
Towards Geometric Deep Learning III: First Geometric Architectures | by Michael Bronstein | Jul, 2022
Origins of Geometric Deep Learning
Geometric Deep Learning approaches a broad class of ML problems from the perspectives of symmetry and invariance, providing a common blueprint for neural network architectures as diverse as CNNs, GNNs, and Transformers. In a new series of posts, we study how these ideas have taken us from ancient Greece to convolutional neural networks.
In the third post from the “Towards Geometric Deep Learning series,” we discuss the first “geometric” neural networks: the Neocognitron and CNNs. This post is based on the introduction chapter of the book M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric Deep Learning (to appear with MIT Press upon completion) and accompanies our course in the African Masters in Machine Intelligence (AMMI). See Part I discussing symmetry and Part II on the early history of neural networks and the first “AI Winter.”
The inspiration for the first neural network architectures of the new ‘geometric’ type came from neuroscience. In a series of experiments that would become classical and bring them a Nobel Prize in medicine, the duo of Harvard neurophysiologists David Hubel and Torsten Wiesel [1–2] unveiled the structure and function of a part of the brain responsible for pattern recognition — the visual cortex. By presenting changing light patterns to a cat and measuring the response of its brain cells (neurons), they showed that the neurons in the visual cortex have a multi-layer structure with local spatial connectivity: a cell would produce a response only if cells in its proximity (‘receptive field’ [3]) were activated.

Furthermore, the organisation appeared to be hierarchical, where the responses of ‘simple cells’ reacting to local primitive oriented step-like stimuli were aggregated by ‘complex cells,’ which produced responses to more complex patterns. It was hypothesized that cells in deeper layers of the visual cortex would respond to increasingly complex patterns composed of simpler ones, with a semi-joking suggestion of the existence of a ‘grandmother cell’ [4] that reacts only when shown the face of one’s grandmother.
The understanding of the structure of the visual cortex has had a profound impact on early works in computer vision and pattern recognition, with multiple attempts to imitate its main ingredients. Kunihiko Fukushima, at that time a researcher at the Japan Broadcasting Corporation, developed a new neural network architecture [5] “similar to the hierarchy model of the visual nervous system proposed by Hubel and Wiesel,” which was given the name neocognitron [6].
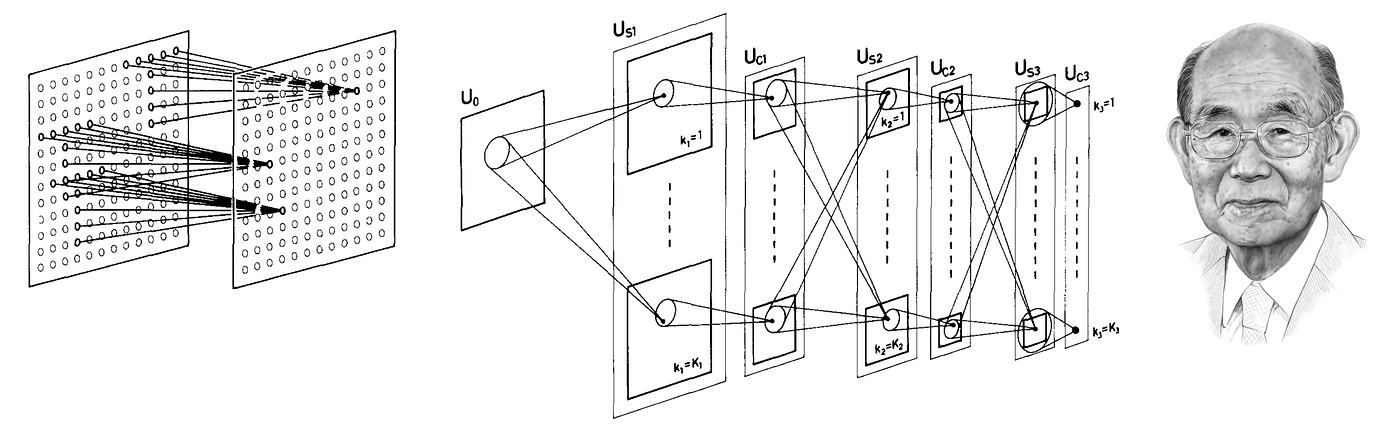
The neocognitron consisted of interleaved S– and C-layers of neurons (a naming convention reflecting its inspiration in the biological visual cortex); the neurons in each layer were arranged in 2D arrays following the structure of the input image (‘retinotopic’), with multiple ‘cell-planes’ (feature maps in modern terminology) per layer. The S-layers were designed to be translationally symmetric: they aggregated inputs from a local receptive field using shared learnable weights, resulting in cells in a single cell-plane have receptive fields of the same function, but at different positions. The rationale was to pick up patterns that could appear anywhere in the input. The C-layers were fixed and performed local pooling (a weighted average), affording insensitivity to the specific location of the pattern: a C-neuron would be activated if any of the neurons in its input are activated.
