
The Power of Geospatial Intelligence and Similarity Analysis for Data Mapping
Strategically enhancing address mapping during data integration using geocoding and string matching
Many individuals in the big data industry may encounter the following scenario: Is the acronym “TIL” equivalent to the phrase “Today I learned” when extracting these two entries from distinct systems? Your program might get confused too when records come in with different names even though it means the same thing. As we are pulling data with discrepancies together from different operational systems, the data ingestion process can be more time-consuming than originally thought!
Now, you are working for a food supply chain company whose clients are from the catering industry. The company provides two data extracts about clients’ contact information and their restaurant details from different operational systems. You need to link them together so that the front-end dashboarding team can gain more information from the populated data. Unfortunately, there are no unique primary keys to link these two data sources but some geographic information and names of restaurants. This article is going to enhance your geographical mapping solution by combining geopy and fuzzywuzzy on top of manual mapping.
Using pandas read the two data sources:
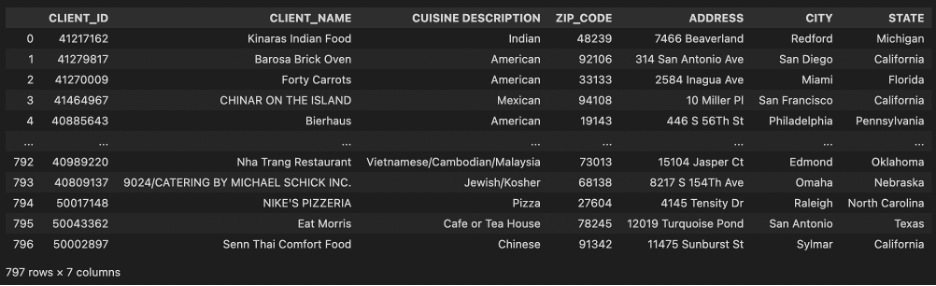
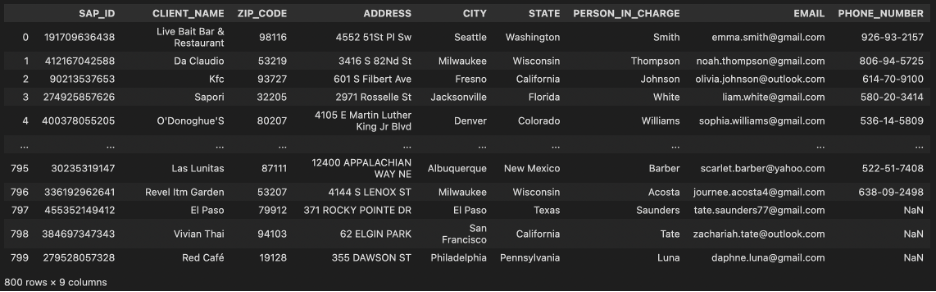
Basic Data Cleaning and Manual Mapping
When dealing with large datasets, every factor that might affect the accuracy of mapping needs to be considered. Including basic data cleaning and manual mapping as the first step can improve data consistency and alignment for more accurate results.
*The following code should be applied to both data sources.
1: Capitalization (eg. 123 Main St and 123 MAIN ST should be mapped)
https://medium.com/media/36f18239b0b945a378a64f2912c4f32c/href
2: Inadvertent Whitespace and Unnecessary Punctuations (eg. 123 Main St_whitespace_ or 123 Main St; should be mapped with 123 Main St)
https://medium.com/media/0fdfbcaddcede43d034bc406e66c0141/href
3: Standardizing Postal Abbreviation (eg. 123 Main Street should be mapped with 123 Main St)
Please consider using the full standardized postal abbreviation mapping table from the United States Postal Service Street Suffix Abbreviations in practical applications for higher consistency and accuracy in mapping geographical locations.
https://medium.com/media/f6583e53639b22a0d3e19a682e2c0acd/href
Other potential factors that might affect the accuracy of mapping include misspellings in addresses (eg. 123 Mian St and 123 Main St) and shortened addresses (eg. 123 Forest Hill and 123 Frst Hl) could be challenging to tackle using manual mapping approach, which more advanced mapping technique should be introduced.
Geopy
Geopy is an open-source Python library that plays a crucial role in the geospatial landscape by converting human-readable addresses into precise geographic coordinates through address geocoding. It employs great-circle distance calculations to accurately compute latitude and longitude during the geocoding process. Other geocoding APIs such as the Google Maps Geocoding API, OpenCage Geocoding API, and Smarty API can also be considered based on the specific business requirements of the project.
https://medium.com/media/20d501db46610863ec032a3407015bb5/href
After the geocoding process, we can merge the two DataFrames using LATITUDE and LONGITUDE columns with pandas library and check the number of rows that are successfully mapped. Addresses that cannot be mapped will be passed on to the next mapping stage.
https://medium.com/media/aee896cb462132921cc939eda572391b/hrefhttps://medium.com/media/60fd11b6209696ca710bcf17a35f2873/href
Fuzzy Wuzzy
Fuzzywuzzy is another Python library that is designed to facilitate fuzzy string matching, by providing a set of tools for comparing and measuring the similarity between strings. The library uses algorithms like Levenshtein distance to quantify the degree of resemblance between strings, which is particularly useful for data containing typos or discrepancies. A confidence score will be populated for each address comparison, which is a numerical value between 0 and 100. A higher score suggests a stronger similarity between the strings, while a lower score indicates a lesser degree of similarity. In our case, we can use fuzzywuzzy to tackle the remaining rows that cannot be mapped with geopy.
https://medium.com/media/e4a9b6211fc6bd0e7a2bea7d213905fc/href

The demo above only uses column ADDRESS for string matching, adding another column in common CLENT_NAME to this process can advance mapping in this business scenario which brings more accurate output.
