of the Vision Transformer Architecture
Convolutional neural networks (CNNs) [xi] have traditionally held dominance within computer vision, demonstrating high performance on common tasks such as image classification, object detection, and segmentation. However, training such models requires significant amounts of labeled data for supervised learning, a highly labor-intensive task that is challenging to scale and slow to adapt to dynamic changes in the environment or requirements. Furthermore, the labeled datasets that do exist in the public domain may frequently be unsuitable to the unique use cases and/or imagery types that exist within the national security domain.
Recent years have seen the inception of the ViT architecture as a leading contender in the computer vision arena. The power of ViTs is in their ability to decompose images into fixed size patches and encode these fragments into a linear sequence of embeddings that capture semantic representations, similar to a sentence that describes the image. The ViT then sequentially understands each fragment, applying multi-head self-attention to recognize patterns and capture relationships globally across all fragments, to build a coherent understanding of the image [xii].
This results in several benefits over CNNs. First and foremost, ViTs are shown to demonstrate performance that matches or exceeds the state of the art compared to CNNs on many image classification datasets when trained on large quantities of data (e.g., 14 million — 300 million images). This level of performance is achieved while requiring 2–4 times less compute to train. In addition, ViTs can natively handle images of varying dimension due to their ability to process arbitrary sequence lengths (within memory constraints). Lastly, ViTs can capture long-range dependencies between inputs and provide enhanced scalability over CNNs. ViTs do have some limitations in comparison to CNNs. ViTs are unable to generalize well when trained on insufficient data due to lacking strong inductive biases, such as translation equivariance and locality. As a result, CNNs outperform ViTs on smaller datasets. However, when considering the scaling challenges present within DoD, ViTs show promise as an architecture to lead in this space.
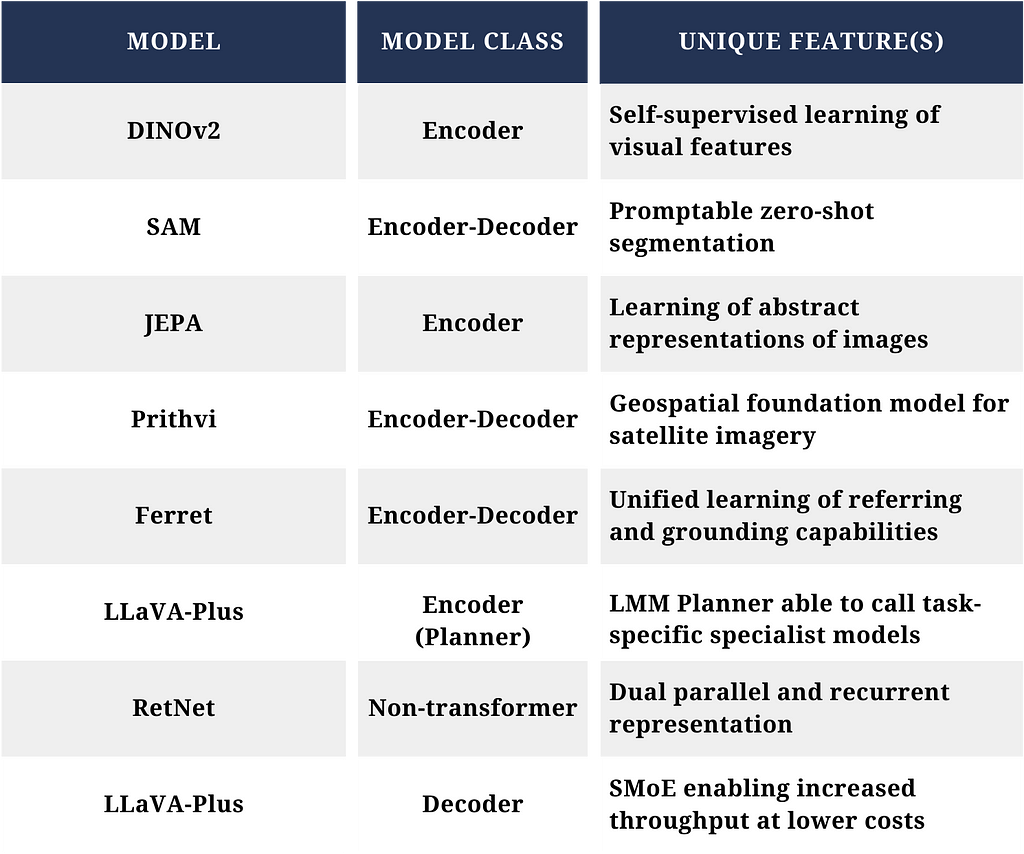
2023 saw several computer vision advances leveraging ViT architectures. While in no way exhaustive, four models that highlight the rapid evolution of computer vision are Distillation of Knowledge with No Labels Version 2 (DINOv2), the Segment Anything Model (SAM), the Joint-Embedding Predictive Architecture (JEPA), and the Prithvi geospatial foundation model.
DINOv2 [xiii] leverages two concepts that advanced computer vision. The first concept is that of self-supervised learning of visual features directly from images, removing the need for large quantities of labels to support model training. Central to this approach is DINOv2’s data processing pipeline, which clusters images from a large uncurated dataset with images from a smaller curated dataset through a self-supervised retrieval system. This process results in the ability to create a large augmented curated dataset without a drop in quality, a key hurdle that must be crossed in scaling image foundation models. Additionally, DINOv2 employs a teacher-student distillation method to transfer knowledge from a large model to smaller models. At a high level, this approach works by freezing the weights of the large model with the goal of minimizing the differences between the embeddings coming from the smaller models with that of the larger model. This method is shown to achieve better performance than attempting to train smaller models directly on the data. Once trained, DINOv2 learned features demonstrate very good transferability across domains and the ability understand relations between similar parts of different objects. This results in an image foundation model whose outputs can be used by multiple downstream models for specific tasks.
SAM [xiv] is an image segmentation foundation model capable of promptable zero-shot segmentation of unfamiliar objects and images, without the need for additional training. This is accomplished through an architecture with three components: a ViT image encoder, a prompt encoder able to support both sparse (e.g., points, boxes, text) and dense (i.e., mask) prompts, and a fast mask decoder that efficiently maps the image embedding, prompt embeddings, and an output token to an autogenerated image mask. SAM is not without limitations as it requires large-scale supervised training, can miss fine structures, suffer from minor hallucinations, and may not produce boundaries as crisp as other methods. However, initial efforts present opportunity to address mission use cases that require the ability to segment objects in imagery.
Originally adapted to image tasks, JEPA [xv] is the first computer vision architecture designed to address critical shortcomings in existing ML systems needed to reach human levels of learning and understanding of the external world [xvi]. JEPA attempts to overcome limitations with current self-supervised learning methods (e.g., invariance-based methods, generative methods) through predicting missing image information in an abstract representation space. In practice, this is performed by predicting the representations (e.g., embeddings) of various target blocks (e.g., tail, legs, ears) in an image based on being provided a single context block (e.g., body and head of a dog). By predicting semantic representations of target blocks, without explicitly predicting the image pixels, JEPA is able to more closely replicate how humans predict missing parts of an image. More importantly, JEPA’s performance is comparable with invariance-based methods on semantic tasks, performs better on low-level vision tasks (e.g., object counting), and demonstrates high scalability and computational efficiency. This model architecture is continuing to be advanced with the introduction of latent variable energy-based models [xvii] to achieve multimodal predictions in high-dimensional problems with significant uncertainty (e.g., autonomous system navigation) and has recently been adapted to video [xviii].