Since the main application of the neocognitron was character recognition, translation invariance [7] was crucial. This property was a fundamental difference from earlier neural networks such as Rosenblatt’s perceptron: in order to use a perceptron reliably, one had to first normalise the position of the input pattern, whereas in the neocognitron, the insensitivity to the pattern position was baked into the architecture. Neocognitron achieved it by interleaving translationally-equivariant local feature extraction layers with pooling, creating a multiscale representation [8]. Computational experiments showed that Fukushima’s architecture was able to successfully recognise complex patterns such as letters or digits, even in the presence of noise and geometric distortions.
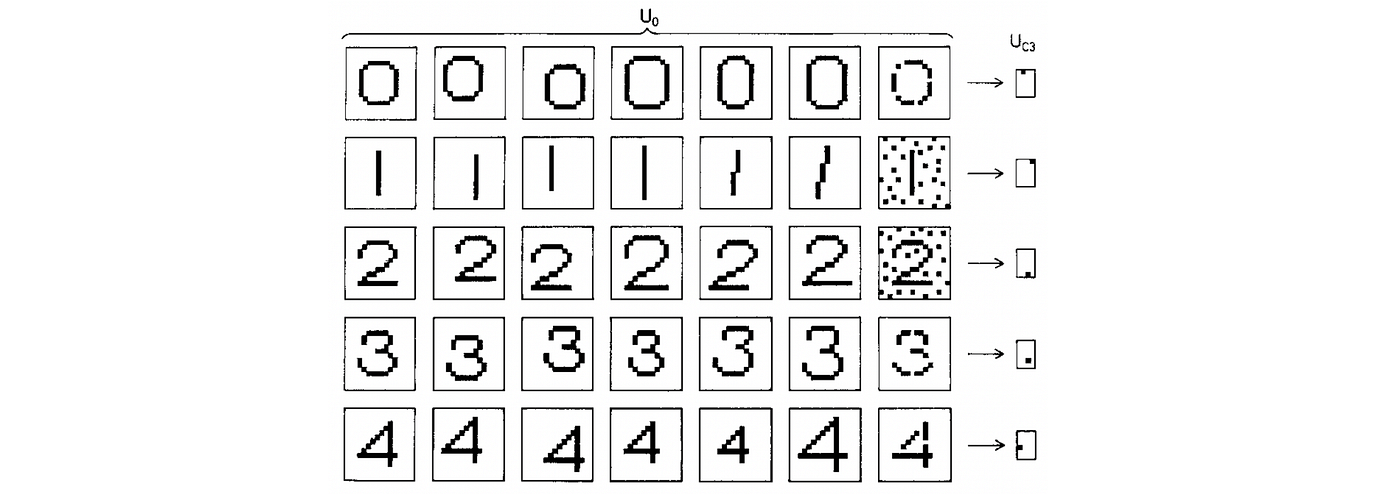
Looking from the vantage point of four decades of progress in the field, one finds that the neocognitron already had strikingly many characteristics of modern deep learning architectures: depth (Fukishima simulated a seven-layer network in his paper), local receptive fields, shared weights, and pooling. It even used half-rectifier (ReLU) activation function, which is often believed to be introduced in recent deep learning architectures [9]. The main distinction from modern systems was in the way the network was trained: neocognitron was a ‘self-organised’ architecture trained in an unsupervised manner since backpropagation had still not been widely used in the neural network community.
