
Towards increased truthfulness in LLM applications
Application-oriented methods from current research
Abstract
This article explores methods to enhance the truthfulness of Retrieval Augmented Generation (RAG) application outputs, focusing on mitigating issues like hallucinations and reliance on pre-trained knowledge. I identify the causes of untruthful results, evaluate methods for assessing truthfulness, and propose solutions to improve accuracy. The study emphasizes the importance of groundedness and completeness in RAG outputs, recommending fine-tuning Large Language Models (LLMs) and employing element-aware summarization to ensure factual accuracy. Additionally, it discusses the use of scalable evaluation metrics, such as the Learnable Evaluation Metric for Text Simplification (LENS), and Chain of Thought-based (CoT) evaluations, for real-time output verification. The article highlights the need to balance the benefits of increased truthfulness against potential costs and performance impacts, suggesting a selective approach to method implementation based on application needs.
1. Introduction
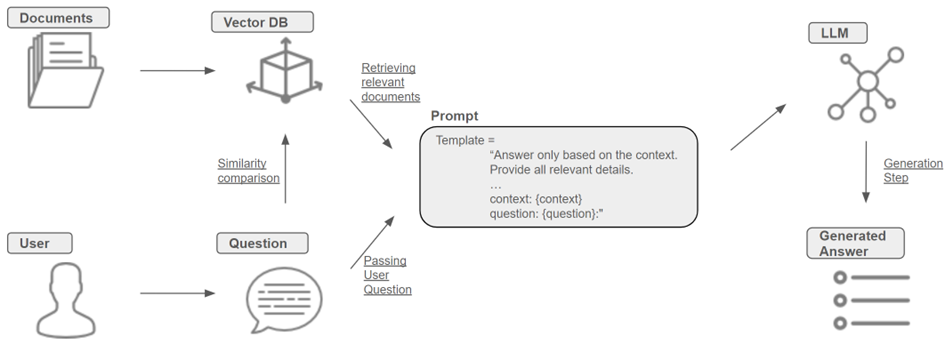
A widely used Large Language Model (LLM) architecture which can provide insight into application outputs and reduce hallucinations is Retrieval Augmented Generation (RAG). RAG is a method to expand LLM memory by combining parametric memory (i.e. LLM pre-trained) with non-parametric (i.e. document retrieved) memories. To do this, the most relevant documents are retrieved from a vector database and, together with the user question and a customised prompt, passed to an LLM, which generates a response (see Figure 1). For further details, see Lewis et al. (2021).
A real-world application can, for instance, connect an LLM to a database of medical guideline documents. Medical practitioners can replace manual look-up by asking natural language questions using RAG as a “search engine”. The application would answer the user’s question and reference the source guideline. If the answer is based on parametric memory, e.g. answering on guidelines contained in the pre-training but not the connected database, or if the LLM hallucinates, this could have drastic implications.
Firstly, if the medical practitioners verify with the referenced guidelines, they could lose trust in the application answers, leading to less usage. Secondly, and more worryingly, if not every answer is verified, an answer can be falsely assumed to be based on the queried medical guidelines, directly affecting the patient’s treatment. This highlights the relevance of the truthfulness of output in RAG applications.
In this article assessing RAG, truth is defined as being firmly grounded in factual knowledge of the retrieved document. To investigate this issue, one General Research Question (GRQ) and three Specific Research Questions (SRQ) are derived.
GRQ: How can the truthfulness of RAG outputs be improved?
SRQ 1: What causes untruthful results to be generated by RAG applications?
SRQ 2: How can truthfulness be evaluated?
SRQ 3: What methods can be used to increase truthfulness?
To answer the GRQ, the SRQs are analysed sequentially on the basis of literature research. The aim is to identify methods that can be implemented for use cases such as the above example from the medical field. Ultimately two categories of solution methods will be recommended for further analysis and customisation.