Lastly, IBM, through a public/private partnership involving NASA and IBM Research, developed the first open-source geospatial foundation model for remote sensing data called Prithvi [xix]. Model development leveraged a First-of-a-Kind framework to build a representative dataset of raw multi-temporal and multi-spectral satellite images that avoided biases toward the most common geospatial features and removed noise from cloud cover or missing data from sensor malfunctions. This dataset was then used for self-supervised foundation model pretraining using an encoder-decoder architecture based on the masked autoencoder (MAE) [xx] approach. Prithvi was subsequently fined tuned using a small set of labeled images for specific downstream tasks, such as multi-temporal cloud imputation, flood mapping, fire-scar segmentation, and multi-temporal crop segmentation. Importantly, Prithvi is shown to generalize to different resolutions and geographic regions from the entire globe using a few labeled data during fine-tuning and is being used to convert NASA’s satellite observations into customized maps of natural disasters and other environmental changes.
III. Rapid Evolution: AI Trends in Flux
2023 also introduced the convergence of LLMs and ViTs (along with other modes) into Large Multimodal Models (LMMs), also referred to as vision language models (VLM) or multimodal large language models (MLLM). The strength of these models lies in their ability to combine the understanding of text with the interpretation of visual data [xxi]. However, this is not without challenges as training large multimodal models in an end-to-end manner would be immensely costly and risk catastrophic forgetting. In practice, training such models generally involves a learnable interface between a pre-trained visual encoder and an LLM [xxii].
Several influential models were released, to include Google’s PALM-E [xxiii] robotics vision-language model with state-of-the-art performance on the Outside Knowledge Visual Question Answering (OK-VQA) benchmark without task-specific fine tuning and the recently released Gemini [xxiv] family of models, trained multimodally over videos, text, and images. In addition, Meta released ImageBind [xxv], an LMM that learns a joint embedding across six different modalities (i.e., images, text, audio, depth perception, thermal, and inertial measurement unit (IMU) data). Two models, in particular, highlight the rapid evolution in this space.
The first of these is Apple’s Ferret [xxvi] model, which can address the problem of enabling spatial understanding in vision-language learning. It does so through unified learning of referring (the ability to understand the semantics of a specific point or region in an image) and grounding (the process of using LLMs with relevant, use-case specific external information) capabilities within large multimodal models. This model elevates multimodal vision and language capabilities one step closer to the way humans process the world through seamless integration of referring and grounding capabilities with dialogue and reasoning. To achieve results, Ferret was trained via GRIT, a Ground-and-Refer Instruction-Tuning dataset with 1.1M samples including grounding (i.e., text-in location-out), referring (location-in text-out), and mixed (text/location-in text/location-out) data covering multiple levels of spatial knowledge. The model was then evaluated on tasks jointly requiring referring/grounding, semantics, knowledge, and reasoning, demonstrating superior performance when evaluated on conventional referring and grounding tasks while reducing object hallucinations.
The second of these is Large Language and Vision Assistants that Plug and Learn to Use Skills (LLaVA-Plus) [xxvii], a general-purpose multimodal assistant that was released in late 2023 and built upon the initial LLaVA [xxviii] model released earlier in the year. The design of LLaVA-Plus was influenced by the Society of Mind theory of natural intelligence [xxix], in which emergent capabilities arise from combination of individual task or skill specific tools. The modularized system architecture presents a novel approach that allows an LMM, operating as a planner, to learn a wide range of skills. This enables the expansion of capabilities and interfaces at scale through leveraging a repository of vision and vision-language specialist models as tools for use when needed. This facilitates not only user-oriented dialogues, where the model immediately responds to user instruction using innate knowledge, but also skill-oriented dialogues where the LMM can initiate requests to call the appropriate specialist model in response to an instruction to accomplish a task. While there are limitations due to hallucinations and tool use conflicts in practice, LLaVA-Plus is an innovative step to new methods for human-computer teaming through multimodal AI agents.
Lastly, as exciting as these developments are, one would be remiss without mentioning experimentation with emerging architectures that have the potential to revolutionize the field some more. The first architecture is the Rententive Network [xxx] (RetNet), a novel architecture that is a candidate to supersede the transformer as the dominant architecture for computer vision, language, and multimodal foundation models. RetNets demonstrate benefits seen in transformers and recurrent neural networks, without some of the drawbacks of each. These include training parallelism, low cost inference, and transformer-comparable performance with efficient long-sequence modeling. RetNets substitute conventional multi-head attention, used within transformers, with a multi-scale retention mechanism that is able to fully utilize GPUs and enable efficient O(1) inference in terms of memory and compute.
The second is IBM’s recently released Mixtral 8x7B [xxxi] model, a decoder-only Sparse Mixture of Experts (SMoE) language model where each layer of the model is composed of eight feedforward blocks that act as experts. This novel architecture achieves faster inference speeds with superior cost-performance, using only 13B active parameters for each token at inference. It does so through an approach where each token is evaluated by two experts at a given timestep. However, these two experts can vary at each timestep, enabling each token to access the full sparse parameter count at 47B parameters. Of note, the model retains a higher memory cost that is proportional to the sparse parameter count. This model architecture confers tremendous benefits. At one tenth of the parameters, Mixtral 8x7B is able to match or exceed the performance of LLAMA 2 70B and GPT-3.5 (175B parameters) on most benchmarks. In addition, the cost efficiencies of this model are conducive to deployment and inference on tactical infrastructure, where compute, size, and weight constraints are a factor.
Although diverse and developed to accomplish different tasks, the models covered here illustrate the many innovation pathways that are being traversed in advancing AI capabilities. Of note, are the difference model classes (e.g., encoder only, encoder-decoder, decoder only) that are employed across the various models. A future effort may be to explore if there are performance benefits or tradeoffs due to class based on the task.
As these capabilities continue to mature, we will likely see a combining of features within models as certain features become expectations for performance. There will also be a shift towards creation of a multi-model ecosystem in recognition that one size does not fit all. Instead, AI agents acting as planners, orchestrators, and teammates will collaborate to dynamically select the best specialist model or tool for the task based on use case or Persona of Query driven needs [xxxii].
IV. Challenges and Risks
While the previous survey of model advancements helps illustrate the increasing rate of change within this field spurred by advancements in generative AI and foundation models, there are several challenges that cannot be overlooked as Federal organizations consider how to employ these capabilities. For the purposes of this section, we reference research primarily addressing LLMs. This was a deliberate choice to highlight risks inherent to models that leverage the autoregressive transformer architecture.
First, is the issue of resource constraints, both for enterprise training and inferencing of models and for model training and inferencing at the edge. The rise of ever larger AI models encompassing multiple billions of parameters is leading to strained resources due to infrastructure costs for compute, specialized AI talent needed to implement capabilities, and the challenges associated with amassing, curating, and training on the colossal data volumes required for such models. Such challenges can translate into financial shocks to organizational budgets that may have been set in the years prior due to the need to run high performance servers equipped with GPUs or attract and retain top AI talent. Additionally, there is an increasing need to perform training, retraining, and inferencing of models at the edge to support the processing, exploitation, and dissemination of detections of multimodal data. This requires the ability to run models on smaller hardware (e.g., human packable devices, onboard autonomous systems or sensors), where size, weight, and power are significant considerations.