Fukushima’s design was further developed by Yann LeCun, a fresh graduate from the University of Paris [10] with a PhD thesis on the use of backpropagation for training neural networks. In his first post-doctoral position at the AT&T Bell Laboratories, LeCun and colleagues built a system to recognise hand-written digits on envelopes in order to allow the US Postal Service to automatically route mail.

In a paper that is now classical [11], LeCun et al. described the first three-layer convolutional neural network (CNN) [12]. Similarly to the neocognitron, LeCun’s CNN also used local connectivity with shared weights and pooling. However, it forwent Fukushima’s more complex nonlinear filtering (inhibitory connections) in favour of simple linear filters that could be efficiently implemented as convolutions using multiply-and-accumulate operations on a digital signal processor (DSP) [13].
This design choice, departing from the neuroscience inspiration and terminology and moving into the realm of signal processing, would play a crucial role in the ensuing success of deep learning. Another key novelty of CNN was the use of backpropagation for training.
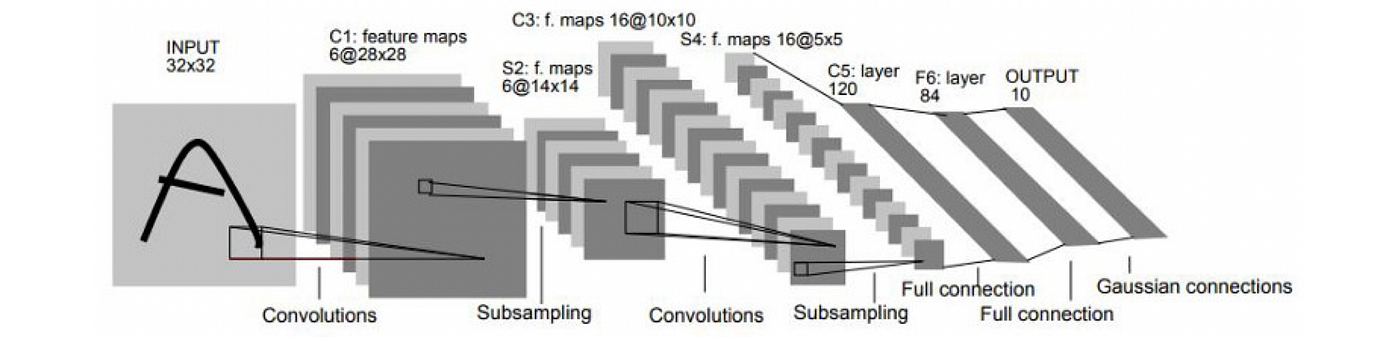
LeCun’s works showed convincingly the power of gradient-based methods for complex pattern recognition tasks and was one of the first practical deep learning-based systems for computer vision. An evolution of this architecture, a CNN with five layers named LeNet-5 as a pun on the author’s name [14], was used by US banks to read handwritten cheques.
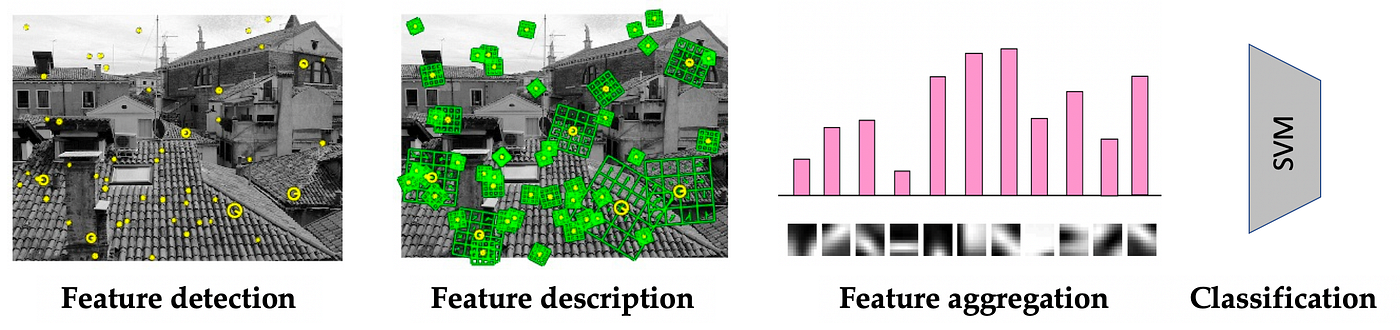
The computer vision research community, however, in its vast majority steered away from neural networks and took a different path. The typical architecture of visual recognition systems of the first decade of the new millennium was a carefully hand-crafted feature extractor (typically detecting interesting points in an image and providing their local description in a way that is robust to perspective transformations and contrast changes [15]) followed by a simple classifier (most often a support vector machine (SVM) and more rarely, a small neural network) [16].
