
System Design Series: 0 to 100 Guide to Data Streaming Systems
System Design Series: The Ultimate Guide for Building High-Performance Data Streaming Systems from Scratch!
Setting up an example problem: A Recommendationxt System
“Data Streaming” sounds incredibly complex and “Data Streaming Pipelines” even more so. Before we talk about what that means and burden ourselves with jargon, let’s start with the reason for the existence of any software system, a problem.
Our problem is pretty simple, we have to build a recommendation system for an e-commerce website (something like Amazon) i.e. a service that returns a set of products for a particular user based on the preferences of that user. We don’t need to tire ourselves with how it works just yet (more on that later), for now, we will focus on how data is sent to this service, and how it returns data.
Data is sent to the service in the form of “events”. Each of these events is a particular action performed by the user. For example, a click on a particular product, or a search query. In simple words, all user interactions on our website, from a simple scroll to an expensive purchase, is considered an “event”.
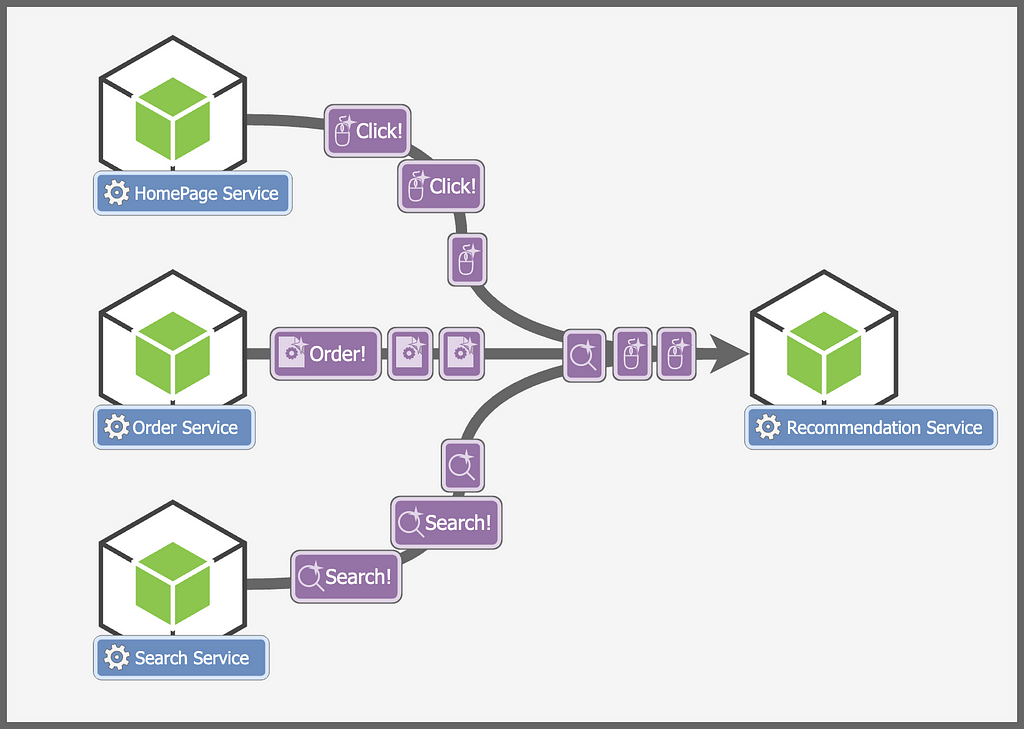
These events essentially tell us about the user. For example, a user interested in buying a gaming PC might also be interested in a gaming keyboard or mouse.
Every once in a while, our service gets a request to fetch recommendations for a user, its job is simple, respond with a list of products the user is interested in.

For now, we don’t care how this recommendations list is populated, assume that this “Recommendation Service” does some magical steps (more on this magic later at the end of the post, for now, we don’t care much about the logic of these steps) and figures out what our users prefer.
Recommendations are usually an afterthought in many systems, but it's much more critical than you may think. Almost every application you use relies heavily on recommendation services like these to drive user actions. For example, according to this paper, 35% of Amazon web sales were generated through their recommended items.