The second of these is the issue of trustworthiness. To rely on generative AI and foundation models within mission critical workflows, one must be able to trust the output of such models. As such, the trustworthiness of models is of paramount concern. Much of the discourse on this topic has focused on hallucinations within the output, as well as attempts to define a broad set of dimensions against which to measure trustworthiness [xxxiii][xxxiv]. While these are valid concerns, trustworthiness extends beyond these dimensions to also include ensuring that the model arrives at the best possible outcome based on the latest corpus of data and training. One must be able to trust that the outcome is a global maximum in terms of suitability for the task, as opposed to a local maximum, which could have real world impacts if embedded into a mission critical workflow.
Third, and likely the most daunting, is that of security and privacy. To be able to leverage generative AI within Federal environments, one must be able to do so without compromise to the network and the data that resides on that network. Research has shown that LLMs can pose risks security and privacy and such vulnerabilities can be grouped into AI model inherent vulnerabilities (e.g., data poisoning backdoor attacks, training data extraction) and non-AI model inherent vulnerabilities (e.g., remote code execution, prompt injection, side channel attacks). To date, LLMs have been predominantly used in user level attacks such as disinformation, misinformation, and social engineering [xxxv], although new attacks continue to appear. For example, it has been shown that one can train deceptive LLMs able to switch their behavior from trusted to malicious in response to external events or triggers, eluding initial risk evaluation and creating a false sense of trust before attacking [xxxvi]. In addition, 2024 heralded the creation of AI worms [xxxvii] that can steal data and spread malware and spam. Such an attack uses an adversarial self-replicating prompt embedded within multimodal media files (e.g., text, image, audio) to effectively jailbreak and task the target LLM. Should future LLM/LMMs be given access to operating system and hardware-level functions, then threats from these vectors could escalate dramatically.
These challenges aren’t without opportunities. NIST recently released the inaugural version of its Artificial Intelligence Risk Management Framework [xxxviii] to aid with mitigating the risks related to AI. However, the nascent nature of this field means that much still remains unknown. Couple this with the fact that rigidity and bureaucracy within the RMF process means that, in some cases, by the time technology is approved for use and operationalized, it may be one or two generations behind state-of-the-art capabilities. Organizations face a challenge of how do they operationalize technology using a process that may take 9–12 months to complete when that same technology may be surpassed within six months.
V. Human-AI Collaboration: Redefining the Workforce
As AI trends continue to advance, this will have a profound impact on the dynamics of the workforce. Collaboration between humans and AI systems will become the norm as those who are able and willing to partner with AI will experience increased efficiency, innovation, and effectiveness. Supported by autonomous or semi-autonomous actions by AI agents [xxxix], human-AI teams will reshape how we make sense of and interact with the world.
AI will also play a pivotal role in transforming job roles and skill requirements. The workforce will need to adapt to this shift by acquiring new skills and competencies that complement, not compete with, AI’s capabilities and strengths. There will be a growing need for professionals who can effectively manage and collaborate with AI systems and other human-AI teams, increasing the demand for soft skills such as emotional intelligence, critical thinking, and creativity.
This evolution in skill sets will require changes in organizational talent programs to ensure training of the incoming workforce aligns to near-term and long-term organizational needs in AI. In addition to focusing on incoming professionals, organizations must prioritize upskilling and reskilling of the existing workforce to move the organization as a whole through the transformation journey to embrace this new AI era. While not covered in depth in this article, this topic is one that must be carefully considered to promote AI adoption in ways that take into account ethical considerations and ensure that AI systems are designed and implemented responsibly.
VI. Future Outlook and Recommendations
The pace of technological change will continue to accelerate over the next 18-month horizon. The precise path of this change is unpredictable, as each advancing month gives way to new developments that reframe the world’s understanding of the art of the possible. As breathtaking as some recent capabilities are, these technologies are still in a nascent stage. To have business and mission value, the maturation and commercialization of generative AI capabilities must continue, which will take some time.
In addition, Generative AI remains experimental and has not yet been operationalized for critical mission application. As organizations consider how to move forward with using the tremendous power of generative AI and foundation models, any strategy must be based upon a High OPTEMPO Concurrency where one is simultaneously experimenting with the newest technology, developing and training on a continuous basis in the mode of “Always in a State of Becoming” [xl]. To do so, organizations must be willing to accept additional risk, but also make use of emerging technologies to modernize existing methods. For example, LLMs have been shown to identify security vulnerabilities in code with greater effectiveness than leading commercial tools using traditional methods. Such methods can be used to enhance speed and efficacy in detecting vulnerable and malicious code as part of the RMF process [xli].
Posturing oneself to capitalize on AI advancements, especially in the realm of computer vision, necessitates that leaders within the organization become versed and remain current on rapidly progressing developments in AI. As part of their strategy, organizations should consider how to invest in the infrastructure and data foundation that will enable an AI-first future. This includes building modern data architectures and approaches to facilitate the rapid exchange of information as well as machine manipulation of data and services required to support automated discovery, understanding, and actions on the data. Moreover, organizations need to begin regular experimentation now in order to build the organizational capacity and learning needed for the future.
VII. Conclusion
As we progress through the remainder of the year, the trajectory of technological advancement is poised to surge into uncharted realms of what’s possible with AI. The advent of increasingly intricate multimodal models will revolutionize human-AI collaboration. Interactive analysis and interrogation of multimodal data, coupled with autonomous or semi-autonomous actions by AI agents and heightened reasoning capabilities derived from models able to create internal representations of the external world, will redefine operational landscapes.
The imperative to wield these capabilities to understand and decipher vast pools of visual and multimodal data, critical to national security, will define the latter half of this decade. Navigating this transformative era necessitates a forward-thinking mindset, the courage to increase one’s risk appetite, and the resilience to shape organizational strategy and policy to capitalize on the coming wave of change. As such, leaders must adopt a proactive stance in integrating AI, while placing an emphasis on its responsible deployment. Doing so will enable organizations to harness the full potential of evolving AI technologies.
All views expressed in this article are the personal views of the author.