Conclusion
This address mapping technique is versatile across various industries. The combination of manual mapping, geopy, and fuzzywuzzy provides a comprehensive approach to enhance geographical mapping accuracy, making it a valuable asset for businesses across different sectors that a facing similar challenges in data ingestion and integration.
The Power of Geospatial Intelligence and Similarity Analysis for Data Mapping was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Strategically enhancing address mapping during data integration using geocoding and string matching
Many individuals in the big data industry may encounter the following scenario: Is the acronym “TIL” equivalent to the phrase “Today I learned” when extracting these two entries from distinct systems? Your program might get confused too when records come in with different names even though it means the same thing. As we are pulling data with discrepancies together from different operational systems, the data ingestion process can be more time-consuming than originally thought!

Now, you are working for a food supply chain company whose clients are from the catering industry. The company provides two data extracts about clients’ contact information and their restaurant details from different operational systems. You need to link them together so that the front-end dashboarding team can gain more information from the populated data. Unfortunately, there are no unique primary keys to link these two data sources but some geographic information and names of restaurants. This article is going to enhance your geographical mapping solution by combining geopy and fuzzywuzzy on top of manual mapping.
Using pandas read the two data sources:
Basic Data Cleaning and Manual Mapping
When dealing with large datasets, every factor that might affect the accuracy of mapping needs to be considered. Including basic data cleaning and manual mapping as the first step can improve data consistency and alignment for more accurate results.
*The following code should be applied to both data sources.
1: Capitalization (eg. 123 Main St and 123 MAIN ST should be mapped)
https://medium.com/media/36f18239b0b945a378a64f2912c4f32c/href
2: Inadvertent Whitespace and Unnecessary Punctuations (eg. 123 Main St_whitespace_ or 123 Main St; should be mapped with 123 Main St)
https://medium.com/media/0fdfbcaddcede43d034bc406e66c0141/href
3: Standardizing Postal Abbreviation (eg. 123 Main Street should be mapped with 123 Main St)
Please consider using the full standardized postal abbreviation mapping table from the United States Postal Service Street Suffix Abbreviations in practical applications for higher consistency and accuracy in mapping geographical locations.
https://medium.com/media/f6583e53639b22a0d3e19a682e2c0acd/href
Other potential factors that might affect the accuracy of mapping include misspellings in addresses (eg. 123 Mian St and 123 Main St) and shortened addresses (eg. 123 Forest Hill and 123 Frst Hl) could be challenging to tackle using manual mapping approach, which more advanced mapping technique should be introduced.
Geopy
Geopy is an open-source Python library that plays a crucial role in the geospatial landscape by converting human-readable addresses into precise geographic coordinates through address geocoding. It employs great-circle distance calculations to accurately compute latitude and longitude during the geocoding process. Other geocoding APIs such as the Google Maps Geocoding API, OpenCage Geocoding API, and Smarty API can also be considered based on the specific business requirements of the project.
https://medium.com/media/20d501db46610863ec032a3407015bb5/href
After the geocoding process, we can merge the two DataFrames using LATITUDE and LONGITUDE columns with pandas library and check the number of rows that are successfully mapped. Addresses that cannot be mapped will be passed on to the next mapping stage.
https://medium.com/media/aee896cb462132921cc939eda572391b/hrefhttps://medium.com/media/60fd11b6209696ca710bcf17a35f2873/href
Fuzzy Wuzzy
Fuzzywuzzy is another Python library that is designed to facilitate fuzzy string matching, by providing a set of tools for comparing and measuring the similarity between strings. The library uses algorithms like Levenshtein distance to quantify the degree of resemblance between strings, which is particularly useful for data containing typos or discrepancies. A confidence score will be populated for each address comparison, which is a numerical value between 0 and 100. A higher score suggests a stronger similarity between the strings, while a lower score indicates a lesser degree of similarity. In our case, we can use fuzzywuzzy to tackle the remaining rows that cannot be mapped with geopy.
https://medium.com/media/e4a9b6211fc6bd0e7a2bea7d213905fc/href
The demo above only uses column ADDRESS for string matching, adding another column in common CLENT_NAME to this process can advance mapping in this business scenario which brings more accurate output.
Conclusion
This address mapping technique is versatile across various industries. The combination of manual mapping, geopy, and fuzzywuzzy provides a comprehensive approach to enhance geographical mapping accuracy, making it a valuable asset for businesses across different sectors that a facing similar challenges in data ingestion and integration.
The Power of Geospatial Intelligence and Similarity Analysis for Data Mapping was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.