The problem however lies in the sheer scale of data. Even if we run just a moderately popular website, we could still be getting hundreds of thousands of events per second (maybe even millions) at peak time! And if there is a new product or a huge sale, then it might go much higher.
And our problems don’t end there. We have to process this data (perform the magic we talked about before) in real-time and provide recommendations to users in real time! If there is a sale, even a few minutes of delay in updating recommendations could cause significant financial losses to a business.
What is a Data Streaming Pipeline?
A Data Streaming Pipeline is just what I described above. It is a system that ingests continuous data (like events), performs multiple processing steps, and stores the results for future use.
In our case, the events will come from multiple services, our processing steps will involve a few “magical” steps to compute recommendations about the user, and then we will update the recommendations for each user in a data store. When we get a query for recommendations for a particular user, we simply fetch the recommendations we stored earlier and return them.
The purpose of this post is to understand how to handle this scale of data, how to ingest it, process it, and output it for use later, rather than to understand the actual logic of the processing steps (but we will still dive a little into it for fun).
Creating a Data Streaming Pipeline: Step-by-step
There is a lot to talk about, ingestion, processing, output, and querying, so let’s approach it one step at a time. Think of each step as a smaller, isolated problem. At each step, we will start with the most intuitive solution, see why it doesn’t work, and build a solution that does work.
Data Ingestion
Let’s start at the beginning of the pipeline, data ingestion. The data ingestion problem is pretty easy to understand, the goal is just to ingest events from multiple sources.
But while the problem seems simple at first, it comes with its fair share of nuances,
- The scale of data is extremely high, easily going into hundreds of thousands of events per second.
- All these events have to be ingested in real-time, we cannot have a delay of even a few seconds.
Let’s start simple, the most intuitive way to achieve this is to send each event as a request to the recommendation system, but this solution has a lot of problems,
- Services sending events shouldn’t need to wait for a response from our recommendation service. That will increase latency on the services and block them till the recommendation service sends them a 200. They should instead send fire-and-forget requests.
- The number of events would be highly volatile, going up and down throughout the day (for example, going up in the evenings or during sales), we would have to scale our recommendation service based on the scale of events. This is something we will have to manage and calculate.
- If our recommendation service crashes, then we will lose events while it is down. In this architecture, our recommendation service is a single point of failure.
Let’s fix this by using a message broker or an “event streaming platform” like Apache Kafka. If you don’t know what that is, it's simply a tool that you set up that can ingest messages from “publishers” to certain topics. “Subscribers” listen or subscribe to a topic and whenever a message is published on the topic, the subscriber receives the message. We will talk more about Kafka topics in the next section.
What you need to know about Kafka is that it facilitates a decoupled architecture between producers and consumers. Producers can publish a message on a Kafka topic and they don’t need to care when, how, or if the consumer consumes the message. The consumer can consume the message on its own time and process it. Kafka would also facilitate a very high scale since it can scale horizontally, and linearly, providing almost infinite scaling capability (as long as we keep adding more machines)

So each service sends events to Apache Kafka. The recommendation service fetches these events from Kafka. Let’s see how this helps us –
- Events are processed asynchronously, services no longer need to wait for the response from the Recommendation Service.
- It is easier to scale Kafka, and if the scale of events increases, Kafka will simply store more events while we scale up our recommendation service.
- Even if the recommendation service crashes, we won’t lose any events. Events are persisted in Kafka so we never lose any data.
Now we know how to ingest events into our service, let’s move to the next part of the architecture, processing events.
Data Processing
Data processing is an integral part of our data pipeline. Once we receive events, we need to generate new recommendations for the user. For example, if a user searches for “Monitor”, we need to update the recommendations for this user based on this search, maybe add that the user is interested in monitors.
Before we talk more about the architecture, let’s forget all this and talk a little about how to generate recommendations. This is also where machine learning comes in, it's not very important to understand this to continue with the post, but it’s pretty fun so I will try to give a very basic brief description of how it works.