However, the balance of power was changed by the rapid growth in computing power and the amounts of available annotated visual data. It became possible to implement and train increasingly bigger and more complex CNNs that allowed addressing increasingly challenging visual pattern recognition tasks [17], culminating in a Holy Grail of computer vision at that time: the ImageNet Large Scale Visual Recognition Challenge. Established by the American-Chinese researcher Fei-Fei Li in 2009, ImageNet was an annual challenge consisting of the classification of millions of human-labeled images into 1000 different categories.
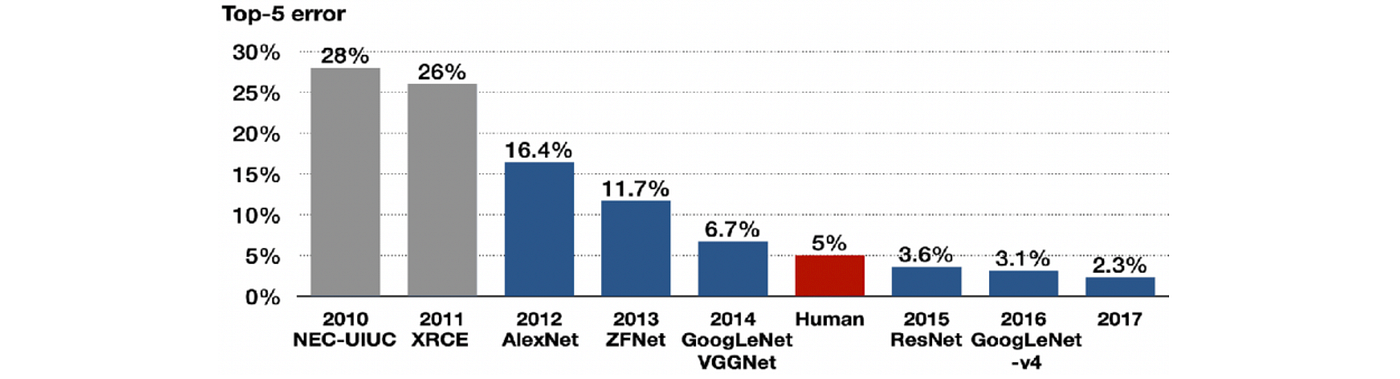
A CNN architecture developed at the University of Toronto by Krizhevsky, Sutskever, and Hinton [18] managed to beat by a large margin [19] all the competing approaches such as smartly engineered feature detectors based on decades of research in the field. AlexNet (as the architecture was called in honour of its developer, Alex Krizhevsky) was significantly bigger in terms of the number of parameters and layers compared to its older sibling LeNet-5 [20], but conceptually the same. The key difference was the use of a graphics processor (GPU) for training [21], now the mainstream hardware platform for deep learning [22].
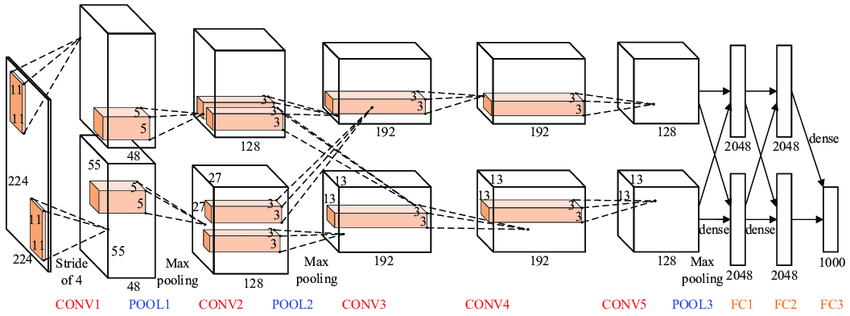
The success of CNNs on ImageNet became the turning point for deep learning and heralded its broad acceptance in the following decade. Multi-billion dollar industries emerged as a result, with deep learning successfully used in commercial systems ranging from speech recognition in Apple iPhone to Tesla self-driving cars. More than forty years after the scathing review of Rosenblatt’s work, the connectionists were finally vindicated.
