
Syntax: the language form
Language processing in humans and computers: Part 3
How do you know that this is a sentence?
Syntax is deep, semantics is arbitrary
People speak many languages. People who speak different languages generally don’t understand each other. How is it possible to have a general theory of language?
Life is also diversified in many species, and different species generally cannot interbreed¹. But life is a universal capability of self-reproduction and biology is a general theory of life.
General linguistics is based on Noam Chomsky’s Cartesian assumption²: that all languages arise from a universal capability of speech, innate to our species. The claim is that all of our different languages share the same deep structures embedded in our brains. Since different languages assign different words to the same things, the semantic assignments of words to meanings are not a part of these universal deep structures. Chomskian general linguistics is mainly concerned with general syntax. It also studies (or it used to study) the transformations of the deep syntactic structures into the surface structures observable in particular languages, just like biology studies the ways in which the general mechanisms of heredity lead to particular organisms. Oversimplified a little, the Chomskian thesis implied that
* syntax is the main subject of modern linguistics, whereas
* semantics is studied in complementary ways in
— philosophy of meaning, be it under the title of semiology, or in the many avatars of structuralism; and by different methods in
— search engine engineering, information retrieval indices and catalogs, user profiling, and targeted advertising.
However, the difference between the pathways from deep structures to surface structures as studied in linguistics on one hand and in biology on
* in biology, the carriers of the deep structures of life are directly observable and empirically studied in genetics, whereas
* in linguistics, the deep structures of syntax are not directly observable but merely postulated, as Chomsky’s Cartesian foundations, and the task of finding actual carriers is left to a future science.
This leaves the Cartesian assumption about the universal syntactic structures on shaky ground. The emergence of large language models may be a tectonic shift of that ground. Most of our early interactions with chatbots seem to suggest that the demarcation line between syntax and semantics may not be as clear as traditionally assumed.
To understand a paradigm shift, we need to understand the paradigm. To stand a chance to understand large language models, we need a basic understanding of the language models previously developed in linguistics. In this lecture and in the next one, we parkour through the theories of syntax and of semantics, respectively.
Grammar
Constituent (phrase structure) grammars
Grammar is trivial in the sense that it was the first part of trivium. Trivium and quadrivium were the two main parts of medieval schools, partitioning the seven liberal arts that were studied. Trivium consisted of grammar, logic, and rhetorics; quadrivium of arithmetic, geometry, music, and astronomy. Theology, law, and medicine were not studied as liberal arts because they were controlled by the Pope, the King, and by physicians’ guilds, respectively. So grammar was the most trivial part of trivium. At the entry point of their studies, the students were taught to classify words into 8 basic syntactic categories, going back to Dionysios Trax from II century BCE: nouns, verbs, participles, articles, pronouns, prepositions, adverbs, and conjunctions. The idea of categories goes back to the first book of Aristotle’s Organon³. The basic noun-verb scaffolding of Indo-European languages was noted still earlier, but Aristotle spelled out the syntax-semantics conundrum: What do the categories of words in the language say about the classes of things in the world? For a long time, partitioning words into categories remained the entry point of all learning. As understanding of language evolved, its structure became the entry point.
Formal grammars and languages are defined in the next couple of displays. They show how it works. If you don’t need the details, skip them and move on to the main idea. The notations are explained among the notes⁴.


The idea of the phrase structure theory of syntax is to start from a lexicon as the set of terminals 𝛴 and to specify a grammar 𝛤 that generates all well-formed sentences that you want to generate as the induced language 𝓛.
How grammars generate sentences. The most popular sentences are in the form “Subject loves Object”. One of the most popular sentence from grammar textbooks is in the next figure on the left:
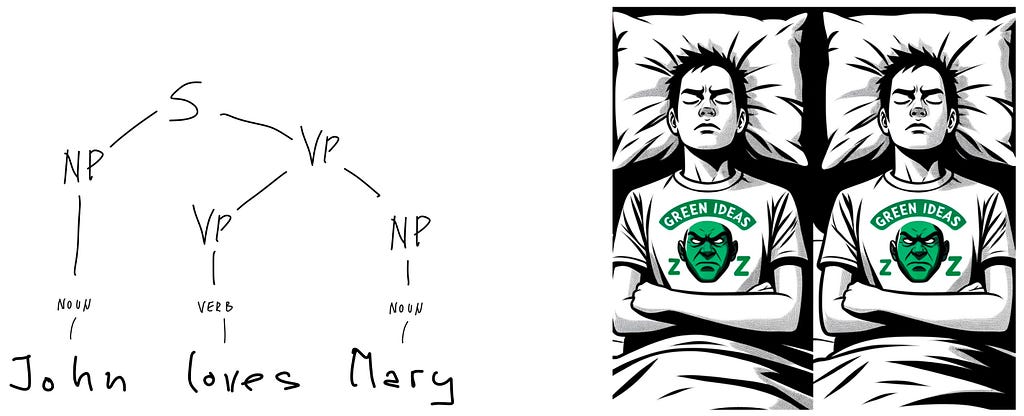
The drawing above the sentence is its constituent tree. The sentence consists of a noun phrase (NP) and a verb phrase (VP), both as simple as possible: the noun phrase is a noun denoting the subject, the verb phrase a transitive verb with another noun phrase denoting the object. The “subject-object’’ terminology suggests different things to different people. A wide variety of ideas. If even the simplest possible syntax suggests a wide variety of semantical connotations, then there is no such thing as a purely syntactic example. Every sequence of words has a meaning, and meaning is a process, always on the move, always decomposable. To demonstrate the separation of syntax from semantics, Chomsky constructed the (syntactically) well-formed but (semantically) meaningless sentence illustrated by Dall-E in the above figure on the right. The example is used as evidence that syntactic correctness does not imply semantic interpretability. But there is also a whole tradition of creating poems, stories, and illustrations that assign meanings to this sentence. Dall-E’s contribution above is among the simpler ones.
Marxist linguistics and engineering. For a closer look at the demarcation line between syntax and semantics, consider the ambiguity of the sentence “One morning I shot an elephant in my pajamas”, delivered by Groucho Marx in the movie “Animal Crackers”.
https://youtu.be/NfN_gcjGoJo?si=AucqaRQvvfoAlVIo
The claim is ambiguous because it permits the two syntactic analyses:
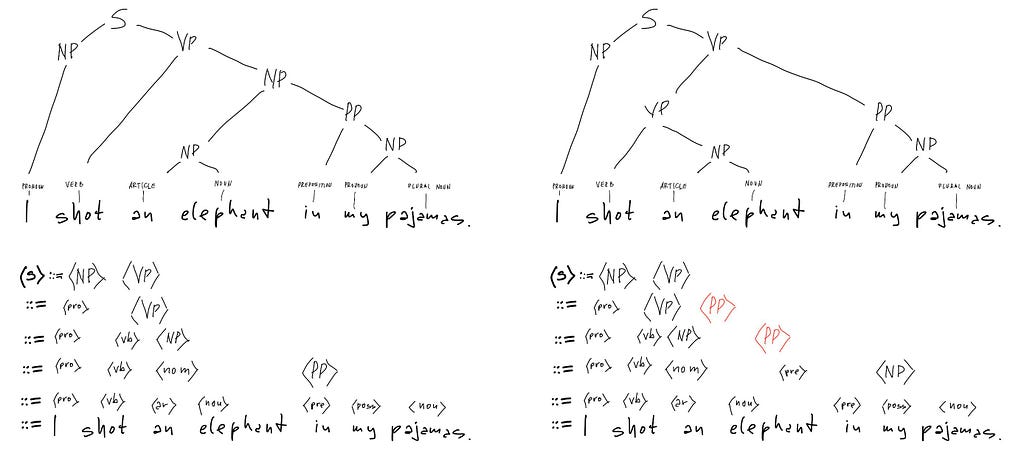
both derived using the same grammar:

While both analyses are syntactically correct, only one is semantically realistic, whereas the other one is a joke. To plant the joke, Groucho’s his claim to the second interpretation by saying “How he got into my pajamas I’ll never know.” The joke is the unexpected turn from syntactic ambiguity to semantic impossibility. The sentences about “colorless green ideas” and “elephant in my pajamas” illustrate the same process apparent divergence of syntax and semantics, which sometimes comes across as funny, sometimes not.