Let’s try to better understand user interactions and what they mean. When the user interacts with our website with a search, a click, or a scroll event, the user is telling us something about his/her interests. Our goal is to understand these interactions and use them to understand the user.
When you think of a user, you probably think of a person, with a name, age, etc. but for our purposes, it's easier to think of every user as a vector, or simply a set of numbers. It sounds confusing(how can a user be represented as a set of numbers after all), but bear with me, and let’s see how this works.
Let’s assume we can represent each user(or his/her interests) as a point in a 2D space. Each axis represents a trait of our user. Let’s assume the X-axis represents how much he/she likes to travel, and the Y-axis represents how much he/she likes photography. Each action by the user influences the position of this user in the 2D space.
Let’s say a user starts with the following point in our 2D space —

When the user searches for a “travel bag”, we move the point to the right since that hints that the user likes traveling.
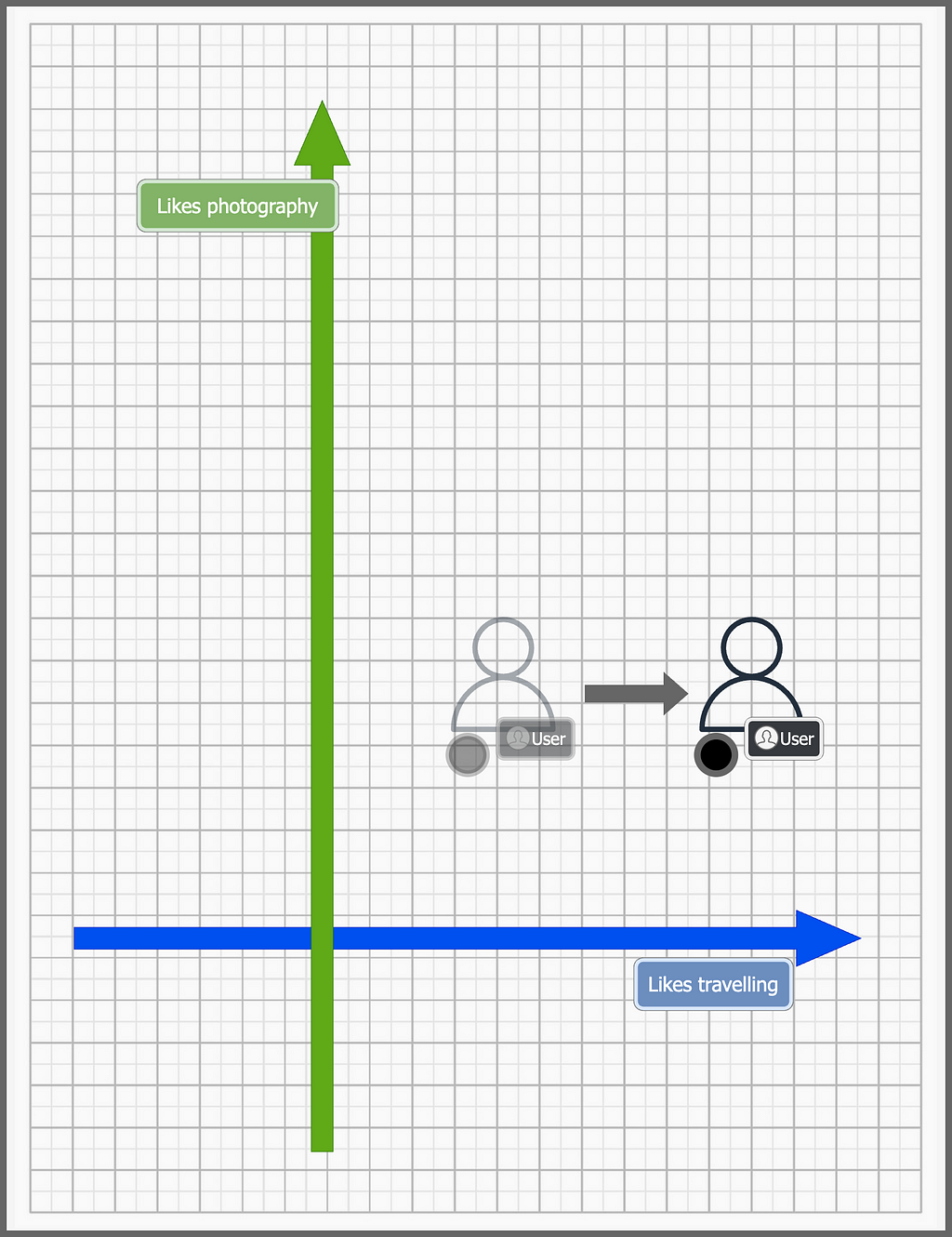
If the user had searched for a camera, we would have moved the user upwards in the Y-axis instead.