2. Untruthful RAG output
As previously defined, a truthful answer should be firmly grounded in factual knowledge of the retrieved document. One metric for this is factual consistency, measuring if the summary contains untruthful or misleading facts that are not supported by the source text (Liu et al., 2023). It is used as a critical evaluation metric in multiple benchmarks (Kim et al., 2023; Fabbri et al., 2021; Deutsch & Roth, 2022; Wang et al., 2023; Wu et al., 2023). In the area of RAG, this is often referred to as groundedness (Levonian et al., 2023). Moreover, to take the usefulness of a truthful answer into consideration, its completeness is also of relevance. The following paragraphs give insight into the reason behind untruthful RAG results. This refers to the Generation Step in Figure 1, which summarises the retrieved documents with respect to the user question.
Firstly, the groundedness of an RAG application is impacted if the LLM answer is based on parametric memory rather than the factual knowledge of the retrieved document. This can, for instance, occur if the answer comes from pre-trained knowledge or is caused by hallucinations. Hallucinations still remain a fundamental problem of LLMs (Bang et al., 2023; Ji et al., 2023; Zhang & Gao, 2023), from which even powerful LLMs suffer (Liu et al., 2023). As per definition, low groundedness results in untruthful RAG results.
Secondly, completeness describes if an LLM´s answer lacks factual knowledge from the documents. This can be due to the low summarisation capability of an LLM or missing domain knowledge to interpret the factual knowledge (T. Zhang et al., 2023). The output could still be highly grounded. Nevertheless, an answer could be incomplete with respect to the documents. Leading to incorrect user perception of the content of the database. In addition, if factual knowledge from the document is missing, the LLM can be encouraged to make up for this by answering with its own parametric memory, raising the abovementioned issue.
Having established the key causes of untruthful outputs, it is necessary to first measure and quantify these errors before a solution can be pursued. Therefore, the following section will cover the methods of measurement for the aforementioned sources of untruthful RAG outputs.
3. Evaluating truthfulness
Having elaborated on groundedness and completeness and their origins, this section intends to guide through their measurement methods. I will begin with the widely known general-purpose methods and continue by highlighting recent trends. TruLens´s Feedback Functions plot serves here as a valuable reference for scalability and meaningfulness (see Figure2).
When talking about natural language generation evaluations, traditional evaluation metrics like ROUGE (Lin, 2004) and BLEU (Papineni et al., 2002) are widely used but tend to show a discrepancy from human assessments (Liu et al., 2023). Furthermore, Medium Language Models (MLMs) have demonstrated superior results to traditional evaluation metrics, but can be replaced by LLMs in many areas (X. Zhang & Gao, 2023). Lastly, another well-known evaluation method is the human evaluation of generated text, which has apparent drawbacks of scale and cost (Fabbri et al., 2021). Due to the downsides of these methods (see Figure 2), these are not relevant for further consideration in this paper.
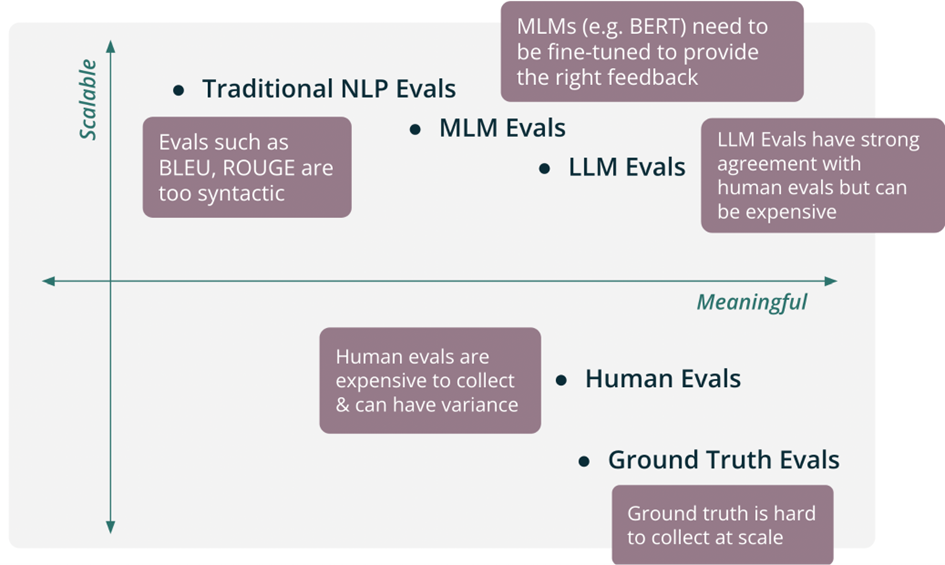
Concerning recent trends, evaluation metrics have developed with the increase in the popularity of LLMs. One such development are LLM evaluations, allowing another LLM through Chain of Thought (CoT) reasoning to evaluate the generated text (Liu et al., 2023). Through bespoke prompting strategies, areas of focus like groundedness and completeness can be emphasised and numerically scored (Kim et al., 2023). For this method, it has been shown that a larger model size is beneficial for summarisation evaluation (Liu et al., 2023). Moreover, this evaluation can also be based on references or collected ground truth, comparing generated text and reference text (Wu et al., 2023). For open-ended tasks without a single correct answer, LLM-based evaluation outperforms reference-based metrics in terms of correlation with human quality judgements. Moreover, ground-truth collection can be costly. Therefore, reference or ground-truth based metrics are outside the scope of this assessment (Liu et al., 2023; Feedback Functions — TruLens, o. J.).
