
Tuning-Free Longer Context Lengths For LLMs — A Review of Self-Extend (LLM Maybe LongLM)
Tuning-Free Longer Context Lengths For LLMs — A Review of Self-Extend (LLM Maybe LongLM)
A simple strategy to enable LLMs to consume longer context length inputs during inference without the need for finetuning.
In this article we will look at the paper “LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning” by Hongye Jin et. al. that was just released on arxiv 2 days ago (2nd Jan 2024).
Github: https://github.com/datamllab/LongLM
LLMs like GPT-3 or BERT are typically trained on fixed-length sequences. This design choice arises from practical constraints: managing computational resources and maintaining efficiency during training. As a result, these models are usually trained on sequences of a predetermined maximum length (like 512 tokens for BERT, or a few thousand for larger models). The limitation here is that the model’s self-attention mechanism, a key component that helps the model understand and generate language, is trained to only attend to contexts within this fixed length.
During training, the model learns to create representations of input sequences, incorporating both the content (tokens) and position of each token. Positional encoding , a method to incorporate the order of words, plays a crucial role here. However, since the training involves fixed-length sequences, the model’s understanding of positional relationships is confined to this range. When faced with longer sequences at inference time, the model encounters positions and relative distances between tokens that it has never seen before, leading to what the authors refer to as “positional O.O.D (Out-Of-Distribution)” issues. Essentially, the model’s performance degrades because it is processing input that is different in structure from what it was trained on.
The challenge, therefore, lies in enabling these models to handle longer sequences then they were trained on, without encountering performance degradation due to positional O.O.D issues. This problem is especially pertinent in real-world applications where input sequences can be much longer than the training sequences, and the ability to maintain context over these longer lengths is crucial for tasks like document summarization, extended conversation understanding, or reading lengthy technical documents. The authors argue that LLMs are naturally equipped to handle longer text sequences than they are typically trained on, the only major bottleneck to this potential is O.O.D positional encodings.
The paper suggested a simple yet effective strategy to adapt the longer ‘inference time’ sequences to models trained on limited context length without any finetuning.
Before we talk about the paper’s approach lets quickly look at perplexity metric used to evaluate LLMs.
Perplexity (PPL)
Perplexity (PPL) is a commonly used metric in NLP to evaluate the performance of language models. It’s a measure of how well a probabilistic model predicts a sample. In the context of language models, perplexity gauges how well the model predicts a sequence of words. Perplexity is defined as the exponentiated average negative log-likelihood of a sequence of words. Mathematically
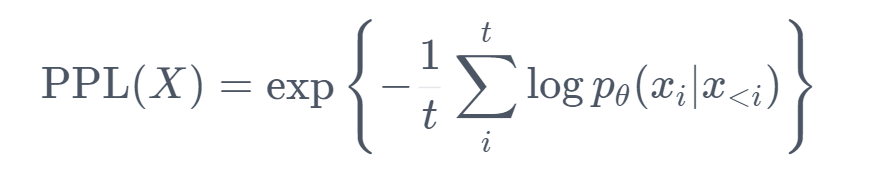
A lower perplexity score indicates a better language model. It means the model assigns higher probabilities, on average, to the test samples it sees. In other words, the model is less ‘surprised’ by the actual sequence of words it encounters, which is why the term ‘perplexity’ is used. Perplexity is usually used for causal models like GPT, Mistral etc (and not for MLMs like BERT). A great blog on huggingface to understand perplexity: https://huggingface.co/docs/transformers/perplexity
Self-Extend
In standard LLMs, each token in a sequence attends to every other token, considering their relative positions. This positional information is critical for understanding the context and relationships between words. However, this mechanism is based on the maximum sequence length seen during training. When the input sequence exceeds this length, the model encounters positions it has never seen before (O.O.D.), leading to a decrease in performance.
Grouped Attention:
To convert the O.O.D. positions into the range that model is trained to see, a simple mathematical “floor division” (denoted as “//” in programming) operation is performed.