[1] D. H. Hubel and T. N. Wiesel, Receptive fields of single neurones in the cat’s striate cortex (1959), The Journal of Physiology 148(3):574.
[2] D. H. Hubel and T. N. Wiesel, Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex (1962), The Journal of Physiology 160(1):106.
[3] The term ‘receptive field’ predates Hubel and Wiesel and was used by neurophysiologists from the early twentieth century, see C. Sherrington, The integrative action of the nervous system (1906), Yale University Press.
[4] The term ‘grandmother cell’ is likely to have first appeared in Jerry Lettvin’s course ‘Biological Foundations for Perception and Knowledge’ held at MIT in 1969. A similar concept of ‘gnostic neurons’ was introduced two years earlier in a book by Polish neuroscientist J. Konorski, Integrative activity of the brain; an interdisciplinary approach (1967). See C. G. Gross, Genealogy of the “grandmother cell” (2002), The Neuroscientist 8(5):512–518.
[5] K. Fukushima, Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position (1980), Biological Cybernetics 36:196– 202. The shift-invariance property is alluded to in the title.
[6] Often misspelled as ‘neurocognitron’, the name ‘neocognitron’ suggests it was an improved version of an earlier architecture of K. Fukushima, Cognitron: a self-organizing multilayered neural network (1975), Biological Cybernetics 20:121–136.
[7] In the words of the author himself, having an output that is “dependent only upon the shape of the stimulus pattern, and is not affected by the position where the pattern is presented.”
[8] We refer to this principle as scale separation, which, like symmetry, is a fundamental property of many physical systems. In convolutional architectures, scale separation allows dealing with a broader class of geometric transformations in addition to translations.
[9] ReLU-type activations date back to at least the 1960s and have been previously employed in K. Fukushima, Visual feature extraction by a multilayered network of analog threshold elements (1969), IEEE Trans. Systems Science and Cybernetics 5(4):322–333.
[10] Université Pierre-et-Marie-Curie, today part of the Sorbonne University.
[11] Y. LeCun et al., Backpropagation applied to handwritten zip code recognition (1989) Neural Computation 1(4):541–551.
[12] In LeCun’s 1989 paper, the architecture was not named; the term ‘convolutional neural network’ or ‘convnet’ would appear in a later paper in 1998 [14].
[13] LeCun’s first CNN was trained on a CPU (a SUN-4/250 machine). However, the image recognition system using a trained CNN was run on AT&T DSP-32C (a second-generation digital signal processor with 256KB of memory capable of performing 125m floating-point multiply-and-accumulate operations per second with 32-bit precision), achieving over 30 classifications per second.
[14] Y. LeCun et al., Gradient-based learning applied to document recognition (1998), Proc. IEEE 86(11): 2278–2324.
[15] One of the most popular feature descriptors was the scale-invariant feature transform (SIFT), introduced by David Lowe in 1999. The paper was rejected multiple times and appeared only five years later, D. G. Lowe, Distinctive image features from scale-invariant keypoints, (2004) IJCV 60(2):91–110. It is one of the most cited computer vision papers.
[16] A prototypical approach was “bag-of-words” representing images as histograms of vector-quantised local descriptors. See e.g. J. Sivic and A. Zisserman, Video Google: A text retrieval approach to object matching in videos (2003), ICCV.
[17] In particular, the group of Jürgen Schmidhuber developed deep large-scale CNN models that won several vision competitions, including Chinese character recognition (D. C. Ciresan et al., Deep big simple neural nets for handwritten digit recognition (2010), Neural Computation 22(12):3207–3220) and traffic sign recognition (D. C. Ciresan et al., Multi-column deep neural network for traffic sign classification. Neural Networks 32:333–338, 2012).
[18] A. Krizhevsky, I. Sutskever, and G. E. Hinton, ImageNet classification with deep convolutional neural networks (2012), NIPS.
[19] AlexNet achieved an error over 10.8% smaller than the runner up.