References:
[i] S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. Lee, Y. Li, S. Lundberg, H. Nori, H. Palangi, M. Ribeiro, Y. Zhang, “Sparks of Artificial General Intelligence: Early experiments with GPT-4,” arXiv:2303.12712, 2023. 13, 92
[ii] H. Naveed, A. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, A. Mian, “A Comprehensive Overview of Large Language Models,” arXiv:2307.06435, 2023. 1, 2, 3, 4
[iii] K. Pandya, M. Holia, “Automating Customer Service using LangChain: Building custom open-source GPT Chatbot for organizations,” arXiv:2310.05421, 2023. 1, 2
[iv] S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, X. Wu, “Unifying Large Language Models and Knowledge Graphs: A Roadmap,” arXiv:2306.08302, 2023. 1, 2
[v] Z. Xie, T. Cohn, J. Lau, “The Next Chapter: A Study of Large Language Models in Storytelling,” arXiv:2301.09790, 2023. 1, 2
[vi] Microsoft Research AI4Science, Microsoft Azure Quantum, “The Impact of Large Language Models on Scientific Discovery: a Preliminary Study using GPT-4,” arXiv:2311.07361, 2023. 4, 5
[vii] A. Shukla, L. Agarwal, J. Goh, G. Gao, R. Agarwal, “Catch Me If You Can: Identifying Fraudulent Physician Reviews with Large Language Models Using Generative Pre-Trained Transformers,” arXiv:2304.09948, 2023. 15, 16, 17
[viii] Z. Guo, S. Yu, “AuthentiGPT: Detecting Machine-Generated Text via Black-Box Language Models Denoising,” arXiv:2311.07700, 2023. 3, 4, 5
[ix] H. Xu, Y. Kim, A. Sharaf, H. Awadalla, “A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models,” arXiv:2309.11674, 2023. 2, 3
[x] G. Savcisens, T. Eliassi-Rad, L. Hansen, L. Mortensen, L. Lilleholt, A. Rogers, I. Zettler, S. Lehmann, “Using Sequences of Life-events to Predict Human Lives,” arXiv:2306.03009, 2023. 3, 4, 5
[xi] K. O’Shea, R. Nash, “An Introduction to Convolutional Neural Networks,” arXiv:1511.08458, 2015. 3, 4, 5, 6, 7, 8
[xii] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” arXiv:2010.11929, 2021. 2, 3, 4, 7, 8, 9
[xiii] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, P. Bojanowski, “DINOv2: Learning Robust Visual Features without Supervision,” arXiv:2304.07193. 2023, 2, 4, 15, 20
[xiv] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. Berg, W. Lo, P. Dollár, R. Girshick, “Segment Anything,” arXiv:2304.02643. 2023, 5, 12
[xv] M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, N. Ballas, “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture,” arXiv:2301.08243. 2023, 1, 2, 3, 4, 5, 6
[xvi] Y. LeCun, “A Path Towards Autonomous Machine Intelligence,” OpenReview.net. Version 0.9.2, 2022–06–27
[xvii] A. Dawid, Y. LeCun, “Introduction to Latent Variable Energy-Based Models: A Path Towards Autonomous Machine Intelligence,” arXiv:2306.02572. 2023, 8, 9, 10, 11, 12
[xviii] A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y. LeCun, M. Assran, N. Ballas, “V-JEPA: Latent Video Prediction for Visual Representation Learning,” OpenReview.net. 2024–02–10
[xix] J. Jakubik, S. Roy, C. Phillips, P. Fraccaro, D. Godwin, B. Zadrozny, D. Szwarcman, C. Gomes, G. Nyirjesy, B. Edwards, D. Kimura, N. Simumba, L. Chu, S. Mukkavilli, D. Lambhate, K. Das, R. Bangalore, D. Oliveira, M. Muszynski, K. Ankur, M. Ramasubramanian, I. Gurung, S. Khallaghi, H. Li, M. Cecil, M. Ahmadi, F. Kordi, H. Alemohammad, M. Maskey, R. Ganti, K. Weldemariam, R. Ramachandran, “Foundation Models for Generalist Geospatial Artificial Intelligence,” arXiv:2310.18660. 2023, 2, 3, 4, 6, 21
[xx] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” arXiv:2111.06377. 2021, 3, 4
[xxi] R. Hamadi, “Large Language Models Meet Computer Vision: A Brief Survey,” arXiv:2311.16673. 2023, 4
[xxii] S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, E. Chen, “A Survey on Multimodal Large Language Models,” arXiv:2306.13549. 2023, 5
[xxiii] D. Driess, F. Xia, M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y. Chebotar, P. Sermanet, D. Duckworth, S. Levine, V. Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, P. Florence, “PaLM-E: An Embodied Multimodal Language Model,” arXiv:2303.03378. 2023, 1, 2, 3, 6
[xxiv] S. Akter, Z. Yu, A. Muhamed, T. Ou, A. Bäuerle, Á. Cabrera, K. Dholakia, C. Xiong, G. Neubig, “An In-depth Look at Gemini’s Language Abilities,” arXiv:2312.11444. 2023, 2
[xxv] R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. Alwala, A. Joulin, I. Misra, “ImageBind: One Embedding Space To Bind Them All,” arXiv:2305.05665. 2023, 1, 2, 3, 4
[xxvi] H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S. Chang, Y. Yang, “Ferret: Refer and Ground Anything Anywhere at Any Granularity,” arXiv:2310.07704. 2023, 1, 2
[xxvii] S. Liu, H. Cheng, H. Liu, H. Zhang, F. Li, T. Ren, X. Zou, J. Yang, H. Su, J. Zhu, L. Zhang, J. Gao, C. Li, “LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents,” arXiv:2311.05437. 2023, 1, 2, 3, 4, 5, 6
[xxviii] H. Liu, C. Li, Q. Wu, Y. Lee, “Visual Instruction Tuning,” arXiv:2304.08485. 2023, 2, 3, 4, 5
[xxix] M. Minsky, Society of Mind, Simon and Schuster. 1988
[xxx] Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, F. Wei, “Retentive Network: A Successor to Transformer for Large Language Models,” arXiv:2307.08621. 2023, 2, 3, 4, 5
[xxxi] A. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. Chaplot, D. de las Casas, E. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. Lavaud, L. Saulnier, M. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. Le Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, W. El Sayed, “Mixtral of Experts,” arXiv:2401.04088. 2024, 1, 2, 3
[xxxii] M. Zhuge, H. Liu, F. Faccio, D. Ashley, R. Csordás, A. Gopalakrishnan, A. Hamdi, H. Hammoud, V. Herrmann, K. Irie, L. Kirsch, B. Li, G. Li, S. Liu, J. Mai, P. Piękos, A. Ramesh, I. Schlag, W. Shi, A. Stanić, W. Wang, Y. Wang, M. Xu, D. Fan, B. Ghanem, J. Schmidhuber, “Mindstorms in Natural Language-Based Societies of Mind,” arXiv:2305.17066. 2023, 1, 2, 3, 4
[xxxiii] L. Sun, Y. Huang, H. Wang, S. Wu, Q. Zhang, C. Gao, Y. Huang, W. Lyu, Y. Zhang, X. Li, Z. Liu, Y. Liu, Y. Wang, Z. Zhang, B. Kailkhura, C. Xiong, C. Xiao, C. Li, E. Xing, F. Huang, H. Liu, H. Ji, H. Wang, H. Zhang, H. Yao, M. Kellis, M. Zitnik, M. Jiang, M. Bansal, J. Zou, J. Pei, J. Liu, J. Gao, J. Han, J. Zhao, J. Tang, J. Wang, J. Mitchell, K. Shu, K. Xu, K. Chang, L. He, L. Huang, M. Backes, N. Gong, P. Yu, P. Chen, Q. Gu, R. Xu, R. Ying, S. Ji, S. Jana, T. Chen, T. Liu, T. Zhou, W. Wang, X. Li, X. Zhang, X. Wang, X. Xie, X. Chen, X. Wang, Y. Liu, Y. Ye, Y. Cao, Y. Chen, Y. Zhao, “TrustLLM: Trustworthiness in Large Language Models,” arXiv:2401.05561. 2024, 6, 7
[xxxiv] Y. Liu, Y. Yao, J. Ton, X. Zhang, R. Guo, H. Cheng, Y. Klochkov, M. Taufiq, H. Li, “Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models’ Alignment,” arXiv:2308.05374. 2023, 7, 8, 9
[xxxv] Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, Y. Zhang, “A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly,” arXiv:2312.02003. 2024 1, 2
[xxxvi] E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDiarmid, T. Lanham, D. Ziegler, T. Maxwell, N. Cheng, A. Jermyn, A. Askell, A. Radhakrishnan, C. Anil, D. Duvenaud, D. Ganguli, F. Barez, J. Clark, K. Ndousse, K. Sachan, M. Sellitto, M. Sharma, N. DasSarma, R. Grosse, S. Kravec, Y. Bai, Z. Witten, M. Favaro, J. Brauner, H. Karnofsky, P. Christiano, S. Bowman, L. Graham, J. Kaplan, S. Mindermann, R. Greenblatt, B. Shlegeris, N. Schiefer, E. Perez, “Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training,” arXiv:2401.05566. 2024, 1, 2, 3, 4, 5, 6
[xxxvii] S. Cohen, R. Bitton, B. Nassi, “ComPromptMized: Unleashing Zero-click Worms that Target GenAI-Powered Applications,” https://sites.google.com/view/compromptmized. 2024
[xxxviii] National Institute of Standards and Technology, “Artificial Intelligence Risk Management Framework (AI RMF 1.0),” https://doi.org/10.6028/NIST.AI.100-1. 2023
[xxxix] J. Park, J. O’Brien, C. Cai, M. Morris, P. Liang, M. Bernstein, “Generative Agents: Interactive Simulacra of Human Behavior,” arXiv:2304.03442. 2023, 1, 2, 3
[xl] Concept referenced from Greg Porpora, IBM Distinguished Engineer on 21 February, 2024.