Concluding with a noteworthy recent development, the Learnable Evaluation Metric for Text Simplification (LENS), stated to be “the first supervised automatic metric for text simplification evaluation” by Maddela et al. (2023), has demonstrated promising outcomes in recent benchmarks. It is recognized for its effectiveness in identifying hallucinations (Kew et al., 2023). In terms of scalability and meaningfulness this is expected to be slightly more scalable, due to lower cost, and slightly less meaningful than LLM evaluations, placing LENS close to LLM Evals in the right top corner of Figure 2. Nevertheless, further assessment would be required to verify these claims. This would conclude the evaluations methods in scope and the next section is focusing on methods of their application.
4. Toward increased truthfulness
Having established in section 1, the relevance of truthfulness in RAG applications, with SRQ1 the causes of untruthful output and with SRQ2 its evaluation, this section will focus on SRQ3. Hence, detailing specific recommended methods improving groundedness and completeness to increase truthful responses. These methods can be categorised into two groups, improvements in the generation of output and validation of output.
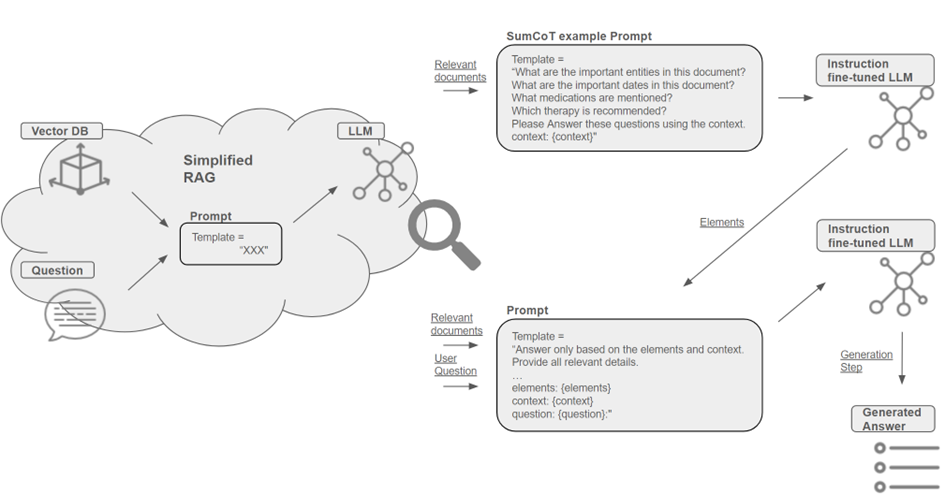
In order to improve the generation step of the RAG application, this article will highlight two methods. These are visualised in Figure 3, with the simplified RAG architecture referenced on the left. The first methods is fine-tuning the generation LLM. Instruction tuning over model size is critical to the LLM’s zero-shot summarisation capability. Thus, state-of-the-art LLMs can perform on par with summaries written by freelance writers (T. Zhang et al., 2023). The second method focuses on element-aware summarisation. With CoT prompting, like presented in SumCoT, LLMs can generate summaries step by step, emphasising the factual entities of the source text (Wang et al., 2023). Specifically, in an additional step, factual elements are extracted from the relevant documents and made available to the LLM in addition to the context for the summarisation, see Figure 3. Both methods have shown promising results for improving the groundedness and completeness of LLM-generated summaries.