For example, consider a sequence of 8 tokens and a group size of 2. The original positions [0, 1, 2, 3, 4, 5, 6, 7] would be mapped to [0, 0, 1, 1, 2, 2, 3, 3]. By grouping tokens, the model can handle sequences longer than its original training limitation, effectively extending its context window.
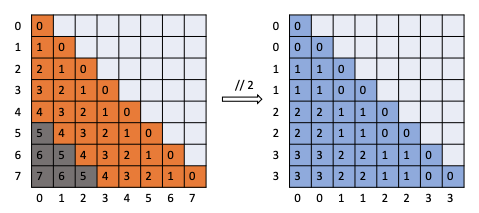
But this inaccuracy in positions where multiple tokens have same positional embedding can leads to some degradataion in performance. The paper shows that with small group size PPL (Perplexity) is a slightly higher than the original LLMs.
The neighboring tokens are the most important tokens to generate the next token. For tokens that are close to each other, the precise relative positioning is essential for understanding the immediate context, such as the syntax and semantics of a sentence. Whereas when the tokens are far apart in a text, the precise relative positions between them become less crucial for understanding the overall context or meaning. The exact order of words in distant parts of a text is less important than the general thematic connection between those parts.
This is where the paper proposes to combine the grouped attention (which has the FLOOR operation applied) with normal attention (with regular positions). The authors propose using normal attention for a predefined “neighbor window” around each token and grouped attention for tokens outside this window. Using the notations from the paper, ‘L’: Pretraining context window size, ‘G’: Group size for grouped attention, ‘wn’: Window size for neighbor tokens:
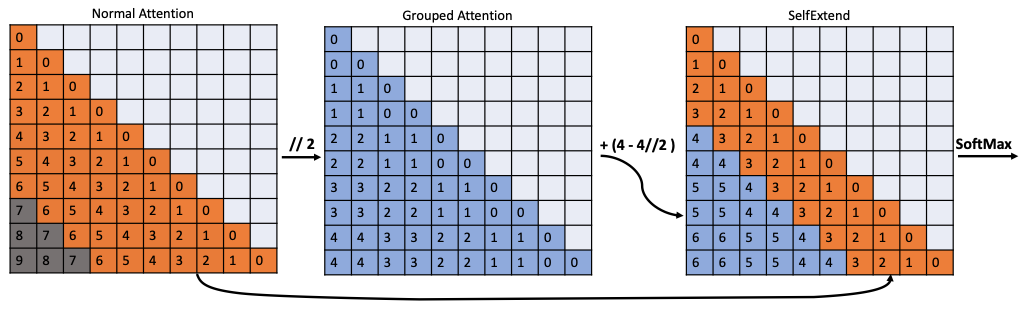
The authors introduce a shift in the relative position for grouped attention by wn − (wn // G) to ensure a smooth transition between normal and grouped attention areas. Finally, they merge the two parts of attention by replacing the attention values outside the neighbor token window with the values from grouped attention.
For example, considering a sequence where the original model’s context window is 7 tokens, the group size is 2, and the neighbor window is 4 tokens. For token positions [0, 1, 2, 3, 4, 5, 6], normal attention is applied to [0, 1, 2, 3] and grouped attention to [4, 5, 6]. The attention matrix will be a blend of the two, with the precise attention for the first four tokens and grouped attention for the last three. The final attention matrix is then used to compute the output of the Transformer’s attention layer, maintaining both local precision and long-range context awareness.
Conclusion
The paper showed comparison against LLaMA-2, Mistral and SOLAR with and without Self-Extend. As per the paper, Self-extend significantly decreases the perplexity of the models for long context window sizes. The models were also tested on a variety of tasks such as single-document and multi-document question answering, summarization, and few-shot learning. In most cases, LLMs with Self-Extend outperformed their original versions and even some fine-tuned models on these benchmarks. The models were also tested on various short-context tasks from the Hugging Face Open LLM benchmark suite. There was negligible impact on the performance of these tasks, indicating that Self-Extend does not adversely affect the model’s ability to handle shorter texts.