History of formal grammars. The symbol ::= used in formal grammars suggests that the grammatical rules used to be thought of as one-way equations, with the suggested interpretation of rule (1) in the definition of formal grammars something like: “Whenever you see αβγ, you can rewrite it as αδγ, but not the other way around.” Algebraic theories presented by systems of such one-way equations were studied by Axel Thue in the early XX century. Emil Post used such systems to construct what we would now recognize as programs in his studies of string rewriting in the 1920s, long before Gödel and Turing spelled out the idea of programming. He proved in the 1940s that his string rewriting systems were as powerful as Turing’s, Gödel’s, and Church’s models of computation, which had in the meantime appeared. Noam Chomsky’s 1950s proposal of formal grammars as the principal tool of general linguistics was based on Post’s work and inspired by the general theory of computation, entering at the time the phase sophistication and power. While usable grammars of natural languages still required a lot of additional work on transformations, side conditions, binding, and so on, the simple formal grammars that Chomsky classified back then remained the principal tool for specifying programming languages ever since.
Hierarchy of formal grammars and languages. Chomsky defined the nest of languages displayed in the next figure by imposing constraints on the grammatical rules that generate the languages.
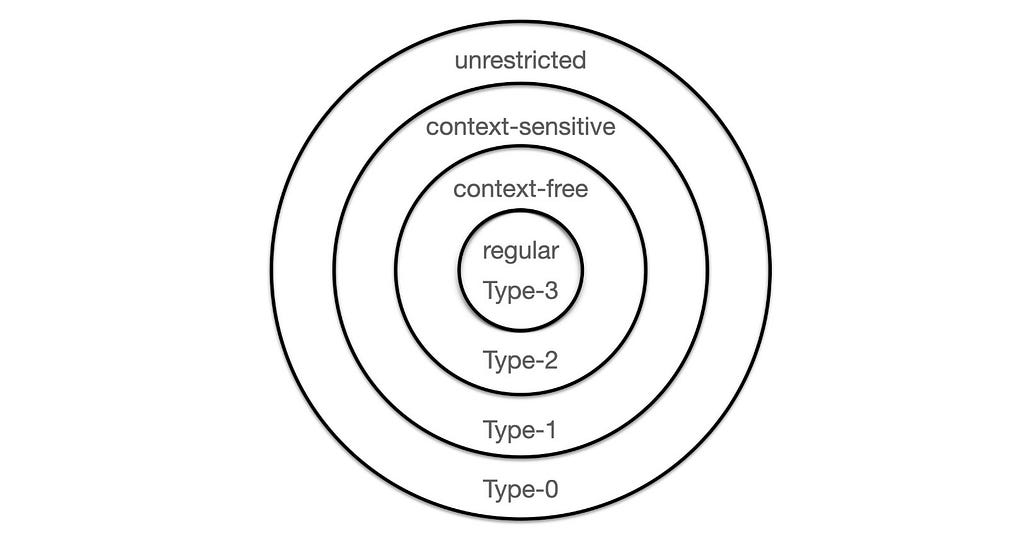
The constraints are summarized in the following table. We say that

Here are some examples from each grammar family⁵, together with typical derivation trees and languages:
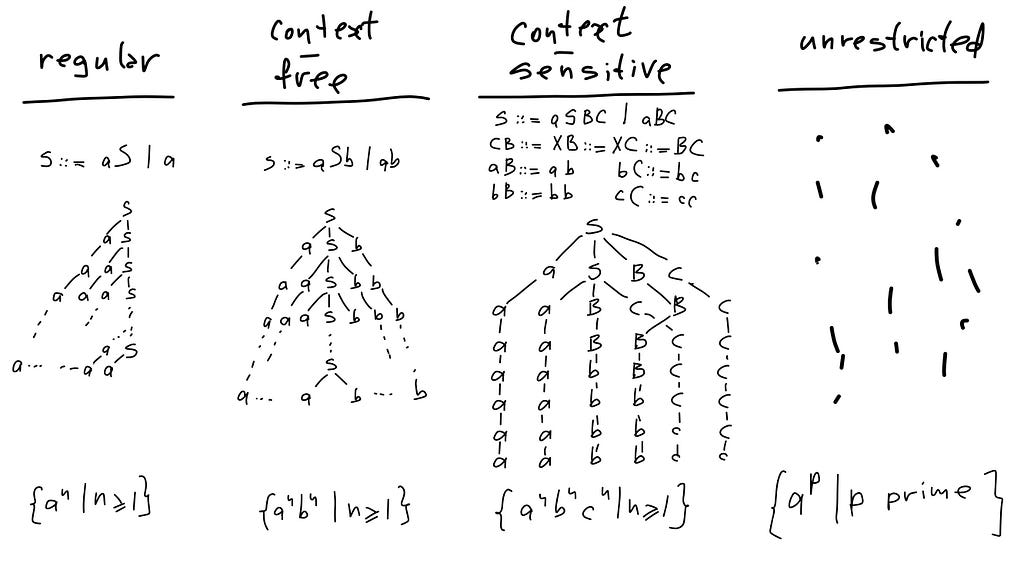
Does it really work like this in my head? In general, scientific models of reality usually do not claim that they are the reality. Physicists don’t claim that particles consist of density matrices used to model them. Grammars are just a computational model of language, born in the early days of the theory of computation. The phrase structure grammars were an attempt to explain language in computational terms. Nowadays even the programming language often don’t work that way anymore. It’s just a model.
However, when it comes to mental models of mental processes, the division between the reality and its models becomes subtle. They can reflect and influence each other. A computational model of a computer allows the computer to simulate itself. A language can be modeled within itself, and the model can be similar to the process that it models. How close can it get?
Dependency grammars
Dependency grammars are a step closer to capturing the process of sentence production. Grammatical dependency is a relation between words in a sentence. It relates a head word and an (ordered!) tuple of dependents. The sentence is produced as the dependents are chosen for the given head words, or the heads for the given dependents. The choices are made in the order in which the words occur. Here is how this works on the example of Groucho’s elephant sentence:

Unfolding dependencies. The pronoun “I” occurs first, and it can only form a sentence as a dependent on some verb. The verb “shot” is selected as the head of that dependency as soon as it is uttered. The sentence could then be closed if the verb “shot” is used as intransitive. If it is used as transitive, then the object of action needs to be selected as its other dependent. Groucho selects the noun “elephant”. English grammar requires that this noun is also the head of another dependency, with an article as its dependent. Since the article is required to precede the noun, the word “elephant” is not uttered before its dependent “an” or “the” is chosen. After the words “I shot an elephant” are uttered (or received), there are again multiple choices to be made: the sentence can be closed with no further dependents, or a dependent can be added to the head “shot”, or else it can be added to the head “elephant”. The latter two syntactic choices correspond to the different semantical meanings that create ambiguity. If the prepositional phrase “in my pajamas” is a syntactic dependent of the head “shot”, then the subject “I” wore the pajamas when they shot. If the prepositional phrase is a syntactic dependent of the head “elephant”, then the object of shooting wore the pajamas when they were shot. The two dependency analyses look like this, with the corresponding constituency analyses penciled above them.
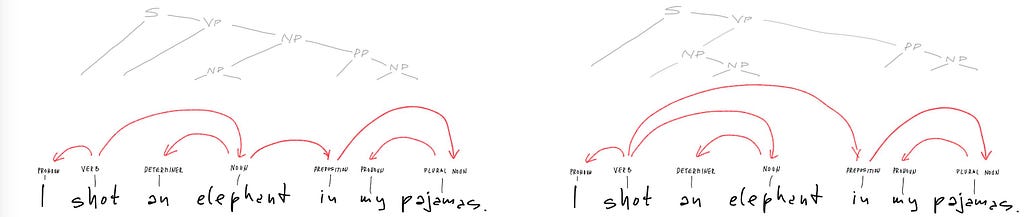
The dependent phrase “in my pajamas” is headed by the preposition “in”, whose dependent is the noun “pajamas”, whose dependent is the possessive “my”. After that, the speaker has to choose again whether to close the sentence or to add another dependent phrase, say “while sleeping furiously”, which opens up the same two choices of syntactic dependency and semantic ambiguity. To everyone’s relief, the speaker chose to close the sentence.
Is dependency a syntactic or a semantic relation? The requirements that a dependency relation exists are usually syntactic. E.g., to form a sentence, a starting noun is usually a dependent of a verb. But the choice of a particular dependent or head assignment is largely semantical: whether I shot an elephant or a traffic sign. The choice of an article dependent on the elephant depends on the context, possibly remote: whether a particular elephant has been determined or not. If it has not been determined, then the form of the independent article an is determined syntactically, and not semantically.
So the answer to the above question seems to suggest that the partition of the relations between words into syntactic and semantic is too simplistic for some situations since the two aspects of language are not independent and can be inseparable.