We also represent each product as a point in the same 2D space,

The position of the user in the above diagram indicates that the user loves to travel, and also likes photography a little. Each of the products is also placed according to how relevant they are to photography and traveling.
Since the user and the products are just points in a 2-dimensional space, we can compare them and perform mathematical operations on them. For example, from the above diagram, we can find the nearest product to the user, in this case, the suitcase, and confidently say that it is a good recommendation for the user.
The above is a very basic introduction to recommendation systems (more on them at the end of the post). These vectors (usually much larger than 2 dimensions) are called embeddings (user embeddings that represent our users, and product embeddings that represent products on our website). We can generate them using different types of machine-learning models and there is a lot more to them than what I described but the basic principle remains the same.
Let’s come back to our problem. For every event, we need to update the user embeddings (move the user on our n-dimensional chart), and return related products as recommendations.
Let’s think of a few basic steps for each event that we need to perform to generate these embeddings,
- update-embeddings: Update the user’s embeddings
- gen-recommendations: Fetch products related to (or near) the user embeddings
- save: Save the generated recommendations and events
We can build a Python service for each type of event.
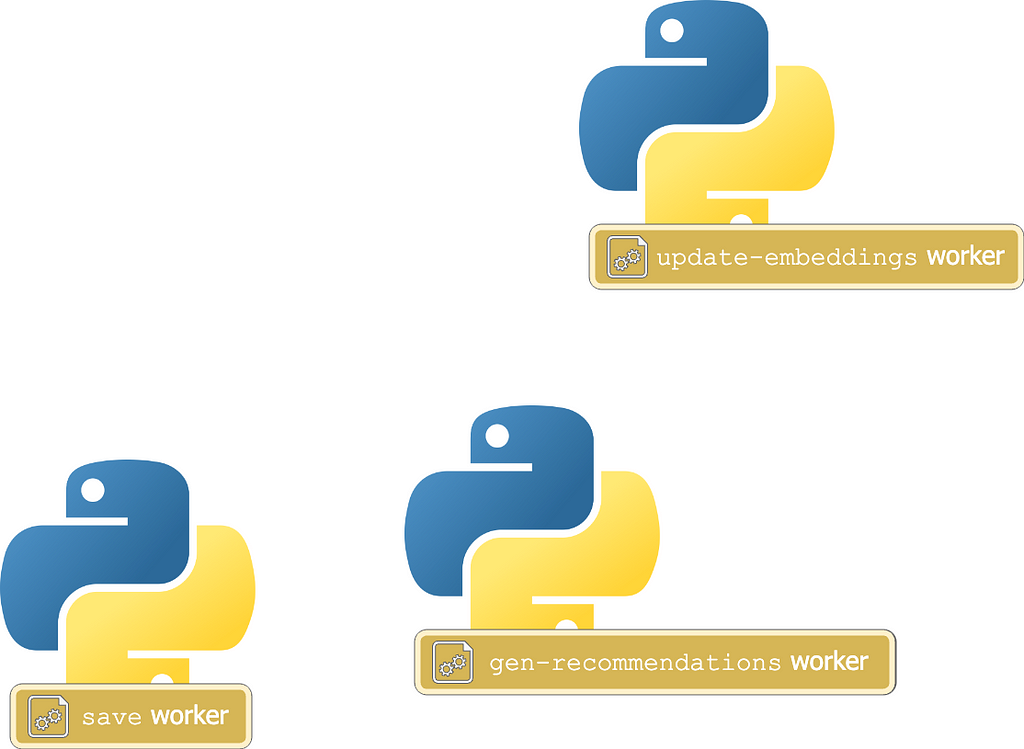
Each of these microservices would listen to a Kafka topic, process the event, and send it to the next topic, where a different service would be listening.