[xli] Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, Y. Zhang, “A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly,” arXiv:2312.02003. 2024 1, 2
Sensemaking at Scale: Navigating Current Trends in Computer Vision was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
A survey of recent developments in vision and multimodal models along with considerations for leaders as they position their organizations to capitalize on the coming wave of AI fueled change.

I. Introduction
The past 18 months have ushered in tremendous change that is disrupting the very nature of work. Generative Artificial Intelligence (GenAI), Large Language Models (LLMs), and foundation models have become ubiquitous in vernacular. These models, containing billions of parameters and trained on massive amounts of data using self-supervised methods, are performing complex natural language tasks and exhibiting more generalized intelligence compared to earlier models [i][ii]; fueling unparallel productivity gains across diverse industries through numerous use cases such as personalized customer care and self-service [iii], knowledge management [iv] and content creation [v], research and development [vi], fraud detection [vii][viii], language translation [ix], and even forecasting of life expectancy [x].
Closely following in this wake are emerging developments in computer vision methods and approaches. At the forefront of this shift are advancements in vision transformer (ViT) architectures that are propelling computer vision capabilities into unprecedented levels of sophistication. Awareness of the rapid development and maturation of these capabilities is crucial to navigating the rapidly evolving AI landscape. Now, more than ever, defense leaders need to understand and harness these capabilities within Processing, Exploitation, and Dissemination (PED) and mission planning workflows to enable sensemaking at scale.
II. Rise of the Vision Transformer Architecture
Convolutional neural networks (CNNs) [xi] have traditionally held dominance within computer vision, demonstrating high performance on common tasks such as image classification, object detection, and segmentation. However, training such models requires significant amounts of labeled data for supervised learning, a highly labor-intensive task that is challenging to scale and slow to adapt to dynamic changes in the environment or requirements. Furthermore, the labeled datasets that do exist in the public domain may frequently be unsuitable to the unique use cases and/or imagery types that exist within the national security domain.
Recent years have seen the inception of the ViT architecture as a leading contender in the computer vision arena. The power of ViTs is in their ability to decompose images into fixed size patches and encode these fragments into a linear sequence of embeddings that capture semantic representations, similar to a sentence that describes the image. The ViT then sequentially understands each fragment, applying multi-head self-attention to recognize patterns and capture relationships globally across all fragments, to build a coherent understanding of the image [xii].
This results in several benefits over CNNs. First and foremost, ViTs are shown to demonstrate performance that matches or exceeds the state of the art compared to CNNs on many image classification datasets when trained on large quantities of data (e.g., 14 million — 300 million images). This level of performance is achieved while requiring 2–4 times less compute to train. In addition, ViTs can natively handle images of varying dimension due to their ability to process arbitrary sequence lengths (within memory constraints). Lastly, ViTs can capture long-range dependencies between inputs and provide enhanced scalability over CNNs. ViTs do have some limitations in comparison to CNNs. ViTs are unable to generalize well when trained on insufficient data due to lacking strong inductive biases, such as translation equivariance and locality. As a result, CNNs outperform ViTs on smaller datasets. However, when considering the scaling challenges present within DoD, ViTs show promise as an architecture to lead in this space.
2023 saw several computer vision advances leveraging ViT architectures. While in no way exhaustive, four models that highlight the rapid evolution of computer vision are Distillation of Knowledge with No Labels Version 2 (DINOv2), the Segment Anything Model (SAM), the Joint-Embedding Predictive Architecture (JEPA), and the Prithvi geospatial foundation model.
DINOv2 [xiii] leverages two concepts that advanced computer vision. The first concept is that of self-supervised learning of visual features directly from images, removing the need for large quantities of labels to support model training. Central to this approach is DINOv2’s data processing pipeline, which clusters images from a large uncurated dataset with images from a smaller curated dataset through a self-supervised retrieval system. This process results in the ability to create a large augmented curated dataset without a drop in quality, a key hurdle that must be crossed in scaling image foundation models. Additionally, DINOv2 employs a teacher-student distillation method to transfer knowledge from a large model to smaller models. At a high level, this approach works by freezing the weights of the large model with the goal of minimizing the differences between the embeddings coming from the smaller models with that of the larger model. This method is shown to achieve better performance than attempting to train smaller models directly on the data. Once trained, DINOv2 learned features demonstrate very good transferability across domains and the ability understand relations between similar parts of different objects. This results in an image foundation model whose outputs can be used by multiple downstream models for specific tasks.
SAM [xiv] is an image segmentation foundation model capable of promptable zero-shot segmentation of unfamiliar objects and images, without the need for additional training. This is accomplished through an architecture with three components: a ViT image encoder, a prompt encoder able to support both sparse (e.g., points, boxes, text) and dense (i.e., mask) prompts, and a fast mask decoder that efficiently maps the image embedding, prompt embeddings, and an output token to an autogenerated image mask. SAM is not without limitations as it requires large-scale supervised training, can miss fine structures, suffer from minor hallucinations, and may not produce boundaries as crisp as other methods. However, initial efforts present opportunity to address mission use cases that require the ability to segment objects in imagery.
Originally adapted to image tasks, JEPA [xv] is the first computer vision architecture designed to address critical shortcomings in existing ML systems needed to reach human levels of learning and understanding of the external world [xvi]. JEPA attempts to overcome limitations with current self-supervised learning methods (e.g., invariance-based methods, generative methods) through predicting missing image information in an abstract representation space. In practice, this is performed by predicting the representations (e.g., embeddings) of various target blocks (e.g., tail, legs, ears) in an image based on being provided a single context block (e.g., body and head of a dog). By predicting semantic representations of target blocks, without explicitly predicting the image pixels, JEPA is able to more closely replicate how humans predict missing parts of an image. More importantly, JEPA’s performance is comparable with invariance-based methods on semantic tasks, performs better on low-level vision tasks (e.g., object counting), and demonstrates high scalability and computational efficiency. This model architecture is continuing to be advanced with the introduction of latent variable energy-based models [xvii] to achieve multimodal predictions in high-dimensional problems with significant uncertainty (e.g., autonomous system navigation) and has recently been adapted to video [xviii].
Lastly, IBM, through a public/private partnership involving NASA and IBM Research, developed the first open-source geospatial foundation model for remote sensing data called Prithvi [xix]. Model development leveraged a First-of-a-Kind framework to build a representative dataset of raw multi-temporal and multi-spectral satellite images that avoided biases toward the most common geospatial features and removed noise from cloud cover or missing data from sensor malfunctions. This dataset was then used for self-supervised foundation model pretraining using an encoder-decoder architecture based on the masked autoencoder (MAE) [xx] approach. Prithvi was subsequently fined tuned using a small set of labeled images for specific downstream tasks, such as multi-temporal cloud imputation, flood mapping, fire-scar segmentation, and multi-temporal crop segmentation. Importantly, Prithvi is shown to generalize to different resolutions and geographic regions from the entire globe using a few labeled data during fine-tuning and is being used to convert NASA’s satellite observations into customized maps of natural disasters and other environmental changes.