[20] AlexNet had eleven layers was trained on 1.2M images from ImageNet (for comparison, LeNet-5 had five layers and was trained on 60K MNIST digits). Additional important changes compared to LeNet-5 were the use of ReLU activation (instead of tanh), maximum pooling, dropout regularisation, and data augmentation.
[21] It took nearly a week to train AlexNet on a pair of Nvidia GTX 580 GPUs, capable of ~200G FLOP/sec.
[22] Though GPUs were initially designed for graphics applications, they turned out to be a convenient hardware platform for general-purpose computations (“GPGPU”). First such works showed linear algebra algorithms, see e.g. J. Krüger and R. Westermann, Linear algebra operators for GPU implementation of numerical algorithms (2003), ACM Trans. Graphics 22(3):908–916. The first use of GPUs for neural networks was by K.-S. Oh and K. Jung, GPU implementation of neural networks (2004), Pattern Recognition 37(6):1311–1314, predating AlexNet by nearly a decade.
Origins of Geometric Deep Learning
Geometric Deep Learning approaches a broad class of ML problems from the perspectives of symmetry and invariance, providing a common blueprint for neural network architectures as diverse as CNNs, GNNs, and Transformers. In a new series of posts, we study how these ideas have taken us from ancient Greece to convolutional neural networks.

In the third post from the “Towards Geometric Deep Learning series,” we discuss the first “geometric” neural networks: the Neocognitron and CNNs. This post is based on the introduction chapter of the book M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric Deep Learning (to appear with MIT Press upon completion) and accompanies our course in the African Masters in Machine Intelligence (AMMI). See Part I discussing symmetry and Part II on the early history of neural networks and the first “AI Winter.”
The inspiration for the first neural network architectures of the new ‘geometric’ type came from neuroscience. In a series of experiments that would become classical and bring them a Nobel Prize in medicine, the duo of Harvard neurophysiologists David Hubel and Torsten Wiesel [1–2] unveiled the structure and function of a part of the brain responsible for pattern recognition — the visual cortex. By presenting changing light patterns to a cat and measuring the response of its brain cells (neurons), they showed that the neurons in the visual cortex have a multi-layer structure with local spatial connectivity: a cell would produce a response only if cells in its proximity (‘receptive field’ [3]) were activated.
Furthermore, the organisation appeared to be hierarchical, where the responses of ‘simple cells’ reacting to local primitive oriented step-like stimuli were aggregated by ‘complex cells,’ which produced responses to more complex patterns. It was hypothesized that cells in deeper layers of the visual cortex would respond to increasingly complex patterns composed of simpler ones, with a semi-joking suggestion of the existence of a ‘grandmother cell’ [4] that reacts only when shown the face of one’s grandmother.
The understanding of the structure of the visual cortex has had a profound impact on early works in computer vision and pattern recognition, with multiple attempts to imitate its main ingredients. Kunihiko Fukushima, at that time a researcher at the Japan Broadcasting Corporation, developed a new neural network architecture [5] “similar to the hierarchy model of the visual nervous system proposed by Hubel and Wiesel,” which was given the name neocognitron [6].
The neocognitron consisted of interleaved S– and C-layers of neurons (a naming convention reflecting its inspiration in the biological visual cortex); the neurons in each layer were arranged in 2D arrays following the structure of the input image (‘retinotopic’), with multiple ‘cell-planes’ (feature maps in modern terminology) per layer. The S-layers were designed to be translationally symmetric: they aggregated inputs from a local receptive field using shared learnable weights, resulting in cells in a single cell-plane have receptive fields of the same function, but at different positions. The rationale was to pick up patterns that could appear anywhere in the input. The C-layers were fixed and performed local pooling (a weighted average), affording insensitivity to the specific location of the pattern: a C-neuron would be activated if any of the neurons in its input are activated.
Since the main application of the neocognitron was character recognition, translation invariance [7] was crucial. This property was a fundamental difference from earlier neural networks such as Rosenblatt’s perceptron: in order to use a perceptron reliably, one had to first normalise the position of the input pattern, whereas in the neocognitron, the insensitivity to the pattern position was baked into the architecture. Neocognitron achieved it by interleaving translationally-equivariant local feature extraction layers with pooling, creating a multiscale representation [8]. Computational experiments showed that Fukushima’s architecture was able to successfully recognise complex patterns such as letters or digits, even in the presence of noise and geometric distortions.