Since we are again using Kafka instead of sending requests, this architecture gives us all the advantages we discussed before as well. No single Python microservice is a single point of failure and it's much easier to handle scale. The last service save-worker has to save the recommendations for future use. Let’s see how that works.
Data Sinks
Once we have processed an event, and generated recommendations for it, we need to store the event and recommendation data. Before we decide where to store events and recommendation data, let’s consider the requirements for the data store
- Scalability and high write throughput— Remember we have a lot of incoming events, and each event also updates user recommendations. This means our data store should be able to handle a very high number of writes. Our database should be highly scalable and should be able to scale linearly.
- Simple queries — We are not going to perform complex JOINs, or do different types of queries. Our query needs are relatively simple, given a user, return the list of precomputed recommendations
- No ACID Requirements — Our database doesn’t need to have strong ACID compliance. It doesn’t need any guarantees for consistency, atomicity, isolation, and durability.
In simple terms, we are concerned with a database that can handle an immense amount of scale, with no extra bells and whistles.
Cassandra is a perfect choice for these requirements. It scales linearly due to its decentralized architecture and can scale to accommodate very high write throughput which is exactly what we need.
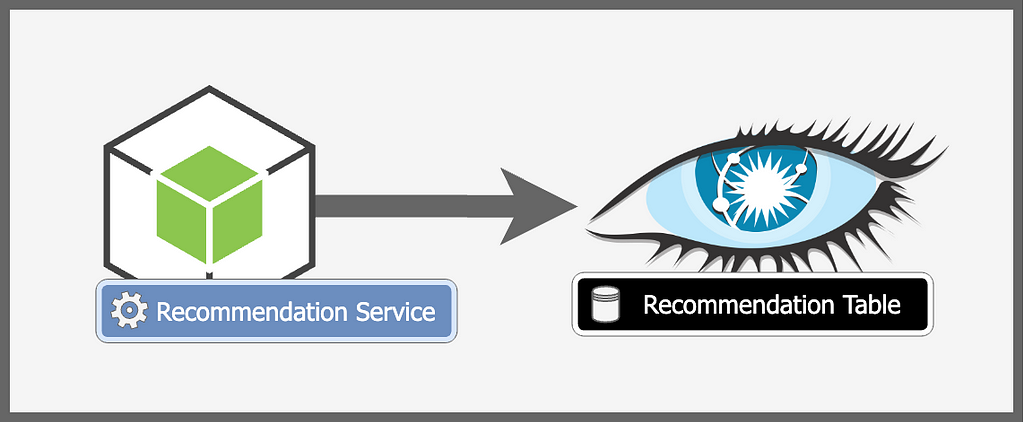
We can use two tables, one for storing recommendations for every user, and the other for storing events. The last Python microservice save worker would save the event and recommendation data in Cassandra.

Querying
Querying is pretty simple. We have already computed and persisted recommendations for each user. To query these recommendations, we simply need to query our database and fetch recommendations for the particular user.
Full Architecture
And, that’s it! We are done with the entire architecture, let’s draw out the complete architecture and see what it looks like.

For more learning
Kafka
Kafka is an amazing tool developed by LinkedIn to handle an extreme amount of scale (this blog post by LinkedIn in 2015 talked about ~13 million messages per second!).
Kafka is amazing at scaling linearly and handling crazy high scale, but to build such systems, engineers need to know and understand Kafka, what is it, how it works, and how it fares against other tools.