III. Rapid Evolution: AI Trends in Flux
2023 also introduced the convergence of LLMs and ViTs (along with other modes) into Large Multimodal Models (LMMs), also referred to as vision language models (VLM) or multimodal large language models (MLLM). The strength of these models lies in their ability to combine the understanding of text with the interpretation of visual data [xxi]. However, this is not without challenges as training large multimodal models in an end-to-end manner would be immensely costly and risk catastrophic forgetting. In practice, training such models generally involves a learnable interface between a pre-trained visual encoder and an LLM [xxii].
Several influential models were released, to include Google’s PALM-E [xxiii] robotics vision-language model with state-of-the-art performance on the Outside Knowledge Visual Question Answering (OK-VQA) benchmark without task-specific fine tuning and the recently released Gemini [xxiv] family of models, trained multimodally over videos, text, and images. In addition, Meta released ImageBind [xxv], an LMM that learns a joint embedding across six different modalities (i.e., images, text, audio, depth perception, thermal, and inertial measurement unit (IMU) data). Two models, in particular, highlight the rapid evolution in this space.
The first of these is Apple’s Ferret [xxvi] model, which can address the problem of enabling spatial understanding in vision-language learning. It does so through unified learning of referring (the ability to understand the semantics of a specific point or region in an image) and grounding (the process of using LLMs with relevant, use-case specific external information) capabilities within large multimodal models. This model elevates multimodal vision and language capabilities one step closer to the way humans process the world through seamless integration of referring and grounding capabilities with dialogue and reasoning. To achieve results, Ferret was trained via GRIT, a Ground-and-Refer Instruction-Tuning dataset with 1.1M samples including grounding (i.e., text-in location-out), referring (location-in text-out), and mixed (text/location-in text/location-out) data covering multiple levels of spatial knowledge. The model was then evaluated on tasks jointly requiring referring/grounding, semantics, knowledge, and reasoning, demonstrating superior performance when evaluated on conventional referring and grounding tasks while reducing object hallucinations.
The second of these is Large Language and Vision Assistants that Plug and Learn to Use Skills (LLaVA-Plus) [xxvii], a general-purpose multimodal assistant that was released in late 2023 and built upon the initial LLaVA [xxviii] model released earlier in the year. The design of LLaVA-Plus was influenced by the Society of Mind theory of natural intelligence [xxix], in which emergent capabilities arise from combination of individual task or skill specific tools. The modularized system architecture presents a novel approach that allows an LMM, operating as a planner, to learn a wide range of skills. This enables the expansion of capabilities and interfaces at scale through leveraging a repository of vision and vision-language specialist models as tools for use when needed. This facilitates not only user-oriented dialogues, where the model immediately responds to user instruction using innate knowledge, but also skill-oriented dialogues where the LMM can initiate requests to call the appropriate specialist model in response to an instruction to accomplish a task. While there are limitations due to hallucinations and tool use conflicts in practice, LLaVA-Plus is an innovative step to new methods for human-computer teaming through multimodal AI agents.
Lastly, as exciting as these developments are, one would be remiss without mentioning experimentation with emerging architectures that have the potential to revolutionize the field some more. The first architecture is the Rententive Network [xxx] (RetNet), a novel architecture that is a candidate to supersede the transformer as the dominant architecture for computer vision, language, and multimodal foundation models. RetNets demonstrate benefits seen in transformers and recurrent neural networks, without some of the drawbacks of each. These include training parallelism, low cost inference, and transformer-comparable performance with efficient long-sequence modeling. RetNets substitute conventional multi-head attention, used within transformers, with a multi-scale retention mechanism that is able to fully utilize GPUs and enable efficient O(1) inference in terms of memory and compute.
The second is IBM’s recently released Mixtral 8x7B [xxxi] model, a decoder-only Sparse Mixture of Experts (SMoE) language model where each layer of the model is composed of eight feedforward blocks that act as experts. This novel architecture achieves faster inference speeds with superior cost-performance, using only 13B active parameters for each token at inference. It does so through an approach where each token is evaluated by two experts at a given timestep. However, these two experts can vary at each timestep, enabling each token to access the full sparse parameter count at 47B parameters. Of note, the model retains a higher memory cost that is proportional to the sparse parameter count. This model architecture confers tremendous benefits. At one tenth of the parameters, Mixtral 8x7B is able to match or exceed the performance of LLAMA 2 70B and GPT-3.5 (175B parameters) on most benchmarks. In addition, the cost efficiencies of this model are conducive to deployment and inference on tactical infrastructure, where compute, size, and weight constraints are a factor.
Although diverse and developed to accomplish different tasks, the models covered here illustrate the many innovation pathways that are being traversed in advancing AI capabilities. Of note, are the difference model classes (e.g., encoder only, encoder-decoder, decoder only) that are employed across the various models. A future effort may be to explore if there are performance benefits or tradeoffs due to class based on the task.
As these capabilities continue to mature, we will likely see a combining of features within models as certain features become expectations for performance. There will also be a shift towards creation of a multi-model ecosystem in recognition that one size does not fit all. Instead, AI agents acting as planners, orchestrators, and teammates will collaborate to dynamically select the best specialist model or tool for the task based on use case or Persona of Query driven needs [xxxii].
IV. Challenges and Risks
While the previous survey of model advancements helps illustrate the increasing rate of change within this field spurred by advancements in generative AI and foundation models, there are several challenges that cannot be overlooked as Federal organizations consider how to employ these capabilities. For the purposes of this section, we reference research primarily addressing LLMs. This was a deliberate choice to highlight risks inherent to models that leverage the autoregressive transformer architecture.
First, is the issue of resource constraints, both for enterprise training and inferencing of models and for model training and inferencing at the edge. The rise of ever larger AI models encompassing multiple billions of parameters is leading to strained resources due to infrastructure costs for compute, specialized AI talent needed to implement capabilities, and the challenges associated with amassing, curating, and training on the colossal data volumes required for such models. Such challenges can translate into financial shocks to organizational budgets that may have been set in the years prior due to the need to run high performance servers equipped with GPUs or attract and retain top AI talent. Additionally, there is an increasing need to perform training, retraining, and inferencing of models at the edge to support the processing, exploitation, and dissemination of detections of multimodal data. This requires the ability to run models on smaller hardware (e.g., human packable devices, onboard autonomous systems or sensors), where size, weight, and power are significant considerations.
The second of these is the issue of trustworthiness. To rely on generative AI and foundation models within mission critical workflows, one must be able to trust the output of such models. As such, the trustworthiness of models is of paramount concern. Much of the discourse on this topic has focused on hallucinations within the output, as well as attempts to define a broad set of dimensions against which to measure trustworthiness [xxxiii][xxxiv]. While these are valid concerns, trustworthiness extends beyond these dimensions to also include ensuring that the model arrives at the best possible outcome based on the latest corpus of data and training. One must be able to trust that the outcome is a global maximum in terms of suitability for the task, as opposed to a local maximum, which could have real world impacts if embedded into a mission critical workflow.