Looking from the vantage point of four decades of progress in the field, one finds that the neocognitron already had strikingly many characteristics of modern deep learning architectures: depth (Fukishima simulated a seven-layer network in his paper), local receptive fields, shared weights, and pooling. It even used half-rectifier (ReLU) activation function, which is often believed to be introduced in recent deep learning architectures [9]. The main distinction from modern systems was in the way the network was trained: neocognitron was a ‘self-organised’ architecture trained in an unsupervised manner since backpropagation had still not been widely used in the neural network community.
Fukushima’s design was further developed by Yann LeCun, a fresh graduate from the University of Paris [10] with a PhD thesis on the use of backpropagation for training neural networks. In his first post-doctoral position at the AT&T Bell Laboratories, LeCun and colleagues built a system to recognise hand-written digits on envelopes in order to allow the US Postal Service to automatically route mail.
In a paper that is now classical [11], LeCun et al. described the first three-layer convolutional neural network (CNN) [12]. Similarly to the neocognitron, LeCun’s CNN also used local connectivity with shared weights and pooling. However, it forwent Fukushima’s more complex nonlinear filtering (inhibitory connections) in favour of simple linear filters that could be efficiently implemented as convolutions using multiply-and-accumulate operations on a digital signal processor (DSP) [13].
This design choice, departing from the neuroscience inspiration and terminology and moving into the realm of signal processing, would play a crucial role in the ensuing success of deep learning. Another key novelty of CNN was the use of backpropagation for training.
LeCun’s works showed convincingly the power of gradient-based methods for complex pattern recognition tasks and was one of the first practical deep learning-based systems for computer vision. An evolution of this architecture, a CNN with five layers named LeNet-5 as a pun on the author’s name [14], was used by US banks to read handwritten cheques.
The computer vision research community, however, in its vast majority steered away from neural networks and took a different path. The typical architecture of visual recognition systems of the first decade of the new millennium was a carefully hand-crafted feature extractor (typically detecting interesting points in an image and providing their local description in a way that is robust to perspective transformations and contrast changes [15]) followed by a simple classifier (most often a support vector machine (SVM) and more rarely, a small neural network) [16].
However, the balance of power was changed by the rapid growth in computing power and the amounts of available annotated visual data. It became possible to implement and train increasingly bigger and more complex CNNs that allowed addressing increasingly challenging visual pattern recognition tasks [17], culminating in a Holy Grail of computer vision at that time: the ImageNet Large Scale Visual Recognition Challenge. Established by the American-Chinese researcher Fei-Fei Li in 2009, ImageNet was an annual challenge consisting of the classification of millions of human-labeled images into 1000 different categories.
A CNN architecture developed at the University of Toronto by Krizhevsky, Sutskever, and Hinton [18] managed to beat by a large margin [19] all the competing approaches such as smartly engineered feature detectors based on decades of research in the field. AlexNet (as the architecture was called in honour of its developer, Alex Krizhevsky) was significantly bigger in terms of the number of parameters and layers compared to its older sibling LeNet-5 [20], but conceptually the same. The key difference was the use of a graphics processor (GPU) for training [21], now the mainstream hardware platform for deep learning [22].
The success of CNNs on ImageNet became the turning point for deep learning and heralded its broad acceptance in the following decade. Multi-billion dollar industries emerged as a result, with deep learning successfully used in commercial systems ranging from speech recognition in Apple iPhone to Tesla self-driving cars. More than forty years after the scathing review of Rosenblatt’s work, the connectionists were finally vindicated.
[1] D. H. Hubel and T. N. Wiesel, Receptive fields of single neurones in the cat’s striate cortex (1959), The Journal of Physiology 148(3):574.
[2] D. H. Hubel and T. N. Wiesel, Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex (1962), The Journal of Physiology 160(1):106.
[3] The term ‘receptive field’ predates Hubel and Wiesel and was used by neurophysiologists from the early twentieth century, see C. Sherrington, The integrative action of the nervous system (1906), Yale University Press.