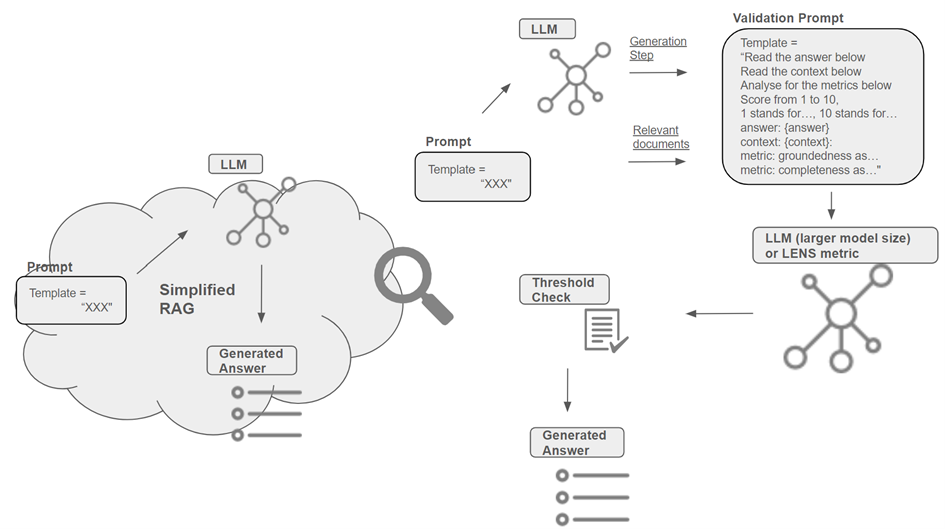
In validation of the RAG outputs, LLM-generated summaries are evaluated for groundedness and completeness. This can be done by CoT prompting an LLM to aggregate a groundedness and completeness score. In Figure 4 an example CoT prompt is depicted, which can be forwarded to an LLM of larger model size for completion. Furthermore, this step can be replaced or advanced by using supervised metrics like LENS. At last, the generated evaluation is compared against a threshold. In case of not grounded or incomplete outputs, those can be modified, raised to the user or potentially rejected.
Before adapting these methods to RAG applications, it should be considered that evaluation at run-time and fine-tuning the generation model will lead to additional costs. Furthermore, the evaluation step will affect the applications’ answering speed. Lastly, no answer due to output rejections and raised truthfulness concerns might confuse application users. Consequently, it is critical to evaluate these methods with respect to the field of application, the functionality of the application and the user´s expectations. Leading to a customised approach increasing outputs truthfulness of RAG applications.
Unless otherwise noted, all images are by the author.