Third, and likely the most daunting, is that of security and privacy. To be able to leverage generative AI within Federal environments, one must be able to do so without compromise to the network and the data that resides on that network. Research has shown that LLMs can pose risks security and privacy and such vulnerabilities can be grouped into AI model inherent vulnerabilities (e.g., data poisoning backdoor attacks, training data extraction) and non-AI model inherent vulnerabilities (e.g., remote code execution, prompt injection, side channel attacks). To date, LLMs have been predominantly used in user level attacks such as disinformation, misinformation, and social engineering [xxxv], although new attacks continue to appear. For example, it has been shown that one can train deceptive LLMs able to switch their behavior from trusted to malicious in response to external events or triggers, eluding initial risk evaluation and creating a false sense of trust before attacking [xxxvi]. In addition, 2024 heralded the creation of AI worms [xxxvii] that can steal data and spread malware and spam. Such an attack uses an adversarial self-replicating prompt embedded within multimodal media files (e.g., text, image, audio) to effectively jailbreak and task the target LLM. Should future LLM/LMMs be given access to operating system and hardware-level functions, then threats from these vectors could escalate dramatically.
These challenges aren’t without opportunities. NIST recently released the inaugural version of its Artificial Intelligence Risk Management Framework [xxxviii] to aid with mitigating the risks related to AI. However, the nascent nature of this field means that much still remains unknown. Couple this with the fact that rigidity and bureaucracy within the RMF process means that, in some cases, by the time technology is approved for use and operationalized, it may be one or two generations behind state-of-the-art capabilities. Organizations face a challenge of how do they operationalize technology using a process that may take 9–12 months to complete when that same technology may be surpassed within six months.
V. Human-AI Collaboration: Redefining the Workforce
As AI trends continue to advance, this will have a profound impact on the dynamics of the workforce. Collaboration between humans and AI systems will become the norm as those who are able and willing to partner with AI will experience increased efficiency, innovation, and effectiveness. Supported by autonomous or semi-autonomous actions by AI agents [xxxix], human-AI teams will reshape how we make sense of and interact with the world.
AI will also play a pivotal role in transforming job roles and skill requirements. The workforce will need to adapt to this shift by acquiring new skills and competencies that complement, not compete with, AI’s capabilities and strengths. There will be a growing need for professionals who can effectively manage and collaborate with AI systems and other human-AI teams, increasing the demand for soft skills such as emotional intelligence, critical thinking, and creativity.
This evolution in skill sets will require changes in organizational talent programs to ensure training of the incoming workforce aligns to near-term and long-term organizational needs in AI. In addition to focusing on incoming professionals, organizations must prioritize upskilling and reskilling of the existing workforce to move the organization as a whole through the transformation journey to embrace this new AI era. While not covered in depth in this article, this topic is one that must be carefully considered to promote AI adoption in ways that take into account ethical considerations and ensure that AI systems are designed and implemented responsibly.
VI. Future Outlook and Recommendations
The pace of technological change will continue to accelerate over the next 18-month horizon. The precise path of this change is unpredictable, as each advancing month gives way to new developments that reframe the world’s understanding of the art of the possible. As breathtaking as some recent capabilities are, these technologies are still in a nascent stage. To have business and mission value, the maturation and commercialization of generative AI capabilities must continue, which will take some time.
In addition, Generative AI remains experimental and has not yet been operationalized for critical mission application. As organizations consider how to move forward with using the tremendous power of generative AI and foundation models, any strategy must be based upon a High OPTEMPO Concurrency where one is simultaneously experimenting with the newest technology, developing and training on a continuous basis in the mode of “Always in a State of Becoming” [xl]. To do so, organizations must be willing to accept additional risk, but also make use of emerging technologies to modernize existing methods. For example, LLMs have been shown to identify security vulnerabilities in code with greater effectiveness than leading commercial tools using traditional methods. Such methods can be used to enhance speed and efficacy in detecting vulnerable and malicious code as part of the RMF process [xli].
Posturing oneself to capitalize on AI advancements, especially in the realm of computer vision, necessitates that leaders within the organization become versed and remain current on rapidly progressing developments in AI. As part of their strategy, organizations should consider how to invest in the infrastructure and data foundation that will enable an AI-first future. This includes building modern data architectures and approaches to facilitate the rapid exchange of information as well as machine manipulation of data and services required to support automated discovery, understanding, and actions on the data. Moreover, organizations need to begin regular experimentation now in order to build the organizational capacity and learning needed for the future.
VII. Conclusion
As we progress through the remainder of the year, the trajectory of technological advancement is poised to surge into uncharted realms of what’s possible with AI. The advent of increasingly intricate multimodal models will revolutionize human-AI collaboration. Interactive analysis and interrogation of multimodal data, coupled with autonomous or semi-autonomous actions by AI agents and heightened reasoning capabilities derived from models able to create internal representations of the external world, will redefine operational landscapes.
The imperative to wield these capabilities to understand and decipher vast pools of visual and multimodal data, critical to national security, will define the latter half of this decade. Navigating this transformative era necessitates a forward-thinking mindset, the courage to increase one’s risk appetite, and the resilience to shape organizational strategy and policy to capitalize on the coming wave of change. As such, leaders must adopt a proactive stance in integrating AI, while placing an emphasis on its responsible deployment. Doing so will enable organizations to harness the full potential of evolving AI technologies.
All views expressed in this article are the personal views of the author.
References:
[i] S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. Lee, Y. Li, S. Lundberg, H. Nori, H. Palangi, M. Ribeiro, Y. Zhang, “Sparks of Artificial General Intelligence: Early experiments with GPT-4,” arXiv:2303.12712, 2023. 13, 92
[ii] H. Naveed, A. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, A. Mian, “A Comprehensive Overview of Large Language Models,” arXiv:2307.06435, 2023. 1, 2, 3, 4
[iii] K. Pandya, M. Holia, “Automating Customer Service using LangChain: Building custom open-source GPT Chatbot for organizations,” arXiv:2310.05421, 2023. 1, 2