Syntax as typing
Syntactic type-checking
In programming, type-checking is a basic error-detection mechanism: e.g., the inputs of an arithmetic operation are checked to be of type 𝖨𝗇𝗍𝖾𝗀𝖾𝗋, the birth dates in a database are checked to have the month field of type 𝖬𝗈𝗇𝗍𝗁, whose terms may be the integers 1,2,…, 12, and if someone’s birth month is entered to be 101, the error will be caught in type-checking. Types allow the programmer to ensure correct program execution by constraining the data that can be processed⁶.
In language processing, the syntactic types are used in a similar process, to restrict the scope of the word choices. Just like the type 𝖨𝗇𝗍𝖾𝗀𝖾𝗋 restricts the inputs of arithmetic operations tointegers, the syntactic type <verb> restricts the predicates in sentences to verbs. If you hear something sounding like “John lo℥∼ Mary’’, then without the type constraints, you have more than 3000 English words starting with “lo” to consider as possible completions. With the syntactic constraint that the word that you didn’t discern must be a transitive verb in third person singular, you are down to “lobs”, “locks”, “logs”,… maybe “loathes”, and of course, “loves”.
Parsing and typing
The rules of grammar are thus related to the type declarations in programs as
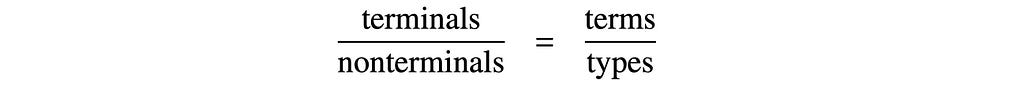
In the grammar listed above after the two parsings of Grouch’s elephant sentence, the terminal rules listed on the left are the basic typing statements, whereas the non-terminal rules on the right are type constructors, building composite types from simpler types. The constituency parse trees thus display the type structures of the parsed sentences. The words of the sentence occur as the leaves, whereas the inner tree nodes are the types. The branching nodes are the composite types and the non-branching nodes are the basic types. Constituency parsing is typing.
The dependency parsings, on the other hand, do a strange thing: having routed the dependencies from a head term to its dependents through the constituent types that connect them, that sidestep the types and directly connect the head with its dependents. This is what the above dependency diagrams show. Dependency parsing reduces syntactic typing to term dependencies.
But only the types that record nothing but the term dependencies can be reduced to them. The two dependency parsings of the elephant sentence look something like this:
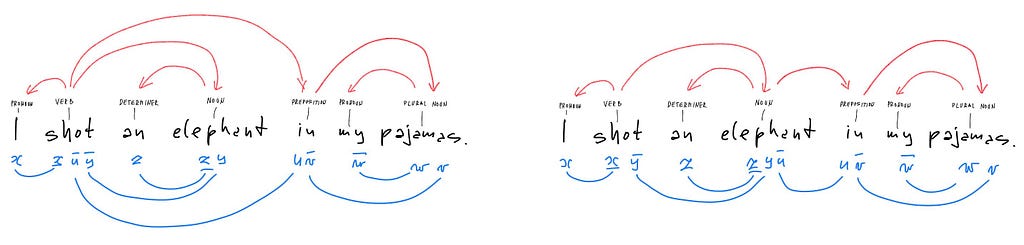
The expressions below the two copies of the sentence are the syntactic types captured by dependency parsings. They are generated by tupling reference variables x,y,… etc., with their left adjoints denoted by overlining and their right adjoints by underlining. Such syntactic types form pregroups, an algebraic structure introduced in the late 1990s by Jim Lambek, as a simplification of his syntactic calculus of categorial grammars. He introduced the latter in the late 1950s, to explore correctness decision procedures applicable to Ajdukiewicz’s syntactic connexions from the 1930s and Bar-Hillel’s quasi-arithmetic from the early 1950s. The entire tradition of reference-based logic of meaning goes back to Husserl’s “Logical investigations”. It is still actively studied. We only touch the pregroups, and only as a stepping stone.
Pregroup grammars
Pregroup definition and properties
A pregroup is an ordered monoid with left and right adjoints. An ordered monoid is a monoid where the underlying set is ordered and the monoid product is monotone.
If you know what this means, you can skip this section. You can also skip it if you don’t need to know how it works, since the main idea should transpire as you go anyway. Just in case, here are the details.
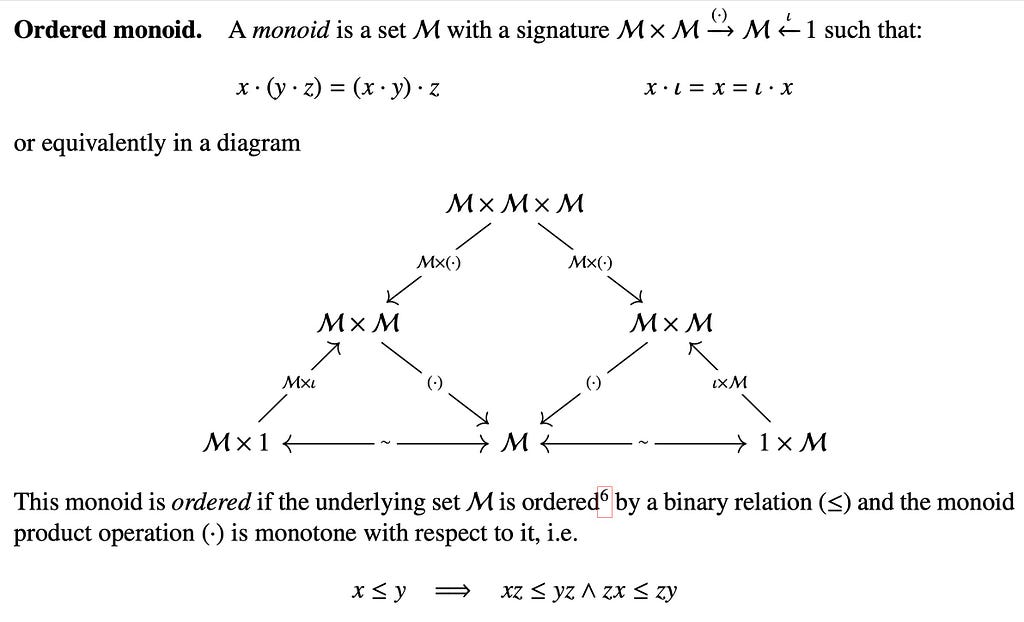

It is easy to show that all elements of all pregroups, as ordered monoids with adjoints, satisfy the following claims:

The simplest pregroups are freely generated from given posets of basic types. An element of the free pregroup are the finite strings of basic types, with the order induced pointwise, and (most importantly) by the above rules for the adjoints. If you want to see a fun non-free example, consider the monoid of monotone maps from integers to integers. Taken with the pointwise order, they form a pregroup because every bounded set contains its meet and join, and therefore every monotone map preserves them, which allows constructing both of its adjoints.
Here is why pregroups help with understanding language.
Parsing as type-checking
To check semantic correctness of a given phrase, each word in the phrase is first assigned a pregroup element as its syntactic type. The type of the phrase is the product of the types of its words, multiplied in the pregroup. The phrase is a well-formed sentence if its syntactic type is pregroup unit 𝜄. In other words, we compute the syntactic type S of the given phrase, and it is a sentence just when S≤𝜄. The computation can be reduced to drawing arcs to connect each type x with an adjoint, be it left or right, and coupling them so that each pair falls below 𝜄. If the arcs are well-nested⁷, eliminating the adjacent adjoints and replacing them by the unit 𝜄 makes other adjoints adjacent, and you proceed until you are left with the unit. The original type must have been below it, since the procedure was non-descending. If the types cannot be matched in this way, the phrase is not a sentence, and the type actually tells you what kind of a phrase it is.
We obviously skipped all details and some are significant. In practice, the head of the sentence is annotated by a type variable S that does not discharged with an adjoint, and its wire does not arc to another type in the sentence but points straight out. This wire can be interpreted as a reference to another sentence. The other wires are arcs between pairs of adjoints. They often deviate from the dependency references, mainly because it is expected that the words of the same type in a lexicon should receive the same pregroup type. The advantages of this approach are a matter of contention. The only point that matters here is that syntax is typing⁸.
Beyond sentence
Why do we partition speech into sentences?
Why don’t we stream words, like network routers stream packets? Why can’t we approximate what we want to say by adding more words, just like numbers approximate points in space by adding more digits?
The old answer is: “We make sentences to catch a breath”. When we complete a sentence, we release the dependency threads between its words. Without that, the dependencies accumulate, and you can only keep so many threads in your mind at a time. Breathing keeps references from knotting.