List of References
Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D., Wilie, B., Lovenia, H., Ji, Z., Yu, T., Chung, W., Do, Q. V., Xu, Y., & Fung, P. (2023). A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity (arXiv:2302.04023). arXiv. https://doi.org/10.48550/arXiv.2302.04023
Deutsch, D., & Roth, D. (2022). Benchmarking Answer Verification Methods for Question Answering-Based Summarization Evaluation Metrics (arXiv:2204.10206). arXiv. https://doi.org/10.48550/arXiv.2204.10206
Fabbri, A. R., Kryściński, W., McCann, B., Xiong, C., Socher, R., & Radev, D. (2021). SummEval: Re-evaluating Summarization Evaluation (arXiv:2007.12626). arXiv. https://doi.org/10.48550/arXiv.2007.12626
Feedback Functions — TruLens. (o. J.). Abgerufen 11. Februar 2024, von https://www.trulens.org/trulens_eval/core_concepts_feedback_functions/#feedback-functions
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Dai, W., Madotto, A., & Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), 1–38. https://doi.org/10.1145/3571730
Kew, T., Chi, A., Vásquez-Rodríguez, L., Agrawal, S., Aumiller, D., Alva-Manchego, F., & Shardlow, M. (2023). BLESS: Benchmarking Large Language Models on Sentence Simplification (arXiv:2310.15773). arXiv. https://doi.org/10.48550/arXiv.2310.15773
Kim, J., Park, S., Jeong, K., Lee, S., Han, S. H., Lee, J., & Kang, P. (2023). Which is better? Exploring Prompting Strategy For LLM-based Metrics (arXiv:2311.03754). arXiv. https://doi.org/10.48550/arXiv.2311.03754
Levonian, Z., Li, C., Zhu, W., Gade, A., Henkel, O., Postle, M.-E., & Xing, W. (2023). Retrieval-augmented Generation to Improve Math Question-Answering: Trade-offs Between Groundedness and Human Preference (arXiv:2310.03184). arXiv. https://doi.org/10.48550/arXiv.2310.03184
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arXiv:2005.11401). arXiv. https://doi.org/10.48550/arXiv.2005.11401
Lin, C.-Y. (2004). ROUGE: A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out, 74–81. https://aclanthology.org/W04-1013
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., & Zhu, C. (2023). G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment (arXiv:2303.16634). arXiv. https://doi.org/10.48550/arXiv.2303.16634
Maddela, M., Dou, Y., Heineman, D., & Xu, W. (2023). LENS: A Learnable Evaluation Metric for Text Simplification (arXiv:2212.09739). arXiv. https://doi.org/10.48550/arXiv.2212.09739
Papineni, K., Roukos, S., Ward, T., & Zhu, W.-J. (2002). Bleu: A Method for Automatic Evaluation of Machine Translation. In P. Isabelle, E. Charniak, & D. Lin (Hrsg.), Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (S. 311–318). Association for Computational Linguistics. https://doi.org/10.3115/1073083.1073135
Wang, Y., Zhang, Z., & Wang, R. (2023). Element-aware Summarization with Large Language Models: Expert-aligned Evaluation and Chain-of-Thought Method (arXiv:2305.13412). arXiv. https://doi.org/10.48550/arXiv.2305.13412
Wu, N., Gong, M., Shou, L., Liang, S., & Jiang, D. (2023). Large Language Models are Diverse Role-Players for Summarization Evaluation (arXiv:2303.15078). arXiv. https://doi.org/10.48550/arXiv.2303.15078
Zhang, T., Ladhak, F., Durmus, E., Liang, P., McKeown, K., & Hashimoto, T. B. (2023). Benchmarking Large Language Models for News Summarization (arXiv:2301.13848). arXiv. https://doi.org/10.48550/arXiv.2301.13848
Zhang, X., & Gao, W. (2023). Towards LLM-based Fact Verification on News Claims with a Hierarchical Step-by-Step Prompting Method (arXiv:2310.00305). arXiv. https://doi.org/10.48550/arXiv.2310.00305
Towards increased truthfulness in LLM applications was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Application-oriented methods from current research
Abstract
This article explores methods to enhance the truthfulness of Retrieval Augmented Generation (RAG) application outputs, focusing on mitigating issues like hallucinations and reliance on pre-trained knowledge. I identify the causes of untruthful results, evaluate methods for assessing truthfulness, and propose solutions to improve accuracy. The study emphasizes the importance of groundedness and completeness in RAG outputs, recommending fine-tuning Large Language Models (LLMs) and employing element-aware summarization to ensure factual accuracy. Additionally, it discusses the use of scalable evaluation metrics, such as the Learnable Evaluation Metric for Text Simplification (LENS), and Chain of Thought-based (CoT) evaluations, for real-time output verification. The article highlights the need to balance the benefits of increased truthfulness against potential costs and performance impacts, suggesting a selective approach to method implementation based on application needs.