[iv] S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, X. Wu, “Unifying Large Language Models and Knowledge Graphs: A Roadmap,” arXiv:2306.08302, 2023. 1, 2
[v] Z. Xie, T. Cohn, J. Lau, “The Next Chapter: A Study of Large Language Models in Storytelling,” arXiv:2301.09790, 2023. 1, 2
[vi] Microsoft Research AI4Science, Microsoft Azure Quantum, “The Impact of Large Language Models on Scientific Discovery: a Preliminary Study using GPT-4,” arXiv:2311.07361, 2023. 4, 5
[vii] A. Shukla, L. Agarwal, J. Goh, G. Gao, R. Agarwal, “Catch Me If You Can: Identifying Fraudulent Physician Reviews with Large Language Models Using Generative Pre-Trained Transformers,” arXiv:2304.09948, 2023. 15, 16, 17
[viii] Z. Guo, S. Yu, “AuthentiGPT: Detecting Machine-Generated Text via Black-Box Language Models Denoising,” arXiv:2311.07700, 2023. 3, 4, 5
[ix] H. Xu, Y. Kim, A. Sharaf, H. Awadalla, “A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models,” arXiv:2309.11674, 2023. 2, 3
[x] G. Savcisens, T. Eliassi-Rad, L. Hansen, L. Mortensen, L. Lilleholt, A. Rogers, I. Zettler, S. Lehmann, “Using Sequences of Life-events to Predict Human Lives,” arXiv:2306.03009, 2023. 3, 4, 5
[xi] K. O’Shea, R. Nash, “An Introduction to Convolutional Neural Networks,” arXiv:1511.08458, 2015. 3, 4, 5, 6, 7, 8
[xii] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” arXiv:2010.11929, 2021. 2, 3, 4, 7, 8, 9
[xiii] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, P. Bojanowski, “DINOv2: Learning Robust Visual Features without Supervision,” arXiv:2304.07193. 2023, 2, 4, 15, 20
[xiv] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. Berg, W. Lo, P. Dollár, R. Girshick, “Segment Anything,” arXiv:2304.02643. 2023, 5, 12
[xv] M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, N. Ballas, “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture,” arXiv:2301.08243. 2023, 1, 2, 3, 4, 5, 6
[xvi] Y. LeCun, “A Path Towards Autonomous Machine Intelligence,” OpenReview.net. Version 0.9.2, 2022–06–27
[xvii] A. Dawid, Y. LeCun, “Introduction to Latent Variable Energy-Based Models: A Path Towards Autonomous Machine Intelligence,” arXiv:2306.02572. 2023, 8, 9, 10, 11, 12
[xviii] A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y. LeCun, M. Assran, N. Ballas, “V-JEPA: Latent Video Prediction for Visual Representation Learning,” OpenReview.net. 2024–02–10
[xix] J. Jakubik, S. Roy, C. Phillips, P. Fraccaro, D. Godwin, B. Zadrozny, D. Szwarcman, C. Gomes, G. Nyirjesy, B. Edwards, D. Kimura, N. Simumba, L. Chu, S. Mukkavilli, D. Lambhate, K. Das, R. Bangalore, D. Oliveira, M. Muszynski, K. Ankur, M. Ramasubramanian, I. Gurung, S. Khallaghi, H. Li, M. Cecil, M. Ahmadi, F. Kordi, H. Alemohammad, M. Maskey, R. Ganti, K. Weldemariam, R. Ramachandran, “Foundation Models for Generalist Geospatial Artificial Intelligence,” arXiv:2310.18660. 2023, 2, 3, 4, 6, 21
[xx] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” arXiv:2111.06377. 2021, 3, 4
[xxi] R. Hamadi, “Large Language Models Meet Computer Vision: A Brief Survey,” arXiv:2311.16673. 2023, 4
[xxii] S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, E. Chen, “A Survey on Multimodal Large Language Models,” arXiv:2306.13549. 2023, 5
[xxiii] D. Driess, F. Xia, M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y. Chebotar, P. Sermanet, D. Duckworth, S. Levine, V. Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, P. Florence, “PaLM-E: An Embodied Multimodal Language Model,” arXiv:2303.03378. 2023, 1, 2, 3, 6
[xxiv] S. Akter, Z. Yu, A. Muhamed, T. Ou, A. Bäuerle, Á. Cabrera, K. Dholakia, C. Xiong, G. Neubig, “An In-depth Look at Gemini’s Language Abilities,” arXiv:2312.11444. 2023, 2
[xxv] R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. Alwala, A. Joulin, I. Misra, “ImageBind: One Embedding Space To Bind Them All,” arXiv:2305.05665. 2023, 1, 2, 3, 4
[xxvi] H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S. Chang, Y. Yang, “Ferret: Refer and Ground Anything Anywhere at Any Granularity,” arXiv:2310.07704. 2023, 1, 2
[xxvii] S. Liu, H. Cheng, H. Liu, H. Zhang, F. Li, T. Ren, X. Zou, J. Yang, H. Su, J. Zhu, L. Zhang, J. Gao, C. Li, “LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents,” arXiv:2311.05437. 2023, 1, 2, 3, 4, 5, 6
[xxviii] H. Liu, C. Li, Q. Wu, Y. Lee, “Visual Instruction Tuning,” arXiv:2304.08485. 2023, 2, 3, 4, 5
[xxix] M. Minsky, Society of Mind, Simon and Schuster. 1988
[xxx] Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, F. Wei, “Retentive Network: A Successor to Transformer for Large Language Models,” arXiv:2307.08621. 2023, 2, 3, 4, 5
[xxxi] A. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. Chaplot, D. de las Casas, E. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. Lavaud, L. Saulnier, M. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. Le Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, W. El Sayed, “Mixtral of Experts,” arXiv:2401.04088. 2024, 1, 2, 3
[xxxii] M. Zhuge, H. Liu, F. Faccio, D. Ashley, R. Csordás, A. Gopalakrishnan, A. Hamdi, H. Hammoud, V. Herrmann, K. Irie, L. Kirsch, B. Li, G. Li, S. Liu, J. Mai, P. Piękos, A. Ramesh, I. Schlag, W. Shi, A. Stanić, W. Wang, Y. Wang, M. Xu, D. Fan, B. Ghanem, J. Schmidhuber, “Mindstorms in Natural Language-Based Societies of Mind,” arXiv:2305.17066. 2023, 1, 2, 3, 4
[xxxiii] L. Sun, Y. Huang, H. Wang, S. Wu, Q. Zhang, C. Gao, Y. Huang, W. Lyu, Y. Zhang, X. Li, Z. Liu, Y. Liu, Y. Wang, Z. Zhang, B. Kailkhura, C. Xiong, C. Xiao, C. Li, E. Xing, F. Huang, H. Liu, H. Ji, H. Wang, H. Zhang, H. Yao, M. Kellis, M. Zitnik, M. Jiang, M. Bansal, J. Zou, J. Pei, J. Liu, J. Gao, J. Han, J. Zhao, J. Tang, J. Wang, J. Mitchell, K. Shu, K. Xu, K. Chang, L. He, L. Huang, M. Backes, N. Gong, P. Yu, P. Chen, Q. Gu, R. Xu, R. Ying, S. Ji, S. Jana, T. Chen, T. Liu, T. Zhou, W. Wang, X. Li, X. Zhang, X. Wang, X. Xie, X. Chen, X. Wang, Y. Liu, Y. Ye, Y. Cao, Y. Chen, Y. Zhao, “TrustLLM: Trustworthiness in Large Language Models,” arXiv:2401.05561. 2024, 6, 7
[xxxiv] Y. Liu, Y. Yao, J. Ton, X. Zhang, R. Guo, H. Cheng, Y. Klochkov, M. Taufiq, H. Li, “Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models’ Alignment,” arXiv:2308.05374. 2023, 7, 8, 9
[xxxv] Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, Y. Zhang, “A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly,” arXiv:2312.02003. 2024 1, 2
[xxxvi] E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDiarmid, T. Lanham, D. Ziegler, T. Maxwell, N. Cheng, A. Jermyn, A. Askell, A. Radhakrishnan, C. Anil, D. Duvenaud, D. Ganguli, F. Barez, J. Clark, K. Ndousse, K. Sachan, M. Sellitto, M. Sharma, N. DasSarma, R. Grosse, S. Kravec, Y. Bai, Z. Witten, M. Favaro, J. Brauner, H. Karnofsky, P. Christiano, S. Bowman, L. Graham, J. Kaplan, S. Mindermann, R. Greenblatt, B. Shlegeris, N. Schiefer, E. Perez, “Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training,” arXiv:2401.05566. 2024, 1, 2, 3, 4, 5, 6
[xxxvii] S. Cohen, R. Bitton, B. Nassi, “ComPromptMized: Unleashing Zero-click Worms that Target GenAI-Powered Applications,” https://sites.google.com/view/compromptmized. 2024
[xxxviii] National Institute of Standards and Technology, “Artificial Intelligence Risk Management Framework (AI RMF 1.0),” https://doi.org/10.6028/NIST.AI.100-1. 2023
[xxxix] J. Park, J. O’Brien, C. Cai, M. Morris, P. Liang, M. Bernstein, “Generative Agents: Interactive Simulacra of Human Behavior,” arXiv:2304.03442. 2023, 1, 2, 3
[xl] Concept referenced from Greg Porpora, IBM Distinguished Engineer on 21 February, 2024.
[xli] Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, Y. Zhang, “A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly,” arXiv:2312.02003. 2024 1, 2
Sensemaking at Scale: Navigating Current Trends in Computer Vision was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.