I wrote a blog post in which I explained what Kafka is, how it differs from message brokers, and excerpts from the original Kafka paper written by LinkedIn engineers. If you liked this post, check out my post on Kafka —
System Design Series: Apache Kafka from 10,000 feet
Cassandra
Cassandra is a unique database meant to handle very high write throughput. The reason it can handle such high throughput is due to its high scalability decentralized architecture. I wrote a blog post recently discussing Cassandra, how it works, and most importantly when to use it and when not to —
System Design Solutions: When to use Cassandra and when not to
Recommendation Systems
Recommendation systems are an amazing piece of technology, and they are used in almost all applications that you and I use today. In any system, personalization and recommendation systems form the crux of the search and discovery flow for users.
I have been writing quite a bit about search systems, and I have touched up a bit on how to build basic personalization in search systems, but my next topic will be to dive deeper into the nitty gritty of recommendation engines, how they work, and how to architect them. If that sounds interesting to you, follow me on Medium for more content! I also post a lot of byte-sized content on LinkedIn for regular reading, for example, this post on Kafka Connect that describes how it works, and why it is so popular with just one simple diagram.
Conclusion
Hope you enjoyed this post, if you have any feedback about the post or any thoughts on what I should talk about next, you can post it as a comment!
System Design Series: 0 to 100 Guide to Data Streaming Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
System Design Series: The Ultimate Guide for Building High-Performance Data Streaming Systems from Scratch!

Setting up an example problem: A Recommendationxt System
“Data Streaming” sounds incredibly complex and “Data Streaming Pipelines” even more so. Before we talk about what that means and burden ourselves with jargon, let’s start with the reason for the existence of any software system, a problem.
Our problem is pretty simple, we have to build a recommendation system for an e-commerce website (something like Amazon) i.e. a service that returns a set of products for a particular user based on the preferences of that user. We don’t need to tire ourselves with how it works just yet (more on that later), for now, we will focus on how data is sent to this service, and how it returns data.
Data is sent to the service in the form of “events”. Each of these events is a particular action performed by the user. For example, a click on a particular product, or a search query. In simple words, all user interactions on our website, from a simple scroll to an expensive purchase, is considered an “event”.
These events essentially tell us about the user. For example, a user interested in buying a gaming PC might also be interested in a gaming keyboard or mouse.
Every once in a while, our service gets a request to fetch recommendations for a user, its job is simple, respond with a list of products the user is interested in.
For now, we don’t care how this recommendations list is populated, assume that this “Recommendation Service” does some magical steps (more on this magic later at the end of the post, for now, we don’t care much about the logic of these steps) and figures out what our users prefer.
Recommendations are usually an afterthought in many systems, but it's much more critical than you may think. Almost every application you use relies heavily on recommendation services like these to drive user actions. For example, according to this paper, 35% of Amazon web sales were generated through their recommended items.
The problem however lies in the sheer scale of data. Even if we run just a moderately popular website, we could still be getting hundreds of thousands of events per second (maybe even millions) at peak time! And if there is a new product or a huge sale, then it might go much higher.
And our problems don’t end there. We have to process this data (perform the magic we talked about before) in real-time and provide recommendations to users in real time! If there is a sale, even a few minutes of delay in updating recommendations could cause significant financial losses to a business.
What is a Data Streaming Pipeline?
A Data Streaming Pipeline is just what I described above. It is a system that ingests continuous data (like events), performs multiple processing steps, and stores the results for future use.
In our case, the events will come from multiple services, our processing steps will involve a few “magical” steps to compute recommendations about the user, and then we will update the recommendations for each user in a data store. When we get a query for recommendations for a particular user, we simply fetch the recommendations we stored earlier and return them.
The purpose of this post is to understand how to handle this scale of data, how to ingest it, process it, and output it for use later, rather than to understand the actual logic of the processing steps (but we will still dive a little into it for fun).
Creating a Data Streaming Pipeline: Step-by-step
There is a lot to talk about, ingestion, processing, output, and querying, so let’s approach it one step at a time. Think of each step as a smaller, isolated problem. At each step, we will start with the most intuitive solution, see why it doesn’t work, and build a solution that does work.