Exercise. We make long sentences for a variety of reasons and purposes. A sample of a long sentence is provided below⁹. Try to split it into shorter ones. What is gained and what lost by such operations? Ask a chatbot to do it.
Anaphora is a syntactic pattern that occurs within or between sentences. In rhetorics and poetry, it is the figure of speech where the same phrase is repeated to amplify the argument or thread a reference. In ChatGPT’s view, it works because the rhythm of the verse echoes the patterns of meaning:
In every word, life’s rhythm beats,
In every truth, life’s voice speaks.
In every dream, life’s vision seeks,
In every curse, life’s revenge rears.
In every laugh, life’s beat nears,
In every pause, life’s sound retreats.
Syntactic partitions reflect the semantic partitions. Sentential syntax is the discipline of charging and discharging syntactic dependencies to transmit semantic references.
Language articulations and network layers
The language streams are articulated into words, sentences, paragraphs, sections, chapters, books, libraries, literatures; speakers tell stories, give speeches, maintain conversations, follow conventions, comply with protocols. Computers reduce speech to tweets and expand it to chatbots.
The layering of language articulations is an instance of stratification of communication channels. Artificial languages evolved the same layering. The internet stack is another instance.
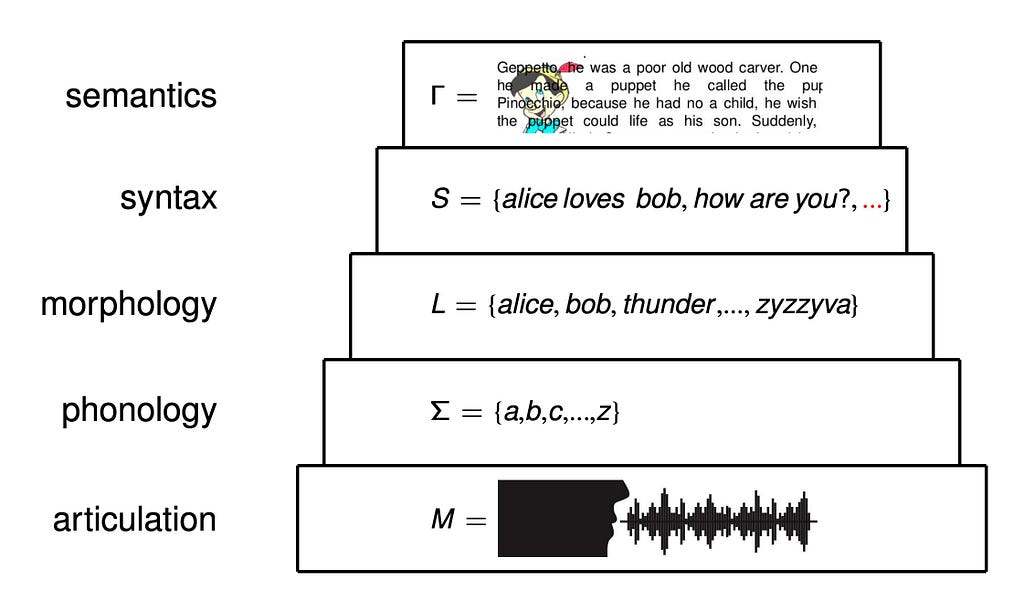

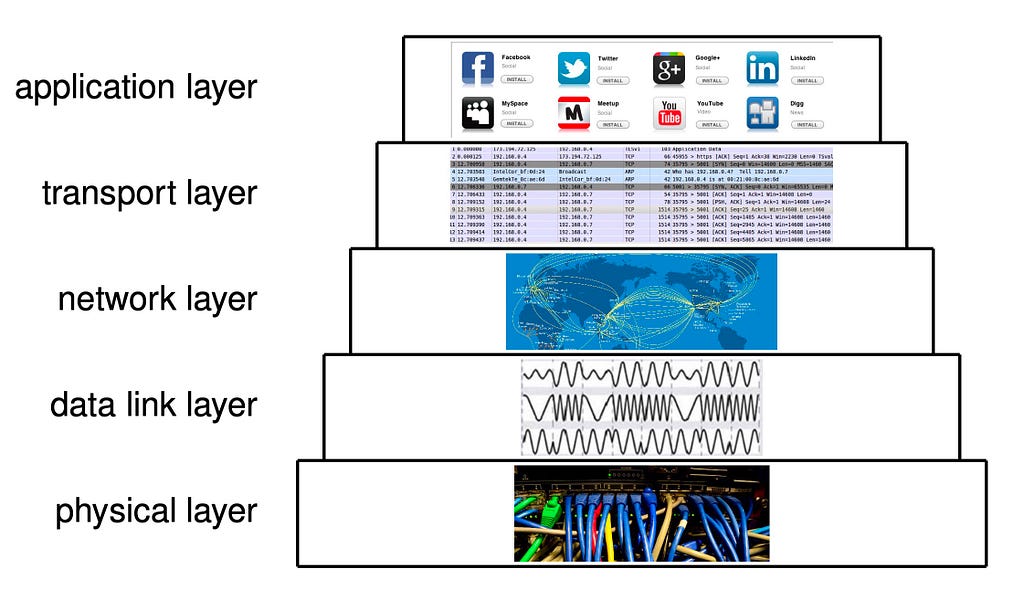
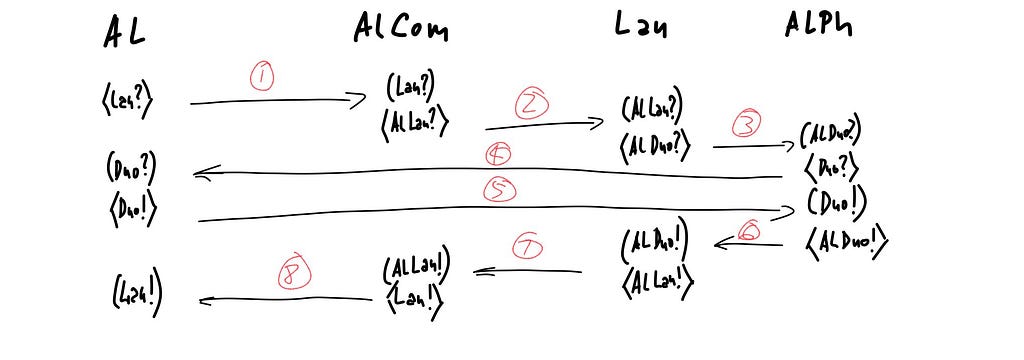
Information carriers are implemented on top of each other, in living organisms, in the communication networks between them, and in all languages the humans developed around us. Reference coupling mechanisms similar to syntactic types emerge at all levels, in many varieties. The pregroup structure of sentential syntax is reflected by the question-answer structure of simple discourse and by the SYN-ACK pattern of the basic network protocols. Closely related structures arise in protocols across the board. Here a high-level view of a standard 2-factor authentication protocol, presented as a basic cord space¹⁰:
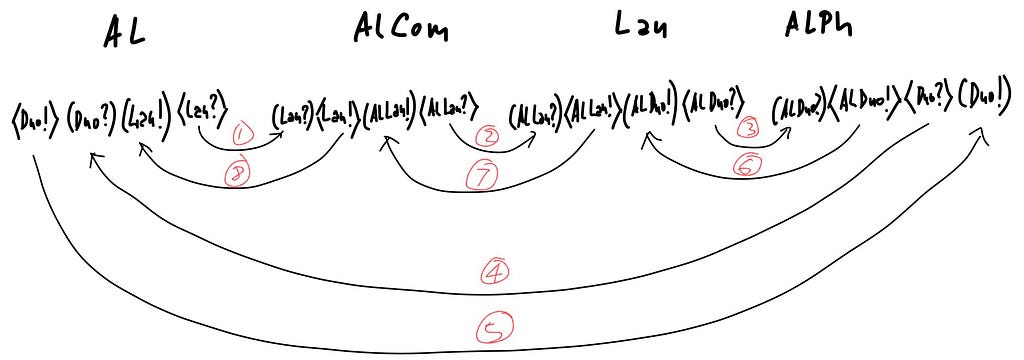
Here is the same protocol displayed with the cord actions viewed as adjoint types, with the corresponding interactions are marked by the same sequence numbers:
Mathematical models of natural-language conversations, security and network protocols, software-system architectures share features. They may be features of a high-level deep syntax, shared by all communication processes. Such syntax could conceivably arise from the physical laws of information processing, or from innate capabilities of a species, as hypothesized in the Chomskian theory.