1. Introduction
A widely used Large Language Model (LLM) architecture which can provide insight into application outputs and reduce hallucinations is Retrieval Augmented Generation (RAG). RAG is a method to expand LLM memory by combining parametric memory (i.e. LLM pre-trained) with non-parametric (i.e. document retrieved) memories. To do this, the most relevant documents are retrieved from a vector database and, together with the user question and a customised prompt, passed to an LLM, which generates a response (see Figure 1). For further details, see Lewis et al. (2021).
A real-world application can, for instance, connect an LLM to a database of medical guideline documents. Medical practitioners can replace manual look-up by asking natural language questions using RAG as a “search engine”. The application would answer the user’s question and reference the source guideline. If the answer is based on parametric memory, e.g. answering on guidelines contained in the pre-training but not the connected database, or if the LLM hallucinates, this could have drastic implications.
Firstly, if the medical practitioners verify with the referenced guidelines, they could lose trust in the application answers, leading to less usage. Secondly, and more worryingly, if not every answer is verified, an answer can be falsely assumed to be based on the queried medical guidelines, directly affecting the patient’s treatment. This highlights the relevance of the truthfulness of output in RAG applications.
In this article assessing RAG, truth is defined as being firmly grounded in factual knowledge of the retrieved document. To investigate this issue, one General Research Question (GRQ) and three Specific Research Questions (SRQ) are derived.
GRQ: How can the truthfulness of RAG outputs be improved?
SRQ 1: What causes untruthful results to be generated by RAG applications?
SRQ 2: How can truthfulness be evaluated?
SRQ 3: What methods can be used to increase truthfulness?
To answer the GRQ, the SRQs are analysed sequentially on the basis of literature research. The aim is to identify methods that can be implemented for use cases such as the above example from the medical field. Ultimately two categories of solution methods will be recommended for further analysis and customisation.
2. Untruthful RAG output
As previously defined, a truthful answer should be firmly grounded in factual knowledge of the retrieved document. One metric for this is factual consistency, measuring if the summary contains untruthful or misleading facts that are not supported by the source text (Liu et al., 2023). It is used as a critical evaluation metric in multiple benchmarks (Kim et al., 2023; Fabbri et al., 2021; Deutsch & Roth, 2022; Wang et al., 2023; Wu et al., 2023). In the area of RAG, this is often referred to as groundedness (Levonian et al., 2023). Moreover, to take the usefulness of a truthful answer into consideration, its completeness is also of relevance. The following paragraphs give insight into the reason behind untruthful RAG results. This refers to the Generation Step in Figure 1, which summarises the retrieved documents with respect to the user question.
Firstly, the groundedness of an RAG application is impacted if the LLM answer is based on parametric memory rather than the factual knowledge of the retrieved document. This can, for instance, occur if the answer comes from pre-trained knowledge or is caused by hallucinations. Hallucinations still remain a fundamental problem of LLMs (Bang et al., 2023; Ji et al., 2023; Zhang & Gao, 2023), from which even powerful LLMs suffer (Liu et al., 2023). As per definition, low groundedness results in untruthful RAG results.
Secondly, completeness describes if an LLM´s answer lacks factual knowledge from the documents. This can be due to the low summarisation capability of an LLM or missing domain knowledge to interpret the factual knowledge (T. Zhang et al., 2023). The output could still be highly grounded. Nevertheless, an answer could be incomplete with respect to the documents. Leading to incorrect user perception of the content of the database. In addition, if factual knowledge from the document is missing, the LLM can be encouraged to make up for this by answering with its own parametric memory, raising the abovementioned issue.
Having established the key causes of untruthful outputs, it is necessary to first measure and quantify these errors before a solution can be pursued. Therefore, the following section will cover the methods of measurement for the aforementioned sources of untruthful RAG outputs.
3. Evaluating truthfulness
Having elaborated on groundedness and completeness and their origins, this section intends to guide through their measurement methods. I will begin with the widely known general-purpose methods and continue by highlighting recent trends. TruLens´s Feedback Functions plot serves here as a valuable reference for scalability and meaningfulness (see Figure2).