Data Ingestion
Let’s start at the beginning of the pipeline, data ingestion. The data ingestion problem is pretty easy to understand, the goal is just to ingest events from multiple sources.
But while the problem seems simple at first, it comes with its fair share of nuances,
- The scale of data is extremely high, easily going into hundreds of thousands of events per second.
- All these events have to be ingested in real-time, we cannot have a delay of even a few seconds.
Let’s start simple, the most intuitive way to achieve this is to send each event as a request to the recommendation system, but this solution has a lot of problems,
- Services sending events shouldn’t need to wait for a response from our recommendation service. That will increase latency on the services and block them till the recommendation service sends them a 200. They should instead send fire-and-forget requests.
- The number of events would be highly volatile, going up and down throughout the day (for example, going up in the evenings or during sales), we would have to scale our recommendation service based on the scale of events. This is something we will have to manage and calculate.
- If our recommendation service crashes, then we will lose events while it is down. In this architecture, our recommendation service is a single point of failure.
Let’s fix this by using a message broker or an “event streaming platform” like Apache Kafka. If you don’t know what that is, it's simply a tool that you set up that can ingest messages from “publishers” to certain topics. “Subscribers” listen or subscribe to a topic and whenever a message is published on the topic, the subscriber receives the message. We will talk more about Kafka topics in the next section.
What you need to know about Kafka is that it facilitates a decoupled architecture between producers and consumers. Producers can publish a message on a Kafka topic and they don’t need to care when, how, or if the consumer consumes the message. The consumer can consume the message on its own time and process it. Kafka would also facilitate a very high scale since it can scale horizontally, and linearly, providing almost infinite scaling capability (as long as we keep adding more machines)
So each service sends events to Apache Kafka. The recommendation service fetches these events from Kafka. Let’s see how this helps us –
- Events are processed asynchronously, services no longer need to wait for the response from the Recommendation Service.
- It is easier to scale Kafka, and if the scale of events increases, Kafka will simply store more events while we scale up our recommendation service.
- Even if the recommendation service crashes, we won’t lose any events. Events are persisted in Kafka so we never lose any data.
Now we know how to ingest events into our service, let’s move to the next part of the architecture, processing events.
Data Processing
Data processing is an integral part of our data pipeline. Once we receive events, we need to generate new recommendations for the user. For example, if a user searches for “Monitor”, we need to update the recommendations for this user based on this search, maybe add that the user is interested in monitors.
Before we talk more about the architecture, let’s forget all this and talk a little about how to generate recommendations. This is also where machine learning comes in, it's not very important to understand this to continue with the post, but it’s pretty fun so I will try to give a very basic brief description of how it works.
Let’s try to better understand user interactions and what they mean. When the user interacts with our website with a search, a click, or a scroll event, the user is telling us something about his/her interests. Our goal is to understand these interactions and use them to understand the user.
When you think of a user, you probably think of a person, with a name, age, etc. but for our purposes, it's easier to think of every user as a vector, or simply a set of numbers. It sounds confusing(how can a user be represented as a set of numbers after all), but bear with me, and let’s see how this works.
Let’s assume we can represent each user(or his/her interests) as a point in a 2D space. Each axis represents a trait of our user. Let’s assume the X-axis represents how much he/she likes to travel, and the Y-axis represents how much he/she likes photography. Each action by the user influences the position of this user in the 2D space.
Let’s say a user starts with the following point in our 2D space —
When the user searches for a “travel bag”, we move the point to the right since that hints that the user likes traveling.
If the user had searched for a camera, we would have moved the user upwards in the Y-axis instead.
We also represent each product as a point in the same 2D space,
The position of the user in the above diagram indicates that the user loves to travel, and also likes photography a little. Each of the products is also placed according to how relevant they are to photography and traveling.
Since the user and the products are just points in a 2-dimensional space, we can compare them and perform mathematical operations on them. For example, from the above diagram, we can find the nearest product to the user, in this case, the suitcase, and confidently say that it is a good recommendation for the user.