Beyond syntax
We have seen how syntactic typing supports semantic information transmission. Already Groucho’s elephant sentence fed syntactic and semantic ambiguities back into each other.
But if syntactic typing and semantic assignments steer each other, then the generally adopted restriction of syntactic analyses to sentences cannot be justifiable, since semantic ambiguities certainly cannot be resolved on the level of a sentence. Groucho proved that.
Semantic context-sensitivity
Consider the sentence
John said he was sick and got up to leave.
Adding a context changes its meaning:
Mark collapsed on bed.
John said he was sick and got up to leave.
For most people, “he was sick” now refers to Mark. Note that the silent “he” in “[he] got up to leave” remains bound to John. Or take
Few professors came to the party and had a great time.
The meaning does not significantly change if we split the sentence in two and expand :
Since it started late, few professors came to the party. They had a great time.
Like in the John and Mark example, a context changes the semantical binding, this time of “it”:
There was a departmental meeting at 5. Since it started late, few professors came to the party. They had a great time.
But this time, moreover, binding “they’’ in a first sentence changes the binding of “they’’ in the last sentence:
They invited professors. There was a departmental meeting at 5. Since it started late, few professors came to the party. They had a great time.
The story is now that students had a great time — the students who are never named, but derived from the professors!
Syntactic context-sensitivity
On the level of sentential syntax of natural languages, as generated by formal grammars, proving context-sensitivity amounts to finding a language that contains some of the patterns known to require a context-sensitive grammar, such as aⁿbⁿcⁿ for arbitrary letters a,b,c∈𝛴 and any number n, or ww, www, or wwww for arbitrary word w∈𝛴*. Since people are unlikely to go around saying to each other things like aⁿbⁿcⁿ, the task boiled down to finding languages which require constructions of repetitive words in the form ww, www, etc. The quest for such examples became quite competitive.
Since a language with a finite lexicon has a finite number of words for numbers, at some point you have to say something like “quadrillion quadrillion” if quadrillion is the largest number denoted by a single word. But it was decided that numbers don’t count.
Then someone found that in Central-African language Bambara, the construction that says “any dog” is in the form “dog dog”. Then someone else claimed context-sensitive nesting phenomena in Dutch, but not everyone agreed. Eventually, most people settled on Swiss German as a definitely context sensitive language, and the debate about syntactic contexts-sensitivity subsided.
With a hindsight, it has the main features of theological debates. The main problem with counting how many angels can stand on the tip of a needle is that angels don’t stand on needles. The main problem with syntactic context sensitivity is that contexts are never purely syntactic.
Communication is the process of sharing semantical contexts
Chomsky noted that natural language should be construed as context-sensitive in the paper where he defined the notion of context-sensitivity. Restricting the language models to syntax, and syntax to sentences, made proving his observation into a conundrum.
But now that the theology of syntactic contexts is behind us, and the language models are in front of us, waiting to be understood, the question arises: How are contexts really processed? How do we do it, and how do the chatbots do it? How are the big contexts stored? The reader of a novel builds the context of that novel starting from the first sentence, and refers to it 800 pages later. What does the context of a big novel look like in a language model?
Semantic dependencies on remote contexts have been one of the central problems of natural language processing from the outset. The advances in natural language processing that we witness currently are to a large extent based on the progress in solving that that problem. To get an idea about the challenge, consider the following paragraph¹¹:
Unsteadily, Holmes stepped out of the barge. Moriarty was walking away
down the towpath and into the fog. Holmes ran after him. `Give it back to me’, he shouted. Moriarty turned and laughed. He opened his hand and the
small piece of metal fell onto the path. Holmes reached to pick it up but
Moriarty was too quick for him. With one slight movement of his foot, he tipped the key into the lock.
If you are having trouble understanding what just happened, you are in a good company. Without sufficient hints, the currently available chatbots do not seem to be able to produce a correct interpretation¹². In the next part, we will see how semantic contexts arise, including much larger, and after that we will be ready to explain how they are processed.
Attributions
As mentioned in the text, the anaphoric verses “In every… life’s” were composed by ChatGPT, and the illustration of the sentence “Colorless green ideas sleep furiously” was created by Dall-E. All other graphics were created by the author.
Notes
¹The fact that most people do not understand each other even when they speak the same language echoes the fact that most members of the same species do not breed, but select mates through complex rituals.
²Early linguists (Humboldt, Boas, Sapir, Whorf) were mainly focused on understanding different worldviews (Weltanschauung, Weltanzicht) by understanding different languages (German, Hebrew, English, Hopi, Nahuan…).
³The partition of trivium echoes the organization of Organon, where the first book, devoted to categories, was followed by three devoted to logic, and the final two to topical argumentations, feeding into rhetorics.
⁴For any set A write A* to denote the set of all n-tuples 𝛼={a1,a2,…,an} from A, for all n = 0,1,… and arbitrary a1,a2,…,an from A. Since n can be 0, A* includes the empty tuple, written <>. Denoting the set of all labels by 𝛬 = 𝛴∪𝛯, the set of rules is a finite binary relation [::=] ⊆ 𝛬*×𝛬*, obtained by listing (1).
⁵Chomsky’s “Type-x’’ terminology is unrelated with the “syntactic type’’ terminology. Many linguists use “syntactic categories’’ instead. But the term “category’’ is in the meantime widely used in mathematics in a completely different meaning, increasingly applied in linguistics.
⁶For historic and logical background of the mathematical theory of types, see Ch.1 of the book “Programs as diagrams”.
⁷If the arcs are not well-nested, as it is the case, for instance, with Dutch syntax, then the procedure is more complicated, but we won’t go into that.
⁸For more details on pregroup-based syntactic analysis see Jim Lambek’s book “From Word to Sentence”. For the logical and mathematical background, see “Lambek prergroups are Frobenius spiders”.
⁹“That night he dreamt of horses on a high plain where the spring rains had brought up the grass and the wildflowers out of the ground and the flowers ran all blue and yellow far as the eye could see and in the dream he was among the horses running and in the dream he himself could run with the horses and they coursed the young mares and fillies over the plain where their rich bay and their chestnut colors shone in the sun and the young colts ran with their dams and trampled down the flowers in a haze of pollen that hung in the sun like powdered gold and they ran he and the horses out along the high mesas where the ground resounded under their running hooves and they flowed and changed and ran and their manes and tails blew off them like spume and there was nothing else at all in that high world and they moved all of them in a resonance that was like a music among them and they were none of them afraid horse nor colt nor mare and they ran in that resonance which is the world itself and which cannot be spoken but only praised.” — Cormac McCarthy, All the Pretty Horses
¹⁰Cord spaces are a simple formalism for analyzing security protocols.
¹¹The paragraph is a variation on the context of Sir Arthur Conan Doyle’s short story “The final problem”.
¹² On key attention span:
Syntax: the language form was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Language processing in humans and computers: Part 3
How do you know that this is a sentence?
Syntax is deep, semantics is arbitrary
People speak many languages. People who speak different languages generally don’t understand each other. How is it possible to have a general theory of language?
Life is also diversified in many species, and different species generally cannot interbreed¹. But life is a universal capability of self-reproduction and biology is a general theory of life.
General linguistics is based on Noam Chomsky’s Cartesian assumption²: that all languages arise from a universal capability of speech, innate to our species. The claim is that all of our different languages share the same deep structures embedded in our brains. Since different languages assign different words to the same things, the semantic assignments of words to meanings are not a part of these universal deep structures. Chomskian general linguistics is mainly concerned with general syntax. It also studies (or it used to study) the transformations of the deep syntactic structures into the surface structures observable in particular languages, just like biology studies the ways in which the general mechanisms of heredity lead to particular organisms. Oversimplified a little, the Chomskian thesis implied that
* syntax is the main subject of modern linguistics, whereas
* semantics is studied in complementary ways in
— philosophy of meaning, be it under the title of semiology, or in the many avatars of structuralism; and by different methods in
— search engine engineering, information retrieval indices and catalogs, user profiling, and targeted advertising.
However, the difference between the pathways from deep structures to surface structures as studied in linguistics on one hand and in biology on
* in biology, the carriers of the deep structures of life are directly observable and empirically studied in genetics, whereas
* in linguistics, the deep structures of syntax are not directly observable but merely postulated, as Chomsky’s Cartesian foundations, and the task of finding actual carriers is left to a future science.
This leaves the Cartesian assumption about the universal syntactic structures on shaky ground. The emergence of large language models may be a tectonic shift of that ground. Most of our early interactions with chatbots seem to suggest that the demarcation line between syntax and semantics may not be as clear as traditionally assumed.