When talking about natural language generation evaluations, traditional evaluation metrics like ROUGE (Lin, 2004) and BLEU (Papineni et al., 2002) are widely used but tend to show a discrepancy from human assessments (Liu et al., 2023). Furthermore, Medium Language Models (MLMs) have demonstrated superior results to traditional evaluation metrics, but can be replaced by LLMs in many areas (X. Zhang & Gao, 2023). Lastly, another well-known evaluation method is the human evaluation of generated text, which has apparent drawbacks of scale and cost (Fabbri et al., 2021). Due to the downsides of these methods (see Figure 2), these are not relevant for further consideration in this paper.
Concerning recent trends, evaluation metrics have developed with the increase in the popularity of LLMs. One such development are LLM evaluations, allowing another LLM through Chain of Thought (CoT) reasoning to evaluate the generated text (Liu et al., 2023). Through bespoke prompting strategies, areas of focus like groundedness and completeness can be emphasised and numerically scored (Kim et al., 2023). For this method, it has been shown that a larger model size is beneficial for summarisation evaluation (Liu et al., 2023). Moreover, this evaluation can also be based on references or collected ground truth, comparing generated text and reference text (Wu et al., 2023). For open-ended tasks without a single correct answer, LLM-based evaluation outperforms reference-based metrics in terms of correlation with human quality judgements. Moreover, ground-truth collection can be costly. Therefore, reference or ground-truth based metrics are outside the scope of this assessment (Liu et al., 2023; Feedback Functions — TruLens, o. J.).
Concluding with a noteworthy recent development, the Learnable Evaluation Metric for Text Simplification (LENS), stated to be “the first supervised automatic metric for text simplification evaluation” by Maddela et al. (2023), has demonstrated promising outcomes in recent benchmarks. It is recognized for its effectiveness in identifying hallucinations (Kew et al., 2023). In terms of scalability and meaningfulness this is expected to be slightly more scalable, due to lower cost, and slightly less meaningful than LLM evaluations, placing LENS close to LLM Evals in the right top corner of Figure 2. Nevertheless, further assessment would be required to verify these claims. This would conclude the evaluations methods in scope and the next section is focusing on methods of their application.
4. Toward increased truthfulness
Having established in section 1, the relevance of truthfulness in RAG applications, with SRQ1 the causes of untruthful output and with SRQ2 its evaluation, this section will focus on SRQ3. Hence, detailing specific recommended methods improving groundedness and completeness to increase truthful responses. These methods can be categorised into two groups, improvements in the generation of output and validation of output.
In order to improve the generation step of the RAG application, this article will highlight two methods. These are visualised in Figure 3, with the simplified RAG architecture referenced on the left. The first methods is fine-tuning the generation LLM. Instruction tuning over model size is critical to the LLM’s zero-shot summarisation capability. Thus, state-of-the-art LLMs can perform on par with summaries written by freelance writers (T. Zhang et al., 2023). The second method focuses on element-aware summarisation. With CoT prompting, like presented in SumCoT, LLMs can generate summaries step by step, emphasising the factual entities of the source text (Wang et al., 2023). Specifically, in an additional step, factual elements are extracted from the relevant documents and made available to the LLM in addition to the context for the summarisation, see Figure 3. Both methods have shown promising results for improving the groundedness and completeness of LLM-generated summaries.
In validation of the RAG outputs, LLM-generated summaries are evaluated for groundedness and completeness. This can be done by CoT prompting an LLM to aggregate a groundedness and completeness score. In Figure 4 an example CoT prompt is depicted, which can be forwarded to an LLM of larger model size for completion. Furthermore, this step can be replaced or advanced by using supervised metrics like LENS. At last, the generated evaluation is compared against a threshold. In case of not grounded or incomplete outputs, those can be modified, raised to the user or potentially rejected.
Before adapting these methods to RAG applications, it should be considered that evaluation at run-time and fine-tuning the generation model will lead to additional costs. Furthermore, the evaluation step will affect the applications’ answering speed. Lastly, no answer due to output rejections and raised truthfulness concerns might confuse application users. Consequently, it is critical to evaluate these methods with respect to the field of application, the functionality of the application and the user´s expectations. Leading to a customised approach increasing outputs truthfulness of RAG applications.
Unless otherwise noted, all images are by the author.