This task asks a language model to find a basic passkey (a random five-digit number) hidden in a lengthy, nonsensical text sequence scattered at various levels. The findings reveal that Self-Extend, without specific adjustments, achieves 100% success in finding the passkey at all tested depths and context lengths.
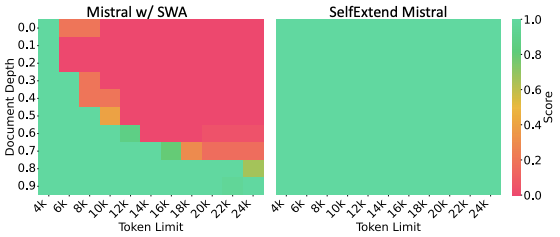
Additionally, the results show that even though Mistral w/ SWA (Sliding Window Attention) has a reduced PPL outside its initial training context range, it’s limited to extracting information (like the passkey) only within its sliding window.
Overall, this suggests that Self-Extend successfully leverages the inherent capabilities of LLMs for extended contexts.
Tuning-Free Longer Context Lengths For LLMs — A Review of Self-Extend (LLM Maybe LongLM) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Tuning-Free Longer Context Lengths For LLMs — A Review of Self-Extend (LLM Maybe LongLM)
A simple strategy to enable LLMs to consume longer context length inputs during inference without the need for finetuning.

In this article we will look at the paper “LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning” by Hongye Jin et. al. that was just released on arxiv 2 days ago (2nd Jan 2024).
Github: https://github.com/datamllab/LongLM
LLMs like GPT-3 or BERT are typically trained on fixed-length sequences. This design choice arises from practical constraints: managing computational resources and maintaining efficiency during training. As a result, these models are usually trained on sequences of a predetermined maximum length (like 512 tokens for BERT, or a few thousand for larger models). The limitation here is that the model’s self-attention mechanism, a key component that helps the model understand and generate language, is trained to only attend to contexts within this fixed length.
During training, the model learns to create representations of input sequences, incorporating both the content (tokens) and position of each token. Positional encoding , a method to incorporate the order of words, plays a crucial role here. However, since the training involves fixed-length sequences, the model’s understanding of positional relationships is confined to this range. When faced with longer sequences at inference time, the model encounters positions and relative distances between tokens that it has never seen before, leading to what the authors refer to as “positional O.O.D (Out-Of-Distribution)” issues. Essentially, the model’s performance degrades because it is processing input that is different in structure from what it was trained on.
The challenge, therefore, lies in enabling these models to handle longer sequences then they were trained on, without encountering performance degradation due to positional O.O.D issues. This problem is especially pertinent in real-world applications where input sequences can be much longer than the training sequences, and the ability to maintain context over these longer lengths is crucial for tasks like document summarization, extended conversation understanding, or reading lengthy technical documents. The authors argue that LLMs are naturally equipped to handle longer text sequences than they are typically trained on, the only major bottleneck to this potential is O.O.D positional encodings.
The paper suggested a simple yet effective strategy to adapt the longer ‘inference time’ sequences to models trained on limited context length without any finetuning.
Before we talk about the paper’s approach lets quickly look at perplexity metric used to evaluate LLMs.
Perplexity (PPL)
Perplexity (PPL) is a commonly used metric in NLP to evaluate the performance of language models. It’s a measure of how well a probabilistic model predicts a sample. In the context of language models, perplexity gauges how well the model predicts a sequence of words. Perplexity is defined as the exponentiated average negative log-likelihood of a sequence of words. Mathematically
A lower perplexity score indicates a better language model. It means the model assigns higher probabilities, on average, to the test samples it sees. In other words, the model is less ‘surprised’ by the actual sequence of words it encounters, which is why the term ‘perplexity’ is used. Perplexity is usually used for causal models like GPT, Mistral etc (and not for MLMs like BERT). A great blog on huggingface to understand perplexity: https://huggingface.co/docs/transformers/perplexity
Self-Extend
In standard LLMs, each token in a sequence attends to every other token, considering their relative positions. This positional information is critical for understanding the context and relationships between words. However, this mechanism is based on the maximum sequence length seen during training. When the input sequence exceeds this length, the model encounters positions it has never seen before (O.O.D.), leading to a decrease in performance.