[4] The term ‘grandmother cell’ is likely to have first appeared in Jerry Lettvin’s course ‘Biological Foundations for Perception and Knowledge’ held at MIT in 1969. A similar concept of ‘gnostic neurons’ was introduced two years earlier in a book by Polish neuroscientist J. Konorski, Integrative activity of the brain; an interdisciplinary approach (1967). See C. G. Gross, Genealogy of the “grandmother cell” (2002), The Neuroscientist 8(5):512–518.
[5] K. Fukushima, Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position (1980), Biological Cybernetics 36:196– 202. The shift-invariance property is alluded to in the title.
[6] Often misspelled as ‘neurocognitron’, the name ‘neocognitron’ suggests it was an improved version of an earlier architecture of K. Fukushima, Cognitron: a self-organizing multilayered neural network (1975), Biological Cybernetics 20:121–136.
[7] In the words of the author himself, having an output that is “dependent only upon the shape of the stimulus pattern, and is not affected by the position where the pattern is presented.”
[8] We refer to this principle as scale separation, which, like symmetry, is a fundamental property of many physical systems. In convolutional architectures, scale separation allows dealing with a broader class of geometric transformations in addition to translations.
[9] ReLU-type activations date back to at least the 1960s and have been previously employed in K. Fukushima, Visual feature extraction by a multilayered network of analog threshold elements (1969), IEEE Trans. Systems Science and Cybernetics 5(4):322–333.
[10] Université Pierre-et-Marie-Curie, today part of the Sorbonne University.
[11] Y. LeCun et al., Backpropagation applied to handwritten zip code recognition (1989) Neural Computation 1(4):541–551.
[12] In LeCun’s 1989 paper, the architecture was not named; the term ‘convolutional neural network’ or ‘convnet’ would appear in a later paper in 1998 [14].
[13] LeCun’s first CNN was trained on a CPU (a SUN-4/250 machine). However, the image recognition system using a trained CNN was run on AT&T DSP-32C (a second-generation digital signal processor with 256KB of memory capable of performing 125m floating-point multiply-and-accumulate operations per second with 32-bit precision), achieving over 30 classifications per second.
[14] Y. LeCun et al., Gradient-based learning applied to document recognition (1998), Proc. IEEE 86(11): 2278–2324.
[15] One of the most popular feature descriptors was the scale-invariant feature transform (SIFT), introduced by David Lowe in 1999. The paper was rejected multiple times and appeared only five years later, D. G. Lowe, Distinctive image features from scale-invariant keypoints, (2004) IJCV 60(2):91–110. It is one of the most cited computer vision papers.
[16] A prototypical approach was “bag-of-words” representing images as histograms of vector-quantised local descriptors. See e.g. J. Sivic and A. Zisserman, Video Google: A text retrieval approach to object matching in videos (2003), ICCV.
[17] In particular, the group of Jürgen Schmidhuber developed deep large-scale CNN models that won several vision competitions, including Chinese character recognition (D. C. Ciresan et al., Deep big simple neural nets for handwritten digit recognition (2010), Neural Computation 22(12):3207–3220) and traffic sign recognition (D. C. Ciresan et al., Multi-column deep neural network for traffic sign classification. Neural Networks 32:333–338, 2012).
[18] A. Krizhevsky, I. Sutskever, and G. E. Hinton, ImageNet classification with deep convolutional neural networks (2012), NIPS.
[19] AlexNet achieved an error over 10.8% smaller than the runner up.
[20] AlexNet had eleven layers was trained on 1.2M images from ImageNet (for comparison, LeNet-5 had five layers and was trained on 60K MNIST digits). Additional important changes compared to LeNet-5 were the use of ReLU activation (instead of tanh), maximum pooling, dropout regularisation, and data augmentation.
[21] It took nearly a week to train AlexNet on a pair of Nvidia GTX 580 GPUs, capable of ~200G FLOP/sec.
[22] Though GPUs were initially designed for graphics applications, they turned out to be a convenient hardware platform for general-purpose computations (“GPGPU”). First such works showed linear algebra algorithms, see e.g. J. Krüger and R. Westermann, Linear algebra operators for GPU implementation of numerical algorithms (2003), ACM Trans. Graphics 22(3):908–916. The first use of GPUs for neural networks was by K.-S. Oh and K. Jung, GPU implementation of neural networks (2004), Pattern Recognition 37(6):1311–1314, predating AlexNet by nearly a decade.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.