List of References
Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D., Wilie, B., Lovenia, H., Ji, Z., Yu, T., Chung, W., Do, Q. V., Xu, Y., & Fung, P. (2023). A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity (arXiv:2302.04023). arXiv. https://doi.org/10.48550/arXiv.2302.04023
Deutsch, D., & Roth, D. (2022). Benchmarking Answer Verification Methods for Question Answering-Based Summarization Evaluation Metrics (arXiv:2204.10206). arXiv. https://doi.org/10.48550/arXiv.2204.10206
Fabbri, A. R., Kryściński, W., McCann, B., Xiong, C., Socher, R., & Radev, D. (2021). SummEval: Re-evaluating Summarization Evaluation (arXiv:2007.12626). arXiv. https://doi.org/10.48550/arXiv.2007.12626
Feedback Functions — TruLens. (o. J.). Abgerufen 11. Februar 2024, von https://www.trulens.org/trulens_eval/core_concepts_feedback_functions/#feedback-functions
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Dai, W., Madotto, A., & Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), 1–38. https://doi.org/10.1145/3571730
Kew, T., Chi, A., Vásquez-Rodríguez, L., Agrawal, S., Aumiller, D., Alva-Manchego, F., & Shardlow, M. (2023). BLESS: Benchmarking Large Language Models on Sentence Simplification (arXiv:2310.15773). arXiv. https://doi.org/10.48550/arXiv.2310.15773
Kim, J., Park, S., Jeong, K., Lee, S., Han, S. H., Lee, J., & Kang, P. (2023). Which is better? Exploring Prompting Strategy For LLM-based Metrics (arXiv:2311.03754). arXiv. https://doi.org/10.48550/arXiv.2311.03754
Levonian, Z., Li, C., Zhu, W., Gade, A., Henkel, O., Postle, M.-E., & Xing, W. (2023). Retrieval-augmented Generation to Improve Math Question-Answering: Trade-offs Between Groundedness and Human Preference (arXiv:2310.03184). arXiv. https://doi.org/10.48550/arXiv.2310.03184
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arXiv:2005.11401). arXiv. https://doi.org/10.48550/arXiv.2005.11401
Lin, C.-Y. (2004). ROUGE: A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out, 74–81. https://aclanthology.org/W04-1013
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., & Zhu, C. (2023). G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment (arXiv:2303.16634). arXiv. https://doi.org/10.48550/arXiv.2303.16634
Maddela, M., Dou, Y., Heineman, D., & Xu, W. (2023). LENS: A Learnable Evaluation Metric for Text Simplification (arXiv:2212.09739). arXiv. https://doi.org/10.48550/arXiv.2212.09739
Papineni, K., Roukos, S., Ward, T., & Zhu, W.-J. (2002). Bleu: A Method for Automatic Evaluation of Machine Translation. In P. Isabelle, E. Charniak, & D. Lin (Hrsg.), Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (S. 311–318). Association for Computational Linguistics. https://doi.org/10.3115/1073083.1073135
Wang, Y., Zhang, Z., & Wang, R. (2023). Element-aware Summarization with Large Language Models: Expert-aligned Evaluation and Chain-of-Thought Method (arXiv:2305.13412). arXiv. https://doi.org/10.48550/arXiv.2305.13412
Wu, N., Gong, M., Shou, L., Liang, S., & Jiang, D. (2023). Large Language Models are Diverse Role-Players for Summarization Evaluation (arXiv:2303.15078). arXiv. https://doi.org/10.48550/arXiv.2303.15078
Zhang, T., Ladhak, F., Durmus, E., Liang, P., McKeown, K., & Hashimoto, T. B. (2023). Benchmarking Large Language Models for News Summarization (arXiv:2301.13848). arXiv. https://doi.org/10.48550/arXiv.2301.13848
Zhang, X., & Gao, W. (2023). Towards LLM-based Fact Verification on News Claims with a Hierarchical Step-by-Step Prompting Method (arXiv:2310.00305). arXiv. https://doi.org/10.48550/arXiv.2310.00305
Towards increased truthfulness in LLM applications was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.