Grouped Attention:
To convert the O.O.D. positions into the range that model is trained to see, a simple mathematical “floor division” (denoted as “//” in programming) operation is performed.
For example, consider a sequence of 8 tokens and a group size of 2. The original positions [0, 1, 2, 3, 4, 5, 6, 7] would be mapped to [0, 0, 1, 1, 2, 2, 3, 3]. By grouping tokens, the model can handle sequences longer than its original training limitation, effectively extending its context window.
But this inaccuracy in positions where multiple tokens have same positional embedding can leads to some degradataion in performance. The paper shows that with small group size PPL (Perplexity) is a slightly higher than the original LLMs.
The neighboring tokens are the most important tokens to generate the next token. For tokens that are close to each other, the precise relative positioning is essential for understanding the immediate context, such as the syntax and semantics of a sentence. Whereas when the tokens are far apart in a text, the precise relative positions between them become less crucial for understanding the overall context or meaning. The exact order of words in distant parts of a text is less important than the general thematic connection between those parts.
This is where the paper proposes to combine the grouped attention (which has the FLOOR operation applied) with normal attention (with regular positions). The authors propose using normal attention for a predefined “neighbor window” around each token and grouped attention for tokens outside this window. Using the notations from the paper, ‘L’: Pretraining context window size, ‘G’: Group size for grouped attention, ‘wn’: Window size for neighbor tokens:
The authors introduce a shift in the relative position for grouped attention by wn − (wn // G) to ensure a smooth transition between normal and grouped attention areas. Finally, they merge the two parts of attention by replacing the attention values outside the neighbor token window with the values from grouped attention.
For example, considering a sequence where the original model’s context window is 7 tokens, the group size is 2, and the neighbor window is 4 tokens. For token positions [0, 1, 2, 3, 4, 5, 6], normal attention is applied to [0, 1, 2, 3] and grouped attention to [4, 5, 6]. The attention matrix will be a blend of the two, with the precise attention for the first four tokens and grouped attention for the last three. The final attention matrix is then used to compute the output of the Transformer’s attention layer, maintaining both local precision and long-range context awareness.
Conclusion
The paper showed comparison against LLaMA-2, Mistral and SOLAR with and without Self-Extend. As per the paper, Self-extend significantly decreases the perplexity of the models for long context window sizes. The models were also tested on a variety of tasks such as single-document and multi-document question answering, summarization, and few-shot learning. In most cases, LLMs with Self-Extend outperformed their original versions and even some fine-tuned models on these benchmarks. The models were also tested on various short-context tasks from the Hugging Face Open LLM benchmark suite. There was negligible impact on the performance of these tasks, indicating that Self-Extend does not adversely affect the model’s ability to handle shorter texts.
This task asks a language model to find a basic passkey (a random five-digit number) hidden in a lengthy, nonsensical text sequence scattered at various levels. The findings reveal that Self-Extend, without specific adjustments, achieves 100% success in finding the passkey at all tested depths and context lengths.
Additionally, the results show that even though Mistral w/ SWA (Sliding Window Attention) has a reduced PPL outside its initial training context range, it’s limited to extracting information (like the passkey) only within its sliding window.
Overall, this suggests that Self-Extend successfully leverages the inherent capabilities of LLMs for extended contexts.
Tuning-Free Longer Context Lengths For LLMs — A Review of Self-Extend (LLM Maybe LongLM) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Denial of responsibility! Techno Blender is an automatic aggregator of the all world’s media. In each content, the hyperlink to the primary source is specified. All trademarks belong to their rightful owners, all materials to their authors. If you are the owner of the content and do not want us to publish your materials, please contact us by email – [email protected]. The content will be deleted within 24 hours.