The above is a very basic introduction to recommendation systems (more on them at the end of the post). These vectors (usually much larger than 2 dimensions) are called embeddings (user embeddings that represent our users, and product embeddings that represent products on our website). We can generate them using different types of machine-learning models and there is a lot more to them than what I described but the basic principle remains the same.
Let’s come back to our problem. For every event, we need to update the user embeddings (move the user on our n-dimensional chart), and return related products as recommendations.
Let’s think of a few basic steps for each event that we need to perform to generate these embeddings,
- update-embeddings: Update the user’s embeddings
- gen-recommendations: Fetch products related to (or near) the user embeddings
- save: Save the generated recommendations and events
We can build a Python service for each type of event.
Each of these microservices would listen to a Kafka topic, process the event, and send it to the next topic, where a different service would be listening.
Since we are again using Kafka instead of sending requests, this architecture gives us all the advantages we discussed before as well. No single Python microservice is a single point of failure and it's much easier to handle scale. The last service save-worker has to save the recommendations for future use. Let’s see how that works.
Data Sinks
Once we have processed an event, and generated recommendations for it, we need to store the event and recommendation data. Before we decide where to store events and recommendation data, let’s consider the requirements for the data store
- Scalability and high write throughput— Remember we have a lot of incoming events, and each event also updates user recommendations. This means our data store should be able to handle a very high number of writes. Our database should be highly scalable and should be able to scale linearly.
- Simple queries — We are not going to perform complex JOINs, or do different types of queries. Our query needs are relatively simple, given a user, return the list of precomputed recommendations
- No ACID Requirements — Our database doesn’t need to have strong ACID compliance. It doesn’t need any guarantees for consistency, atomicity, isolation, and durability.
In simple terms, we are concerned with a database that can handle an immense amount of scale, with no extra bells and whistles.
Cassandra is a perfect choice for these requirements. It scales linearly due to its decentralized architecture and can scale to accommodate very high write throughput which is exactly what we need.
We can use two tables, one for storing recommendations for every user, and the other for storing events. The last Python microservice save worker would save the event and recommendation data in Cassandra.
Querying
Querying is pretty simple. We have already computed and persisted recommendations for each user. To query these recommendations, we simply need to query our database and fetch recommendations for the particular user.
Full Architecture
And, that’s it! We are done with the entire architecture, let’s draw out the complete architecture and see what it looks like.
For more learning
Kafka
Kafka is an amazing tool developed by LinkedIn to handle an extreme amount of scale (this blog post by LinkedIn in 2015 talked about ~13 million messages per second!).
Kafka is amazing at scaling linearly and handling crazy high scale, but to build such systems, engineers need to know and understand Kafka, what is it, how it works, and how it fares against other tools.
I wrote a blog post in which I explained what Kafka is, how it differs from message brokers, and excerpts from the original Kafka paper written by LinkedIn engineers. If you liked this post, check out my post on Kafka —
System Design Series: Apache Kafka from 10,000 feet
Cassandra
Cassandra is a unique database meant to handle very high write throughput. The reason it can handle such high throughput is due to its high scalability decentralized architecture. I wrote a blog post recently discussing Cassandra, how it works, and most importantly when to use it and when not to —
System Design Solutions: When to use Cassandra and when not to
Recommendation Systems
Recommendation systems are an amazing piece of technology, and they are used in almost all applications that you and I use today. In any system, personalization and recommendation systems form the crux of the search and discovery flow for users.
I have been writing quite a bit about search systems, and I have touched up a bit on how to build basic personalization in search systems, but my next topic will be to dive deeper into the nitty gritty of recommendation engines, how they work, and how to architect them. If that sounds interesting to you, follow me on Medium for more content! I also post a lot of byte-sized content on LinkedIn for regular reading, for example, this post on Kafka Connect that describes how it works, and why it is so popular with just one simple diagram.
Conclusion
Hope you enjoyed this post, if you have any feedback about the post or any thoughts on what I should talk about next, you can post it as a comment!
System Design Series: 0 to 100 Guide to Data Streaming Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.