To understand a paradigm shift, we need to understand the paradigm. To stand a chance to understand large language models, we need a basic understanding of the language models previously developed in linguistics. In this lecture and in the next one, we parkour through the theories of syntax and of semantics, respectively.
Grammar
Constituent (phrase structure) grammars
Grammar is trivial in the sense that it was the first part of trivium. Trivium and quadrivium were the two main parts of medieval schools, partitioning the seven liberal arts that were studied. Trivium consisted of grammar, logic, and rhetorics; quadrivium of arithmetic, geometry, music, and astronomy. Theology, law, and medicine were not studied as liberal arts because they were controlled by the Pope, the King, and by physicians’ guilds, respectively. So grammar was the most trivial part of trivium. At the entry point of their studies, the students were taught to classify words into 8 basic syntactic categories, going back to Dionysios Trax from II century BCE: nouns, verbs, participles, articles, pronouns, prepositions, adverbs, and conjunctions. The idea of categories goes back to the first book of Aristotle’s Organon³. The basic noun-verb scaffolding of Indo-European languages was noted still earlier, but Aristotle spelled out the syntax-semantics conundrum: What do the categories of words in the language say about the classes of things in the world? For a long time, partitioning words into categories remained the entry point of all learning. As understanding of language evolved, its structure became the entry point.
Formal grammars and languages are defined in the next couple of displays. They show how it works. If you don’t need the details, skip them and move on to the main idea. The notations are explained among the notes⁴.

The idea of the phrase structure theory of syntax is to start from a lexicon as the set of terminals 𝛴 and to specify a grammar 𝛤 that generates all well-formed sentences that you want to generate as the induced language 𝓛.
How grammars generate sentences. The most popular sentences are in the form “Subject loves Object”. One of the most popular sentence from grammar textbooks is in the next figure on the left:
The drawing above the sentence is its constituent tree. The sentence consists of a noun phrase (NP) and a verb phrase (VP), both as simple as possible: the noun phrase is a noun denoting the subject, the verb phrase a transitive verb with another noun phrase denoting the object. The “subject-object’’ terminology suggests different things to different people. A wide variety of ideas. If even the simplest possible syntax suggests a wide variety of semantical connotations, then there is no such thing as a purely syntactic example. Every sequence of words has a meaning, and meaning is a process, always on the move, always decomposable. To demonstrate the separation of syntax from semantics, Chomsky constructed the (syntactically) well-formed but (semantically) meaningless sentence illustrated by Dall-E in the above figure on the right. The example is used as evidence that syntactic correctness does not imply semantic interpretability. But there is also a whole tradition of creating poems, stories, and illustrations that assign meanings to this sentence. Dall-E’s contribution above is among the simpler ones.
Marxist linguistics and engineering. For a closer look at the demarcation line between syntax and semantics, consider the ambiguity of the sentence “One morning I shot an elephant in my pajamas”, delivered by Groucho Marx in the movie “Animal Crackers”.
https://youtu.be/NfN_gcjGoJo?si=AucqaRQvvfoAlVIo
The claim is ambiguous because it permits the two syntactic analyses:
both derived using the same grammar:
While both analyses are syntactically correct, only one is semantically realistic, whereas the other one is a joke. To plant the joke, Groucho’s his claim to the second interpretation by saying “How he got into my pajamas I’ll never know.” The joke is the unexpected turn from syntactic ambiguity to semantic impossibility. The sentences about “colorless green ideas” and “elephant in my pajamas” illustrate the same process apparent divergence of syntax and semantics, which sometimes comes across as funny, sometimes not.
History of formal grammars. The symbol ::= used in formal grammars suggests that the grammatical rules used to be thought of as one-way equations, with the suggested interpretation of rule (1) in the definition of formal grammars something like: “Whenever you see αβγ, you can rewrite it as αδγ, but not the other way around.” Algebraic theories presented by systems of such one-way equations were studied by Axel Thue in the early XX century. Emil Post used such systems to construct what we would now recognize as programs in his studies of string rewriting in the 1920s, long before Gödel and Turing spelled out the idea of programming. He proved in the 1940s that his string rewriting systems were as powerful as Turing’s, Gödel’s, and Church’s models of computation, which had in the meantime appeared. Noam Chomsky’s 1950s proposal of formal grammars as the principal tool of general linguistics was based on Post’s work and inspired by the general theory of computation, entering at the time the phase sophistication and power. While usable grammars of natural languages still required a lot of additional work on transformations, side conditions, binding, and so on, the simple formal grammars that Chomsky classified back then remained the principal tool for specifying programming languages ever since.
Hierarchy of formal grammars and languages. Chomsky defined the nest of languages displayed in the next figure by imposing constraints on the grammatical rules that generate the languages.
The constraints are summarized in the following table. We say that
Here are some examples from each grammar family⁵, together with typical derivation trees and languages:
Does it really work like this in my head? In general, scientific models of reality usually do not claim that they are the reality. Physicists don’t claim that particles consist of density matrices used to model them. Grammars are just a computational model of language, born in the early days of the theory of computation. The phrase structure grammars were an attempt to explain language in computational terms. Nowadays even the programming language often don’t work that way anymore. It’s just a model.
However, when it comes to mental models of mental processes, the division between the reality and its models becomes subtle. They can reflect and influence each other. A computational model of a computer allows the computer to simulate itself. A language can be modeled within itself, and the model can be similar to the process that it models. How close can it get?
Dependency grammars
Dependency grammars are a step closer to capturing the process of sentence production. Grammatical dependency is a relation between words in a sentence. It relates a head word and an (ordered!) tuple of dependents. The sentence is produced as the dependents are chosen for the given head words, or the heads for the given dependents. The choices are made in the order in which the words occur. Here is how this works on the example of Groucho’s elephant sentence:
Unfolding dependencies. The pronoun “I” occurs first, and it can only form a sentence as a dependent on some verb. The verb “shot” is selected as the head of that dependency as soon as it is uttered. The sentence could then be closed if the verb “shot” is used as intransitive. If it is used as transitive, then the object of action needs to be selected as its other dependent. Groucho selects the noun “elephant”. English grammar requires that this noun is also the head of another dependency, with an article as its dependent. Since the article is required to precede the noun, the word “elephant” is not uttered before its dependent “an” or “the” is chosen. After the words “I shot an elephant” are uttered (or received), there are again multiple choices to be made: the sentence can be closed with no further dependents, or a dependent can be added to the head “shot”, or else it can be added to the head “elephant”. The latter two syntactic choices correspond to the different semantical meanings that create ambiguity. If the prepositional phrase “in my pajamas” is a syntactic dependent of the head “shot”, then the subject “I” wore the pajamas when they shot. If the prepositional phrase is a syntactic dependent of the head “elephant”, then the object of shooting wore the pajamas when they were shot. The two dependency analyses look like this, with the corresponding constituency analyses penciled above them.
The dependent phrase “in my pajamas” is headed by the preposition “in”, whose dependent is the noun “pajamas”, whose dependent is the possessive “my”. After that, the speaker has to choose again whether to close the sentence or to add another dependent phrase, say “while sleeping furiously”, which opens up the same two choices of syntactic dependency and semantic ambiguity. To everyone’s relief, the speaker chose to close the sentence.
Is dependency a syntactic or a semantic relation? The requirements that a dependency relation exists are usually syntactic. E.g., to form a sentence, a starting noun is usually a dependent of a verb. But the choice of a particular dependent or head assignment is largely semantical: whether I shot an elephant or a traffic sign. The choice of an article dependent on the elephant depends on the context, possibly remote: whether a particular elephant has been determined or not. If it has not been determined, then the form of the independent article an is determined syntactically, and not semantically.
So the answer to the above question seems to suggest that the partition of the relations between words into syntactic and semantic is too simplistic for some situations since the two aspects of language are not independent and can be inseparable.
Syntax as typing
Syntactic type-checking
In programming, type-checking is a basic error-detection mechanism: e.g., the inputs of an arithmetic operation are checked to be of type 𝖨𝗇𝗍𝖾𝗀𝖾𝗋, the birth dates in a database are checked to have the month field of type 𝖬𝗈𝗇𝗍𝗁, whose terms may be the integers 1,2,…, 12, and if someone’s birth month is entered to be 101, the error will be caught in type-checking. Types allow the programmer to ensure correct program execution by constraining the data that can be processed⁶.
In language processing, the syntactic types are used in a similar process, to restrict the scope of the word choices. Just like the type 𝖨𝗇𝗍𝖾𝗀𝖾𝗋 restricts the inputs of arithmetic operations tointegers, the syntactic type <verb> restricts the predicates in sentences to verbs. If you hear something sounding like “John lo℥∼ Mary’’, then without the type constraints, you have more than 3000 English words starting with “lo” to consider as possible completions. With the syntactic constraint that the word that you didn’t discern must be a transitive verb in third person singular, you are down to “lobs”, “locks”, “logs”,… maybe “loathes”, and of course, “loves”.
Parsing and typing
The rules of grammar are thus related to the type declarations in programs as
In the grammar listed above after the two parsings of Grouch’s elephant sentence, the terminal rules listed on the left are the basic typing statements, whereas the non-terminal rules on the right are type constructors, building composite types from simpler types. The constituency parse trees thus display the type structures of the parsed sentences. The words of the sentence occur as the leaves, whereas the inner tree nodes are the types. The branching nodes are the composite types and the non-branching nodes are the basic types. Constituency parsing is typing.
The dependency parsings, on the other hand, do a strange thing: having routed the dependencies from a head term to its dependents through the constituent types that connect them, that sidestep the types and directly connect the head with its dependents. This is what the above dependency diagrams show. Dependency parsing reduces syntactic typing to term dependencies.
But only the types that record nothing but the term dependencies can be reduced to them. The two dependency parsings of the elephant sentence look something like this:
The expressions below the two copies of the sentence are the syntactic types captured by dependency parsings. They are generated by tupling reference variables x,y,… etc., with their left adjoints denoted by overlining and their right adjoints by underlining. Such syntactic types form pregroups, an algebraic structure introduced in the late 1990s by Jim Lambek, as a simplification of his syntactic calculus of categorial grammars. He introduced the latter in the late 1950s, to explore correctness decision procedures applicable to Ajdukiewicz’s syntactic connexions from the 1930s and Bar-Hillel’s quasi-arithmetic from the early 1950s. The entire tradition of reference-based logic of meaning goes back to Husserl’s “Logical investigations”. It is still actively studied. We only touch the pregroups, and only as a stepping stone.
Pregroup grammars
Pregroup definition and properties
A pregroup is an ordered monoid with left and right adjoints. An ordered monoid is a monoid where the underlying set is ordered and the monoid product is monotone.
If you know what this means, you can skip this section. You can also skip it if you don’t need to know how it works, since the main idea should transpire as you go anyway. Just in case, here are the details.
It is easy to show that all elements of all pregroups, as ordered monoids with adjoints, satisfy the following claims:
The simplest pregroups are freely generated from given posets of basic types. An element of the free pregroup are the finite strings of basic types, with the order induced pointwise, and (most importantly) by the above rules for the adjoints. If you want to see a fun non-free example, consider the monoid of monotone maps from integers to integers. Taken with the pointwise order, they form a pregroup because every bounded set contains its meet and join, and therefore every monotone map preserves them, which allows constructing both of its adjoints.
Here is why pregroups help with understanding language.
Parsing as type-checking
To check semantic correctness of a given phrase, each word in the phrase is first assigned a pregroup element as its syntactic type. The type of the phrase is the product of the types of its words, multiplied in the pregroup. The phrase is a well-formed sentence if its syntactic type is pregroup unit 𝜄. In other words, we compute the syntactic type S of the given phrase, and it is a sentence just when S≤𝜄. The computation can be reduced to drawing arcs to connect each type x with an adjoint, be it left or right, and coupling them so that each pair falls below 𝜄. If the arcs are well-nested⁷, eliminating the adjacent adjoints and replacing them by the unit 𝜄 makes other adjoints adjacent, and you proceed until you are left with the unit. The original type must have been below it, since the procedure was non-descending. If the types cannot be matched in this way, the phrase is not a sentence, and the type actually tells you what kind of a phrase it is.
We obviously skipped all details and some are significant. In practice, the head of the sentence is annotated by a type variable S that does not discharged with an adjoint, and its wire does not arc to another type in the sentence but points straight out. This wire can be interpreted as a reference to another sentence. The other wires are arcs between pairs of adjoints. They often deviate from the dependency references, mainly because it is expected that the words of the same type in a lexicon should receive the same pregroup type. The advantages of this approach are a matter of contention. The only point that matters here is that syntax is typing⁸.
Beyond sentence
Why do we partition speech into sentences?
Why don’t we stream words, like network routers stream packets? Why can’t we approximate what we want to say by adding more words, just like numbers approximate points in space by adding more digits?
The old answer is: “We make sentences to catch a breath”. When we complete a sentence, we release the dependency threads between its words. Without that, the dependencies accumulate, and you can only keep so many threads in your mind at a time. Breathing keeps references from knotting.
Exercise. We make long sentences for a variety of reasons and purposes. A sample of a long sentence is provided below⁹. Try to split it into shorter ones. What is gained and what lost by such operations? Ask a chatbot to do it.
Anaphora is a syntactic pattern that occurs within or between sentences. In rhetorics and poetry, it is the figure of speech where the same phrase is repeated to amplify the argument or thread a reference. In ChatGPT’s view, it works because the rhythm of the verse echoes the patterns of meaning:
In every word, life’s rhythm beats,
In every truth, life’s voice speaks.
In every dream, life’s vision seeks,
In every curse, life’s revenge rears.
In every laugh, life’s beat nears,
In every pause, life’s sound retreats.
Syntactic partitions reflect the semantic partitions. Sentential syntax is the discipline of charging and discharging syntactic dependencies to transmit semantic references.
Language articulations and network layers
The language streams are articulated into words, sentences, paragraphs, sections, chapters, books, libraries, literatures; speakers tell stories, give speeches, maintain conversations, follow conventions, comply with protocols. Computers reduce speech to tweets and expand it to chatbots.
The layering of language articulations is an instance of stratification of communication channels. Artificial languages evolved the same layering. The internet stack is another instance.
Information carriers are implemented on top of each other, in living organisms, in the communication networks between them, and in all languages the humans developed around us. Reference coupling mechanisms similar to syntactic types emerge at all levels, in many varieties. The pregroup structure of sentential syntax is reflected by the question-answer structure of simple discourse and by the SYN-ACK pattern of the basic network protocols. Closely related structures arise in protocols across the board. Here a high-level view of a standard 2-factor authentication protocol, presented as a basic cord space¹⁰:
Here is the same protocol displayed with the cord actions viewed as adjoint types, with the corresponding interactions are marked by the same sequence numbers:
Mathematical models of natural-language conversations, security and network protocols, software-system architectures share features. They may be features of a high-level deep syntax, shared by all communication processes. Such syntax could conceivably arise from the physical laws of information processing, or from innate capabilities of a species, as hypothesized in the Chomskian theory.
Beyond syntax
We have seen how syntactic typing supports semantic information transmission. Already Groucho’s elephant sentence fed syntactic and semantic ambiguities back into each other.
But if syntactic typing and semantic assignments steer each other, then the generally adopted restriction of syntactic analyses to sentences cannot be justifiable, since semantic ambiguities certainly cannot be resolved on the level of a sentence. Groucho proved that.
Semantic context-sensitivity
Consider the sentence
John said he was sick and got up to leave.
Adding a context changes its meaning:
Mark collapsed on bed.
John said he was sick and got up to leave.
For most people, “he was sick” now refers to Mark. Note that the silent “he” in “[he] got up to leave” remains bound to John. Or take
Few professors came to the party and had a great time.
The meaning does not significantly change if we split the sentence in two and expand :
Since it started late, few professors came to the party. They had a great time.
Like in the John and Mark example, a context changes the semantical binding, this time of “it”:
There was a departmental meeting at 5. Since it started late, few professors came to the party. They had a great time.
But this time, moreover, binding “they’’ in a first sentence changes the binding of “they’’ in the last sentence:
They invited professors. There was a departmental meeting at 5. Since it started late, few professors came to the party. They had a great time.
The story is now that students had a great time — the students who are never named, but derived from the professors!
Syntactic context-sensitivity
On the level of sentential syntax of natural languages, as generated by formal grammars, proving context-sensitivity amounts to finding a language that contains some of the patterns known to require a context-sensitive grammar, such as aⁿbⁿcⁿ for arbitrary letters a,b,c∈𝛴 and any number n, or ww, www, or wwww for arbitrary word w∈𝛴*. Since people are unlikely to go around saying to each other things like aⁿbⁿcⁿ, the task boiled down to finding languages which require constructions of repetitive words in the form ww, www, etc. The quest for such examples became quite competitive.
Since a language with a finite lexicon has a finite number of words for numbers, at some point you have to say something like “quadrillion quadrillion” if quadrillion is the largest number denoted by a single word. But it was decided that numbers don’t count.
Then someone found that in Central-African language Bambara, the construction that says “any dog” is in the form “dog dog”. Then someone else claimed context-sensitive nesting phenomena in Dutch, but not everyone agreed. Eventually, most people settled on Swiss German as a definitely context sensitive language, and the debate about syntactic contexts-sensitivity subsided.
With a hindsight, it has the main features of theological debates. The main problem with counting how many angels can stand on the tip of a needle is that angels don’t stand on needles. The main problem with syntactic context sensitivity is that contexts are never purely syntactic.
Communication is the process of sharing semantical contexts
Chomsky noted that natural language should be construed as context-sensitive in the paper where he defined the notion of context-sensitivity. Restricting the language models to syntax, and syntax to sentences, made proving his observation into a conundrum.
But now that the theology of syntactic contexts is behind us, and the language models are in front of us, waiting to be understood, the question arises: How are contexts really processed? How do we do it, and how do the chatbots do it? How are the big contexts stored? The reader of a novel builds the context of that novel starting from the first sentence, and refers to it 800 pages later. What does the context of a big novel look like in a language model?
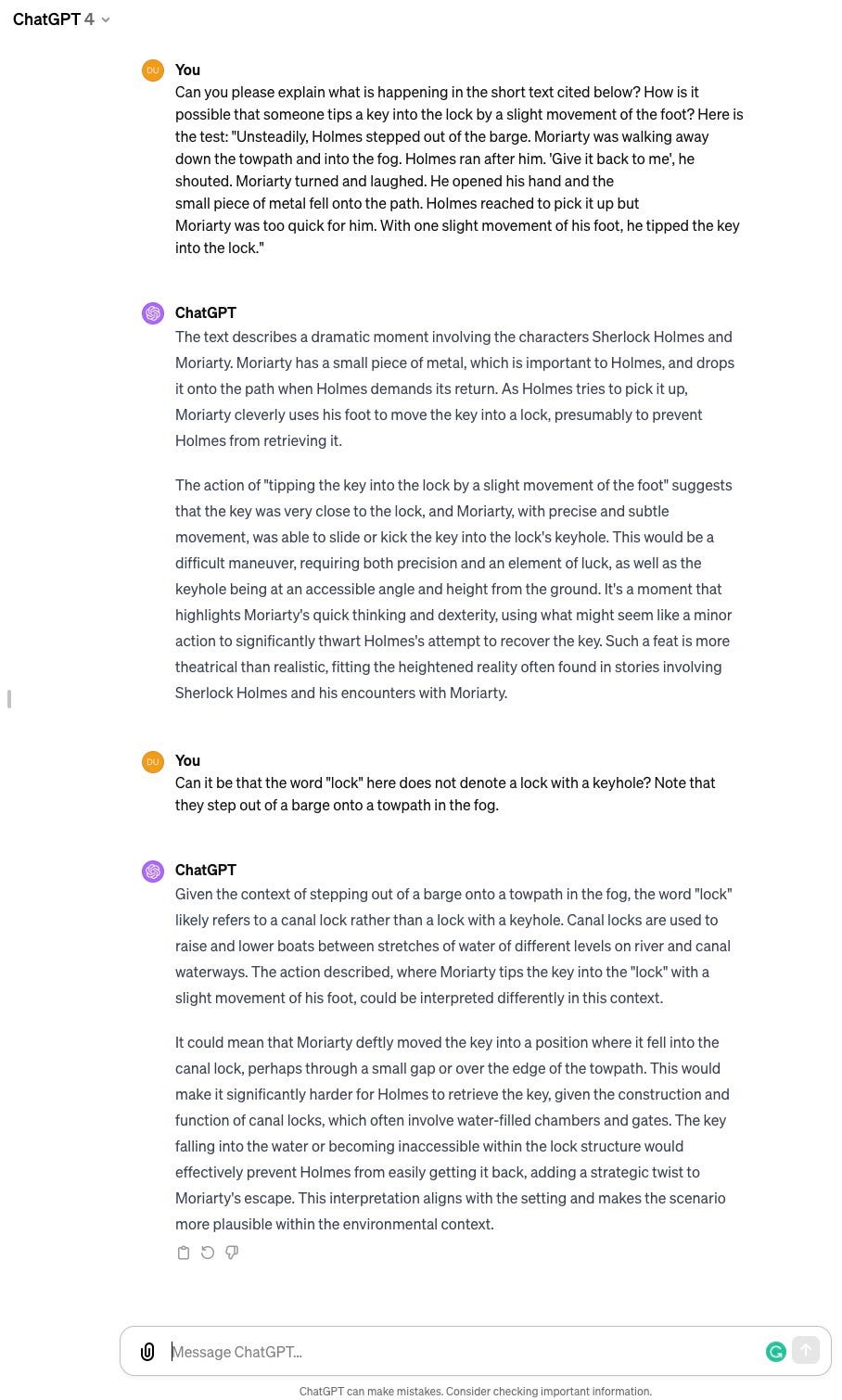
Semantic dependencies on remote contexts have been one of the central problems of natural language processing from the outset. The advances in natural language processing that we witness currently are to a large extent based on the progress in solving that that problem. To get an idea about the challenge, consider the following paragraph¹¹:
Unsteadily, Holmes stepped out of the barge. Moriarty was walking away
down the towpath and into the fog. Holmes ran after him. `Give it back to me’, he shouted. Moriarty turned and laughed. He opened his hand and the
small piece of metal fell onto the path. Holmes reached to pick it up but
Moriarty was too quick for him. With one slight movement of his foot, he tipped the key into the lock.
If you are having trouble understanding what just happened, you are in a good company. Without sufficient hints, the currently available chatbots do not seem to be able to produce a correct interpretation¹². In the next part, we will see how semantic contexts arise, including much larger, and after that we will be ready to explain how they are processed.
Attributions
As mentioned in the text, the anaphoric verses “In every… life’s” were composed by ChatGPT, and the illustration of the sentence “Colorless green ideas sleep furiously” was created by Dall-E. All other graphics were created by the author.
Notes
¹The fact that most people do not understand each other even when they speak the same language echoes the fact that most members of the same species do not breed, but select mates through complex rituals.
²Early linguists (Humboldt, Boas, Sapir, Whorf) were mainly focused on understanding different worldviews (Weltanschauung, Weltanzicht) by understanding different languages (German, Hebrew, English, Hopi, Nahuan…).
³The partition of trivium echoes the organization of Organon, where the first book, devoted to categories, was followed by three devoted to logic, and the final two to topical argumentations, feeding into rhetorics.
⁴For any set A write A* to denote the set of all n-tuples 𝛼={a1,a2,…,an} from A, for all n = 0,1,… and arbitrary a1,a2,…,an from A. Since n can be 0, A* includes the empty tuple, written <>. Denoting the set of all labels by 𝛬 = 𝛴∪𝛯, the set of rules is a finite binary relation [::=] ⊆ 𝛬*×𝛬*, obtained by listing (1).
⁵Chomsky’s “Type-x’’ terminology is unrelated with the “syntactic type’’ terminology. Many linguists use “syntactic categories’’ instead. But the term “category’’ is in the meantime widely used in mathematics in a completely different meaning, increasingly applied in linguistics.
⁶For historic and logical background of the mathematical theory of types, see Ch.1 of the book “Programs as diagrams”.
⁷If the arcs are not well-nested, as it is the case, for instance, with Dutch syntax, then the procedure is more complicated, but we won’t go into that.
⁸For more details on pregroup-based syntactic analysis see Jim Lambek’s book “From Word to Sentence”. For the logical and mathematical background, see “Lambek prergroups are Frobenius spiders”.
⁹“That night he dreamt of horses on a high plain where the spring rains had brought up the grass and the wildflowers out of the ground and the flowers ran all blue and yellow far as the eye could see and in the dream he was among the horses running and in the dream he himself could run with the horses and they coursed the young mares and fillies over the plain where their rich bay and their chestnut colors shone in the sun and the young colts ran with their dams and trampled down the flowers in a haze of pollen that hung in the sun like powdered gold and they ran he and the horses out along the high mesas where the ground resounded under their running hooves and they flowed and changed and ran and their manes and tails blew off them like spume and there was nothing else at all in that high world and they moved all of them in a resonance that was like a music among them and they were none of them afraid horse nor colt nor mare and they ran in that resonance which is the world itself and which cannot be spoken but only praised.” — Cormac McCarthy, All the Pretty Horses
¹⁰Cord spaces are a simple formalism for analyzing security protocols.
¹¹The paragraph is a variation on the context of Sir Arthur Conan Doyle’s short story “The final problem”.
¹² On key attention span:
Syntax: the language form was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.